Download presentation
Presentation is loading. Please wait.

1
1장 기본 개념

2
자료와 정보 컴퓨터 주기억장치 I = P(D) 자료 정보 자료, 프로그램 보조 기억장치 자료구조 → 자료저장, 이용
알고리즘 → 프로그램 보조 기억장치 I = P(D)
")
3
자료구조의 영역

4
자료구조 기본개념 선형구조 배열(연속 리스트(continuous list) 스택(stack), 큐(queue)
연결 리스트(linked list) 비선형구조 트리(tree), 그래프(graph) 자료구조 응용 탐색, 정렬
 비선형구조. 트리(tree), 그래프(graph) 자료구조 응용. 탐색, 정렬.")
5
선형구조 배열 : 스택 : 큐 : 연결리스트:

6
비선형 구조 트리 그래프 1 : N N : M 14

7
알고리즘과 프로그램 알고리즘(algorithm) 특정 문제를 해결하기 위해 기술한 일련의 논리의 순서 프로그램(program)
알고리즘을 컴퓨터가 이해하고 실행할 수 있는 특정 프로그래밍 언어로 표현한 것 program = algorithm + data structure

8
알고리즘의 특징 입력 : 외부 제공 자료가 있을 수 있음 출력 : 한가지 이상의 결과 생성 명확성 : 각 명령은 명확
유한성 : 한정된 단계 실행 후 종료 유효성 : 컴퓨터 처리 가능 18

9
알고리즘 기술 방법 알고리즘 기술언어 사용 자연어에 의한 표현 한글 또는 영문 슈도코드(PSEUDO CODE)
도형에 의한 표현 흐름도(FLOW CHART) 박스(BOX) 다이어그램 19
 박스(BOX) 다이어그램. 19.")
10
자료의 종류와 표현(1) 정수형 자료 실수형 자료 4byte (short : 2byte, int와 long : 4byte)
10진수 35표현 실수형 자료 4byte (float : 4byte, double과 long double : 8byte) 10진수 표현 1 31 000 0000 0010 0011 부호부 정수부 1 7 8 31 100 0010 1101 1100 0000 가수부 지수부 부호부
 10진수 표현 부호부. 정수부 가수부. 지수부. 부호부.")
11
자료의 종류와 표현(2) 문자형 자료 논리형 자료 포인터형 자료 저장장소의 주소를 표현하기 위한 자료형
영문자 : 1byte, 한글문자 : 2byte A는 ASCII 코드인 ‘ ’이 저장 논리형 자료 참(true, 1) 또는 거짓(false, 0) &&(AND), ||(OR), !(NOT) 포인터형 자료 저장장소의 주소를 표현하기 위한 자료형 int i, *pi : i는 정수 변수, pi는 정수에 대한 포인터 변수 pi = &i : &i는 i의 주소 값을 pi의 값으로 지정 *pi = 10 : 포인터 pi가 가리키는 장소에 10을 저장
 또는 거짓(false, 0) &&(AND), ||(OR), !(NOT) 포인터형 자료. 저장장소의 주소를 표현하기 위한 자료형. int i, *pi : i는 정수 변수, pi는 정수에 대한 포인터 변수. pi = &i : &i는 i의 주소 값을 pi의 값으로 지정. *pi = 10 : 포인터 pi가 가리키는 장소에 10을 저장.")
12
자료와 자료형 자료 현실 세계의 관찰이나 측정을 통해 수집된 값이나 사실 프로그램의 처리 대상이 되는 모든 것 자료형 자료의 집합과 이 자료에 적용할 수 있는 연산의 집합 예) integer 자료형 - 자료:정수(…-2,-1,0,1,2…), 연산자: +, -, *, /, mod 추상 자료형(ADT)은 객체의 명세와 그 연산의 명세가 그 객체의 표현과 연산의 구현으로부터 분리된 자료형
 integer 자료형. - 자료:정수(…-2,-1,0,1,2…), 연산자: +, -, *, /, mod. 추상 자료형(ADT)은 객체의 명세와 그 연산의 명세가 그 객체의 표현과 연산의 구현으로부터 분리된 자료형.")
13
추상 자료형 추상화(abstraction) 추상 자료형(abstraction data type : ADT)
자세한 것은 무시하고, 필수적이고 중요한 속성만으로 단순화시키는 과정 추상 자료형(abstraction data type : ADT) 자료형의 논리적 정의 자료와 연산의 본질에 대한 명세만 정의한 자료형 자료가 무엇이고, 각 연산의 기능을 정의 추상화와 구체화의 관계 자료 연산 추상 자료형 알고리즘 자료형 프로그램 추상화 구체화
 자료형의 논리적 정의. 자료와 연산의 본질에 대한 명세만 정의한 자료형. 자료가 무엇이고, 각 연산의 기능을 정의. 추상화와 구체화의 관계. 자료. 연산. 추상 자료형. 알고리즘. 자료형. 프로그램. 추상화. 구체화.")
14
자연수의 추상자료형 ADT Natno object : { i | i integer, i ≥ 0}
function : for all x, y Natno zero() ::= return 0; isZero(x) ::= if (x=0) then return true else return false; succ(x) ::= return x + 1; add(x, y) ::= return x + y; subtract(x, y) ::= if x < y then return 0 else return x - y; equal(x, y) ::= if x = y then return true End Natno 19
 ::= return 0; isZero(x) ::= if (x=0) then return true. else return false; succ(x) ::= return x + 1; add(x, y) ::= return x + y; subtract(x, y) ::= if x < y then return 0. else return x - y; equal(x, y) ::= if x = y then return true. End Natno. 19.")
15
순환(recursion) 순환의 종류 순환 방식의 적용 직접순환 : A A’ 간접순환 : A B A
분할 정복(divide and conquer)의 특성을 가진 문제에 적합 어떤 복잡한 문제를 직접 간단하게 풀 수 있는 작은 문제로 분할하여 해결하려는 방법
의 특성을 가진 문제에 적합. 어떤 복잡한 문제를 직접 간단하게 풀 수 있는 작은 문제로 분할하여 해결하려는 방법.")
16
순환 알고리즘과 비순환 알고리즘 n!의 계승(factorial) 함수를 정의 순환 정의
 함수를 정의 순환 정의")
17
Factorial 순환 함수(1) 순환 알고리즘 Factorial(n) // n은 음이 아닌 정수
if (n <= 1) then return 1 else return (n·factorial(n-1)); end Factorial() Factorial(4) = (4·Factorial(3)) = (4·(3·Factorial(2))) = (4·(3·(2·Factorial(1)))) = (4·(3·(2·1))) = (4·(3·2)) = (4·6) = 24
 then return 1. else return (n·factorial(n-1)); end Factorial() Factorial(4) = (4·Factorial(3)) = (4·(3·Factorial(2))) = (4·(3·(2·Factorial(1)))) = (4·(3·(2·1))) = (4·(3·2)) = (4·6) = 24.")
18
Factorial 순환 함수(2) 비순환 함수 표현 n-Factorial(n)
if (n <= 1) then return 1; fact 1; for( i 2; i<= n; i i+1) do{ fact fact*i; } return fact; end n-Factorial()
 then return 1; fact 1; for( i 2; i<= n; i i+1) do{ fact fact*i; } return fact; end n-Factorial()")
19
성능 분석과 성능 측정 성능 분석(performance analysis) 프로그램을 실행하는데 필요한 시간과 공간 추정
성능 측정(performance measurement) 컴퓨터가 실제로 프로그램을 실행하는데 걸리는 시간 측정
 컴퓨터가 실제로 프로그램을 실행하는데 걸리는 시간 측정.")
20
성능분석 공간복잡도 Sp = Sc + Se 고정공간 + 가변공간 시간복잡도 Tp = Tc + Te 컴파일시간 + 실행시간 19

21
연산시간 표기법 연산시간 표기법 Big-Oh (O) Big-Oh (O), Big-Omega (Ω), Big-Theta (θ)
f, g가 양의 정수를 갖는 함수일 때, 두 양의 상수 a, b가 존재하고, 모든 n ≥ b에 대해 f(n) ≤ a • g(n)이면, f(n) = O(g(n)) f(n) = 3n : f(n) = O(n) (a=4, b=2) f(n) = 1000n2 +100n – 6 : f(n) = O(n2) (a=1001, b=100) f(n) = 6 • 2n + n2 : f(n) = O(2n) (a=7, b=4) f(n) = : f(n) = O(1) (a=100, b=1) 19
 ≤ a • g(n)이면, f(n) = O(g(n)) f(n) = 3n + 2 : f(n) = O(n) (a=4, b=2) f(n) = 1000n2 +100n – 6 : f(n) = O(n2) (a=1001, b=100) f(n) = 6 • 2n + n2 : f(n) = O(2n) (a=7, b=4) f(n) = 100 : f(n) = O(1) (a=100, b=1) 19.")
22
연산시간 표현

