Download presentation
1
한국어 정보의 전산 처리 강좌 소개 박진호 (서울대 국문과 교수)
")
2
이 강좌에서 익힐 것들 컴퓨터에서의 텍스트 처리의 기초 이론 학습
컴퓨터 메모리 구조, 문자코드, 정규표현 웹으로부터 데이터(텍스트, 이미지 등) 수집 (crawling) command line tools (wget, curl) + shell script, Ruby 등 전산화된 대량의 텍스트 데이터에서 원하는 정보를 추출하기 기존 소프트웨어 이용: 콘코던서, command line tools 코딩/프로그래밍(스크립트 작성): 프로그래밍 언어 Ruby 이용 추출된 정보를 더 유용한 형태로 가공, 변형하기 코드 변환, 형태소분석기 command line tools, R, Ruby 등 이용 추출된 정보에 대한 통계적 분석, 시각화 R 이용: base R, ggplot2, tidyverse 등의 패키지 이용 다변량 통계 분석: 다차원척도법(mds), 군집분석(clustering)
 수집 (crawling) command line tools (wget, curl) + shell script, Ruby 등. 전산화된 대량의 텍스트 데이터에서 원하는 정보를 추출하기. 기존 소프트웨어 이용: 콘코던서, command line tools. 코딩/프로그래밍(스크립트 작성): 프로그래밍 언어 Ruby 이용. 추출된 정보를 더 유용한 형태로 가공, 변형하기. 코드 변환, 형태소분석기. command line tools, R, Ruby 등 이용. 추출된 정보에 대한 통계적 분석, 시각화. R 이용: base R, ggplot2, tidyverse 등의 패키지 이용. 다변량 통계 분석: 다차원척도법(mds), 군집분석(clustering)")
3
인문학 전공자들도 이런 훈련이 필요한 이유 역사학, 철학, 문학, 언어학 등 인문학의 각 분야는 전통적으로 많은 양 의 텍스트를 읽고 이해하고, 어떤 문제의식을 바탕으로 이 텍스트 자료 로부터 어떤 정보를 추출하여 연구를 해 왔음. 대량의 인문학 텍스트 자료가 전산화되고 컴퓨터 기술이 발전함에 따 라, 일일이 꼼꼼히 읽지 않은 대량의 자료로부터 컴퓨터를 이용하여 원 하는 정보를 추출하여 연구에 이용할 수 있게 됨. 비교적 소량의 자료를 꼼꼼히 읽는 식으로는 얻을 수 없는 정보, 통찰 력, 자료상의 패턴을, 이러한 신기술로 얻고 알아낼 수도 있음. 데이터과학, 빅데이터, 네트워크이론, 기계학습, 인공지능 등의 기술이 발달함에 따라 이를 인문학 연구에 이용할 수 있는 전망도 생김. 기업에서도 이런 훈련이 된 사람에 대한 수요가 늘고 있기 때문에, 연 구자가 되기보다는 기업에 취업하려는 학생들에게도 유용함.

4
사례 1: 문자열 검색 현대 한국어에서 부사 ‘비록‘이 나타나면 그 절 끝의 연결어미로 ‘- 어도‘, ‘-더라도’, ‘-을지라도‘, ‘-은들’ 등이 나타남. 중세 한국어에서서 부사 ‘비록‘과 호응하는 연결어미에는 어떤 것 들이 있었을까? 정규표현(regular expression)을 지원하는 콘코던스를 이용하여 해 당 용례를 쉽게 추출할 수 있음. EmEditor, Antconc, Uniconc 등 ‘비록’으로 시작하고 ‘도‘로 끝나는 문자열을 검색하기 위한 정규표 현: 비록[^\n]+?도
을 지원하는 콘코던스를 이용하여 해 당 용례를 쉽게 추출할 수 있음. EmEditor, Antconc, Uniconc 등. ‘비록’으로 시작하고 ‘도‘로 끝나는 문자열을 검색하기 위한 정규표 현: 비록[^\n]+ 도.")
