Download presentation
Presentation is loading. Please wait.

1
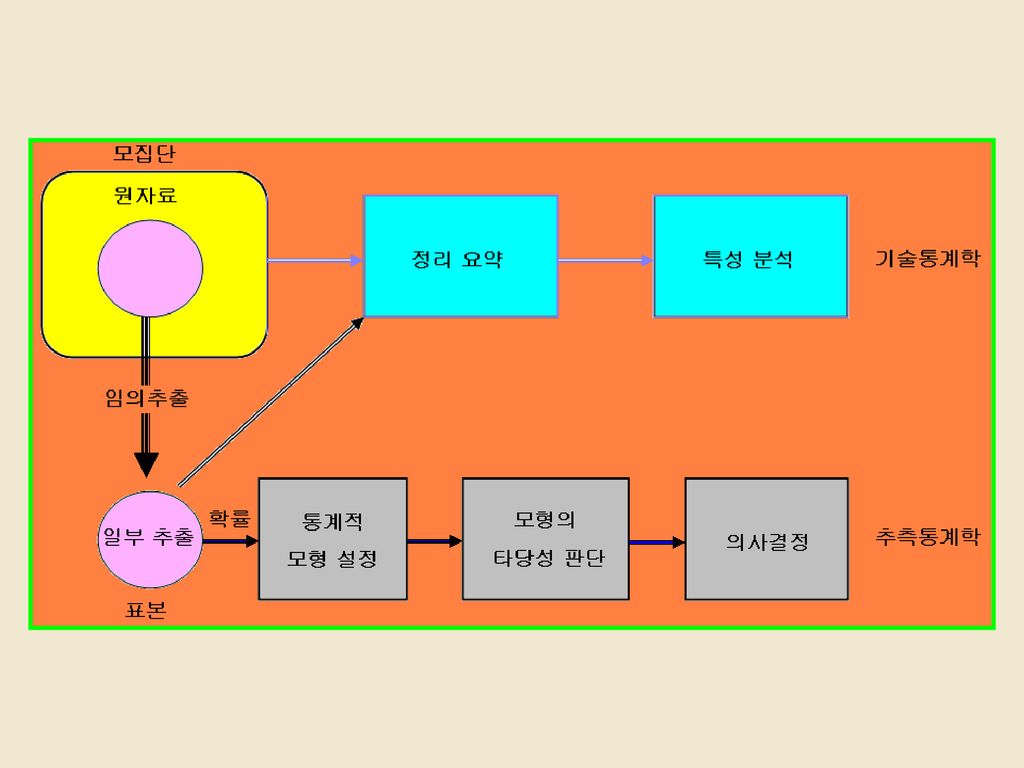
기 술 통 계 학 6 1 기술통계학 2 자료의 정리 3 위치척도 4 산포의 척도

2
1 기술통계학 기술통계학에 대한 이해와 기술통계학에서 사용되는 여러 용어들에 대하여 알아본다.

3
▶ ▶ ▶ 통계학(statistics) : 일회성으로 끝나는 것이 아니라 연속성과
객관성 있는 통계조사 또는 통계실험 결과를 다루는 학문 ▶ 전수조사(census) : 인구 총조사와 같이 통계조사의 대상이 되는 전체를 조사하는 방법 (시간적․공간적, 경제적으로 많은 제약) ▶ 표본조사(sample survey) : 개개의 요소들이 선정될 가능성을 동등하게 부여하여 객관적이고 공정하게 일부 요소만을 선택하여 (임의추출;random sampling) 조사하는 방법
 : 인구 총조사와 같이 통계조사의 대상이. 되는 전체를 조사하는 방법. (시간적․공간적, 경제적으로 많은 제약) ▶ 표본조사(sample survey) : 개개의 요소들이 선정될 가능성을. 동등하게 부여하여 객관적이고 공정하게 일부 요소만을 선택하여. (임의추출;random sampling) 조사하는 방법.")
4
▶ ▶ ▶ ▶ 모집단(population) : 통계실험의 모든 대상들의 집합 자료집단(data set) : 조사내용의 집합
예) 가구원 수의 집합 {1인, 2인, 3인, 4인, 5인, 6인이상} 자료(data) : 자료집단 개개의 성분 ▶ 관찰값(observation) : 각 자료의 관찰되거나 측정된 값 ▶
 가구원 수의 집합 {1인, 2인, 3인, 4인, 5인, 6인이상} 자료(data) : 자료집단 개개의 성분. ▶ 관찰값(observation) : 각 자료의 관찰되거나 측정된 값. ▶")
5
▶ ▶ ▶ ▶ 표본(sample) : 모집단으로부터 추출된 일부 대상들의 집합
원자료(raw data) : 통계적으로 처리되지 않은 최초의 수집된 자료 ▶ 기술통계학(descriptive statistics) : 자료를 수집, 정리하여 자료가 갖는 특성을 표, 그래프 또는 그림 등에 의하여 나타내거나 분석하는 통계학의 일부 ▶ 추측통계학(inferential statistics) : 표본을 대상으로 얻은 정보 로부터 전체 자료가 갖는 특성을 과학적으로 추론하는 통계학의 일부
 : 통계적으로 처리되지 않은 최초의 수집된. 자료. ▶ 기술통계학(descriptive statistics) : 자료를 수집, 정리하여. 자료가 갖는 특성을 표, 그래프 또는 그림 등에 의하여 나타내거나. 분석하는 통계학의 일부. ▶ 추측통계학(inferential statistics) : 표본을 대상으로 얻은 정보. 로부터 전체 자료가 갖는 특성을 과학적으로 추론하는 통계학의. 일부.")
6
▶ ▶ ▶ ▶ ▶ 모수(parameter) : 모집단의 특성을 나타내는 수치
유한모집단(finite population) : 유한 개의 자료로 구성된 모집단 ▶ 무한모집단(infinite population) : 셈할 수 있는 개수로 구성되거나 관찰값이 구간으로 나타나는 모집단 ▶ 이산자료(discrete data) : 모집단이 유한하거나 셈할 수 있는 개수로 구성되는 자료 ▶ 연속자료(conrinuous data) : 이산자료가 아닌 무한모집 단을 구성하는 자료
 : 유한 개의 자료로 구성된. 모집단. ▶ 무한모집단(infinite population) : 셈할 수 있는 개수로. 구성되거나 관찰값이 구간으로 나타나는 모집단. ▶ 이산자료(discrete data) : 모집단이 유한하거나 셈할 수. 있는 개수로 구성되는 자료. ▶ 연속자료(conrinuous data) : 이산자료가 아닌 무한모집. 단을 구성하는 자료.")
8
2 자료의 정리 점도표를 비롯한 여러 가지 그림에 의하여 자료를 정리하여 그 자료의 특성을 조사하는 방법에 대하여 알아본다.

9
▶ ▶ ▶ ▶ ▶ 질적자료(qualitative data), 범주형 자료(categorical data) :
피부색이나 혈액형 또는 지역명과 같이 숫자에 의하여 표현되지 않는 자료 ▶ 양적자료(quantitative data) : 자료가 숫자로 표현되며, 그 숫자 가 의미를 갖는 자료. 크기와 대소관계를 비교가능 ▶ 명목자료(nominal data) : 숫자 그 자체로는 아무런 의미가 없고 단지 범주를 사용하기 편하도록 숫자로 대치한 자료 ▶ 순서자료(ordinal data) : 순서의 개념을 갖는 질적자료 ▶ 집단화자료(grouped data) : 양적자료인 시험성적을 90점이상 A, 80∼89는 B, 70∼79는 C, 60∼69는 D 그리고 59점 이하는 F라는 범주로 묶어서 나타내는 자료 A, B, C, D, F
 : 자료가 숫자로 표현되며, 그 숫자. 가 의미를 갖는 자료. 크기와 대소관계를 비교가능. ▶ 명목자료(nominal data) : 숫자 그 자체로는 아무런 의미가 없고. 단지 범주를 사용하기 편하도록 숫자로 대치한 자료. ▶ 순서자료(ordinal data) : 순서의 개념을 갖는 질적자료. ▶ 집단화자료(grouped data) : 양적자료인 시험성적을 90점이상. A, 80∼89는 B, 70∼79는 C, 60∼69는 D 그리고 59점 이하는. F라는 범주로 묶어서 나타내는 자료 A, B, C, D, F.")
10
점도표(dot-plot) 점도표는 질적자료뿐만 아니라 양적자료에도 사용할 수 있으며, 원자료의 특성을 그림으로 나타내는 가장 간단한 방법이다. 수평축에 범주 또는 측정값을 기입하고, 수직축에 그들의 관찰 도수를 기입한다. ⊙ 장점 : 자료의 정확한 위치를 알 수 있으며, 수집한 자료의 흩어진 모양을 쉽게 파악 ⊙ 단점 : 자료의 수에 해당하는 점을 찍어서 나타내므로 그 수가 매우 많은 경우에는 부적당하다 9 4 5 7 인 원 O형 AB형 B형 A형 혈액형

