Download presentation
Presentation is loading. Please wait.

1
ALGORiTHM Algorithm 2000 서울산업대학교 전자계산학과

2
차 례 제 1 장 알고리즘과 복잡도 분석 제 2 장 자료구조 제 3 장 분할 및 정복
차 례 제 1 장 알고리즘과 복잡도 분석 제 2 장 자료구조 제 3 장 분할 및 정복 제 4 장 탐욕적 방법(Greedy Method) 제 5 장 동적프로그래밍 제 6 장 백트랙킹(Backtracking) 제 7 장 NP 이론 : 계산 복잡도 및 풀기 어려운 문제 제 8 장 병렬 컴퓨터 및 병렬 알고리즘 차례
 제 5 장 동적프로그래밍. 제 6 장 백트랙킹(Backtracking) 제 7 장 NP 이론 : 계산 복잡도 및 풀기 어려운 문제. 제 8 장 병렬 컴퓨터 및 병렬 알고리즘. 차례.")
3
제 1 장 알고리즘과 복잡도 분석 1.1 알고리즘의 개념 1.2 알고리즘 분석 및 복잡도 측정 1.3 순환적 알고리즘
제 1 장 알고리즘과 복잡도 분석 1.1 알고리즘의 개념 1.2 알고리즘 분석 및 복잡도 측정 1.3 순환적 알고리즘 1.4 연습문제 제 1 장

4
1.1 알고리즘의 개념 우리가 컴퓨터를 이용하여 문제에 대한 해답을 얻기까지 다음과 같은 단계들을 거친다.
1단계(시스템 분석) : 주어진 문제를 정의, 이해하며 타당성 등을 검토한다. 2단계(입,출력 결정) : 문제에 대한 입,출력을 결정한다. 어떤 데이터 타입의 변수들이 입,출력에 사용되는지를 결정하며, 출력형태 및 필요한 파일 설계 등을 한다. 1.1 알고리즘의 개념
 : 주어진 문제를 정의, 이해하며 타당성 등을 검토한다. 2단계(입,출력 결정) : 문제에 대한 입,출력을 결정한다. 어떤 데이터 타입의 변수들이 입,출력에 사용되는지를 결정하며, 출력형태 및 필요한 파일 설계 등을 한다. 1.1 알고리즘의 개념.")
5
3단계(알고리즘 설계) : 문제에 대한 해답을 얻기까지의 과정 및 절차를 명확하게 나타낸다.
4단계(코딩) : 설계된 알고리즘을 어떤 구체적인 프로그래밍 언어를 사용하여 코딩한다. 5단계(실행 및 테스트) : 코딩된 프로그램을 컴퓨터 하드웨어에 실제로 여러 데이터를 통해 수행시키며 옳게 작동됨을 검증한다. 알고리즘의 개념(계속)
 : 설계된 알고리즘을 어떤 구체적인 프로그래밍 언어를 사용하여 코딩한다. 5단계(실행 및 테스트) : 코딩된 프로그램을 컴퓨터 하드웨어에 실제로 여러 데이터를 통해 수행시키며 옳게 작동됨을 검증한다. 알고리즘의 개념(계속)")
6
우리가 알고리즘에서 생각해야 할 사항은 다음과 같다.
1) 명확성(definiteness) : 알고리즘을 구성하고 있는 각 명령어들은 명확해야 한다. 예) x = y + z 2) 효과성(effectiveness) : 알고리즘을 구성하는 각 명령어들은 컴퓨터 하드웨어에서 수행 가능한 것들이어야 한다. 예) 정수들에 대한 사칙연산 3) 종료성(termination) : 우리가 전산학에서 생각하는 모든 알고리즘들은 일단 시작되면, 명령어들을 유한 번 수행한 다음에 언젠가는 반드시 끝나야 한다. 알고리즘의 개념(계속)
 명확성(definiteness) : 알고리즘을 구성하고 있는 각 명령어들은 명확해야 한다. 예) x = y + z. 2) 효과성(effectiveness) : 알고리즘을 구성하는 각 명령어들은 컴퓨터 하드웨어에서 수행 가능한 것들이어야 한다. 예) 정수들에 대한 사칙연산. 3) 종료성(termination) : 우리가 전산학에서 생각하는 모든 알고리즘들은 일단 시작되면, 명령어들을 유한 번 수행한 다음에 언젠가는 반드시 끝나야 한다. 알고리즘의 개념(계속)")
7
void sequential_search(int n, const key_type A[],
보기 1.1 알고리즘 1.1 : 순차적 탐색 알고리즘 문제 : n개의 키들로 구성된 리스트 A에서 어떤 주어진 키 x가 A에 있는가를 결정하시오. 입력 : 자연수 n, 인덱스가 1부터 n까지인 n개의 원소(키)로 구성된 리스트 A, 그리고 탐색 대상인 키 x 출력 : x의 A에서의 위치를 나타내는 인덱스, 만약 x가 A에 없으면 0 void sequential_search(int n, const key_type A[], key_type x, index& location) { location = 1; while (location <= n && A[location] != x) location++; if (location > n) location = 0; } 알고리즘 1.1
![void sequential_search(int n, const key_type A[],](http://slidesplayer.org/slide/14753381/90/images/7/void+sequential_search%28int+n%2C+const+key_type+A%5B%5D%2C.jpg "보기 1.1. 알고리즘 1.1 : 순차적 탐색 알고리즘. 문제 : n개의 키들로 구성된 리스트 A에서 어떤 주어진 키 x가. A에 있는가를 결정하시오. 입력 : 자연수 n, 인덱스가 1부터 n까지인 n개의 원소(키)로. 구성된 리스트 A, 그리고 탐색 대상인 키 x. 출력 : x의 A에서의 위치를 나타내는 인덱스, 만약 x가 A에 없으면 0. void sequential_search(int n, const key_type A[], key_type x, index& location) { location = 1; while (location <= n && A[location] != x) location++; if (location > n) location = 0; } 알고리즘 1.1.")
8
void matrix_multiplication(int n, const number A[][],
보기 1.2 알고리즘 1.2 : 두 정방행렬의 곱셈 문제 : 두 개의 n * n 정방행렬에 대한 곱셈을 하시오. 입력 : 자연수 n, 두 개의 n * n 정방행렬 A 및 B 출력 : A 및 B를 곱한 결과 얻어지는 n * n 정방행렬 C void matrix_multiplication(int n, const number A[][], const number B[][], number C[][]) { index i, j, k; for (i = 1; i <= n; i++) for (j = 1; j <= n; j++) { C[i][j] = 0; for (k = 1; k <= n; k++) C[i][j] = C[i][j] + A[i][k] * B[k][j] } 알고리즘 1.2
![void matrix_multiplication(int n, const number A[][],](http://slidesplayer.org/slide/14753381/90/images/8/void+matrix_multiplication%28int+n%2C+const+number+A%5B%5D%5B%5D%2C.jpg "보기 1.2. 알고리즘 1.2 : 두 정방행렬의 곱셈. 문제 : 두 개의 n * n 정방행렬에 대한 곱셈을 하시오. 입력 : 자연수 n, 두 개의 n * n 정방행렬 A 및 B. 출력 : A 및 B를 곱한 결과 얻어지는 n * n 정방행렬 C. void matrix_multiplication(int n, const number A[][], const number B[][], number C[][]) { index i, j, k; for (i = 1; i <= n; i++) for (j = 1; j <= n; j++) { C[i][j] = 0; for (k = 1; k <= n; k++) C[i][j] = C[i][j] + A[i][k] * B[k][j] } 알고리즘 1.2.")
9
void exchange_sort(int n, key_type A[]) { index i, j;
보기 1.3 알고리즘 1.3 : 교환정렬 문제 : n 개의 키들로 구성된 리스트 A를 오름차순으로 정렬하시오. 입력 : 자연수 n, 1부터 n 까지인 n 개의 원소로 구성된 리스트 A 출력 : 오름차순으로 정렬된 리스트 A void exchange_sort(int n, key_type A[]) { index i, j; for (i = 1; i <= n - 1; i++) for (j = i + 1; j <= n; j++) if (A[j] < A[i]) exchange A[i] and a[j]; } 알고리즘 1.3
![void exchange_sort(int n, key_type A[]) { index i, j;](http://slidesplayer.org/slide/14753381/90/images/9/void+exchange_sort%28int+n%2C+key_type+A%5B%5D%29+%7B+index+i%2C+j%3B.jpg "보기 1.3. 알고리즘 1.3 : 교환정렬. 문제 : n 개의 키들로 구성된 리스트 A를 오름차순으로. 정렬하시오. 입력 : 자연수 n, 1부터 n 까지인 n 개의 원소로 구성된 리스트 A. 출력 : 오름차순으로 정렬된 리스트 A. void exchange_sort(int n, key_type A[]) { index i, j; for (i = 1; i <= n - 1; i++) for (j = i + 1; j <= n; j++) if (A[j] < A[i]) exchange A[i] and a[j]; } 알고리즘 1.3.")
10
number sum_of_elts(int n, const number A[]) { index i; number sum;
보기 1.4 알고리즘 1.4 : 행렬원소들의 합계 문제 : n 개의 숫자들이 있는 리스트(1차원 배열) A의 모든 원소 들을 더하시오. 입력 : 자연수 n 및 n 개의 숫자 원소들로 구성된 리스트 A 출력 : 리스트 A 의 모든 원소들을 더한 합계인 sum_of_elts number sum_of_elts(int n, const number A[]) { index i; number sum; sum = 0; for (i = 1; i <= n; i++) sum = sum + A[i] return sum; } 알고리즘 1.4
![number sum_of_elts(int n, const number A[]) { index i; number sum;](http://slidesplayer.org/slide/14753381/90/images/10/number+sum_of_elts%28int+n%2C+const+number+A%5B%5D%29+%7B+index+i%3B+number+sum%3B.jpg "보기 1.4. 알고리즘 1.4 : 행렬원소들의 합계. 문제 : n 개의 숫자들이 있는 리스트(1차원 배열) A의 모든 원소. 들을 더하시오. 입력 : 자연수 n 및 n 개의 숫자 원소들로 구성된 리스트 A. 출력 : 리스트 A 의 모든 원소들을 더한 합계인 sum_of_elts. number sum_of_elts(int n, const number A[]) { index i; number sum; sum = 0; for (i = 1; i <= n; i++) sum = sum + A[i] return sum; } 알고리즘 1.4.")
11
1.2 알고리즘 분석 및 복잡도 측정 알고리즘 종류 알고리즘 1 알고리즘 2 알고리즘 3 알고리즘 4 알고리즘 5
1.2 알고리즘 분석 및 복잡도 측정 알고리즘 종류 알고리즘 1 알고리즘 알고리즘 알고리즘 알고리즘 5 처리속도(sec) n n log n n n n 입력크기에 대한 처리시간 n = 초 초 초 초 초 n = 초 초 초 초 * 1014 n = 1, 초 초 초 시간 세기 n = 10, 초 초 분 일 (century) n = 100, 초 분 일 년 그림 1.1 1.2 알고리즘 분석 및 복잡도 측정
 33n 46 n log n 13 n2 3.4 n3 2n. 입력크기에. 대한 처리시간. n = 초 초 초 초 0.001초. n = 초 0.03 초 0.13 초 3.4 초 4 * n = 1, 초 0.45 초 13 초 0.94 시간 세기. n = 10, 초 6.1 초 22 분 39 일 (century) n = 100, 초 1.3 분 1.5 일 108 년. 그림 알고리즘 분석 및 복잡도 측정.")
12
n Cray 컴퓨터 3n3 나노 초 TRS 컴퓨터 19,500,000 n 나노 초 10 3 마이크로 초 200 밀리 초
마이크로 초 밀리 초 밀리 초 초 1, 초 초 2, 초 초 10, 분 분 1,000, 년 시간 (1초 = 1,000 밀리 초 = 1,000,000 마이크로 초 = 1,000,000,000 나노 초) 그림 1.2 그림 1.2
 그림 1.2. 그림 1.2.")
13
보기 1.5 리스트(1차원 배열)의 크기 순차적 탐색에서 실행되는 비교횟수 이진 탐색에서 그림 1.3 1, , 1,048, ,048, 4,294,967, ,294,967, 그림 1.3

14
알고리즘 1.5 : 이진탐색(binary search) 알고리즘(비순환적)
어떤 주어진 키 x가 A에 있는가를 결정하시오. 입력 : 자연수 n, 인덱스가 1부터 n까지인 n개의 원소(키)로 구성된 오름차순으로 정렬된 리스트 A, 그리고 탐색 대상인 키 x 출력 : x의 A 에서의 위치를 나타내는 인덱스인 location 만약 x가 A에 없으면 0 알고리즘 1.5
로 구성된. 오름차순으로 정렬된 리스트 A, 그리고 탐색 대상인 키 x. 출력 : x의 A 에서의 위치를 나타내는 인덱스인 location. 만약 x가 A에 없으면 0. 알고리즘 1.5.")
15
low = 1; high = n; location = 0;
void binary_search(int n, const key_type A[], const key_type x, index& location) { index low, middle, high; low = 1; high = n; location = 0; while (low <= high && location == 0) { middle = (low + high)/2 ; if (x == A[middle]) location = middle; else if (x < A[middle]) high = middle - 1; else low = middle + 1; } 알고리즘 1.5(계속)
 { index low, middle, high; low = 1; high = n; location = 0; while (low <= high && location == 0) { middle = (low + high)/2 ; if (x == A[middle]) location = middle; else if (x < A[middle]) high = middle - 1; else low = middle + 1; } 알고리즘 1.5(계속)")
16
int recursive_fibo(int n) { if (n <= 1) return n; else
보기 1.6 알고리즘 1.6 : 피보나치 수열의 일반항(순환적 알고리즘) 문제 : 앞에서 정의된 피보나치 수열의 n번째 일반항을 구하시오. 입력 : 0과 같거나 큰 정수 n 출력 : 피보나치 수열의 n번째 일반항 int recursive_fibo(int n) { if (n <= 1) return n; else return recursive_fibo(n - 1) + recursive_fibo(n - 2); } 알고리즘 1.6
 문제 : 앞에서 정의된 피보나치 수열의 n번째 일반항을 구하시오. 입력 : 0과 같거나 큰 정수 n. 출력 : 피보나치 수열의 n번째 일반항. int recursive_fibo(int n) { if (n <= 1) return n; else. return recursive_fibo(n - 1) + recursive_fibo(n - 2); } 알고리즘 1.6.")
17
int recursive_fibo(int n) { int f[0..n] index i; f[0] = 0;
알고리즘 1.7 : 피보나치 수열의 일반항(비순환적 알고리즘) 문제 : 앞에서 정의된 피보나치 수열의 n번째 일반항을 구하시오. 입력 : 0과 같거나 큰 정수 n 출력 : 피보나치 수열의 n번째 일반항 int recursive_fibo(int n) { int f[0..n] index i; f[0] = 0; if (n > 0) { f[1] = 1; for (i = 2; i <= n; i++) f[i] = f[i-1] + f[i-2]; } return f[n]; 알고리즘 1.7
![int recursive_fibo(int n) { int f[0..n] index i; f[0] = 0;](http://slidesplayer.org/slide/14753381/90/images/17/int+recursive_fibo%28int+n%29+%7B+int+f%5B0..n%5D+index+i%3B+f%5B0%5D+%3D+0%3B.jpg "알고리즘 1.7 : 피보나치 수열의 일반항(비순환적 알고리즘) 문제 : 앞에서 정의된 피보나치 수열의 n번째 일반항을 구하시오. 입력 : 0과 같거나 큰 정수 n. 출력 : 피보나치 수열의 n번째 일반항. int recursive_fibo(int n) { int f[0..n] index i; f[0] = 0; if (n > 0) { f[1] = 1; for (i = 2; i <= n; i++) f[i] = f[i-1] + f[i-2]; } return f[n]; 알고리즘 1.7.")
18
그림 1.4 Recursive -fobo(5) Recursive -fobo(4) Recursive -fobo(3)
 Recursive -fobo(4) Recursive -fobo(3)")
19
n 계산되는 항들의 개수 그림 1.5 그림 1.5

20
n n + 1 2n/2 알고리즘 1.6을 사용했을 때의 수행시간의 하한 알고리즘 1.7을 수행시간
,048, ,048 마이크로 초 나노 초 * 초 나노 초 * 분 나노 초 * 일 나노 초 * 년 나노 초 * * 107 년 나노 초 * * 1013 년 나노 초 그림 1.6 그림 1.6

21
n 의 값 시간 이름 상수 log n 로그 n 선형 nlog n 선형로그 n 차 n 차 2n 지수 n! 팩토리얼 * 1033 그림 1.7 그림 1.7

