질의처리 최적화 충북대학교 정보통신공학부 복경수 ksbok@chungbuk.ac.kr
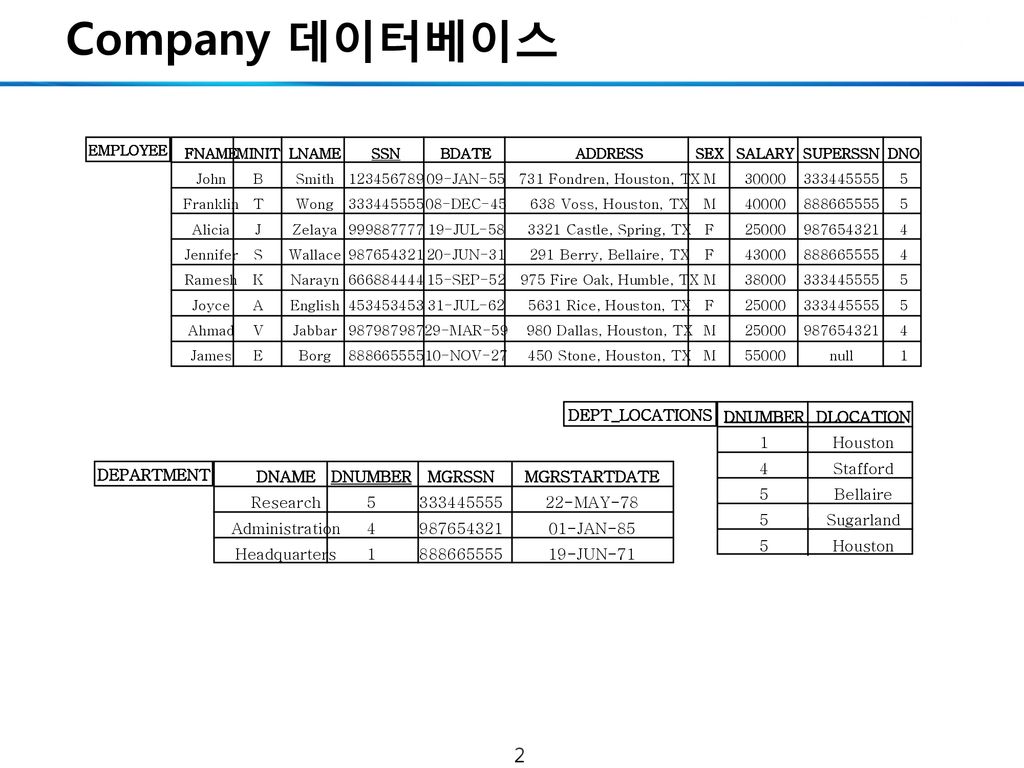
Company 데이터베이스 DEPARTMENT DNAME Research Administration Headquarters EMPLOYEE FNAME John Franklin Alicia Jennifer Ramesh Joyce Ahmad James MINIT B T J S K A V E LNAME Smith Wong Zelaya Wallace Narayn English Jabbar Borg SSN 123456789 333445555 999887777 987654321 666884444 453453453 987987987 888665555 BDATE 09-JAN-55 08-DEC-45 19-JUL-58 20-JUN-31 15-SEP-52 31-JUL-62 29-MAR-59 10-NOV-27 ADDRESS 731 Fondren, Houston, TX 638 Voss, Houston, TX 3321 Castle, Spring, TX 291 Berry, Bellaire, TX 975 Fire Oak, Humble, TX 5631 Rice, Houston, TX 980 Dallas, Houston, TX 450 Stone, Houston, TX SEX M F SALARY 30000 40000 25000 43000 38000 55000 SUPERSSN null DNO 5 4 1 DEPARTMENT DNAME Research Administration Headquarters DNUMBER MGRSSN MGRSTARTDATE 22-MAY-78 01-JAN-85 19-JUN-71 DEPT_LOCATIONS DLOCATION Houston Stafford Bellaire Sugarland
Company 데이터베이스 PROJECT PNAME ProductX ProductY ProductZ Computerization Reorganization Newbenefits PNUMBER 1 2 3 10 20 30 PLOCATION Bellaire Sugarland Houston Stafford DNUM 5 4 1 WORKS_ON ESSN 123456789 666884444 453453453 333445555 999887777 987987987 987654321 888665555 PNO 1 2 3 10 20 30 HOURS 32.5 7.5 40.0 20.0 10.0 30.0 35.0 5.0 15.0 null DEPENDENT ESSN 333445555 987654321 123456789 DEPENDENT_NAME Alice Theodore Joy Abner Michael Allice Elizabeth SEX F M BDATE 05-APR-76 25-OCT-73 03-MAY-48 29-FEB-32 01-JAN-78 32-DEC-78 05-MAY-57 RELATIONSHIP DAUGHTER SON SPOUSE
고수준 질의 처리 과정 어휘 분석, 구문 분석, 검증 고수준 언어로 표현된 질의 질의를 중간 형태로 표현 실행 계획 질의를 실행하기 위한 코드 질의 결과 질의 최적화 질의 코드 생성기 런타임 데이터베이스 처리기 코드는 직접 실행되거나 (인터프리터 방식), 저장된 뒤 필요할 때마다 실행될 수 있음 (컴파일 방식)
