Download presentation
Presentation is loading. Please wait.

1
Statistics 상지대학교 1 / 22 추정 개요 점추정과 구간추정 표본크기 두 모집단의 비교

2
Statistics 상지대학교 2 / 22 질문 1 : 동전을 10 번 던져 앞면이 6 번, 뒷면이 4 번 나타났다면 이 동전은 잘 만들어졌다 고 할 수 있을까 ? 잘 만들어진 동전 - 앞면과 뒷면이 나타날 확률이 각각 50% 인 동전 확률 50% 란 - 무한 번의 확률실험을 할 때 그 중 반은 앞면이 나타난다 ⇒ 동전을 무한 번 던져보기 전에는 앞면이 나타날 확률이 50% 라는 사실을 정확히 알 수 없다 질문 2 : 총 근로자가 5,000 명인 어느 회사에서 출근시간 자유 (flexible schedule) 제를 시행하기 전에는 총 근로자의 일년 평균 결근일이 3 일 ( 표준편차 1 일 ) 이 었으나 시행 후 25 명의 근로자들을 뽑아 평균 결근일을 조사한 결과 2 일이었 다면 이 제도는 과연 이 회사 근로자들의 결근일을 줄이는데 기여한 것일까 ? 전체 근로자 5,000 명 중 25 명만 조사 두 질문의 공통점 : 일부분만 (10 회 또는 25 명 ) 조사
 제를 시행하기 전에는 총 근로자의 일년 평균 결근일이 3 일 ( 표준편차 1 일 ) 이 었으나 시행 후 25 명의 근로자들을 뽑아 평균 결근일을 조사한 결과 2 일이었 다면 이 제도는 과연 이 회사 근로자들의 결근일을 줄이는데 기여한 것일까 . 전체 근로자 5,000 명 중 25 명만 조사 두 질문의 공통점 : 일부분만 (10 회 또는 25 명 ) 조사.")
3
Statistics 상지대학교 3 / 22 모집단의 크기 동전던지기 - 무한 (infinite), 근로자 - 유한 (finite) * 한 의사가 진료한 단 몇 명의 환자가 모집단이 될 수 있다 질문 3 : 이처럼 관심의 대상인 모집단의 크기가 무한일 수도 있고 유한일 수도 있다면, 연구자는 어떤 크기의 모집단을 선택하는 것이 좋을까 ? 연구자의 관심대상이 무엇이냐에 따라 모집단의 성격과 크기가 결정되므 로, 연구의 목표 ( 관심 ) 가 가치가 있느냐로 판단할 문제지, 단순히 모집단의 크기만 생각한다는 것은 무의미하다 다만 연구가치가 있는 모집단일 경우, 크기가 작다면 모집단 자체를 직접 조사하기 쉬운 반면, 크다는 것은 자신의 연구결과가 보다 더 넓은 대상에 적용 모집단 자체 조사 ( 전수조사, Census) - 불가능할 수도 있고 가능하다 하더 라도 그것을 조사하는 비용을 고려 지불할 수 있는 시간적, 경제적 비용의 범위 내에서 조사, 자신의 연구결과 의 확대 적용이 가능한 방법 ⇒ 모집단 전체를 잘 대표하는 부분집단 ( 표본 ) 만을 조사한 후 그 결과를 보 다 큰 대상 ( 모집단 ) 에 확대 적용시키는 방법
 가 가치가 있느냐로 판단할 문제지, 단순히 모집단의 크기만 생각한다는 것은 무의미하다 다만 연구가치가 있는 모집단일 경우, 크기가 작다면 모집단 자체를 직접 조사하기 쉬운 반면, 크다는 것은 자신의 연구결과가 보다 더 넓은 대상에 적용 모집단 자체 조사 ( 전수조사, Census) - 불가능할 수도 있고 가능하다 하더 라도 그것을 조사하는 비용을 고려 지불할 수 있는 시간적, 경제적 비용의 범위 내에서 조사, 자신의 연구결과 의 확대 적용이 가능한 방법 ⇒ 모집단 전체를 잘 대표하는 부분집단 ( 표본 ) 만을 조사한 후 그 결과를 보 다 큰 대상 ( 모집단 ) 에 확대 적용시키는 방법.")