6
사례 2: 접미사 ‘-스럽-’ 연구 접미사 ‘-스럽-’에 대해 논문을 쓰려고 할 때, ‘-스럽-’을 포함한 단어 목록 을 사전에서 추출하고 말뭉치에서 빈도를 추출할 수 있음. 표준국어대사전에서 목록 추출: 961개 $ <sdic/sdic_u8.txt pcregrep "#2[^#]*스럽" | gawk 'BEGIN{FS="#"} {print substr($2,2)}‘ 고려대 한국어대사전에서 목록 추출: 864개 $ <korea_dic.txt pcregrep "^<lem>.*스럽“ | gawk ‘BEGIN{FS=“>”} {print $2}’ 고려대 한국어대사전은 Daum에서 서비스하는 것을 web crawling으로 수집한 것. 말뭉치에서 ‘스럽‘ 앞에 오는 말의 빈도를 추출할 수 있음. $ <경향2008년.txt tr " " "\n" | pcregrep "스럽|스런|스러우|스러운|스러울|스러움 " | gawk 'BEGIN{FS="스"}{print $1}' | sort | uniq -c | sort -gr 신문 말뭉치는 한국언론재단에서 서비스하는 것을 web crawling으로 수집한 것
}‘ 고려대 한국어대사전에서 목록 추출: 864개. $ <korea_dic.txt pcregrep ^<lem>.*스럽 | gawk ‘BEGIN{FS= > } {print $2}’ 고려대 한국어대사전은 Daum에서 서비스하는 것을 web crawling으로 수집한 것. 말뭉치에서 ‘스럽‘ 앞에 오는 말의 빈도를 추출할 수 있음. $ <경향2008년.txt tr \n | pcregrep 스럽|스런|스러우|스러운|스러울|스러움 | gawk BEGIN{FS= 스 }{print $1} | sort | uniq -c | sort -gr. 신문 말뭉치는 한국언론재단에서 서비스하는 것을 web crawling으로 수집한 것.")
