Download presentation
Presentation is loading. Please wait.

1
[ 예제 ] 시장수익률의 확률분포 확률변수의 분포
![[ 예제 ] 시장수익률의 확률분포 확률변수의 분포](http://images.slidesplayer.org/40/11124379/slides/slide_1.jpg "[ 예제 ] 시장수익률의 확률분포 확률변수의 분포")
2
목적 내년 시장수익률의 확률분포에 대한 평균, 분산, 표준편차 계산

3
배경설명 투자자 A 씨는 내년의 시장수익률을 분석하려고 한다. 시장수익률 (market return) 은 투자한 자금으로부터 얻은 연간이득 ( 또는 손실 ) 의 백분율을 의미한다. A 씨는 내년의 국가경제가 다음과 같은 다섯 가지 시나리오 중 하나가 될 것으로 믿고 있다. 1) rapid expansion, 2) moderate expansion, 3) no growth, 4) moderate contraction, 5) serious contraction A 씨는 각 시나리오에서의 시장수익률을 0.23, 0.18, 0.15, 0.09, 0.03 으로 추정하였다.
 은 투자한 자금으로부터 얻은 연간이득 ( 또는 손실 ) 의 백분율을 의미한다. A 씨는 내년의 국가경제가 다음과 같은 다섯 가지 시나리오 중 하나가 될 것으로 믿고 있다. 1) rapid expansion, 2) moderate expansion, 3) no growth, 4) moderate contraction, 5) serious contraction A 씨는 각 시나리오에서의 시장수익률을 0.23, 0.18, 0.15, 0.09, 0.03 으로 추정하였다..")
4
배경설명 -- 계속 A 씨는 내년의 국가경제에 대한 시나리오의 발생확률을 각각 0.12, 0.40, 0.25, 0.15, 0.08 으로 평가하였다. 이러한 정보로부터 A 씨는 시장수익률 확률분포의 기대값, 분산, 표준편차 등을 계산하고자 한다.

5
확률변수의 유형 이산확률변수 (discrete random variable) 는 유한개의 결과값을 갖는다. 연속확률변수 (continuous random variable) 는 결과값이 연속체로 되어있다. 수학적으로 이산확률변수와 연속확률변수는 매우 큰 차이가 있다. 연속확률변수를 정확히 설명하려면 미분적분학이 필요하다. 여기서는 이산확률변수를 중심으로 설명한다.
 는 결과값이 연속체로 되어있다. 수학적으로 이산확률변수와 연속확률변수는 매우 큰 차이가 있다. 연속확률변수를 정확히 설명하려면 미분적분학이 필요하다. 여기서는 이산확률변수를 중심으로 설명한다..")
6
이산확률변수 확률변수 X 의 확률분포 (probability distribution) 는 X 가 취할 수 있는 값 x i 과 그 발생확률 P(X=x i ) 을 나열해 놓은 것을 의미한다. 발생확률은 항상 0 과 1 사이의 값이어야 한다. 즉 0 ≤ P(X=x i ) ≤ 1 발생확률의 합은 1 이 되어야 한다. 즉 Σ i P(X=x i ) = 1
 ≤ 1 발생확률의 합은 1 이 되어야 한다. 즉 Σ i P(X=x i ) = 1.")
7
확률분포의 요약 확률분포 (probability distribution) 는 둘 또는 세 개의 숫자로 요약될 수 있다. – 기대값 (expected value) 으로 부르기도 하는 평균 (mean) 은 확률을 가중치로 사용하여 계산한 가중합계이다. –E(X) = Σ i x i P(X=x i ) – 분포의 변동성 (variability) 은 분산 (variance) 또는 표준편차 (standard deviation) 로 측정한다. 분산은 평균으로부터 편차를 제곱하고 이 값에 확률을 가중치로 사용하여 계산한 가중합계이다. 표준편차는 분산의 제곱근이다. 분산은 확률변수의 단위의 제곱으로 표현되므로 표준편차가 더 자연스러운 변동성의 측정수단이다. –Var(X) = Σ i (x i – E(X)) 2 P(X=x i ) –Std(X) = (Var(X)) 1/2
 으로 부르기도 하는 평균 (mean) 은 확률을 가중치로 사용하여 계산한 가중합계이다. –E(X) = Σ i x i P(X=x i ) – 분포의 변동성 (variability) 은 분산 (variance) 또는 표준편차 (standard deviation) 로 측정한다. 분산은 평균으로부터 편차를 제곱하고 이 값에 확률을 가중치로 사용하여 계산한 가중합계이다. 표준편차는 분산의 제곱근이다. 분산은 확률변수의 단위의 제곱으로 표현되므로 표준편차가 더 자연스러운 변동성의 측정수단이다. –Var(X) = Σ i (x i – E(X)) 2 P(X=x i ) –Std(X) = (Var(X)) 1/2.")
8
MarketReturn.xls 이 파일에는 투자자가 추정한 시장수익률과 확률이 포함되어있다. Mean, Probs, Returns, Var, Sqdevs 등은 범위이름으로 설정된 것이다.

