Download presentation
2
주요 내용 기본 용어 이진 트리(binary tree) 이진 탐색 트리(binary search tree)
트리 순회(tree traversal) 신장 트리(spanning tree)
 신장 트리(spanning tree)")
3
기본 용어 트리(tree) 비방향 그래프 G={V, E}에서 모든 정점의 쌍 (u,v)가 연결
되어 있고 순환(cycle)을 갖지 않을 때 G를 트리라고 한다.
을 갖지 않을 때 G를 트리라고 한다.")
4
예: G1과 G2는 트리가 아니고 G3와 G4는 트리이다.
6 1 6 3 5 3 5 G1 G2 2 4 2 4 6 1 6 3 5 3 5 G4 G3

5
비방향 그래프 G={V, E}의 모든 정점이 연결되어 있고 모든 정점의 쌍 (u, v) 사이에는 유일한 경로가 존재하면
<정리> 비방향 그래프 G={V, E}의 모든 정점이 연결되어 있고 모든 정점의 쌍 (u, v) 사이에는 유일한 경로가 존재하면 그래프 G는 트리이다. 뿌리 트리(rooted tree) 트리의 한 정점에서부터 시작하여 연결선들이 방향을 갖는 트리를 뿌리 트리라고 하며 이 정점을 뿌리(root)라고 한다. 2 4 6 2 4 2 3 5 4 5 1 1 6 2 5 3 6 1 4 6 1 3 5 G의 뿌리 트리 3 G
 사이에는 유일한 경로가 존재하면. 그래프 G는 트리이다. 뿌리 트리(rooted tree) 트리의 한 정점에서부터 시작하여 연결선들이 방향을 갖는. 트리를 뿌리 트리라고 하며 이 정점을 뿌리(root)라고 한다 G의 뿌리 트리. 3. G.")
6
부모(parent), 자식(child), 형제(sibling)
서로 인접한 정점들 중에서 뿌리에 가까운 위치에 있는 정점을 부모, 먼 위치에 있는 정점을 자식이라고 한다. 그리고 동일한 부모를 갖는 정점들은 형제(sibling)라고 한다. 잎(leaf) : 자식이 없는 정점 내부 정점(internal vertex) :자식을 갖는 모든 정점들 조상(ancestor): 루트로부터 그 정점에 이르는 경로 상에 존재하는 모든 정점들 자손(descendant): 그 정점을 조상으로 하는 모든 정점들 레벨(level) : 뿌리에서 시작하여 정점들이 연결되는 단계를 깊이(depth) 혹은 높이(height) :트리가 갖는 최대 레벨 수
라고 한다. 잎(leaf) : 자식이 없는 정점. 내부 정점(internal vertex) :자식을 갖는 모든 정점들. 조상(ancestor): 루트로부터 그 정점에 이르는 경로 상에. 존재하는 모든 정점들. 자손(descendant): 그 정점을 조상으로 하는 모든 정점들. 레벨(level) : 뿌리에서 시작하여 정점들이 연결되는 단계를. 깊이(depth) 혹은 높이(height) :트리가 갖는 최대 레벨 수.")
7
순서 트리(ordered tree) :각 정점의 자식들이 왼쪽에서
오른쪽으로 순서를 갖고 정렬이 되는 트리 n-트리(n-ary tree) : 자식이 최대 n개가 존재하는 트리 완전 n-트리(complete n-tree) 모든 부모의 자식들이 정확히 n개씩 존재하고 그 정점들이 중간에 비지 않고 순서대로 채워져 있는 트리 포화 n-트리(full n-tree) 마지막 레벨의 정점들이 모두 채워진 트리 이진 트리(binary tree) : n=2인 트리 완전 이진 트리(complete binary tree) 모든 부모 정점이 왼쪽 자식과 오른쪽 자식을 갖는 이진 트리
 : 자식이 최대 n개가 존재하는 트리. 완전 n-트리(complete n-tree) 모든 부모의 자식들이 정확히 n개씩 존재하고 그 정점들이. 중간에 비지 않고 순서대로 채워져 있는 트리. 포화 n-트리(full n-tree) 마지막 레벨의 정점들이 모두 채워진 트리. 이진 트리(binary tree) : n=2인 트리. 완전 이진 트리(complete binary tree) 모든 부모 정점이 왼쪽 자식과 오른쪽 자식을 갖는 이진 트리.")
8
예: 정점1과 (2, 3, 4), 정점 2와 (5,6), 5와 11, 11과 (16, 17, 18)은 부모와 자식의 관계
정점 8의 조상은 (1, 4)이며, 정점 17의 조상은 (1, 2, 5, 11) 정점2의 자손은 (5, 6, 11, 16, 17, 18) 1 레벨 1 레벨 2 2 3 4 레벨 3 5 7 8 9 10 6 11 12 13 14 15 레벨 4 레벨 5 16 17 18
이며, 정점 17의 조상은 (1, 2, 5, 11) 정점2의 자손은 (5, 6, 11, 16, 17, 18) 1. 레벨 1. 레벨 레벨 레벨 4. 레벨")
9
(a) 완전3-트리 (b) 이진 트리 (c) 완전 이진 트리
 완전3-트리 (b) 이진 트리 (c) 완전 이진 트리")
10
n개의 정점을 갖는 트리의 총 연결선의 수는 n-1개이다.
<정리> n개의 정점을 갖는 트리의 총 연결선의 수는 n-1개이다. 트리는 그래프와 달리 뿌리를 제외하고는 모든 정점들이 뿌리를 향하여 하나의 연결선을 갖는다. 만약 그렇지 않다면 하나 이상의 경로가 존재하게 된다. 따라서 뿌리 노드를 제외한 모든 정점 n-1개는 n-1 연결선을 갖는다. <정리> 포화 n-트리(full n-ary tree)가 k개의 내부 정점을 갖는다면 총 정점의 수는 nk+1이다. a a b c b c d d e f g 포화 3-트리 포화 이진 트리
가 k개의 내부 정점을 갖는다면. 총 정점의 수는 nk+1이다. a. a. b. c. b. c. d. d. e. f. g. 포화 3-트리. 포화 이진 트리.")
11
주요 내용 기본 용어 이진 트리(binary tree) 이진 탐색 트리(binary search tree)
트리 순회(tree traversal) 신장 트리(spanning tree)
 신장 트리(spanning tree)")
12
일반 트리를 이진 트리로 변환 일반적인 n-트리는 이진 트리로 변환하여 사용할 수 있다.
일반 트리의 정점을 u라고 하고 u의 자식이 v1, v2,..., vn라면 v1은 u의 왼쪽 자식으로 하고, v2는 v1의 오른쪽 자식으로 하고, v3는 v2의 오른쪽 자식으로 한다. 이와 같이 vi+1은 vi (i > 1)의 오른쪽 자식으로 하면 이진 트리가 구성된다.
의 오른쪽 자식으로 하면 이진 트리가 구성된다.")
13
1 2 1 3 5 6 7 2 4 4 3 8 10 5 6 7 8 9 10 11 12 9 11 일반 트리 12 변환된 이진 트리