7
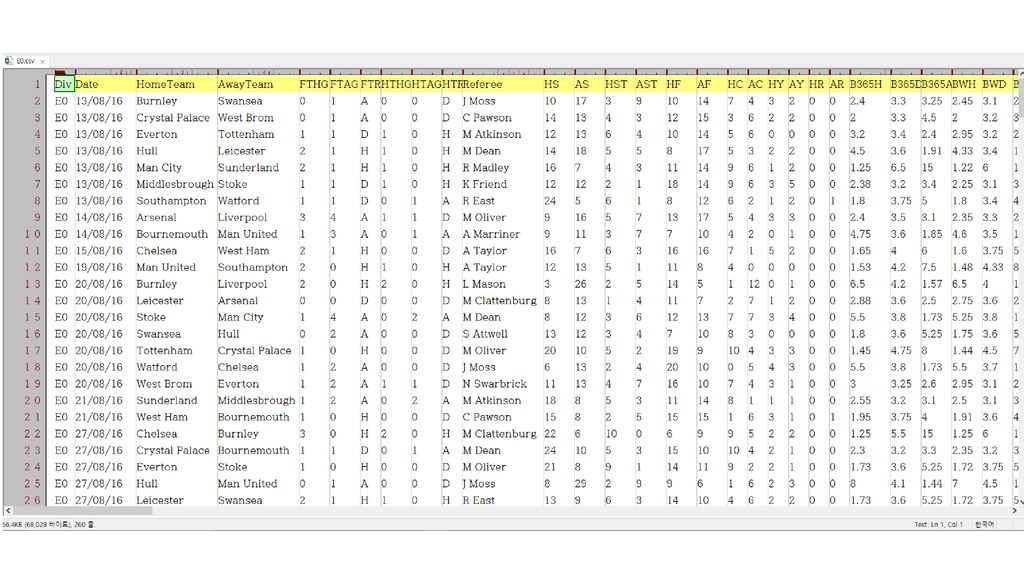
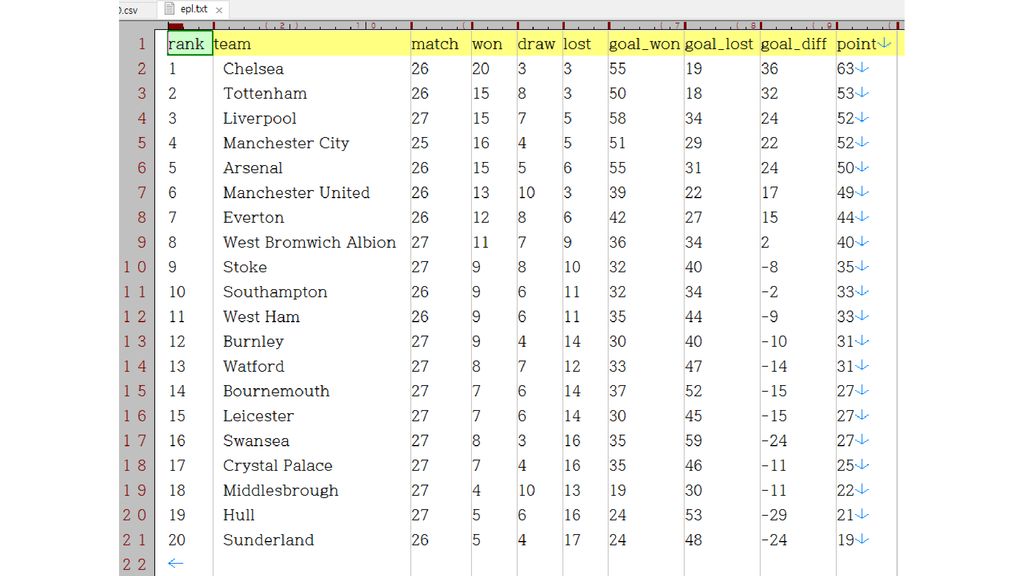
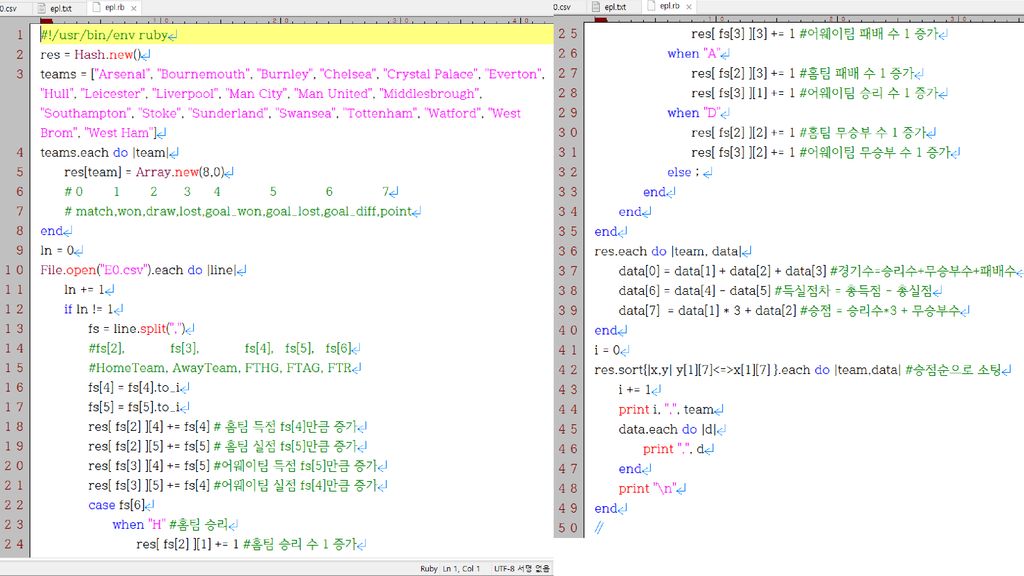
사례 3: 스포츠 경기 전적 통계 잉글랜드 프리미어리그(EPL) 홈페이지에서 각 시즌의 모든 경기 의 전적 데이터를 제공하고 있음. 여러분이 영국축구협회 직원인데, 경기가 있었던 날마다 위의 데이터는 다른 직원이 입력하고 여러분은 이 데이터를 바탕으로 업데이트된 종합 전적표를 만 들어야 한다고 치자. 프로그래밍 언어 Ruby로 간단한 스크립트를 짜서 실행하면 됨.

11
사례 4: 시험 성적 처리 여러분이 고등학교 교사이고, 어느 반의 담임을 맡았는데 국어, 영어, 수학 3 과목의 시험이 있었고
3개 과목 담당 선생님으로부터 각각 성적표를 받았다고 치자. 여러분은 담임으로서 이 모든 과목의 성적표를 하나로 합쳐서 학생별 총점, 평균, 석차 과목별 평균, 표준편차 등의 통계를 내야 한다. 특정 과목과 과목 사이에 특별한 상관관계가 있는지도 알아보고 싶다. 모든 과목 성적표를 하나로 합치는 일: command line tool인 join이나 csvjoin으로 할 수도 있고, R에서 할 수도 있음. 기타 모든 통계는 R에서 처리할 수 있음. 엑셀을 이용할 수도 있으나, 데이터 양이 많을 때는 비효율적임.