23
연산시간함수의 변화 2n n3 n2 n nlog2n log2n 1 2 4 8 16 32 64 128 65536 32768
16384 8192 4096 2048 1024 512 256 log2n 2n n2 19

24
2장 배열과 레코드

25
배열(array) 원소들은 모두 같은 형(type), 같은 크기
자료를 컴퓨터 기억장치 내의 연속적인 기억장소에 저장하여 순차적으로 또는 임의적으로 접근할 수 있는 가장 간단한 선형 자료구조 <인덱스, 원소> 쌍의 집합 원소들은 모두 같은 형(type), 같은 크기 접근 방법은 직접 접근 배열 이름이 a라면, a[인덱스]=원소 값 1 2 3 4 5 6 7 8 9 원소값 10 30 … 인덱스
, 같은 크기. 접근 방법은 직접 접근. 배열 이름이 a라면, a[인덱스]=원소 값 원소값 … 인덱스.")
26
배열의 추상자료형

27
배열(array) – 1차원 배열 배열 원소의 수 : U(상한 값) – L(하한 값) + 1
………. ……… A[99] A(L) A(L+1) A(L+2) A(L+3) ………. ……… A(U) 원소 또는 멤버 배열 원소의 수 : U(상한 값) – L(하한 값) + 1 A[100]이라고 배열을 선언하면 A[0]부터 A[99]까지 사용 A[-2:3]은 A[-2], A[-1], A[0], A[1], A[2], A[3]을 나타냄. ( 다른 언어에서 사용) Address(i) = Address(A(L)) + i
 A(L+1) A(L+2) A(L+3) ………. ……… A(U) 원소 또는 멤버. 배열 원소의 수 : U(상한 값) – L(하한 값) + 1. A[100]이라고 배열을 선언하면 A[0]부터 A[99]까지 사용. A[-2:3]은 A[-2], A[-1], A[0], A[1], A[2], A[3]을 나타냄. ( 다른 언어에서 사용) Address(i) = Address(A(L)) + i.")
28
배열(array) – 2차원 배열(1) 2차원 배열 (n × m) 행(row) 열(Column) A[0][0] A[0][1]
… A[0][m-1] A[1][0] A[2][0] …. A[n-1][0] A[n-1][m-1] 열(Column)
![배열(array) – 2차원 배열(1) 2차원 배열 (n × m) 행(row) 열(Column) A[0][0] A[0][1]](http://slidesplayer.org/slide/14444350/90/images/28/%EB%B0%B0%EC%97%B4%28array%29+%E2%80%93+2%EC%B0%A8%EC%9B%90+%EB%B0%B0%EC%97%B4%281%29+2%EC%B0%A8%EC%9B%90+%EB%B0%B0%EC%97%B4+%28n+%C3%97+m%29+%ED%96%89%28row%29+%EC%97%B4%28Column%29+A%5B0%5D%5B0%5D+A%5B0%5D%5B1%5D.jpg "… A[0][m-1] A[1][0] A[2][0] …. A[n-1][0] A[n-1][m-1] 열(Column)")
29
배열(array) – 2차원 배열(2) 2차원 배열 (n × m) 2차원 배열의 저장 방법 행 우선 저장 방법
… A[0][m-1] A[1][0] A[2][0] …. A[n-1][0] A[n-1][m-1] Address(A(i,j)) = Address(A(L1,L2)) + (i-L1)*(U2-L2+1)*k + (j-L2)*k
) = Address(A(L1,L2)) + (i-L1)*(U2-L2+1)*k + (j-L2)*k.")
30
배열(array) – 2차원 배열(3) 2차원 배열 (n × m) 2차원 배열의 저장 방법 열 우선 저장 방법
… A[0][m-1] A[1][0] A[2][0] …. A[n-1][0] A[n-1][m-1] Address(A(i,j)) = Address(A(L1,L2)) + (j-L2)*(U1-L1+1)*k + (i-L1)*k
) = Address(A(L1,L2)) + (j-L2)*(U1-L1+1)*k + (i-L1)*k.")
31
배열의 표현 - 2차원 배열(4) n1:행의 수, n2:열의 수, 원소 수:n1 • n2
2차원 배열의 선언 : a[n1, n2] n1:행의 수, n2:열의 수, 원소 수:n1 • n2 2차원 배열을 1차원 메모리 표현 1 2 행 열 [0,0] [0,1] [0,2] [1,0] [1,1] [1,2] 0행 1행 행우선 0열 열우선 1열 2열 A[2,3]

32
배열의 표현 - 2차원 배열(5) 2차원 배열 a[m, n]일 경우, 처음 원소 : a[0,0] 주소가 α일 때,
임의의 원소 a[i,j]의 주소 행 우선 : α + i*n +j 열 우선 : α + j*m +i A[2,3]일때 A[1,0]의 주소 행우선 : 1+1x3+0 열우선 : 1+0x2+1 1
![배열의 표현 - 2차원 배열(5) 2차원 배열 a[m, n]일 경우, 처음 원소 : a[0,0] 주소가 α일 때,](http://slidesplayer.org/slide/14444350/90/images/32/%EB%B0%B0%EC%97%B4%EC%9D%98+%ED%91%9C%ED%98%84+-+2%EC%B0%A8%EC%9B%90+%EB%B0%B0%EC%97%B4%285%29+2%EC%B0%A8%EC%9B%90+%EB%B0%B0%EC%97%B4+a%5Bm%2C+n%5D%EC%9D%BC+%EA%B2%BD%EC%9A%B0%2C+%EC%B2%98%EC%9D%8C+%EC%9B%90%EC%86%8C+%3A+a%5B0%2C0%5D+%EC%A3%BC%EC%86%8C%EA%B0%80+%CE%B1%EC%9D%BC+%EB%95%8C%2C.jpg "임의의 원소 a[i,j]의 주소. 행 우선 : α + i*n +j. 열 우선 : α + j*m +i A[2,3]일때 A[1,0]의 주소. 행우선 : 1+1x3+0. 열우선 : 1+0x")
33
배열(array) – 3차원 배열 3차원 배열 a[n1, n2, n3] : <면, 행, 열> α α+ n2 · n3
a[0, 0, 0]의 주소를 α라 할 때, a[i1, i2, i3]의 주소 : α + i1 · n2 · n3 + i2 · n3 +i3 n2×n3 원소 … α α+ n2 · n3 α+(n1-1) · n2 · n3 a[0, n2, n3] a[1, n2, n3] a[n1, n2, n3]
![배열(array) – 3차원 배열 3차원 배열 a[n1, n2, n3] : <면, 행, 열> α α+ n2 · n3](http://slidesplayer.org/slide/14444350/90/images/33/%EB%B0%B0%EC%97%B4%28array%29+%E2%80%93+3%EC%B0%A8%EC%9B%90+%EB%B0%B0%EC%97%B4+3%EC%B0%A8%EC%9B%90+%EB%B0%B0%EC%97%B4+a%5Bn1%2C+n2%2C+n3%5D+%3A+%3C%EB%A9%B4%2C+%ED%96%89%2C+%EC%97%B4%3E+%CE%B1+%CE%B1%2B+n2+%C2%B7+n3.jpg "a[0, 0, 0]의 주소를 α라 할 때, a[i1, i2, i3]의 주소 : α + i1 · n2 · n3 + i2 · n3 +i3. n2×n3. 원소. … α. α+ n2 · n3. α+(n1-1) · n2 · n3. a[0, n2, n3] a[1, n2, n3] a[n1, n2, n3]")
34
순서 리스트(1) 순서를 가진 원소들의 순열 물리적 순서가 아닌 원소의 특성에 의한 논리적 순서를 의미
리스트(list)는 단순히 원소들의 순열(sequence) 리스트 L=(e1, e2, …, en) L은 리스트 이름, ei는 리스트 원소 공백 리스트(원소가 하나도 없는 리스트)의 표현 : L=( ) 리스트의 각 원소는 선행자(predecessor)와 후속자(successor)를 가짐 요일 = (월, 화, 수, 목, 금, 토, 일)
는 단순히 원소들의 순열(sequence) 리스트 L=(e1, e2, …, en) L은 리스트 이름, ei는 리스트 원소. 공백 리스트(원소가 하나도 없는 리스트)의 표현 : L=( ) 리스트의 각 원소는 선행자(predecessor)와 후속자(successor)를 가짐. 요일 = (월, 화, 수, 목, 금, 토, 일)")
35
순서리스트(2) S = (a1,a2,…,an) 리스트 길이(n) : 유한
리스트 읽음(left→right, right→left) : access i번째 원소검색(1≤i≤n) : retrieve i번째에 새로운 값 저장(1≤i≤n) : update i번째에 새로운 원소삽입 : insert i→i+1 i번째 원소 삭제 : delete i+1→i 19
 : access. i번째 원소검색(1≤i≤n) : retrieve. i번째에 새로운 값 저장(1≤i≤n) : update. i번째에 새로운 원소삽입 : insert i→i+1. i번째 원소 삭제 : delete i+1→i. 19.")
36
리스트를 처리하는 연산