11
도수분포표(frequency table)
질적자료에 사용하며, 각 범주와 그에 대응하는 도수 그리고 상대도수 등을 나열한 도표 범 주 도수 상대도수(%) A형 7 28 B형 4 16 AB형 5 20 O형 9 36 ⊙ 장점 : 각 범주의 도수와 상대적인 비율을 쉽게 비교할 수 있다.
 A형 B형 AB형 O형 ⊙ 장점 : 각 범주의 도수와 상대적인 비율을 쉽게 비교할 수 있다.")
12
선그래프(line graph), 막대그래프(bar chart)
선그래프 : 각 범주에 대응하는 도수 또는 상대도수 등을 수직선으로 나타낸 그림 막대그래프 : 각 범주에 대응하는 도수 또는 상대도수 등을 같은 폭의 수직막대로 나타낸 그림 파레토 그림(Pareto chart) : 각 범주의 도수가 감소하도록 범주를 재배열한 막대그래프 ⊙ 장점 : 각 범주에 대한 도수분포표에 비하여 각 범주의 도수 또는 상대도수를 시각적으로 쉽게 비교할 수 있다.
 : 각 범주의 도수가 감소하도록 범주를 재배열한 막대그래프. ⊙ 장점 : 각 범주에 대한 도수분포표에 비하여 각 범주의 도수 또는 상대도수를 시각적으로 쉽게 비교할 수 있다.")
13
도수 선그래프 상대도수 선그래프 도수 막대그래프 상대도수 막대그래프 파레토 그림

14
도수 다각형(Frequency Polygon)
각 범주에 대한 막대그래프의 상단 중심부 또는 선그래프의 점을 사선으로 연결하여 각 범주를 비교하는 그림 도수 다각형 상대도수 다각형

15
원그래프(Pie Chart) 각 범주의 상대도수에 비례하는 중심각을 갖는 파이조각 모양으로 나누어진 원으로 작성한 그림
질적자료의 각 범주를 상대적으로 비교할 때 많이 사용한다. 각 파이조각에 범주의 명칭과 비율 그리고 도수 등을 기입한다. 특정 범주를 강조하기 위하여 파이조각 하나를 별도로 끄집어내기도 함 범 주 도수 상대도수(%) 중심각( ◦) A형 7 28 360•(0.28) = 100 B형 4 16 360•(0.16) = 58 AB형 5 20 360•(0.20) = 72 O형 9 36 360•(0.36) = 130
 중심각( ◦) A형 •(0.28) = 100. B형 •(0.16) = 58. AB형 •(0.20) = 72. O형 •(0.36) = 130.")
16
통계청 조사 자료 : 광역도시별 경제활동인구(2009년 4월) (1) 경제활동인구에 대한 도수분포표 작성
(2) 상대도수 막대그래프 작성 (3) 상대도수 다각형 작성 (4) 원그래프 작성 지역 인구 서울 5,087 부산 1,639 대구 1,180 인천 1,350 광주 664 대전 726 울산 544 <출처 : 통계청 홈페이지>
 상대도수 막대그래프 작성. (3) 상대도수 다각형 작성. (4) 원그래프 작성. 지역. 인구. 서울. 5,087. 부산. 1,639. 대구. 1,180. 인천. 1,350. 광주 대전 울산 <출처 : 통계청 홈페이지>")
17
(1) 전체 광역도시의 총경제활동인구 : 11,190명 각 도시별 경제활동인구의 상대도수 : 서울 : 5087 11190 = 0.455 부산 : 1639 11190 = 0.146 대구 : 1180 11190 = 0.105 인천 : 1350 11190 = 0.121 광주 : 664 11190 = 0.059 대전 : 726 11190 = 0.065 울산 : 544 11190 = 0.049 지 역 경제활동인구 상대도수 서울 5,087 0.455 부산 1,639 0.146 대구 1,180 0.105 인천 1,350 0.121 광주 664 0.059 대전 726 0.065 울산 544 0.049 계 11,190 1.000

18
(2) (3) 상대도수 막대그래프 상대도수 다각형 (4) 서울 : 360•(0.455) = 163.8 부산 : 360•(0.146) = 52.6 대구 : 360•(0.105) = 37.8 인천 : 360•(0.121) = 43.6 광주 : 360•(0.059) = 21.2 대전 : 360•(0.065) = 23.4 울산 : 360•(0.049) = 17.6 중심각
 = 광주 : 360•(0.059) = 대전 : 360•(0.065) = 울산 : 360•(0.049) = 중심각.")
19
집단화 자료의 도수분포표 양적자료를 적당한 크기로 집단화하여 좀 더 쉽게 이해하도록 적당한 간격으로 집단화하여 만든 도수분포표
⊙ 장점 : 누적상대도수 즉, 분포함수가 F(x)=0.5가 되는 대략적인 중심의 위치를 알 수 있다. 대략적인 자료의 흩어진 정도 파악할 수 있다. ⊙ 단점 : 원자료의 정확한 관찰값을 알 수 없다. 계급(class) : 적당한 간격으로 집단화하여 나타낸 범주들 계급간격(class width) : 이웃하는 두 계급의 위쪽 경계에서 아래쪽 경계를 뺀 값 계급값(class mark) : 각 계급의 중앙에 위치한 값, 용어설명 위쪽 경계 + 아래쪽 경계 2
=0.5가 되는 대략적인 중심의 위치를 알. 수 있다. 대략적인 자료의 흩어진 정도 파악할 수 있다. ⊙ 단점 : 원자료의 정확한 관찰값을 알 수 없다. 계급(class) : 적당한 간격으로 집단화하여 나타낸 범주들. 계급간격(class width) : 이웃하는 두 계급의 위쪽 경계에서 아래쪽 경계를 뺀 값. 계급값(class mark) : 각 계급의 중앙에 위치한 값, 용어설명. 위쪽 경계 + 아래쪽 경계. 2.")
20
☞ ☞ 집단화 자료의 도수분포표 작성 방법 계급의 수를 결정하는 방법 제1열 : 계급의 번호를 작성하여 기입
제2열 : 각 계급 안에 놓이는 관찰값의 도수를 기입 제3열 : 각 계급의 도수를 전체 관찰값의 상대도수를 기입 제4열 : 이전 계급까지의 모든 도수 또는 상대도수를 합한 누적도수를 기입 제5열 : 누적상대도수를 기입 제6열 : 계급의 중앙값을 나타내는 계급값을 기입 ☞ 계급의 수를 결정하는 방법 자료의 수(n)가 200개 이하 : k = n + 3 에 가까운 정수 자료의 수가 충분히 크면 Sturges 공식에 가까운 정수 Sturges 공식 : k = log10 n 자료 수 30 50 120 250 500 1000 계급 수 200개 이하 자료 2~8 4~10 8~14 Sturges 방법 6 7 8 9 10 11
가 200개 이하 : k = n + 3 에 가까운 정수. 자료의 수가 충분히 크면 Sturges 공식에 가까운 정수. Sturges 공식 : k = log10 n. 자료 수 계급 수. 200개 이하 자료. 2~8. 4~10. 8~14. Sturges 방법")
21
자료의 최대 관찰값 – 자료의 최소 관찰값 k w = 각 계급의 간격(w) : 경계에서의 중복을 피하기 위하여 0이상 ∼ 10미만 10이상 ∼ 20미만 방법을 사용하나 가능한 지양함. 0 ∼ 9.5 9.5 ∼ 19.5 방법을 권장 최소 관찰값 - 최소 단위 2 제1계급의 하한 : 측정값이 120, 25와 같이 자연수인 경우 1.5, 2.4와 같이 소수점 이하 1자리수인 경우 1.05, 2.14와 같이 소수점 이하 2자리수인 경우 최소단위 : 1 0.1 0.01

22
예 머리의 직경이 50㎜인 볼트를 제조하는 회사로부터 100개의 볼트를 임의로 수집하여 측정한 결과
49.6 50.5 49.9 51.6 49.6 48.7 49.7 49.1 48.7 51.0 50.1 48.7 50.4 50.6 51.5 49.4 51.1 49.8 49.8 49.0 47.2 50.4 49.1 50.5 50.9 49.8 49.6 49.3 50.5 50.2 52.0 50.7 50.4 48.6 50.9 51.2 50.7 48.5 50.0 51.3 47.6 49.1 51.0 51.9 49.5 49.7 48.6 49.7 48.5 48.3 50.5 48.7 50.5 49.1 50.4 51.2 50.4 49.9 50.0 50.4 50.7 49.3 50.8 49.8 48.9 49.0 49.5 49.9 49.7 51.3 51.0 49.5 49.9 49.6 50.5 50.3 48.9 49.2 51.2 48.0 49.8 49.1 48.8 51.7 49.7 50.3 50.6 50.0 49.6 51.2 47.6 50.8 49.7 49.9 50.6 49.7 49.9 49.7 51.8 55.1 도수 분포표 작성 ?