12
사례 4: 시험 성적 처리 우선 국어 성적표와 영어 성적표를 통합 국어-영어 성적표와 수학 성적표를 통합
$ csvjoin -c name kor.csv eng.csv >kor_eng.csv 국어-영어 성적표와 수학 성적표를 통합 $ csvjoin -c name kor_eng.csv math.csv >kor_eng_math.csv command line tools인 gawk를 이용한 학생별 총점, 평균 계산 $ <kor_eng_math.csv gawk 'BEGIN{FS=",";OFS=","}{sum=$2+$3+$4; avg=sum/3; print $0, sum, avg}' >kor_eng_math_sum_avg.csv gawk를 이용한 과목별 총점, 평균 계산 $ <kor_eng_math.csv gawk 'BEGIN{FS=",";OFS=","}{k_sum+=$2; e_sum+=$3; m_sum+=$4} END{ n=NR-1; print k_sum, e_sum, m_sum; print k_sum/n, e_sum/n, m_sum/n}' R과 Rio를 이용한 과목별 총점, 평균, 표준편차 등 계산 총점 $ <kor.csv Rio -e 'sum(df$kor)‘ (영어, 수학도 마찬가지) 평균 $ <kor.csv Rio -e 'mean(df$kor)‘ 표준편차 $ <kor.csv Rio -e 'sd(df$kor)‘ 기초 통계 요약 $ <kor.csv Rio -e 'summary(df$kor)'
‘ (영어, 수학도 마찬가지) 평균 $ <kor.csv Rio -e mean(df$kor)‘ 표준편차 $ <kor.csv Rio -e sd(df$kor)‘ 기초 통계 요약 $ <kor.csv Rio -e summary(df$kor)")
13
사례 4: 시험 성적 통계 처리 및 시각화 과목간 상관관계: cor(score$kor, score$math) (R console에서의 명령) 또는 with(score, cor(kor,math)) $ <kor_eng_math.csv csvcut –c kor,math | Rio –f cor (command line 명령) 국어-수학: 국어-영어: 영어-수학 0.582 boxplot 그리기: boxplot(score$kor, score$eng, score$math) 또는 with(score, boxplot(kor,eng,math)) scatterplot 그리기: ggplot(score, aes(kor,math)) + geom_point()