37
다항식의 1차원 배열표현(1) <표현1> 계수를 순서적으로 표현 <표현2> 0이 아닌 계수만을 취한 표현
2X4+10X3+X2+6 : (2, 10, 1, 0, 6) <표현2> 0이 아닌 계수만을 취한 표현 2X4+10X3+X2+6 : (4, 2, 3, 10, 2, 1, 0, 6) p(x)=anxn+an-1xn-1+…+a1x+a0 an an-1 an-2 … a1 a0 coef[o] [1] [2] [n-1] [n] b(x)=bm-1xem-1+bm-2xem-2+…+b0xe0 (em-1, bm-1, em-2, bm-2, …, e0, b0) 19
 <표현2> 0이 아닌 계수만을 취한 표현. 2X4+10X3+X2+6 : (4, 2, 3, 10, 2, 1, 0, 6) p(x)=anxn+an-1xn-1+…+a1x+a0. an. an-1. an-2. … a1. a0. coef[o] [1] [2] [n-1] [n] b(x)=bm-1xem-1+bm-2xem-2+…+b0xe0. (em-1, bm-1, em-2, bm-2, …, e0, b0) 19.")
38
다항식의 1차원 배열표현(2) <표현1> <표현2> 예)A=5X10+2 일 경우
A=(n, an, an-1, … , a1, a0) 10 5 2 <표현2> A’=(m,em-1,bm-1,em-2,bm-2,…,e0,b0) 10 5 2 19
 <표현2> A’=(m,em-1,bm-1,em-2,bm-2,…,e0,b0)")
39
다항식의 2차원 배열 2X8-6X5+10X3+X2-2 : (8, 2, 5, -6, 3, 10, 2, 1, 0, -2)
<표현2> 0이 아닌 계수만을 취한 표현 방법으로 p[5,2]에 표현 8 5 3 2 p[0] [1] [2] [3] [4] 지수 [0] -6 10 -2 계수 1

40
다항식의 ADT(1)
")
41
다항식의 ADT(2)
")
42
두 다항식 덧셈 알고리즘(1)
")
43
두 다항식 덧셈 알고리즘(2)
")
44
희소행렬

45
행렬의 배열 표현

46
희소행렬의 표현 방법 행렬은 <행, 열, 값>으로 원소를 식별 0이 아닌 원소에 대해 열이 3인 2차원 배열로 표현
효율적인 연산을 위해 행과 열을 오름차순으로 저장 B= 76 13 3 25 -19 56 7×6 7 6 8 4 2 5 1 [0] [1] [2] b[0] [3] [4] [5] [6] [7] [8] C[9,3] 19

47
희소 행렬의 전치 (1) 전치 행렬 (transposed matrix) 간단한 전치 행렬 알고리즘 (행 우선 표현)
원소의 행과 열을 교환시킨 행렬 원소 <i, j, v> → <j, i, v>, 예) <0, 4, 13> → <4, 0, 13> 간단한 전치 행렬 알고리즘 (행 우선 표현) 희소 행렬의 전치 행 우선, 행 내에선 열 오름차순으로 저장된 경우, 각 열 별로 차례로 모든 원소를 찾아 행의 오름차순으로 저장하는 작업을 반복 for (j ←0; j <= n-1 ; j ←j+1 ) do for (i ←0; i <=m-1 ; i ←i+1 ) do b[j, i] ← a[i, j];
 <0, 4, 13> → <4, 0, 13> 간단한 전치 행렬 알고리즘 (행 우선 표현) 희소 행렬의 전치. 행 우선, 행 내에선 열 오름차순으로 저장된 경우, 각 열 별로 차례로 모든 원소를 찾아 행의 오름차순으로 저장하는 작업을 반복. for (j ←0; j <= n-1 ; j ←j+1 ) do. for (i ←0; i <=m-1 ; i ←i+1 ) do. b[j, i] ← a[i, j];")
48
전치행렬을 저장한 배열

49
희소 행렬의 전치 (2)
")
50
희소생렬의 전치 알고리즘

51
희소행렬의 구조체 선언

52
희소행렬의 전치 프로그램

53
문자열 추상 자료형

54
문자열 s와 t를 strcat(s, t) 연결 함수로 연결한 결과
문자열 연결 #define MAX_SIZE /* 문자열의 최대 크기 */ char s[MAX_SIZE]="dog"; char t[MAX_SIZE]="house"; char s[]="dog"; char t[]="house"; s[0] s[1] s[2] s[3] d o g \0 h t[0] t[1] t[2] t[3] t[4] t[5] o u s e \0 h s[0] s[1] s[2] s[3] s[4] s[5] s[6] s[7] s[8] s[9] o u s e \0 d g 문자열 s와 t를 strcat(s, t) 연결 함수로 연결한 결과 19
 연결 함수로 연결한 결과. 19.")
55
문자열 삽입 #include <string.h>
#define MAX_SIZE /* 가장 긴 문자열의 길이 */ char string1[MAX_SIZE], *s = string1; char string2[MAX_SIZE], *t = string2; u t o \ 0 a m o b i l e \0 s t \ 0 a \ 0 a u t o \ 0 a u t o m o b i l e \ 0 temp 초기상태 strncpy(temp,s,i) 호출 후 strcat(temp,t) 호출 후 strcat(temp,s+i) 호출 후
 호출 후. strcat(temp,t) 호출 후. strcat(temp,s+i) 호출 후.")
56
레코드 논리적으로 서로 연관이 있는 자료 원소들의 집합체 집합체의 이름 : 레코드 이름
레코드 집합체 내의 각 자료 원소 : 필드(항목, field) 학번 이름 나이 출생지 성별 76543 홍길동 18 서울 M int char short Char 4byte 9byte 2byte 5byte 1byte
 학번. 이름. 나이. 출생지. 성별 홍길동. 18. 서울. M. int. char. short. Char. 4byte. 9byte. 2byte. 5byte. 1byte.")
57
C언어에서의 레코드 구현(1)
")
58
Typedef를 이용한 구조체 정의

59
레코드와 파일 레코드들의 모음(집합체) : 파일(file)
순차 파일(sequence file) : 파일 내의 모든 레코드들의 논리적 구조가 동일한 파일 키 필드(key field) : 레코드를 구별할 수 있는 특정 필드 키 순차 파일(key-sequenced file) : 키 필드의 값에 따라 레코드들이 정렬된 파일 학번 이름 나이 출생지 성별 76543 홍길동 18 서울 M 76545 김철수 20 경기 76612 박영희 19 충청 W 76615 이기수 21 전라 76724 정미영 경상 76811 최미숙 강원
 : 파일 내의 모든 레코드들의 논리적 구조가 동일한 파일. 키 필드(key field) : 레코드를 구별할 수 있는 특정 필드. 키 순차 파일(key-sequenced file) : 키 필드의 값에 따라 레코드들이 정렬된 파일. 학번. 이름. 나이. 출생지. 성별 홍길동. 18. 서울. M 김철수. 20. 경기 박영희. 19. 충청. W 이기수. 21. 전라 정미영. 경상 최미숙. 강원.")
60
3장 스택과 큐

