Download presentation
Presentation is loading. Please wait.

1
Chapter 8. TEXT CLUSTERING 서울시립대 전자전기컴퓨터공학과 데이터마이닝 연구실 G201149027 노준호

2
8.1 Introduction How to partition a collection of texts into groups? Classification (supervised) 정답 data 필요, 알고리즘에 의해 training 후 group 을 나눔 정답 data 에서 비용 발생 Clustering (unsupervised) 알고리즘, Unknown Data 만으로 group 을 나눔
 정답 data 필요, 알고리즘에 의해 training 후 group 을 나눔 정답 data 에서 비용 발생 Clustering (unsupervised) 알고리즘, Unknown Data 만으로 group 을 나눔.")
3
8.2 Clustering K-Means Simple technique

4
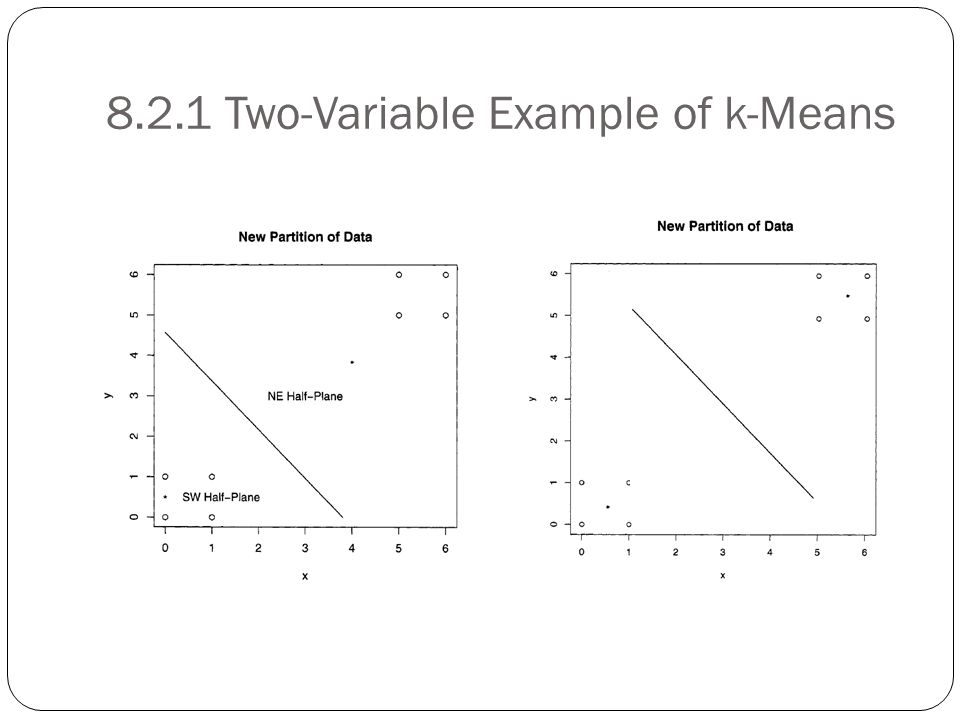
8.2.1 Two-Variable Example of k-Means

6
8.2.2 k-Means with R Using R Kmeans() 함수 제공 data = (0,0), (0,1), (1,0), (1,1), (5,5), (5,6), (6,5), (6,6)
 함수 제공 data = (0,0), (0,1), (1,0), (1,1), (5,5), (5,6), (6,5), (6,6)")
7
8.2.2 k-Means with R k = 4 일 때, 결과가 일정하지 않음 false 시작점이 random 하고, 결과가 시작점에 sensitive 함

8
8.2.3 He versus She in Poe’s Short Stories Clustering Data : Poe’s 69 short stories Data 개수 : 69 개 (short stories) Variable(Demension) 개수 : 2 개 (he, she) dataheShe 1(The Gold Bug)224 2(Four Beasts in One)1033 ………
 Variable(Demension) 개수 : 2 개 (he, she) dataheShe 1(The Gold Bug)224 2(Four Beasts in One)1033 ………")
9
8.2.3 He versus She in Poe’s Short Stories code

10
8.2.3 He versus She in Poe’s Short Stories output - poe68.csv - size.csv

11
8.2.3 He versus She in Poe’s Short Stories he, she 의 rate 를 계산

12
8.2.3 He versus She in Poe’s Short Stories Plotting

13
8.2.3 He versus She in Poe’s Short Stories k-Means (k = 2)
")
14
8.2.3 He versus She in Poe’s Short Stories k = 3, 4, 5, 6 일 때

15
8.2.3 He versus She in Poe’s Short Stories k = 6 일 때, 3 번 cluster 의 데이터들의 타이틀 3 번 cluster : she 의 비율이 높고, he 의 비율이 낮음

16
8.2.4 Poe Clusters Using Eight Pronouns k-means Variable(Demension) 개수 : 8 개 (he, she, him, her, his, hers, himself, herself) ( 단위 : rate) k = 2 plotting x 축 : heRate y 축 : herRate
 개수 : 8 개 (he, she, him, her, his, hers, himself, herself) ( 단위 : rate) k = 2 plotting x 축 : heRate y 축 : herRate")
17
8.2.4 Poe Clusters Using Eight Pronouns x 축 : heRate, y 축 : 다른 pronoun rate

18
8.2.4 Poe Clusters Using Eight Pronouns dimension 이 커질수록 분석이 어려움 poe’s story 의 dimension : 20,000 개 PCA 를 사용하여 dimension 을 줄임

19
8.2.5 clustering Poe Using Principal Components 주성분 추출

20
8.2.5 clustering Poe Using Principal Components k-Means (k =2) Variable : 8 개의 주성분, 2 개의 주성분
 Variable : 8 개의 주성분, 2 개의 주성분")
21
8.2.6 Hierarchical Clustering of Poe’s Short Stories Hierarchical clustering 가장 가까운 거리를 묶음

22
8.3 A note on classification Training 문서가 없어서 classification 을 다루지 않음 유명 작가의 classification 의 효용은 거의 없음 Overfitting 특정 문서에 특화됨 일반적인 문서에서 성능이 나쁠 수 있음

Similar presentations




 를 써서 말한 사람 (speaker) 의 말을 그대 로 전달하는 방법을 “ 직접화법 ” 이라고 하며, 말한 사람의 말을 전달하는.>")

 : 다수의 대상들 ( 소비자, 제품, 기타 ) 을 그들이 소유하는 특 성을 토대로 유사한 대상들끼리 그룹핑하는 다변량 통계기법 → 군집내의 구성원들은 가급 적.>")


 less 원급 than>")









>")