Selenium & Beautiful Soup 파이썬을 활용한 금융 데이터 분석 기초 및 심화 과정 1 1
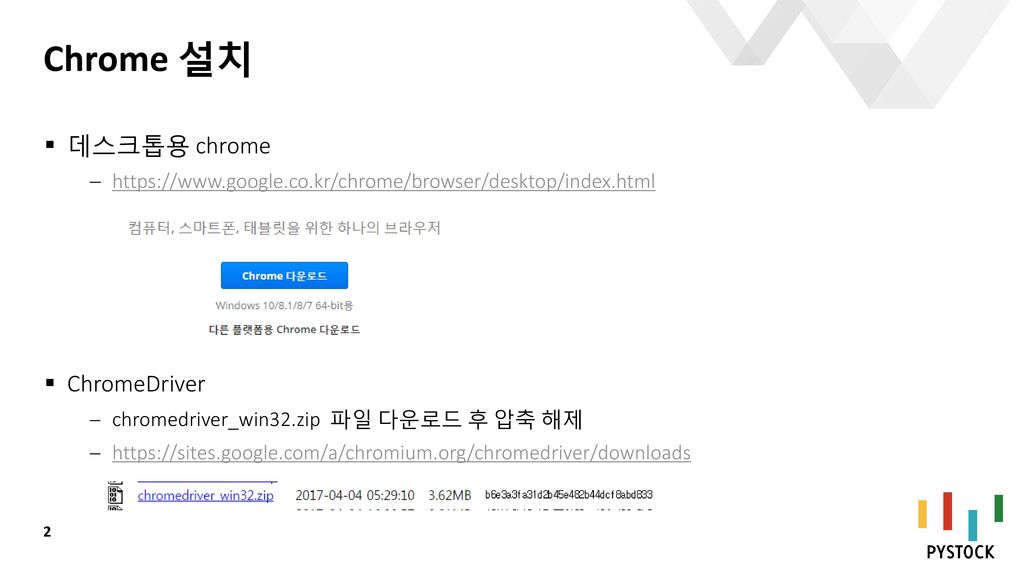
Chrome 설치 데스크톱용 chrome ChromeDriver https://www.google.co.kr/chrome/browser/desktop/index.html ChromeDriver chromedriver_win32.zip 파일 다운로드 후 압축 해제 https://sites.google.com/a/chromium.org/chromedriver/downloads
Selenium 모듈 설치 Python bindings for Selenium 윈도우 명령 프롬프트를 실행한 후 다음 명령어를 입력 pip install –U selenium
Selenium으로 네이버 띄우기 from selenium import webdriver lab04/Selenium/01.py Selenium으로 네이버 띄우기 from selenium import webdriver browser = webdriver.Chrome("chromedriver.exe") # chrome driver 파일의 경로 설정 browser.get("http://www.naver.com")
네이버 검색하기 from selenium import webdriver lab04/Selenium/02.py 네이버 검색하기 from selenium import webdriver browser = webdriver.Chrome("chromedriver.exe") browser.get("http://www.naver.com") # 네이버 검색창 (id를 통해 찾거나 class를 통해 찾을 수 있습니다.) input = browser.find_element_by_class_name("input_text") #input = browser.find_element_by_id("query") input.send_keys("미래에셋대우") input.submit()
네이버 로그인하기 (1/2) 크롬 개발자도구를 사용하여 아이디/비밀번호의 id를 확인
네이버 로그인하기 (2/2) from selenium import webdriver lab04/Selenium/03.py 네이버 로그인하기 (2/2) from selenium import webdriver browser = webdriver.Chrome("chromedriver.exe") browser.get("http://www.naver.com") # 네이버 검색창 id = browser.find_element_by_id("id") id.send_keys("네이버 아이디") passwd = browser.find_element_by_id("pw") passwd.send_keys("네이버 패스워드") passwd.submit()
Beautiful Soup Beautiful Soup Parser Beautiful Soup is a Python library for pulling data out of HTML and XML files https://www.crummy.com/software/BeautifulSoup/bs4/doc/ Parser html.parser (default) lxml html5lib (설치하기)
Parser 선택의 차이 lab04/Selenium/04.py from bs4 import BeautifulSoup html = ''' <p id="foo1"> 첫 번째 문단 </p> <p id="foo2"> 두 번째 문단 </p> ''' soup1 = BeautifulSoup(html, "html.parser") soup2 = BeautifulSoup(html, "html5lib") print(soup1) print(soup2) html.parser html5lib
Navigating HTML (1/5) find_all select soup.find_all(“p”) soup.find_call([“th”, “td”]) soup.find_all(class_=“ohlc”) soup.find_all(id=“test”) select soup.select(“p”) soup.select(“th, td”) soup.select(“.ohlc”) soup.select(“[id=test]”)
Navigating HTML (2/5) from bs4 import BeautifulSoup lab04/Selenium/05.py Navigating HTML (2/5) from bs4 import BeautifulSoup soup = BeautifulSoup(open("./01.html", encoding="utf-8"), "html5lib") print(soup.find_all("div")) print(soup.select("div")) [<div id="test"> Example <div> OHLC </div></div>, <div> OHLC </div>]
Navigating HTML (3/5) lab04/Selenium/06.py from bs4 import BeautifulSoup soup = BeautifulSoup(open("./01.html", encoding="utf-8"), "html5lib") print(soup.find_all(["th", "td"])) print(soup.select("th, td"))
Navigating HTML (4/5) lab04/Selenium/07.py from bs4 import BeautifulSoup soup = BeautifulSoup(open("./01.html", encoding="utf-8"), "html5lib") print(soup.find_all(class_="ohlc")) print(soup.select(".ohlc"))
Navigating HTML (5/5) lab04/Selenium/08.py from bs4 import BeautifulSoup soup = BeautifulSoup(open("./01.html", encoding="utf-8"), "html5lib") print(soup.find_all(id="test")) print(soup.select("[id=test]"))
네이버 메일 목록 가져오기 (1/2) 메일 주소 https://mail.naver.com/ lab04/Selenium/09.py 네이버 메일 목록 가져오기 (1/2) 메일 주소 https://mail.naver.com/ 메일 목록에 해당하는 CSS Selector를 복사 적당히 다듬기
네이버 메일 목록 가져오기 (2/2) browser.get("https://mail.naver.com") html = browser.page_source soup = BeautifulSoup(html, "html.parser") subject_list = soup.select('ol.mailList > li > div.mTitle > div.subject > a > span') for i in subject_list[::3]: print(i.text.strip()[11:])
네이버 페이 동일한 방식으로 CSS Selector 확인 lab04/Selenium/10.py 네이버 페이 동일한 방식으로 CSS Selector 확인 browser.get("https://order.pay.naver.com/home") html = browser.page_source soup = BeautifulSoup(html, "html.parser") buy_list = soup.select('div.p_inr > div.p_info > a > span') for item in buy_list: print(item.text.strip())
국고채 금리가져오기 http://www.index.go.kr/strata/jsp/showStblGams3.jsp?stts_cd=288401&idx_cd=2884&freq=Y&period=1998:2016
국고채 금리가져오기 import requests from bs4 import BeautifulSoup url = "http://www.index.go.kr/strata/jsp/showStblGams3.jsp?stts_cd=288401&idx_cd=2884&freq=Y&period=1998:2016" html = requests.get(url).text soup = BeautifulSoup(html, "html5lib") tr_data = soup.select("tr > td") for tr in tr_data: print(tr.text)