61
스택의 정의 x P Y Z 자료의 입력과 출력이 한쪽 끝에서만 이루어짐
후입 선출 리스트(LIFO, Last In First Out) PUSH, POP 연산 top포인터로 삽입과 삭제가 이루어짐 삽입 삭제 5 여유 공간 4 top P 3 x 2 Y 1 Z bottom -1
 PUSH, POP 연산. top포인터로 삽입과 삭제가 이루어짐. 삽입. 삭제. 5. 여유. 공간. 4. top. P. 3. x. 2. Y. 1. Z. bottom. -1.")
62
스택의 자료 삽입과 삭제 삽입 : Push, 삭제 : Pop top을 스택 포인터(stack pointer)라 함 top D
B C D top E

63
스택의 추상자료형(1)
")
64
스택의 추상자료형(2)
")
65
스택의 순차 표현 1차원 배열, Stack[n]을 이용한 순차 표현 스택을 표현하는 가장 간단한 방법
스택의 i 번째 원소는 Stack[i-1]에 저장 변수 top은 스택의 톱 원소를 가리킴 (초기: top = -1) stack[0] 첫 번째 원소 stack[1] 두 번째 원소 … stack[i-1] i 번째 원소 stack[n-1] n 번째 원소
![스택의 순차 표현 1차원 배열, Stack[n]을 이용한 순차 표현 스택을 표현하는 가장 간단한 방법](http://slidesplayer.org/slide/14444350/90/images/65/%EC%8A%A4%ED%83%9D%EC%9D%98+%EC%88%9C%EC%B0%A8+%ED%91%9C%ED%98%84+1%EC%B0%A8%EC%9B%90+%EB%B0%B0%EC%97%B4%2C+Stack%5Bn%5D%EC%9D%84+%EC%9D%B4%EC%9A%A9%ED%95%9C+%EC%88%9C%EC%B0%A8+%ED%91%9C%ED%98%84+%EC%8A%A4%ED%83%9D%EC%9D%84+%ED%91%9C%ED%98%84%ED%95%98%EB%8A%94+%EA%B0%80%EC%9E%A5+%EA%B0%84%EB%8B%A8%ED%95%9C+%EB%B0%A9%EB%B2%95.jpg "스택의 i 번째 원소는 Stack[i-1]에 저장. 변수 top은 스택의 톱 원소를 가리킴 (초기: top = -1) stack[0] 첫 번째 원소. stack[1] 두 번째 원소. … stack[i-1] i 번째 원소. stack[n-1] n 번째 원소.")
66
C배열을 이용한 스택의 구현(1) #include <stdio.h> #include <stdlib.h>
#define STACK_SIZE 100 typedef int element; /* element를 int 타입으로 정의*/ element stack[STACK_SIZE]; void push(int *top, element item) { if(*top >= STACK_SIZE - 1) { /* 스택이 만원인 경우 */ printf(" Stack is full\n"); return;} stack[++(*top)] = item;} /* top은 top+1로*/
 { if(*top >= STACK_SIZE - 1) { /* 스택이 만원인 경우 */ printf( Stack is full\n ); return;} stack[++(*top)] = item;} /* top은 top+1로*/")
67
C배열을 이용한 스택의 구현(2) element pop(int *top) {
if (*top == -1){ /* 스택이 공백인 경우 */ printf("Stack is empty\n"); exit(1);} else return stack[(*top)--]; } /* top은 top-1로 */ element delete1(int *top) {
{ /* 스택이 공백인 경우 */ printf( Stack is empty\n ); exit(1);} else return stack[(*top)--]; } /* top은 top-1로 */ element delete1(int *top) {")
68
C배열을 이용한 스택의 구현(3) int isEmpty(int *top) {
if (*top = = -1) return 1; /* 공백이면 1, 공백이 아니면 0 */ else return 0;} element peek(int top) { if (top == -1) { /* 스택이 공백인 경우 */ printf("Stack is empty\n"); exit(1);} else return stack[top]; }
 return 1; /* 공백이면 1, 공백이 아니면 0 */ else return 0;} element peek(int top) { if (top == -1) { /* 스택이 공백인 경우 */ printf( Stack is empty\n ); exit(1);} else return stack[top]; }")
69
스택과 큐의 응용 분야 스택의 응용 분야 큐의 응용 분야 시스템 스택, 서브루틴 호출 인터럽트처리, 컴파일러 수식의 계산 순환
작업 스케줄링 버퍼 관리 19

70
스택의 응용분야(1) β α 시스템 스택 프로그램 간의 호출과 복귀에 따른 실행 순서 관리
항상 스택의 톱에는 현재 실행되는 함수의 활성화 레코드 존재 스택 p : main() f1() 호출 end α: f2() 호출 β: f1() f2() β α
 f1() 호출. end. α: f2() 호출. β: f1() f2() β. α.")
71
Factorial 순환함수

72
수식의 표현 수식의 표기법 중위 표기 : A+B 전위 표기 : +AB 후위 표기 : AB+

73
스택을 이용한 수식 계산(1) 수식의 표기법 : A+B*C-D/E 스택을 이용한 후위 표기식의 계산
연산 ABC*+DE/- AT1+DE/- T2DE/- T2T3- T4 T1 BC* T2 A+T1 T3 D/E T4 T2–T3

74
스택을 이용한 수식 계산(2) ABC*+DE/- 공백 스택 A B C T1 T1 B*C T2 T2 A+T1 D E T3
T4 T2-T3 T4T4 T4 :결과 계산 완료

75
스택을 이용한 수식 계산(3) 후위 표기식 계산 evalPostfix(exp)
// 후기 표기식의 계산. 후위 표기식의 끝은 ∞이라고 가정 stack[n]; // 피연산자를 저장하기 위한 스택 top ← -1; while (true) do { token ← getToken(exp); // 식에서 토큰을 읽어옴 case { token = operand : push(stack, token); token = operator : {토큰이 연산자인 경우 stack에서 피연산자들을 삭제하여 계산을 하고 그 결과를 다시 stack에 삽입}; else : print(pop(stack)); // 토큰이 ∞인 경우 } } end evalPostfix()
 do { token ← getToken(exp); // 식에서 토큰을 읽어옴. case { token = operand : push(stack, token); token = operator : {토큰이 연산자인 경우 stack에서. 피연산자들을 삭제하여 계산을 하고 그 결과를. 다시 stack에 삽입}; else : print(pop(stack)); // 토큰이 ∞인 경우. } } end evalPostfix()")
76
스택을 이용한 수식 계산(4) 후위 표기식 수동 변환 방법 ((A + (B * C))-(D / E)) ABC*+DE/-
1. 중위 표기식을 완전하게 괄호로 묶는다. 2. 각 연산자를 묶고 있는 괄호의 오른쪽 괄호로 연산자를 이동시킨다. 3. 괄호를 모두 제거한다. ABC*+DE/- ((A + (B * C))-(D / E))
)-(D / E))")
77
큐의 표현 f r 배열Q 자료의 삽입과 삭제가 서로 다른 끝에서 이루어짐 선입선출(FIFO)
자료의 삽입과 삭제가 서로 다른 끝에서 이루어짐 선입선출(FIFO) C에서 Q[n]을 이용한 순차 표현 n : 큐에 저장할 수 있는 최대 원소 수 초기화 : front = rear = -1 (공백 큐) 공백 큐 : front = rear, 만원 : rear = n-1 n-1 -1 배열Q f r
 C에서 Q[n]을 이용한 순차 표현. n : 큐에 저장할 수 있는 최대 원소 수. 초기화 : front = rear = -1 (공백 큐) 공백 큐 : front = rear, 만원 : rear = n n 배열Q. f r.")
78
큐의 추상자료형(1)
")
79
큐의 추상자료형(1)
")
80
큐의 자료 삽입과 삭제 삽입 (add) -1 front rear A B 1 C 2 삭제 (delete) D 3
 -1 front rear A B 1 C 2 삭제 (delete) D 3")
81
큐의 응용 분야 택시, 은행, 백화점 등의 대기 행렬 작업 스케줄링 버퍼 관리

82
큐의 생성

83
큐에 원소의 삽입 및 삭제

84
순차 큐의 문제 순차 큐 rear=n-1인 경우 만원이지만, 반드시 n개의 원소가 큐에 있지는 않음
큐의 앞에서 삭제로 인해 빈 공간이 생길 수 있음 빈 공간을 없애기 위해 앞쪽으로 이동, front rear재설정 시간, 연산의 지연 문제 n-1 순차 큐