9
확률분포의 요약지표 계산 확률분포의 요약지표 계산 –Mean return: =SUMPRODUCT(Returns,Probs) –Squared Deviations: =(C4-Mean)^2 –Variance: =SUMPRODUCT(SqDevs,Probs) –Standard Deviation: =SQRT(Var) 평균 (mean) 은 15.3%, 표준편차 (standard deviation) 는 5.3% 이다. 이 값이 의미하는 바는 ?

10
요약지표에 대한 분석 First, the mean or expected return does not imply that the most likely return is 15.3%, nor is this the value that the investor “expects” to occur. The value 15.3% is not even a possible market return. We can understand these measures better in terms of long-run averages. If we can see the coming year repeated many times, using the same probability distribution, then the average of these times would be close to 15.3% and their standard deviation would be 5.3%.

11
[ 예제 ] GM 주식과 금에 대한 투자 포트폴리오 분석 두 확률변수의 분포
![[ 예제 ] GM 주식과 금에 대한 투자 포트폴리오 분석 두 확률변수의 분포](http://images.slidesplayer.org/40/11124379/slides/slide_11.jpg "[ 예제 ] GM 주식과 금에 대한 투자 포트폴리오 분석 두 확률변수의 분포")
12
목적 결합확률분포 (joint distribution) 를 구하고 이를 이용해 주어진 두 가지 투자안 수익률의 공분산 (covariance) 과 상관계수 (correlation) 를 계산함
 를 구하고 이를 이용해 주어진 두 가지 투자안 수익률의 공분산 (covariance) 과 상관계수 (correlation) 를 계산함")
13
배경설명 투자자 A 씨는 GM 주식 (General Motors stock) 과 금에 투자할 것을 계획하고 있다. 이러한 투자안의 수익은 내년의 전반적인 경제상태에 따라 달라질 것이다. A 씨는 경제상태를 depression, recession, normal, boom 등의 4 가지로 구분하고 각 상태의 확률을 0.05, 0.30, 0.50, 0.15 으로 보고 있다.

14
배경설명 -- 계속 A 씨는 두 가지 투자안 수익률의 결합분포를 분석하고자 한다. 또한 A 씨는 GM 주식과 금에 대한 투자 포트폴리오의 분포를 분석하고자 한다.