22
2n n2 n log n g n Log n 그림 1.8 n 그림 1.8

23
for (i = 1;i <= n; i++) for (j = 1; j <= n; j++)
보기 1.7 다음 알고리즘의 시간 복잡도를 구하시오. 단, 모듈 A를 처리하는데 상수시간 k가 소요된다. for (i = 1;i <= n; i++) for (j = 1; j <= n; j++) for (k = 1; k <= n; k++) A(); 보기 1.7 위의 알고리즘은 루우프가 세 번 중첩되어 있으며, 각 루우프 마다 n 번씩 반복하므로 전체 반복횟수는 n * n * n = n3 이다. 따라서, 시간 복잡도는 O(n3)이다.
 for (j = 1; j <= n; j++) for (k = 1; k <= n; k++) A(); 보기 1.7. 위의 알고리즘은 루우프가 세 번 중첩되어 있으며, 각 루우프 마다 n 번씩 반복하므로 전체 반복횟수는 n * n * n = n3 이다. 따라서, 시간 복잡도는 O(n3)이다.")
24
i = 1; while (i <= n) { A(); i = i * b; }
보기 1.8 i = 1; while (i <= n) { A(); i = i * b; } 보기 1.8 이 알고리즘에서 루우프 변수 i는 1, b, b2, b3, b4, … 과 같이 b의 지수승이 된다. 따라서 k를 bk > n 을 만족하는 처음의 지수라고 하면, 모듈 A는 정확히 k 번 만큼 수행된다. 즉, k = logbn + 1 이다. 따라서 시간 복잡도는 O(logbn)이다.
 { A(); i = i * b; } 보기 1.8. 이 알고리즘에서 루우프 변수 i는 1, b, b2, b3, b4, … 과 같이 b의 지수승이 된다. 따라서 k를 bk > n 을 만족하는 처음의 지수라고 하면, 모듈 A는 정확히 k 번 만큼 수행된다. 즉, k = logbn + 1 이다. 따라서 시간 복잡도는 O(logbn)이다.")
25
- notation - notation O - notation
정의) n >= n0 인 모든 정수 n에 대하여 f(n) <= c * g(n) 을 만족하는 두 정수 c와 n0 가 존재할 때, 우리는 f(n) = O(g(n))이라고 정의한다. - notation 정의) n >= n0 인 모든 정수 n에 대하여 f(n) >= c * g(n) 을 만족하는 두 정수 c와 n0 가 존재할 때, 우리는 f(n) = (g(n))이라고 정의한다. - notation 정의) n >= n0 인 모든 정수 n에 대하여 c1 * g(n) <= f(n) <= c2 * g(n)을 만족하는 세 정수 c1 , c2 , n0 가 존재할 때, 우리는 f(n) = (g(n))이라고 정의한다. 그림 1.9 (g)는 적어도 함수 g만큼 빠르게 증가하는 함수임. (g)는 함수 g와 같은 비율로 증가하는 함수임. 그림 1.9 O(g)는 함수 g 보다 빠르지 않게 증가하는 함수임.
 n >= n0 인 모든 정수 n에 대하여 f(n) <= c * g(n) 을 만족하는 두 정수 c와 n0 가 존재할 때, 우리는 f(n) = O(g(n))이라고 정의한다. - notation. 정의) n >= n0 인 모든 정수 n에 대하여 f(n) >= c * g(n) 을 만족하는 두 정수 c와 n0 가 존재할 때, 우리는 f(n) = (g(n))이라고 정의한다. - notation. 정의) n >= n0 인 모든 정수 n에 대하여 c1 * g(n) <= f(n) <= c2 * g(n)을 만족하는 세 정수 c1 , c2 , n0 가 존재할 때, 우리는 f(n) = (g(n))이라고 정의한다. 그림 1.9. (g)는 적어도 함수 g만큼 빠르게 증가하는 함수임. (g)는 함수 g와 같은 비율로 증가하는 함수임. 그림 1.9. O(g)는 함수 g 보다 빠르지 않게 증가하는 함수임.")
26
a가 상수일 때 a * nk = O(nk)인 사실을 증명하시오.
보기 1.9 a가 상수일 때 a * nk = O(nk)인 사실을 증명하시오. 증명>> a * nk <= c * nk 가 성립되도록 c >= a로 잡는다. 보기 1.10 만약 f(n) = O(h(n)), g(n) = O(h(n)) 이면 f(n) + g(n) = O(h(n))인 사실을 증명하시오. 증명>> c = c1 + c2로 하면, f(n) + g(n) <= c * h(n)이 된다. 보기 1.9/ 1.10
인 사실을 증명하시오. 증명>> a * nk <= c * nk 가 성립되도록 c >= a로 잡는다. 보기 만약 f(n) = O(h(n)), g(n) = O(h(n)) 이면 f(n) + g(n) = O(h(n))인 사실을 증명하시오. 증명>> c = c1 + c2로 하면, f(n) + g(n) <= c * h(n)이 된다. 보기 1.9/")
27
보기 1.11 f1(n) = O(g1(n)), f2(n) = O(g2(n)) 이면 f1(n) + f2(n) = O(max (g1(n), g2(n)) )인 사실을 증명하시오. 증명>> 정의에서 n >= max(n1, n2)인 모든 정수 n에 대하여 f1(n) <= c1 * max (g1(n), g2(n)) 이며, n >= max(n1, n2)인 모든 정수 n에 대하여 f2(n) <= c2 * max (g1(n), g2(n)) 이다. 따라서 n >= max(n1, n2)인 모든 정수 n에 대하여 f1(n) + f2(n) <= (c1 + c2) * max (g1(n), g2(n)) 이다. c = (c1 + c2) 로 하면 증명이 끝난다. 보기 1.11
인 모든 정수 n에 대하여 f1(n) <= c1 * max (g1(n), g2(n)) 이며, n >= max(n1, n2)인 모든 정수 n에 대하여 f2(n) <= c2 * max (g1(n), g2(n)) 이다. 따라서 n >= max(n1, n2)인 모든 정수 n에 대하여 f1(n) + f2(n) <= (c1 + c2) * max (g1(n), g2(n)) 이다. c = (c1 + c2) 로 하면 증명이 끝난다. 보기")
28
for (j = i + 1; j < n; j++) {
보기 1.12 for (i = 0; i < n - 1; i++) for (j = i + 1; j < n; j++) { temp = a[i, j]; a[i, j] = a [j, i]; a[i, j] = temp; } 이 프로그램의 시간 복잡도는 O(n2)이다. 보기 1.12/ 1.13 보기 1.13 F(n) = n3 + 2n2 은 (n3) 임을 증명하시오. 증명>> c = 1로 하면, n >= 0인 모든 n에 대하여 f(n) >= c * n3 이다.
 for (j = i + 1; j < n; j++) { temp = a[i, j]; a[i, j] = a [j, i]; a[i, j] = temp; } 이 프로그램의 시간 복잡도는. O(n2)이다. 보기 1.12/ 보기 F(n) = n3 + 2n2 은 (n3) 임을 증명하시오. 증명>> c = 1로 하면, n >= 0인 모든 n에 대하여 f(n) >= c * n3 이다.")
29
1) f(n) O(g(n)) if and only if g(n) ( f(n))
정리 1) f(n) O(g(n)) if and only if g(n) ( f(n)) 2) f(n) (g(n)) if and only if g(n) ( f(n)) 3) 만약 a, b > 1이면, logan logbn이 성립한다. 다시 말해서, 모든 로그함수의 복잡도 함수들은 같은 복잡도의 범주에 속한다. 우리는 이 책에서 이와 같은 로그함수적인 복잡도 함수를 (lg n)으로 나타낸다. 4) 만약 b > a > 0이라면, an O (bn) 이 성립한다. 다시 말해서 모든 지수함수의 복잡도 범주에 속하지 않는다. 정리
 f(n) O(g(n)) if and only if g(n) ( f(n)) 2) f(n) (g(n)) if and only if g(n) ( f(n)) 3) 만약 a, b > 1이면, logan logbn이 성립한다. 다시 말해서, 모든 로그함수의 복잡도 함수들은 같은 복잡도의 범주에 속한다. 우리는 이 책에서 이와 같은 로그함수적인 복잡도 함수를 (lg n)으로 나타낸다. 4) 만약 b > a > 0이라면, an O (bn) 이 성립한다. 다시 말해서 모든 지수함수의 복잡도 범주에 속하지 않는다. 정리.")
30
정리 5) 모든 a > 0 에 대하여, an O (n!)이 성립한다. 다시 말해서, 복잡도 함수 n!은 어떠한 지수함수 복잡도 함수보다도 더 나쁘다.(비능률적) 6) k > j > 2이고 b > a > 1 일 때, 다음과 같은 복잡도 함수들의 범주의 리스트를 생각하자. (lg n), (n), (n lg n), (n2), (nj), (nk), (an), (bn), (n!) 만약 복잡도 함수 f(n)이 위 범주들의 리스트에서 g(n)을 포함하는 범주의 왼쪽에 있다면, f(n) O(g(n))이 성립한다. 7) 만약 c >= 0, d > 0, f(n) O(g(n)) 그리고 h(n) (g(n))이라면, c * f(n) + d * h(n) (g(n))이 성립한다. 정리
 k > j > 2이고 b > a > 1 일 때, 다음과 같은 복잡도 함수들의 범주의 리스트를 생각하자. (lg n), (n), (n lg n), (n2), (nj), (nk), (an), (bn), (n!) 만약 복잡도 함수 f(n)이 위 범주들의 리스트에서 g(n)을 포함하는 범주의 왼쪽에 있다면, f(n) O(g(n))이 성립한다. 7) 만약 c >= 0, d > 0, f(n) O(g(n)) 그리고 h(n) (g(n))이라면, c * f(n) + d * h(n) (g(n))이 성립한다. 정리.")
31
1.3 순환적 알고리즘 int factorial(int n) { int i, f = 1;
보기 1.14 알고리즘 1.8 : 팩토리얼 함수 (비순환적 알고리즘) 문제 : 앞에서 정의된 팩토리얼 함수의 n번째 일반항을 구하시오. 입력 : 0과 같거나 큰 정수 n 출력 : 팩토리얼 함수의 n번째 일반항 int factorial(int n) { int i, f = 1; for (i = n; i > 0; i--) f *= i; return(f); } 1.3 순환적 알고리즘
 문제 : 앞에서 정의된 팩토리얼 함수의 n번째 일반항을 구하시오. 입력 : 0과 같거나 큰 정수 n. 출력 : 팩토리얼 함수의 n번째 일반항. int factorial(int n) { int i, f = 1; for (i = n; i > 0; i--) f *= i; return(f); } 1.3 순환적 알고리즘.")
32
int recursive_factorial(int n) { if i == 0 return(1);
알고리즘 1.9 : 팩토리얼 함수 (순환적 알고리즘) 문제 : 앞에서 정의된 팩토리얼 함수의 n번째 일반항을 구하시오. 입력 : 0과 같거나 큰 정수 n 출력 : 팩토리얼 함수의 n번째 일반항 int recursive_factorial(int n) { if i == 0 return(1); else return( n * recursive_factorial(n - 1); } 알고리즘 1.9
 문제 : 앞에서 정의된 팩토리얼 함수의 n번째 일반항을 구하시오. 입력 : 0과 같거나 큰 정수 n. 출력 : 팩토리얼 함수의 n번째 일반항. int recursive_factorial(int n) { if i == 0 return(1); else return( n * recursive_factorial(n - 1); } 알고리즘 1.9.")
33
순환적 알고리즘을 반복구조를 사용한 알고리즘으로 변환시키는 방법
1) 순환적 알고리즘에는 반드시 초기조건이 명시되어 있다. 예) 순환적 알고리즘 recursive_factorial에서는 n = 0 피보나치 수열인 경우 n = 0과 n =1 순환적 알고리즘에 나타난 초기조건을 for, while, do와 같은 반복구조문장의 초기조건으로 한다. 2) 순환적 알고리즘의 현재 값과 다음 값의 관계로 부터 다음 값을 구하는 관계식을 얻는다. 3) 위에서 얻은 관계식을 반복 구조 문장으로 나타낸다. 알고리즘 변환
 순환적 알고리즘에는 반드시 초기조건이 명시되어 있다. 예) 순환적 알고리즘 recursive_factorial에서는 n = 0. 피보나치 수열인 경우 n = 0과 n =1. 순환적 알고리즘에 나타난 초기조건을 for, while, do와 같은. 반복구조문장의 초기조건으로 한다. 2) 순환적 알고리즘의 현재 값과 다음 값의 관계로 부터 다음 값을. 구하는 관계식을 얻는다. 3) 위에서 얻은 관계식을 반복 구조 문장으로 나타낸다. 알고리즘 변환.")
34
1) 한 번에 막대기의 맨 위에 있는 디스크 만을 옮길 수 있다.
보기 1.15 하노이 탑 문제 디스크를 옮길 때의 규칙 1) 한 번에 막대기의 맨 위에 있는 디스크 만을 옮길 수 있다. 2) 크기가 큰 디스크는 절대로 크기가 적은 디스크 밑에 꽂힐 수 없다. 막대기에 꽂혀있는 디스크들은 크기가 적은 순서대로 막대기의 위에서 부터 꽂혀있다. 따라서 가장 큰 디스크가 맨 밑에 있으며, 가장 적은 디스크가 맨 위에 있다. 하노이 탑 문제
 한 번에 막대기의 맨 위에 있는 디스크 만을 옮길 수 있다. 2) 크기가 큰 디스크는 절대로 크기가 적은 디스크 밑에 꽂힐 수. 없다. 막대기에 꽂혀있는 디스크들은 크기가 적은 순서대로. 막대기의 위에서 부터 꽂혀있다. 따라서 가장 큰 디스크가. 맨 밑에 있으며, 가장 적은 디스크가 맨 위에 있다. 하노이 탑 문제.")
35
1) 먼저 가장 큰 디스크 k를 제외한 나머지 k-1개의 디스크들을
k개의 Hanoi Top 문제 (그림 1.10 참조) 1) 먼저 가장 큰 디스크 k를 제외한 나머지 k-1개의 디스크들을 막대기 A에서 막대기 B로 옮긴다. (그림 1.10 (b) 참조) 2) 가장 큰 디스크 k를 막대기 A에서 한 번에 막대기 C로 옮긴다. (그림 1.10 (c) 참조) 3) 막대기 B에 꽂혀 있는 디스크 1에서 k-1까지의 k-1개의 디스크 들을 막대기 A를 이용하여 막대기 B에서 막대기 C로 옮긴다. (그림 1.10 (d)참조) 하노이 탑 문제
 1) 먼저 가장 큰 디스크 k를 제외한 나머지 k-1개의 디스크들을. 막대기 A에서 막대기 B로 옮긴다. (그림 1.10 (b) 참조) 2) 가장 큰 디스크 k를 막대기 A에서 한 번에 막대기 C로 옮긴다. (그림 1.10 (c) 참조) 3) 막대기 B에 꽂혀 있는 디스크 1에서 k-1까지의 k-1개의 디스크. 들을 막대기 A를 이용하여 막대기 B에서 막대기 C로 옮긴다. (그림 1.10 (d)참조) 하노이 탑 문제.")
36
. A B C 1 2 k k-1 (a) (b) (c) (d) 그림 1.10 그림 1.10
 (b) (c) (d) 그림 1.10 그림 1.10")
37
void Hanoi_tower(int n, char from, char to, char temp) {
알고리즘 1.10 : 하노이 탑 알고리즘 (순환적 알고리즘) 문제 : 하노이 탑 문제를 해결하시오. 입력 : 자연수 n 출력 : 디스크를 어느 말뚝에서 어느 말뚝으로 옮기는 순서 void Hanoi_tower(int n, char from, char to, char temp) { if (n == 1) printf(“Move disk 1 from peg %c to peg %c”, from, to); else { Hanoi_tower (n - 1, from, temp, to); printf(“Move disc %d from peg %c to peg %c”, n, from, to); } 알고리즘 1.10
 문제 : 하노이 탑 문제를 해결하시오. 입력 : 자연수 n. 출력 : 디스크를 어느 말뚝에서 어느 말뚝으로 옮기는 순서. void Hanoi_tower(int n, char from, char to, char temp) { if (n == 1) printf( Move disk 1 from peg %c to peg %c , from, to); else { Hanoi_tower (n - 1, from, temp, to); printf( Move disc %d from peg %c to peg %c , n, from, to); } 알고리즘")
38
제 2 장 자료구조 2.1 소개 2.2 배열과 레코드 2.3 스택(stack)과 큐 (queue) 2.4 리스트 2.5 트리
제 2 장 자료구조 2.1 소개 2.2 배열과 레코드 2.3 스택(stack)과 큐 (queue) 2.4 리스트 2.5 트리 2.6 그래프 2.7 해싱 2.8 연습문제
과 큐 (queue) 2.4 리스트. 2.5 트리. 2.6 그래프. 2.7 해싱. 2.8 연습문제.")
39
2.2 배열과 레코드 1차원 배열 address(A[i]) = address(A[i] + k * (i - 1) 식 (2.1)
다차원 배열 2차원(행 우선) : address(A[i, j]) = address(A[l1, l2]) + (i - l1 ) * (u2 - l2 + 1) * k + (j - l2) * k 식(2.2) 2차원(열 우선) : address(A[i, j]) = address(A[l1, l2]) + (j - l2 ) * (u2 - l1 + 1) * k + (i - l2) * k 식(2.3) 3차원(행 우선) : address(A[p, q, r]) = address(A[l1, l2, l3]) + (p - l1 ) * (u2 - l2 + 1) * (u3 - l3 + 1) * k + (q - l2 ) * (u3 - l3 + 1) * k + (r - l3) * k 식(2.4) 3차원(열 우선) : address(A[p, q, r]) = address(A[l1, l2, l3]) + (p - l1) * k + (q - l2 ) * (u1 - l1 + 1) * k + (r - l3 ) * (u1 - l1 + 1) * (u2 - l2 + 1) * k 식(2.5)
![2.2 배열과 레코드 1차원 배열 address(A[i]) = address(A[i] + k * (i - 1) 식 (2.1)](http://slidesplayer.org/slide/14753381/90/images/39/2.2+%EB%B0%B0%EC%97%B4%EA%B3%BC+%EB%A0%88%EC%BD%94%EB%93%9C+1%EC%B0%A8%EC%9B%90+%EB%B0%B0%EC%97%B4+address%28A%5Bi%5D%29+%3D+address%28A%5Bi%5D+%2B+k+%2A+%28i+-+1%29+%EC%8B%9D+%282.1%29.jpg "다차원 배열. 2차원(행 우선) : address(A[i, j]) = address(A[l1, l2]) + (i - l1 ) * (u2 - l2 + 1) * k + (j - l2) * k 식(2.2) 2차원(열 우선) : address(A[i, j]) = address(A[l1, l2]) + (j - l2 ) * (u2 - l1 + 1) * k + (i - l2) * k 식(2.3) 3차원(행 우선) : address(A[p, q, r]) = address(A[l1, l2, l3]) + (p - l1 ) * (u2 - l2 + 1) * (u3 - l3 + 1) * k. + (q - l2 ) * (u3 - l3 + 1) * k + (r - l3) * k 식(2.4) 3차원(열 우선) : address(A[p, q, r]) = address(A[l1, l2, l3]) + (p - l1) * k + (q - l2 ) * (u1 - l1 + 1) * k. + (r - l3 ) * (u1 - l1 + 1) * (u2 - l2 + 1) * k 식(2.5)")
40
2.3 스택(stack)과 큐(queue) 2.3.1 stack (a) (b) 그림 2.1 그림 2.2 E B A C D
F를 삽입 D를 삭제 C를 삭제 F를 삭제 E를 삭제 B를 삭제 A를 삭제 Top = 2 Top = 0 Top = 3 Top = 1 F Top = -1 빈스틱 top Top = 1 (a) bottom 새 노드 삽입 삭제 (b) 그림 2.1 그림 2.2
 bottom. 새 노드 삽입. 삭제. (b) 그림 2.1. 그림 2.2.")
41
void push (int *top, element node) { if (*top >= MAX_SIZE - 1) {
stack_overflow(); return; } stack[++(*top)] = node; 삽입(PUSH) element pop (int *top) { if (*top == -1) { stack_underflow(); return; } return stack [(*top)--]; 제거(POP)
; return; } stack[++(*top)] = node; 삽입(PUSH) element pop (int *top) { if (*top == -1) { stack_underflow(); return; } return stack [(*top)--]; 제거(POP)")
42
if (top == -1) return (true); else return (false); }
기타 스택 연산들 IS_EMPTY (int *top) { if (top == -1) return (true); else return (false); } READ_TOP (int *top) { if (top == -1) return stack_underflow; else return stack[top]; }
 { if (top == -1) return (true); else return (false); } READ_TOP (int *top) { if (top == -1) return stack_underflow; else return stack[top]; }")
43
2.3.2 queue #define Q_SIZE n; //n은 큐의 최대 크기*/ typedef struct {
삭제 (pop) 삽입 (push) (a) 큐의 표현 #define Q_SIZE n; //n은 큐의 최대 크기*/ typedef struct { char key; …//노드에 대한 다른 필드들의 정의 */ } node; node queue[Q_SIZE]; int rear = front = -1; rear E D C B A front 자료의 삭제 자료의 삽입 (b) 그림 2.3
 삽입. (push) (a) 큐의 표현. #define Q_SIZE n; //n은 큐의 최대 크기*/ typedef struct { char key; …//노드에 대한 다른 필드들의 정의 */ } node; node queue[Q_SIZE]; int rear = front = -1; rear. E. D. C. B. A. front. 자료의 삭제. 자료의 삽입. (b) 그림 2.3.")
44
node q_delete(int *front,int rear) { if (*front == rear)
큐에 새 노드 삽입 큐의 노드 삭제 node q_delete(int *front,int rear) { if (*front == rear) return queue_underfow (); return queue[++(*front)]; } void q_insert(int *rear, node item) { if (*rear == Q_SIZE - 1) { queue_overflow (); return; } queue[++(*rear)] = item; ... 1 2 n-3 n-2 n-1 front rear 그림 2.4
 { if (*front == rear) return queue_underfow (); return queue[++(*front)]; } void q_insert(int *rear, node item) { if (*rear == Q_SIZE - 1) { queue_overflow (); return; } queue[++(*rear)] = item; n-3. n-2. n-1. front. rear. 그림 2.4.")
45
큐에서 노드의 삽입과 삭제 A E B C D 그림 2.5 front = rea r = -1 front = 2 rear = 3

46
deque A B X Y ... 노드의 삽입 노드의 삭제 end1 end2 그림 2.6

47
2.4 리스트 data link ... link 그림 2.7 연결 리스트 보기 2.1 일요일 월요일 화요일 수요일 목요일
2.4 리스트 data link ... 그림 2.7 연결 리스트 보기 2.1 1차원 배열을 이용한 순차적 리스트 일요일 월요일 화요일 수요일 목요일 금요일 토요일 배열 A[n] L0 L0+1 L0+2 L0+3 L0+4 L0+5 L0+6 주소 월요일 link 일요일 토요일 금요일 목요일 수요일 화요일 그림 2.8 선형 리스트를 연결 리스트로

48
2.5 트리 정의) 1) 선행자(predecessor)가 없는 뿌리(root)라고 불리는 특별한 노드가 하나만 존재한다.
2.5 트리 정의) 1) 선행자(predecessor)가 없는 뿌리(root)라고 불리는 특별한 노드가 하나만 존재한다. 2) 뿌리를 제외한 나머지 모든 노드들은 T1, T2, …, Tn 의 집합으로 분할되는데, T1, T2, …, Tn 자신들도 트리이다. 우리는 T1, T2, …, Tn 을 뿌리의 서브트리(subtree)라고 한다. T1 T2 Level 1 B D C E F A B D C E F A G Level 2 Level 3 Level 4 그림 2.9 그림 2.10
 1) 선행자(predecessor)가 없는 뿌리(root)라고 불리는 특별한 노드가 하나만 존재한다. 2) 뿌리를 제외한 나머지 모든 노드들은 T1, T2, …, Tn 의 집합으로 분할되는데, T1, T2, …, Tn 자신들도 트리이다. 우리는 T1, T2, …, Tn 을 뿌리의 서브트리(subtree)라고 한다. T1. T2. Level 1. B. D. C. E. F. A. B. D. C. E. F. A. G. Level 2. Level 3. Level 4. 그림 2.9. 그림")
49
(a) (b) T4 T3 B C A 그림 2.11 A E D B C 그림 2.13 A i H D K J E M L F O N
G C B 그림 2.12

50
(a) 이진트리의 레벨 i에 있을 수 있는 노드의 최대수는 2i-1
이진 트리의 표현 및 성질들 (a) 이진트리의 레벨 i에 있을 수 있는 노드의 최대수는 2i-1 (b) 깊이가 k인 이진트리에 있을 수 있는 노드의 최대수는 2k-1 정리 [증명] (a) i에 대한 수학적 귀납법에 의한다. 1단계(기초단계) : i = 1일때 트리는 뿌리노드로만 이루어졌으므로 트리에 있을 수 있는 노드의 최대수는 1이다. 2i-1 = 20 = 1이므로 (a) 성립 2단계(귀납적 가정단계) : 1 <= j < i 인 모든 j에 대하여, 레벨 j에 있을 수 있는 노드의 최대수가 2j-1 이라고 가정하자. 3단계(귀납단계) : 앞의 귀납적 가정단계에 의하여 레벨 i -1에 있을 수 있는 노드들의 최대수는 2i-2 이다. 이진트리의 각 노드는 자식노드를 최대한 2개 까지 가질 수 있으므로, 레벨 i에 있을 수 있는 노드들의 최대수는 레벨 i - 1에 있을 수 있는 노드들의 개수인 2i-2에 2를 곱한 것이다.
 이진트리의 레벨 i에 있을 수 있는 노드의 최대수는 2i-1. (b) 깊이가 k인 이진트리에 있을 수 있는 노드의 최대수는 2k-1. 정리. [증명] (a) i에 대한 수학적 귀납법에 의한다. 1단계(기초단계) : i = 1일때 트리는 뿌리노드로만 이루어졌으므로 트리에 있을 수 있는 노드의 최대수는 1이다. 2i-1 = 20 = 1이므로 (a) 성립. 2단계(귀납적 가정단계) : 1 <= j < i 인 모든 j에 대하여, 레벨 j에 있을 수 있는 노드의 최대수가 2j-1 이라고 가정하자. 3단계(귀납단계) : 앞의 귀납적 가정단계에 의하여 레벨 i -1에 있을 수 있는 노드들의 최대수는 2i-2 이다. 이진트리의 각 노드는 자식노드를 최대한 2개 까지 가질 수 있으므로, 레벨 i에 있을 수 있는 노드들의 최대수는 레벨 i - 1에 있을 수 있는 노드들의 개수인 2i-2에 2를 곱한 것이다.")
51
즉, 레벨 i에 있을 수 있는 노드들의 최대수는 2i-2 * 2 = 2i-1 개가 된다. 따라서 (a)의 증명이 완결된다.
뿌리노드 레벨 i 레벨 i-1 그림 2.14 즉, 레벨 i에 있을 수 있는 노드들의 최대수는 2i-2 * 2 = 2i-1 개가 된다. 따라서 (a)의 증명이 완결된다. (b) 깊이가 k인 이진트리에 있을 수 있는 노드들의 최대수는 (레벨 1에 있을 수 있는 최대 노드 수) + (레벨 2에 있을 수 있는 최대 노드 수) + (레벨 3에 있을 수 있는 최대 노드 수) + … + (레벨 k에 있을 수 있는 최대 노드 수) = ∑2i-1 = 2k - 1 k i=1
의 증명이 완결된다. (b) 깊이가 k인 이진트리에 있을 수 있는 노드들의 최대수는. (레벨 1에 있을 수 있는 최대 노드 수) + (레벨 2에 있을 수 있는 최대 노드 수) + (레벨 3에 있을 수 있는 최대 노드 수) + … + (레벨 k에 있을 수 있는 최대 노드 수) = ∑2i-1 = 2k - 1. k. i=1.")
52
typedef struct node *ptr; typedef srruct node { ptr lchild; char data;
rchild lchild rchild data 그림 2.15 /* 노드에 대한 데이터 타입 정의(C 언어) */ typedef struct node *ptr; typedef srruct node { ptr lchild; char data; ptr rchild; };
 */ typedef struct node *ptr; typedef srruct node { ptr lchild; char data; ptr rchild; };")
53
T6 A B C (a) i H D E F G D B C A H i F G E (b) 그림 2.16
 i H D E F G D B C A H i F G E (b) 그림 2.16")
54
void preoder(tree_pointer ptr) { if (ptr) {
이진트리의 순회(binary tree traversal) (a) 전위순회(preoder traversal : 뿌리노드를 방문(root) 왼쪽 서브트리를 전위순회(left) 오른쪽 서브트리를 전위순회(right) (b) 중위순회(inoder traversal) : 왼쪽 서브트리를 중위순회(left) 뿌리노드를 방문(root) 오른쪽 서브트리를 중위순회(right) (c) 후위순회(postoder traversal) : 왼쪽 서브트리를 후위순회(left) 오른쪽 서브트리를 후위순회(right) 뿌리노드를 방문(root) 정의 void preoder(tree_pointer ptr) { // 이진트리를 전위순회하는 프로그램 if (ptr) { printf(“%c”, ptr->data); preoder(ptr->lchild); preoder(ptr->rchild); }
 (a) 전위순회(preoder traversal : 뿌리노드를 방문(root) 왼쪽 서브트리를 전위순회(left) 오른쪽 서브트리를 전위순회(right) (b) 중위순회(inoder traversal) : 왼쪽 서브트리를 중위순회(left) 뿌리노드를 방문(root) 오른쪽 서브트리를 중위순회(right) (c) 후위순회(postoder traversal) : 왼쪽 서브트리를 후위순회(left) 오른쪽 서브트리를 후위순회(right) 뿌리노드를 방문(root) 정의. void preoder(tree_pointer ptr) { // 이진트리를 전위순회하는 프로그램. if (ptr) { printf( %c , ptr->data); preoder(ptr->lchild); preoder(ptr->rchild); }")
55
void inoder(tree_pointer ptr) { if (ptr) { inoder(ptr->lchild);
// 이진트리를 중위순회하는 프로그램 if (ptr) { inoder(ptr->lchild); printf(“%c”, ptr->data); inoder(ptr->rchild); } void iter_inoder(ptr node) { int top = -1 // stack의 초기화 ptr stack[STACK_SIZE]; for ( ; ; ) { for ( ; node; node = node->lchild) insert(&top, node); // stack에 삽입 node = delete(&top); // stack에서 제거 if (!node) break; // empty stack prontf(“%c”, node->data); node = node->rchild }
 { inoder(ptr->lchild); printf( %c , ptr->data); inoder(ptr->rchild); } void iter_inoder(ptr node) { int top = -1 // stack의 초기화. ptr stack[STACK_SIZE]; for ( ; ; ) { for ( ; node; node = node->lchild) insert(&top, node); // stack에 삽입. node = delete(&top); // stack에서 제거. if (!node) break; // empty stack. prontf( %c , node->data); node = node->rchild. }")
56
void postorder(ptr p) { if (p) { postorder(p->lchild);
// 이진트리를 후위순회하는 프로그램 if (p) { postorder(p->lchild); postorder(p->rchild); printf(“%c”, p->data); } + * 보기 2.4 E C * D preorder : +**/ABCDE inorder : A/B*C*D+E postorder : AB/C*D*E+ A B / 그림 2.17
 { postorder(p->lchild); postorder(p->rchild); printf( %c , p->data); } + * 보기 2.4. E. C. * D. preorder : +**/ABCDE. inorder : A/B*C*D+E. postorder : AB/C*D*E+ A. B. / 그림")
57
스레드 된 이진트리(threaded binary tree)
스레드 포인터 정의 (a) p가 가리키는 노드가 왼쪽 자식 노드가 없는 경우( p->lchild = null) 이 경우 우리는 p->lchild의 값을, 이진트리를 중위순회할 때 p의 바로 앞에 방문하는 노드를 가리키는 포인터, 즉 p의 바로 앞 선행노드(immediate predecessor)를 가리키는 포인터로 한다. (b) p가 가리키는 노드가 오른쪽 자식 노드가 없는 경우(p->rchild = null) 이 경우 우리는 p->rchild의 값을, 이진트리를 중위순회할 때 p의 바로 뒤에 방문하는 노드를 가리키는 포인터, 즉 p의 바로 뒤 후행노드(immediate successor)를 가리키는 포인터로 한다.
 p가 가리키는 노드가 왼쪽 자식 노드가 없는 경우( p->lchild = null) 이 경우 우리는 p->lchild의 값을, 이진트리를 중위순회할 때 p의 바로 앞에 방문하는 노드를 가리키는 포인터, 즉 p의 바로 앞 선행노드(immediate predecessor)를 가리키는 포인터로 한다. (b) p가 가리키는 노드가 오른쪽 자식 노드가 없는 경우(p->rchild = null) 이 경우 우리는 p->rchild의 값을, 이진트리를 중위순회할 때 p의 바로 뒤에 방문하는 노드를 가리키는 포인터, 즉 p의 바로 뒤 후행노드(immediate successor)를 가리키는 포인터로 한다.")
58
ptr BST(ptr root, char key) { // 이진 탐색트리를 탐색하는 순환적 프로그램
이진 탐색트리(binary search tree) 정의 (1) 각 노드의 왼쪽 서브트리의 키 값은 그 노드의 키 값보다 작다. (2) 각 노드의 오른쪽 서브트리의 키 값은 그 노드의 키 값보다 크다. (3) 각 노드의 왼쪽 서브트리 및 오른쪽 서브트리들은 다시 이진탐색 트리가 된다. ptr BST(ptr root, char key) { // 이진 탐색트리를 탐색하는 순환적 프로그램 // 키는 character 데이터 타입을 갖는다고 가정한다. // 주어진 키 값을 갖는 노드의 위치를 트리에서 찾아서 그 위치(포인터)를 // 돌려준다. 만약 그러한 노드가 트리에 없으면 null을 반환한다. if (!root) return NULL; if (key == root->data) return root; if (key < root->data) return BST(root->lchild, key); else return BST(root->rchild, key); }
 정의. (1) 각 노드의 왼쪽 서브트리의 키 값은 그 노드의 키 값보다 작다. (2) 각 노드의 오른쪽 서브트리의 키 값은 그 노드의 키 값보다 크다. (3) 각 노드의 왼쪽 서브트리 및 오른쪽 서브트리들은 다시 이진탐색. 트리가 된다. ptr BST(ptr root, char key) { // 이진 탐색트리를 탐색하는 순환적 프로그램. // 키는 character 데이터 타입을 갖는다고 가정한다. // 주어진 키 값을 갖는 노드의 위치를 트리에서 찾아서 그 위치(포인터)를. // 돌려준다. 만약 그러한 노드가 트리에 없으면 null을 반환한다. if (!root) return NULL; if (key == root->data) return root; if (key < root->data) return BST(root->lchild, key); else return BST(root->rchild, key); }")
59
ptr BST(ptr tree, char key)
// 변환한 프로그램 // 가정 및 모든 조건은 BST와 동일 while (tree) { if (key == tree->data) return tree; if (key < tree->data) tree = tree->lchild; else tree = tree->rchild; } return NULL;
 { if (key == tree->data) return tree; if (key < tree->data) tree = tree->lchild; else tree = tree->rchild; } return NULL;")
60
힙 트리(heap tree) (1) 모든 노드의 키 값이 자식 노드의 키 값보다 같거나 크다.
정의 (1) 모든 노드의 키 값이 자식 노드의 키 값보다 같거나 크다. (2) 단말 노드가 아닌 모든 내부 노드들은 반드시 2개의 자식 노드들을 갖는다. (3) 모든 단말 노드들은 마지막 레벨, 혹은 마지막 레벨의 바로 위의 레벨에만 있다. (4) 만약 트리가 포화 이진트리(full binary tree)가 아니면, 모든 단말 노드들은 반드시 왼쪽에서 부터 차례로 있다.
 모든 노드의 키 값이 자식 노드의 키 값보다 같거나 크다. (2) 단말 노드가 아닌 모든 내부 노드들은 반드시 2개의 자식 노드들을 갖는다. (3) 모든 단말 노드들은 마지막 레벨, 혹은 마지막 레벨의 바로 위의 레벨에만 있다. (4) 만약 트리가 포화 이진트리(full binary tree)가 아니면, 모든 단말 노드들은 반드시 왼쪽에서 부터 차례로 있다.")
61
보기 2.5 15 8 1 10 11 6 12 15 8 1 11 10 2 3 6 12 (a) (b) 5 (c) 15 1 8 10 11 2 3 6 12 15 8 1 10 12 2 3 6 (d) 그림 2.18
 그림")
62
void heap_insert(element item, int *n) { int i; if(HEAP_FULL (*n)) {
보기 2.6 15 10 11 6 12 8 1 3 2 void heap_insert(element item, int *n) { // 현재 크기가 n인 힙트리에 item을 삽입하여 새로운 힙트리를 만든다. int i; if(HEAP_FULL (*n)) { printf(“The heap is full\n”); exit (1); } i = ++(*n); while((i! = 1) && (item.key > heap[i/2].key)) { heap[i] = heap[i/2]; i /= 2; heap[i] = item;
 { // 현재 크기가 n인 힙트리에 item을 삽입하여 새로운 힙트리를 만든다. int i; if(HEAP_FULL (*n)) { printf( The heap is full\n ); exit (1); } i = ++(*n); while((i! = 1) && (item.key > heap[i/2].key)) { heap[i] = heap[i/2]; i /= 2; heap[i] = item;")
63
(a) (b) (c) (d) (e) (f) (g) (h) (i) 보기 2.7 2 8 2 2 8 2 6 8 2 6 8 1 2 6
10 10 6 8 1 2 8 6 10 1 2 15 8 6 10 1 2 (f) (g) (h) (i)
 (g) (h) (i)")
64
6 8 15 10 1 2 6 8 10 15 1 2 6 8 10 15 1 2 3 (j) (k) (l) 6 12 10 15 8 2 3 1 6 8 10 15 1 2 3 12 6 8 10 15 12 2 3 1 (n) (o) (m)
 (o) (m)")
65
6 12 10 15 8 2 3 1 11 6 12 10 15 11 2 3 1 8 (p) (q) 15 2 11 10 12 8 1 3 6 (r) 그림 2.19
 그림")
66
• 2.6 Graph C A B D D C B A B A C (a) (b) B A D C G1 A B C G2
그림 2.22 그림 2.20 B A D C G1 A B C G2 G1 = ({A,B,C,D}, {(A,B), (A,C), (A,D), (B,C),(B,D),(C,D)}} G2 = ({A,B,C}, {(A,B), (B,B)}} (b) (a) 그림 2.21
, (A,C), (A,D), (B,C),(B,D),(C,D)}} G2 = ({A,B,C}, {(A,B), (B,B)}} (b) (a) 그림")
67
C B A D 그림 2.23

