Download presentation
Presentation is loading. Please wait.

1
쉽게 배우는 알고리즘 6장. 해시 테이블Hash Table

2
6장.해시 테이블Hash Table 사실을 많이 아는 것 보다는 이론적 틀이 중요하고, 기억력보다는
생각하는 법이 더 중요하다. - 제임스 왓슨

3
학습목표 해시 테이블의 발생 동기를 이해한다. 해시 테이블의 원리를 이해한다. 해시 함수 설계 원리를 이해한다.
충돌 해결 방법들과 이들의 장단점을 이해한다. 해시 테이블의 검색 성능을 분석할 수 있도록 한다.

4
저장/검색의 복잡도 Array Binary search tree
O(n) Binary search tree 최악의 경우 Θ(n) 평균 Θ(log n) Balanced binary search tree(e.g. red-black tree) 최악의 경우 Θ(log n) B-tree Balanced binary search tree보다 상수 인자가 작다 Hash table 평균 Θ(1)
 Binary search tree. 최악의 경우 Θ(n) 평균 Θ(log n) Balanced binary search tree(e.g. red-black tree) 최악의 경우 Θ(log n) B-tree. Balanced binary search tree보다 상수 인자가 작다. Hash table. 평균 Θ(1)")
5
Hash Table 원소가 저장될 자리가 원소의 값에 의해 결정되는 자료구조 평균 상수 시간에 삽입, 삭제, 검색
매우 빠른 응답을 요하는 응용에 유용 예: 119 긴급구조 호출과 호출번호 관련 정보 검색 주민등록 시스템 Hash table은 최소 원소를 찾는 것과 같은 작업은 지원하지 않는다

6
주소 계산 검색키 주소계산 배열 모양의 테이블

7
크기 13인 Hash Table에 5 개의 원소가 저장된 예
입력: 25, 13, 16, 15, 7 13 1 2 15 3 16 4 5 6 7 8 9 10 11 12 25 Hash function h(x) = x mod 13
 = x mod 13.")
8
Hash Function 입력 원소가 hash table에 고루 저장되어야 한다 계산이 간단해야 한다
여러가지 방법이 있으나 가장 대표적인 것은 division method와 multiplication method이다

9
Multiplication Method
Division Method h(x) = x mod m m: table 사이즈. 대개 prime number임. Multiplication Method h(x) = (xA mod 1) * m A: 0 < A < 1 인 상수 m은 굳이 소수일 필요 없다. 따라서 보통 2p 으로 잡는다(p 는 정수)
 = x mod m. m: table 사이즈. 대개 prime number임. Multiplication Method. h(x) = (xA mod 1) * m. A: 0 < A < 1 인 상수. m은 굳이 소수일 필요 없다. 따라서 보통 2p 으로 잡는다(p 는 정수)")
10
Multiplication method의 작동 원리
x xA mod 1 1 1 m (xA mod 1) Multiplication method의 작동 원리 m-1
 Multiplication method의 작동 원리. m-1.")
11
Collision Hash table의 한 주소를 놓고 두 개 이상의 원소가 자리를 다투는 것
Hashing을 해서 삽입하려 하니 이미 다른 원소가 자리를 차지하고 있는 상황 Collision resolution 방법은 크게 두 가지가 있다 Chaining Open Addressing

12
Collision의 예 h(29) = 29 mod 13 = 3 29를 삽입하려 하자 이미 다른 원소가 차지하고 있다!
입력: 25, 13, 16, 15, 7 13 1 2 15 3 16 4 5 6 7 8 9 10 11 12 25 h(29) = 29 mod 13 = 3 29를 삽입하려 하자 이미 다른 원소가 차지하고 있다! Hash function h(x) = x mod 13
 = 29 mod 13 = 3. 29를 삽입하려 하자 이미 다른 원소가 차지하고 있다! Hash function h(x) = x mod 13.")
13
Collision Resolution Chaining Open addressing
같은 주소로 hashing되는 원소를 모두 하나의 linked list로 관리한다 추가적인 linked list 필요 Open addressing Collision이 일어나더라도 어떻게든 주어진 테이블 공간에서 해결한다 추가적인 공간이 필요하지 않다