 국어-수학: 국어-영어: 영어-수학 boxplot 그리기: boxplot(score$kor, score$eng, score$math) 또는 with(score, boxplot(kor,eng,math)) scatterplot 그리기: ggplot(score, aes(kor,math)) + geom_point()")
14
사례 5: wordcloud 분석 일정한 말뭉치에서 각 단어/형태의 빈도를 추출한 뒤
R의 wordcloud 패키지를 이용하여 빈도에 따라 단어/형태의 크기를 크 게 보여주는 시각화를 할 수 있음. 경향신문 2000년 말뭉치를 형태소분석기로 분석한 뒤 울산대에서 개발한 Utagger 사용 각 형태의 빈도 추출 $ <경향2000년.txt.tag tr " " "\n" | tr "+" "\n" | sort | uniq -c >경향 2000.txt.tag.freq “빈도 형태” 포맷의 파일을 “형태,빈도” 포맷으로 변형 $ <경향2000.txt.tag.freq gawk 'BEGIN{FS="/"}{print $1}' | gawk 'BEGIN{FS="__"}{print $1}' | gawk 'BEGIN{FS=" ";OFS=","}{print $2,$1}' >경향 2000.txt.tag.freq.csv wordcloud(words=c$form, freq=c$freq, min.freq=1000) 1000회 이상 출현한 단어들의 wordcloud 표시 wordcloud2(data=c) : 컬러, html5 포맷(interactive)
 1000회 이상 출현한 단어들의 wordcloud 표시. wordcloud2(data=c) : 컬러, html5 포맷(interactive)")
16
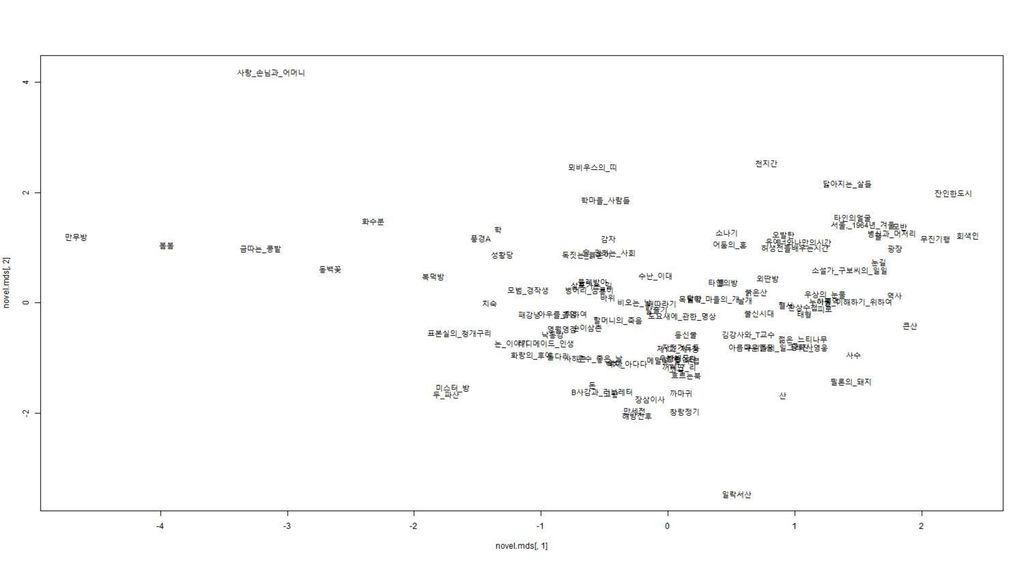
사례 6: 계량적 문체 분석 작가들의 문체에 대해 전통적으로 인상적인 2분법적 분류가 흔 히 행해져 왔음.
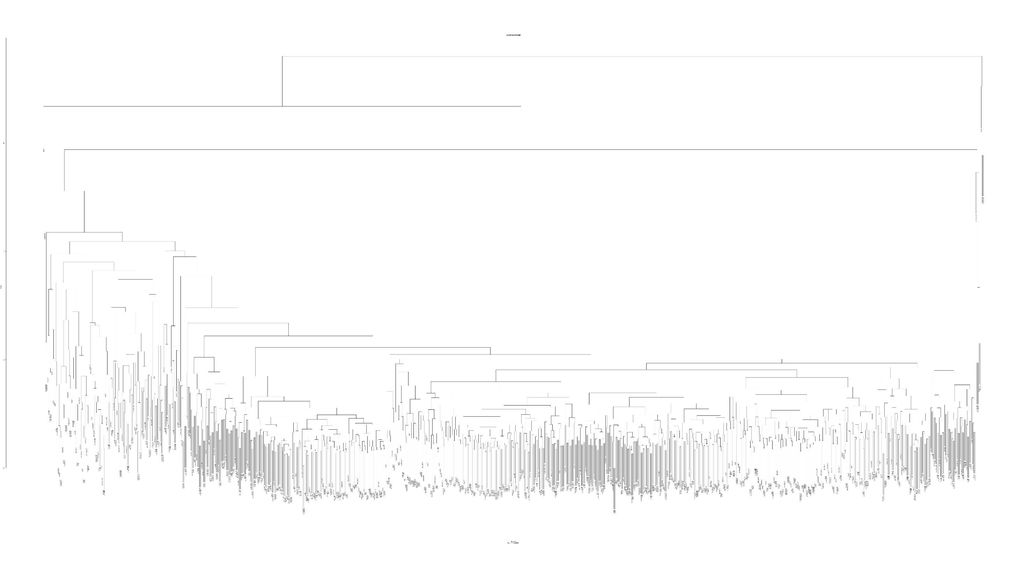
간결체 대 만연체, 강건체 대 우유체, 서사적 문체 대 묘사적 문체 등 문체 특성을 계량적으로 측정하여 문체 연구를 객관화할 필요 가 있음. 누구의 문제와 누구의 문체가 더 가까운지(비슷한지)를 측정하 는 것도 객관적 지표가 필요함. 통계 기법(주로 다변량 통계 기법)을 이용하면 기존 연구에서 엄두를 내지 못했던 것도 탐색할 수 있음. 106개의 한국근현대소설에 대해 다차원척도법(mds), 군집분석 (clustering) 등을 해 본 결과: 다음 페이지.