4
Statistics 상지대학교 4 / 22 확률표본 : 집단을 잘 대표하는 표본 ? 연구자의 주관이나 편견이 개입되지 않은, 모집단에서 골고루 뽑힌 표본 골고루 ? - 모집단의 구성원 어느 누구라도 표본으로 뽑힐 가능성이 같다 랜덤샘플링 (random sampling) 확률표본 (random sample) 확률표본에서 얻은 결과는 모집단을 정확히 반영 ? 예 ) 100 명으로 구성된 모집단 자료 ( 평균 ) 랜덤하게 48 명을 뽑았을 때의 평균 또 다시 48 명을 랜덤하게 뽑았을 때의 평균 모두 같을까 ?
 확률표본 (random sample) 확률표본에서 얻은 결과는 모집단을 정확히 반영 . 예 ) 100 명으로 구성된 모집단 자료 ( 평균 ) 랜덤하게 48 명을 뽑았을 때의 평균 또 다시 48 명을 랜덤하게 뽑았을 때의 평균 모두 같을까 .")
5
Statistics 상지대학교 5 / 22 랜덤샘플링 ⇒ 일치한다고 할 수 없다 표본이 가진 정보가 부분적 ⇒ 표본의 정보에 근거한 주장은 어느 정도 불확실성 (uncertainty) 모수와 통계량 모수 (parameter) - 모집단 분포의 특성을 나타내는 양적 (quantitative) 척도 통계량 (statistic) - 표본분포의 특성을 나타내는 양적 척도 모수 – 그리스문자 , 통계량 – 알파벳
 모수와 통계량 모수 (parameter) - 모집단 분포의 특성을 나타내는 양적 (quantitative) 척도 통계량 (statistic) - 표본분포의 특성을 나타내는 양적 척도 모수 – 그리스문자 , 통계량 – 알파벳")
6
Statistics 상지대학교 6 / 22 추정 (Estimation) 모집단평균 ( 모수 ) 표본평균 ( 통계량 ) Sampling Estimation How Sampling ? →SRS, SRS, SS, CS →Size(sub group), interval How estimating ? →tools : mean, variance, … →point estimation →interval estimation →hypothesis testing
, interval How estimating . →tools : mean, variance, … →point estimation →interval estimation →hypothesis testing.")
7
Statistics 상지대학교 7 / 22 추정량 (estimator) : 추정에 사용된 통계량 / P183 추정량은 어느 정도 믿을 수 있는가 ? ⇒ 표본평균은 모평균과 얼마나 가까운가 ? 모집단 평균 4.5 4.2 4.6 4.84.4 4.5

8
Statistics 상지대학교 8 / 22 95% C.I.(confidence interval) 표준오차 (S.E., standard error) : 표본평균의 표준편차
 표준오차 (S.E., standard error) : 표본평균의 표준편차")
9
Statistics 상지대학교 9 / 22 브라운관 수명 (P180 reading) 6.2 3.7 5.6 6.7 5.9 6.8 5.0 4.1 5.3 4.8 – 위의 자료가 나타내는 모집단의 분포에서 알고자 하는 정보 – 정보를 얻을 수 있는 방법 모집단의 특성 ← 중심위치, 산포도 모평균, 모분산, 모비율과 같은 모수에 대한 어떤 판단을 내려야 한다. 모집단 → 표본 → 표본평균, 표본분산 → 모평균, 모분산 데이터를 기초로 통계이론에 의한 결론 ← 이러한 과정 “ 통계적 추론 ” 통계적 추정 : 표본을 이용하여 모수와 같은 모집단의 어떤 미지의 값을 추측하는 과정 → 브라운관의 평균 수명 ( ) 가설검정 : 표본을 이용하여 모집단에 대한 어떤 예상 또는 주장의 옳고 그름을 판정하거 나 주장의 채택 또는 기각을 결정하는 과정 → 브라운관의 수명이 5.4 이상이라는 주장이 옳은가 ? 그른가 ? 점 추정 : 하나의 모수를 하나의 값으로 추정 (P 814) 구간추정 : 모수가 포함되리라고 기대되는 범위를 구하는 것 → 추정 가설검정
 가설검정 : 표본을 이용하여 모집단에 대한 어떤 예상 또는 주장의 옳고 그름을 판정하거 나 주장의 채택 또는 기각을 결정하는 과정 → 브라운관의 수명이 5.4 이상이라는 주장이 옳은가 . 그른가 . 점 추정 : 하나의 모수를 하나의 값으로 추정 (P 814) 구간추정 : 모수가 포함되리라고 기대되는 범위를 구하는 것 → 추정 가설검정.")