23
(1) 계급의 수를 결정 : 총 자료수가 100이므로 k = 8
(2) 최대값과 최소값을 찾는다. max = 55.2 , min = 47.2 (3) 계급 간격을 구한다. max = 55.2 , min = 47.2 w = max - min 8 = = 1 (4) 1계급의 하한을 구한다. : 47.2 –(0.5) = 47.15 (5) 각 계급간격을 구한다. : 47.2 –(0.5) = 47.15 (6) 각 계급의 계급값을 구한다. (7) 도수분포표의 제1열과 제2열에 계급번호와 계급간격을 기입하고, 차례대로 도수, 상대도수, 누적도수, 누적상대도수, 계급값 등을 기입한다.
 최대값과 최소값을 찾는다. max = 55.2 , min = (3) 계급 간격을 구한다. max = 55.2 , min = w = max - min = = 1. (4) 1계급의 하한을 구한다. : 47.2 –(0.5) = (5) 각 계급간격을 구한다. : 47.2 –(0.5) = (6) 각 계급의 계급값을 구한다 (7) 도수분포표의 제1열과 제2열에 계급번호와 계급간격을 기입하고, 차례대로 도수, 상대도수, 누적도수, 누적상대도수, 계급값 등을 기입한다.")
24
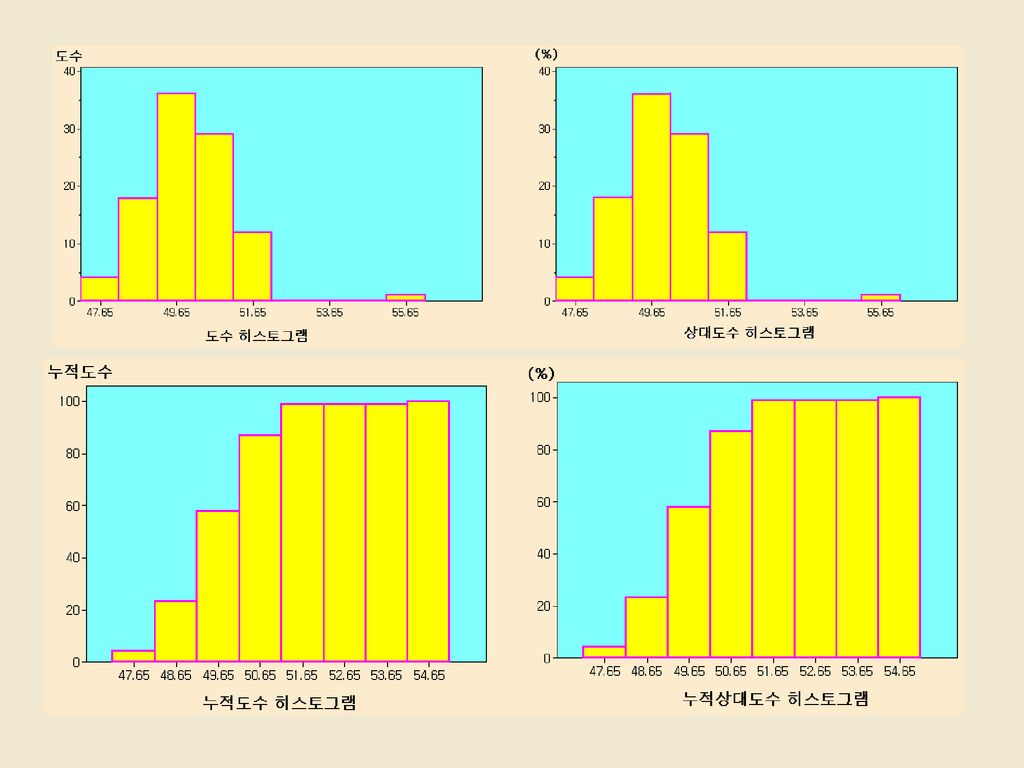
제3계급의 후반부에 중심의 위치가 있음 계 급 계급간격 도수 상대도수 누적도수 누적상대도수 계급값 제1계급 47.15 ~ 48.15 4 0.04 4 0.04 47.65 제2계급 48.15 ~ 49.15 18 0.18 22 0.22 48.65 제3계급 49.15 ~ 50.15 36 0.36 58 0.58 49.65 제4계급 50.15 ~ 29 0.29 87 0.87 50.65 제5계급 51.15 ~ 52.15 12 0.12 99 0.99 51.65 제6계급 52.15 ~ 53.15 0.00 99 0.99 52.65 제7계급 53.15 ~ 54.15 0.00 99 0.99 53.65 제8계급 54.15 ~ 55.15 1 0.01 100 1.00 54.65 합 계 100 1.00 100 1.00 이상점(outlier) : 대다수의 자료로부터 멀리 떨어져 있는 측정값
 : 대다수의 자료로부터 멀리 떨어져 있는 측정값.")
25
자료의 수가 50이므로 계급의 수를 5로 정하면, 최소값 25 그리고 최대값 98이므로 계급간격 w :
50명의 통계학 성적 도수분포표를 작성 대략적인 중심의 위치 83 90 60 25 50 94 60 62 97 43 67 84 79 62 78 48 85 52 77 90 25 84 41 65 58 75 83 71 74 68 89 88 76 69 77 89 73 98 77 58 77 69 75 69 65 67 69 79 85 45 자료의 수가 50이므로 계급의 수를 5로 정하면, 최소값 25 그리고 최대값 98이므로 계급간격 w : w = max - min 5 = = 15 제1계급의 하한을 24.5라 하면, 다음의 도수분포표를 얻는다. 계급 계급간격 도수 상대도수 누적도수 누적상대도수 계급값 1 24.5~39.5 2 0.04 32 39.5~54.5 6 0.12 8 0.16 47 3 54.5~69.5 15 0.30 23 0.46 62 4 69.5~84.5 17 0.34 40 0.80 77 5 84.5~99.5 10 0.20 50 1.00 92 합계 대략적인 중심의 위치는 제3계급까지 누적상대도수가 0.46이고 제4계급의 도수가 17이므로 하한에 가까운 70 정도로 생각할 수 있다.

26
히스토그램(Histogram) 집단화 자료에 대한 도수분포표의 계급간격을 수평축에 작성하고, 수직축에 도수 또는 상대도수에 해당하는 막대모양으로 작성한 그림 수직축에 누적도수 또는 누적상대도수를 기입할 수 있다. ⊙ 장점 : 도수분포표에 비하여 보다 더 시각적으로 중심의 위치와 자료가 어떠한 모양으로 흩어져 있는가에 대하여 쉽게 파악할 수 있다. ⊙ 단점 : 각 계급 안에 놓이는 자료의 정확한 측정값을 알 수 없다.

28
히스토그램의 유형

29
도수분포다각형(Frequency Polygon)
히스토그램의 연속적인 막대의 상단중심부를 직선으로 연결하여 다각형 양적자료에 대하여 시각적인 효과를 준다. 수직축에 상대도수, 누적도수 및 누적상대도수 등을 작성할 수 있다.

30
우리나라 30-40대 근로자의 혈압과 50-60대 근로자의 혈압을 비교 두 그룹의 혈압을 비교하는 상대도수 분포다각형
혈 압 30-40대 근로자 수 50-60대 근로자 수 89.5 ~ 109.5 16 3 109.5 ~ 129.5 418 82 129.5 ~ 149.5 1,235 274 149.5 ~ 169.5 432 226 169.5 ~ 189.5 57 97 189.5 ~ 209.5 4 18 209.5 ~ 229.5 7 229.5 ~ 259.5 계 2,162 710 두 그룹의 혈압별 상대도수를 먼저 구한다.

31
상대도수 히스토그램을 먼저 그리고, 각 계급의 상단 중심부를 선으로 잇는다.
혈 압 30-40대 근로자 수 30-40대 근로자의 상대도수 50-60대 근로자 수 50-60대 근로자의 상대도수 89.5 ~ 109.5 16 0.007 3 0.004 109.5 ~ 129.5 418 0.193 82 0.116 129.5 ~ 149.5 1,235 0.571 274 0.386 149.5 ~ 169.5 432 0.200 226 0.318 169.5 ~ 189.5 57 0.027 97 0.137 189.5 ~ 209.5 4 0.002 18 0.025 209.5 ~ 229.5 0.000 7 0.010 229.5 ~ 259.5 계 2,162 1.000 710 상대도수 히스토그램을 먼저 그리고, 각 계급의 상단 중심부를 선으로 잇는다.