14
이진 트리의 특성 <정리> 완전 이진 트리(complete binary tree)인 경우 트리의 높이가
h라면 총 정점의 수 N은 2h-1 ≤ N ≤ 2h-1 각 레벨에서 정점의 수는 1, 2, 22, ..., 2h-1이므로 높이가 h인 포화 이진 트리의 정점의 수는 다음과 같이 계산된다. h-1 = 2h-1 높이가 h인 완전 이진 트리의 갯수는 가장 적을 경우 높이가 h-1인 포화 이진 트리의 수 보다 1이 많다. 즉 ( h-2)+1 = 2h-1 따라서 높이가 h인 이진 트리의 정점의 수는 위와 같이 된다.
+1 = 2h-1. 따라서 높이가 h인 이진 트리의 정점의 수는 위와 같이 된다.")
15
예: 다음의 트리들은 모두 높이 4를 갖는 완전 이진 트리이다. (a)는 높이 4인 완전 이진 트리로서 가장 적은 수의 정점으로 구성된 예를 보여 주고 있다. 이때 총 정점의 수는 8이다. (b)는 포화 완전 트리로서 총 정점의 수는 15개이다. (a) (b)
는 포화 완전 트리로서 총 정점의 수는 15개이다. (a) (b)")
16
<정리> N개의 정점을 갖는 완전 이진 트리의 높이는 log2N+1이다. 앞의 정리의 식 양변을 log로 하면, h-1 ≤ log2N ≤ log(2h-1) 이다. log(2h-1) < log(2h) = h 이므로 h-1 ≤ log2N < h h ≤ log2N+1 < h+1 따라서 N개의 정점을 갖는 완전 이진 트리의 높이는 log2N+1 이 된다.
 < log(2h) = h 이므로. h-1 ≤ log2N < h. h ≤ log2N+1 < h+1. 따라서 N개의 정점을 갖는 완전 이진 트리의 높이는. log2N+1 이 된다.")
17
이진 트리의 표현 이중 연결 리스트(doubly linked list) 배열(array)
단순 연결 리스트(singly linked list)
")
18
이중 연결 리스트를 사용한 트리의 표현 start A B H C E I K D F G J L A H B C E I K D F