85
원형 큐 n개의 원소를 갖는 배열 Q[n] 원형으로 운영 rear = (11+1) mod 12 = 12/12……나머지 0
mod(modulus) 연산자 이용 rear (rear+1) mod n : front (front+1) mod n rear = (11+1) mod 12 = 12/12……나머지 0 Q(5) Q(4) E . D . . Q(3) . C . n-1 Q(2) B Q(n-3) 원형 큐 A Q(n-2) Q(1) Q(0) Q(n-1)
![원형 큐 n개의 원소를 갖는 배열 Q[n] 원형으로 운영 rear = (11+1) mod 12 = 12/12……나머지 0](http://slidesplayer.org/slide/14444350/90/images/85/%EC%9B%90%ED%98%95+%ED%81%90+n%EA%B0%9C%EC%9D%98+%EC%9B%90%EC%86%8C%EB%A5%BC+%EA%B0%96%EB%8A%94+%EB%B0%B0%EC%97%B4+Q%5Bn%5D+%EC%9B%90%ED%98%95%EC%9C%BC%EB%A1%9C+%EC%9A%B4%EC%98%81+rear+%3D+%2811%2B1%29+mod+12+%3D+12%2F12%E2%80%A6%E2%80%A6%EB%82%98%EB%A8%B8%EC%A7%80+0.jpg "mod(modulus) 연산자 이용. rear (rear+1) mod n : front (front+1) mod n. rear = (11+1) mod 12. = 12/12……나머지 0. Q(5) Q(4) E. . D. . . Q(3) . C n-1. Q(2) B. Q(n-3) 원형 큐. A. Q(n-2) Q(1) Q(0) Q(n-1)")
86
원형 큐의 순차표현

87
원형 큐의 구현(1)
")
88
원형 큐의 구현(2)
")
89
원형 큐의 원소 자료형 정의

90
큐의 원소를 처리할 배열 선언

91
원형 큐의 삭제 예제 35 27 65 48 52 0 1 2 3 4 f=0 r=3 r=0 65,27,35의 삽입 초기상태
(공백 큐 상태) f=1 65의 삭제 48,52의 삽입 (만원 큐 상태) 35 27 65 48 52 19
 f=1. 65의 삭제. 48,52의 삽입. (만원 큐 상태)")
92
데크(Double Ended Queue)
리스트의 처음과 마지막 원소에 대해 삽입, 삭제 삽입 right left 삭제 스크롤(scroll) 쉘프(shelf) 19
 쉘프(shelf) 19.")
93
데크의 삽입, 삭제 예 처음상태, l=2, r=3 0 1 2 3 4 5 a b l에 c삽입, l=1, r=3
a b l에 c삽입, l=1, r=3 r에 d삽입, l=1, r=4 c d l에 c삭제, l=2, r=4 19

94
4장 연결 리스트

95
노드 구조와 포인터 비순차 표현 또는 연결 표현 노드(node) 원소의 물리적 순서가 리스트의 논리적 순서와 일치할 필요 없음
원소를 저장할 때 이 원소의 다음 원소에 대한 주소도 함께 저장해야 함 노드 : <원소, 주소> 쌍의 저장 구조 노드(node) 자료 필드 : 리스트의 원소, 즉 자료 값을 저장하는 곳 링크 필드 : 다음 노드의 주소값을 저장하는 장소(포인터) 노드의 구조 : 자료 링크
 자료 필드 : 리스트의 원소, 즉 자료 값을 저장하는 곳. 링크 필드 : 다음 노드의 주소값을 저장하는 장소(포인터) 노드의 구조 : 자료. 링크.")
96
연결리스트(1) 각 노드는 자료 필드(data field)와 다음 노드의 주소 값을 가지는 링크 필드(link field)로 구성되는 자료 구조 삽입/삭제 시 원소 이동 발생 없음 종류 단순 연결 리스트 (linked list) 원형 연결 리스트(circular linked list) 이중 연결 리스트(double linked list) 이중 원형 연결 리스트(double circular linked list) eat L 자료 링크 fat hat mat vat null
 원형 연결 리스트(circular linked list) 이중 연결 리스트(double linked list) 이중 원형 연결 리스트(double circular linked list) eat. L. 자료. 링크. fat. hat. mat. vat. null.")
97
리스트의 표현

98
링크를 이용한 리스트 표현

99
연결 리스트(2) 링크에 주소값이 저장 마지막 노드 링크는 null을 저장 연결 리스트 전체는 포인터 변수 L로 나타냄
공백 리스트의 경우 L의 값은 null이 됨 널 포인터 노드의 필드 선택은 점 연산자를 이용 L.data : L이 가리키는 노드의 data 필드값, “eat” L.link.data : L이 가리키는 노드의 link 값이 가리키는 노드의 data 값, “fat” eat L 자료 링크 1004 1000 fat 1100 hat 1110 mat 1120 vat null

100
연결 리스트(3) 포인터 변수에 대한 연산은 제한되어 있음
p=null 또는 p≠null : 공백 포인터인가 또는 공백 포인터가 아닌가의 검사 p=q : 포인터 p와 q가 모두 같은 노드 주소를 가리키는가? p←null : p의 포인터 값으로 널을 지정 p←q : q가 가리키는 노드를 p도 똑같이 가리키도록 지정 p.link←q : p가 가리키는 노드의 링크 필드에 q의 포인터값을 지정 p←q.link : q가 가리키는 노드의 링크 값을 포인터 p의 포인터 값으로 지정

101
C에서의 포인터(1) 포인터 포인터 선언 다른 어떤 변수(variable)의 주소(address)를 그의 값으로 저장하는 변수
데이터 타입 이름 뒤나 변수 이름(식별자) 앞에 *를 붙임 예) char 타입의 변수와 포인터 선언 char c = ‘k’; char *pc; /* 또는 char* pc; */ pc = &c; K c pc
 앞에 *를 붙임. 예) char 타입의 변수와 포인터 선언. char c = ‘k’; char *pc; /* 또는 char* pc; */ pc = &c; K. c. pc.")
102
C에서의 포인터(2) 값 참조 포인터가 지시하는 주소의 값(내용)을 참조하기 위해서는 포인터 역 참조(dereference)를 해야 함 즉, 포인터 pc에 저장되어 있는 주소를 참조해 그 주소를 따라 가서 거기에 저장되어 있는 내용(값)을 검색 이 역 참조는 포인터 변수 앞에 *를 붙여 표현함 예) char c = ‘k’; char *pc; /* 또는 char* pc; */ pc = &c; - printf ("c is %c\n", c); - printf ("c is %c\n", *pc); 이 두 명령문은 같은 값을 출력
 char c = ‘k’; char *pc; /* 또는 char* pc; */ pc = &c; - printf ( c is %c\n , c); - printf ( c is %c\n , *pc); 이 두 명령문은 같은 값을 출력.")
103
C에서의 포인터(3) 값의 변경 c의 값을 ‘y’로 변경 1) c에 바로 ‘y’를 지정하거나
2) 포인터 pc를 이용해서 간접적으로 역 참조를 통해 변경 pc = &c; /* pc에 변수 c의 주소를 지정 */ c = 'y'; /* c에 ‘y'를 지정 */ *pc = 'y'; /* pc가 지시하고 있는 주소, c에 ‘y'를 지정 */ y c pc
 포인터 pc를 이용해서 간접적으로 역 참조를 통해 변경. pc = &c; /* pc에 변수 c의 주소를 지정 */ c = y ; /* c에 ‘y 를 지정 */ *pc = y ; /* pc가 지시하고 있는 주소, c에 ‘y 를 지정 */ y. c. pc.")
104
구조체 포인터 타입(1) 자체 참조 구조(self-referential structure)
struct의 멤버는 같은 타입의 또 다른 struct를 지시하는 포인터도 될 수 있음 리스트의 노드를 정의하는데 유용함 p = p->next; 와 같이 포인터를 순회시킴으로써, 이 포인터 p가 가리키는 노드에 연결된 다음 노드 접근 struct char_list_node { char letter; struct char_list_node *next; }; struct char_list_node *p;

105
구조체 포인터 타입(2) typedef 키워드 typedef struct char_list_node *list_pointer;
포인터 타입 list_pointer는 아직 정의되지 않은 char_list_node라는 struct 타입을 이용하여 정의 포인터 p는 NULL 값으로 초기화 typedef struct char_list_node *list_pointer; struct char_list_node{ char letter; list_pointer next; }; list_pointer p = NULL;