를 측정하 는 것도 객관적 지표가 필요함. 통계 기법(주로 다변량 통계 기법)을 이용하면 기존 연구에서 엄두를 내지 못했던 것도 탐색할 수 있음. 106개의 한국근현대소설에 대해 다차원척도법(mds), 군집분석 (clustering) 등을 해 본 결과: 다음 페이지.")
19
사례 7: 성리학의 키워드에 따른 문집 분류 사상사 연구자들이 성리학에서 중요시하는 30여개의 키워드를 대상 으로 조선시대 학자들이 이 키워드를 어떻게 사용했는지 연구해 왔음. "經權", "恭敬", "鬼神", "禮樂", "佛老", "義利", "一貫", "中庸", "中和", "忠恕", " 忠信", "太極", "通書", "皇極", "敬", "德", "道", "禮", "理", "命", "性", "誠", "信", " 心", "意", "義", "仁", "才", "情", "志", "智" 수백여개의 문집 텍스트(역사정보통합시스템에서 crawling한 것)에서 이들 키워드의 사용 빈도를 조사하여 다변량 통계 분석을 해 보았음. 이 연구나 문체분석에서 분류를 위한 새로운 지표를 더 개발하고 통계적 분류 결과가 질적 분석 결과나 연구자의 직관과 부합하는지 검증할 필요가 있음.
에서 이들 키워드의 사용 빈도를 조사하여. 다변량 통계 분석을 해 보았음. 이 연구나 문체분석에서 분류를 위한 새로운 지표를 더 개발하고. 통계적 분류 결과가 질적 분석 결과나 연구자의 직관과 부합하는지 검증할 필요가 있음.")
23
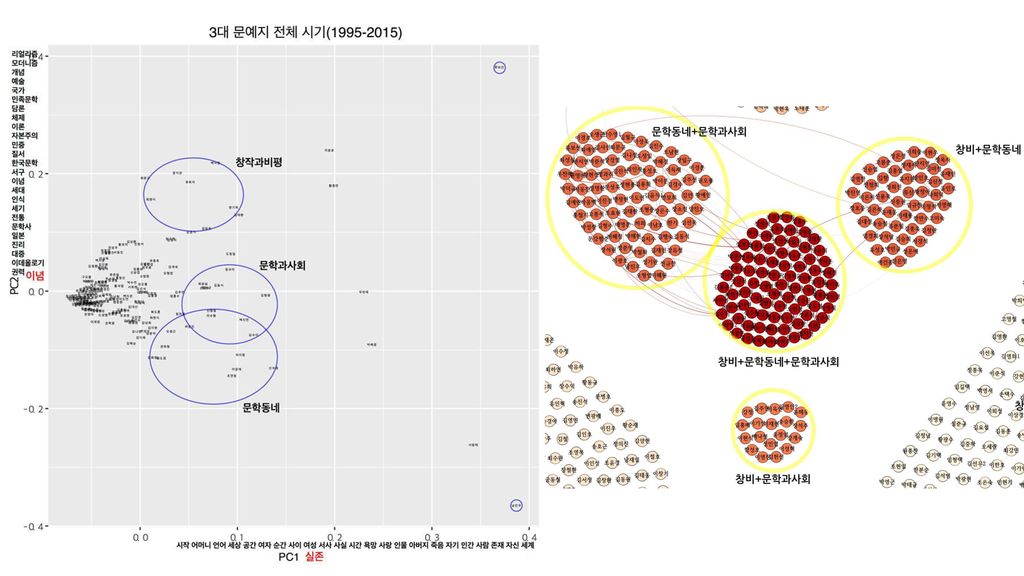
통계 기법을 이용한 기타 연구 사례 영어 수여동사를 3형식으로 쓸지 4형식으로 쓸지에 영향을 미치는 요 인에 대한 Log-linear model 분석 (스탠포드대 Bresnan, 이대 최혜원) 종속변수는 2분 변수, 독립변수는 여럿임(연속형 변수, 범주형 변수 가능) 독립변수: R과 T의 한정성, 유정성, 길이(음절수) 등 단형 부정문을 쓸지 장형 부정문을 쓸지에 영향을 미치는 요인에 대 한 Log-linear model 분석 (고려대 강범모) 독립변수: 동사/형용사, 고유어/한자어, 본용언 길이(음절수) 등 여러 언어적 변수를 바탕으로 한 텍스트 타입 분류 Biber, 숭실대 김용진, 고려대 강범모/김흥규/허명회 인자분석(또는 요인분석, factor analysis) 이용 문예지별 비평가들의 문체 분석 (카이스트 대학원생 김병준) 주성분분석(pca) 이용
 독립변수: R과 T의 한정성, 유정성, 길이(음절수) 등. 단형 부정문을 쓸지 장형 부정문을 쓸지에 영향을 미치는 요인에 대 한 Log-linear model 분석 (고려대 강범모) 독립변수: 동사/형용사, 고유어/한자어, 본용언 길이(음절수) 등. 여러 언어적 변수를 바탕으로 한 텍스트 타입 분류. Biber, 숭실대 김용진, 고려대 강범모/김흥규/허명회. 인자분석(또는 요인분석, factor analysis) 이용. 문예지별 비평가들의 문체 분석 (카이스트 대학원생 김병준) 주성분분석(pca) 이용.")