15
GMGold.xls 이 파일에는 GM 주식과 금의 추정수익률과 확률이 수록되어 있다.

16
두 가지 확률변수의 관계 두 가지 확률변수는 결합확률접근법 (joint probability approach) 또는 시나리오접근법 (scenario approach) 으로 관계는 나타낼 수 있다. 이들 두 방법은 확률을 각 결과치 (outcome) 에 부여하는 방법이 다르다. 두 가지 변수의 관련성은 공분산 (covariance) 또는 상관관계 (correlation) 로 측정할 수 있다.
 에 부여하는 방법이 다르다. 두 가지 변수의 관련성은 공분산 (covariance) 또는 상관관계 (correlation) 로 측정할 수 있다..")
17
관련성 요약지표 확률변수 X 의 결과값이 x i 가 되고 확률변수 Y 의 결과값이 y i 가 될 확률 p(x i, y i ) 을 결합확률 (joint probability) 이라고 한다. 공분산 (covariance) Cov(X,Y) = Σ i (x i – E(X)) (y i – E(Y)) p(x i, y i ) 상관관계 (correlation) Corr(X,Y) = Cov(X,Y) / [ Std(X) Std(Y) ]
 Cov(X,Y) = Σ i (x i – E(X)) (y i – E(Y)) p(x i, y i ) 상관관계 (correlation) Corr(X,Y) = Cov(X,Y) / [ Std(X) Std(Y) ].")
18
관련성 요약지표 -- 계속 공분산과 상관관계 모두 X 와 Y 간의 선형관계 (linear relationship) 의 강도를 나타낸다. X 와 Y 가 같은 방향으로 변하면 공분산과 상관관계는 양의 값을 갖고 반대방향으로 변하면 음의 값을 갖는다. 공분산은 X 와 Y 의 측정단위 (measurement units) 에 따라 값이 달라지기 때문에 해석하기 어렵다. 그러나 상관관계는 항상 -1 과 +1 사이의 값을 갖는다.
 에 따라 값이 달라지기 때문에 해석하기 어렵다. 그러나 상관관계는 항상 -1 과 +1 사이의 값을 갖는다..")
19
시나리오접근법 주어진 경제상태가 GM 주식 및 금의 수익률을 결정하므로 4 가지 결과값 (outcome) 이 가능하다. 가능한 결과값은 -0.20 과 0.05, 0.10 과 0.20, 0.30 과 -0.12, 0.50 과 0.09 이다. 각 결과값은 결합확률을 갖는다. GM 주식과 금 수익률의 평균, 분산, 표준편차를 각각 계산한다.

20
공분산과 상관관계 계산 공분산과 상관관계를 다음과 같이 계산한다. 1 평균편차 (Deviations from means): 공분산을 계산하기 위해서는 평균편차를 계산해야 한다. 평균편차를 계산하기 위해 B14 에 =C4-GMMean 을 입력하고 이를 B17 까지 복사한다. 같은 방식으로 금 수익률의 평균편차를 계산한다. 2 공분산 (Covariance): GM 주식 수익률과 금 수익률간의 공분산을 계산하기 위해 B23 에 수식 =SUMPRODUCT(GMDevs,GoldDevs,Probs) 을 입력한다.
: 공분산을 계산하기 위해서는 평균편차를 계산해야 한다. 평균편차를 계산하기 위해 B14 에 =C4-GMMean 을 입력하고 이를 B17 까지 복사한다. 같은 방식으로 금 수익률의 평균편차를 계산한다. 2 공분산 (Covariance): GM 주식 수익률과 금 수익률간의 공분산을 계산하기 위해 B23 에 수식 =SUMPRODUCT(GMDevs,GoldDevs,Probs) 을 입력한다..")
21
공분산과 상관관계 계산 -- 계속 3 상관관계 (Correlation): GM 주식 수익률과 금 수익률간의 상관관계를 계산하기 위해 B24 에 수식 =Covar/(GMStdev*GoldStedev) 를 입력한다. 공분산이 음수인 것은 GM 주식 수익률과 금 수익률이 반대방향으로 움직이는 경향을 가지고 있음을 나타낸다. 그러나 공분산으로 움직이는 경향의 정도를 판단하기는 어렵다. 상관관계가 -0.410 인 것은 반대방으로 움직이며 보통수준의 관련성이 있음을 나타낸다. 그런데 GM 주식 수익률과 금 수익률의 관계가 선형관계가 아니기 때문에 상관관계를 분석에 사용하기는 어렵다.