32
줄기-잎 그림(Stem-Leaf Display)
도수분포표나 히스토그램이 갖고 있는 성질을 그대로 보존하면서 각 계급 안에 들어있는 개개의 측정값을 제공하는 그림 ☞ 줄기-잎 그림 작성 방법 줄기와 잎을 구분한다. 변동이 작은 부분을 줄기, 변동이 많은 부분을 잎으로 지정한다. (2) 줄기 부분을 작은 수부터 순차적으로 나열하고, 잎 부분을 원자료의 관찰 순서대로 나열한다. (3) 잎 부분의 관찰값을 순서대로 나열하고 전체 자료의 중앙에 놓이는 관찰값이 있는 행의 맨 앞에 괄호( )를 만들고, 괄호 안에 그 행의 잎의 수(도수)를 기입한다. (4) 괄호가 있는 행을 중심으로 괄호와 동일한 열에 누적도수를 위와 아래방향에서 각각 기입하고, 최소단위와 자료의 전체 개수를 기입한다.
 줄기 부분을 작은 수부터 순차적으로 나열하고, 잎 부분을 원자료의 관찰 순서대로 나열한다. (3) 잎 부분의 관찰값을 순서대로 나열하고 전체 자료의 중앙에 놓이는 관찰값이 있는 행의 맨 앞에 괄호( )를 만들고, 괄호 안에 그 행의 잎의 수(도수)를 기입한다. (4) 괄호가 있는 행을 중심으로 괄호와 동일한 열에 누적도수를 위와 아래방향에서 각각 기입하고, 최소단위와 자료의 전체 개수를 기입한다.")
33
예 머리의 직경이 50㎜인 볼트를 제조하는 회사로부터 100개의 볼트를 임의로 수집하여 측정한 결과
49.6 50.5 49.9 51.6 49.6 48.7 49.7 49.1 48.7 51.0 50.1 48.7 50.4 50.6 51.5 49.4 51.1 49.8 49.8 49.0 47.2 50.4 49.1 50.5 50.9 49.8 49.6 49.3 50.5 50.2 52.0 50.7 50.4 48.6 50.9 51.2 50.7 48.5 50.0 51.3 47.6 49.1 51.0 51.9 49.5 49.7 48.6 49.7 48.5 48.3 50.5 48.7 50.5 49.1 50.4 51.2 50.4 49.9 50.0 50.4 50.7 49.3 50.8 49.8 48.9 49.0 49.5 49.9 49.7 51.3 51.0 49.5 49.9 49.6 50.5 50.3 48.9 49.2 51.2 48.0 49.8 49.1 48.8 51.7 49.7 50.3 50.6 50.0 49.6 51.2 47.6 50.8 49.7 49.9 50.6 49.7 49.9 49.7 51.8 55.1 줄기-잎 그림 작성 ?

34
우선 변동이 많은 부분(소수점 이하 자리)과 적은 부분(정수 부분)으로 줄기와 잎을 구분하고,
줄기 부분을 먼저 크기순에 의하여 아래방향으로 작성하고 행으로 잎의 부분을 관찰 순서에 의하여 작성한다. 잎의 부분을 순서대로 나열하고 첫 번째 열에 상・하 방향으로 누적도수를 작성한다. 끝으로 누적도수가 50%에 해당하는 행에 그 행의 도수를 괄호 안에 기입하고, 최소단위와 자료의 수를 기입하면, 간격이 “1”인 줄기-잎 그림이 완성된다. (1), (2) 단계 (3), (4) 단계
, (2) 단계. (3), (4) 단계.")
35
☞ 세분화 된 줄기-잎 그림 잎 부분의 간격이 “0.5”인 좀 더 세분화된 줄기-잎 그림
잎의 자료가 0~4인 경우와 5~9인 경우의 줄기를 각각 “o”와 “*”로 구분

36
줄기-잎 그림을 90 회전한 그림 ◦ 계급간격이 0.5이고, 각 계급의 자료값을 보여주는 히스토그램 또는 도수다각형

37
예제 1에 주어진 자료에 대하여, 간격이 10인 줄기-잎 그림과 간격이 5인 줄기-잎 그림 간격이 10인 줄기-잎 그림 간격이 5인 줄기-잎 그림

38
산점도(Scatter Diagram) 예
독립변수(x)와 응답변수(y)의 관계를 가지는 두 자료를 (x, y) 형태로 좌표평면 위에 작성한 그림 두 변수 사이의 상관관계를 쉽게 파악할 수 있다. 산점도에 가장 적합한 직선 y = ax + b를 구하면, 다음 관측값을 쉽게 예측할 수 있다. 이상점으로 판단되는 자료값을 쉽게 알 수 있다. 예 통계청에서 발표한 2038년부터 2049년까지 우리나라 인구동향 (단위 : 명) 년도 추계인구 2038 46,954,437 2039 46,657,404 2040 46,343,017 2041 46,011,395 2042 45,662,678 2043 45,297,469 2044 44,916,600 2045 44,520,935 2046 44,111,099 2047 43,687,610 2048 43,251,164 2049 42,802,545
와 응답변수(y)의 관계를 가지는 두 자료를 (x, y) 형태로 좌표평면 위에 작성한 그림. 두 변수 사이의 상관관계를 쉽게 파악할 수 있다. 산점도에 가장 적합한 직선 y = ax + b를 구하면, 다음 관측값을 쉽게 예측할 수 있다. 이상점으로 판단되는 자료값을 쉽게 알 수 있다. 예. 통계청에서 발표한 2038년부터 2049년까지 우리나라 인구동향. (단위 : 명) 년도. 추계인구 ,954, ,657, ,343, ,011, ,662, ,297, ,916, ,520, ,111, ,687, ,251, ,802,545.")
39
우리나라 인구동향에 대한 산점도 2005년 추계인구의 예측 이상점의 발견

