제 5 장 stack and queue
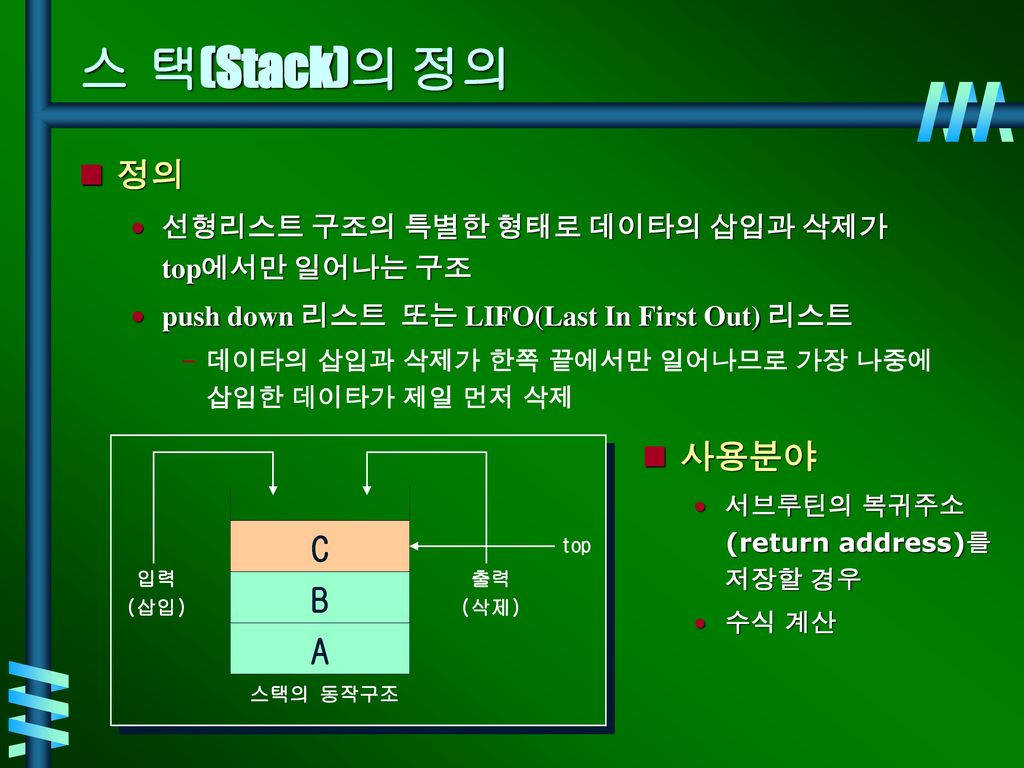
스 택(Stack)의 정의 정의 사용분야 C B A 선형리스트 구조의 특별한 형태로 데이타의 삽입과 삭제가 top에서만 일어나는 구조 push down 리스트 또는 LIFO(Last In First Out) 리스트 데이타의 삽입과 삭제가 한쪽 끝에서만 일어나므로 가장 나중에 삽입한 데이타가 제일 먼저 삭제 사용분야 서브루틴의 복귀주소 (return address)를 저장할 경우 수식 계산 C top 입력 (삽입) B 출력 (삭제) A 스택의 동작구조
스택 표현과 연산 (1/4) 스택 표현 1차원 배열 표현 - 스택이 포함할 수 있는 최대 크기를 알 수 있을 때 연결 리스트로 표현 - 스택의 최대 크기를 알 수 없을 때 top D 4 C B top D C B A A (b) (a)를 연결리스트로 표현 (a) 배열표현
스택 표현과 연산 (2/4) 연 산 push(x) - 스택에 데이터x를 삽입하는 연산, top의 값을 1씩 증가 pop() - 스택의 데이타를 삭제하는 연산, top의 값을 1씩 감소
스택 표현과 연산 (3/4) 스택의 수행과정 1 C 3 B 2 B A 1 A A top top top top (a) 초기상태 A 1 A A (a) 초기상태 (b) A 삽입후 (c) B 삽입후 (d) C 삽입후
스택 표현과 연산 (4/4) 스택의 수행과정 2 D 4 D D D C C 3 C E 3 B B B 2 B A A A A top (e) D 삽입후 (f) D 삭제후 (c) C 삭제후 (d) E 삽입후
스택의 배열 구현 (1/3) 스택 선언 항목유무조사 공백인 스택 : top== -1; item 배열: 스택의 항목 top: 현 스택의 top 위치 항목유무조사 공백인 스택 : top== -1; #define MAXSTACK 100 struct stack{ int item[MAXSTACK]; int top; }; struct stack *s; if (s->top == -1) printf(“stack is empty”); else printf(“stack is not empty”);
스택의 배열 구현 (2/3) 항목 삭제 int pop(struct stack *s){ int popp; if (s->top == =1){ printf(“stack underflow”); exit(1); } popp=s->item[s->top--]; return(popp);
스택의 배열 구현 (3/3) 항목 삽입 void push(struct stack *s, int x){ if(s->top == MAXSTACK-1){ printf(“stack overflow”); exit(1); } s->item[++s->top]=x;
스택 오버플로우 처리 (1/2) 하나의 기억장소에 2개 스택을 보관 운영하는 방법 top : 입출력이 발생되는 스택의 끝 bottom : 스택의 시작 위치 STACK1 STACK2 좌우로 이동할 수 있음 STACK1 가용 공간 STACK2 bottom1 top1 top2 bottom2
스택 오버플로우 처리 (2/2) ··· 하나의 기억장소에 n개의 스택을 보관 운영하는 방법 topi = bottomi 이면 i 번째 스택의 empty topi = bottomi+1 이면 i 번째 스택의 포화 상태 topi > bottomi+1 이면 i번째 스택의 오버플로 기억 장소의 빈 공간을 찾아 기억 공간을 재압축(repacking) STACK1 STACK2 STACK3 ··· STACK4 bottom1 top1 top2 top3 topn-1 topn bottom2 bottom3 bottom4 bottomn 초기상태 bottom1 = top1 bottom2 = top2 bottomn = topn
수식계산 (1/4) 연산자의 우선순위 연산에서 괄호가 없을 경우 또는 괄호 내에서 우선순위가 필요 연산자 우선 순위 단항연산자 -, ! 6 *, /, % 5 +, - 4 <, <=, >, >= 3 && 2 ∥ 1