22
시뮬레이션 (Simulation) GM 주식 수익률과 금 수익률에 대한 시뮬레이션으로 이들의 공분산과 상관관계를 설명할 수 있다. GM- 금 수익률 시뮬레이션에서는 다음의 두 가지 사항이 핵심이다. 첫째, GM 주식과 금 수익률 자체를 시뮬레이트하는 것이 아니라 경제상황을 시뮬레이트해야 한다. –A21 에 RAND 함수를 입력하고 B21 에 VLOOKUP(A21,LTable,2), C21 에 VLOOKUP(A21,LTable,3) 를 입력한다. – 이 방식은 같은 난수를 사용해서 수익률을 생성하는데 같은 시나리오를 사용하게 된다.
, C21 에 VLOOKUP(A21,LTable,3) 를 입력한다. – 이 방식은 같은 난수를 사용해서 수익률을 생성하는데 같은 시나리오를 사용하게 된다..")
23
시뮬레이션 -- 계속 둘째, 수익률이 모의로 만들어졌으면 이 수익률로 공분산과 상관관계를 계산할 수 있다. –B8 에 COVAR(SimGM,SimGOLD) 를 입력하고 B9 에 CORREL(SimGM,SimGold) 를 입력하여 공분산과 상관관계를 계산한다. COVAR 과 CORREL 은 built-in 함수이다. – 확률분포에서 계산한 관련성 요약지표와 시뮬레이션결과에서 계산한 관련성 요약지표가 매우 유사한 값을 나타내고 있다. 두 지표값이 완벽하게 일치하지는 않고 있지만 모의로 만들어지는 수익률의 수가 많아질 수록 점점 더 일치하게 된다.
 를 입력하고 B9 에 CORREL(SimGM,SimGold) 를 입력하여 공분산과 상관관계를 계산한다. COVAR 과 CORREL 은 built-in 함수이다. – 확률분포에서 계산한 관련성 요약지표와 시뮬레이션결과에서 계산한 관련성 요약지표가 매우 유사한 값을 나타내고 있다. 두 지표값이 완벽하게 일치하지는 않고 있지만 모의로 만들어지는 수익률의 수가 많아질 수록 점점 더 일치하게 된다..")
24
GM 과 Gold 수익률 시뮬레이션

25
포트폴리오 분석 투자자 A 씨가 $10,000 중 일부는 GM 주식에 투자하고 나머지는 금에 투자하고 한다. 경제상태에 대한 시나리오가 4 개이므로 포트폴리오 수익률의 결과치도 4 개가 된다. 포트폴리오수익률 (portfolio returns) 은 일반적인 방법으로 계산하였다. 포트폴리오수익률 = Σ i 투자비율 i 수익률 i
 은 일반적인 방법으로 계산하였다. 포트폴리오수익률 = Σ i 투자비율 i 수익률 i.")
26
포트폴리오 분석 -- 계속 투자자가 GM 주식에 더 많이 투자할 수록 포트롤리오의 기대수익률과 포트폴리오 수익률의 표준편차가 어떻게 변화하는가를 보자. – 이를 위해 포트폴리오수익률의 평균 및 표준편차를 GM 주식에 대한 투자비율의 함수로 나타내었다 (B24 와 C24 에 각각 =C18 과 =C20 을 입력하고 A24:C35 를 범위로 선택한 후 ‘ 데이터 ’ 메뉴의 ‘ 표 ’ 부메뉴를 선택한다. 그리고 ‘ 열 입력 셀 ’ 에 B6 을 입력하고 엔터를 누른다 ). 포트폴리오수익률의 평균 및 표준편차의 그래프를 살펴보면 GM 주식에 대한 투자비율이 높아질 수록 일정하게 기대수익률이 높아지는 것을 알 수 있다.
. 포트폴리오수익률의 평균 및 표준편차의 그래프를 살펴보면 GM 주식에 대한 투자비율이 높아질 수록 일정하게 기대수익률이 높아지는 것을 알 수 있다..")
27
포트폴리오 분석 -- 계속 그러나 위험수준의 지표로 사용되는 표준편차는 감소하다가 일정 부분 이후에서 증가하고 있다. 이는 포트폴리오의 기대수익률과 ( 표준편차로 측정된 ) 위험간에 교환관계 (trade-off) 가 있음을 의미한다. 투자자 A 씨가 GM 주식에 대한 투자비율을 높일 수록 기대수익률이 높아지지만 0.4 를 지나면서 위험도 함께 증가한다.
 위험간에 교환관계 (trade-off) 가 있음을 의미한다. 투자자 A 씨가 GM 주식에 대한 투자비율을 높일 수록 기대수익률이 높아지지만 0.4 를 지나면서 위험도 함께 증가한다..")
28
Distribution of Portfolio Return