고수준 질의 처리 과정 어휘 분석 및 검증 스캐너 파서 질의 트리 실행 전략 런타임 데이터베이스 처리기 질의에서 질의어의 토큰(SQL키워드, 애트리뷰트이름, 릴레이션 이름)을 식별 파서 질의의 구문이 질의어의 문법 규칙에 맞게 작성되었는지 검사 질의에 사용된 애트리뷰트와 릴레이션의 이름들이 데이터베이스 스키마에 유효하고 의미적으로 합당한지 검사 질의 트리 질의의 내부 표현을 생성->질의 그래프라는 그래프 자료구조를 표현 실행 전략 하나의 질의는 다수의 가능한 실행 전략을 가짐 질의 최적화는 질의를 처리하는데 적절한 실행 전략을 선택 코드 생성기는 실행 계획을 수행하기 위한 코드를 생성 런타임 데이터베이스 처리기 질의 코드를 실행하여 질의 결과를 생성 오류 발생시 런타임 데이터베이스 처리기가 오류 메시지를 발생
SQL 질의를 관계대수로 번역 관계대수 번역 SQL 질의는 관계 대수식으로 번역하고 질의 트리 자료구조로 표현 질의 트리 자료구조로 표현되면 최적화가 수행 전형적인 SQL 질의는 질의 블록(query block)들올 구분 질의 블록은 대수 연산자들로 번역되어 최적화되는 기본 단위 하나의 질의 블록은 하나의 SELECT-FROM-WHERE식으로 포함 질의 안에 중첩된 하나의 질의 블록은 별개의 질의 블록으로 취급 질의 최적화기는 각 블록에 대하여 실행 계획을 수립
SQL 질의를 관계대수로 번역 SQL 질의 SELECT LNAME,FNAME FROM EMPLOYEE WHERE SALARY > (SELECT MAX(SALARY) FROM EMPLOYEE WHERE DNO = 5); (2) 질의 블록들로 분해: 외부블록 : SELECT LNAME,FNAME FROM EMPLOYEE WHERE SALARY > C 내부블록: SELECT MAX(SALARY) FROM EMPLOYEE WHERE DNO = 5 (3) 관계대수로 번역: 외부블록:πLNAME, FNAME(σSALARY>C(EMPLOYEE)) 내부블록: MAX SALARY (σDNO=5(EMPLOYEE)) // 확장된 관계대수식
외부 정렬 알고리즘 외부 정렬 필요성 대부분의 데이터베이스 화일처럼 디스크에 저장된 레코드들로 구성 주기억 장치에 한꺼번에 수용할 수 없는 대규모 화일들에 적합한 정렬 알고리즘 필요성 ORDER BY 절, SELECT 절의 DISTINCT, 조인 연산의 처리에서 사용 집합 연산 (합집합, 교집합, 차집합)의 처리에서도 사용
외부 정렬 알고리즘 정렬-합병 알고리즘 주 화일을 런(run)이라고 하는 작은 부화일(subfile)들로 나눔 이들을 정렬한 후 정렬한 런들을 합병하여 더 큰 규모의 정렬된 부화일들을 생성하는 과정을 반복 주기억 장치에 버퍼 공간을 필요로 하며 그 버퍼 공간에서 런들의 실제 정렬과 합병이 수행 정렬 단계 이용가능한 버퍼 공간에 들어갈 수 있는 화일의 런들을 주기억 장치로 읽어온 뒤, 내부 정렬 알고리즘을 이용하여 정렬 이들을 임시 정렬된 부화일(또는 런)로서 디스크에 저장 Read RUN; Sort; Write RUN 합병 단계 정렬된 런들이 한 번 이상의 패스(pass)를 거쳐 합병 4-way 합병 (4개의 RUN들을 합병하여 하나의 RUN을 생성) 하나의 RUN으로 될 때 까지 합병을 반복 수행
선택 연산 단순 선택(simple selection)을 위한 탐색 방법 화일 스캔 인덱스 스캔 S1. 선형 탐색(linear search) S2. 이진 탐색(binary search) 인덱스 스캔 S3. 기본 인덱스나 해시 키를 사용하여 단일 레코드를 검색 S4. 기본 인덱스를 사용하여 여러 개의 레코드들을 검색 S5. 클러스터링 인덱스를 사용하여 여러 개의 레코드들을 검색 S6. 보조(B+-트리) 인덱스를 사용