수식계산 (2/4) 수식 표기법 중위(infix) 표기 방법 전위(prefix) 표기 방법 <피연산자-연산자-피연산자> 예) A + B 전위(prefix) 표기 방법 <연산자-피연산자-피연산자> 예) + A B 중위 표기 -> 전위 표기 방법으로의 전환 예) (((((-A) / B) * C) + (D * E)) - (A * C)) => - + * / - A B C * D E * A C 후위(postfix or reverse polish) 표기 방법 <피연산자-피연산자-연산자> 예) A B + 컴퓨터가 수식을 계산하기에 가장 적합한 방법 컴파일러 : 중위표기 수식을 후기 표기 방법으로 변환한 후 스택을 이용 수식 계산
수식계산 (3/4) 후위 표기식의 장점 후위 표기식 계산 알고리즘 괄호를 필요로 하지 않는다. 연산자들의 우선 순위가 필요 없게 된다. 스택을 사용하면 식을 왼쪽에서 오른쪽으로 읽어 가면서 쉽게 계산할 수 있다. 후위 표기식 계산 알고리즘 수식을 구성하는 원소(token)을 읽어서 그것이 피연산자이면 스택에 넣고, 연산자이면 필요한 수만큼의 피연산자를 꺼내어 연산을 수행하고 그 결과를 스택에 다시 넣는다
수식계산 (4/4) 중위 표기식을 후위 표기식으로의 변환 알고리즘 중위에서 후위 표기식으로 변환 시 스택 이용 중위 표기실을 연산자들의 우선순위에 따라 완전한 괄호를 포함하는 식으로 표현 모든 연산자들을 그와 대응하는 오른쪽 괄호의 밖으로 옮김 괄호를 모두 제거 중위에서 후위 표기식으로 변환 시 스택 이용 연산자의 올바른 연산 위치를 결정하기 위하여 스택 이용 스택 속의 연산자 우선 순위 ISP(in-stack priority) 새로 읽은 연산자의 우선 순위 ICP(in-coming priority) ISP ICP: 스택 속의 연산자를 꺼내어 출력하고 읽은 연산자는 스택에 저장한다. ISP < ICP: 새로 읽은 연산자를 스택에 저장
미로 실험[1/2] 스택 이용 지금까지 지나왔던 길을 되돌아와서 어느 일정한 위치에서 다시 새로운 탐색을 시작해야 하는데 이때 지나가는 경로를 스택 구조를 이용하여 구현하면 지나왔던 길로 쉽게 되돌아 감 미로 maze[m+2][n+2]: 가로 길이가 m칸이고, 세로 길이가 n칸 (행과 열 각 추가의 2개 요소는 가장자리의 표현의 위함) 배열 값 1: 길이 없는 경우 배열 값 0: 길이 있는 경우 (즉, 미로의 벽은 1에 해당) 시작 위치: maze[1][1], 출구: maze[m][n] maze[11][11] 1
미로 실험[2/2] 쥐의 이동 쥐의 위치: 행과 열의 인덱스 (i,j) 배열 move 배열 mark[m+2][n+2] 문제 해결을 간단히 하기 위하여 별도의 배열에 가능한 움직임들에 대한 정보를 미리 저장 배열 mark[m+2][n+2] 한번 갔던 길을 다시 가는 일을 막기 위하여 0으로 초기화된 배열 쥐가 미로의 (i,j)를 지나갈 때에 mark(i,j)를 1로 만들어 나중에 방향을 선택할 때에 지나갔던 길인지를 판별
큐(Queue)의 정의 정의 한쪽 끝에서 항목들이 삭제되고, 다른 한쪽 끝에서 항목들이 삽입되는 선형 리스트 FIFO(First-In First-Out) : 가장 먼저 삽입된 항목이 가장 먼저 삭제 응용 작업 스케줄링, 대기 행렬 이론(queueing theory) 삭제 삽입 -1 1 2 3 A B C D 프런트(front) 리어(rear)
큐의 배열 표현과 연산 (1/2) 큐의 표현 1차원 배열 : Queue[T] Queue = [Q0, Q1, Q2,...QT-1] front(Q) = Q0 rear (Q) = QT-1 front : 실제 큐의 front보다 하나 앞을 가리킴 rear : 실제 큐의 rear 큐가 빈 상태 : front = rear 큐의 초기조건 : front = rear = -1
큐의 배열 표현과 연산 (2/2) 큐의 삽입과 삭제 ··· A B C D ··· -1 1 2 3 front front rear 1 2 3 ··· A B C D ··· front front rear rear (삭제) (삽입)