10
Statistics 상지대학교 10 / 22 전체 값에서 자유롭게 변화할 수 있는 측정치의 수 주어진 자료에서 표준편차를 구하는 경우 먼저 각 점수의 편차를 구한다. 그 런데 편차는 모든 편차의 합은 “0” 이라는 조건 때문에 서로 독립적인 값이 아 니라 서로 관련되어 있다. 제곱합을 자유도로 나눈 것을 산포의 측도로 이용한다. 5 5 15 10 원자료 10 ? ? 7 7 ? ? 1 1 내각의 합 은 180° 20 ? ? 5 5 자유도를 이용하여 표본의 통계치를 계산하면 그 값은 모집단의 불편 추정 치가 된다. 자유도 (degree of freedom;df)
.")
11
Statistics 상지대학교 11 / 22 점추정 모평균의 추정 (P184) – 가장 관심이 많은 모수이다. –μ 를 추정 – 무한모집단의 경우 모집단의 평균이 μ 이고, 분산이 일 때 표본평균 는 여기에서 불편추정량 : 모수 θ 의 추정량 에 대하여 – 불편추정이 얼마나 좋은 추정량인가를 나타내는 방법으로 그 추정량의 표준편차를 이용한 다.(P185) 표본평균 의 성질 (P186 그림 7-1 설명 ) – ( 는 μ 의 불편 추정량 ) – 표준오차 표준오차
 표본평균 의 성질 (P186 그림 7-1 설명 ) – ( 는 μ 의 불편 추정량 ) – 표준오차 표준오차.")
12
Statistics 상지대학교 12 / 22 점추정 표본평균 의 성질 (P186 그림 7-1 설명할 것 ) – 모집단 μ 를 중심으로 대칭인 분포를 따르면 의 분포도 μ 를 중심으로 대칭이며 – 표준편차는 모표준편차의 로서 n 값이 클수록 는 μ 에 더욱 밀집된 분포를 따른다. – 는 μ 에 아주 가까운 값이 될 것을 기대한다., s 의 자리수 → 소표본 ( 데이터의 자리수 보다 1 자리 많게 ) 대표본 ( 데이터의 자리수 보다 2 자리 많게 ) s 의 유효숫자 → 3 자리까지 소표본 → 30 이하 대표본 → 30 이상 비모수통계학 → 10-15 제곱합의 간편계산법 (P187-8 reading) 표준오차의 의미 의 값이 모평균 μ 로부터 표준편차 의 거리 에 있는 값을 취할 가능성은 68.7% 정도
 대표본 ( 데이터의 자리수 보다 2 자리 많게 ) s 의 유효숫자 → 3 자리까지 소표본 → 30 이하 대표본 → 30 이상 비모수통계학 → 제곱합의 간편계산법 (P187-8 reading) 표준오차의 의미 의 값이 모평균 μ 로부터 표준편차 의 거리 에 있는 값을 취할 가능성은 68.7% 정도.")
13
Statistics 상지대학교 13 / 22 점추정 ( 예 7-2 / P189 reading ) 자동차회사 영업사원 → 차량수명을 고려하여 우편발송 7.5 6 5.5 3 3.5 10 8 6.5 7 4 3.5 3 5 5 11 2 2.5 7 7 7 ( 단위 : 년 ) 따라서 평균의 추정값과 오차는 다음과 같다.
 자동차회사 영업사원 → 차량수명을 고려하여 우편발송 ( 단위 : 년 ) 따라서 평균의 추정값과 오차는 다음과 같다.")