14
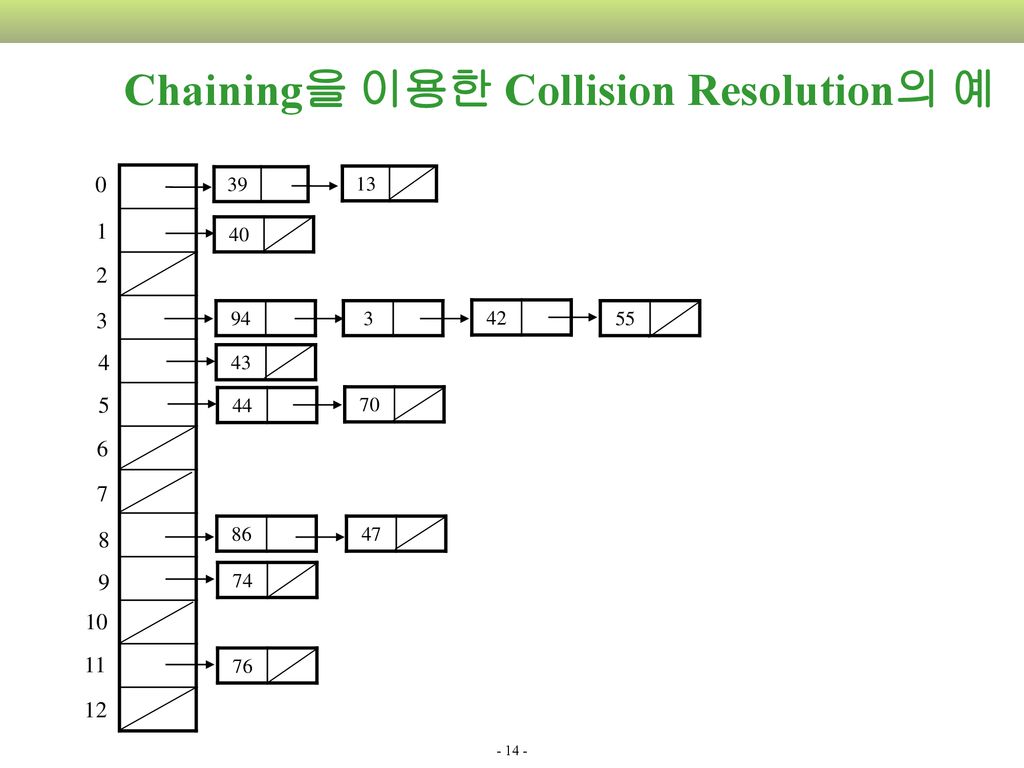
Chaining을 이용한 Collision Resolution의 예
39 13 1 40 2 3 94 3 42 55 4 43 5 44 70 6 7 8 86 47 9 74 10 11 76 12
15
Open Addressing 빈자리가 생길 때까지 해시값을 계속 만들어낸다 중요한 세가지 방법
h0(x), h1(x), h2(x), h3(x), … 중요한 세가지 방법 Linear probing Quadratic probing Double hashing
, h1(x), h2(x), h3(x), … 중요한 세가지 방법. Linear probing. Quadratic probing. Double hashing.")
16
Linear Probing hi(x) = (h(x) + i) mod m
예: 입력 순서 25, 13, 16, 15, 7, 28, 31, 20, 1, 38 13 1 2 15 3 16 4 28 5 6 7 8 9 10 11 12 25 13 1 2 15 3 16 4 28 5 31 6 7 8 20 9 10 11 12 25 13 1 2 15 3 16 4 28 5 31 6 38 7 8 20 9 10 11 12 25 hi(x) = (h(x) + i) mod 13
 = (h(x) + i) mod 13.")
17
Linear Probing은 Primary Clustering에 취약하다
1 2 15 3 16 4 28 5 31 6 44 7 8 9 10 11 37 12 Primary clustering의 예

18
Quadratic Probing hi(x) = (h(x) + c1i2 + c2i) mod m
예: 입력 순서 15, 18, 43, 37, 45, 30 1 2 15 3 4 43 5 18 6 45 7 8 30 9 10 11 37 12 hi(x) = (h(x) + i2 ) mod 13
 = (h(x) + i2 ) mod 13.")
19
Quadratic Probing은 Secondary Clustering에 취약하다
초기 해시 함수값을 갖는 현상 1 2 15 3 28 4 5 54 6 41 7 8 21 9 10 11 67 12 Secondary clustering의 예