선택 연산 복합 선택(complex selection)을 위한 탐색 방법 논리곱 조건(conjunctive condition)인 경우 : 여러 단순 조건들이 AND로 연결된 것 인덱스를 이용하여 레코드 포인터들을 구하고 이들을 통해 레코드들을 읽어서 다른 조건들을 비교 S7. 개별 인덱스를 사용하는 논리곱 선택(conjunctive selection) S8. 복합 인덱스를 사용하는 논리곱 선택 S9. 레코드 포인터들의 교집합에 의한 논리곱 선택 논리합 조건인 경우 : 여러 단순 조건들이 OR로 연결된 것 각 조건을 만족하는 레코드들의 합집합 방법 1. 단순 조건들 중 어느 하나라도 접근경로를 가지지 않으면 선형 탐색 방법을 사용할 수 밖에 없음 방법 2. 각 조건을 만족하는 레코드 포인터들의 합집합을 구하여 레코드들을 읽음
선택 연산 선택률(selectivity) 조건을 만족하는 투플수를 릴레이션의 전체 투플수로 나눈 값: 0과 1 사이의 값 선택률에 따라 인덱스를 선택 모든 조건에 대하여 정확한 선택률을 가질 수 없음 선택률 추정치는 DBMS 카탈로그에 유지되며 최적화기가 이를 사용
조인 연산 조인 연산 질의 처리에서 가장 시간이 많이 소요되는 연산 중 하나 J1. 중첩 루프 조인(nested loop join) R(외부 루프)의 각 레코드에 대해 S(내부 루프)의 모든 레코드를 검색 두 레코드가 조인조건을 만족하는가를 테스트 J2. 단일 루프 조인(single loop join) R에 있는 각 레코드에 대해 인덱스를 사용 S의 레코드들 중에서 조인 조건을 만족하는 모든 레코드들을 검색 J3. 정렬-합병 조인(sort-merge) R과 S의 모든 레코드들을 조인 애트리뷰트를 기반으로 정렬 R과 S의 화일 블록들의 쌍을 순서대로 읽어서 조인 조건을 테스트 J4. 해시조인(hash join) 분할단계 : R의 레코드들을 해시 화일 버켓들로 해시 조사단계: S의 각 레코드를 해시하여 동일한 해시주소를 갖는 각 버켓에 속하는 R과 S의 레코드들이 조인조건을 만족하면 결합
프로젝트와 집합 연산 ∏<attribute list> (R) 합집합, 교집합, 차집합 카티션 프로덕트(R X S) 연산의 결과를 정렬한 다음 중복된 투플을 제거 합집합, 교집합, 차집합 합집합 호환성 릴레이션들에만 적용 동일한 애트리뷰트들에 대해 두 릴레이션들을 정렬 후 각 릴레이션을 한번 조사하는 것으로 결과를 산출 카티션 프로덕트(R X S) 구현 비용이 많이 소요 질의 최적화 동안 연산을 피하고 동등한 연산으로 대치
집계 연산 집계 연산자 MIN, MAX, COUNT, AVERAGE, SUM SELECT MAX(SALARY) FROM EMPLOYEE SALARY에 대하여 인덱스가 있는 경우: 그 인덱스를 이용하여 집단 연산의 결과를 구할 수 있음 SALARY에 대해 인덱스가 없는 경우: 화일 스캔을 해야 함 인덱스는 밀집 인덱스, 즉 주 화일의 각 레코드에 대하여 하나의 엔트리를 가지는 경우 COUNT, AVERAGE, SUM 연산자에 대해서도 사용 인덱스 내의 값들에 해당 연산을 적용 비밀집 인덱스의 경우에는 정확한 계산을 위해 각 인덱스 엔트리와 연관된 레코드들의 실제 개수가 사용 인덱스로부터 유일한 값들의 개수를 계산할 수 있는 COUNT DISTINCT의 경우는 예외