29
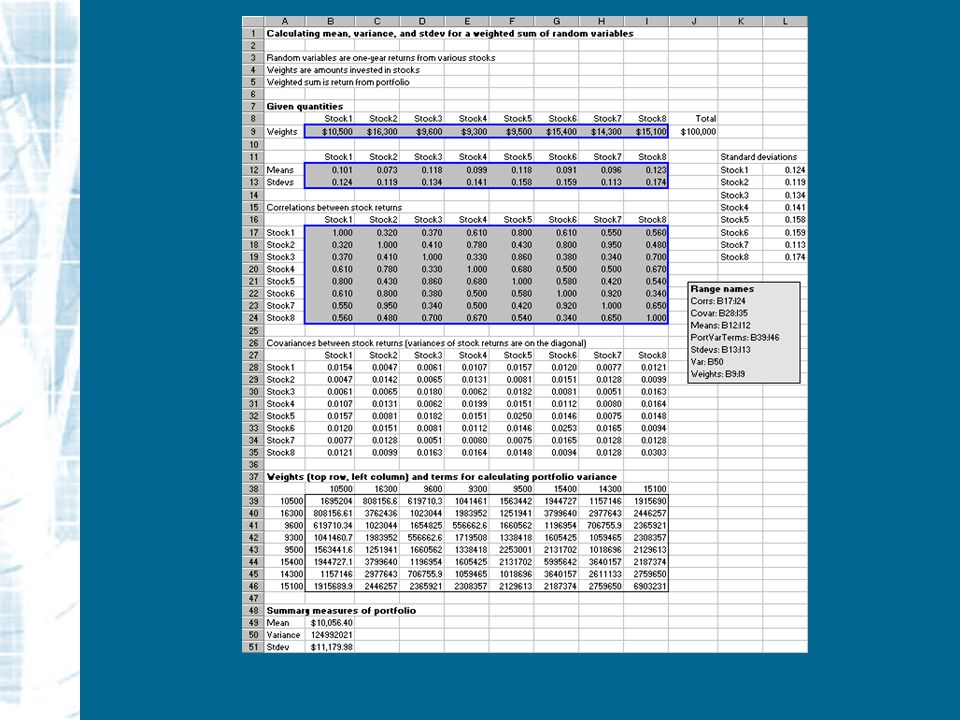
[ 예제 ] Describing Investment Portfolio Returns 확률변수의 선형함수 ( 가중합계 )
![[ 예제 ] Describing Investment Portfolio Returns 확률변수의 선형함수 ( 가중합계 )](http://images.slidesplayer.org/40/11124379/slides/slide_29.jpg "[ 예제 ] Describing Investment Portfolio Returns 확률변수의 선형함수 ( 가중합계 )")
30
목적 포트폴리오의 연평균수익률과 위험을 결정할 수 있다.

31
Invest.xls 투자자 B 씨는 투자자금으로 $100,000 를 가지고 있으며 8 개 주식에 분산투자를 하고자 한다. B 씨는 이들 주식의 과거 수익률자료를 수집하여 평균, 표준편차, 상관관계 등을 추정하였다. Invest.xls 에는 이들 8 개 주식의 과거자료로부터 추정한 평균, 표준편차, 상관관계 자료들이 수록되어 있다. B 씨는 이들 요약지표가 미래의 수익률에 관한 정보로서 역할을 할 것으로 믿고 있다.