25
이 강좌의 강조점 1: command line tools
윈도우用 GUI를 가진 프로그램도 일부 사용하기는 하지만 콘코던서, 형태소분석기, 엑셀 등 command line tool에 초점을 맞춤. command line tool의 장점 각각의 tool은 한 가지 일을 잘 함. (Unix 철학을 반영) 대개 free이고 또한 open source임. 70년대 이후 오래도록 쓰이면서 유용성이 검증되었음. 복잡한 과제를 수행하고자 할 때에는, pipe로 여러 tool을 연결해서 쓰면 됨. 자기 스스로 만든 스크립트(shell 스크립트, ruby 스크립트 등)와도 연결해서 쓸 수 있음. 매우 많은 수의 파일을 일괄 처리할 때 유용함. (batch나 shell script 이용) 초보자는 대개 GUI를 선호하나, 컴퓨터를 다루는 수준이 높아질수록 command line tool을 선호하는 경향이 있음.
 대개 free이고 또한 open source임. 70년대 이후 오래도록 쓰이면서 유용성이 검증되었음. 복잡한 과제를 수행하고자 할 때에는, pipe로 여러 tool을 연결해서 쓰면 됨. 자기 스스로 만든 스크립트(shell 스크립트, ruby 스크립트 등)와도 연결해서 쓸 수 있음. 매우 많은 수의 파일을 일괄 처리할 때 유용함. (batch나 shell script 이용) 초보자는 대개 GUI를 선호하나, 컴퓨터를 다루는 수준이 높아질수록 command line tool을 선호하는 경향이 있음.")
26
이 강좌의 강조점 2: 코딩하여 스스로 만들기 남이 만들어 놓은 tool이라도 사용법을 잘 익혀서 유용하게 잘 쓰면 좋기는 하나 자신의 필요/요구에 딱 들어맞지 않을 때가 많음. 남이 만든 tool들을 여러 개 연결해서 당면 과제를 수행할 수 있기는 하나 처리 속도가 너무 느릴 때가 있음. 자기 필요에 딱 맞게 당면 과제를 신속히 수행할 수 있는 프로그램을 스스로 만들 수 있으면 매우 유용함. 프로그래밍 언어를 배우는 것은 그리 어렵지 않음. 프로그래밍 언어의 다양화, 진화에 따라 low level의 궂은 일(하드웨어, 메모 리 등의 리소스 제어)은 컴퓨터/언어가 알아서 처리하고, 프로그래머는 high level의 과제에 집중할 수 있게 되었음. 직관적이고, 자연언어에 상당히 가까운 프로그래밍 언어들이 속속 출현
은 컴퓨터/언어가 알아서 처리하고, 프로그래머는 high level의 과제에 집중할 수 있게 되었음. 직관적이고, 자연언어에 상당히 가까운 프로그래밍 언어들이 속속 출현.")
27
이 강좌의 강조점 3: Ruby 배우기 쉽고 널리 쓰이는 스크립트 언어로 Python과 Ruby가 있음.