68
2.7 해싱(hashing) 1) 개념 : 레코드가 테이블에 저장되어 있을 때 레코드의 키 값을
주면, 이 키 값을 어떤 수학적 함수에 의하여 테이블 주소 로 변환 시켜 원하는 레코드를 탐색하는 것 2) 자주 사용되는 해싱함수들 나눗셈 방법 폴딩(folding) 방법 중간제곱 방법 자릿수 분석(digit analysis) 방법 기수 변환(radix transformation) 방법 3) 충돌 해결 방법 개방주소(open addressing) 방법 2차 탐사(quadratic probing) 방법 체이닝(chaining) 방법
 자주 사용되는 해싱함수들. 나눗셈 방법. 폴딩(folding) 방법. 중간제곱 방법. 자릿수 분석(digit analysis) 방법. 기수 변환(radix transformation) 방법. 3) 충돌 해결 방법. 개방주소(open addressing) 방법. 2차 탐사(quadratic probing) 방법. 체이닝(chaining) 방법.")
70
3.1 분할 및 정복(Divide & Conquer)의 개념
Divide_Conquer(int p, int q) int m; // 1 <= p <= q <= n { if small(p, q) return (G(p, q)); else { m = Divide(p, q); // p <= m < q return(Combine(Divide_Conquer(p, m), Divide_Conquer(m + 1, q); }
 int m; // 1 <= p <= q <= n. { if small(p, q) return (G(p, q)); else { m = Divide(p, q); // p <= m < q. return(Combine(Divide_Conquer(p, m), Divide_Conquer(m + 1, q); }")
71
3.2 Binary search 분할 및 정복에 의한 이진탐색 방법 1) 분할 과정
탐색대상의 정렬된 1차원 배열을 같은 크기의 두 부분으로 나눈다. 만약 x가 배열의 가운데에 있는 원소보다 적으면, 배열의 왼쪽 전반부분을 다음 번 탐색부분으로 택한다. 만약 x가 배열의 가운데에 있는 원소보다 크면 배열의 오른쪽 후반부분을 다음 번 탐색부분으로 택한다. 2) 정복 과정 배열의 분할된 부분에 x가 있는지의 여부를 결정한다. 배열의 분할된 부분이 충분히 적은 크기가 아니면, 분할 및 정복 과정을 되풀이 한다. 위의 정복 과정에서 얻어진 결과를 해답으로 한다.
 정복 과정. 배열의 분할된 부분에 x가 있는지의 여부를 결정한다. 배열의 분할된 부분이 충분히 적은 크기가 아니면, 분할 및 정복 과정을 되풀이 한다. 위의 정복 과정에서 얻어진 결과를 해답으로 한다.")
72
알고리즘 3.1 : 이진탐색 알고리즘 (순환적 알고리즘) 문제 : n개의 키들로 구성된 오름차순으로 정렬된 리스트 A에서
보기 3.1 알고리즘 3.1 : 이진탐색 알고리즘 (순환적 알고리즘) 문제 : n개의 키들로 구성된 오름차순으로 정렬된 리스트 A에서 어떤 주어진 키 x가 A에 있는가를 결정하시오. 입력 : 자연수n, 인덱스가 1부터 n까지 인덱스된 n개의 원소(키)로 구성된 오름차순으로 정렬된 리스트 A, 그리고 탐색 대상 인 키 x 출력 : x의 A에서의 위치를 나타내는 position 만약 x가 A에 없으면 0
 문제 : n개의 키들로 구성된 오름차순으로 정렬된 리스트 A에서. 어떤 주어진 키 x가 A에 있는가를 결정하시오. 입력 : 자연수n, 인덱스가 1부터 n까지 인덱스된 n개의 원소(키)로. 구성된 오름차순으로 정렬된 리스트 A, 그리고 탐색 대상. 인 키 x. 출력 : x의 A에서의 위치를 나타내는 position. 만약 x가 A에 없으면 0.")
73
index position (index low, index high)
{ index middle; if (low > high) return 0; else { middle = (low + high)/2 ; if (x == A[middle]) return middle; else if (x < A[middle]) return position(low,middle-1); else return position(middle + 1, high); }
 return 0; else { middle = (low + high)/2 ; if (x == A[middle]) return middle; else if (x < A[middle]) return position(low,middle-1); else return position(middle + 1, high); }")
74
3.3 Strassen의 행렬식 곱셈 알고리즘 B11 B22 B21 B12 C11 C22 C21 C12 A11 A22 A21
보기 3.2 B11 B22 B21 B12 C11 C22 C21 C12 A11 A22 A21 A12 n/2 그림 3.1 Strassen 방법을 사용할 때 행렬의 분할 보기 3.3 C11 C22 C21 C12 2 C 그림 3.2 n = 4일때의 Strassen 방법의 사용을 위한 행렬 분할

75
compute C = A B using the standard algorithm; else {
알고리즘 3.2 : 두 개의 n * n 정방행렬에 대한 곱셈 알고리즘 문제 : n이 2의 지수일 때, 두 개의 n * n 정방행렬의 곱셈을 구하시오. 입력 : 2의 지수인 자연수 n 및 두 개의 n * n 정방행렬 A와 B 출력 : A와 B를 곱한 결과의 행렬식 C void strassen (int n, nn_matrix A, nn_matrix B, nn_matrix& C) { if (n <= threshold) compute C = A B using the standard algorithm; else { partition A into four submatrices A11, A12, A21, A22; partition B into four submatrices B11, B12, B21, B22; compute C = A B using Strassen’s method; // example recursive call; strassen (n/2, A11 + A22 + B11 + B22, , T1) }
 { if (n <= threshold) compute C = A B using the standard algorithm; else { partition A into four submatrices A11, A12, A21, A22; partition B into four submatrices B11, B12, B21, B22; compute C = A B using Strassen’s method; // example recursive call; strassen (n/2, A11 + A22 + B11 + B22, , T1) }")
76
3.4 최대값 및 최소값 문제 void seq_maxmin (int max, int min) { int i, n;
3.4 최대값 및 최소값 문제 알고리즘 3.3 : 최대값 및 최소값 알고리즘 문제 : 1차원배열(리스트)에서 최소값 및 최대값을 구하시오. 입력 : 자연수 n 및 1차원 배열(리스트) A 출력 : A의 최소값 min 및 최대값 max void seq_maxmin (int max, int min) { int i, n; max = A[1]; min = A[1]; for (i = 2; i <= n; i++) { if (A[i] > max) max = A[i]; if (A[i] < min) min = A[i]; }
에서 최소값 및 최대값을 구하시오. 입력 : 자연수 n 및 1차원 배열(리스트) A. 출력 : A의 최소값 min 및 최대값 max. void seq_maxmin (int max, int min) { int i, n; max = A[1]; min = A[1]; for (i = 2; i <= n; i++) { if (A[i] > max) max = A[i]; if (A[i] < min) min = A[i]; }")
77
max_min (int i, int j, int tmax, int tmin) // 1 ≤i ≤j ≤n
알고리즘 3.4 : 1차원 배열(리스트)에서 최대값 및 최소값 문제 : n개의 정수 원소로서 구성된 1차원배열(리스트)에서 최소값 및 최대값을 구하시오. 입력 : 자연수 n 및 n개의 정수 원소들로 구성된1차원 배열 A 출력 : A에서의 최소값 min 및 최대값 max max_min (int i, int j, int tmax, int tmin) // 1 ≤i ≤j ≤n // tmax is the largest element in A[i,j] // tmin is the smallest element in A[i,j] { int gmax, gmin, hmax, hmin, middle; if (i == j) { tmin = A[i]; tmax = A[i]; }
에서 최대값 및 최소값. 문제 : n개의 정수 원소로서 구성된 1차원배열(리스트)에서. 최소값 및 최대값을 구하시오. 입력 : 자연수 n 및 n개의 정수 원소들로 구성된1차원 배열 A. 출력 : A에서의 최소값 min 및 최대값 max. max_min (int i, int j, int tmax, int tmin) // 1 ≤i ≤j ≤n. // tmax is the largest element in A[i,j] // tmin is the smallest element in A[i,j] { int gmax, gmin, hmax, hmin, middle; if (i == j) { tmin = A[i]; tmax = A[i]; }")
78
else if (i == j - 1) { if (A[i] < A[j] { tmax = A[j]; tmin = A[i]; } else { middle = (i + j)/2 ; max_min(i, middle, gmax, gmin); max_min(middle+1,j,hmax,hmin); tmax = maximum(gmax, hmax); tmin = minimum(gmin, hmin);
![else if (i == j - 1) { if (A[i] < A[j] { tmax = A[j]; tmin = A[i]; } else { middle = (i + j)/2 ;](http://slidesplayer.org/slide/14753381/90/images/78/else+if+%28i+%3D%3D+j+-+1%29+%7B+if+%28A%5Bi%5D+%3C+A%5Bj%5D+%7B+tmax+%3D+A%5Bj%5D%3B+tmin+%3D+A%5Bi%5D%3B+%7D+else+%7B+middle+%3D+%EF%83%AB+%28i+%2B+j%29%2F2+%EF%83%BB+%3B.jpg "max_min(i, middle, gmax, gmin); max_min(middle+1,j,hmax,hmin); tmax = maximum(gmax, hmax); tmin = minimum(gmin, hmin);")
79
보기 3.4 1 9 5 4 3 2 16 8 11 7 6 18 A : 인덱스 원소의 값 (6, 9, 18, 8) (1, 5, 9, 0) (1, 9, 18, 10) (1, 3, 9, 2) (4, 5, 5, 0) (6, 7, 18, 8) (8, 9, 16, 11) (3, 3,2,2) (1, 2, 9, 3) 9 4 3 2 1 6 5 8 7 그림 3.4
 (1, 3, 9, 2) (4, 5, 5, 0) (6, 7, 18, 8) (8, 9, 16, 11) (3, 3,2,2) (1, 2, 9, 3) 그림 3.4.")
80
3.5 합병정렬(merge sort) n개의 원소들로 구성된 1차원 배열을 분할 및 정복에 의한 방법으로 합병정렬을 수행할 때는 다음 세 단계를 거친다. 1) 분할단계(divide step) 주어진 크기가 n인 1차원 배열을 크기가 각각 n/2인 부분 배열로 분할한다. 2) 정복단계(conquer step) 분할된 부분배열들을 정렬시킨다. 분할된 부분배열에 대하여 정렬이 쉽게 이루어지지 않으면 분할 및 정복 단계를 순환적으로 계속 수행한다. 3) 결합단계(combine step) 정렬된 부분배열들을 결합하여 크기가 두 배인 새로운 단일배열을 얻는다.
 정복단계(conquer step) 분할된 부분배열들을 정렬시킨다. 분할된 부분배열에 대하여 정렬이 쉽게 이루어지지 않으면 분할 및 정복 단계를 순환적으로 계속 수행한다. 3) 결합단계(combine step) 정렬된 부분배열들을 결합하여 크기가 두 배인 새로운 단일배열을 얻는다.")
81
보기 3.5 [36, 2, 3, 15, 32, 4, 10, 30] [32] [4] [32, 4] [4, 32] [10] [30] [10, 30] [32, 4, 10, 30] [4, 10, 30, 32] [36] [2] [36, 2] [2, 36] [3] [15] [3, 15] [36, 2, 3, 15] [2, 3, 15, 36] [2, 3, 4, 10, 15, 30, 32, 36] (divide) (merge) 그림 3.5
![보기 3.5 [36, 2, 3, 15, 32, 4, 10, 30] [32] [4] [32, 4] [4, 32] [10] [30] [10, 30] [32, 4, 10, 30]](http://slidesplayer.org/slide/14753381/90/images/81/%EB%B3%B4%EA%B8%B0+3.5+%5B36%2C+2%2C+3%2C+15%2C+32%2C+4%2C+10%2C+30%5D+%5B32%5D+%5B4%5D+%5B32%2C+4%5D+%5B4%2C+32%5D+%5B10%5D+%5B30%5D+%5B10%2C+30%5D+%5B32%2C+4%2C+10%2C+30%5D.jpg "[4, 10, 30, 32] [36] [2] [36, 2] [2, 36] [3] [15] [3, 15] [36, 2, 3, 15] [2, 3, 15, 36] [2, 3, 4, 10, 15, 30, 32, 36] (divide) (merge) 그림 3.5.")
82
void mergesort (int n, keytype A[]) { const int h = n/2 , m = n - h;
알고리즘 3.5 : 합병정렬 알고리즘 문제 : n개의 키들로 구성된 1차원 배열 A의 원소들을 오름차순 으로 정렬하시오. 입력 : 자연수 n 및 1에서 n까지 인덱스 된 1차원 배열 A 출력 : 오름차순으로 정렬된 배열 A void mergesort (int n, keytype A[]) { const int h = n/2 , m = n - h; keytype S[1..h], T[1..m]; if (n > 1) { copy A[1] through A[h] to S[1] through S[h]; copy A[h+1] through A[n] to T[1] through T[m]; mergesort(h, S); mergesort(m, T); merge(h, m, S, T, A); }
![void mergesort (int n, keytype A[]) { const int h = n/2 , m = n - h;](http://slidesplayer.org/slide/14753381/90/images/82/void+mergesort+%28int+n%2C+keytype+A%5B%5D%29+%7B+const+int+h+%3D+n%2F2+%2C+m+%3D+n+-+h%3B.jpg "알고리즘 3.5 : 합병정렬 알고리즘. 문제 : n개의 키들로 구성된 1차원 배열 A의 원소들을 오름차순. 으로 정렬하시오. 입력 : 자연수 n 및 1에서 n까지 인덱스 된 1차원 배열 A. 출력 : 오름차순으로 정렬된 배열 A. void mergesort (int n, keytype A[]) { const int h = n/2 , m = n - h; keytype S[1..h], T[1..m]; if (n > 1) { copy A[1] through A[h] to S[1] through S[h]; copy A[h+1] through A[n] to T[1] through T[m]; mergesort(h, S); mergesort(m, T); merge(h, m, S, T, A); }")
83
알고리즘 3.6 : 정렬된 배열들을 합치는 알고리즘 문제 : 이미 정렬된 두 개의 1차원 배열들을 하나의 정렬된 1차원 배열로 합병시키시오. 입력 : 자연수 h 및 m, 그리고 1에서 h까지로 인덱스된 정렬된 1차원 배열 S 및 1에서 m까지로 인덱스된 정렬된 1차원 배열 T 출력 : S 및 T의 키들을 하나로 합병하여 1에서 h + m개의 키들이 있는 새로 정렬된 1차원 배열 A

84
void merge(int h, int m, const keytype S[],
const keytype T[], keytype A[]) index i, j, k; i = 1; j = 1; k = 1; while (i <= h && j <= m) { if (S[i] < T[j]) { A[k] = S[i]; i++; } else { A[k] = T[j]; j++; k++ if (i > h) copy T[j] through T[m] to A[k] through A[h+m]; else copy S[i] through S[h] to A[k] through A[h+m];
![void merge(int h, int m, const keytype S[],](http://slidesplayer.org/slide/14753381/90/images/84/void+merge%28int+h%2C+int+m%2C+const+keytype+S%5B%5D%2C.jpg "const keytype T[], keytype A[]) index i, j, k; i = 1; j = 1; k = 1; while (i <= h && j <= m) { if (S[i] < T[j]) { A[k] = S[i]; i++; } else { A[k] = T[j]; j++; k++ if (i > h) copy T[j] through T[m] to A[k] through A[h+m]; else copy S[i] through S[h] to A[k] through A[h+m];")
85
보기 3.6 [2, 3, 15, 36] [4, 10, 30, 32] [2, 3, 4, 10, 15, 30, 32] [2, 3, 15, 36] [4, 10, 30, 32] [2, 3, 4, 10, 15, 30] [2, 3, 15, 36] [4, 10, 30, 32] [2, 3, 4, 10, 15, 30, 32, 36] [2, 3, 15, 36] [4, 10, 30, 32] [2, 3, 4, 10, 15] [2, 3, 15, 36] [4, 10, 30, 32] [2, 3, 4, 10] [2, 3, 15, 36] [4, 10, 30, 32] [2, 3, 4] [2, 3, 15, 36] [4, 10, 30, 32] [2, 3] [2, 3, 15, 36] [4, 10, 30, 32] [2] k S T A 그림 3.6
![보기 [2, 3, 15, 36] [4, 10, 30, 32] [2, 3, 4, 10, 15, 30, 32] 6 [2, 3, 15, 36] [4, 10, 30, 32]](http://slidesplayer.org/slide/14753381/90/images/85/%EB%B3%B4%EA%B8%B0+%5B2%2C+3%2C+15%2C+36%5D+%5B4%2C+10%2C+30%2C+32%5D+%5B2%2C+3%2C+4%2C+10%2C+15%2C+30%2C+32%5D+6+%5B2%2C+3%2C+15%2C+36%5D+%5B4%2C+10%2C+30%2C+32%5D.jpg "[2, 3, 4, 10, 15, 30] - [2, 3, 15, 36] [4, 10, 30, 32] [2, 3, 4, 10, 15, 30, 32, 36] 5 [2, 3, 15, 36] [4, 10, 30, 32] [2, 3, 4, 10, 15] 4 [2, 3, 15, 36] [4, 10, 30, 32] [2, 3, 4, 10] 3 [2, 3, 15, 36] [4, 10, 30, 32] [2, 3, 4] 2 [2, 3, 15, 36] [4, 10, 30, 32] [2, 3] 1 [2, 3, 15, 36] [4, 10, 30, 32] [2] k S T A. 그림 3.6.")
86
void new_mergesort (index low, index high) { index mid;
문제 : n개의 키들로 구성된 1차원 배열(리스트) A의 원소들을 오름차순으로 정렬하시오. 입력 : 자연수 n 및 1에서 n까지 인덱스된 1차원 배열 A 출력 : 오름차순으로 정렬된 배열 A void new_mergesort (index low, index high) { index mid; if (low < high) { mid = (low + high)/2 ; new_mergesort(low, mid); new_mergesort(mid+1, high); new_mergesort(low, mid, high); }
 A의 원소들을. 오름차순으로 정렬하시오. 입력 : 자연수 n 및 1에서 n까지 인덱스된 1차원 배열 A. 출력 : 오름차순으로 정렬된 배열 A. void new_mergesort (index low, index high) { index mid; if (low < high) { mid = (low + high)/2 ; new_mergesort(low, mid); new_mergesort(mid+1, high); new_mergesort(low, mid, high); }")
87
알고리즘 3.8 : new_mergesort에서 사용되는 새로운 합병
문제 : 알고리즘 new_mergesort에서 얻어진 2개의 정렬된 A의 부분 배열들을 정렬하여 하나의 배열로 합병하시오. 입력 : 세 개의 인덱스 변수 low, mid, high 및 low에서 high로 인덱스된 배열 A의 부분배열 인덱스가 low에서 mid 까지인 부분배열 및 mid + 1에서 high까지 인덱스된 부분배열은 이미 정렬되었다. 출력 : 인덱스가 low에서 high까지인 배열 A의 정렬된 부분배열

88
void new_merge (index low, index mid, index high)
{ index i, j, k; keytype S[low..high]; // local array needed for the merging i = low; j = mid + 1; k = low; while (i <= mid && j <= high) { if (A[i] < A[j]) { S[k] = A[i]; i++; } else { S[k] = A[j]; j++; k++; if (i > mid) move A[j] through A[high] to S[k] through S[high]; else move A[i] through A[mid] to S[k] through S[high]; move S[low] through S[high] to A[low] through A[high];
 { if (A[i] < A[j]) { S[k] = A[i]; i++; } else { S[k] = A[j]; j++; k++; if (i > mid) move A[j] through A[high] to S[k] through S[high]; else move A[i] through A[mid] to S[k] through S[high]; move S[low] through S[high] to A[low] through A[high];")
89
3.6 퀵 정렬 (quick sort) void quicksort (index low, index high) {
알고리즘 3.9 : 퀵 정렬 알고리즘 문제 : n개의 원소들로 구성된 1차원 배열 A를 오름차순으로 정렬하시오. 입력 : 자연수 n 및 1에서 n까지 인덱스된 배열 A 출력 : 오름차순으로 정렬된 1차원 배열 A void quicksort (index low, index high) { index pivotpoint; if (high > low) { partition(low, high, pivotpoint); quicksort(low, pivotpoint - 1); quicksort(pivotpoint + 1, high); }
 { index pivotpoint; if (high > low) { partition(low, high, pivotpoint); quicksort(low, pivotpoint - 1); quicksort(pivotpoint + 1, high); }")
90
편의상, A에 대한 피봇을 A의 첫번째 원소 10으로 한다면, 퀵 정렬방법에 의한 과정은 다음과 같다.
보기 3.7 주어진 1차원 배열 A = [10, 30, 4, 36, 3, 2, 15, 32]를 알고리즘 3.9에 의해 오름차순으로 정렬하고자 한다. 편의상, A에 대한 피봇을 A의 첫번째 원소 10으로 한다면, 퀵 정렬방법에 의한 과정은 다음과 같다. 1) 배열 A를 피봇 10보다 적은 원소들로 구성된 부분행렬과 피봇 10보다 큰 부분행렬로 다음과 같이 분할한다. 2) 분할된 부분배열들을 오름차순으로 정렬한다. 피봇보다 적은 원소들 피봇보다 큰 피봇원소 피봇원소 정렬됨
 배열 A를 피봇 10보다 적은 원소들로 구성된 부분행렬과 피봇 10보다 큰 부분행렬로 다음과 같이 분할한다 ) 분할된 부분배열들을 오름차순으로 정렬한다 피봇보다 적은. 원소들. 피봇보다 큰. 피봇원소. 피봇원소. 정렬됨.")
91
알고리즘 3.10 : 분할(partition) 알고리즘
문제 : 배열 A를 프로시저 quicksort에서 사용되는 두 개의 부분배열 로 분할하시오. 입력 : 두 개의 인덱스 변수 low 및 high, 그리고 low에서 high까지 인덱스된 A의 부분배열 출력 : 인덱스 low에서 high까지 인덱스된 부분배열에 대한 피봇 위치를 나타내는 pivotpoint

92
void partition (index low, index high, index& pivotpoint)
{ index I, j; keytype pivotitem; pivotitem = A[low]; // Choose first item for pivotitem j = low; for (I = low + 1; I <= high; I++) if (A[I] < pivotitem) { j++; exchange A[I] and A[j]; } pivotpoint = j; exchange A[low] and A[pivotpoint]; //Put pivotitem at pivotpoint
 if (A[I] < pivotitem) { j++; exchange A[I] and A[j]; } pivotpoint = j; exchange A[low] and A[pivotpoint]; //Put pivotitem at pivotpoint.")
93
i j A[1] A[2] A[3] A[4] A[5] A[6] A[7] A[8]
보기 3.8 i j A[1] A[2] A[3] A[4] A[5] A[6] A[7] A[8] 초기치 결과 그림 3.7
![i j A[1] A[2] A[3] A[4] A[5] A[6] A[7] A[8]](http://slidesplayer.org/slide/14753381/90/images/93/i+j+A%5B1%5D+A%5B2%5D+A%5B3%5D+A%5B4%5D+A%5B5%5D+A%5B6%5D+A%5B7%5D+A%5B8%5D.jpg "보기 3.8. i j A[1] A[2] A[3] A[4] A[5] A[6] A[7] A[8] 초기치. 결과. 그림 3.7.")
94
보기 3.9 15 32 3 10(피봇) 2 4 10 30 36 그림 3.8
 그림 3.8.")
95
제 4 장 탐욕적 방법(Greedy Method)
4.1 탐욕적 방법의 소개 4.2 단일출발점에서의 최단경로 문제 4.3 배낭 문제 4.4 최소 신장트리 4.5 연습문제