14
Statistics 상지대학교 14 / 22 점추정 모분산과 모표준편차의 추정 (P189 reading ) 관측값과 표본평균과의 차이 를 평균에 대한 편차라 한다. 즉, 편차들의 크기는 자료들이 표본평균으로부터 얼마나 퍼져 있는가를 나타내는 척 도이다. 편차의 합은 항상 0 이 된다. 대안제시가 필요함 ? 현실적 대안 ? 모비율의 추정량 (P192 reading ) 모비율 p 인 무한모집단에서 n 개의 표본을 추출, 특정 곡성을 갖는 개수 X ∼ B(n, p) Var(X) = np Var(X) = np(1-p) 자유도 자유로이 쓰는 이유 → 불편 추정량 ? 표본분산
 모비율 p 인 무한모집단에서 n 개의 표본을 추출, 특정 곡성을 갖는 개수 X ∼ B(n, p) Var(X) = np Var(X) = np(1-p) 자유도 자유로이 쓰는 이유 → 불편 추정량 . 표본분산.")
15
Statistics 상지대학교 15 / 22 점추정 모분산과 모표준편차의 추정량 (P191 reading ) 모분산의 추정량 모표준편차 추정량 모비율 p 의 추정량 : 표본비율 (P192 reading ) 모비율 p 인 무한모집단에서 n 개의 표본을 추출, 특정 곡성을 갖는 개수 X –B(n, p) 표본비율 의 성질 ( 는 p 의 불편 추정량 ) 표준오차
 모분산의 추정량 모표준편차 추정량 모비율 p 의 추정량 : 표본비율 (P192 reading ) 모비율 p 인 무한모집단에서 n 개의 표본을 추출, 특정 곡성을 갖는 개수 X –B(n, p) 표본비율 의 성질 ( 는 p 의 불편 추정량 ) 표준오차")
16
Statistics 상지대학교 16 / 22 구간추정 대표본에서 모평균의 신뢰구간 (P 193) 표준정규분포에서 오른쪽 꼬리의 면적이 α 인 점 이라 하자. 표준 정규확률변수 Z 에 대해 는 구간추정에서 사용하는 값은 다음과 같다. 이 평균이 μ 이고 분산이 인 무한 모집단에서의 확률표본일 때 다음이 성립 모집단이 정규분포를 따를 때 의 정의와 표준정규분포의 성질로 부터

17
Statistics 상지대학교 17 / 22 구간추정 Z 통계량을 고려하면 대표본에서 모평균 μ 의 100(1-α)% 신뢰구간 σ 알려질 때 σ 모를 때 참고 대표본에서 μ 의 신뢰구간 가운데 가장 많이 쓰이는 신뢰구산의 상한과 하한은 예 7-6(P199) 신뢰구간의 상 한
% 신뢰구간 σ 알려질 때 σ 모를 때 참고 대표본에서 μ 의 신뢰구간 가운데 가장 많이 쓰이는 신뢰구산의 상한과 하한은 예 7-6(P199) 신뢰구간의 상 한")
18
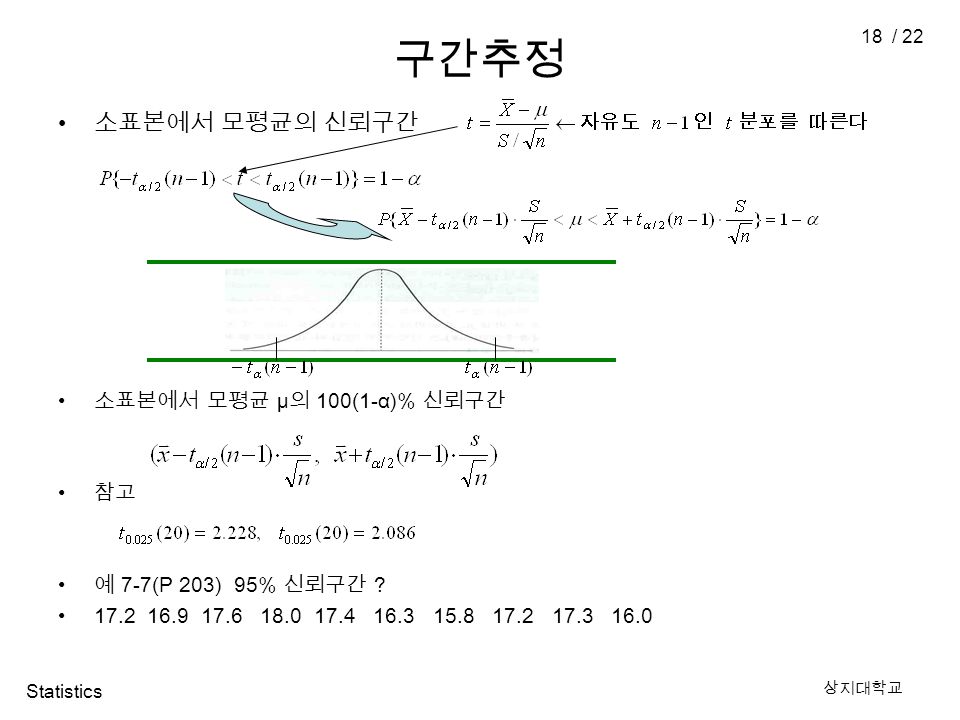
Statistics 상지대학교 18 / 22 구간추정 소표본에서 모평균의 신뢰구간 소표본에서 모평균 μ 의 100(1-α)% 신뢰구간 참고 예 7-7(P 203) 95% 신뢰구간 ? 17.2 16.9 17.6 18.0 17.4 16.3 15.8 17.2 17.3 16.0