19
배열을 사용한 트리의 표현 1 2 3 4 5 6 7 8 9 10 11 12 13 2 3 4 5 7 10 A B C D E F G H I J K L 9 6 8 12 11 13 A B H C E I K D F G J L

20
단순 연결 리스트를 사용한 트리의 표현 A B C D E F G H I J K L 1 2 3 4 5 6 7 8 9 10 11
12 B H A C E B B B H F G C E I K D F G J L I K J L

21
주요 내용 기본 용어 이진 트리(binary tree) 이진 탐색 트리(binary search tree)
트리 순회(tree traversal) 신장 트리(spanning tree)
 신장 트리(spanning tree)")
22
순차 검색(sequential search)
리스트의 다음과 같은 키 값들이 존재한다고 하자. {10, 5, 13, 23, 3, 15, 4, 20, 32, 1} 이 리스트에서 키 값이 15인 데이터 요소를 찾기 위해서 이 리스트의 첫 번째 키 값부터 차례대로 비교하며 찾아 나가는 것을 순차 검색이라고 한다. 리스트에 N개의 데이터 요소가 존재하면 평균 비교 회수는 N/2이 된다.

23
이진 탐색(binary search) 만약 리스트의 키 값이 정렬되어 있다면 순차 검색 보다
빠른 시간 안에 검색을 할 수 있다. {1, 3, 4, 5, 10, 13, 15, 20, 23, 32} 먼저 찾고자 하는 키 값을 리스트의 중간에 위치한 값, 13과 비교한다. 만약 찾고자 하는 키 값이 13 보다 작으면 이 값은 13보다 왼쪽에 위치하고 있으며, 13보다 크다면 13의 오른쪽에 위치하고 있다. 따라서 다음 단계에서 13보다 왼쪽에 있는 값들, 혹은 오른쪽에 있는 값들을 갖고 같은 절차를 반복한다. 최대 비교 회수는 리스트의 수가 N이라면 log N이다.

24
else if(구간의 중간값 > 키값) 오른쪽 구간 선택 else 왼쪽 구간 선택
[일고리즘] 이진 탐색 while (리스트 구간의 크기 > 0) 구간의 중간값을 구한다. if(구간의 중간값 = 키값) 탐색 종료 else if(구간의 중간값 > 키값) 오른쪽 구간 선택 else 왼쪽 구간 선택 이러한 이진 검색을 하기 위해서는 먼저 리스트가 순서대로 정렬되어 있어야 한다. 따라서 탐색 전에 순서대로 정렬하기 위한 시간이 요구된다. 그런데 이진 검색을 하기 위해서 이진 탐색 트리를 사용하면 순서대로 정렬하는 것과 이진 탐색을 하는 것이 용이하게 구현될 수 있다.
 구간의 중간값을 구한다. if(구간의 중간값 = 키값) 탐색 종료. else if(구간의 중간값 > 키값) 오른쪽 구간 선택. else. 왼쪽 구간 선택. 이러한 이진 검색을 하기 위해서는 먼저 리스트가 순서대로 정렬되어. 있어야 한다. 따라서 탐색 전에 순서대로 정렬하기 위한 시간이 요구된다. 그런데 이진 검색을 하기 위해서 이진 탐색 트리를 사용하면 순서대로. 정렬하는 것과 이진 탐색을 하는 것이 용이하게 구현될 수 있다.")
25
이진 탐색 트리 이진 트리 G=(V,E)에서 잎(leaf)을 제외한 모든 정점 v와
v의 왼쪽 자식 vL, 오른쪽 자식 vR의 키 값이 다음의 관계식을 만족하면 이진 탐색 트리이다. key(vL) < key(v) < key(vR) 이 식의 부등호는 트리 내에 동일한 값을 갖는 정점들이 없는 경우에 해당한다. 만약 트리에 동일한 값을 갖는 정점들이 존재하면 그 정점들은 어느 것을 부모 정점 혹은 자식 정점에 놓더라도 상관이 없다.
 < key(v) < key(vR) 이 식의 부등호는 트리 내에 동일한 값을 갖는 정점들이 없는. 경우에 해당한다. 만약 트리에 동일한 값을 갖는 정점들이. 존재하면 그 정점들은 어느 것을 부모 정점 혹은 자식 정점에. 놓더라도 상관이 없다.")
26
예: 이진 탐색 트리 30 50 20 70 45 12 5 15 55 18 17