40
위치척도 중심위치의 척도(measure of centrality) :
3 위치척도 중심위치의 척도인 표본평균, 절사평균, 표본중앙값과 표본최빈값, 표본사분위수 및 표본백분위수의 성질에 대하여 알아본다. 중심위치의 척도(measure of centrality) : 표본으로 얻은 자료를 대표해서 나타내는 척도 히스토그램 또는 도수분포의 중심을 나타내는 수치 중심위치를 나타내는 척도 : 표본평균과 중앙값 그리고 최빈값 등
 : 표본으로 얻은 자료를 대표해서 나타내는 척도. 히스토그램 또는 도수분포의 중심을 나타내는 수치. 중심위치를 나타내는 척도 : 표본평균과 중앙값 그리고 최빈값 등.")
41
☞ ☞ 표본평균(Sample Mean) 모평균(population mean) 표본평균(sample mean) m = S xi
중심의 위치를 나타내는데 가장 보편적으로 사용하는 위치척도 확률변수 X의 기대값 E(X)가 확률분포의 중심을 나타내는 것과 동일한 의미 모집단 또는 표본에서 관찰된 모든 측정값을 더하여 전체 도수로 나눈 수치 ☞ 모평균(population mean) m = S xi 1 N i = 1 모집단의 평균 : ☞ 표본평균(sample mean) x = S xi 1 n i = 1 표본의 평균 :
가 확률분포의 중심을 나타내는 것과 동일한 의미. 모집단 또는 표본에서 관찰된 모든 측정값을 더하여 전체 도수로 나눈 수치. ☞ 모평균(population mean) m = S xi. 1. N. i = 1. 모집단의 평균 : ☞ 표본평균(sample mean) x = S xi. 1. n. i = 1. 표본의 평균 :")
42
추측통계학에서 모평균을 추정하거나 검정하기 위하여 표본평균을 이용한다.
☞ 표본평균의 특성 ⊙ 장점 : 계산하기 쉽다. 모든 측정값을 반영한 정보를 제공한다. 각 자료와 평균과의 편차의 제곱을 모두 더한 잔차제곱합(residual sum of squares; RSS) 이 다른 유형의 위치척도에 비하여 작다. 잔차제곱합 : RSS = S (xi – x)2 추측통계학에서 모평균을 추정하거나 검정하기 위하여 표본평균을 이용한다. ⊙ 단점 : 이상점에 큰 영향을 받는다.
 이 다른 유형의 위치척도에 비하여 작다. 잔차제곱합 : RSS = S (xi – x)2. 추측통계학에서 모평균을 추정하거나 검정하기 위하여 표본평균을 이용한다. ⊙ 단점 : 이상점에 큰 영향을 받는다.")
43
두 자료집단에 대하여 자료집단 A : [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] 자료집단 B : [1, 2, 3, 4, 5, 6, 7, 8, 9, 100] (1) 두 자료집단의 평균을 구하고, 두 집단의 평균을 비교 (2) 자료집단 A의 각 측정값에 2씩 더한 자료들의 평균 (3) 자료집단 A의 각 측정값에 2씩 곱한 자료들의 평균 (1) 자료집단 A의 평균 : 10 x = = 5.5 자료집단 B의 평균 : 10 y = = 14.5 자료집단 A에 비하여 자료집단 B의 중심의 위치가 매우 크다.
![두 자료집단에 대하여 자료집단 A : [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] 자료집단 B : [1, 2, 3, 4, 5, 6, 7, 8, 9, 100] (1) 두 자료집단의 평균을 구하고, 두 집단의 평균을 비교.](http://slidesplayer.org/slide/15070546/91/images/43/%EB%91%90+%EC%9E%90%EB%A3%8C%EC%A7%91%EB%8B%A8%EC%97%90+%EB%8C%80%ED%95%98%EC%97%AC+%EC%9E%90%EB%A3%8C%EC%A7%91%EB%8B%A8+A+%3A+%5B1%2C+2%2C+3%2C+4%2C+5%2C+6%2C+7%2C+8%2C+9%2C+10%5D+%EC%9E%90%EB%A3%8C%EC%A7%91%EB%8B%A8+B+%3A+%5B1%2C+2%2C+3%2C+4%2C+5%2C+6%2C+7%2C+8%2C+9%2C+100%5D+%281%29+%EB%91%90+%EC%9E%90%EB%A3%8C%EC%A7%91%EB%8B%A8%EC%9D%98+%ED%8F%89%EA%B7%A0%EC%9D%84+%EA%B5%AC%ED%95%98%EA%B3%A0%2C+%EB%91%90+%EC%A7%91%EB%8B%A8%EC%9D%98+%ED%8F%89%EA%B7%A0%EC%9D%84+%EB%B9%84%EA%B5%90..jpg "(2) 자료집단 A의 각 측정값에 2씩 더한 자료들의 평균. (3) 자료집단 A의 각 측정값에 2씩 곱한 자료들의 평균. (1) 자료집단 A의 평균 : x = = 5.5. 자료집단 B의 평균 : y = = 자료집단 A에 비하여 자료집단. B의 중심의 위치가 매우 크다.")
44
자료집단 [6, 6, 7, 3, 6, 7, 7, 6, 9, 3]에 대한 표본평균을 구하고, 도수분포표
(2) 자료집단 A에 2씩 더한 자료 : C : [3, 4, 5, 6, 7, 8, 9, 10, 11, 12] 10 C = = 7.5 (3) 자료집단 A에 2씩 곱한 자료 : D : [2, 4, 6, 8, 10, 12, 14, 16, 18, 20] 10 D = = 11 자료집단 [6, 6, 7, 3, 6, 7, 7, 6, 9, 3]에 대한 표본평균을 구하고, 도수분포표 자료 도수 상대도수 3 2 0.2 6 4 0.4 7 0.3 9 1 0.1 합계 10 1.00 자료집단의 평균 : 10 x = = 6
![자료집단 [6, 6, 7, 3, 6, 7, 7, 6, 9, 3]에 대한 표본평균을 구하고, 도수분포표](http://slidesplayer.org/slide/15070546/91/images/44/%EC%9E%90%EB%A3%8C%EC%A7%91%EB%8B%A8+%5B6%2C+6%2C+7%2C+3%2C+6%2C+7%2C+7%2C+6%2C+9%2C+3%5D%EC%97%90+%EB%8C%80%ED%95%9C+%ED%91%9C%EB%B3%B8%ED%8F%89%EA%B7%A0%EC%9D%84+%EA%B5%AC%ED%95%98%EA%B3%A0%2C+%EB%8F%84%EC%88%98%EB%B6%84%ED%8F%AC%ED%91%9C.jpg "(2) 자료집단 A에 2씩 더한 자료 : C : [3, 4, 5, 6, 7, 8, 9, 10, 11, 12] C = = 7.5. (3) 자료집단 A에 2씩 곱한 자료 : D : [2, 4, 6, 8, 10, 12, 14, 16, 18, 20] D = = 11. 자료집단 [6, 6, 7, 3, 6, 7, 7, 6, 9, 3]에 대한 표본평균을 구하고, 도수분포표. 자료. 도수. 상대도수 합계 자료집단의 평균 : x = = 6.")
45
로부터 10 x = 3•2 + 6•4 + 7•3 + 9•1 10 = 표본평균 : 2 10 4 10 3 10 1 10 = 3• • • • = 6 측정값 비율 X 3 6 7 9 합계 P(X = x) 0.2 0.4 0.3 0.1 1.00 상대도수에 의한 각 측정값의 확률표 E(X) = 3•(0.2) + 6•(0.4) + 7•(0.3) + 9•(0.1) = 6 표본평균 기대값 : f1, f2, …, fk x1, x2, …, xk n 각 관측값의 상대도수 합 서로 다른 관측값 x = x1• x2• … + xk• f1 f2 fk
 상대도수에 의한 각 측정값의 확률표. E(X) = 3•(0.2) + 6•(0.4) + 7•(0.3) + 9•(0.1) = 6. 표본평균. 기대값 : f1, f2, …, fk. x1, x2, …, xk. n. 각 관측값의 상대도수. 합. 서로 다른 관측값. x = x1• + x2• + … + xk• f1. f2. fk.")
46
도수분포표에 대한 표본평균 범주 도수 상대도수 6 0.10 1 18 0.30 2 27 0.45 3 4 0.05 합계 60 1.00 x = 0•(0.1) + 1•(0.3) + 2•(0.45) + 3•(0.1) + 4•(0.05) = 1.65
 + 1•(0.3) + 2•(0.45) + 3•(0.1) + 4•(0.05) =")
47
절사평균(Trimmed Mean; TM)
예 예제 1의 자료집단 B에 대하여, 자료값 “1”, “100”을 제거한 평균 자료집단 A : [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] 자료집단 B : [1, 2, 3, 4, 5, 6, 7, 8, 9, 100] 10 x = = 5.5 10 y = = 5.5 산술평균이 갖는 이상점에 대한 영향을 줄인 산술평균 a%에 해당하는 큰 쪽과 작은 쪽의 관찰값을 제거한 나머지의 평균 an = 정수(k)이면, k개의 측정값을 각각 양쪽에서 절사시킴 an이 정수가 아니면, [an]개 씩 양쪽에서 절사시킴.
이면, k개의 측정값을 각각 양쪽에서 절사시킴. an이 정수가 아니면, [an]개 씩 양쪽에서 절사시킴.")
48
표본평균과 15%-절사평균 자료집단 : [62, 69, 72, 34, 69, 67, 70, 65, 99] 표본평균 x = 9 = 60 15%-절사평균 절사 측정값의 개수 : [an] = [(0.15)•9] = [1.35] = 1 TM = 9 = 58.14
![표본평균과 15%-절사평균 자료집단 : [62, 69, 72, 34, 69, 67, 70, 65, 99] 표본평균. x =](http://slidesplayer.org/slide/15070546/91/images/48/%ED%91%9C%EB%B3%B8%ED%8F%89%EA%B7%A0%EA%B3%BC+15%25-%EC%A0%88%EC%82%AC%ED%8F%89%EA%B7%A0+%EC%9E%90%EB%A3%8C%EC%A7%91%EB%8B%A8+%3A+%5B62%2C+69%2C+72%2C+34%2C+69%2C+67%2C+70%2C+65%2C+99%5D+%ED%91%9C%EB%B3%B8%ED%8F%89%EA%B7%A0.+x+%3D.jpg "9. = %-절사평균. 절사 측정값의 개수 : [an] = [(0.15)•9] = [1.35] = 1. TM = =")
49
표본 중앙값(Sample Median; Me)
표본평균이 갖는 이상점에 대한 영향을 제거할 수 있는 중심위치의 척도 자료의 측정값을 크기순서로 나열하여 가장 가운데 순위에 놓이는 값 확률변수의 중앙값과 동일한 의미 x 2 n+1 n +1 + Me = , n이 홀수인 경우 , n이 짝수인 경우 ⊙ 장점 : 어느 한 쪽으로 치우친 분포를 갖는 자료에 대하여 평균보다 좋은 중심의 위치를 나타낸다. ⊙ 단점 : 전체 자료를 크기 순으로 나열하여 중앙에 놓이는 자료를 찾아야 한다는 점에서 자료의 수가 많은 경우에 부적절 수리적으로 다루기 매우 힘들다는 이유로 추측통계학에서 별로 사용하지 않는다.