집계 연산 SELECT DNO, AVG(SALARY) FROM EMPLOYEE GROUP BY DNO; 해슁을 이용하여 투플들을 각 그룹으로 분할하여 그룹들을 생성한 후 각 그룹에서 집계 연산을 수행
외부 조인 SELECT LNAME, FNAME, DNAME FROM (EMPLOYEE LEFT OUTER JOIN DEPARTMENT ON DNO=DNUMBER); 조인 알고리즘을 수정하여 구현 내부 조인을 계산한 결과 생성 조인 결과에 나타나지 않은 투프를 검색하여 NULL 값을 부여 두 결과를 합집합 연산을 수행 별개 알고리즘 고안 외부 조인을 위하여 조인 알고리즘의 수정이 아닌 별개의 알고리즘을 개발할 수도 있으나 이의 효율성은 낮음
파이프라이닝을 사용한 연산 결합 일반적인 연산 SQL로 명시된 질의는 관계 대수식으로 변환 만일 한번에 하나의 연산을 실행한다면 임시 연산들의 결과를 저장하기 위해 디스크에 임시 파일을 생성 디스크에 대규모 임시 파일을 생성하고 저장하는데 많은 시간 소요 임시 파일은 즉시 다른 연산의 입력으로 사용 임시 파일들의 수를 감소시키기 위해 질의 내의 연산들의 조합에 대한 알고리즘에 대응되는 질의 실행 코드를 생성하는 것이 보편적
파이프라이닝을 사용한 연산 결합 파이프라이닝 또는 스트림 기반 처리(stream-based processing) 질의 처리 도중에 생성되는 임시 결과 화일의 수를 감소시키는데 목적 하나의 연산의 결과를 임시 화일에 저장하는 대신에 다음 연산의 입력으로 사용하는 것이 파이프라이닝의 기본 아이디어 예 기본 릴레이션들에 대하여 두 개의 실렉트 연산 다음에 조인 연산이 오면 각 실렉트 연산의 결과물인 투플들은 생성되는 대로 스트림 또는 파이프라인 상에서 조인 알고리즘의 입력으로 제공
경험적 질의 최적화 경험적 규칙들을 사용 질의의 내부 표현(일반적으로 질의 트리 또는 질의 그래프 자료 구조)을 변형 실행 시 기대되는 성능을 향상시키는 최적화 기술 고수준의 질의를 위한 파서는 먼저 초기 내부 표현을 생성하고 이는 경험적 규칙들에 따라 최적화 그 다음에, 질의에 포함된 화일들에서 사용 가능한 접근 경로들에 근거하여 연산들의 집단을 실행하기 위한 질의 실행 계획이 생성 성능 향상을 위한 경험적 규칙들 예: 조인을 수행하기 전에 실렉트나 프로젝트 연산을 수행 경험적 규칙들의 적용대상 질의에 대하여 파서가 생성한 초기 내부 표현 : 질의 트리 또는 질의 그래프 질의 트리 : 관계대수 혹은 확장된 관계 대수식을 표현하는데 사용 질의그래프: 관계 해석식을 표현하는데 사용
질의 트리 질의 트리 : 관계대수식의 내부 표현 질의트리의 구조 질의 트리의 실행 리프노드 : 질의의 입력 릴레이션들 내부노드 : 관계대수 연산들 질의 트리의 실행 트리는 질의에 포함된 연산들의 처리 순서를 나타냄 내부노드의 연산에 대해 피연산자가 사용 가능할 때마다 그 연산을 실행하고, 그 연산의 결과로 생성된 릴레이션으로 그 내부노드를 대치한다. 루트노드가 실행되어 질의에 대한 최종 결과 릴레이션이 생성되면 실행이 종료
질의 트리 관계 대수 표현 SQL 표현 SELECT PNUMBER, DNUM, LNAME, ADDRESS, BDATE FROM PROJECT, DEPARTMENT, EMPLOYEE WHERE DNUM=DNUMBER AND MGRSSN=SSN AND PLOCATION=‘Stafford’ ∏ PNUMBER, DNUM,LNAME,ADDRESS,BDATE(((σ PLOCATION=‘Stafford’(PROJECT)) DNUM=DNUMBER(DEPARTMENT)) MGRSSN = SSN(EMPLOYEE))