27
[알고리즘] 이진 탐색 트리 알고리즘 x: 찾으려는 키 값 v0: 이진 탐색 트리의 뿌리 NULL: 트리의 정점이 아닌 것을 나타냄 v ← v0 while (v ≠ NULL) if (x = key(v)) 탐색 종료 if (x < key(v)) v ← v의 왼쪽 자식 if (x > key(v)) v ← v의 오른쪽 자식
![[알고리즘] 이진 탐색 트리 알고리즘 x: 찾으려는 키 값. v0: 이진 탐색 트리의 뿌리. NULL: 트리의 정점이 아닌 것을 나타냄. v ← v0. while (v ≠ NULL)](http://slidesplayer.org/slide/11290959/61/images/27/%5B%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98%5D+%EC%9D%B4%EC%A7%84+%ED%83%90%EC%83%89+%ED%8A%B8%EB%A6%AC+%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98+x%3A+%EC%B0%BE%EC%9C%BC%EB%A0%A4%EB%8A%94+%ED%82%A4+%EA%B0%92.+v0%3A+%EC%9D%B4%EC%A7%84+%ED%83%90%EC%83%89+%ED%8A%B8%EB%A6%AC%EC%9D%98+%EB%BF%8C%EB%A6%AC.+NULL%3A+%ED%8A%B8%EB%A6%AC%EC%9D%98+%EC%A0%95%EC%A0%90%EC%9D%B4+%EC%95%84%EB%8B%8C+%EA%B2%83%EC%9D%84+%EB%82%98%ED%83%80%EB%83%84.+v+%E2%86%90+v0.+while+%28v+%E2%89%A0+NULL%29.jpg "if (x = key(v)) 탐색 종료. if (x < key(v)) v ← v의 왼쪽 자식. if (x > key(v)) v ← v의 오른쪽 자식.")
28
이진 탐색 트리를 만드는 절차 리스트에 {10, 5, 13, 23, 3, 15, 4, 20, 32, 1}의 순서로 입력될 때