106
포인터의 할당과 반환 메모리의 동적 할당 int i, *pi; float f, *pf;
pi = (int *)malloc(sizeof(int)); pf = (float *)malloc(sizeof(float)); *pi = 10; *pf = 3.14; printf("an integer = %d, a float = %f\n",*pi, *pf); free(pi); free(pf); pi pf 10 3.14 i f
malloc(sizeof(int)); pf = (float *)malloc(sizeof(float)); *pi = 10; *pf = 3.14; printf( an integer = %d, a float = %f\n ,*pi, *pf); free(pi); free(pf); pi. pf i. f.")
107
C에서의 단순 연결 리스트(1) ① typedef struct list_node *list_pointer;
③ int data; ④ list_pointer link; }; void create(list_pointer t){ list_pointer i; ⑤ i=(list_pointer)malloc(sizeof(list_node)); ⑥ *t=i; i->data=3304; ⑦ i=(list_pointer)malloc(sizeof(list_node)); ⑧ t->link=i; ⑨ i->link=NULL; i->data=3308; } 데이터 링크 i 데이터 링크 t 3304 (a) (b) (c) (d) (e) 3308
{ list_pointer i; ⑤ i=(list_pointer)malloc(sizeof(list_node)); ⑥ *t=i; i->data=3304; ⑦ i=(list_pointer)malloc(sizeof(list_node)); ⑧ t->link=i; ⑨ i->link=NULL; i->data=3308; } 데이터 링크. i. 데이터 링크. t (a) (b) (c) (d) (e)")
108
C에서의 단순 연결 리스트(2) ① void insert(list_pointer t, list_pointer x) {
② list_pointer i; ③ i=(list_pointer)malloc(sizeof(list_node)); ④ i->data=3305; ⑤ if (*t==NULL) { *t=i; i->link=NULL;} ⑥ else{i->link=x->link; x->link=i; } ⑦ } 3304 3308 X i 3305 데이터 링크 (a) (b) t (c) t=null일 때 (d)
malloc(sizeof(list_node)); ④ i->data=3305; ⑤ if (*t==NULL) { *t=i; i->link=NULL;} ⑥ else{i->link=x->link; x->link=i; } ⑦ } X. i 데이터 링크. (a) (b) t. (c) t=null일 때. (d)")
109
C에서의 단순 연결 리스트(3) ① void delete(list_pointer x, list_pointer y, list_pointer t) { ② if (*y==NULL){ t=t->link; } ③ else{ y->link=x->link; } ④ free(x); ⑤ } null 3305 t (a) x y=null (삭제 후) (삭제 전) y=0일 때 y 3304 3308 (b) y가 null이 아닐 때 (c) 반환 자유공간리스트
; ⑤ } null t. (a) x. y=null. (삭제 후) (삭제 전) y=0일 때. y (b) y가 null이 아닐 때. (c) 반환. 자유공간리스트.")
110
C에서의 단순 연결 리스트(4) ① void print(list_pointer t){ ② list_pointer p;
③ p=t; ④ while(p){ ⑤ printf("%d",p->data); ⑥ p=p->link; ⑦ } ⑧ } 3305 t p 3304 3308 5 3 8
{ ⑤ printf( %d ,p->data); ⑥ p=p->link; ⑦ } ⑧ } t. p")
111
C에서의 단순 연결 리스트의 역순 ① void invert(list_pointer x) {
② list_pointer r, p, q; ③ p=x; q=NULL; ④ while(p){ ⑤ r=q; q=p; ⑥ p=plink; ⑦ q link=r; ⑧ } ⑨ x=q; } 13 9 5 2 null X p q=0 q r=0 r p=null
{ ⑤ r=q; q=p; ⑥ p=plink; ⑦ q link=r; ⑧ } ⑨ x=q; } null. X. p. q=0. q. r=0. r. p=null.")
112
단순 연결리스트의 결합(1)
")
113
단순 연결리스트의 결합(2)
")
114
연결 리스트를 이용한 스택과 큐 스택 큐 link null top data link null front data rear 19

115
연결 스택(1) ① void adds(list_pointer t, int y){ ② list_pointer x;
x=(list_pointer)malloc(sizeof(list_node)); xdata=y; xlink=t; t=x; } x link data (a) (c) y t null x (d) y t null link data (b)
malloc(sizeof(list_node)); xdata=y; xlink=t; t=x; } x. link. data. (a) (c) y. t. null. x. (d) y. t. null. link. data. (b)")
116
연결 스택(2) ① void deletes(list_pointer t, int y){ list_pointer x;
if(t==NULL){ stack_empty(); retrun; x=t; y=xdata; t=xlink; free(x); } x (a) y t null (b) (c) 자유공간리스트 반환
{ stack_empty(); retrun; x=t; y=xdata; t=xlink; free(x); } x. (a) y. t. null. (b) (c) 자유공간리스트. 반환.")
117
연결 큐(1) ① void addq(poly_pointer, int y, list_pointer front, list_pointer rear) { list_pointer x=(list_pointer)malloc(sizeof(list_node)); xdata=y; xlink=NULL; if(front==NULL){ *front=x; *rear=x; } else{ *rearlink=x; *rear=x; } x link data (a) null (b) y (c) front=null일 경우 front rear front≠null일 경우
{ *front=x; *rear=x; } else{ *rearlink=x; *rear=x; } x. link. data. (a) null. (b) y. (c) front=null일 경우. front. rear. front≠null일 경우.")
118
연결된 큐(2) ① void deleteq(list_pointer front, int *y){
list_pointer x=front; if(front==NULL); queue_empty(); return; } x=front; front=xlink; y=xdata; free(x); (a) x rear null front (b) 반환 x null 저장 front rear y 자유공간 리스트
; queue_empty(); return; } x=front; front=xlink; y=xdata; free(x); (a) x. rear. null. front. (b) 반환. x. null. 저장. front. rear. y. 자유공간. 리스트.")
119
원형 연결 리스트(1) 마지막 노드가 다시 첫 번째 노드를 가리키는 리스트 한 노드에서 다른 어떤 노드로도 접근할 수 있음
리스트 전체를 가용공간 리스트에 반환할 때 리스트의 길이에 관계없이 일정 시간에 반환할 수 있음` C ... data link

120
원형 연결 리스트(2) typedef struct poly_node *poly_pointer;
int coef; int expon; poly_pointer link; }; ① void decerase(poly_pointer t){ poly_pointer x; if(t==NULL) {return;} x=t link; t link = free; free = x; } t=3x14+2x8+1의 원형 연결 리스트의 노드 반환 14 3 2 8 1 t X (a) 14 3 2 8 1 t free … X (b) null 14 3 2 8 1 t free … (c) null X
{ poly_pointer x; if(t==NULL) {return;} x=t link; t link = free; free = x; } t=3x14+2x8+1의 원형. 연결 리스트의 노드 반환 t. X. (a) t. free. … X. (b) null t. free. … (c) null. X.")
121
원형 연결 리스트(3) ① void insert_front(list_pointer *a, list_pointer x){
② if(a==NULL) { a=x; x link = x;} else{ xlink=alink; alink=x; } x1 a x2 x3 data link x1 a x2 x3 앞 (a) x a=x; (b) a x3 x a 8 x3 (c) 5 3 x a x3 (e) x a x3 (d) x x a x3 (f)
 { a=x; x link = x;} else{ xlink=alink; alink=x; } x1. a. x2. x3. data. link. x1. a. x2. x3. 앞. (a) x. a=x; (b) a. x3. x. a. 8. x3. (c) x. a. x3. (e) x. a. x3. (d) x. x. a. x3. (f)")
122
원형 연결 리스트의 노드 길이 ① int length(list_pointer a){ list_pointer ptr;
int count=0; if(a!=NULL) {ptr=a; do { count++; ptr=ptrlink; } while(ptr==a); } return count; x1 a x2 x3 ptr
 {ptr=a; do. { count++; ptr=ptrlink; } while(ptr==a); } return count; x1. a. x2. x3. ptr.")
123
단순 연결 리스트 노드 삽입&삭제 P T X T P 찾아야 할 노드 … (a) 삽입 할 때 삽입 할 노드 찾아야 할 노드 …
2 … 15 x 18 23 (a) 삽입 할 때 16 삽입 할 노드 X 찾아야 할 노드 T 2 … 15 x 16 x 23 18 P (b) 삭제 할 때 삭제 할 노드 19
 삽입 할 때. 16. 삽입 할 노드. X. 찾아야 할 노드. T. 2. … 15. x. 16. x P. (b) 삭제 할 때. 삭제 할 노드. 19.")
124
이중 연결 리스트(1) 한 노드에서 후속 노드와 선행 노드를 가리키는 포인터를 가지는 리스트
헤드 노드를 갖는 이중 연결 원형 리스트 p = RLINK(LLINK(p)) =LLINK(RLINK(p)) LEFT null RIGHT LLINK 데이터 RLINK p 헤드 노드 LLINK 데이터 RLINK p
) =LLINK(RLINK(p)) LEFT. null. RIGHT. LLINK 데이터 RLINK. p. 헤드 노드. LLINK 데이터 RLINK. p.")
125
이중 연결 리스트(2) ① void ddelete(list_pointer x, list_pointer L) {
② if (x == L) { no_more_nodes(); return; } ③ x->llink->rlink=x->rlink; ④ x->rlink->llink=x->llink; ⑤ free(x); p L R 5 3 2 1 x q p L x q X p L q X
 { no_more_nodes(); return; } ③ x->llink->rlink=x->rlink; ④ x->rlink->llink=x->llink; ⑤ free(x); p. L. R x. q. p. L. x. q. X. p. L. q. X.")
126
이중 연결 리스트(3) ① void dinsert(list_pointer p, list_pointer x) {
② p->llink=x; ③ p->rlink=x->rlink; ④ x->rlink->llink=p; ⑤ x->rlink=p; } … x p