질의 트리 질의 Q2에 대한 두 개의 질의트리 ∏ PNUMBER, DNUM,LNAME,ADDRESS,BDATE MGRSSN = SSN EMPLOYEE DNUM=DNUMBER DEPARTMENT σPLOCATION=‘Stafford’ PROJECT 질의 Q2에 대한 두 개의 질의트리
질의 그래프 질의 그래프 질의를 실행하기 위한 순서가 나타나지 않음 일반적으로 질의 트리를 선호 E D P Q2의 SQL 질의에 대한 질의 그래프 ‘Stafford’ [P.PNUMBER,P.DNUM] D.MGRSSN=E.SSN [E.LNAME,E.ADDRESS,E.BDATE] P.PLOCATION=‘Stafford’ P.DNUM=D.NUMBER
질의 트리의 경험적 최적화 서로 다른 관계 대수식 다수의 서로 다른 관계 대수식이 동등하므로 서로 다른 질의 트리들도 동등 질의 파서는 어떤 최적화도 수행하지 않으면서 SQL 질의에 대등하는 표준적인 초기 질의 트리를 생성 경험적 질의 최적화기 질의 트리를 효율적으로 실행할 수 있는 최종 질의 트리를 변환
Q2의 SQL 질의에 대한 초기 (규준) 질의 트리 질의 트리의 경험적 최적화 초기 질의 트리 ∏ PNUMBER, DNUM,LNAME,ADDRESS,BDATE σDNUM=DNUMBER AND MGRSSN=SSN AND PLOCATION=‘Stafford’ EMPLOYEE DEPARTMENT PROJECT X Q2의 SQL 질의에 대한 초기 (규준) 질의 트리
질의 트리의 경험적 최적화 SELECT LNAME 질의 Q FROM EMPLOYEE, WORKS_ON, PROJECT WHERE PNAME = ‘Aquarius’ AND PNUMBER = PNO AND ESSN = SSN AND BDATE > ‘1957-12-31’;
질의 트리의 경험적 최적화 SQL 질의 Q에 대한 초기 (규준) 질의트리 ∏ LNAME σPNAME=‘Aquarius’ AND PNUMBER=PNO AND ESSN=SSN AND BDATE>’1957-12-31’ PROJECT WORKS_ON X SQL 질의 Q에 대한 초기 (규준) 질의트리 EMPLOYEE
질의 트리의 경험적 최적화 실렉트 연산들을 질의트리의 아래로 이동 ∏ LNAME σPNUMBER=PNO X σESSN=SSN PROJECT WORKS_ON X 실렉트 연산들을 질의트리의 아래로 이동 EMPLOYEE σPNAME=‘Aquarius’ σESSN=SSN σBDATE>’1957-12-31’
질의 트리의 경험적 최적화 보다 제한적인 실렉트 연산을 먼저 적용 ∏ LNAME σESSN=SSN X σPNUMBER=PNO WORKS_ON X 보다 제한적인 실렉트 연산을 먼저 적용 EMPLOYEE σBDATE>’1957-12-31’ σESSN=SSN σPNAME=‘Aquarius’ PROJECT
질의 트리의 경험적 최적화 카티션 프로덕트와 실렉트를 조인 연산으로 대체 ∏ LNAME ESSN = SSN PNUMBER=PNO WORKS_ON 카티션 프로덕트와 실렉트를 조인 연산으로 대체 EMPLOYEE σBDATE>’1957-12-31’ σPNAME=‘Aquarius’ PROJECT ESSN = SSN