29
10 10 13 5 13 5 23 23 3 3 4 15 15 10 10 13 13 5 5 23 23 3 3 32 4 15 4 15 20 20
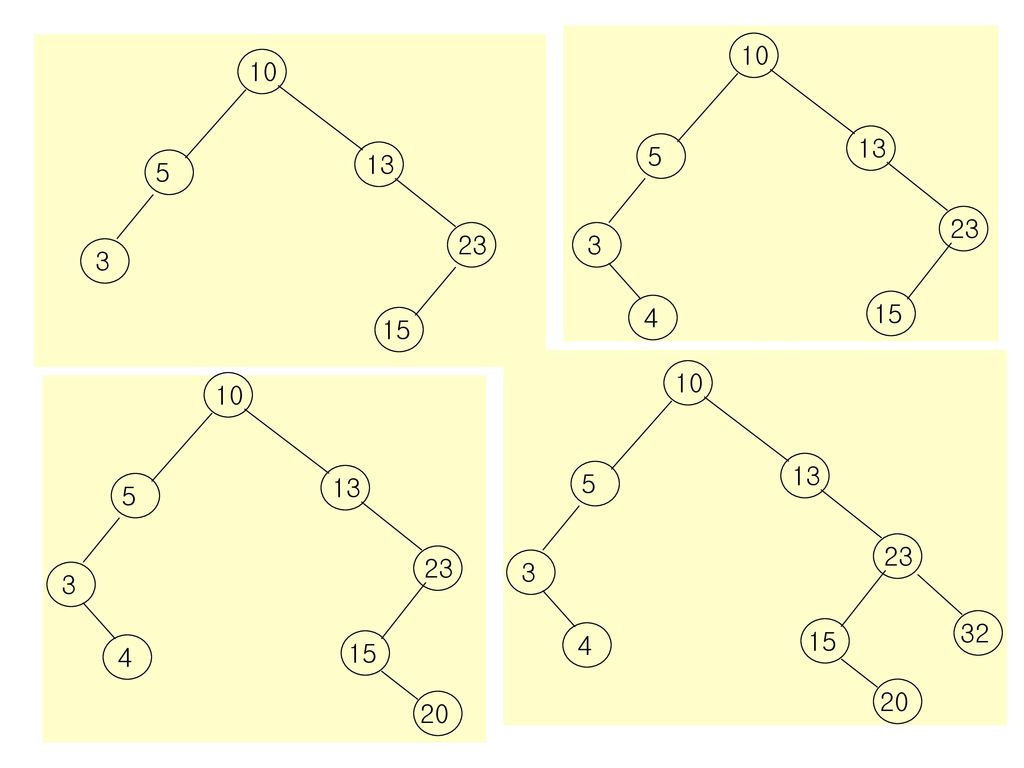
30
10 13 5 23 3 32 4 15 1 20
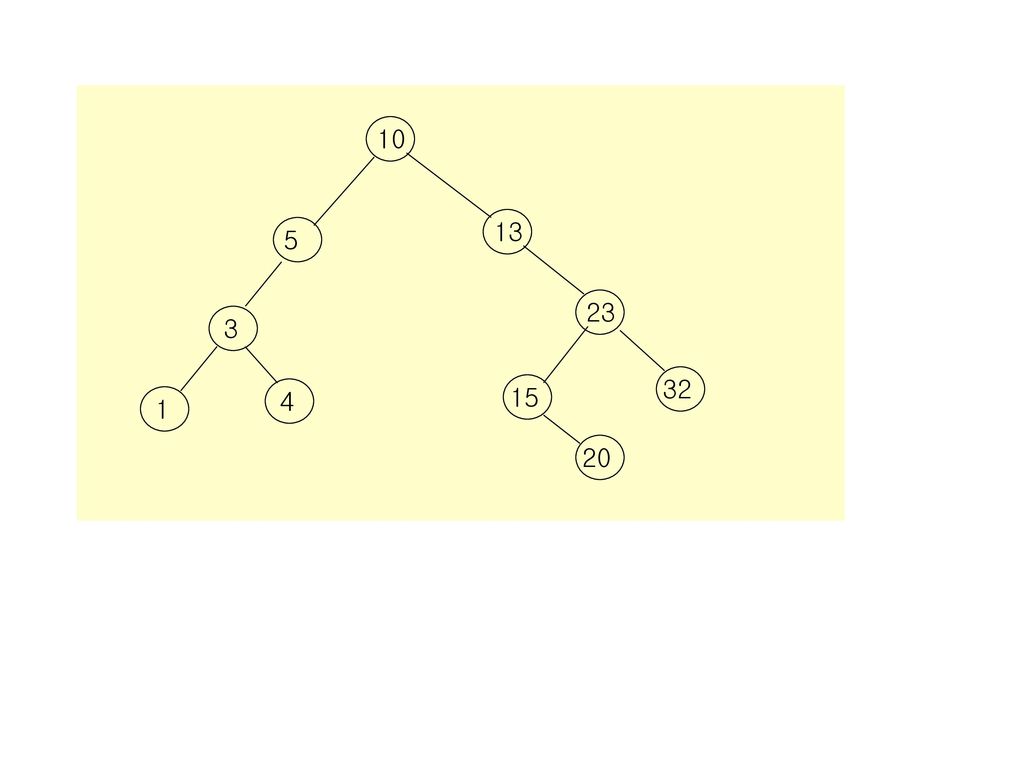
31
탐색을 할 때 비교하는 최대 회수 균형잡힌 이진 탐색 트리(balanced binary search tree)의 경우 완전 이진 트리에 접근하므로 근사적으로 log2N이다. 이진 탐색 트리를 구성할 때 비교하는 최대 회수 비교 회수는 이진 트리의 깊이와 같다. 따라서 리스트의 수가 N이라면 트리의 높이는 log2N 이므로 최대 비교 회수는 log2N 이다.

32
주요 내용 기본 용어 이진 트리(binary tree) 이진 탐색 트리(binary search tree)
트리 순회(tree traversal) 신장 트리(spanning tree)
 신장 트리(spanning tree)")
33
트리 순회 방법 전위 순회(preorder traverse) 중위 순회(inorder traverse)
후위 순회(postorder traverse) 층별 순회(levelorder traverse)
 층별 순회(levelorder traverse)")
34
단계2: 트리 T의 왼쪽 자식 rL을 뿌리로 하는 부분 트리 TL를 전위 순회한다.
단계3: 트리 T의 오른쪽 자식 rR을 뿌리로 하는 부분 트리 TR를 만약 T가 뿌리 r 외에 더 이상의 정점이 없으면 종료된다. r 단계1: r 방문 단계2: TL을 전위 순회 단계3: TR을 전위 순회 rL rR TL TR