127
자유 공간 리스트(1) 필요에 따라 요구한 노드를 할당할 수 있는 자유 메모리 풀
자유 공간 관리를 위해 연결리스트 구조를 이용하기 위해서는 초기에 사용할 수 있는 메모리를 연결 리스트로 만들어 놓아야 함 초기 자유 공간 리스트 노드 할당 요청이 오면 리스트 앞에서부터 공백 노드를 할당 link null Free ...

128
자유 공간 리스트(2) 새로 노드를 할당하는 함수 (getNode) 노드를 할당한 뒤의 자유 공간 리스트 getNode()
if (Free = null) then underflow(); // 언더플로우 처리 루틴 newNode ← Free; Free ← Free.link; return newNode; end getNode() link data null Free ... newNode
 then. underflow(); // 언더플로우 처리 루틴. newNode ← Free; Free ← Free.link; return newNode; end getNode() link. data. null. Free. ... newNode.")
129
자유 공간 리스트(3) 가용 공간이 모두 할당된 경우의 처리 방법
1. 프로그램이 더 이상 사용하지 않는 노드들을 자유 공간 리스트에 반환 2. 시스템이 자동적으로 모든 노드들을 검사하여 사용하지 않는 노드들을 전부 수집하여 자유 공간 리스트의 노드로 만든 뒤 다시 노드 할당 작업 재개 - garbage collection

130
자유 공간 리스트(4) 삭제된 노드를 자유 공간 리스트에 반환 삭제된 노드 p를 자유 공간 리스트 Free에 반환
returnNode(p) p.link ← Free; Free ← p; end returnNode() null Free data ... p link
 p.link ← Free; Free ← p; end returnNode() null. Free. data. ... p. link.")
131
다항식의 리스트 표현 각 항을 하나의 노드로 표현
각 노드는 계수(coef)와 지수(exp), 다음 항을 가리키는 링크(link) 필드로 구성 다항식 A(x)=2x4+x2+6 과 B(x)=6x4-5x3+7x을 표현 다항식 노드 : coef exp link 2 4 A 1 6 null coef exp link 6 4 B -5 3 7 1 null
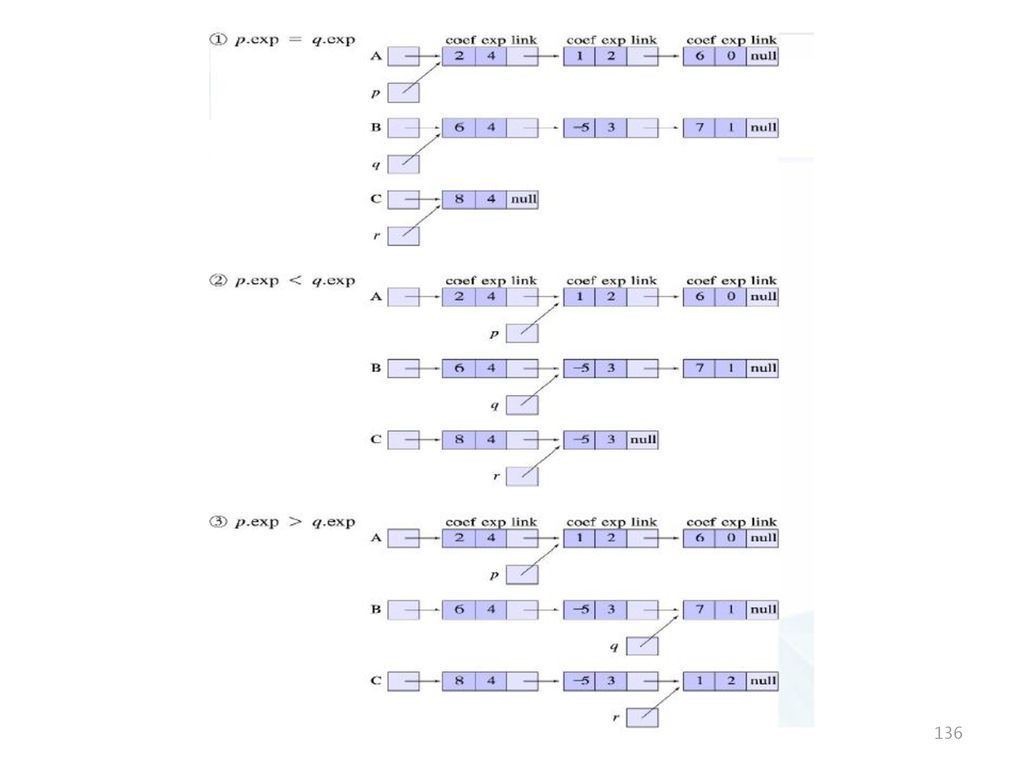
와 지수(exp), 다음 항을 가리키는 링크(link) 필드로 구성. 다항식 A(x)=2x4+x2+6 과 B(x)=6x4-5x3+7x을 표현. 다항식 노드 : coef. exp. link A null. coef. exp. link B null.")
132
다항식에 새로운 항 첨가 알고리즘

133
다항식의 덧셈 알고리즘(1)
")
134
다항식 덧셈 알고리즘(2)
")
135
다항식 덧셈 알고리즘(3)
")
137
원형연결리스트의 노드반환

138
일반 리스트 n≥0개의 원소 e1, e2, … en의 유한 순차 리스트의 원소가 원자일 뿐 아니라 리스트도 허용
리스트는 L=(e1, e2, … en)과 같이 표현 head(L) : n≥1인 경우 첫 번째 원소 e1 tail(L) : 첫번째 원소를 제외한 나머지 리스트 (e2, … en) 공백 리스트에 대해서는 head와 tail은 정의되지 않음 정의 속에 다시 리스트를 사용하고 있기 때문에 순환적 정의 노드 구조 : tag data link 19
과 같이 표현. head(L) : n≥1인 경우 첫 번째 원소 e1. tail(L) : 첫번째 원소를 제외한 나머지 리스트 (e2, … en) 공백 리스트에 대해서는 head와 tail은 정의되지 않음. 정의 속에 다시 리스트를 사용하고 있기 때문에 순환적 정의. 노드 구조 : tag. data. link. 19.")
139
일반 리스트의 예 A=( a, (b,c) ) B=( A, A, ( ) ) C=( a, C ) D=( )
B=((a, (b,c)), (a, (b,c)), ()) C=( a, C ) C=(a,(a,(a,…) D=( ) A 1 a null b c B C tag data link D=() Dnull 19
), (a, (b,c)), ()) C=( a, C ) C=(a,(a,(a,…) D=( ) A. 1. a. null. b. c. B. C. tag. data. link. D=() Dnull. 19.")
140
5장 트리

141
트리(1) 비선형 구조의 자료구조 자료 사이의 계층적 관계를 구조화 기억장소의 할당 및 자료저장과 탐색에 이용
가계도 : 자신, 부모, 형제, 조부모, 선조, 후손 기억장소의 할당 및 자료저장과 탐색에 이용 정렬, 검색에 많이 응용