50
각 자료집단의 표본 중앙값 자료집단 A : [7, 15, 11, 5, 9], 자료집단 B : [7, 15, 110, 5, 9], 자료집단 C : [2, 7, 15, 11, 5, 9] 자료집단 A : 5개의 측정값으로 구성되어 있으므로 중앙값은 크기순으로 나열하여 3번째 위치 재배열 : [5, 7, 9, 11, 15] Me = 9 자료집단 B : 5개의 측정값으로 구성되어 있으므로 중앙값은 크기순으로 나열하여 3번째 위치 재배열 : [5, 7, 9, 15, 110] Me = 9 자료집단 C : 6개의 측정값으로 구성되어 있으므로 중앙값은 3번째와 4번째 위치에 놓이는 측정값의 평균 Me = = 8 7 + 9 2 재배열 : [2, 5, 7, 9, 11, 15]
![각 자료집단의 표본 중앙값 자료집단 A : [7, 15, 11, 5, 9], 자료집단 B : [7, 15, 110, 5, 9], 자료집단 C : [2, 7, 15, 11, 5, 9]](http://slidesplayer.org/slide/15070546/91/images/50/%EA%B0%81+%EC%9E%90%EB%A3%8C%EC%A7%91%EB%8B%A8%EC%9D%98+%ED%91%9C%EB%B3%B8+%EC%A4%91%EC%95%99%EA%B0%92+%EC%9E%90%EB%A3%8C%EC%A7%91%EB%8B%A8+A+%3A+%5B7%2C+15%2C+11%2C+5%2C+9%5D%2C+%EC%9E%90%EB%A3%8C%EC%A7%91%EB%8B%A8+B+%3A+%5B7%2C+15%2C+110%2C+5%2C+9%5D%2C+%EC%9E%90%EB%A3%8C%EC%A7%91%EB%8B%A8+C+%3A+%5B2%2C+7%2C+15%2C+11%2C+5%2C+9%5D.jpg "자료집단 A : 5개의 측정값으로 구성되어 있으므로 중앙값은 크기순으로 나열하여 3번째 위치. 재배열 : [5, 7, 9, 11, 15] Me = 9. 자료집단 B : 5개의 측정값으로 구성되어 있으므로 중앙값은 크기순으로 나열하여 3번째 위치. 재배열 : [5, 7, 9, 15, 110] Me = 9. 자료집단 C : 6개의 측정값으로 구성되어 있으므로 중앙값은 3번째와 4번째 위치에 놓이는 측정값의 평균. Me = = 재배열 : [2, 5, 7, 9, 11, 15]")
51
표본 최빈값(Sample Mode; Mo)
질적자료와 양적자료에 모두 사용 가능 2번 이상 발생하는 측정값 중에서 가장 많은 도수를 가지는 자료값 확률변수의 중앙값과 동일한 의미 ⊙ 장점 : 극단값에 대한 영향을 전혀 받지 않는다. 자료의 수가 적은 자료집단에 대한 중심위치를 잘 나타낸다. ⊙ 단점 : 존재하지 않거나 1개 이상 존재할 수 있다. 수리적으로 다루기 매우 힘들다는 이유로 추측통계학에서 별로 사용하지 않는다.

52
대칭형 단봉분포 오른쪽으로 치우친 왼쪽으로 치우친 쌍봉분포 자료집단 A : [1, 5, 7, 9, 11, 15, 19] 최빈값이 없음. 자료집단 B : [4, 9, 2, 5, 10, 2, 3, 1] Mo = 2 자료집단 C : [1, 2, 5, 1, 2, 5, 3, 1, 5] Mo = 1, 5
![대칭형 단봉분포. 오른쪽으로 치우친. 왼쪽으로 치우친. 쌍봉분포. 자료집단 A : [1, 5, 7, 9, 11, 15, 19] 최빈값이 없음.](http://slidesplayer.org/slide/15070546/91/images/52/%EB%8C%80%EC%B9%AD%ED%98%95+%EB%8B%A8%EB%B4%89%EB%B6%84%ED%8F%AC.+%EC%98%A4%EB%A5%B8%EC%AA%BD%EC%9C%BC%EB%A1%9C+%EC%B9%98%EC%9A%B0%EC%B9%9C.+%EC%99%BC%EC%AA%BD%EC%9C%BC%EB%A1%9C+%EC%B9%98%EC%9A%B0%EC%B9%9C.+%EC%8C%8D%EB%B4%89%EB%B6%84%ED%8F%AC.+%EC%9E%90%EB%A3%8C%EC%A7%91%EB%8B%A8+A+%3A+%5B1%2C+5%2C+7%2C+9%2C+11%2C+15%2C+19%5D+%EC%B5%9C%EB%B9%88%EA%B0%92%EC%9D%B4+%EC%97%86%EC%9D%8C..jpg "자료집단 B : [4, 9, 2, 5, 10, 2, 3, 1] Mo = 2. 자료집단 C : [1, 2, 5, 1, 2, 5, 3, 1, 5] Mo = 1, 5.")
53
히스토그램이나 도수분포가 종 모양으로 대칭 ▶ x = TM = Me = Mo 오른쪽으로 치우친 분포 또는 왼쪽으로 긴 꼬리를 가지는 분포 ▶ x < TM < Me < Mo 왼쪽으로 치우친 분포 ▶ Mo < Me < TM < x

54
☞ 표본사분위수(sample quartiles) 예
확률변수의 사분위수와 동일하게 표본으로 수집된 자료들을 크기순서로 나열하여 4등분하는 척도 제1사분위수(Q1), 제2사분위수(Q2), 제3사분위수(Q3) 제2사분위수 = 표본중앙값 (Q2 = Me) 제1사분위수 : 최소값과 중앙값 사이의 중앙값 제3사분위수 : 최대값과 중앙값 사이의 중앙값 예 측정값 1 2 3 4 5 6 7 8 9 10 합계 도수 12 11 14 100 100개로 구성된 다음 자료집단에 대하여 제2사분위수 : 전체 100개이므로 50번째와 51번째 측정값의 평균 Q2 = 5.5 제1사분위수 : 아래쪽 50개 측정값의 중앙값, 25번째와 26번째 측정값의 평균 Q1 = 3 제3사분위수 : 위쪽 50개 측정값의 중앙값, 75번째와 76번째 측정값의 평균 Q3 = 8
, 제2사분위수(Q2), 제3사분위수(Q3) 제2사분위수 = 표본중앙값 (Q2 = Me) 제1사분위수 : 최소값과 중앙값 사이의 중앙값. 제3사분위수 : 최대값과 중앙값 사이의 중앙값. 예. 측정값 합계. 도수 개로 구성된 다음 자료집단에 대하여. 제2사분위수 : 전체 100개이므로 50번째와 51번째 측정값의 평균 Q2 = 5.5. 제1사분위수 : 아래쪽 50개 측정값의 중앙값, 25번째와 26번째 측정값의 평균 Q1 = 3. 제3사분위수 : 위쪽 50개 측정값의 중앙값, 75번째와 76번째 측정값의 평균 Q3 = 8.")
55
☞ 표본백분위수(sample percentiles) 자료집단을 100등분하는 척도들
k-백분위수 Pk는 k%의 자료값들이 Pk 보다 작고, 나머지 (100-k)%의 자료값들이 Pk 보다 크게 주어지는 값 25-, 50-, 75-백분위수 : 제1사분위수, 제2사분위수, 제3사분위수 pk/100 = m(자연수)이면 m번째와 m+1번째 위치하는 자료값의 평균 : x(m) + x(m+1) 2 pk/100 ≠(자연수)이면 pk보다 큰 가장 작은 정수 m번째 위치하는 자료값 x(m) 자료집단에 대한 30-백분위수 P30 , 60-백분위수 P60 , 사분위수 (Q1 , Q2 , Q3) 자료집단 [83 90 60 25 50 94 60 62 97 43 67 84 79 62 78]
%의 자료값들이 Pk 보다 크게 주어지는 값. 25-, 50-, 75-백분위수 : 제1사분위수, 제2사분위수, 제3사분위수. pk/100 = m(자연수)이면 m번째와 m+1번째 위치하는 자료값의 평균 : x(m) + x(m+1) 2. pk/100 ≠(자연수)이면 pk보다 큰 가장 작은 정수 m번째 위치하는 자료값 x(m) 자료집단에 대한 30-백분위수 P30 , 60-백분위수 P60 , 사분위수 (Q1 , Q2 , Q3) 자료집단 [ ]")
56
자료집단을 크기 순으로 재배열 재배열 : [25 43 50 60 60 62 62 67 84 90 94 97 ] 30-백분위수 : pk/100 = (0.3)•15 = 4.5, P30 = x(5) = 60 60-백분위수 : pk/100 = (0.6)• 15 = 9, P60 = (x(9) + x(10) )/2 = 78.5 사분위수의 위치 : (0.25)•15 = 3.75, (0.5)•15 = 7.5, (0.75)•15 = 11.25 사분위수 : Q1 = x(4) = 60 , Q2 = x(8) = 67, Q3 = x(12) = 84
![자료집단을 크기 순으로 재배열 재배열 : [ ] 30-백분위수 : pk/100 = (0.3)•15 = 4.5, P30 = x(5) = 60.](http://slidesplayer.org/slide/15070546/91/images/56/%EC%9E%90%EB%A3%8C%EC%A7%91%EB%8B%A8%EC%9D%84+%ED%81%AC%EA%B8%B0+%EC%88%9C%EC%9C%BC%EB%A1%9C+%EC%9E%AC%EB%B0%B0%EC%97%B4+%EC%9E%AC%EB%B0%B0%EC%97%B4+%3A+%5B+%5D+30-%EB%B0%B1%EB%B6%84%EC%9C%84%EC%88%98+%3A+pk%2F100+%3D+%280.3%29%E2%80%A215+%3D+4.5%2C+P30+%3D+x%285%29+%3D+60..jpg "60-백분위수 : pk/100 = (0.6)• 15 = 9, P60 = (x(9) + x(10) )/2 = 사분위수의 위치 : (0.25)•15 = 3.75, (0.5)•15 = 7.5, (0.75)•15 = 사분위수 : Q1 = x(4) = 60 , Q2 = x(8) = 67, Q3 = x(12) = 84.")
57
4 산포의 척도 범위, 표본사분위수, 평균편차, 분산과 표준편차, 변동계수 등과 같은 산포의 척도에 대한 특성과 상자그림을 그리는 방법 등에 대하여 알아본다. ▶ 동일한 평균을 가지고 있더라도 확연히 서로 다른 분포를 이루고 있으므로 두 집단은 동일하거나 비슷한 집단이라고 결론을 내릴 수 없음. ☞ 자료의 흩어진 모양을 나타내는 척도가 필요하며, 이러한 척도를 산포도(measure of dispersion)라 함.
라 함.")
58
두 집단의 평균과 점도표를 구하고, 두 자료집단이 동일한 특성을 갖는다고 할 수 있는지 분석 집단 자료 A 20, 45, 95, 80, 70, 85, 95, 87, 21, 95, 90, 39, 28, 86, 84 B 57, 60, 68, 71, 75, 71, 55, 71, 81, 71, 65, 65, 78, 71, 61 두 자료집단의 평균은 동일하게 68이다. 자료집단 A는 최하 20에서 최고 95가지 폭넓게 분포하지만, 자료집단 B는 평균을 중심으로 자료집단 A에 비하여 밀집되어 있다.