경험적 경험적 최적화 관계 대수 연산들을 위한 일반적인 변환 규칙 규칙 1. 연속적인 σ σc1 AND c2 AND...AND cn(R) ≡ σc1(σc2(...(σcn(R))...)) 규칙 2. σ의 교환법칙 σc1(σc2(R)) ≡ σc2(σc1(R)) 규칙 3. 연속적인 ∏ ∏List1(∏List2(...(∏Listn(R))...)) ≡ ∏List1(R) 규칙 4. σ와 ∏의 교환 ∏A1,A2,...,An(σc(R)) ≡ σc(∏A1,A2,...,An(R)) 규칙 5. (혹은 X)의 교환법칙 R cS ≡ S cR 규칙 6. σ와 (혹은 X)의 교환 σc(R S) ≡ (σc(R) S)
경험적 경험적 최적화 규칙 7. ∏와 (혹은 X)의 교환 ∏L(R cS) ≡ (∏A1,...,An(R)) c(∏B1,...,Bm(S)) 규칙 8. 집합연산의 교환법칙 ∪와 ∩사이에는 교환법칙이 성립 - 연산에는 교환법칙이 성립하지 않음 규칙 9. , X, ∪, ∩의 결합법칙 (R Θ S) Θ T ≡ R Θ (S Θ T) 규칙 10. σ와 집합연산의 교환 ∪, ∩, - 와 σ 는 교환 가능 규칙 11. ∏와 ∪의 교환 ∏L(R U S) ≡ (∏L(R)) U (∏L(S)) 규칙 12. 일련의 (σ, ×) 연산을 로 변환 σc(R X S ) ≡ (R c S)
경험적 경험적 최적화 경험적 대수 최적화 알고리즘의 개요 논리곱 조건을 가진 실렉트 연산을 개개의 실렉트 연산들의 연속으로 분리 (규칙 1 사용) 실렉트 연산을 질의트리의 가장 아래로 이동 (규칙 2, 4, 6, 10 사용) 가장 제한적인 실렉트 연산들을 가진 리프노드 릴레이션들이 가장 먼저 실행되게 재배치함 (규칙 5, 9 사용) 카티션 프로덕트 연산을 후속 실렉트 연산과 결합하여 조인연산으로 변환 프로젝트 연산의 애트리뷰트들의 리스트를 나눠서 가능한 한 트리의 아래로 이동 (규칙 3, 4, 7, 11 사용) 단일 알고리즘에 의해 독립적으로 실행될 수 있는 연산들의 그룹을 나타내는 서브트리들을 식별
선택률과 비용추정치 비용 기반 질의 최적화(cost-based query optimization) 질의 최적화기가 경험적 규칙들에만 전적으로 의존해서는 안됨 질의 최적화기는 서로 다른 실행 전략들의 사용에 따르는 질의의 실행 비용을 추정하고 비교하여 최저의 비용 추정치를 가지는 전략을 선택 보다 정교한 최적화는 컴파일된 질의에 적합하고, 부분적이고 시간이 덜 소모되는 최적화는 인터프리트된 질의에서 가장 잘 동작 질의 최적화에 사용되는 비용 함수들은 추정치이지 정확한 것은 아님 최적화 단계가 가장 효율적인 질의 실행 전략을 선택하지 못할 수도 있음
질의 실행 비용 구성요소 보조 기억장치의 접근 비용 저장 비용 계산 비용 메모리 사용 비용 통신 비용 디스크의 데이터 블록을 찾고, 읽고, 쓰는 비용 정렬, 해싱, 기본 인덱스, 보조 인덱스 등에 따라 다름 저장 비용 질의의 실행 전략에 따라 생성되는 중간 화일들의 저장 비용 계산 비용 질의 실행 단계에서 연산 수행 비용 레코드 탐색, 정렬, 조인을 위한 합병, 필드값 계산 등 메모리 사용 비용 질의를 실행하는 동안 필요한 메모리 버퍼의 갯수 통신 비용 질의와 질의 결과의 전송
의미적 질의 최적화 데이터베이스 스키마에 명시된 제약조건 사용한 질의 최적화 예제 SELECT E.LNAME, M.LNAME FROM EMPLOYEE E M WHERE E.SUPERSSN = M.SSN AND E.SALARY > M.SALARY 질의의 의미 : 상사보다 더 많은 봉급을 받는 사원의 이름 제약조건: 어떤 사원도 자신의 상사보다 더 많은 급여를 받을 수 없다. 결론 : 위 질의를 수행할 필요가 없다.