35
전위 순회를 할 때 방문하는 노드의 순서 A B H C E I K D J L F G ABCDFEGHIJKL

36
preorder 알고리즘(1) 입력: r(이진 트리의 뿌리) 출력: 각 노드의 값 preorder(r){
if(r == null) return display r lchild = r의 왼쪽 자식 preorder(lchild) rchild = r의 오른쪽 자식 preorder(rchild) }
 return. display r. lchild = r의 왼쪽 자식. preorder(lchild) rchild = r의 오른쪽 자식. preorder(rchild) }")
37
preorder 알고리즘(2): stack을 이용
출력: 각 노드의 값 preorder_stack(r){ PUSH(S, r) while (queue ≠ empty) { x= POP(S) display x if(x has a right child) PUSH(S, x의 right child) if(x has a left child) PUSH(S, x의 left child) }
{ PUSH(S, r) while (queue ≠ empty) { x= POP(S) display x. if(x has a right child) PUSH(S, x의 right child) if(x has a left child) PUSH(S, x의 left child) }")
38
중위 순회(inorder traverse) 단계1: 트리 T의 왼쪽 자식 rL을 뿌리로 하는 부분 트리 TL을 중위 순회한다.
단계3: 트리 T의 오른쪽 자식 rR을 뿌리로 하는 부분 트리 TR을 만약 T가 뿌리 r 외에 더 이상의 정점이 없으면 종료된다. r 단계2: r 방문 단계1: TL을 중위 순회 단계3: TR을 중위 순회 rL rR TL TR

39
중위 순회를 할 때 방문하는 노드의 순서 A B H C E I K D J L F G DCFBEGAIJHLK

40
inorder 알고리즘 입력: r(이진 트리의 뿌리) 출력: 각 노드의 값 inorder(r){ if(r == null)
return lchild = r의 왼쪽 자식 inorder(lchild) display r rchild = r의 오른쪽 자식 inorder(rchild) }
 display r. rchild = r의 오른쪽 자식. inorder(rchild) }")
41
후위 순회(postorder traverse) 단계1: 트리 T의 왼쪽 자식 rL을 뿌리로 하는 부분 트리 TL를
후위 순회한다. 단계2: 트리 T의 오른쪽 자식 rR을 뿌리로 하는 부분 트리 TR를 단계3: 트리 T의 뿌리 r을 방문한다. 만약 T가 뿌리 r 외에 더 이상의 정점이 없으면 종료된다. r 단계3: r 방문 단계1: TL을 후위 순회 단계2: TR을 후위 순회 rL rR TL TR

42
후위 순회를 할 때 방문하는 노드의 순서 A B H C E I K D J L F G D F C G E B J I L K H A

43
postorder 알고리즘 입력: r(이진 트리의 뿌리) 출력: 각 노드의 값 postorder(r){
if(r == null) return lchild = r의 왼쪽 자식 postorder(lchild) rchild = r의 오른쪽 자식 postorder(rchild) display r }
 return. lchild = r의 왼쪽 자식. postorder(lchild) rchild = r의 오른쪽 자식. postorder(rchild) display r. }")
44
단계2: 트리 T의 level 2의 sibling 노드들을 방문한다.
층별 순회(level traverse) 단계1: 트리 T의 뿌리 r을 방문한다. 단계2: 트리 T의 level 2의 sibling 노드들을 방문한다. 단계3: level i(i=3,4,…)의 sibling 노드들을 방문한다. 층별 순회를 할 때 방문하는 노드의 순서 A B H C E I K D J L F G ABHCEIKDFGJL
 단계1: 트리 T의 뿌리 r을 방문한다. 단계2: 트리 T의 level 2의 sibling 노드들을 방문한다. 단계3: level i(i=3,4,…)의 sibling 노드들을 방문한다. 층별 순회를 할 때 방문하는 노드의 순서. A. B. H. C. E. I. K. D. J. L. F. G. ABHCEIKDFGJL.")
45
층별 순회의 알고리즘 queue를 이용 입력: r(이진 트리의 뿌리) 출력: 각 노드의 값 preorder_queue(r){
enque(Q, r) while (queue ≠ empty) { x= dequeue(Q) display x if(x has a left child) enqueue(Q, x의 left child) if(x has a left child) enqueue(Q, x의 right child) }
 while (queue ≠ empty) { x= dequeue(Q) display x. if(x has a left child) enqueue(Q, x의 left child) if(x has a left child) enqueue(Q, x의 right child) }")
46
수식 트리 수식은 연산자(operator)와 피연산자(operand)로 이루어져
있다. 이 연산자와 피연산자를 결합하여 수식을 표현한다. 수식을 표현하는 방법 전위 표기법(prefix notation) 중위 표기법(infix notation) 후위 표기법(postfix notation)
 중위 표기법(infix notation) 후위 표기법(postfix notation)")
47
예: 중위 표기법에 의한 수식 표현 (A + ((B+C) /D)) * (E-F) 전위 표기법에 의한 수식 표현 * + A / + B C D - E F 후위 표기법에 의한 수식 표현 A B C +D / + E F - * 전위 표기법과 후위 표기법은 연산자의 우선 순위를 위해서 괄호를 사용할 필요가 없다는 장점이 있다.