32
Invest.xls Invest.xls -- 계속 B 씨는 이들 8 개 주식으로 구성된 포트폴리오를 분석하고자 한다. 포트폴리오의 연평균수익률은 얼마인가 ? 그리고 분산 및 표준편차는 어느정도인가 ?

33
입력자료

34
가중합계의 기대값과 분산 가중합계 Y = a 1 X 1 + a 2 X 2 + … + a n X n 가중합계의 기대값 E(Y) = a 1 E(X 1 ) + a 2 E(X 2 ) + … + a n E(X n ) 상호독립적인 확률변수의 가중합계의 분산 Var(Y) = a 1 2 Var(X 1 ) + a 2 2 Var(X 2 ) + … + a n 2 Var(X n ) 가중합계의 분산 Var(Y) = a 1 2 Var(X 1 ) + a 2 2 Var(X 2 ) + … + a n 2 Var(X n ) + 2a 1 a 2 Cov(X 1,X 2 ) + 2a 1 a 3 Cov(X 1,X 3 ) + … + 2a n-1 a n Cov(X n-1,X n )
 = a 1 E(X 1 ) + a 2 E(X 2 ) + … + a n E(X n ) 상호독립적인 확률변수의 가중합계의 분산 Var(Y) = a 1 2 Var(X 1 ) + a 2 2 Var(X 2 ) + … + a n 2 Var(X n ) 가중합계의 분산 Var(Y) = a 1 2 Var(X 1 ) + a 2 2 Var(X 2 ) + … + a n 2 Var(X n ) + 2a 1 a 2 Cov(X 1,X 2 ) + 2a 1 a 3 Cov(X 1,X 3 ) + … + 2a n-1 a n Cov(X n-1,X n )")
35
Solution 확률변수 X 는 주식의 연간수익률이고, 가중치 a 는 주식에 투자된 금액 ($) 이다. X 에 대한 요약지표 ( 평균, 표준편차, 상관관계 ) 는 rows 12,13, 17-24 에 수록되어 있다. 포트폴리오 Y = a 1 X 1 + a 2 X 2 + … + a 8 X 8 포트폴리오의 평균수익률은 B49 에 =SUMPRODUCT(Weights, Means) 를 입력하여 구할 수 있다.
 는 rows 12,13, 에 수록되어 있다. 포트폴리오 Y = a 1 X 1 + a 2 X 2 + … + a 8 X 8 포트폴리오의 평균수익률은 B49 에 =SUMPRODUCT(Weights, Means) 를 입력하여 구할 수 있다..")
36
Solution -- 계속 포트폴리오수익률 (Y) 의 분산을 계산하기 위해서는 준비가 필요하다. 분산, 표준편차, 상관관계, 공분산 등은 다음의 관계를 갖는다. Var(X i ) = (Stdev(X i )) 2 Cov(X i, X j ) = StDev(X i ) X Stdev(X j ) X Corr(X i,X j )
 = (Stdev(X i )) 2 Cov(X i, X j ) = StDev(X i ) X Stdev(X j ) X Corr(X i,X j ).")
37
Solution -- 계속 공분산을 Excel 에서 계산할 때 TRANSPOSE 함수를 사용해서 L 열에 표준편차를 나타내어 두면 편리하다. 이렇게 하려면 먼저 L12:L19 범위를 선택하고 선택된 범위에 =TRANSPOSE(Stdevs) 를 입력한 후 Ctrl-Shift- Enter 를 누른다. 이제 B28:I35 범위에 X’s 의 분산 및 공분산 테이블을 만든다 (B28 에 =$L12*B$13*B17 를 입력하고 이를 범위의 나머지 셀에 복사한다 ).
 를 입력한 후 Ctrl-Shift- Enter 를 누른다. 이제 B28:I35 범위에 X’s 의 분산 및 공분산 테이블을 만든다 (B28 에 =$L12*B$13*B17 를 입력하고 이를 범위의 나머지 셀에 복사한다 )..")
38
Solution -- 계속 마지막으로 포트폴리오의 분산을 B50 에 계산한다. B50 에 분산을 계산하기 위해 먼저 필요한 가중 분산 - 공분산 테이블을 다음과 같은 방법으로 만든다. – 가중치행 (Row of weights) 범위 B38:I18 을 선택한 후 =Weights 을 입력하고 Ctrl-Enter 를 누름 – 가중치열 (Column of weights) A39:A46 를 선택한 후 =TRANSPOSE(Weights) 를 입력하고 Ctrl-Shift-Enter 를 누름
 범위 B38:I18 을 선택한 후 =Weights 을 입력하고 Ctrl-Enter 를 누름 – 가중치열 (Column of weights) A39:A46 를 선택한 후 =TRANSPOSE(Weights) 를 입력하고 Ctrl-Shift-Enter 를 누름.")
39
Solution -- continued – 가중 분산 - 공분산 테이블 (Table of Weighted Variance- Covariance) 포트폴리오의 분산을 구성하는 가중 분산 - 공분산 테이블을 만든다 (B39 에 =$A39*B28*B$38 을 입력하고 이 수식을 B39:I46 에 복사한다 ). – 포트롤리오 분산 및 표준편차 (Portfolio variance and standard deviation) B50 에 =SUM(PortVarTerms) 를 입력하여 포트폴리오 분산을 계산한다. 포트폴리오 수익률의 표준편차는 B51 에 분산의 제곱근으로 계산한다. 계산결과는 다음 slide 에 나타낸 것과 같다.
 B50 에 =SUM(PortVarTerms) 를 입력하여 포트폴리오 분산을 계산한다. 포트폴리오 수익률의 표준편차는 B51 에 분산의 제곱근으로 계산한다. 계산결과는 다음 slide 에 나타낸 것과 같다..")
41
Solution -- 계속 약 $11,200 의 표준편차는 비교적 큰 값이다. 표준편차는 포트폴리오의 위험을 나타내는 지표이다. 투자자는 항상 높은 기대수익률을 기대하면서 동시에 낮은 위험을 원한다. 그러나 높은 수익을 얻으려면 항상 더 많은 위험을 감수해야 한다.