20
Double Hashing hi(x) = (h(x) + i f (x)) mod m h(x) = x mod 13
예: 입력 순서 15, 19, 28, 41, 67 1 2 15 3 4 67 5 6 19 7 8 9 28 10 11 41 12 h0(15) = h0(28) = h0(41) = h0(67) = 2 h1(67) = 3 h1(28) = 8 h(x) = x mod 13 f(x) = (x mod 11) + 1 h1(41) = 10 hi(x) = (h(x)+i f(x)) mod 13
 = h0(28) = h0(41) = h0(67) = 2. h1(67) = 3. h1(28) = 8. h(x) = x mod 13. f(x) = (x mod 11) + 1. h1(41) = 10. hi(x) = (h(x)+i f(x)) mod 13.")
21
삭제시 조심할 것 (a) 원소 1 삭제 (b) 38 검색, 문제발생 (c) 표식을 해두면 문제없다 13 1 2 15 3 16
13 1 2 15 3 16 4 28 5 31 6 38 7 8 20 9 10 11 12 25 13 1 2 15 3 16 4 28 5 31 6 38 7 8 20 9 10 11 12 25 13 1 DELETED 2 15 3 16 4 28 5 31 6 38 7 8 20 9 10 11 12 25 (a) 원소 1 삭제 (b) 38 검색, 문제발생 (c) 표식을 해두면 문제없다
 원소 1 삭제. (b) 38 검색, 문제발생. (c) 표식을 해두면 문제없다.")
22
Hash Table에서의 검색 시간 Load factor α
Hash table에 n 개의 원소가 저장되어 있다면 α = n/m 이다 Hash table에서의 검색 효율은 load factor와 밀접한 관련이 있다

23
Chaning에서의 검색 시간 정리 1 Chaining을 이용하는 hashing에서 load factor가 α일 때, 실패하는 검색에서 probe 횟수의 기대치는 α이다 정리 2 Chaining을 이용하는 hashing에서 load factor가 α일 때, 성공하는 검색에서 probe 횟수의 기대치는 1 + α/2 + α/2n 이다

24
Open Addressing에서의 검색 시간
Assumption (uniform hashing) Probe 순서 h0(x), h1(x), …, hm-1(x)가 0부터 m-1 사이의 수로 이루어진 permutation을 이루고, 모든 permutation은 같은 확률로 일어난다 정리 3 Load factor α=n/m 인 open addressing hashing에서 실패하는 검색에서 probe 횟수의 기대치는 최대 1/(1- α )이다 정리 4 Load factor α=n/m 인 open addressing hashing에서 성공하는 검색에서 probe 횟수의 기대치는 최대 (1/ α) log(1/(1- α)) 이다
 Probe 순서 h0(x), h1(x), …, hm-1(x)가 0부터 m-1 사이의 수로 이루어진 permutation을 이루고, 모든 permutation은 같은 확률로 일어난다. 정리 3. Load factor α=n/m 인 open addressing hashing에서 실패하는 검색에서 probe 횟수의 기대치는 최대 1/(1- α )이다. 정리 4. Load factor α=n/m 인 open addressing hashing에서 성공하는 검색에서 probe 횟수의 기대치는. 최대 (1/ α) log(1/(1- α)) 이다.")
25
Load Factor가 우려스럽게 높아지면
Load factor가 높아지면 일반적으로 hash table의 효율이 떨어진다 일반적으로, threshold을 미리 설정해 놓고 load factor가 이에 이르면 Hash table의 크기를 두 배로 늘인 다음 hash table에 저장되어 있는 모든 원소를 다시 hashing하여 저장한다

26
생각해 볼 것 Load factor가 아주 낮으면 각 조사 방법들이 차이가 많이 나는가? 성공적인 검색과 삽입의 관계는?
[정리 4]의 증명과도 관계 있음 ~10/17/2007

27
Thank you

Similar presentations
 광양 매화마을 (40m) 사천 와룡산 철쭉 (1h) 사천 한려수도 (1h) 순천 순천만 갈대밭 (1h) 순천 삼보사찰 송광사 (1h20m) 구례 산수유마을 (1h30m) 산청 웅석계곡 (1h30m) 거제 외도 (1h50m)>")




 3-1 3 단원. 언어의 특성 기호성 자의성 사회성 규칙성 창조성 역사성.>")

 16:00.>")
>")




>")