96
4.1 탐욕적 방법의 소개 * 탐욕적 방법으로 알고리즘을 설계하는 과정
4.1 탐욕적 방법의 소개 * 탐욕적 방법으로 알고리즘을 설계하는 과정 - 선택절차(selection procedure) : 해답집합에 포함시킬 것을 선택한다. 선택기준은 지금까지의 과거 및 앞으로의 미래를 고려하지 않고 지금 스텝에서만 국부적으로 가장 옳다고 생각되는 것 하나를 선택한다. - 타당성 조사(feasibility chech) : 방금 선택된 것을 해답집합에 포함시키는 것이 과연 타당한지를 조사한다. - 해답조사(solution check) : 새로운 항목이 포함되어 새로이 구성된 해답집합이 과연 문제의 해답에 대한 제반 조건들을 만족하느냐를 조사한다.
 : 해답집합에 포함시킬 것을 선택한다. 선택기준은 지금까지의 과거 및 앞으로의 미래를 고려하지 않고 지금 스텝에서만 국부적으로 가장 옳다고 생각되는 것 하나를 선택한다. - 타당성 조사(feasibility chech) : 방금 선택된 것을 해답집합에 포함시키는 것이 과연 타당한지를 조사한다. - 해답조사(solution check) : 새로운 항목이 포함되어 새로이 구성된 해답집합이 과연 문제의 해답에 대한 제반 조건들을 만족하느냐를 조사한다.")
97
while (there are more coins and the instance is not solved) {
/* 갑돌이의 거스름 돈 지불문제 (탐욕적 방법) */ while (there are more coins and the instance is not solved) { grab the largest remaining coin; // selection procedure fesibility check if (adding the coin makes the change exceed the amount owed) reject the coin; else add the coin to the change; if (the total value of the change equals the amount owed) // solution check the instance is solved; }
 */ while (there are more coins and the instance is not solved) { grab the largest remaining coin; // selection procedure fesibility check. if (adding the coin makes the change exceed the. amount owed) reject the coin; else. add the coin to the change; if (the total value of the change equals the amount owed) // solution check. the instance is solved; }")
98
500 100 10 50 갑돌이가 처음 갖고 있는 동전 : 손님에게 주어야 되는 돈 : 610원 거스름 돈
1단계 : 500원짜리 동전을 선택 2단계 : 100원짜리 동전을 선택 5단계 : 10원짜리 동전을 선택 4단계 : 50원짜리 동전을 배제 (위와 같은 이유) 3단계 : 두 번째의 100원 동전을 배제 ( ∵두 번째의 100원 동전을 거스름 돈에 포함시키면, 손님에게 주어야 될 돈을 초과하므로) 100 10 50 그림 4.1 거스름 돈
 3단계 : 두 번째의 100원 동전을 배제. ( ∵두 번째의 100원 동전을 거스름. 돈에 포함시키면, 손님에게 주어야. 될 돈을 초과하므로) 그림 4.1. 거스름 돈.")
99
120 100 50 10 10 10 10 갑돌이가 처음 갖고 있는 동전 : 손님에게 주어야 되는 돈 : 610원 거스름 돈 120 1단계 : 120원짜리 동전을 선택 120 100 2단계 : 100원짜리 동전을 배제 120 50 4단계 : 50원짜리 동전을 배제 120 10 10 10 10 5단계 : 10원짜리 동전을 선택 (최적의 거스름 돈은 100원 + 50원 + 10원 동전을 주는 것) 그림 4.2
 그림 4.2.")
100
4.2 단일 출발점에서의 최단경로 문제 (Dijkstra algorithm) V0 V2 V1 V3 V4 V5 G1 보기 4.1
4.2 단일 출발점에서의 최단경로 문제 (Dijkstra algorithm) 보기 4.1 V0 V2 V1 V3 V4 V5 10 20 45 50 15 3 30 35 G1 그림 4.3
 보기 4.1. V0. V2. V1. V3. V4. V G1. 그림 4.3.")
101
length(w) = minimum (length(w), length(u) + W(u,w))
S : 출발점으로부터의 최단경로가 이미 알려진 꼭지점들의 집합 V0 : 출발점 length(w) : w S일 때, 출발점 에서 S에 있는 꼭지점들만 방문하여 w로 가는 최단경로의 비용 W(u,w) : 꼭지점 u에서 w로 가는 edge에 부과된 비용 length(u)와 W(u,w)를 더한 결과를 length(w)와 비교(그림 4.4 참조) 경우 1) length(w) < length(u) + W(u,w) 인 경우 새로운 중간 경유지 u를 방문하는 것이 지금까지 알려진 최단 여행경로 보다 더 좋지 않은 경우이므로 length(w)에는 아무 변화가 없다. 경우 2) length(u) + W9u,w) < length(w) 인 경우 새로운 중간 경유지 u를 방문하는 것이 지금까지 알려진 최단 여행경로 보다 더 좋은 경우이므로 length(w) = length(u) + W(u,w)로 변경한다. length(w) = minimum (length(w), length(u) + W(u,w))
 : w S일 때, 출발점 에서 S에 있는 꼭지점들만 방문하여. w로 가는 최단경로의 비용. W(u,w) : 꼭지점 u에서 w로 가는 edge에 부과된 비용. length(u)와 W(u,w)를 더한 결과를 length(w)와 비교(그림 4.4 참조) 경우 1) length(w) < length(u) + W(u,w) 인 경우. 새로운 중간 경유지 u를 방문하는 것이 지금까지 알려진 최단 여행경로 보다 더 좋지 않은 경우이므로 length(w)에는 아무 변화가 없다. 경우 2) length(u) + W9u,w) < length(w) 인 경우. 새로운 중간 경유지 u를 방문하는 것이 지금까지 알려진 최단 여행경로 보다 더 좋은 경우이므로 length(w) = length(u) + W(u,w)로 변경한다. length(w) = minimum (length(w), length(u) + W(u,w))")
102
W V0 U length(w) length(u) W(u,w) 그림 4.4
 length(u) W(u,w) 그림 4.4")
103
V0 V1 V2 V3 V4 * Dijkstra 알고리즘을 그림 4.5의 그래프에 적용한 보기
보기 4.2 V0 V1 V2 V3 V4 2 5 6 3 4 10 1 그림 4.5 * Dijkstra 알고리즘을 그림 4.5의 그래프에 적용한 보기 1단계 : 시작 꼭지점을 v0라 하자. S = {v0 }가 되며, v0 에서 각 꼭지점으로의 거리를 나타내는 변수 length의 값은 다음과 같이 얻어진다. Length(v0) = Length(v1) = 2 Length(v2) = Length(v3) = Length(v4) = 3
 = 0 Length(v1) = 2. Length(v2) = 5 Length(v3) = Length(v4) = 3.")
104
2단계 : 집합 S에 아직 속하지 않은 꼭지점 중에서 length(v1)이 가장 적은 값을 가지므로 v1을 선택하여 집합 S에 포함시킨다. (v0 는 이미 집합 S의 원소이므로 선택대상이 아니다.) 즉 S = {v0 ,v1}이 되며, v0 에서 각 꼭지점으로의 거리를 나타내는 length의 값은 다음과 같이 변경된다. Length(v0) = 0 Length(v1) = 2 Length(v2) = min(length(v2), length(v1) + w(v1,v2)) = min(5, 2+6) = 5 Length(v3) = min(length(v3), length(v1) + w(v1,v3)) = min( ,2+4) = 6 Length(v4) =min(length(v4), length(v1) + w(v1,v4)) = min(3, 2+10) = 3
 = 0. Length(v1) = 2. Length(v2) = min(length(v2), length(v1) + w(v1,v2)) = min(5, 2+6) = 5. Length(v3) = min(length(v3), length(v1) + w(v1,v3)) = min( ,2+4) = 6. Length(v4) =min(length(v4), length(v1) + w(v1,v4)) = min(3, 2+10) = 3.")
105
3단계 : 집합 S에 아직 속하지 않은 꼭지점 중에서 length(v4)가 가장 적은 값을 가지므로 v4를 선택하여 집합 S에 포함시킨다. 즉 S = {v0 ,v1 ,v4}가 되며, ,v0 에서 각 꼭지점으로의 거리를 나타내는 length의 값은 다음과 같이 구해진다. Length(v0) = 0 Length(v1) = 2 Length(v2) = min(length(v2), length(v4) + w(v4,v2)) = min(5, 3+1) = 4 Length(v3) = min(length(v3), length(v4) + w(v4,v3)) = min(6, 3+2) = 5 Length(v4) = 3
 = 0. Length(v1) = 2. Length(v2) = min(length(v2), length(v4) + w(v4,v2)) = min(5, 3+1) = 4. Length(v3) = min(length(v3), length(v4) + w(v4,v3)) = min(6, 3+2) = 5. Length(v4) = 3.")
106
4단계 : 집합 S에 아직 속하지 않은 꼭지점 중에서 length(v2)가 가장 적은 값을 가지므로 v2를 선택하여 집합 S에 포함시킨다. 즉 S = {v0 ,v1 ,v2 ,v4}가 되며, ,v0 에서 각 꼭지점으로의 거리를 나타내는 length의 값은 다음과 같이 구해진다. Length(v0) = 0 Length(v1) = 2 Length(v2) = 4 Length(v3) = min(length(v3), length(v2) + w(v2,v3)) = min(5, 4+6) = 5 Length(v4) = 3
 = 0. Length(v1) = 2. Length(v2) = 4. Length(v3) = min(length(v3), length(v2) + w(v2,v3)) = min(5, 4+6) = 5. Length(v4) = 3.")
107
5단계 : 집합 S에 아직 속하지 않은 꼭지점 중에서 length(v3)가 가장 적은 값을 가지므로 v3를 선택하여 집합 S에 포함시킨다. 즉 S = {v0 ,v1 ,v2 , v3 , v4}가 되며, ,v0 에서 각 꼭지점으로의 거리를 나타내는 length의 값은 다음과 같이 구해진다. Length(v0) = 0 Length(v1) = 2 Length(v2) = 4 Length(v3) = 5 Length(v4) = 3
 = 0. Length(v1) = 2. Length(v2) = 4. Length(v3) = 5. Length(v4) = 3.")
108
단계 집합 S 선택된 꼭지점 Length[ ]의 값 v v v v v4 {v0 } 1 {v0 ,v1} 2 v1 {v0 ,v1 ,v4} 3 v4 {v0 ,v1 ,v2 ,v4} 4 v2 {v0 ,v1 ,v2 , v3 , v4} 5 v3 그림 4.6
![단계 집합 S. 선택된. 꼭지점. Length[ ]의 값. v0 v1 v2 v3 v4. {v0 } 3.](http://slidesplayer.org/slide/14753381/90/images/108/%EB%8B%A8%EA%B3%84+%EC%A7%91%ED%95%A9+S.+%EC%84%A0%ED%83%9D%EB%90%9C.+%EA%BC%AD%EC%A7%80%EC%A0%90.+Length%5B+%5D%EC%9D%98+%EA%B0%92.+v0+v1+v2+v3+v4.+%7Bv0+%7D+%EF%82%A5+3..jpg "{v0 ,v1} 2. v {v0 ,v1 ,v4} 3. v {v0 ,v1 ,v2 ,v4} 4. v2. {v0 ,v1 ,v2 , v3 , v4} 5. v3. 그림 4.6.")
109
void dijkstra (int n, const number W[][], set_of_edges& F) {
문제 : edge들에 가중치가 있는 방향이 있는 그래프에서, 출발 꼭지점 v1 에서 나머지 모든 꼭지점들에 대한 최단경로를 구하시오. 입력 : 자연수 n과 n개의 꼭지점들이 있는 방향이 있는 그래프 G G의 edge들에는 가중치가 있다. W[i][j]는 꼭지점 vi에서 vj 로 가는 edge의 비용이다. 출력 : 최단경로에 있는 edge들의 집합 F void dijkstra (int n, const number W[][], set_of_edges& F) { index i, vnear; edge e; index touch[2..n]; number length[2..n];
![void dijkstra (int n, const number W[][], set_of_edges& F) {](http://slidesplayer.org/slide/14753381/90/images/109/void+dijkstra+%28int+n%2C+const+number+W%5B%5D%5B%5D%2C+set_of_edges%26+F%29+%7B.jpg "문제 : edge들에 가중치가 있는 방향이 있는 그래프에서, 출발 꼭지점 v1 에서 나머지 모든 꼭지점들에 대한 최단경로를 구하시오. 입력 : 자연수 n과 n개의 꼭지점들이 있는 방향이 있는 그래프 G. G의 edge들에는 가중치가 있다. W[i][j]는 꼭지점 vi에서 vj. 로 가는 edge의 비용이다. 출력 : 최단경로에 있는 edge들의 집합 F. void dijkstra (int n, const number W[][], set_of_edges& F) { index i, vnear; edge e; index touch[2..n]; number length[2..n];")
110
F = Ø; for (i = 2; i <= n; i++) // For all vertices, initialize v1 { // to be the last vertex on the touch[i] = 1; // current shortest path from length[i] = W[1][i]; // v1, and initialize length of } // that path to be the weight // on the edge from v1. repeat(n - 1 times) // Add all n-1 vertices to S. { min = ; for (i = 2; i <= n; i++) if (0 <= length[i] < min) min = length[i]; vnear = i; }
 // Add all n-1 vertices to S. { min = ; for (i = 2; i <= n; i++) if (0 <= length[i] < min) min = length[i]; vnear = i; }")
111
e = edge from vertex indexed by touch[vnear]
to vertex indexed by vnear; add e to F; for (i = 2; i <= n; i++) if (length[vnear] + W[vnear] [i] < length[i]) { length[i] = length[vnear] + W[vnear][i]; touch[i] = vnear; // For each vertex not in S, } // update its shortest path. length[vnear] = -1; // Add vertex indexed by } // vnear to S. }
![e = edge from vertex indexed by touch[vnear]](http://slidesplayer.org/slide/14753381/90/images/111/e+%3D+edge+from+vertex+indexed+by+touch%5Bvnear%5D.jpg "to vertex indexed by vnear; add e to F; for (i = 2; i <= n; i++) if (length[vnear] + W[vnear] [i] < length[i]) { length[i] = length[vnear] + W[vnear][i]; touch[i] = vnear; // For each vertex not in S, } // update its shortest path. length[vnear] = -1; // Add vertex indexed by. } // vnear to S. }")
112
4.3 배낭문제 (knapsack problem)
보기 4.3 다음과 같은 배낭문제를 생각하자. n = 3, M = 20, p1 = 25, p2 = 24, p3 = 15, w1 = 18, w2 = 15, w3 = 10 이 때 우리는 다음과 같은 네 가지 실행가능한 것들을 생각할 수 있다. 경우 (x1 , x2 , x3) wi xi pixi 1) 2) 3) 4) ( , , ) 16.5 24.25 20 28.2 31 31.5 1 3 2 4 ( 1 , , 0 ) 15 ( 0 , , 1 ) ( 0 , 1 , ) 최대이익
 wi xi pixi. 1) 2) 3) 4) ( , , ) ( 1 , , 0 ) 15. ( 0 , , 1 ) ( 0 , 1 , ) 최대이익.")
113
알고리즘 4.2 : 부분 배낭문제 알고리즘 문제 : 이익이 최대가 되도록 부분 배낭문제를 해결하시오. 입력 : 자연수 n (물건들의 개수), 물건들의 이익을 나타내는 배열 p, 물건들의 크기를 나타내는 배열 W, 배낭의 전체크기 M 출력 : 각 물건들을 얼마만큼 배낭에 넣는지를 나타내는 배열 X

114
void fractional_knapsack (int M, n, float W[], p[], X[]); {
float cu; // local variable to indicate the remaining knapsack capacity int i; for (i = 1; i <= n; i++) X[i] = 0; // initialize solution array to 0 cu = M; // cu = remaining knapsack capacity for (i = 1; i <= n; i++) { if (W[i] > cu) exit; X[i] = 1; cu = cu - W[i]; } if (i <= n) X[i] = cu / W[i];
![void fractional_knapsack (int M, n, float W[], p[], X[]); {](http://slidesplayer.org/slide/14753381/90/images/114/void+fractional_knapsack+%28int+M%2C+n%2C+float+W%5B%5D%2C+p%5B%5D%2C+X%5B%5D%29%3B+%7B.jpg "float cu; // local variable to indicate the remaining knapsack capacity. int i; for (i = 1; i <= n; i++) X[i] = 0; // initialize solution array to 0. cu = M; // cu = remaining knapsack capacity. for (i = 1; i <= n; i++) { if (W[i] > cu) exit; X[i] = 1; cu = cu - W[i]; } if (i <= n) X[i] = cu / W[i];")
115
정리 4.1 만약 p1/ w1 >= p2/ w2 >= … >= pn/ wn 일 때, 위의 알고리즘 fractional_knapsack은 부분 배낭문제에 대한 최적해를 제공한다. [증명] page 178 참조

116
4.4 최소 신장트리 (minimum spanning tree)
보기 4.4 그래프 G = ({A, B, C, D}, {(A, B), (A, D), (B, C), (B, D), (C, D)}) D A C B G 그림 4.7
, (A, D), (B, C), (B, D), (C, D)}) D. A. C. B. G. 그림 4.7.")
117
G에 대한 신장트리(spanning tree)들
B A C D 그림 4.8

118
V1 V5 V2 V4 V3 5 7 8 10 6 9 5 5 V1 V2 V1 V2 7 7 7 10 7 10 8 8 V3 V4 V3 V4 6 6 9 9 V5 V5 (a) 주어진 그래프 (b) 꼭지점 v1이 먼저 선택된다. Y = {v1, v2} (c) Y={v1}에 가장 가까운(edge의 가중치가 가장 적은) 꼭지점은 v2이므로 v2를 Y에 넣는다 Y = {v1, v2}
 주어진 그래프. (b) 꼭지점 v1이 먼저 선택된다. Y = {v1, v2} (c) Y={v1}에 가장 가까운(edge의 가중치가 가장 적은) 꼭지점은 v2이므로 v2를 Y에 넣는다 Y = {v1, v2}")
119
5 5 5 V1 V2 V1 V2 V1 V2 7 7 7 7 10 7 10 7 10 8 8 8 V3 V4 V3 V4 V3 V4 6 6 6 9 9 9 V5 V5 V5 (d) Y={v1, v2}에 가장 가까운 꼭지점이 v3이므로 v3를 Y에 넣는다 Y = {v1, v2 , v3} (e) Y={v1, v2 , v3}에 가장 가까운 꼭지점이 v5이므로 v5를 Y에 넣는다 Y = {v1, v2 , v3 , v5} (f) 마지막으로 v4가 선택된다.
 Y={v1, v2}에 가장 가까운 꼭지점이 v3이므로 v3를 Y에 넣는다 Y = {v1, v2 , v3} (e) Y={v1, v2 , v3}에 가장 가까운 꼭지점이 v5이므로 v5를 Y에 넣는다 Y = {v1, v2 , v3 , v5} (f) 마지막으로 v4가 선택된다.")
120
void prime (int n, const mumber W[][], set_of edges& F) {
문제 : 주어진 그래프에 대한 최소 신장 트리를 구하시오. 입력 : 자연수 n과 연결된 그래프 G = (V, E). G는 방향이 없는 그래프이며, 연결된 그래프이다. 이 그래프는 n * n 행렬식 W에 의해 표시되며, W[i][j]는 꼭지점 vi와 vj 사이의 edge에 대한 가중치(거리)이다. 출력 : 주어진 그래프 G에 대한 최소 신장 트리 void prime (int n, const mumber W[][], set_of edges& F) { index i, vnear; number min; edge e; index nearest[2..n]; number distance[2..n];
![void prime (int n, const mumber W[][], set_of edges& F) {](http://slidesplayer.org/slide/14753381/90/images/120/void+prime+%28int+n%2C+const+mumber+W%5B%5D%5B%5D%2C+set_of+edges%26+F%29+%7B.jpg "문제 : 주어진 그래프에 대한 최소 신장 트리를 구하시오. 입력 : 자연수 n과 연결된 그래프 G = (V, E). G는 방향이 없는 그래프이며, 연결된 그래프이다. 이 그래프는 n * n 행렬식 W에 의해 표시되며, W[i][j]는. 꼭지점 vi와 vj 사이의 edge에 대한 가중치(거리)이다. 출력 : 주어진 그래프 G에 대한 최소 신장 트리. void prime (int n, const mumber W[][], set_of edges& F) { index i, vnear; number min; edge e; index nearest[2..n]; number distance[2..n];")
121
F = ; for (i = 2; i <= n; i++) { nearest[i] = 1; // For all vertices, initialize v1 distance[i] = W[1][i]; // to be the nearest vertex in } // Y and initialize the distance // from Y to be the weight // on the edge to v1. repeat (n-1 times) // Add all n-1 vertices to Y. min = ; for (i = 2; i <= n; i++) // Check each vertex for if (0 <= distance[i] < min) // being nearest to Y. min = distance[i]; vnear = i; }
![F = ; for (i = 2; i <= n; i++) { nearest[i] = 1; // For all vertices, initialize v1. distance[i] = W[1][i]; // to be the nearest vertex in.](http://slidesplayer.org/slide/14753381/90/images/121/F+%3D+%EF%81%A6%3B+for+%28i+%3D+2%3B+i+%3C%3D+n%3B+i%2B%2B%29+%7B+nearest%5Bi%5D+%3D+1%3B+%2F%2F+For+all+vertices%2C+initialize+v1.+distance%5Bi%5D+%3D+W%5B1%5D%5Bi%5D%3B+%2F%2F+to+be+the+nearest+vertex+in..jpg "} // Y and initialize the distance. // from Y to be the weight. // on the edge to v1. repeat (n-1 times) // Add all n-1 vertices to Y. min = ; for (i = 2; i <= n; i++) // Check each vertex for. if (0 <= distance[i] < min) // being nearest to Y. min = distance[i]; vnear = i; }")
122
e = edge connecting vertices indexed by vnear
and nearest[vnear]; add e to F; distance[vnear] = -1; //Add vertex indexed by for (i = 2; i <= n; i++) // vnear to Y. if (W[i][vnear] < distance[i]) { // For each vertex not in Y. distance[i] = W[i][vnear]; // update its distance from Y. nearest[i] = vnear; }
 // vnear to Y. if (W[i][vnear] < distance[i]) { // For each vertex not in Y. distance[i] = W[i][vnear]; // update its distance from Y. nearest[i] = vnear; }")
123
V1 V5 V2 V4 V3 3 5 6 8 4 7 그림 4.10

124
[ 증명 ] F는 유망한 edge들의 집합이므로, 다음 두 조건을 만족하는 edge들의 집합 F가 존재한다.
정리 4.2 G = ( V, E)가 방향이 없는 연결된 그래프이며, edge들에 가중치가 있다고 하자. 그리고 F E를 유망한 edge들의 집합, Y를 F에 있는 edge들에 의해 연결된 꼭지점들의 집합이라고 하자. E가 Y에 있는 어떤 꼭지점을 V - Y에 있는 꼭지점에 연결시키는 최소 가중치의 edge라고 하면, F {e}는 유망한 edge들의 집합이다. [ 증명 ] F는 유망한 edge들의 집합이므로, 다음 두 조건을 만족하는 edge들의 집합 F가 존재한다. 1) F F 2) (V, F)는 최소 신장 트리
![[ 증명 ] F는 유망한 edge들의 집합이므로, 다음 두 조건을 만족하는 edge들의 집합 F가 존재한다.](http://slidesplayer.org/slide/14753381/90/images/124/%5B+%EC%A6%9D%EB%AA%85+%5D+F%EB%8A%94+%EC%9C%A0%EB%A7%9D%ED%95%9C+edge%EB%93%A4%EC%9D%98+%EC%A7%91%ED%95%A9%EC%9D%B4%EB%AF%80%EB%A1%9C%2C+%EB%8B%A4%EC%9D%8C+%EB%91%90+%EC%A1%B0%EA%B1%B4%EC%9D%84+%EB%A7%8C%EC%A1%B1%ED%95%98%EB%8A%94+edge%EB%93%A4%EC%9D%98+%EC%A7%91%ED%95%A9+F%EF%82%A2%EA%B0%80+%EC%A1%B4%EC%9E%AC%ED%95%9C%EB%8B%A4..jpg "정리 4.2. G = ( V, E)가 방향이 없는 연결된 그래프이며, edge들에 가중치가 있다고 하자. 그리고 F E를 유망한 edge들의 집합, Y를 F에 있는 edge들에 의해 연결된 꼭지점들의 집합이라고 하자. E가 Y에 있는 어떤 꼭지점을 V - Y에 있는 꼭지점에 연결시키는 최소 가중치의 edge라고 하면, F {e}는 유망한 edge들의 집합이다. [ 증명 ] F는 유망한 edge들의 집합이므로, 다음 두 조건을 만족하는 edge들의 집합 F가 존재한다. 1) F F 2) (V, F)는 최소 신장 트리.")
125
V1 V5 V2 V4 V3 1 3 7 2 4 5 V-Y Y e e 그림 정리 4.2에서 이해를 돕기 위한 그림