59
집단 B에 비하여 집단 A가 폭넓게 분포되어 있음.
범위(Range; R) 자료의 최대 관찰값과 최소 관찰값의 차이 ⊙ 장점 : 자료의 수가 적고 어느 정도 대칭성이 있는 분포에 적당함. ⊙ 단점 : 이상점에 크게 영향을 받으며 최대·최소값에 의하여 결정되므로 개개의 자료값이 산포의 척도를 계산하는데 반영되지 못함 예제 1에서, 집단 A : 최대값 = 95, 최소값 = 20 , RA = 95 – 20 =75 집단 B : 최대값 = 81, 최소값 = 55, RB = 81 – 55 = 26 집단 B에 비하여 집단 A가 폭넓게 분포되어 있음.
 자료의 최대 관찰값과 최소 관찰값의 차이. ⊙ 장점 : 자료의 수가 적고 어느 정도 대칭성이 있는 분포에 적당함. ⊙ 단점 : 이상점에 크게 영향을 받으며. 최대·최소값에 의하여 결정되므로 개개의 자료값이 산포의 척도를 계산하는데 반영되지 못함. 예제 1에서, 집단 A : 최대값 = 95, 최소값 = 20 , RA = 95 – 20 =75. 집단 B : 최대값 = 81, 최소값 = 55, RB = 81 – 55 = 26. 집단 B에 비하여 집단 A가 폭넓게 분포되어 있음.")
60
사분위수범위(Interquartiles range; I.Q.R)
범위가 갖는 이상점에 대한 영향을 제거한 산포도 제1사분위수에서 제3사분위수까지의 범위만을 사용하는 척도, 즉 I.Q.R = Q3 – Q1 중앙값을 중심위치로 사용하는 경우에 주로 사용 줄기-잎 그림의 단점 : 이상점에 대한 정보를 완전하게 제공하지 못함 단점 보완 상자그림 꼬리부분에 대한 특성인 이상점에 대한 정보를 제공 자료의 흩어진 모양을 쉽게 알 수 있도록 자료를 요약한 그림

61
☞ 용어 설명 (1) 안울타리(inner fence) : 사분위수 Q1과 Q3에서 (1.5) • I.Q.R만큼 떨어져 있는 값
아래쪽 안울타리(lower inner fence) : fl = Q1 – (1.5) • I.Q.R 위 쪽 안울타리(upper inner fence) : fu = Q3 + (1.5) • I.Q.R (2) 바깥울타리(outer fence) : 사분위수 Q1 과 Q3에서 3 • I.Q.R만큼 떨어져 있는 값 아래쪽 바깥울타리(lower outer fence) : Fl = Q1 - 3 • I.Q.R 위 쪽 바깥울타리(upper outer fence) : Fu = Q3 + 3 • I.Q.R (3) 인접값(adjacent value) : 안울타리와 Q1과 Q3사이에 있는 가장 극단적인 관측값 (4) 보통 이상점(mild outlier) : 안울타리와 바깥울타리 사이에 놓이는 관측값 (5) 이상점(extreme outlier) : 바깥울타리 외부에 놓이는 관측값
 : fl = Q1 – (1.5) • I.Q.R. 위 쪽 안울타리(upper inner fence) : fu = Q3 + (1.5) • I.Q.R. (2) 바깥울타리(outer fence) : 사분위수 Q1 과 Q3에서 3 • I.Q.R만큼 떨어져 있는 값. 아래쪽 바깥울타리(lower outer fence) : Fl = Q1 - 3 • I.Q.R. 위 쪽 바깥울타리(upper outer fence) : Fu = Q3 + 3 • I.Q.R. (3) 인접값(adjacent value) : 안울타리와 Q1과 Q3사이에 있는 가장 극단적인 관측값. (4) 보통 이상점(mild outlier) : 안울타리와 바깥울타리 사이에 놓이는 관측값. (5) 이상점(extreme outlier) : 바깥울타리 외부에 놓이는 관측값.")
62
☞ 상자그림 그리는 방법 자료를 크기순으로 나열하여 사분위수 Q1, Q2 그리고 Q3을 구한다.
(2) 사분위수범위 I.Q.R = Q3 - Q1을 구한다 (3) Q1 에서 Q3 까지를 직사각형 모양의 상자로 연결하여 그리고, 중앙값 Q2의 위치에 “+”를 표시한다. (4) 안울타리를 구하고, 인접값에 기호 “|”로 표시한 후, Q1과 Q3으로부터 인접값까지 직선으로 연결한다.
 사분위수범위 I.Q.R = Q3 - Q1을 구한다. (3) Q1 에서 Q3 까지를 직사각형 모양의 상자로 연결하여 그리고, 중앙값 Q2의 위치에 + 를 표시한다. (4) 안울타리를 구하고, 인접값에 기호 | 로 표시한 후, Q1과 Q3으로부터 인접값까지 직선으로 연결한다.")
63
(5) 바깥울타리를 구하여 예측 가능한 보통 이상점의 위치에 “o”를, 그리고 이상점의 위치에 “×”로 표시한다.
 바깥울타리를 구하여 예측 가능한 보통 이상점의 위치에 o 를, 그리고 이상점의 위치에 × 로 표시한다.")
64
[상자그림의 해석] 대부분의 측정값들에 대한 분포 모양 상자그림 중심 위치
![[상자그림의 해석] 대부분의 측정값들에 대한 분포 모양 상자그림 중심 위치](http://slidesplayer.org/slide/15070546/91/images/64/%5B%EC%83%81%EC%9E%90%EA%B7%B8%EB%A6%BC%EC%9D%98+%ED%95%B4%EC%84%9D%5D+%EB%8C%80%EB%B6%80%EB%B6%84%EC%9D%98+%EC%B8%A1%EC%A0%95%EA%B0%92%EB%93%A4%EC%97%90+%EB%8C%80%ED%95%9C+%EB%B6%84%ED%8F%AC+%EB%AA%A8%EC%96%91+%EC%83%81%EC%9E%90%EA%B7%B8%EB%A6%BC+%EC%A4%91%EC%8B%AC+%EC%9C%84%EC%B9%98.jpg "[상자그림의 해석] 대부분의 측정값들에 대한 분포 모양 상자그림 중심 위치")
65
다음 자료에 대한 사분위수범위와 상자그림 (1) 사분위수범위 : Q1 = P25 = = = 49.3 x(25) + x(26) 2 I.Q.R. = Q3 – Q1 = 50.6 – 49.3 = 1.3 Q2 = P50 = = = 49.9 x(50) + x(51) 2 Q3 = P75 = = = 50.6 x(75) + x(76) 2
 사분위수범위 : Q1 = P25 = = = x(25) + x(26) I.Q.R. = Q3 – Q1. = 50.6 – = 1.3. Q2 = P50 = = = x(50) + x(51) Q3 = P75 = = = x(75) + x(76)")
66
(2) 상자그림 : 안울타리를 구하고, Q1, Q3과 인접값을 연결 fl=Q1 – (1.5) • I.Q.R. = = 47.95 fu=Q3 + (1.5) • I.Q.R. = = 52.55 인접값은 각각 48.0과 52.0 바깥울타리를 구한다. Fl=Q1 - 3 • I.Q.R. = = 45.4 Fu=Q3 + 3 • I.Q.R. = = 54.5 관찰값 55.2는 위쪽 바깥울타리보다 크므로 극단 이상점이고, 관찰값 47.2, 47.6은 인접값과 아래쪽 바깥울타리 사이에 있으므로 보통 이상점이다