42
[ 예제 ] Battery Life Experiment The Binomial Distribution
![[ 예제 ] Battery Life Experiment The Binomial Distribution](http://images.slidesplayer.org/40/11124379/slides/slide_42.jpg "[ 예제 ] Battery Life Experiment The Binomial Distribution")
43
목적 Excel 함수 BINOMDIST 와 CRITBINOM 을 사용해서 이항분포의 확률과 백분위수를 계산하는 방법에 대해서 살펴봄

44
문제 100 개의 전등에 100 개의 배터리가 들어있다. 배터리는 연속적으로 8 시간을 사용한 후에도 작동할 확률이 0.6 이고 작동을 멈출 확률이 0.4 인 것으로 가정한다. 100 개의 전등 중에서 8 시간 후에도 사용할 수 있는 전등 ( 성공 ) 의 수를 X 라고 하자.
 의 수를 X 라고 하자..")
45
문제 -- 계속 다음과 같은 각 사건의 확률을 구하고자 한다. – 정확하게 58 개가 성공 –65 개 이하가 성공 –70 개 미만이 성공 – 적어도 59 개 성공 –65 개 초과해서 성공 –55~65 개 성공 (inclusive) – 정확하게 40 개 실패 – 적어도 35 개 실패 –42 개 미만 실패 X 의 분포에서 95 번째 백분위수를 찾으시오.
 – 정확하게 40 개 실패 – 적어도 35 개 실패 –42 개 미만 실패 X 의 분포에서 95 번째 백분위수를 찾으시오..")
46
이항분포 이항분포 (binomial distribution) 는 다음과 같은 두 가지 상황에서 나타날 수 있는 이산확률분포이다 : – 모집단으로부터 두 가지의 결과 ( 예를 들면, 남자와 여자 ) 로 표본을 추출할 때 – 두 가지 결과만을 갖는 동일한 실험을 반복하여 수행할 때 시행 (trial) 은 실험을 반복할 때의 각 실험을 의미한다.
 는 다음과 같은 두 가지 상황에서 나타날 수 있는 이산확률분포이다 : – 모집단으로부터 두 가지의 결과 ( 예를 들면, 남자와 여자 ) 로 표본을 추출할 때 – 두 가지 결과만을 갖는 동일한 실험을 반복하여 수행할 때 시행 (trial) 은 실험을 반복할 때의 각 실험을 의미한다.")
47
Excel 에서 이항분포의 확률 Excel 에서 이항분포 확률의 계산은 =BINOMDIST(k,n,p,cum) 으로 할 수 있다. The arguments are: –n is the number of trials –p is the probability of success –k is the integer number of successes that we specify –cum is either 0 or 1. It is one if we want the probability of less than or equal to k successes and it is 0 if we want the probability of exactly k successes.