126
Prim의 알고리즘은 항상 최소 신장트리를 얻게 된다.
정리 4.3 Prim의 알고리즘은 항상 최소 신장트리를 얻게 된다. [ 증명 ] 우리는 repeat 루프를 매번 수행할 때마다, 집합 F가 유망한 edge들의 집합인 사실을 다음과 같이 수학적 귀납법에 의해 증명한다. (1단계 : 기초단계) 확실히 공집합 은 유망한 edge들의 집합이다. (2단계 : 가설단계) repeat 루프를 몇 번인가 수행한 다음 지금까지 선택된 edge들의 집합 F가 유망한 edge들의 집합이라고 가정하자. (3단계 : 유도단계) 다음 번 repeat 루프를 수행할 때 선택되는 edge e는 Y에 있는 꼭지점과 V-Y에 있는 꼭지점과를 연결하는 최소 가중치의 edge이므로, 위의 정리 4.2에 의하여 F {e}도 유명한 edge들의 집합이다. 위의 모든 단계에서 증명이 되었으므로, edge들의 마지막 집합 역시 유명한 edge들의 집합이고, 이 집합은 신장트리의 edge들로 구성되었으므로, 이 트리는 최소 신장트리이다.
 확실히 공집합 은 유망한 edge들의 집합이다. (2단계 : 가설단계) repeat 루프를 몇 번인가 수행한 다음 지금까지 선택된 edge들의 집합 F가 유망한 edge들의 집합이라고 가정하자. (3단계 : 유도단계) 다음 번 repeat 루프를 수행할 때 선택되는 edge e는 Y에 있는 꼭지점과 V-Y에 있는 꼭지점과를 연결하는 최소 가중치의 edge이므로, 위의 정리 4.2에 의하여 F {e}도 유명한 edge들의 집합이다. 위의 모든 단계에서 증명이 되었으므로, edge들의 마지막 집합 역시 유명한 edge들의 집합이고, 이 집합은 신장트리의 edge들로 구성되었으므로, 이 트리는 최소 신장트리이다.")
127
void kruksal (int n, int m, set_of_edges E, set_of_edges& F) {
문제 : 주어진 그래프에 대한 최소 신장트리를 구하시오. 입력 : 자연수 n과 연결된 그래프 G = (V, E) G는 방향이 없는 그래프이며, 연결된 그래프이다. 이 그래프는 n * n 행렬식 W에 의해 표시되며, W[i][j]는 꼭지점 vi와 vj 사이의 edge에 대한 가중치(거리)이다. 출력 : 주어진 그래프 G에 대한 최소 신장트리 void kruksal (int n, int m, set_of_edges E, set_of_edges& F) { index i, j; set_pointer p, q; edge e;
 G는 방향이 없는 그래프이며, 연결된 그래프이다. 이 그래프는 n * n 행렬식 W에 의해 표시되며, W[i][j]는. 꼭지점 vi와 vj 사이의 edge에 대한 가중치(거리)이다. 출력 : 주어진 그래프 G에 대한 최소 신장트리. void kruksal (int n, int m, set_of_edges E, set_of_edges& F) { index i, j; set_pointer p, q; edge e;")
128
Sort the m edges in E by weight in nondecreasing order;
F = ; initial(n); // Initialize n disjoint subsets. while (number of edges in F is less than n - 1) { e = edge with least weight not yet considered; i, j = indices of vertices connected by e; p = find(i); q = find(j); if (!equal(p, q)) { merge(p, q); add e to F; }
; // Initialize n disjoint subsets. while (number of edges in F is less than n - 1) { e = edge with least weight not yet considered; i, j = indices of vertices connected by e; p = find(i); q = find(j); if (!equal(p, q)) { merge(p, q); add e to F; }")
129
보기 4.5 V2 V6 V3 V5 V4 1 2 9 3 8 7 V1 4 5 G (a) (b) 그림 4.12
 (b) 그림 4.12")
130
(원래 그래프에 6개의 꼭지점이 있는데 F에 5개의 에지가 생겼으므로 알고리즘 중단)
그림 4.13 (원래 그래프에 6개의 꼭지점이 있는데 F에 5개의 에지가 생겼으므로 알고리즘 중단) V2 V3 V4 V5 1 2 단계 선택된 에지 에지의 비용 에지의 F에 추가 여부 F 초기 . (v2, v3) 추가 (v2, v4) (v3, v5) 3 3
 V2. V3. V4. V 단계. 선택된. 에지. 에지의. 비용. 에지의 F에. 추가 여부. F. 초기. . (v2, v3) 추가. (v2, v4) (v3, v5)")
131
(∵ v1과 v3를 연결하면 사이클이 형성되므로)
4 1 2 4 (v1, v2) 4 추가 3 무시 (∵ v1과 v3를 연결하면 사이클이 형성되므로) V1 V2 V3 V4 V5 4 1 2 5 (v1, v3) 5 3 V1 V2 V3 V4 V5 V6 4 1 2 3 7 6 (v5, v6) 7 추가
 4. 추가. 3. 무시. (∵ v1과 v3를 연결하면 사이클이 형성되므로) V1. V2. V3. V4. V (v1, v3) V1. V2. V3. V4. V5. V (v5, v6) 7. 추가.")
132
그러면 F {e} 는 유망한 edge들의 집합이다.
정리 4.4 G = (V, E)가 방향이 없는 연결된 그래프라고 하자. 그리고 각 edge에는 가중치가 있다고 하자. F E를 유망한 edge들의 집합이라고 하고, edge e가 다음 조건을 만족하는 최소 가중치를 갖는 edge라고 하자. 1) e (E - F) 2) F {e}에 사이클이 없다. 그러면 F {e} 는 유망한 edge들의 집합이다. [ 증명 ] F는 유망한 에지들의 집합이므로, F F이며 (V, F)가 최소 신장트리인 에지들의 집합 F가 존재한다. Page 193 참조
가 방향이 없는 연결된 그래프라고 하자. 그리고 각 edge에는 가중치가 있다고 하자. F E를 유망한 edge들의 집합이라고 하고, edge e가 다음 조건을 만족하는 최소 가중치를 갖는 edge라고 하자. 1) e (E - F) 2) F {e}에 사이클이 없다. 그러면 F {e} 는 유망한 edge들의 집합이다. [ 증명 ] F는 유망한 에지들의 집합이므로, F F이며 (V, F)가 최소 신장트리인 에지들의 집합 F가 존재한다. Page 193 참조.")
133
Kruksal 알고리즘을 수행하면 항상 최소 신장트리를 얻을 수 있다.
정리 4.5 Kruksal 알고리즘을 수행하면 항상 최소 신장트리를 얻을 수 있다. [ 증명 ] 수학적 귀납법으로 쉽게 증명이 된다. 수학적 귀납법에서 처음 기본단계(basis step)에서는 edge들이 수를 0, 다시 말해서 edge들의 집합을 공집합으로 한다. 바로 앞의 정리 4.4를 적용하면 쉽게 증명이 된다.
에서는 edge들이 수를 0, 다시 말해서 edge들의 집합을 공집합으로 한다. 바로 앞의 정리 4.4를 적용하면 쉽게 증명이 된다.")
134
제 5 장 동적프로그래밍 5.1 동적프로그래밍의 개념 5.2 이항계수 5.3 행렬의 연속적인 곱셈 5.4 최적의 이진 탐색트리
제 5 장 동적프로그래밍 5.1 동적프로그래밍의 개념 5.2 이항계수 5.3 행렬의 연속적인 곱셈 5.4 최적의 이진 탐색트리 5.5 외판원 문제 배낭문제 5.7 최단경로 문제 : Floyd algorithm 5.8 연습문제

135
5.1 동적 프로그래밍의 개념 동적 프로그래밍으로 문제를 풀때의 과정
5.1 동적 프로그래밍의 개념 동적 프로그래밍으로 문제를 풀때의 과정 1) 문제의 한 경우에 대한 해답의 성질을 순환적인 수식으로 나타낸다. 2) 문제의 경우를 적은 경우들로 분할하여 이들에 대한 해답을 구한다. 다음에 상향식(bottom-up)으로 처음에 주어진 문제의 경우에 대한 해답을 구한다. 최적의 원리(principle of optimality) : 만약 어떤 문제의 한 경우(instance)에 대한 최적해가 모든 부분경우(subinstance)에 대한 최적해들을 항상 포함할 때, 우리는 최적의 원리가 이 문제에 적용된다고 정의한다. 다시 말하면 최적 결정의 순서는 최초의 결정 및 상태에 관계없이 나머지 모든 결정들에서 나타난 상태에 대하여 최적 결정의 순서를 이룬다.
 문제의 한 경우에 대한 해답의 성질을 순환적인 수식으로 나타낸다. 2) 문제의 경우를 적은 경우들로 분할하여 이들에 대한 해답을 구한다. 다음에 상향식(bottom-up)으로 처음에 주어진 문제의 경우에 대한 해답을 구한다. 최적의 원리(principle of optimality) : 만약 어떤 문제의 한 경우(instance)에 대한 최적해가 모든 부분경우(subinstance)에 대한 최적해들을 항상 포함할 때, 우리는 최적의 원리가 이 문제에 적용된다고 정의한다. 다시 말하면 최적 결정의 순서는 최초의 결정 및 상태에 관계없이 나머지 모든 결정들에서 나타난 상태에 대하여 최적 결정의 순서를 이룬다.")
136
5.2 이항계수 (binomial coefficient)
알고리즘 5.1 : 분할 및 정복에 의한 이항계수 알고리즘 문제 : 이항계수를 구하시오. 입력 : 0보다 같거나 큰 정수 n 및 k, 단 k <= n 출력 : 이항계수 의 값 bin n k int bin (int n, int k) { if (k == 0 ∥n == k) return 1; else return bin(n-1, k-1) + bin(n-1, k) }
 { if (k == 0 ∥n == k) return 1; else. return bin(n-1, k-1) + bin(n-1, k) }")
137
동적 프로그래밍 방법을 사용한 이항계수 구하기 1) 이항계수의 순환적 특성을 유도한다.
B[i-1][j-1] + B[i-1][j] < j < i j = 0 또는 j = i 2) 첫 번째 행에서 시작하여 B의 행들을 밑에서 부터 위로 순차적으로 계산한다. (그림 5.1 참조) B[i][j] = j k 0 1 B[i-1][j-1] + B[i-1][j] B[i][j] I n 그림 5.1
 첫 번째 행에서 시작하여 B의 행들을 밑에서 부터 위로 순차적으로 계산한다. (그림 5.1 참조) B[i][j] = j k B[i-1][j-1] + B[i-1][j] B[i][j] I. n. 그림 5.1.")
138
int dp_bin (int n, int k) { index i, j; int B[0..n][0..k];
알고리즘 5.2 : 동적 프로그래밍에 의한 이항계수 알고리즘 문제 : 동적 프로그래밍 방법으로 이항계수를 구하시오. 입력 : 0보다 같거나 큰 정수 n 및 k, 단 k <= n 출력 : 이항계수 의 값 dp_bin n k int dp_bin (int n, int k) { index i, j; int B[0..n][0..k]; for (i = 0; i <= n; i++) for (j = 0; j <= minimum(i, k); j++) if (j == 0 ∥n == i) B[i][j] = 1; else B[i][j] = B[i-1][j-1] + B[i-1][j]; return B[n][k]; }
![int dp_bin (int n, int k) { index i, j; int B[0..n][0..k];](http://slidesplayer.org/slide/14753381/90/images/138/int+dp_bin+%28int+n%2C+int+k%29+%7B+index+i%2C+j%3B+int+B%5B0..n%5D%5B0..k%5D%3B.jpg "알고리즘 5.2 : 동적 프로그래밍에 의한 이항계수 알고리즘. 문제 : 동적 프로그래밍 방법으로 이항계수를 구하시오. 입력 : 0보다 같거나 큰 정수 n 및 k, 단 k <= n. 출력 : 이항계수 의 값 dp_bin. n. k. int dp_bin (int n, int k) { index i, j; int B[0..n][0..k]; for (i = 0; i <= n; i++) for (j = 0; j <= minimum(i, k); j++) if (j == 0 ∥n == i) B[i][j] = 1; else. B[i][j] = B[i-1][j-1] + B[i-1][j]; return B[n][k]; }")
139
M1 = (13 5), M2 = (5 89), M3 = (89 3), M4 = (3 34)가 주어졌을
보기 5.7 네 개의 행렬 M1 = (13 5), M2 = (5 89), M3 = (89 3), M4 = (3 34)가 주어졌을 때, 이 네 행렬에 관한 연속적인 곱셈 M = M1 M2 M3 M4 를 생각 하자. 결합법칙이 성립하므로 M을 구하는 방법에는 다음 그림 5.2와 같이 서로 다른 다섯가지가 있다. M을 구하는 방법 연산횟수 1 ((M1 M2) M3) M •5 • •89 • •3 •34 = 10582 2 (M1 M2) (M3 M4 ) •5 • •3 • •89 •34 = 54201 3 (M1 ( M2 M3 )) M •89 • •5 • •3 •34 = 2856 M1 (( M2 M3) M4 ) •89 •3 + 5 •3 • •5 •34 = 4055 M1 ( M2 ( M3 M4 )) •3 • •89 • •5 •34 = 26418 No. 그림 5.2
, M2 = (5 89), M3 = (89 3), M4 = (3 34)가 주어졌을. 때, 이 네 행렬에 관한 연속적인 곱셈 M = M1 M2 M3 M4 를 생각. 하자. 결합법칙이 성립하므로 M을 구하는 방법에는 다음 그림 5.2와. 같이 서로 다른 다섯가지가 있다. M을 구하는 방법 연산횟수. 1 ((M1 M2) M3) M4 13 •5 • •89 • •3 •34 = (M1 M2) (M3 M4 ) 13 •5 • •3 • •89 •34 = (M1 ( M2 M3 )) M4 5 •89 • •5 • •3 •34 = M1 (( M2 M3) M4 ) 5 •89 •3 + 5 •3 • •5 •34 = M1 ( M2 ( M3 M4 )) 89 •3 • •89 • •5 •34 = No. 그림 5.2.")
140
그림 5.3 행렬 M k-1 의 열의 개수 d k-1 = 행렬 M k 의 행의 개수 d k-1

141
그림 5.4 검정색으로 표시된 A[1,4]는 보기(5.9)에 대한 결과
보기 5.9 132 대각선 1 대각선 2 대각선 3 대각선 4 대각선 5 최종결과 (최적순서에 필요한 스칼라 곱셈수) 그림 5.4 검정색으로 표시된 A[1,4]는 보기(5.9)에 대한 결과
![그림 5.4 검정색으로 표시된 A[1,4]는 보기(5.9)에 대한 결과](http://slidesplayer.org/slide/14753381/90/images/141/%EA%B7%B8%EB%A6%BC+5.4+%EA%B2%80%EC%A0%95%EC%83%89%EC%9C%BC%EB%A1%9C+%ED%91%9C%EC%8B%9C%EB%90%9C+A%5B1%2C4%5D%EB%8A%94+%EB%B3%B4%EA%B8%B0%285.9%29%EC%97%90+%EB%8C%80%ED%95%9C+%EA%B2%B0%EA%B3%BC.jpg "보기 대각선 1 대각선 2 대각선 3 대각선 4 대각선 최종결과 (최적순서에 필요한 스칼라 곱셈수) 그림 5.4 검정색으로 표시된 A[1,4]는 보기(5.9)에 대한 결과.")
142
알고리즘 5.3 : 행렬의 연속된 곱셈에서의 최소한의 스칼라 연산(곱셈)
문제 : n개의 행렬들을 연속해서 곱할 때, 필요한 최소한의 스칼라 연산(곱셈) 수를 구하시오. 입력 : n개의 행렬들의 차원을 나타내는 d0, d1, d1, …, d0. 행렬 Mi 의 차원은 d[i-1] * d[i]로 표시된다. (1 <= i<= n) 출력 : 최적의 곱셈순서에 대한 스칼라 연산 수를 나타내는 변수 minimult의 값, 그리고 최적의 곱셈 순서를 나타내는 행렬 P
 수를 구하시오. 입력 : n개의 행렬들의 차원을 나타내는 d0, d1, d1, …, d0. 행렬 Mi 의 차원은 d[i-1] * d[i]로 표시된다. (1 <= i<= n) 출력 : 최적의 곱셈순서에 대한 스칼라 연산 수를 나타내는 변수. minimult의 값, 그리고 최적의 곱셈 순서를 나타내는 행렬 P.")
143
int minmult (int n, const int d[], index P[][]) {
index i, j, k, diagonal; int A[1..n][1..n]; for (i = 1; i <= n; i++) A[i][j] = 0; for (diagonal = 1; diagonal <= n - 1; diagonal++) for (i = 1; i <= n - diagonal; i++) { j = i + diagonal; A[i][j] = {A[i][j]+A[k+1][j]+d[i-1]*d[k]*d[j]); p[i][j] = a value of k that gave the minimum; } return A[1][n]; minimum ik j-1
![int minmult (int n, const int d[], index P[][]) {](http://slidesplayer.org/slide/14753381/90/images/143/int+minmult+%28int+n%2C+const+int+d%5B%5D%2C+index+P%5B%5D%5B%5D%29+%7B.jpg "index i, j, k, diagonal; int A[1..n][1..n]; for (i = 1; i <= n; i++) A[i][j] = 0; for (diagonal = 1; diagonal <= n - 1; diagonal++) for (i = 1; i <= n - diagonal; i++) { j = i + diagonal; A[i][j] = {A[i][j]+A[k+1][j]+d[i-1]*d[k]*d[j]); p[i][j] = a value of k that gave the minimum; } return A[1][n]; minimum. ik j-1.")
144
void order (index i, index j) { if (i == j)
알고리즘 5.4 : 최적의 곱셈순서 문제 : 행렬의 연속된 곱셈에 대한 최적의 곱셈순서를 프린트 하시오. 입력 : 행렬의 개수를 나타내는 자연수 n, 알고리즘 5.3에서 얻어진 배열P. 원소 P[i][j]는 Mi 에서 Mj 까지의 연속된 행렬 곱셈에 대한 최적의 곱셈순서가 되기 위해 분리되는 위치를 나타낸다. 출력 : n개의 행렬을 연속되게 곱할 때, 최적의 곱셈순서 void order (index i, index j) { if (i == j) cout << “M” << i; else { k = P[i][j]; cout << “(”; order(i, k); order(k+1, j); cout << “)”; }
 { if (i == j) cout << M << i; else { k = P[i][j]; cout << ( ; order(i, k); order(k+1, j); cout << ) ; }")
145
보기 5.10 while repeat read if for (a) (b) 그림 5.5
 (b) 그림 5.5")
146
while repeat (a) (b) 그림 5.6
 (b) 그림 5.6")
147
뿌리노드가 keym인 최적의 이진 탐색트리 Tm에 대한 평균 탐색시간은 다음의 5가지를 모두 더한 것이다.
key1, key2, …, keym-1 keym+1, keym+2, …, keyn 그림 5.7 뿌리노드가 keym 일 때 최적 이진 탐색트리의 평균 탐색시간 분석 뿌리노드가 keym인 최적의 이진 탐색트리 Tm에 대한 평균 탐색시간은 다음의 5가지를 모두 더한 것이다. 1) C[1][m-1] : Tm 의 왼쪽 서브트리에 대한 평균 탐색시간 2) C[m+1][n] : Tm 의 오른쪽 서브트리에 대한 평균 탐색시간 3) pj : 뿌리노드에서 비교하는 데 필요한 추가의 시간 4) pm : 뿌리노드에 대한 평균 탐색시간 5) pj : 뿌리노드에서 비교하는 데 필요한 추가의 시간 m - 1 j = 1 n j = m+ 1
 C[1][m-1] : Tm 의 왼쪽 서브트리에 대한 평균 탐색시간. 2) C[m+1][n] : Tm 의 오른쪽 서브트리에 대한 평균 탐색시간. 3) pj : 뿌리노드에서 비교하는 데 필요한 추가의 시간. 4) pm : 뿌리노드에 대한 평균 탐색시간. 5) pj : 뿌리노드에서 비교하는 데 필요한 추가의 시간. m - 1. j = 1. n. j = m+ 1.")
148
void optimal_bst (int n, const float p[], float& minavg,
알고리즘 5.5 : 최적의 이진 탐색트리 문제 : 각 키마다 탐색되는 확률이 주어졌을 때, 이 키들에 대한 최적의 이진 탐색트리를 구하시오. 입력 : 자연수 n (키들의 수), 그리고 0과 1 사이의 실수값을 갖는 n 개의 실수 P[i]. 각 P[i]는 i번째 키가 탐색되는 확률이다. 단, 1 <= i <= n. 출력 : 최적의 이진 탐색트리에 대한 평균 탐색시간인 mimavg. 그리고 최적의 이진 탐색트리를 나타내는 2차원 배열 R void optimal_bst (int n, const float p[], float& minavg, index R[][]) { index i, j, k, diagonal; float C[1..n+1][0..n];
![void optimal_bst (int n, const float p[], float& minavg,](http://slidesplayer.org/slide/14753381/90/images/148/void+optimal_bst+%28int+n%2C+const+float+p%5B%5D%2C+float%26+minavg%2C.jpg "알고리즘 5.5 : 최적의 이진 탐색트리. 문제 : 각 키마다 탐색되는 확률이 주어졌을 때, 이 키들에 대한 최적의. 이진 탐색트리를 구하시오. 입력 : 자연수 n (키들의 수), 그리고 0과 1 사이의 실수값을 갖는 n 개의. 실수 P[i]. 각 P[i]는 i번째 키가 탐색되는 확률이다. 단, 1 <= i <= n. 출력 : 최적의 이진 탐색트리에 대한 평균 탐색시간인 mimavg. 그리고 최적의 이진 탐색트리를 나타내는 2차원 배열 R. void optimal_bst (int n, const float p[], float& minavg, index R[][]) { index i, j, k, diagonal; float C[1..n+1][0..n];")
149
for (i = 1; i <=n; i++) { C[i][i-1] = 0; C[i][i] = p[i];
R[i][i] = i; R[i][i-1] = 0; } C[n+1][n] = 0; R[n+1][n] = 0; for (diagonal = 1; diagonal <= n-1; diagonal++) // diagonal-1 is just above the main diagonal for (i = 1; i <= n-diagonal; i++) { j = i + diagonal; C[i][j] = (C[i][m-1] + C[m+1][j]) + Pk; R[i][j] = a value of m that gave the minimum; minavg = C[1][n]; i minimum im j k=i
![for (i = 1; i <=n; i++) { C[i][i-1] = 0; C[i][i] = p[i];](http://slidesplayer.org/slide/14753381/90/images/149/for+%28i+%3D+1%3B+i+%3C%3Dn%3B+i%2B%2B%29+%7B+C%5Bi%5D%5Bi-1%5D+%3D+0%3B+C%5Bi%5D%5Bi%5D+%3D+p%5Bi%5D%3B.jpg "R[i][i] = i; R[i][i-1] = 0; } C[n+1][n] = 0; R[n+1][n] = 0; for (diagonal = 1; diagonal <= n-1; diagonal++) // diagonal-1 is just above the main diagonal. for (i = 1; i <= n-diagonal; i++) { j = i + diagonal; C[i][j] = (C[i][m-1] + C[m+1][j]) + Pk; R[i][j] = a value of m that gave the minimum; minavg = C[1][n]; i. minimum. im j. k=i.")
150
알고리즘 5.6 : 최적의 이진 탐색트리의 생성 문제 : 최적의 이진 탐색트리를 생성하시오. 입력 : 자연수 n (키들의 개수), n 개의 키들 key1, key2, …, keyn 이 순서 대로 배열 Key에 있다. 그리고 R[i][j]는 keyi 에서 keyj 까지의 키들에 대한 최적의 이진 탐색트리의 뿌리노드에 대한 인덱스를 갖으며, 알고리즘 5.5에서 얻어진다. 출력 : n개의 키들에 대한 최적의 이진 탐색트리에 대한 포인터 값 tree

151
node_pointer tree (index i, j) {
index k; node_pointer p; k = R[i][j]; if (k == 0) return NULL; else { p = new nodetype; p -> key = Key[k]; p -> left = tree(i, k-1); p -> right = tree(k+1, j); return p; }
 return NULL; else { p = new nodetype; p -> key = Key[k]; p -> left = tree(i, k-1); p -> right = tree(k+1, j); return p; }")
152
key[1] key[2] key[3] key[4] I READ THE TITLE
보기 5.13 다음과 같은 4개의 key에 대한 배열이 있다고 하자. key[1] key[2] key[3] key[4] I READ THE TITLE 각 키들에 대한 탐색될 확률 p는 다음과 같이 주어졌다. P[1] P[2] P[3] P[4] 3/ / / /8
![key[1] key[2] key[3] key[4] I READ THE TITLE](http://slidesplayer.org/slide/14753381/90/images/152/key%5B1%5D+key%5B2%5D+key%5B3%5D+key%5B4%5D+I+READ+THE+TITLE.jpg "보기 다음과 같은 4개의 key에 대한 배열이 있다고 하자. key[1] key[2] key[3] key[4] I READ THE TITLE. 각 키들에 대한 탐색될 확률 p는 다음과 같이 주어졌다. P[1] P[2] P[3] P[4] 3/8 3/8 1/8 1/8.")
153
그러면 다음과 같은 배열 C 및 R이 알고리즘 5.5에 의해 얻어진다.
3 8 9 11 7 4 5 1 2 C R 1 2 3 4 1 1 2 2 2 2 2 3 3 4 READ I THE 위의 두 알고리즘에 의해 얻어지는 최적의 이진 탐색트리 TITLE 그림 5.8