48
중위 표기법으로 나타내 수식을 이진 트리로 표현한 것을 수식 트리라고 한다. 수식 트리는 내부 노드는 모두 연산자로
구성되며 잎(leaf) 노드는 피연산자로 이루어진다. 예: (A + ((B+C) /D)) * (E-F) * + - A / E F + D B C
 노드는 피연산자로 이루어진다. 예: (A + ((B+C) /D)) * (E-F) * + - A. / E. F. + D. B. C.")
49
이 수식 트리를 전위 순회를 하면 전위 표기법에 의한 수식이 구해진다. * + A / + B C D - E F
이 수식 트리를 후위 순회를 하면 후위 표기법에 의한 수식이 A B C + D / + E F - * * + - A / E F + D B C

50
주요 내용 기본 용어 이진 트리(binary tree) 이진 탐색 트리(binary search tree)
트리 순회(tree traversal) 신장 트리(spanning tree)
 신장 트리(spanning tree)")
51
신장 트리 그래프 G={V,E}에서 V의 모든 정점을 포함하면서
순환(cycle)이 존재하지 않는 부분 그래프(subgraph)를 신장 트리라고 한다. 2 2 4 4 6 1 6 3 5 3 5
이 존재하지 않는 부분 그래프(subgraph)를. 신장 트리라고 한다")
52
신장 트리의 응용 예 c=2 c=1 c=1 c=2 c=1 c=1 c=1 c=1 c=1 c=1 c=2 c=1 c=1 c=2
LAN1 c=2 c=1 브리지2 브리지3 c=1 c=2 c=1 LAN2 브리지1 c=1 c=1 브리지4 c=1 LAN3 c=1 c=1 c=2 브리지5 브리지6 브리지7 c=1 c=1 c=2 LAN4

53
G의 신장 트리 LAN의 그래프 G L1 L1 B1 B2 B3 B1 B2 B3 L2 L2 B4 B4 L3 L3 B6 B7 B6

54
신장 트리에 의한 LAN의 구성 LAN 3 LAN 1 LAN 2 LAN 4 브리지1 브리지2 브리지3 브리지4 브리지5
브리지6 브리지7 LAN 2 LAN 4

55
주어진 그래프에서 그래프의 순회(traverse)를 사용하여 방문하는 정점을 모두 연결하면 신장 트리를 구할 수 있다.
그래프를 순회하는 방법은 깊이 우선 탐색과 넓이 우선 탐색이 있다. L1 L1 B1 B2 B3 B1 L2 L3 B4 B5 B6 B7 B4 L3 L2 L4 B6 B7 B5 B2 B3 L4 깊이 우선 탐색 순서 깊이 우선 탐색에 의한 신장트리