48
BinomFns.xls This file contains the solutions to all of the problems:

49
Solutions The key to solving the probabilities is in the wording of the phrases such as “no more than”, “greater than” and so on. In particular we have to pay close attention to the possibility in some that X = k.

50
Solutions -- continued We can translate the first six probabilities requested to the following: –P(X = 58) –P(X < = 65) –P(X < 70) = P(X < = 69) –P(X 59) = 1 - P(X < 59) = 1 - P(X < = 58) –P(X > 65) = 1 - P(X < = 65) –P(55 < = X < = 65) = P(X < = 65) - P(X < 55) = P(X < = 65) - P(X < = 54) Note that we have converted these so that they include only terms of the form P(X = k) and P(X < = k).
 –P(X < = 65) –P(X < 70) = P(X < = 69) –P(X 59) = 1 - P(X < 59) = 1 - P(X < = 58) –P(X > 65) = 1 - P(X < = 65) –P(55 < = X < = 65) = P(X < = 65) - P(X < 55) = P(X < = 65) - P(X < = 54) Note that we have converted these so that they include only terms of the form P(X = k) and P(X < = k).")
51
Solutions --continued The last three probabilities involve failures instead of successes. Since each trial results in either a success or failure, the number of failures is also binomial distributed with parameters n and 1 - p = 0.4. Therefore, we substitute 1-P for P in the BINOMDIST function.

52
Solutions -- continued Finally, we calculate the 95th percentile of the distribution of X by using the entering the requested probability, 0.95, in cell B27 and the formula: =CRITBINOM(Ntrials,Psucc,B27) in cell A27.
 in cell A27.")
53
Binomial Distributions and Sampling Another aspect of binomial distributions to consider is how this distribution applies to sampling from a population with two type of members. If sampling is done without replacement, then each member of the population can be sampled only once. If sampling is done with replacement then it is possible, although may or may not be likely, to select a given member of the population any number of times.

54
Binomial Distributions and Sampling -- continued Most real world sampling is done without replacement. There is no point in obtaining information from the same person another time. The binomial distribution, however, only applies when sampling is done with replacement. It is only an approximation if sampling is done without replacement. It turns out that the appropriate distribution for sampling without replacement is the hypergeometric distribution, a distribution we will not discuss here.

55
Binomial Distributions and Sampling -- continued However, if n is small relative to N, then the binomial distribution is a very good approximation to the hypergeometric model, so it works well when sampling is without replacement. A rule of thumb is that if n is no greater than 10% of N, that is, no more than 10% of the population is sampled, then the binomial model can be used safely. The bottom line is that in most real-world sampling contexts, the binomial model is perfectly adequate.

Similar presentations
>")
 통계량 (statistic) 표본자료의 함수 즉 모집단 … … 표본 표본추출 … … 통계량 계산.>")








>")
>")
. 고장률은 확률이 아니며 따라서 1 보다 커도 상관없다. 고장이 발생하기 쉬운 정도를 표시하는 척도. 일반으로 고장률은 순간고장률과 평균고장률을 사용하고 있지만.>")
 에서 같은 첨자가 있는 곳은 비워두고, 그 밖에 cell에 수준수 (level) 또는 반복수를 기입>")





>")