154
보기 5.15 V1 V2 V4 V3 12 9 6 15 13 5 10 8 20 V V V V4 V V V V W = (a) 외판원 문제에 대한 방향이 있는 그래프 (b) 그래프 (a)에 대한 인접행렬 그림 5.9
 외판원 문제에 대한. 방향이 있는 그래프. (b) 그래프 (a)에 대한. 인접행렬. 그림 5.9.")
155
알고리즘 5.7 : 외판원 문제 알고리즘 문제 : 에지들 사이의 가중치가 있는 방향이 있는 그래프에 대하여 최적의 여행경로를 구하시오. 단, 에지의 가중치는 반드시 0 보다 큰 수이다. 입력 : 가중치가 있는 방향이 있는 그래프와 자연수 n (꼭지점의 수). 여기서 그래프는 인접 행렬 W로 표시된다. W[i][j]는 그래프에서 꼭지점 vi에서 vj 로 가는 에지의 가중치이다. V는 그래프의 모든 꼭지점들의 집합이다. 출력 : 최적의 여행경비의 값을 나타내는 변수 minlength의 값과 최적의 여행경로를 나타내는 행렬식 P. P[i][A]는 꼭지점 vi 에서 A의 꼭지점들을 한 번씩만 방문하여 v1 으로 가는 최적의 경로에서 꼭지점 바로 다음에 방문하는 꼭지점의 인덱스이다.
. 여기서 그래프는 인접 행렬 W로 표시된다. W[i][j]는 그래프에서 꼭지점 vi에서 vj 로 가는 에지의 가중치이다. V는 그래프의 모든 꼭지점들의 집합이다. 출력 : 최적의 여행경비의 값을 나타내는 변수 minlength의 값과 최적의. 여행경로를 나타내는 행렬식 P. P[i][A]는 꼭지점 vi 에서 A의 꼭지점들을 한 번씩만 방문하여. v1 으로 가는 최적의 경로에서 꼭지점 바로 다음에 방문하는. 꼭지점의 인덱스이다.")
156
void travel (int n, const number W[][];
index P[][]; number& minlength) { index i, j, k; number D[1..n][subset of V-{v1}]; for (i = 2; i <=n; i++) D[i][] = W[i][1]; for (k = 1; k <= n-2; k++) for (all subsets A V - {v1} containing k vertices) for (i such that i 1 and vi is not in A) D[i][A] = (W[i][j]+D[vj][A-{vj}]); P[i][A] = value of j that gave the minimum; } D[1][V-{vi }] = (W[1][j]+D[vj][V-{v1}]); P[1][V-{vi }] = value of j that gave the minimum; minlength = D[1][V-{vi }] ; minimum vj A minimum 2 j n
![void travel (int n, const number W[][];](http://slidesplayer.org/slide/14753381/90/images/156/void+travel+%28int+n%2C+const+number+W%5B%5D%5B%5D%3B.jpg "index P[][]; number& minlength) { index i, j, k; number D[1..n][subset of V-{v1}]; for (i = 2; i <=n; i++) D[i][] = W[i][1]; for (k = 1; k <= n-2; k++) for (all subsets A V - {v1} containing k vertices) for (i such that i 1 and vi is not in A) D[i][A] = (W[i][j]+D[vj][A-{vj}]); P[i][A] = value of j that gave the minimum; } D[1][V-{vi }] = (W[1][j]+D[vj][V-{v1}]); P[1][V-{vi }] = value of j that gave the minimum; minlength = D[1][V-{vi }] ; minimum. vj A. minimum. 2 j n.")
157
f i-1(x - wi) + pi i f0 f1(x) f0(x) = 0 1 2 x f1 3 5 2 3 5 8 7 6
f0 f1(x) f0(x) = 0 1 2 x f1 3 5 8 7 6 f2 f3 그림 5.10 배낭에 물건을 넣었을 때의 이익
 f0(x) = x. f f2. f3. 그림 5.10 배낭에 물건을 넣었을 때의 이익.")
158
void knap (float p[], w[], int n, int M, int m) {
알고리즘 5.8 : 0-1 배낭문제 알고리즘 문제 : 이익이 최대가 되도록 0-1 배낭문제를 해결하시오. void knap (float p[], w[], int n, int M, int m) { float P[], W[], pp, ww; int F[0..n]; int l, h, u, i, j, p, next; F[0] = 1; P[1] = 0; W[1] = 0; // initialize S0 l = 1; h = 1; // start and end of S0 F[1] = 2, next = 2; // next free spot in P and W for (i = 1; i <= n-1; i++) { // generate Si k = l; u = largest k such that l <= k <= h, and W[k] + w[i] <= M; for (j = 1; j <= u; j++) // generate Si (pp, ww) = (P[j] + p[i, W[j] + w[i]); // next element in Si 1 1
![void knap (float p[], w[], int n, int M, int m) {](http://slidesplayer.org/slide/14753381/90/images/158/void+knap+%28float+p%5B%5D%2C+w%5B%5D%2C+int+n%2C+int+M%2C+int+m%29+%7B.jpg "알고리즘 5.8 : 0-1 배낭문제 알고리즘. 문제 : 이익이 최대가 되도록 0-1 배낭문제를 해결하시오. void knap (float p[], w[], int n, int M, int m) { float P[], W[], pp, ww; int F[0..n]; int l, h, u, i, j, p, next; F[0] = 1; P[1] = 0; W[1] = 0; // initialize S0. l = 1; h = 1; // start and end of S0. F[1] = 2, next = 2; // next free spot in P and W. for (i = 1; i <= n-1; i++) { // generate Si. k = l; u = largest k such that l <= k <= h, and W[k] + w[i] <= M; for (j = 1; j <= u; j++) // generate Si. (pp, ww) = (P[j] + p[i, W[j] + w[i]); // next element in Si")
159
while (k <= h && W[k] <= ww) { // merge in from Si-1
P[next] = P[k]; W[next] = W[k]; next = next + 1; k = k +1; { if (k <= h && W[k] = ww) { pp = maximum(pp, P[k]; } if (pp > P[next - 1] { (P[next], W[next]) = (pp, ww);
![while (k <= h && W[k] <= ww) { // merge in from Si-1](http://slidesplayer.org/slide/14753381/90/images/159/while+%28k+%3C%3D+h+%26%26+W%5Bk%5D+%3C%3D+ww%29+%7B+%2F%2F+merge+in+from+Si-1.jpg "P[next] = P[k]; W[next] = W[k]; next = next + 1; k = k +1; { if (k <= h && W[k] = ww) { pp = maximum(pp, P[k]; } if (pp > P[next - 1] { (P[next], W[next]) = (pp, ww);")
160
while (k <= h && P[k] <= P[next - 1] // purge
k = k + 1; } // merge in remaining terms from Si-1 while (k <= h) { (P[next], W[next]) = (P[k], W[k]) next = next + 1; k = k +1; } // initialize for Si-1 l h + 1; h = next - 1; F[i+1] = next; } parts;
![while (k <= h && P[k] <= P[next - 1] // purge](http://slidesplayer.org/slide/14753381/90/images/160/while+%28k+%3C%3D+h+%26%26+P%5Bk%5D+%3C%3D+P%5Bnext+-+1%5D+%2F%2F+purge.jpg "k = k + 1; } // merge in remaining terms from Si-1. while (k <= h) { (P[next], W[next]) = (P[k], W[k]) next = next + 1; k = k +1; } // initialize for Si-1. l h + 1; h = next - 1; F[i+1] = next; } parts;")
161
보기 5.20 V1 V2 V4 V3 15 5 30 50 (a) C = W = (c) (b) 그림 5.11
 (b) 그림")
162
V1 V2 V4 V3 12 14 13 25 8 10 16 V5 15 4 9 그림 5.12 Vi Vk Vj {v1, v2, … , vk-1}에 있는 꼭지점들만 중간경유지로 하여 꼭지점 vi 에서 vk 로 가는 최단경로 W k-1[i][k], {v1, v2, … , vk-1}에 있는 꼭지점들만 중간경유지로 하여 꼭지점 vk 에서 vj 로 가는 최단경로 W k-1[k][j], 그림 5.13

163
알고리즘 5.9 : 최단경로에 대한 Floyd 알고리즘
문제 : 방향이 있는 가중치의 그래프에서 임의의 꼭지점에서 다른 모든 꼭지점들로 가는 최단 경로들의 거리를 구하시오. 입력 : 방향이 있는 가중치 그래프 G와 자연수 n. (꼭지점의 개수) 그래프 G는 행렬 C로 표시된다. 만약 그래프 G의 꼭지점 vi에서 vj 로 가는 에지의 가중치가 cij 라면, C[i][j] = cij가 된다. 출력 : 최단경로의 거리를 나타내는 행렬 W. W[i][j]의 값이 꼭지점 vi에서 vj 로 가는 최단 경로의 거리이다.
 그래프 G는 행렬 C로 표시된다. 만약 그래프 G의 꼭지점 vi에서 vj 로 가는 에지의 가중치가. cij 라면, C[i][j] = cij가 된다. 출력 : 최단경로의 거리를 나타내는 행렬 W. W[i][j]의 값이 꼭지점 vi에서 vj 로 가는 최단 경로의 거리이다.")
164
Void floyd (int n, const number C[][], number W[][])
{ index i, j, k; W = C; for (k = 1; k <= n; k++) for (i = 1; i <= n; i++) for (j = 1; j <= n; j++) W[i][j] = minimum(W[i][j], W[i][k] + W[k][j]); }
![Void floyd (int n, const number C[][], number W[][])](http://slidesplayer.org/slide/14753381/90/images/164/Void+floyd+%28int+n%2C+const+number+C%5B%5D%5B%5D%2C+number+W%5B%5D%5B%5D%29.jpg "{ index i, j, k; W = C; for (k = 1; k <= n; k++) for (i = 1; i <= n; i++) for (j = 1; j <= n; j++) W[i][j] = minimum(W[i][j], W[i][k] + W[k][j]); }")
165
알고리즘 5.10 : Floyd의 알고리즘을 사용하여 최단경로의 비용과
함께 최단경로도 같이 구하는 알고리즘 문제 : 방향이 있는 가중치의 그래프에서 임의의 꼭지점에서 다른 모든 꼭지점들로 가는 최단경로들의 거리와 함께 최단경로도 같이 구하시오. 입력 : 방향이 있는 가중치 그래프 G와 자연수 n. 그래프 G는 행렬 C로 표시된다. 만약, 그래프 G의 꼭지점 vi에서 vj 로 가는 에지의 가중치가 cij 라면, C[][j] = cij 가 된다. 출력 : 최단경로의 거리를 나타내는 행렬 W W[i][j]의 값이 꼭지점 vi에서 vj 로 가는 최단경로의 거리이다. 그리고 최단경로를 나타내는 다음과 같은 행렬 P. P[i][j] = 만약 꼭지점 vi에서 vj 로 가는 최단경로에 중간 경유하는 꼭지점이 없으면 0, 있으면 중간 경유 꼭지점들 중 가장 큰 인덱스

166
void floyd_path (int n, const number C[][], number W[][],
index P[][]) { index i, j, k; for (i = 1; i <= n; i++) for (j = 1; j <= n; j++) P[i][j] = 0; W = C; for (k = 1; k <= n; k++) if (W[i][k] + W[k][j] < W[i][j]) { P[i][j] = k; W[i][j] = W[i][k] + W[k][j]; }
![void floyd_path (int n, const number C[][], number W[][],](http://slidesplayer.org/slide/14753381/90/images/166/void+floyd_path+%28int+n%2C+const+number+C%5B%5D%5B%5D%2C+number+W%5B%5D%5B%5D%2C.jpg "index P[][]) { index i, j, k; for (i = 1; i <= n; i++) for (j = 1; j <= n; j++) P[i][j] = 0; W = C; for (k = 1; k <= n; k++) if (W[i][k] + W[k][j] < W[i][j]) { P[i][j] = k; W[i][j] = W[i][k] + W[k][j]; }")
167
알고리즘 5.11 : 최단경로 출력 알고리즘 문제 : 임의의 꼭지점에서 다른 모든 꼭지점들로 가는 최단경로에 있는 중간 경유지(꼭지점)들을 프린트 하시오. 입력 : 위의 알고리즘에서 얻어진 행렬 P. 그리고 위의 알고리즘에 대한 입력으로서 그래프의 꼭지점에 대한 두 인덱스 q 및 r. P[][] = 만약 꼭지점 vi에서 vj 로 가는 최단 경로에 중간 경유 하는 꼭지점이 없으면 0, 있으면 중간 경유 꼭지점들 중에서 가장 큰 인덱스 출력 : 꼭지점 vq 에서 vr 로 가는 최단 경로에 있는 중간 경유지

168
void path (index q, r) { if (P[q][r] != 0) { path (q, P[q][r]); cout << “v” << P[q][r]; path (P[q][r], r); }
![void path (index q, r) { if (P[q][r] != 0) { path (q, P[q][r]); cout << v << P[q][r]; path (P[q][r], r);](http://slidesplayer.org/slide/14753381/90/images/168/void+path+%28index+q%2C+r%29+%7B+if+%28P%5Bq%5D%5Br%5D+%21%3D+0%29+%7B+path+%28q%2C+P%5Bq%5D%5Br%5D%29%3B+cout+%3C%3C+v+%3C%3C+P%5Bq%5D%5Br%5D%3B+path+%28P%5Bq%5D%5Br%5D%2C+r%29%3B.jpg "}")
169
제 6 장 백트랙킹(backtracking)
6.1 개념 소개 6.2 해밀턴 회로문제 배낭문제 6.4 그래프 채색문제 6.5 서양장기에서의 n-여왕문제 6.6 Monte Carlo 알고리즘 6.7 연습문제
![]()
170
6.1 개념 소개 보기 6.1 x o 그림 6.1 탐색공간트리 (Tic - Tac - Toe) x
 x")
171
void depth_first_search(node v) { node u;
보기 6.2 /* 깊이우선 탐색방법에 대한 요약된 알고리즘 */ void depth_first_search(node v) { node u; visit v; for (each child u of v) depth_first_search(u); } B E D C G F H A 이 상태 공간 트리를 깊이 우선 탐색을 한 결과 => A, B, D, H, E, C, F, G
 { node u; visit v; for (each child u of v) depth_first_search(u); } B. E. D. C. G. F. H. A. 이 상태 공간 트리를 깊이 우선 탐색을 한 결과 => A, B, D, H, E, C, F, G.")
172
/* Backtracking Method */
void check_node(node v) { node u; if (promising(v)) if (there is a solution at v) write the solution; else for (each child u of v) check_node(u); } /* check_node 개정 */ void expand(node v) { node u; for (each child u of v) if (promising(v)) if (there is a solution at v) write the solution; else expand(u); }
![]()
173
6.2 해밀턴 회로문제 (Hamilton Circuit Problem)
>> 해밀턴 회로문제에서 상태 공간 트리는 다음 조건들을 만족한다. 1) I 번째 꼭지점은 반드시 (i - 1) 번째 꼭지점과 서로 이웃해야 한다. 2) (n - 1) 번째 꼭지점은 0 번째 꼭지점(출발 꼭지점)과 이웃해야 한다. 3) i 번째 꼭지점은 처음의(i -1) 꼭지점들 중의 하나가 될 수 없다.
 I 번째 꼭지점은 반드시 (i - 1) 번째 꼭지점과 서로 이웃해야 한다. 2) (n - 1) 번째 꼭지점은 0 번째 꼭지점(출발 꼭지점)과 이웃해야 한다. 3) i 번째 꼭지점은 처음의(i -1) 꼭지점들 중의 하나가 될 수 없다.")
174
V4 V3 V2 V1 V8 V7 V6 V5 V3 V2 V1 V4 V5 (a) 해밀턴 회로를 포함하고 있는 방향이 없는 그래프
(b) 해밀턴 회로가 없는 그래프 그림 6.3 해밀턴 회로 문제
 해밀턴 회로가 없는 그래프. 그림 6.3 해밀턴 회로 문제.")
175
알고리즘 6.1 : 해밀턴 회로 문제에 대한 백트랙킹 알고리즘
문제 : 방향이 없는 연결된 그래프에서의 모든 해밀턴 회로들을 찾으시오. 입력 : 자연수 n 및 n개의 꼭지점들이 있는 방향이 없는 그래프. 이 그래프는 행과 열의 개수가 모두 n인 2차원 행렬 W로 표시된다. 만약 주어진 그래프에서 i번째의 꼭지점과 j 번째의 꼭지점 사이에 에지가 있으면 W[i][j]의 값은 true이며, 아니면 false이다. 출력 : 주어진 그래프에 대한 모든 해밀턴 회로들. 즉, 그래프의 주어진 어떤 꼭지점에서 출발하여 나머지 꼭지점들을 한번씩만 방문하여 처음 출발하였던 꼭지점으로 되돌아 오는 모든 회로들 비고 : 각 회로에 대한 출력은 vindex[0]에서 vindex[n-1]으로 표현된다. 여기서 vindex[i]는 해밀턴 회로에 있는 i 번째 꼭지점을 말하며, 처음 출발 꼭지점의 인덱스는 vindex[0]로 한다.

176
void hamiltonian (index i)
{ index j; if (promising(i)) if (i == n-1) cout << vindex[0] through vindex[n-1]; else for (j = 2; j <= n; j++) { // Try all vertices as vindex[i + 1] = j; // next one. hamiltonian(i+1); } bool promising (index i) bool switch;
) if (i == n-1) cout << vindex[0] through vindex[n-1]; else. for (j = 2; j <= n; j++) { // Try all vertices as. vindex[i + 1] = j; // next one. hamiltonian(i+1); } bool promising (index i) bool switch;")
177
if (i == n-1 && !W[vindex[n-1]][vindex[0]])
switch = false; // First vertex must be adjacent to last. else if ( i > 0 && !W[vindex[i-1]][vindex[i]]) switch = false; // ith vertex must be adjacent to (i-1)st else { switch = true; j = 1; while (j < i && switch) { // Check if vertex is if (vindex[i] == vindex[j]) // already selected. switch = false; j++; } return switch;
![if (i == n-1 && !W[vindex[n-1]][vindex[0]])](http://slidesplayer.org/slide/14753381/90/images/177/if+%28i+%3D%3D+n-1+%26%26+%21W%5Bvindex%5Bn-1%5D%5D%5Bvindex%5B0%5D%5D%29.jpg "switch = false; // First vertex must be adjacent to last. else if ( i > 0 && !W[vindex[i-1]][vindex[i]]) switch = false; // ith vertex must be adjacent to (i-1)st. else { switch = true; j = 1; while (j < i && switch) { // Check if vertex is. if (vindex[i] == vindex[j]) // already selected. switch = false; j++; } return switch;")
178
6.3 0 - 1 배낭문제(knapsack problem)
/* 배낭문제에 대한 최적화 문제(backtracking method) */ void check_node(node v) { node u; if (value(v) is better than best) best = value(v) ; if (promising(v)) for (each child u of v) check_node(u); }
 */ void check_node(node v) { node u; if (value(v) is better than best) best = value(v) ; if (promising(v)) for (each child u of v) check_node(u); }")
179
보기 6.3 i pi wi pi wi
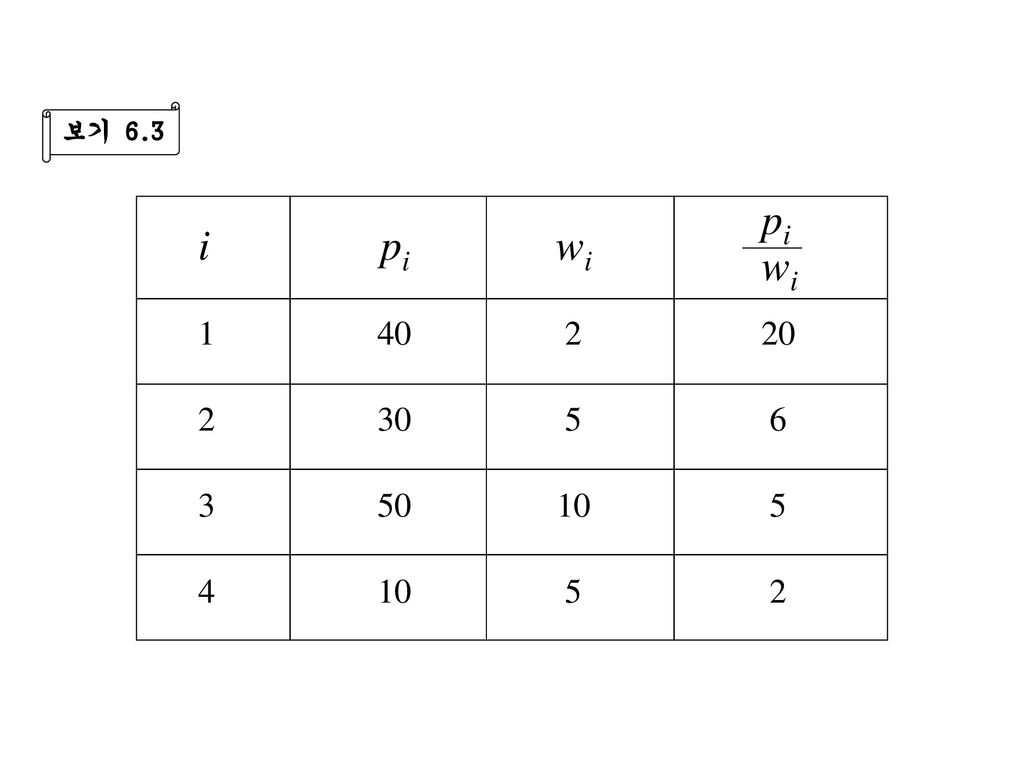
180
(0, 0) 80 12 (4, 1) X 70 7 (4, 2) (3, 2) 100 17 (4, 3) 90 (4, 4) (3, 3) 98 40 2 50 (3, 4) 120 (3, 1) 980 (2, 2) 115 (2, 1) (1, 1) 82 (1, 2) Item 1 Item 2 30 5 Item 3 10 Item 4 그림 6.4 백트랙킹에 의 해 축소된 보기 6.3의 탐색 공간 트리
 120. (3, 1) 980. (2, 2) 115. (2, 1) (1, 1) 82. (1, 2) Item 1. Item Item Item 4. 그림 6.4 백트랙킹에 의 해 축소된 보기 6.3의 탐색 공간 트리.")
181
알고리즘 6.2 : 0-1 배낭문제에 대한 백트랙킹 알고리즘
문제 : 서로 다른 크기(무게) 및 이익을 갖는 n개의 물건들이 있다. 배낭의 크기(무게)를 M이라고 할 때, 최대의 이익을 갖도록 물건 을 배낭에 넣으려면 어떤 물건들을 배낭에 넣고 어떤 물건들은 넣지 말아야 하는가? 단, 물건들을 배낭에 넣을 때는 배낭에 넣는 물건들의 크기는 배낭의 크기 M을 넘지 못한다. 입력 : 물건들의 개수 n, 배낭의 크기 M, 각 물건의 크기를 나타내는 배열 w, 각 물건을 배낭에 넣었을 때의 이익을 나타내는 배열 p. 출력 : n개의 원소들을 갖는 배열 bestset. 만약 i 번째 물건을 배낭에 넣어야 한다면 bestset[i] 의 값이 1이며, 넣지 말아야 한다면 bestset[i]의 값이 0이다. Maxprofit은 주어진 배낭문제에 대한 최적해의 값이다. 즉, 이익이 가장 많도록 배낭에 물건들을 넣을 때의 최대 이익값이다. 비고 : n개의 물건들은 p[i]/w[i] 비율값이 큰 순서대로 정렬되었다. (배열 p 및 w의 원소들은 p[i]/w[i] 비율값이 큰 순서대로 정렬)
 및 이익을 갖는 n개의 물건들이 있다. 배낭의 크기(무게)를 M이라고 할 때, 최대의 이익을 갖도록 물건. 을 배낭에 넣으려면 어떤 물건들을 배낭에 넣고 어떤 물건들은. 넣지 말아야 하는가 단, 물건들을 배낭에 넣을 때는 배낭에 넣는. 물건들의 크기는 배낭의 크기 M을 넘지 못한다. 입력 : 물건들의 개수 n, 배낭의 크기 M, 각 물건의 크기를 나타내는 배열. w, 각 물건을 배낭에 넣었을 때의 이익을 나타내는 배열 p. 출력 : n개의 원소들을 갖는 배열 bestset. 만약 i 번째 물건을 배낭에. 넣어야 한다면 bestset[i] 의 값이 1이며, 넣지 말아야 한다면. bestset[i]의 값이 0이다. Maxprofit은 주어진 배낭문제에 대한. 최적해의 값이다. 즉, 이익이 가장 많도록 배낭에 물건들을 넣을. 때의 최대 이익값이다. 비고 : n개의 물건들은 p[i]/w[i] 비율값이 큰 순서대로 정렬되었다. (배열 p 및 w의 원소들은 p[i]/w[i] 비율값이 큰 순서대로 정렬)")
182
void knapsack (index i; int profit, int weight) {
if (weight <= M && profit > maxprofit) { // This set is maxprofit = profit; // best so far. mumbest = i; // Set numbest to number bestset = include; // of items considered. } // Set bestset to this solution. if (promising(i)) { include[i+1] = “yes”; // Include w[i+1]. knapsack(i+1, profit + p[i+1], weight + w[i+1]; include[i+1] = “no”; // Do not include w[i+1]. knapsack(i+1, profit, weight); } bool promising (index i) { index j, k; int totweight; float bound;
 { // This set is. maxprofit = profit; // best so far. mumbest = i; // Set numbest to number. bestset = include; // of items considered. } // Set bestset to this solution. if (promising(i)) { include[i+1] = yes ; // Include w[i+1]. knapsack(i+1, profit + p[i+1], weight + w[i+1]; include[i+1] = no ; // Do not include w[i+1]. knapsack(i+1, profit, weight); } bool promising (index i) { index j, k; int totweight; float bound;")
183
if (weight >= M) return false; // Node is promising only if we else { // should expand to its children. j = i +1; // There must be some capacity bound = profit; // left for the children. totweight = weight; while (j <= n && totweight + w[j] <= M) { // Grab as totweight = totweight + w[j]; // many as possible. bound = bound + p[j]; j++; } k = j; // Use k for consistency with formula if (k <= n) // in text. Grab fraction of kth item. bound = bound + (M - totweight) * p[k]/w[k]; return bound > maxprofit;
 { // Grab as. totweight = totweight + w[j]; // many as possible. bound = bound + p[j]; j++; } k = j; // Use k for consistency with formula. if (k <= n) // in text. Grab fraction of kth item. bound = bound + (M - totweight) * p[k]/w[k]; return bound > maxprofit;")
184
6.4 그래프 채색문제 (Graph Coloring Problem)
보기 6.4 꼭지점 채색되는 색깔 V1 V2 V 색깔 1 V 색깔 2 V 색깔 3 V4 V3 V 색깔 1 그림 6.5 이웃하는 꼭지점이 다른 색으로 채색되도록, 2가지 색으로는 채색할 수 없지만 3가지 색으로는 채색할 수 있는 방향이 없는 그래프

185
V1 V2 V4 V3 V5 (a) (b) 그림 6.6
 (b) 그림 6.6")
186
3 1 2 start X V1 V2 V3 V4 그림 6.7

187
알고리즘 6.3 : m-채색문제에 대한 백트랙킹 알고리즘
문제 : 방향이 없는 그래프의 꼭지점들을 채색하려고 한다. 이 때 최대 m개의 서로 다른 색깔을 갖고서 이웃하는 꼭지점들은 같은 색으로 채색하지 않으면서 이 그래프의 모든 꼭지점들 을 채색하는 모든 채색방법들을 구하시오. 입력 : 자연수 n (그래프의 꼭지점들의 개수) 및 m (채색하는 색깔 의 최대수) 그리고 n개의 꼭지점을 갖고 있는 방향이 없는 그래프 G. G는 n * n 행렬식 W로 표시된다. 만약 두 꼭지점 vi 와 vi 사이를 잇는 에지가 없으면 W[i][j]의 값은 0(false)이다. 출력 : 최대한 m개의 서로 다른 색깔을 갖고서 이웃하는 두 꼭지 점들이 같은 색으로 채색되지 않으면서 그래프의 모든 꼭지 점들을 색칠하는 채색 방법들. 각 채색 방법에 대한 출력은 n개의 자연수로 구성된 1차원 배열 vcolor(꼭지점에 채색된 색깔의 숫자)이다.
 및 m (채색하는 색깔. 의 최대수) 그리고 n개의 꼭지점을 갖고 있는 방향이 없는. 그래프 G. G는 n * n 행렬식 W로 표시된다. 만약 두 꼭지점 vi 와 vi. 사이를 잇는 에지가 없으면 W[i][j]의 값은 0(false)이다. 출력 : 최대한 m개의 서로 다른 색깔을 갖고서 이웃하는 두 꼭지. 점들이 같은 색으로 채색되지 않으면서 그래프의 모든 꼭지. 점들을 색칠하는 채색 방법들. 각 채색 방법에 대한 출력은. n개의 자연수로 구성된 1차원 배열 vcolor(꼭지점에 채색된. 색깔의 숫자)이다.")
188
void m_coloring (index i)
{ int color; if (promising(i)) if (i == n) cout << vcolor[1] through vcolor[n]; else for (color = 1; color <= m; color++) { vcolor[i+1] = color; // Try every color for m_coloring(i+1); // next vertex. }
) if (i == n) cout << vcolor[1] through vcolor[n]; else. for (color = 1; color <= m; color++) { vcolor[i+1] = color; // Try every color for. m_coloring(i+1); // next vertex. }")
189
bool promising (index i)
{ index j; bool switch; switch = true; j = 1; while (j < i && switch) { // Check if an if (W[i][j] && vcolor[i] == vcolor[j] // adjacent vertex is switch = false; // already this color. j++; } return switch;
 { // Check if an. if (W[i][j] && vcolor[i] == vcolor[j] // adjacent vertex is. switch = false; // already this color. j++; } return switch;")
190
column 1 2 3 4 5 6 7 8 row Q Q Q Q Q Q Q 그림 6.8

191
알고리즘 6.4 : 서양장기의 n - 여왕문제에 대한 백트랙킹 알고리즘
문제 : 어떤 두 여왕도 n * n 서양 장기판에서 같은 행, 열, 및 대각선 에 위치하지 않도록 n개의 여왕들을 서양장기판에 놓는 문제 입력 : 자연수 n 출력 : n * n 서양 장기판에서 어떤 두 여왕도 서로 같은 행, 열, 및 대각선에 있지 않도록 n * n 개의 여왕들을 놓는 모든 방법. 각 출력은 col[1]에서 col[n]까지의 1차원 배열로 나타낸다. Col[i]는 I 번째 행에 있는 여왕이 위치한 열을 말한다.