큐의 배열 구현(1/3) 큐 선언 struct queuestruct { int queue[100]; int f, r; }; struct queuestruct *q;
큐의 배열 구현(2/3) 항목 삽입 void AddQueue(strcut queuestruct *q, int item){ if(q->r = = MAXQUEUE-1) q_full(); /* 단, MAXQUEUE는 해당 큐의 크기 */ else q->queue[++q->r]=item; }
큐의 배열 구현(3/3) 항목 삭제 int DeleteQueue(struct queuestruct *q){ if (q->f == q->r) q_empty(); else return(q->queue[++q->f]); return(0); }
큐의 단점과 해결책 큐의 단점 rear가 배열의 마지막 원소를 가리키는 경우 (rear == MAXQUEUE-1)가 반드시 MAXQUEUE개의 항목이 차 있는 것을 의미하지 않음. front == -1, rear == MAXQUEUE-1 이면 오버플로우 front가 -1보다 크면 데이타 항목이 삭제된 것이므로 큐에 빈 공간이 남아 있음. 계속 항목을 삭제하면 rear pointer와 front pointer가 만나게 되고 공백 큐가 되는데도 오버플로우 현상 발생. 해결책 큐 전체를 왼쪽으로 옮기고 front를 -1로 하고 rear의 값을 조정. 원형 큐 큐의 배열을 선형으로 표현하지 않고 원형으로 표현하는 방법.
원형 큐(Circular Queue) (1/3) 원형 큐의 정의 큐의 배열(arrangement)을 원형으로 표현. 큐를 구성하는 배열의 처음과 끝을 이어놓은 형태의 큐. N개의 원소를 갖는 원형 큐 … … [n-4] I1 [4] [n-3] [4] [n-3] I4 I2 I3 [3] [n-2] [3] I3 [n-2] I2 I4 I1 [2] [n-1] I5 [2] [n-1] [1] [0] [1] [0] front = 0; rear = 4 front = n-5; rear = 0
원형 큐(Circular Queue) (2/3) 항목 삽입 void InsertQ(struct queuestruct *q, int item){ q->r = (q->r +1) % MAXQUEUE; if (q->f == q->r) q_full(); else q->queue[++q->r] = item; }
원형 큐(Circular Queue) (3/3) 항목 삭제 int deleteQ(struct queuestruct *q){ int item; if(q->f == q->r) q_empty(); else{ q->f = (q->f +1) % MAXQUEUE; item=q->queue[++q->f]; return(item); }
데크(Deque : Double Ended Queue) 정의 삽입과 삭제가 양쪽 끝에서 모두 허용될 수 있는 선형 리스트 스택과 큐를 선형리스트 구조에 복합 시킨 형태. 두개의 스택의 bottom 부분이 서로 연결된 것. 삭제 A B C D 삽입 삽입 삭제 end1 end2
데크의 표현 및 연산 스택을 이용하는 경우 연결 리스트를 이용하는 경우 두개의 스택을 연결. 스택들이 뚜렷한 경계가 있거나, 스택의 마지막 원소의 위치를 저장해 놓을 수 있다면 스택들이 같은 기억장소 공유 가능. 기억 장소 오버플로우 발생. 양쪽 끝에서 삽입/삭제 가능하기 때문에 두개의 포인터(left, right 또는 top, bottom) 필요. 연결 리스트를 이용하는 경우 한 데이타 항목을 첨가해야 할 때 사용 가능한 기억 공간을 확보해 주는 함수 이용. 원소 삭제될 때에는 기억 장소 관리 함수를 이용하여 반환
Deque의 종류 입력 제한 데크 출력 제한 데크 입력이 한쪽 끝에서만 일어나도록 제한 (스크롤(scroll)) 출력이 한쪽 끝에서만 일어나도록 제한 (셀프(shelf))