67
평균 편차(mean deviation; M.D)
각 자료의 관찰값과 평균과의 편차에 대한 절대값들의 평균 M.D = S |xi – x| 1 n i = 1 장점 : 이상점에 대한 영향을 덜 받는다 모든 자료의 정보를 내포하고 있다. 단점 : 수리적으로 처리하기 곤란

68
평균 편차 : 자료집단 : [8, 3, 9, 6, 2, 5, 9, 4, 6, 6] 평균 : 10 = 5.8 x = 각 자료와 평균과의 편차 자료 8 3 9 6 2 5 4 합 : 58 편차 2.2 -2.8 3.2 0.2 -3.8 -0.8 -1.8 합 : 0 편차절대값 2.8 3.8 0.8 1.8 합 : 18.4 평균편차 : M.D = = 1.84 18.4 10
![평균 편차 : 자료집단 : [8, 3, 9, 6, 2, 5, 9, 4, 6, 6] 평균 : = 5.8.](http://slidesplayer.org/slide/15070546/91/images/68/%ED%8F%89%EA%B7%A0+%ED%8E%B8%EC%B0%A8+%3A+%EC%9E%90%EB%A3%8C%EC%A7%91%EB%8B%A8+%3A+%5B8%2C+3%2C+9%2C+6%2C+2%2C+5%2C+9%2C+4%2C+6%2C+6%5D+%ED%8F%89%EA%B7%A0+%3A+%3D+5.8..jpg "x = 각 자료와 평균과의 편차. 자료 합 : 58. 편차 합 : 0. 편차절대값 합 : 평균편차 : M.D = =")
69
☞ ☞ 표본분산(sample variance; s2) 표본표준편차(sample standard deviation; s)
분산, 표준편차는 가장 널리 사용하는 산포의 척도 자료집단의 관찰값들이 평균을 중심으로 밀집되어 있는 정도를 나타냄. 표준편차가 클수록 자료는 중심으로부터 넓게 분포되고, 작을수록 중심에 많이 밀집하는 것을 의미 추측통계학에서 바람직하게 모분산을 추측하기 위하여 ☞ 모분산(population variance) s2 = S (xi – m)2 1 N i = 1 모집단의 분산 : ☞ 표본분산, 표본표준편차 추측통계학에서 바람직하게 모분산을 추론하기 위하여 1 n-1 i = 1 n s = S (xi – x )2 1 n-1 i = 1 n 표본의 분산 : s2 = S (xi – x )2 표본의 표준편차 :
 s2 = S (xi – m)2. 1. N. i = 1. 모집단의 분산 : ☞ 표본분산, 표본표준편차. 추측통계학에서 바람직하게. 모분산을 추론하기 위하여. 1. n-1. i = 1. n. s = S (xi – x )2. 1. n-1. i = 1. n. 표본의 분산 : s2 = S (xi – x )2. 표본의 표준편차 :")
70
예제 3의 자료에 대한 표준편차 : 자료집단 : [8, 3, 9, 6, 2, 5, 9, 4, 6, 6] 평균 : x = 5.8
합 : 58 편차 2.2 -2.8 3.2 0.2 -3.8 -0.8 -1.8 합 : 0 편차절대값 2.8 3.8 0.8 1.8 합 : 18.4 편차제곱 4.84 7.84 10.24 00.4 14.44 0.64 3.24 0.04 합 : 51.6 s2 = = 5.733 51.6 9 분산 : 표준편차 : s = = 2.394
![예제 3의 자료에 대한 표준편차 : 자료집단 : [8, 3, 9, 6, 2, 5, 9, 4, 6, 6] 평균 : x = 5.8](http://slidesplayer.org/slide/15070546/91/images/70/%EC%98%88%EC%A0%9C+3%EC%9D%98+%EC%9E%90%EB%A3%8C%EC%97%90+%EB%8C%80%ED%95%9C+%ED%91%9C%EC%A4%80%ED%8E%B8%EC%B0%A8+%3A+%EC%9E%90%EB%A3%8C%EC%A7%91%EB%8B%A8+%3A+%5B8%2C+3%2C+9%2C+6%2C+2%2C+5%2C+9%2C+4%2C+6%2C+6%5D+%ED%8F%89%EA%B7%A0+%3A+x+%3D+5.8.jpg "합 : 58. 편차 합 : 0. 편차절대값 합 : 편차제곱 합 : s2 = = 분산 : 표준편차 : s = =")
71
변동계수(coefficient of variation; C.V)
측정 단위가 동일하지만 평균이 큰 차이를 보이는 두 집단의 흩어진 정도 서로 다른 단위를 갖는 두 집단의 흩어진 정도를 상대적으로 비교하는 척도 변동계수가 클수록 자료의 분포상태는 상대적으로 폭이 넓게 분포한다. C.VP = s m 모집단의 변동계수 : C.VS = s x 표본단의 변동계수 : 수컷 코끼리의 몸무게는 평균 4,550kg 표준편차 150kg이고, 어떤 종류의 쥐의 몸무게는 평균 30g 표준편차 1.67g이라고 한다. 코끼리와 쥐의 상대적인 흩어 진 정도를 비교 150 4550 코끼리의 변동계수 : C.Ve = = 0.033 코끼리의 몸무게가 쥐의 몸무게보다 상대적으로 평균에 더 밀집 1.67 30 쥐의 변동계수 : C.Vm = = 0.056

72
z-점수(z-score), 표준점수(standard score)
절대적인 수치로 주어지는 개개의 특정한 측정값을 전체 자료집단의 상대적인 수치로 변환한 척도 zp = xi - m s 모집단의 표준점수 : zS = xi – x s 표본의 표준점수 : 두 자료집단의 절대적인 비교와 표준점수에 의한 비교 77, 80, 76, 87, 85, 71, 75, 76, 81, 87, 75, 85, 78, 79, 86 B 20, 35, 43, 28, 37, 35, 49, 28, 32, 25, 39, 29, 28, 36, 44 A 측 정 값 집단 예

73
자료집단 A와 자료집단 B의 평균과 표준편차의 비교
xA = , sA = 7.84 xB = , sB = 5.08 두 집단의 절대 측정값에 대한 점도표 비교 [결과] 자료집단 A에 비하여 자료집단 B의 평균이 매우 클 뿐만 아니라 평균에 관한 자료의 밀집정도도 자료집단 B가 작다. z-점수 : zA = x – 33.87 7.84 zB = y – 79.87 5.08 ,

74
A 20 35 43 28 37 49 표준점수 0.1446 1.1655 0.3998 1.9312 32 25 39 29 36 44 0.6551 0.2722 1.2931 B 77 80 76 87 85 71 75 0.0262 1.4033 1.0099 81 78 79 86 0.2230 1.2066 표준점수에 대한 점도표 비교

75
제 6 장

Similar presentations
 계산 컴퓨터에서 숫자를 표기하는 방법 가수 (Fraction) : 부호화된 고정소수점 숫자 지수 (Exponent) : 소수점의 위치를 표시 ( 예 )10 진수 +6132.789 를 표기하면 Fraction Exponent.>")
 통계량 (statistic) 표본자료의 함수 즉 모집단 … … 표본 표본추출 … … 통계량 계산.>")












>")
>")