192
void queens (index i) { index j; if (promising(i)) if (i == n) cout << col[1] through col[n]; else for (j = 1; j <= n; j++) { // See if queen in (+1)st col[i+1] = j; // row can be positioned queens(i+1); // in each of the n columns. }
![void queens (index i) { index j; if (promising(i)) if (i == n) cout << col[1] through col[n]; else.](http://slidesplayer.org/slide/14753381/90/images/192/void+queens+%28index+i%29+%7B+index+j%3B+if+%28promising%28i%29%29+if+%28i+%3D%3D+n%29+cout+%3C%3C+col%5B1%5D+through+col%5Bn%5D%3B+else..jpg "for (j = 1; j <= n; j++) { // See if queen in (+1)st. col[i+1] = j; // row can be positioned. queens(i+1); // in each of the n columns. }")
193
bool promising (index i)
{ index k; bool switch; k = 1; switch = true; // Check if any queen threatens while (k < i && switch) { // queen in the ith row. if (col[i] == col[k] ∥abs(col[i] - col[k]) == i - k) switch = false; k++; } return switch;
 { // queen in the ith row. if (col[i] == col[k] ∥abs(col[i] - col[k]) == i - k) switch = false; k++; } return switch;")
194
백트랙팅을 사용하지 않은 깊이우선 탐색방법에 의해 검사되는 노드들의 수
백트랙킹 알고리즘에 의해 검사되는 노드들의 수 백트랙킹 알고리즘을 사용할 때 상태공간트리에 있는 유망한 노드들의 수 그림 6.9 ,173, , ,057 * * * 105 * * * 107 n

195
6.6 Monte Carlo 알고리즘 : 백트랙킹의 능률성 측정
1) 상태 공간 트리의 같은 레벨에 있는 모든 노드들을 검사할 때는 같은 유망함수(promising funtion)를 사용한다. 2) 상태 공간 트리의 같은 레벨에 있는 노드들은 같은 숫자의 자식노드들을 갖는다.
 상태 공간 트리의 같은 레벨에 있는 모든 노드들을 검사할 때는 같은 유망함수(promising funtion)를 사용한다. 2) 상태 공간 트리의 같은 레벨에 있는 노드들은 같은 숫자의 자식노드들을 갖는다.")
196
알고리즘 6.5 : Monte Carlo 예측시 문제 : Monte Carlo 알고리즘을 사용하여 백트랙킹 알고리즘의 능률성을 추정하시오. 입력 : 백트랙킹 알고리즘에 의해 해결되는 문제의 한 경우 출력 : 백트랙킹 알고리즘에 의해 얻어지는 축소된 상태 공간 트리 에 있는 노드들의 추정 개수. 다시 말해서 백트랙킹 알고리즘이 주어진 문제의 경우에 대한 모든 해답들을 얻기 위해서 검사해야 되는 노드들의 개수.

197
int estimate() { node v; int n, mprod, t, numnodes; v = root of state space tree; numnodes = 1; m = 1; mprod = 1; while (m != 0) { t = numer of children of v; mprod = mprod * m; numnodes = numnodes + mprod * t; m = number of promising children of v; } return numnodes;
 { t = numer of children of v; mprod = mprod * m; numnodes = numnodes + mprod * t; m = number of promising children of v; } return numnodes;")
198
int estimate_n_queens (int n) { index i, j, col[1..n];
알고리즘 6.6 : 알고리즘 6.4에 대한 Monte Carlo 추정시 문제 : n - 여왕문제에 대한 알고리즘 6.4의 능률성을 측정하시오. 입력 : 자연수 n 출력 : 알고리즘 6.4에 의해 얻어지는 축소된 상태 공간 트리에 있는 노드들의 추정치 int estimate_n_queens (int n) { index i, j, col[1..n]; int m, mprod, numnodes; set_of_index prom_children; i = 0; numnodes = 1; m = 1; mprod = 1;
![int estimate_n_queens (int n) { index i, j, col[1..n];](http://slidesplayer.org/slide/14753381/90/images/198/int+estimate_n_queens+%28int+n%29+%7B+index+i%2C+j%2C+col%5B1..n%5D%3B.jpg "알고리즘 6.6 : 알고리즘 6.4에 대한 Monte Carlo 추정시. 문제 : n - 여왕문제에 대한 알고리즘 6.4의 능률성을 측정하시오. 입력 : 자연수 n. 출력 : 알고리즘 6.4에 의해 얻어지는 축소된 상태 공간 트리에. 있는 노드들의 추정치. int estimate_n_queens (int n) { index i, j, col[1..n]; int m, mprod, numnodes; set_of_index prom_children; i = 0; numnodes = 1; m = 1; mprod = 1;")
199
while (m != 0 && i != n) { mprod = mprod * m; numnodes = numnodes + mprod * n; i++; // number of children t is n. m = 0; prom_children = ; // Initialize set of promising for (j = 1; j <= n; j++) { // children to empty. col[i] = j; if (promising(i) { // Determine promising m++; // children. prom_children = prom_children {j}; } // Function promising is the } // one in in Algorithm 6.4. if (m != 0) { j = random selection from prom_children; } return numnodes;
 { // children to empty. col[i] = j; if (promising(i) { // Determine promising. m++; // children. prom_children = prom_children {j}; } // Function promising is the. } // one in in Algorithm 6.4. if (m != 0) { j = random selection from prom_children; } return numnodes;")
200
제 7 장 NP 이론 7.1 개념 소개 7.2 문제의 풀기 어려움 7.3 최적화 문제 및 결정 문제 7.4 P와 NP의 개념
7.1 개념 소개 7.2 문제의 풀기 어려움 7.3 최적화 문제 및 결정 문제 7.4 P와 NP의 개념 7.5 NP-completeness 7.6 NP-hard 문제들 7.7 근사 알고리즘 7.8 연습문제

201
7.2 문제의 풀기 어려움(intractability)
정의 어떤 알고리즘의 최악의 시간 복잡도 W(n)이 입력크기의 다항식 함수에 의해 제한 받을 때, 우리는 그 알고리즘을 다항식-시간의 알고리즘(polynomial-time algorithm)이라고 한다. 다시 말해서, n을 알고리즘에 대한 입력의 크기라 할 때, 다음과 같은 다항식 P(n)이 존재하는 경우이다. W(n) ∈ O(p(n)) 보기 7.1 다항식 시간의 복잡도를 갖는 알고리즘 W(n) : 5n 1/2n2 + 4n n + n nlogn 다항식 시간의 복잡도를 갖지 않는 알고리즘 W(n) : 2n √n n! n
이 입력크기의 다항식 함수에 의해 제한 받을 때, 우리는 그 알고리즘을 다항식-시간의 알고리즘(polynomial-time algorithm)이라고 한다. 다시 말해서, n을 알고리즘에 대한 입력의 크기라 할 때, 다음과 같은 다항식 P(n)이 존재하는 경우이다. W(n) ∈ O(p(n)) 보기 7.1. 다항식 시간의 복잡도를 갖는 알고리즘. W(n) : 5n 1/2n2 + 4n 10n + n9 nlogn. 다항식 시간의 복잡도를 갖지 않는 알고리즘. W(n) : 2n 2√n n! 2 0.3n.")
202
문제들의 3가지 카테고리 1) 1st category : 다항식 시간의 복잡도를 갖는 알고리즘이 존재하는 문제들 * 리스트(1차원 배열)의 원소들을 오름차순으로 정렬하는 문제 : 시간 복잡도 (n lg n)의 알고리즘에 의해 해결 * 이미 정렬된 리스트 : 어떤 주어진 키를 탐색하는 문제에 대한 알고리즘의 복잡도는 (lg n) * 행렬식의 곱셈 문제 : 복잡도가 (n 2.38) 의 알고리즘에 의해 해결
의 알고리즘에 의해 해결. * 이미 정렬된 리스트 : 어떤 주어진 키를 탐색하는 문제에 대한. 알고리즘의 복잡도는 (lg n) * 행렬식의 곱셈 문제 : 복잡도가 (n 2.38) 의 알고리즘에 의해 해결.")
203
2) 2nd category : 풀기 여렵다(intractable)라고 증명된 문제들 * 시간 복잡도가 지수함수인 알고리즘 보다 더 능률적인 알고리즘이 없다고 증명된 문제들 * 결정할 수 없는 문제들 (indecidable problems) - 정지문제(halting problem) * 풀기는 어렵지만 결정할 수 있는문제들
 - 정지문제(halting problem) * 풀기는 어렵지만 결정할 수 있는문제들.")
204
3) 3rd category : 풀기 어렵다고 증명되지는 않았지만, 다항식 시간의 알고리즘이 아직 발견되지 않은 문제들 * 주어진 문제에 대하여 한 개의 해답만을 원할때, 0-1 배낭문제, 외판원 문제 * m≥3 일 때, m색의 채색문제(m-coloring problem)
")
205
while (switch && i < n) if (n % i == 0) // % returns the remainder
보기 7.2 알고리즘 7.1 : 소수인지를 판단하는 알고리즘 문제 : 입력으로 주어진 자연수가 소수(약수가 1과 자신뿐인 수) 인가를 결정하시오. 입력 : 자연수 n 출력 : yes 혹은 no. 만약 n이 소수이면 yes, 소수가 아니면 no bool prime (int n) { int i; bool switch; switch = true; i = 2; while (switch && i < n) if (n % i == 0) // % returns the remainder switch = false; // when n is divided by i else i++; return switch; }
 인가를 결정하시오. 입력 : 자연수 n. 출력 : yes 혹은 no. 만약 n이 소수이면 yes, 소수가 아니면 no. bool prime (int n) { int i; bool switch; switch = true; i = 2; while (switch && i < n) if (n % i == 0) // % returns the remainder. switch = false; // when n is divided by i. else i++; return switch; }")
206
주어진 알고리즘에 대한 입력의 크기(input size)는 입력을 택할 때 사용되는 글자(character)들의 개수이다.
정의 입력의 크기 주어진 알고리즘에 대한 입력의 크기(input size)는 입력을 택할 때 사용되는 글자(character)들의 개수이다. 최악의 시간 복잡도(worst-case time complexity) 어떤 주어진 알고리즘에 대하여 n이 이 알고리즘에 대한 입력의 크기라고 하고 W(n)을 이 알고리즘이 수행하는데 소요되는 스텝(step)들의 최대수라고 하면, 우리는 W(n)을 이 알고리즘의 최악의 시간 복잡도라고 정의한다. ※ Step : 어떤 구체적인 컴퓨터 하드웨어 및 프로그래밍언어 등에 영향을 받지 않는 비교, 산술 배정문 등
는 입력을 택할 때 사용되는 글자(character)들의 개수이다. 최악의 시간 복잡도(worst-case time complexity) 어떤 주어진 알고리즘에 대하여 n이 이 알고리즘에 대한 입력의 크기라고 하고 W(n)을 이 알고리즘이 수행하는데 소요되는 스텝(step)들의 최대수라고 하면, 우리는 W(n)을 이 알고리즘의 최악의 시간 복잡도라고 정의한다. ※ Step : 어떤 구체적인 컴퓨터 하드웨어 및 프로그래밍언어 등에. 영향을 받지 않는 비교, 산술 배정문 등.")
207
7.3 최적화 문제 및 결정 문제 보기 7.3 그래프 채색문제(Graph coloring problem) 최적화문제 : 그래프 채색문제란 가장 적은 색깔로서 서로 이웃하는 부분이 다른 색으로 채색 되도록 그래프를 채색하는 문제로서, 이 때의 색깔의 수(그래픽 채색수:chromatic number)를 구하는 문제이다. 결정문제 : 주어진 자연수 m에 대하여 최대한 m개의 색으로 채색하면서 그래프에 서로 이웃하는 부분이 같은 색으로 채색되지 않도록 색칠하는 것이 가능한가?
를 구하는 문제이다. 결정문제 : 주어진 자연수 m에 대하여 최대한 m개의 색으로 채색하면서 그래프에 서로 이웃하는 부분이 같은 색으로 채색되지 않도록 색칠하는 것이 가능한가")
208
보기 7.4 배낭문제(Knapsack problem) 최적화문제 : 크기가 서로 다른 각 물체를 배낭에 넣었을 때에 생기는 이익이 서로 다를 때, 가장 이익이 많이 발생하도록 배낭에 물체들을 집어넣을 때의 최대 이익값을 구하는 문제이다. 크기가 서로 다른 k개의 물건들을 크기가 M인 배낭속에 집어넣을 때 이익이 서로 다르다고 할 때, 이때 최대의 이익이 얻어지도록 배낭속에 물건들을 집어넣는다면 최대 이익값은 얼마인가? 결정문제 : 주어진 이익값 P에 대하여 배낭의 크기 M을 넘지 않으면서 이익이 적어도 P 이상이 되도록 배낭속에 서로 다른 k개의 물체들을 집어넣는 것이 가능한지 결정하시오.

209
해밀턴 회로의 결정문제 : 어떤 주어진 그래프에 대하여, 과연 해밀턴 회로가 존재하는가?
해밀턴 회로문제(Hamilton circuit problem) 및 외판원 문제(TSP : Traveling Salesperson Problem) 보기 7.5 해밀턴 회로의 결정문제 : 어떤 주어진 그래프에 대하여, 과연 해밀턴 회로가 존재하는가? 외판원 문제의 최적화문제 : 주어진 가중치 그래프(edge들에 가중치가 부여된 그래프)에 대하여, 최소의 가중치(여행경비)를 갖는 해밀턴 회로를 구하시오. 외판원 문제의 결정문제 : 어떤 가중치 그래프 및 자연수 k가 주어졌을 때, 전체 가중치가 많아야 k인 해밀턴 회로가 존재하는지의 여부를 결정하시오.
 및. 외판원 문제(TSP : Traveling Salesperson Problem) 보기 7.5. 해밀턴 회로의 결정문제 : 어떤 주어진 그래프에 대하여, 과연 해밀턴 회로가 존재하는가 외판원 문제의 최적화문제 : 주어진 가중치 그래프(edge들에 가중치가 부여된 그래프)에 대하여, 최소의 가중치(여행경비)를 갖는 해밀턴 회로를 구하시오. 외판원 문제의 결정문제 : 어떤 가중치 그래프 및 자연수 k가 주어졌을 때, 전체 가중치가 많아야 k인 해밀턴 회로가 존재하는지의 여부를 결정하시오.")
210
최적화문제 : 주어진 무방향 그래프의 최대당파에 대한 크기를 구하는 문제
보기 7.6 당파문제(Clique problem) 최적화문제 : 주어진 무방향 그래프의 최대당파에 대한 크기를 구하는 문제 결정문제 : 어떤 자연수 k가 주어졌을 때, 주어진 무방향 그래프에 크기가 적어도 k인 당파가 존재하는지의 여부를 결정하는 문제 A C B D E 그림 7.1 그래프 G
 최적화문제 : 주어진 무방향 그래프의 최대당파에 대한 크기를 구하는 문제. 결정문제 : 어떤 자연수 k가 주어졌을 때, 주어진 무방향 그래프에 크기가 적어도 k인 당파가 존재하는지의 여부를 결정하는 문제. A. C. B. D. E. 그림 7.1 그래프 G.")
211
결정문제 : 어떤 자연수 n에 대하여 p∏≤n을 만족하도록 작업들의 수행순서를 계획할 수 있는가를 결정하시오.
보기 7.7 벌금을 갖는 작업들의 계획문제 최적화문제 : 전체의 벌금을 최소화 하는 문제, 다시 말해서 전체의 벌금이 최소가 되도록 작업들을 어떤 순서로 수행시킬지를 계획하는 문제 결정문제 : 어떤 자연수 n에 대하여 p∏≤n을 만족하도록 작업들의 수행순서를 계획할 수 있는가를 결정하시오.

212
7.4 P와 NP의 개념 P : 다항식 간의 알고리즘에 의해 해결되는 결정문제들의 집합
정의 P : 다항식 간의 알고리즘에 의해 해결되는 결정문제들의 집합 NP : 비결정적인 알고리즘에 의해 다항식 시간 내에 해결되는 결정문제들의 집합 보기 7.8 알고리즘 7.2 : 비결정적인 방법으로 1차원 배열을 정렬 문제 : 주어진 1차원 배열(리스트)의 원소들을 비결정적인 방법 으로 오름차순으로 정렬하시오. 입력 : 자연수 n 및 1차원 배열 A 여기서 n은 A의 원소들의 갯수이다. 출력 : 오름차순으로 정렬된 배열 B
의 원소들을 비결정적인 방법. 으로 오름차순으로 정렬하시오. 입력 : 자연수 n 및 1차원 배열 A. 여기서 n은 A의 원소들의 갯수이다. 출력 : 오름차순으로 정렬된 배열 B.")
213
void nondet_sort (int A[], int B[], int n)
// sort the array A with a nondeterministic algorithm { int i, j; int B[]; B = 0; //initialize B to 0 for ( i =1; i <= n; i++) { j = choice[1..n]; if (B[j] != 0) failure; else B[j] = A[i]; } for (i = 1; i < n; i++) { // verify order if (B[i] > B[i +1]) failure; else { print B; success; }
![void nondet_sort (int A[], int B[], int n)](http://slidesplayer.org/slide/14753381/90/images/213/void+nondet_sort+%28int+A%5B%5D%2C+int+B%5B%5D%2C+int+n%29.jpg "// sort the array A with a nondeterministic algorithm. { int i, j; int B[]; B = 0; //initialize B to 0. for ( i =1; i <= n; i++) { j = choice[1..n]; if (B[j] != 0) failure; else B[j] = A[i]; } for (i = 1; i < n; i++) { // verify order. if (B[i] > B[i +1]) failure; else { print B; success; }")
214
NP의 비결정적인 알고리즘은 다음과 같은 두 단계를 거친다.
1) 비결정적 단계(nondeterministic phase) : 추측단계 주어진 문제의 구체적인 경우(instance)에 대하여 어떤 완전 스트링 S가 만들어진다. S는 주어진 문제의 구체적인 경우에 대한 해답으로 간주될 수 있으므로, 우리는 이 단계를 추측단계라고 한다. 경우에 따라서, S는 아무 의미가 없는 것일 수도 있다. 2) 결정적 단계(deterministic phase) : 검증단계 보통 우리가 생각하는 결정적 알고리즘이 앞의 비결정적 단계에서 얻어진 스트링 S를 입력으로 받아서 수행을 시작한다. 그러면 결정적 알고리즘은 언젠가는 종료되거나 혹은 무한 루프에 돌입하여 영원히 멈추지 않게 된다.
 비결정적 단계(nondeterministic phase) : 추측단계. 주어진 문제의 구체적인 경우(instance)에 대하여 어떤 완전 스트링 S가 만들어진다. S는 주어진 문제의 구체적인 경우에 대한 해답으로 간주될 수 있으므로, 우리는 이 단계를 추측단계라고 한다. 경우에 따라서, S는 아무 의미가 없는 것일 수도 있다. 2) 결정적 단계(deterministic phase) : 검증단계. 보통 우리가 생각하는 결정적 알고리즘이 앞의 비결정적 단계에서 얻어진 스트링 S를 입력으로 받아서 수행을 시작한다. 그러면 결정적 알고리즘은 언젠가는 종료되거나 혹은 무한 루프에 돌입하여 영원히 멈추지 않게 된다.")
215
bood verify (weighted_digraph G, number d, tour S) {
보기 7.9 알고리즘 7.3 : 외판원 문제에 대한 검증단계를 위한 알고리즘 입력 : 방향이 있는 그래프 G(G의 edge 마다 가중치가 있다.) 0 보다 큰 수 d, 그리고 여행경로 S 출력 : 참(true) 값 혹은 거짓(false) 값 bood verify (weighted_digraph G, number d, tour S) { if (S is a tour && the total weight of the edges in S is ≤d) return true; else return false; }
 0 보다 큰 수 d, 그리고 여행경로 S. 출력 : 참(true) 값 혹은 거짓(false) 값. bood verify (weighted_digraph G, number d, tour S) { if (S is a tour && the total weight of the edges in S is ≤d) return true; else. return false; }")
216
NP P 그림 7.2 모든 결정문제들의 집합 P에는 속하지 않으면서 NP에만 속하는 문제들은 아직 명확하게 알려지지 않았다.
정지문제(halting problem) Presburger 산술 등 그림 7.2 모든 결정문제들의 집합
 Presburger 산술 등. 그림 7.2 모든 결정문제들의 집합.")
217
7.5 NP-completeness 보기 7.10 CNF(Conjunctive Nomal form) 만족성(satisifiability) 문제 CNF로 주어진 어떤 논리적 표현식에 대하여 이 표현식을 참으로 만드는 논리적 배정이 존재하는가를 결정하는 문제이다. 보기 7.11 CNF (x1 ∨ x2 ∨ x3 )∧ (x1 ∨ x2 ) ∧ x3 에 대한 CNF 만족성 문제의 해답은 “yes”이다. 다시 말해서 주어진 CNF에 대해서는 논리적 변수 x1 , x2 및 x3 에 적당한 참 및 거짓을 배정하여 주어진 CNF의 결과를 참으로 만들 수 있다. 보기 7.12 CNF (x1 ∨ x2 )∧ x1 ∧ x2 에 대한 CNF 만족성 문제의 해답은 “no”이다. 다시 말해서 주어진 CNF에 대해서는 논리적 변수 x1 , x2 에 어떠한 참 및 거짓을 배정하여도 주어진 CNF를 참으로 만들 수가 없다.
∧ (x1 ∨ x2 ) ∧ x3 에 대한 CNF 만족성 문제의 해답은 yes 이다. 다시 말해서 주어진 CNF에 대해서는 논리적 변수 x1 , x2 및 x3 에 적당한 참 및 거짓을 배정하여 주어진 CNF의 결과를 참으로 만들 수 있다. 보기 CNF (x1 ∨ x2 )∧ x1 ∧ x2 에 대한 CNF 만족성 문제의 해답은 no 이다. 다시 말해서 주어진 CNF에 대해서는 논리적 변수 x1 , x2 에 어떠한 참 및 거짓을 배정하여도 주어진 CNF를 참으로 만들 수가 없다.")
218
두 번째 문제의 알고리즘을 사용하여 첫 번째 문제를 해결한다.
tran y = tran(x) 문제 B에 대한 알고리즘 yes 혹은 no인 해답 x 그림 7.3 문제 A에 대한 알고리즘 보기 7.13 1) 첫 번째 결정문제 : 주어진 n개의 논리적 변수에 대하여 이들 중 적어도 하나가 “참(true) 값을 갖는가? 2) 두 번째 결정문제 : 주어진 n개의 정수에 대하여 가장 큰 값이 자연수인가? k1, k2, … kn = tran( x1, x2, …, xn) 두 번째 문제의 알고리즘을 사용하여 첫 번째 문제를 해결한다.
 문제 B에 대한. 알고리즘. yes 혹은. no인 해답. x. 그림 7.3 문제 A에 대한 알고리즘. 보기 ) 첫 번째 결정문제 : 주어진 n개의 논리적 변수에 대하여 이들 중 적어도 하나가 참(true) 값을 갖는가 2) 두 번째 결정문제 : 주어진 n개의 정수에 대하여 가장 큰 값이 자연수인가 k1, k2, … kn = tran( x1, x2, …, xn) 두 번째 문제의 알고리즘을 사용하여 첫 번째 문제를 해결한다.")
219
만약 결정문제 B가 P에 속하며 A B 이면, 결정문제 A도 P에 속한다. [ 증명 ] page 330 참조
보기 7.14 만약 결정문제 A에서 결정문제 B로의 다항식 시간의 변환 알고리즘이 존재할 때, 우리는 문제 A가 문제 B로 다항식 시간으로 축약가능(reducible)하다고 정의하며, 문제 A가 문제 B로 축약된다고 이야기한다. 그리고 이 사실을 A B로 나타낸다. 정리 7.1 만약 결정문제 B가 P에 속하며 A B 이면, 결정문제 A도 P에 속한다. [ 증명 ] page 330 참조
![만약 결정문제 B가 P에 속하며 A B 이면, 결정문제 A도 P에 속한다. [ 증명 ] page 330 참조](http://slidesplayer.org/slide/14753381/90/images/219/%EB%A7%8C%EC%95%BD+%EA%B2%B0%EC%A0%95%EB%AC%B8%EC%A0%9C+B%EA%B0%80+P%EC%97%90+%EC%86%8D%ED%95%98%EB%A9%B0+A+%EF%82%B5+B+%EC%9D%B4%EB%A9%B4%2C+%EA%B2%B0%EC%A0%95%EB%AC%B8%EC%A0%9C+A%EB%8F%84+P%EC%97%90+%EC%86%8D%ED%95%9C%EB%8B%A4.+%5B+%EC%A6%9D%EB%AA%85+%5D+page+330+%EC%B0%B8%EC%A1%B0.jpg "보기 만약 결정문제 A에서 결정문제 B로의 다항식 시간의 변환 알고리즘이 존재할 때, 우리는 문제 A가 문제 B로 다항식 시간으로 축약가능(reducible)하다고 정의하며, 문제 A가 문제 B로 축약된다고 이야기한다. 그리고 이 사실을 A B로 나타낸다. 정리 7.1. 만약 결정문제 B가 P에 속하며 A B 이면, 결정문제 A도. P에 속한다. [ 증명 ] page 330 참조.")
220
문제 B가 다음 두 가지 조건들을 만족시킬 때, 우리는 문제 B를 NP-Complete 라고 한다. 1) B가 NP에 속한다
2) NP에 속하는 모든 다른 문제 A에 대하여 A B 이다. 정리 7.2 (Cook의 정리) CNF 만족성 문제는 NP-Complete 문제이다. [ 증명 ] Cook(1971) 및 Garey(1979) 참조 정리 7.3 다음 두 조건들이 성립될 때 문제 C는 NP-Complete이다. 1) 문제 C는 NP에 속한다. 2) 어떤 적당한 다른 NP-Complete 문제 B에 대하여 B C 이다. [ 증명 ] page 331 참조
 NP에 속하는 모든 다른 문제 A에 대하여 A B 이다. 정리 7.2. (Cook의 정리) CNF 만족성 문제는 NP-Complete 문제이다. [ 증명 ] Cook(1971) 및 Garey(1979) 참조. 정리 7.3. 다음 두 조건들이 성립될 때 문제 C는 NP-Complete이다. 1) 문제 C는 NP에 속한다. 2) 어떤 적당한 다른 NP-Complete 문제 B에 대하여 B C 이다. [ 증명 ] page 331 참조.")
221
보기 7.15 V = {(y, i) y는 Ci에서의 리터럴(literal)} E = {(y, i), (z, j) i j 이며 z y} (x1, 1) (x1, 2) (x2, 1) (x3, 1) (x2, 2) (x3, 2) 그림 (x1 ∨ x2 ∨ x3 )∧ (x1 ∨ x2 ∨ x3 )일 때의 그래프 G
 (x3, 1) (x2, 2) (x3, 2) 그림 7.4 (x1 ∨ x2 ∨ x3 )∧ (x1 ∨ x2 ∨ x3 )일 때의 그래프 G.")
222
보기 7.16 1 2 그림 7.5 방향이 없는 왼쪽의 그래프를 가중치가 있는 오른쪽의 그래프로 변환하는 알고리즘에 대한 보기