Ruby가 더 배우기 쉽고 아름답기 때문에 Ruby를 선택함. Python Ruby Python > Ruby 사용자 폭이 넓음. 다양한 라이브러리가 나와 있음. 스크립트 언어치고 속도가 빠른 편임. 수학, 과학 관련 라이브러리가 강점. 최근 data science에서 R과 더불어 각광을 받고 있음. 사용자 폭이 상대적으로 좁음. 라이브러리가 상대적으로 적음. 속도가 상대적으로 느림. 수학, 과학 관련 라이브러리가 단점. data science에서 상대적으로 덜 쓰임. Ruby > Python 상대적으로 자연언어에서 멂. Syntax의 일관성이 떨어짐. Object-oriented한 성질에서 벗어날 때가 있음. 직관적이고 자연언어에 매우 가까움. Syntax가 매우 일관적임. 철저하게 object-oriented함,. 웹 관련 라이브러리가 강점: Ruby-on-Rails

28
이 강좌의 강조점 4: 통계 분석 사회과학은 일찍부터 통계가 널리 쓰여 온 데 반해
인문학에서는 통계가 상대적으로 덜 중요시되어 왔음. 인문학도들에게 통계를 체계적으로 교육하고 훈련시키는 시스템이 제대로 안 되어 있음. 이에 따라 인문학자들의 연구에서 통계에 대한 무지로 인한 어처구니 없는 오류가 자주 발생함. 사례 1: 김영랑의 시에서 공명음(ㅁ,ㄴ,ㅇ,ㄹ)의 빈도와 비율을 세어 보았더니 매우 높게 나왔다. 결론: 김영랑은 공명음을 즐겨 쓴다. 사례 2: A의 작품의 평균 문장 길이는 10.4어절, B의 작품의 평균 문장 길이는 11.0어절로 나타났음. 결론: A보다 B가 만연체 문장을 쓴다. 통계는 그리 어렵지 않음. 수학적 기반까지 확고하게 다지려면 어려울 수 있으나 기본 개념을 이해하고 다양한 기법을 어떤 때에 쓰면 좋은지 잘 알아 두는 정 도는 인문학도들도 쉽게 할 수 있음.
의 빈도와 비율을 세어 보았더니 매우 높게 나왔다. 결론: 김영랑은 공명음을 즐겨 쓴다. 사례 2: A의 작품의 평균 문장 길이는 10.4어절, B의 작품의 평균 문장 길이는 11.0어절로 나타났음. 결론: A보다 B가 만연체 문장을 쓴다. 통계는 그리 어렵지 않음. 수학적 기반까지 확고하게 다지려면 어려울 수 있으나. 기본 개념을 이해하고 다양한 기법을 어떤 때에 쓰면 좋은지 잘 알아 두는 정 도는 인문학도들도 쉽게 할 수 있음.")
29
수강생 유의사항 매 시간 학습한 내용을 반드시 복습해야 함.
수업시간에 다룬 데이터 외에 자기 스스로 데이터를 만들거나 웹 등에서 입수하여, 학습한 분석 방법을 새 데이터에 적용해 보 는 연습을 스스로 많이 해야 함. (복습/연습한 것을 숙제로 제출) 머리로 아는 것과 실제로 타이핑해 가며 실습하는 것은 엄청난 차이가 있음. (머리로만 아는 것은 별로 쓸모가 없음) 동일한 task를 여러 방법으로 해결해 보는 연습 필요. 학생 스스로 다양한 task를 생각해 내어 스스로 해결을 시도해 보고, 잘 안 되면 웹 등에서 검색을 통해 해결하고, 그래도 잘 안 되면 교수자에게 요청할 것.
 머리로 아는 것과 실제로 타이핑해 가며 실습하는 것은 엄청난 차이가 있음. (머리로만 아는 것은 별로 쓸모가 없음) 동일한 task를 여러 방법으로 해결해 보는 연습 필요. 학생 스스로 다양한 task를 생각해 내어 스스로 해결을 시도해 보고, 잘 안 되면 웹 등에서 검색을 통해 해결하고, 그래도 잘 안 되면 교수자에게 요청할 것.")







 생활신조 : 인생은 한방 ! 로또나 사자 이상형 : 청순 가련한 모태미녀 특이사항 : 걸그룹 노래에 환장함 식스팩을 갖기엔 슬픈 몸을 타고 남.>")

