142
트리(2) 트리 용어(1) 노드(node) : 저장된 정보 항목, 에지(edge, 계층관계)항목으로 구성
루트 : 트리의 정점 노드 차수(degree) : 노드의 부트리의 개수 트리의 차수는 트리에 속한 노드의 최대 차수 리프(leaf) : 단말노드, 차수가 0 인 노드 내부노드(internal node) : 비단말 노드 부모 노드(parent) : 부트리의 루트에 대하여 루트는 부모 노드 자식 노드(child) : 부트리의 루트는 루트의 자식 노드 형제 노드(brother, sibling) : 부모가 같은 자식 노드들 선조(ancestor) : 자신부터 루트까지의 노드 집합 후손(descendants) : 자신과, 부트리의 모든 노드 집합
 : 노드의 부트리의 개수 트리의 차수는 트리에 속한 노드의 최대 차수. 리프(leaf) : 단말노드, 차수가 0 인 노드. 내부노드(internal node) : 비단말 노드. 부모 노드(parent) : 부트리의 루트에 대하여 루트는 부모 노드. 자식 노드(child) : 부트리의 루트는 루트의 자식 노드. 형제 노드(brother, sibling) : 부모가 같은 자식 노드들. 선조(ancestor) : 자신부터 루트까지의 노드 집합. 후손(descendants) : 자신과, 부트리의 모든 노드 집합.")
143
트리(3) 트리 용어(2) A B C D E F G H I N
레벨(level) : 루트의 레벨은 1, 나머지는 부모 노드 레벨 (루트의 레벨을 1로 정의하기도 함) 높이(height), 깊이(depth) : 최대 레벨 값 A B C D E F G H I N 레벨 1 레벨 2 레벨 3 레벨 4
 : 루트의 레벨은 1, 나머지는 부모 노드 레벨. (루트의 레벨을 1로 정의하기도 함) 높이(height), 깊이(depth) : 최대 레벨 값. A. B. C. D. E. F. G. H. I. N. 레벨 1. 레벨 2. 레벨 3. 레벨 4.")
144
이진 트리(1) A A B B 모든 노드가 정확하게 두 서브트리를 가지고 있는 트리
왼쪽 서브 트리와 오른쪽 서브 트리를 분명하게 구별 이진트리 자체가 노드가 없는 공백이 될 수 있음 정의 : 이진 트리(binary tree: BT) 노드의 유한집합 공백이거나 루트와 두 개의 분리된 이진 트리인 왼쪽 서브 트리와 오른쪽 서브 트리로 구성 A A B (a) B (b)
 노드의 유한집합. 공백이거나 루트와 두 개의 분리된 이진 트리인 왼쪽 서브 트리와 오른쪽 서브 트리로 구성. A. A. B. (a) B. (b)")
145
이진 트리(2) 완전 이진 트리 (complete binary tree)
높이가 k 일 때, k-1 레벨까지는 노드가 차 있고, k 레벨에서는 노드가 왼쪽부터 차 있는 트리 노드 수 : 2k-1 -1 < n <= 2k -1 A B C E D G F I H

146
이진 트리(3) 포화 이진 트리(full binary tree) 각 레벨에 노드가 모두 차 있는 이진 트리
포화 이진 트리 ⇒ 완전 이진 트리 노드 수 : 2k -1 개 1 a b c d e f g 2 3 4 5 6 7

147
이진 트리 정리 A B C D E G F …… 1(=20) …… 2(=21) …… 3(=22)
이진 트리의 level i 에서 최대 노드 수는 2i-1 (i 1) root node의 level 이 0 일때 : 2i (i 0) 깊이가 k인 이진 트리의 최대 노드 수는 2k - 1 (k 1) root의 depth가 0 일 때 : 2k (k 0) . A B C D E G F …… 1(=20) …… 2(=21) …… 3(=22) 19
 root node의 level 이 0 일때 : 2i (i 0) 깊이가 k인 이진 트리의 최대 노드 수는 2k - 1 (k 1) root의 depth가 0 일 때 : 2k (k 0) . A. B. C. D. E. G. F. …… 1(=20) …… 2(=21) …… 3(=22) 19.")
148
이진 트리의 표현(배열) A B C D 1 2 3 4 - 5 6 7 8 19
 A B C D")
149
이진 트리의 표현(연결리스트) DATA LCHILD RCHILD A A A B B B C C C D
LCHILD DATA RCHILD DATA LCHILD RCHILD root C null B A root D null B A C A B C A B C D 19

150
이진 트리 순회(1) A B C 이진 트리에서 각 노드를 차례로 방문 순회방법:LDR,LRD,DLR,RDL,RLD,DRL
 A B C 이진 트리에서 각 노드를 차례로 방문 순회방법:LDR,LRD,DLR,RDL,RLD,DRL")
151
이진 트리의 순회(2) D-L-R 전위순회 L-D-R 중위순회 L-R-D 후위순회 A B C D E F G H I
DATA 19

152
이진 트리 순회(3) 중위 순회 (T1 T0 T2) (T11T10T12) (T21T20T22)
+ / * A ** E B C D T0 T1 T2 T20 T21 T22 T10 T11 T12 T120 T121 T122 중위 순회 (T1 T0 T2) (T21T20T22) (T11T10T12) (T121T120T122)
 (T21T20T22) (T11T10T12) (T121T120T122)")
153
중위순회 void INORDER(tree_pointer T){ if (T){ INORDER(T->LCHILD);
printf("%d", T->DATA); INORDER(T->RCHILD); } } void IN(1) IN(2) P(A) IN(3) void IN(2) IN(4) p(B) IN(0) 1 A C D B 2 3 void IN(4) IN(0) p(D) 4 void IN(3) IN(0) p(C) D B A C 19
; INORDER(T->RCHILD); } } void IN(1) IN(2) P(A) IN(3) void IN(2) IN(4) p(B) IN(0) 1. A. C. D. B void IN(4) IN(0) p(D) 4. void IN(3) IN(0) p(C) D B A C. 19.")
154
스레드 이진 트리(1) 널 링크들을 낭비하지 않고 스레드(thread)를 저장해 활용
스레드 : 트리의 어떤 다른 노드에 대한 포인터 트리를 순회하는 정보로 활용 스레드 이진 트리 생성 방법 노드 p의 right가 널 : 중위 순회에서 중위 후속자에 대한 포인터 저장 노드 p의 left가 널 : 중위 순회에서 중위 선행자에 대한 포인터 저장

155
스레드 이진 트리(2) A B D C I F H E A B D C I F H E
 A B D C I F H E A B D C I F H E")
156
스레드 이진 트리(3) 0 : LLINK = 스레드 포인트 1 : LLINK = 정상 포인트 LTAG =
DATA RLINK RTAG LTAG = 0 : LLINK = 스레드 포인트 1 : LLINK = 정상 포인트 RTAG = 0 : RLINK = 스레드 포인트 1 : RLINK = 정상 포인트

157
스레드 이진 트리(4) 1 HEAD A B C D E F G H I
 1 HEAD A B C D E F G H I")
158
히프 추상 데이터 타입 최대 트리(max tree)는 각 노드의 키 값이(자식이 있다면) 그 자식의 키 값보다 작지 않은 트리이다. 최대 히프(max heap)는 최대 트리인 완전 이진 트리이다. 최소 트리(min tree)는 각 노드의 키 값이(자식이 있다면)자식의 키 값보다 크지 않은 트리이다. 최소 히프(min heap)는 최소 트리이면서 완전 이진 트리이다.
는 각 노드의 키 값이(자식이 있다면)자식의 키 값보다 크지 않은 트리이다. 최소 히프(min heap)는 최소 트리이면서 완전 이진 트리이다.")
159
최대 히프의 예 14 7 12 8 10 6 9 3 6 5 30 25

160
최소 히프의 예 2 4 7 8 10 10 83 20 50 11 21

161
최대 히프에서의 삽입과정 20 2 15 10 14 (a) 삽입전의 히프 20 15 2 14 10 27 20 27
(b) 새로운 노드 27의 초기 위치 15 27 15 20 14 10 2 14 10 2 (c) 히프에 1차 수행 (d) 완성된 히프
 새로운 노드 27의 초기 위치 (c) 히프에 1차 수행. (d) 완성된 히프.")
Similar presentations



.>")
>")

.>")


 2개의 스택, stk1, stk2를 이용하여 큐를 구현하라.>")


구조체, 포인터>")


>")
.>")