223
NP-complete P 보기 7.17 그림 7.6 복합수(Composite number)문제는 여기에 속할 수 있다
항상 “yes”라고 대답 하는 단순한 결정문제는 여기에 속함 복합수(Composite number)문제는 여기에 속할 수 있다 확실히 여기에 속하는 문제들이 존재한다. 그림 7.6
문제는 여기에 속할 수 있다. 확실히 여기에 속하는 문제들이 존재한다. 그림 7.6.")
224
bool composite_problem (int n, int m, int k) {
알고리즘 7.4 : 복합수 문제에 관한 알고리즘 문제 : 주어진 세 자연수에 대하여, 가장 큰 자연수가 나머지 두 자연수 들에 대한 복합수인가? 입력 : 1 보다 큰 세 자연수 n, m 및 k 출력 : 참 값 혹은 거짓 값. 만약 가장 큰 자연수가 나머지 두 자연수들에 대한 복합수이면, 참 값을 리턴하며, 아니라면 거짓 값을 리턴한다. bool composite_problem (int n, int m, int k) { if (m and k are both integers && m, k > 1 && n == m * k) return true; else return false; }
 { if (m and k are both integers && m, k > 1 && n == m * k) return true; else. return false; }")
225
7.6 NP-hard 문제들 만약 P NP이면 NP - (P NP-Complete) 이다.
정리 7.4 만약 P NP이면 NP - (P NP-Complete) 이다. 7.6 NP-hard 문제들 문제 B에 대한 어떤 가상적인 알고리즘에 의하여 문제 A가 다항식 시간 안에 해결될 때, 우리는 문제 A가 문제 B로 다항식 시간의 튜어링 축약가능(polynomial-time Turing reducible)하다고 정의한다. 그리고 이 사실을 A TB로 표시한다. 어떤 NP-Complete 문제 A에 대하여 만약 A TB 이면 우리는 이 문제 B를 NP-hard 문제라고 정의한다..
 이다. 7.6 NP-hard 문제들. 문제 B에 대한 어떤 가상적인 알고리즘에 의하여 문제 A가 다항식. 시간 안에 해결될 때, 우리는 문제 A가 문제 B로 다항식 시간의. 튜어링 축약가능(polynomial-time Turing reducible)하다고 정의한다. 그리고 이 사실을 A TB로 표시한다. 어떤 NP-Complete 문제 A에 대하여 만약 A TB 이면 우리는. 이 문제 B를 NP-hard 문제라고 정의한다..")
226
만약 NP에 있는 어떤 문제 B에 대하여 A TB 라면 우리는 이 문제 A를 NP-easy 문제라고 정의한다.
보기 7.19 만약 P = NP 이면, 어떤 문제도 여기에 있지 않으며, 만약 P NP이면, P의 모든 문제들이 여기에 있다. 모든 문제들 NP-hard NP-Complete 그림 7.7 모든 문제들의 집합과의 관계 만약 NP에 있는 어떤 문제 B에 대하여 A TB 라면 우리는 이 문제 A를 NP-easy 문제라고 정의한다.

227
만약 어떤 문제가 NP-hard인 동시에 NP-easy이면 우리는 이 문제를 NP-equivalent 문제라고 정의한다.
보기 7.20 만약 어떤 문제가 NP-hard인 동시에 NP-easy이면 우리는 이 문제를 NP-equivalent 문제라고 정의한다.

228
7.7 근사 알고리즘 꼭지점을 잇는 에지에 방향이 없으며 가중치가 있는 그래프 G = (V, E)
7.7 근사 알고리즘 보기 7.20 삼각 부등식이 있는 외판원 문제 꼭지점을 잇는 에지에 방향이 없으며 가중치가 있는 그래프 G = (V, E) 가 다음 두 조건을 만족한다고 하자. 1) 서로 다른 두 꼭지점 사이를 연결하는 에지가 반드시 존재한다. 2) 꼭지점 u에서 꼭지점 v를 잇는 에지가 있는 가중치를 c(u, v)라고 나타낼 때, 모든 다른 꼭지점 u에 대하여 c(u, v) <= c(u, w) + c(w, v)가 성립한다. 삼각 부등식(triangular inequality) u v w 그림 7.8 삼각부등식에 대한 그림
 가 다음 두 조건을 만족한다고 하자. 1) 서로 다른 두 꼭지점 사이를 연결하는 에지가 반드시 존재한다. 2) 꼭지점 u에서 꼭지점 v를 잇는 에지가 있는 가중치를 c(u, v)라고. 나타낼 때, 모든 다른 꼭지점 u에 대하여 c(u, v) <= c(u, w) + c(w, v)가. 성립한다. 삼각 부등식(triangular inequality) u. v. w. 그림 7.8 삼각부등식에 대한 그림.")
229
그림 7.9 최소신장트리로 부터 최적의 여행경로에 대한 근사값을 구하는 과정
3 2 4 2 2 2 2 (a) 최초에 주어진 방향이 없는 그래프 각 에지마다 가중치가 표시되어 있다. (b) (a)에 대한 최소 신장트리 3 2 4 4 2 2 start (c) (b)의 각 꼭지점 주위로 두 번 왕복 (d) 지름길이 있는 회로 그림 7.9 최소신장트리로 부터 최적의 여행경로에 대한 근사값을 구하는 과정
 최초에 주어진 방향이 없는 그래프. 각 에지마다 가중치가 표시되어 있다. (b) (a)에 대한 최소 신장트리 start. (c) (b)의 각 꼭지점 주위로 두 번 왕복. (d) 지름길이 있는 회로. 그림 7.9 최소신장트리로 부터 최적의 여행경로에 대한 근사값을 구하는 과정.")
230
그림 7.10 (a) 최소신장트리 (c) (b)에서 지름길이 선택된 다음의 그래프 (b) 꼭지점들이 짝짓기하여
쌍을 이루고 에지들이 트리에 더해진 그래프 그림 7.10

231
app_minimum2 < 2 * min_distance
정리 7.5 최적 여행경로에 대한 전체 가중치를 min_distance, 위에서 설명한 방법에 의해 얻어진 여행경로에 대한 전체 가중치를 app_minimum 이라고 하자. 그러면 다음의 부등식이 성립한다. app_minimum2 < 2 * min_distance [증명] 최소 신장트리의 전체 가중치는 min_distance 보다 적다. 또한 app_minimum의 전체 가중치는 두 최소 신장트리의 전체 가중치를 더한 것보다 크지 않다. 정리 7.6 최적 여행경로의 전체 가중치를 min_distance, 방금 소개한 두 번째 근사 알고리즘에 의해 얻어진 여행 경로의 전체 가중치를 app_minimum2라고 하자. 그러면 다음의 부등식이 성립한다. app_minimum2 < 1.5 * min_distance [증명] page 351 참조

232
제 8 장 병렬 컴퓨터 및 병렬 알고리즘 8.1 소개 8.2 PRAM(Parallel Random Access Machine)
제 8 장 병렬 컴퓨터 및 병렬 알고리즘 8.1 소개 8.2 PRAM(Parallel Random Access Machine) 8.3 다른 병렬 컴퓨터 모형들 8.4 연습문제
 8.3 다른 병렬 컴퓨터 모형들. 8.4 연습문제.")
233
8.1 소개 >> 명령어에 의해 데이터가 처리되는 방법에 따른 컴퓨터의 분류
8.1 소개 처리기 기억장치 그림 8.1 재래의 순차적인 컴퓨터 >> 명령어에 의해 데이터가 처리되는 방법에 따른 컴퓨터의 분류 1) SISD(Single Instruction stream, Single Data stream) 2) MISD(Multiple Instruction steam, Single Data stream) 처리기 기억장치 처리기 • • • 처리기 그림 8.2 MISD 컴퓨터
 SISD(Single Instruction stream, Single Data stream) 2) MISD(Multiple Instruction steam, Single Data stream) 처리기. 기억장치. 처리기. • • • 처리기. 그림 8.2 MISD 컴퓨터.")
234
3) SIMD(Single Instruction stream, Multiple Data stream)
광역제어장치 처리기 • • • 그림 8.3 SISD 컴퓨터 상호연결 네트워크 (Interconnection Network)
")
235
4) MIMD(Multiple Instruction stream, Multiple Data stream)
처리기 제어장치 • • • 그림 8.4 MIMD 컴퓨터 상호연결 네트워크 (Interconnection Network)
")
236
8.2 PRAM(Parallel Random Access Machine)
처리기 제어장치 • • • 그림 8.5 PRAM 모형 상호연결 네트워크 (Interconnection Network) 공동 기억장치
 공동. 기억장치.")
237
1) EREW(Exclusive Read Exclusive Write)
주어진 시간대에 오직 한 처리기만이 공동 기억장치에 입.출력을 할 수 있으며, 이 동안에 다른 처리기들은 공동 기억장치에 접근할 수 없다. 2) ERCW(Exclusive Read Concurrent Write) 여러 개의 처리기들이 동시에 공동 기억장치에 출력하는(쓰는) 것은 가능하지만, 오직 한 처리기만이 독점적으로 읽는 것만이 가능하다. 3) CREW(Concurrent Read Exclusive Write) 여러 개의 처리기들이 동시에 공동 기억장치에 읽는 것이 가능하지만, 오직 한 처리기만이 독점적으로 쓰는 것이 가능하다. 4) CRCW(Concurrent Read Concurrent Write) 여러 개의 처리기들이 동시에 공동 기억장치를 읽는 것이 가능하지만, 오직 한 처리기만이 독점적으로 쓰는 것이 가능하다.
 ERCW(Exclusive Read Concurrent Write) 여러 개의 처리기들이 동시에 공동 기억장치에 출력하는(쓰는) 것은 가능하지만, 오직 한 처리기만이 독점적으로 읽는 것만이 가능하다. 3) CREW(Concurrent Read Exclusive Write) 여러 개의 처리기들이 동시에 공동 기억장치에 읽는 것이 가능하지만, 오직 한 처리기만이 독점적으로 쓰는 것이 가능하다. 4) CRCW(Concurrent Read Concurrent Write) 여러 개의 처리기들이 동시에 공동 기억장치를 읽는 것이 가능하지만, 오직 한 처리기만이 독점적으로 쓰는 것이 가능하다.")
238
A B (A, B)의 우승자 C D (C, D)의 우승자 E F (E, F)의 우승자 G H (G, H)의 우승자 (A, B, C, D)의 우승자 (E, F, G, H)의 우승자 (A, B, C, D, E, F, G, H)의 우승자 즉 최종우승자 그림 8.6 토너먼트 방식의 최종우승자 선발
의 우승자. (A, B, C, D, E, F, G, H)의 우승자. 즉 최종우승자. 그림 8.6 토너먼트 방식의 최종우승자 선발.")
239
알고리즘 8.1 : CREW PRAM 모형으로 배열에서 병렬계산으로
최대값 구하기 문제 : n 개의 원소를 갖는 1차원 배열 A에서 최대값을 구하시오. 입력 : 자연수 n 및 n 개의 원소를 갖는 1차원 배열 A 출력 : A의 최대값 (A에서 가장 큰 원소) 비고 : n은 2의 지수승이고 사용되는 처리기는 n/2이며 각 처리기 는 1, 2, 3, …, n/2 등으로 인덱스 되었다.
 비고 : n은 2의 지수승이고 사용되는 처리기는 n/2이며 각 처리기. 는 1, 2, 3, …, n/2 등으로 인덱스 되었다.")
240
keytype parallel_largest (int n, keytype A[]) {
index step, size; local index p; local keytype first, second; p = index of this processor; size = 1; // size is the size of the subarrays for (step = 1; step <= lg n; step++) if (this processor needs to execute in this step) { read A[2*p-1] into first; read A[2*p-1 + size] into second; write maximum(first, second) into A[2*p-1]; size = 2 * size; } return A[];
![keytype parallel_largest (int n, keytype A[]) {](http://slidesplayer.org/slide/14753381/90/images/240/keytype+parallel_largest+%28int+n%2C+keytype+A%5B%5D%29+%7B.jpg "index step, size; local index p; local keytype first, second; p = index of this processor; size = 1; // size is the size of the subarrays. for (step = 1; step <= lg n; step++) if (this processor needs to execute in this step) { read A[2*p-1] into first; read A[2*p-1 + size] into second; write maximum(first, second) into A[2*p-1]; size = 2 * size; } return A[];")
241
그림 8.7 토너먼트 방식에 바탕을 둔 병렬 알고리즘 8.1로 최대값을 구하는 과정
22 first 1 20 second 1 15 first 2 25 second 2 28 first 3 second 3 14 first 4 26 second 4 P1 P2 P3 P4 A Read Write larger 최대값 그림 8.7 토너먼트 방식에 바탕을 둔 병렬 알고리즘 8.1로 최대값을 구하는 과정

242
>> 충돌문제를 해결하는 몇 가지 방법
1) 모든 처리기들이 같은 값만을 출력시키려고 하는 경우에 한하여 공동 기억장치에 동시 출력을 허용한다. 2) k 개의 처리기들이 동시 출력을 원할 때, 이 중에서 한 처리기만이 임의로 선택하여 공동 기억장치에의 출력을 허용한다. 3) 미리 우선 순위에 의해 PRAM을 구성하는 모든 처리기들을 공동 기억장치에 출력이 허가되는 우선 순위를 부여한다. 그리하여 k 개 의 처리기들이 공동 기억장치에 동시 출력을 원한다면, 이 중에서 가장 높은 우선 순위를 갖는 처리기에게 공동 기억장치에의 접근 을 허용한다.
 모든 처리기들이 같은 값만을 출력시키려고 하는 경우에 한하여. 공동 기억장치에 동시 출력을 허용한다. 2) k 개의 처리기들이 동시 출력을 원할 때, 이 중에서 한 처리기만이. 임의로 선택하여 공동 기억장치에의 출력을 허용한다. 3) 미리 우선 순위에 의해 PRAM을 구성하는 모든 처리기들을 공동. 기억장치에 출력이 허가되는 우선 순위를 부여한다. 그리하여 k 개. 의 처리기들이 공동 기억장치에 동시 출력을 원한다면, 이 중에서. 가장 높은 우선 순위를 갖는 처리기에게 공동 기억장치에의 접근. 을 허용한다.")
243
그림 8.11 병렬 알고리즘 8.2의 수행 과정 P12 P13 P14 P23 P24 P34 Read Compare
25 first12 20 second12 P12 first13 28 second13 P13 first14 22 second14 P14 first23 second23 P23 first24 second24 P24 first34 second34 P34 A B B Read Compare and write 그림 병렬 알고리즘 8.2의 수행 과정

244
keytype parallel_largest2 (int n, const keytype A[]) { int B[1..n];
알고리즘 8.2 : CREW PRAM 모형으로 배열에서 병렬계산으로 최대값 구하기 문제 : n 개의 원소를 갖는 1차원 배열 A에서 최대값을 구하시오. 입력 : 자연수 n 및 n 개의 원소를 갖는 1차원 배열 A 출력 : A의 최대값 (A에서 가장 큰 원소) 비고 : n은 2의 지수승이고 사용되는 처리기는 n(n-1)/2개 이며 각 처리기는 P[i][j] (1 <= i < j <= n)로 인덱스 되었다. keytype parallel_largest2 (int n, const keytype A[]) { int B[1..n]; local index i, j; local keytype first, second; local int chkfrst, chkcnd; i = first index of this processor; j = second index of this processor;
![keytype parallel_largest2 (int n, const keytype A[]) { int B[1..n];](http://slidesplayer.org/slide/14753381/90/images/244/keytype+parallel_largest2+%28int+n%2C+const+keytype+A%5B%5D%29+%7B+int+B%5B1..n%5D%3B.jpg "알고리즘 8.2 : CREW PRAM 모형으로 배열에서 병렬계산으로. 최대값 구하기. 문제 : n 개의 원소를 갖는 1차원 배열 A에서 최대값을 구하시오. 입력 : 자연수 n 및 n 개의 원소를 갖는 1차원 배열 A. 출력 : A의 최대값 (A에서 가장 큰 원소) 비고 : n은 2의 지수승이고 사용되는 처리기는 n(n-1)/2개 이며 각. 처리기는 P[i][j] (1 <= i < j <= n)로 인덱스 되었다. keytype parallel_largest2 (int n, const keytype A[]) { int B[1..n]; local index i, j; local keytype first, second; local int chkfrst, chkcnd; i = first index of this processor; j = second index of this processor;")
245
write 1 into B[i]; // Because 1 <= i <= n-1 and
write 1 into B[j]; // 2 <= j <= n, these write read A[i] into first; // instructions initialize each read A[j] into second; // array element of B to 1. if (first < second) write 0 into B[i]; // B[k] ends up 0 if and only else // if A[k] loses at least one write 0 into B[j]; // comparison. read B[i] into chkfrst; read B[j] into chkscnd; // B[k] still equals 1 if and only if (chkfrst == 1) // if A[k] contains the largest key return A[i]; // Need to check B[j] in case else if (chkscnd == 1) // the largest key is A[n]. return A[j]; // Recall i ranges in value only } // from 1 to n-1.
![write 1 into B[i]; // Because 1 <= i <= n-1 and](http://slidesplayer.org/slide/14753381/90/images/245/write+1+into+B%5Bi%5D%3B+%2F%2F+Because+1+%3C%3D+i+%3C%3D+n-1+and.jpg "write 1 into B[j]; // 2 <= j <= n, these write. read A[i] into first; // instructions initialize each. read A[j] into second; // array element of B to 1. if (first < second) write 0 into B[i]; // B[k] ends up 0 if and only. else // if A[k] loses at least one. write 0 into B[j]; // comparison. read B[i] into chkfrst; read B[j] into chkscnd; // B[k] still equals 1 if and only. if (chkfrst == 1) // if A[k] contains the largest key. return A[i]; // Need to check B[j] in case. else if (chkscnd == 1) // the largest key is A[n]. return A[j]; // Recall i ranges in value only. } // from 1 to n-1.")
246
알고리즘 8.3 : 병렬 합병 정렬 문제 : n 개의 키를 병렬 계산에 의해 오름차순으로 정렬하시오. 입력 : 자연수 n 및 n 개의 원소를 갖는 1차원 배열 A 출력 : 오름차순으로 정렬된 배열 A 비고 : n 이 2의 지수승이고 병렬 알고리즘 8.3을 수행하기 위해 n/2개 의 처리기들이 있으며 n/2 개의 처리기들은 1, 2, …, n/2 으로 인덱스 되었다고 가정한다.

247
void parallel_mergesort (int n, keytype A[]) {
index step, size; local index p, low, mid, high; p = index of this processor; size = 1; for (step = 1; step <= lg n; step++) if (this processor needs to execute in this step) { low = 2 * p - 1; mid = low + size - 1; high = low + 2 * size - 1; parallel_merge(low, mid, high, A); size = 2 * size; }
![void parallel_mergesort (int n, keytype A[]) {](http://slidesplayer.org/slide/14753381/90/images/247/void+parallel_mergesort+%28int+n%2C+keytype+A%5B%5D%29+%7B.jpg "index step, size; local index p, low, mid, high; p = index of this processor; size = 1; for (step = 1; step <= lg n; step++) if (this processor needs to execute in this step) { low = 2 * p - 1; mid = low + size - 1; high = low + 2 * size - 1; parallel_merge(low, mid, high, A); size = 2 * size; }")
248
void parallel_merge (local index low, local index mid,
local index high, keytype A[]) { local index i, j, k; local keytype first, second, U[low..high]; i = low; j = mid + 1; k = low; while (i <= mid && j <= high) { read A[] into first; read A[j] into second; if (first < second) { U[k] = first; i++; }
 { local index i, j, k; local keytype first, second, U[low..high]; i = low; j = mid + 1; k = low; while (i <= mid && j <= high) { read A[] into first; read A[j] into second; if (first < second) { U[k] = first; i++; }")
249
else { U[k] = second; j++; } k++; if (i > mid) read A[j] through A[high] into U[k] through U[high]; else read A[i] through A[mid] into U[k] through U[high]; write U[low] through U[high] into A[low] through A[high];
![else { U[k] = second; j++; } k++; if (i > mid) read A[j] through A[high] into U[k] through U[high];](http://slidesplayer.org/slide/14753381/90/images/249/else+%7B+U%5Bk%5D+%3D+second%3B+j%2B%2B%3B+%7D+k%2B%2B%3B+if+%28i+%3E+mid%29+read+A%5Bj%5D+through+A%5Bhigh%5D+into+U%5Bk%5D+through+U%5Bhigh%5D%3B.jpg "else. read A[i] through A[mid] into U[k] through U[high]; write U[low] through U[high] into A[low] through A[high];")
250
알고리즘 8.4 : 이항계수에 대한 병렬 알고리즘 문제 : 이항계수 의 값을 병렬 계산으로 구하시오. 입력 : 음이 아닌 두 정수 n 및 k (단, n >= k) 출력 : 의 값 비고 : 알고리즘 8.4를 병렬로 수행하려면 k + 1개의 처리기가 필요하며, 각 처리기는 0, 1, …, k로 인덱스 되었다고 가정한다. n! k!(n-k)! n k = n k
! n. k. = n. k.")
251
int parallel_bin (int n, int k) { // Use i instead of step to
index i; // control the steps to be int B[0..n][0..k]; // consistent with Algorithm 5.2. local index j; // Use j instead of p to obtain local int first, second; // index of processor to be j = index of this processor; // consistent with Algorithm 5.2. for (i = 0; i <= n; i++) if (j <= minimum(i, k)) if (j == 0 j == i) write 1 into B[i][j]; else { read B[i-1][j-1] into first; read B[i-1][j] into second; write first + second into B[i][j]; } return B[n][k];
 if (j <= minimum(i, k)) if (j == 0 j == i) write 1 into B[i][j]; else { read B[i-1][j-1] into first; read B[i-1][j] into second; write first + second into B[i][j]; } return B[n][k];")
252
그림 8.9

253
void parallel_matrix_mult (int n, const number A[],
알고리즘 8.5 : 행렬의 곱에 대한 병렬 알고리즘 문제 : 두 개의 n * n 정방행렬 A와 B가 주어졌고, 처음에 A[i][j] 및 B[i][j]가 P[i][j]에 위치할 때, C = A * B를 구하시오. 단, C[i][j]는 P[i][j]에 위치한다. 입력 : 두 개의 정방행렬 A와 B 출력 : C(A와 B의 곱셈 결과) void parallel_matrix_mult (int n, const number A[], const number B[][], number C[][]) { index i, j, k;
![void parallel_matrix_mult (int n, const number A[],](http://slidesplayer.org/slide/14753381/90/images/253/void+parallel_matrix_mult+%28int+n%2C+const+number+A%5B%5D%2C.jpg "알고리즘 8.5 : 행렬의 곱에 대한 병렬 알고리즘. 문제 : 두 개의 n * n 정방행렬 A와 B가 주어졌고, 처음에 A[i][j] 및. B[i][j]가 P[i][j]에 위치할 때, C = A * B를 구하시오. 단, C[i][j]는 P[i][j]에 위치한다. 입력 : 두 개의 정방행렬 A와 B. 출력 : C(A와 B의 곱셈 결과) void parallel_matrix_mult (int n, const number A[], const number B[][], number C[][]) { index i, j, k;")
254
for all rows do in parallel
shift row i of A to the left i steps // namely, perform A[i][j] = A[i][(j+1) mod n] i times for all columns do in parallel shift column j of B upwards j steps // namely, perform B[i][j] = B[(i+1) mod n][j] j times // the data is now in the proper starting positions for all i and j do in parallel C[i][j] = A[i][j] * B[i][j]; for (k = 1; k <= n-1; k++) for all i and j do in parallel { A[i][j] = A[i][(j+1) mod n]; B[i][j] = B[(i+1) mod n][j]; C[i][j] = C[i][j] + A[i][j] * B[i][j] }
 mod n] i times. for all columns do in parallel. shift column j of B upwards j steps. // namely, perform B[i][j] = B[(i+1) mod n][j] j times. // the data is now in the proper starting positions. for all i and j do in parallel. C[i][j] = A[i][j] * B[i][j]; for (k = 1; k <= n-1; k++) for all i and j do in parallel { A[i][j] = A[i][(j+1) mod n]; B[i][j] = B[(i+1) mod n][j]; C[i][j] = C[i][j] + A[i][j] * B[i][j] }")
255
8.3 다른 병렬 컴퓨터 모형들 (a) 3차원 정육각형 하이퍼큐브 (차원 d = 3) (b) 제한된 차수 네트워크 (차수 4)
8.3 다른 병렬 컴퓨터 모형들 (a) 3차원 정육각형 하이퍼큐브 (차원 d = 3) (b) 제한된 차수 네트워크 (차수 4) 그림 8.10
 3차원 정육각형 하이퍼큐브. (차원 d = 3) (b) 제한된 차수 네트워크. (차수 4) 그림")
256
The end

Similar presentations

.>")
 2016. 5. 26 순천향대학교 컴퓨터공학과 하 상 호.>")
 자료구조의 개요 1) 자료구조 ① 일련의 자료들을 조직하고 구조화하는 것 ② 자료의 표현과 그것과 관련된 연산 2) 자료구조에 따라 저장공간의 효율성과 프로그램의 실행시간이 달라짐 3) 어떠한 자료구조에서도 필요한 모든 연산들을 처리하는 것이.>")





(1/2)>")
 알고리즘 개요 (효율, 분석, 차수) Part 1 강원대학교 컴퓨터과학전공 문양세.>")


>")



 문제>")


.>")