56
넓이 우선 탐색 순서 넓이 우선 탐색에 의한 신장트리 L1 L1 B1 B2 B3 B1 B2 B3 L2 L3 L2 B4 B5

57
최소 신장 트리 (minumun spaning tree)
가중 그래프(weighted graph)에서 가중치의 합을 최소로 하는 신장 트리를 최소 신장 트리라고 한다. 최소 신장 트리를 구하는 방법 Prim 알고리즘 Kruskal 알고리즘
에서 가중치의 합을 최소로. 하는 신장 트리를 최소 신장 트리라고 한다. 최소 신장 트리를 구하는 방법. Prim 알고리즘. Kruskal 알고리즘.")
58
[알고리즘] Prim의 최소 신장 트리 알고리즘
입력: 그래프 G={V,E} 출력: 최소 신장 트리 GT = {U, T} 초기값: T = , U = {v} (s ∈ U, 즉 G의 임의의 노드) while (U ≠ V) u ∈ U, v ∈ V-U의 두 정점을 연결하는 모든 연결선 중에서 가장 적은 비용의 (u,v)를 고른다. T = T {(u,v)} U = U {v}
![[알고리즘] Prim의 최소 신장 트리 알고리즘](http://slidesplayer.org/slide/11290959/61/images/58/%5B%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98%5D+Prim%EC%9D%98+%EC%B5%9C%EC%86%8C+%EC%8B%A0%EC%9E%A5+%ED%8A%B8%EB%A6%AC+%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98.jpg "입력: 그래프 G={V,E} 출력: 최소 신장 트리 GT = {U, T} 초기값: T = , U = {v} (s ∈ U, 즉 G의 임의의 노드) while (U ≠ V) u ∈ U, v ∈ V-U의 두 정점을 연결하는 모든 연결선 중에서. 가장 적은 비용의 (u,v)를 고른다. T = T {(u,v)} U = U {v}")
59
Prim 알고리즘을 이용한 예 1 2 A 1 B 9 4 8 12 G 5 10 F C 2 7 11 3 E D 6 1 1 A A
T={(A,B)} U = {A,B} T={(A,B),(A,F)} U = {A,B,F} 초기값 U={A}, T={}
} U = {A,B} T={(A,B),(A,F)} U = {A,B,F} 초기값 U={A}, T={}")
60
3 1 4 1 A B A B 4 4 G G 5 5 F C F C 2 E D E D T={(A,B),(A,F),(F,G)} U = {A,B,F,G} T={(A,B),(A,F),(F,G),(G,E)} U = {A,B,F,G,E} A 1 5 1 6 B A B 4 4 G G 5 5 F C F C 2 3 2 6 6 E D E D T={(A,B),(A,F),(F,G),(G,E),(E,D),(C,D)} U = {A,B,F,G,E,D,C} T={(A,B),(A,F),(F,G),(G,E),(E,D)} U = {A,B,F,G,E,D}
,(A,F),(F,G),(G,E)} U = {A,B,F,G,E} A B. A. B G. G F. C. F. C E. D. E. D. T={(A,B),(A,F),(F,G),(G,E),(E,D),(C,D)} U = {A,B,F,G,E,D,C} T={(A,B),(A,F),(F,G),(G,E),(E,D)} U = {A,B,F,G,E,D}")
61
[알고리즘] Kruskal의 최소 신장 트리 알고리즘
입력: 그래프 G={V,E} 출력: 최소 신장 트리 GT = {U, T} 초기값: T = E의 모든 연결선을 비용이 적은 순서대로 정렬한다. while (T의 연결선의 수 < V의 정점의 수-1) 순서대로 정렬된 E의 연결선 중에서 차례대로 (u,v)를 선택한다. 이때 (u,v)는 T에 속 한 연결선과 순환(cycle)을 만들지 않는 것이어야 한다.
![[알고리즘] Kruskal의 최소 신장 트리 알고리즘](http://slidesplayer.org/slide/11290959/61/images/61/%5B%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98%5D+Kruskal%EC%9D%98+%EC%B5%9C%EC%86%8C+%EC%8B%A0%EC%9E%A5+%ED%8A%B8%EB%A6%AC+%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98.jpg "입력: 그래프 G={V,E} 출력: 최소 신장 트리 GT = {U, T} 초기값: T = E의 모든 연결선을 비용이 적은 순서대로 정렬한다. while (T의 연결선의 수 < V의 정점의 수-1) 순서대로 정렬된 E의 연결선 중에서 차례대로 (u,v)를. 선택한다. 이때 (u,v)는 T에 속 한 연결선과 순환(cycle)을. 만들지 않는 것이어야 한다.")
62
Kruskal 알고리즘을 이용한 예 1 2 A 1 B 9 4 8 12 G 5 10 F C 2 7 11 3 E D 6 A 1 A
T={(A,B)} U = {A,B} 초기값 u={}, T={} T={(A,B),(G,E)} U = {A,B,G,E}
} U = {A,B} 초기값 u={}, T={} T={(A,B),(G,E)} U = {A,B,G,E}")
63
3 4 A 1 B A 1 B 4 G G F C F C 2 3 2 3 E D E D T={(A,B),(G,E),(C,D)} U = {A,B,G,E,C,D} T={(A,B),(G,E),(C,D),(A,F)} U = {A,B,G,E,C,D,F} 5 A 1 B A 1 6 B 4 4 G G F C F C 2 3 2 3 E D E D T={(A,B),(G,E),(C,D),(A,F),(F,G)} U = {A,B,G,E,C,D,F,G} T={(A,B),(G,E),(C,D),(A,F),(F,G),(E,D)} U = {A,B,G,E,C,D,F,G}
,(G,E),(C,D),(A,F)} U = {A,B,G,E,C,D,F} 5. A. 1. B. A B G. G. F. C. F. C E. D. E. D. T={(A,B),(G,E),(C,D),(A,F),(F,G)} U = {A,B,G,E,C,D,F,G} T={(A,B),(G,E),(C,D),(A,F),(F,G),(E,D)} U = {A,B,G,E,C,D,F,G}")






.>")



.>")

 2016. 9. 22 순천향대학교 하상호.>")
.>")
.>")





.>")
 (1) 출발 정점 v를 방문>")