19
Statistics 상지대학교 19 / 22 구간추정 대표본에서 모비율의 신뢰구간 대표본에서 모평균 p 의 100(1-α)% 신뢰구간 참고 적용한계점 : 표본크기 n 이 충분히 클 때 (np>5 이상일 때 ) 예 7-9(P 205) 95% 신뢰구간 ?
% 신뢰구간 참고 적용한계점 : 표본크기 n 이 충분히 클 때 (np>5 이상일 때 ) 예 7-9(P 205) 95% 신뢰구간")
20
Statistics 상지대학교 20 / 22 표본크기 결정 를 μ 의 추정에서 100(1-α)% 오차의 한계라고 한다. 과거의 자료로 부터 σ 를 알 경우 오차의 한계를 d 로 하기 위해 신뢰구간의 길이를 2d 로 하기 위한 표본크기 n 은 다음이 성립한다. 참고 ( 예 7-11) – P208 전구 수명 1,200 시간, 표준편차 : 100 시간, 95% 신뢰구간 추정에서 오차의 한계를 25 시간을 할 경우 표본 크기는 n= 62
 – P208 전구 수명 1,200 시간, 표준편차 : 100 시간, 95% 신뢰구간 추정에서 오차의 한계를 25 시간을 할 경우 표본 크기는 n= 62.")
21
Statistics 상지대학교 21 / 22 표본크기 결정 대표본에서 표본비율 의 100(1-α)% 오차의 한계는 오차의 한계를 d 로 이내로 하기 위한 표본크기 n 은 다음이 성립한다. 참고 p 에 대한 정보가 없을 때 ( 예 7-13) – P210 국회의원 선거에서 특정 후보의 지지율을 조사하였다. 과거 조사된 지지율에 의하면 42% 였다고 한다. 지지율의 95% 추정 오차의 한계를 3% 이내가 되기위해 표본 크기 는 n= 1040
 – P210 국회의원 선거에서 특정 후보의 지지율을 조사하였다. 과거 조사된 지지율에 의하면 42% 였다고 한다. 지지율의 95% 추정 오차의 한계를 3% 이내가 되기위해 표본 크기 는 n=")
22
Statistics 상지대학교 22 / 22 두집단의 비교 P211-P217 개인별 조사 및 정리

Similar presentations
 국가산술 (state arithmetic) 불확실성이 내포된 자료의 수집, 분석, 추정, 검정을 통하여 의사결정에 필요한 정보의 획득과 처리방법을 연구하는 학문 (decision-making science)>")
 -. 통계적사고 -. 모집단과 표본. 통계적 사고 모든 작업은 상호연관된 프로세스의 시스템 예 ) 열처리 작업 공정 원료 투입 공정가열 공정 냉각 공정 모든 프로세스에는 산포가 존재 가피원인 불가피원인 동일 원료동일 생산공정 동일 작업자동일.>")
 통계량 (statistic) 표본자료의 함수 즉 모집단 … … 표본 표본추출 … … 통계량 계산.>")





>")
>")

>")







