Download presentation
1
제2장 배열과구조

2
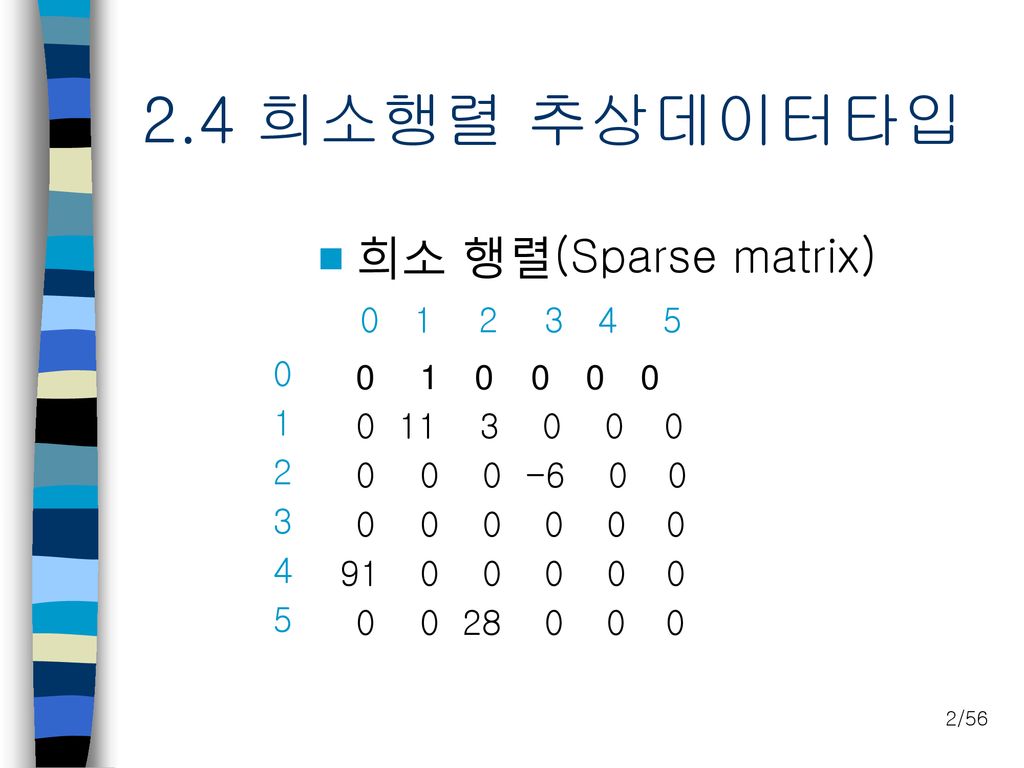
2.4 희소행렬 추상데이터타입 희소 행렬(Sparse matrix) 0 1 0 0 0 0 0 1 2 3 4 5
0 1 0 0 0 0 0 11 3 0 0 0 0 0 0 0 0 0 0 0 0 0 91 0 0 0 0 0 0 0 0 0 1 2 3 4 5
3
2.4 희소행렬 추상데이터타입 • m × n matrix A ≡ A[MAX_ROWS][MAX_COLS]
# of non-zero elements << small # of total elements
![2.4 희소행렬 추상데이터타입 • m × n matrix A ≡ A[MAX_ROWS][MAX_COLS]](http://slidesplayer.org/slide/14110307/86/images/3/2.4+%ED%9D%AC%EC%86%8C%ED%96%89%EB%A0%AC+%EC%B6%94%EC%83%81%EB%8D%B0%EC%9D%B4%ED%84%B0%ED%83%80%EC%9E%85+%E2%80%A2+m+%C3%97+n+matrix+A+%E2%89%A1+A%5BMAX_ROWS%5D%5BMAX_COLS%5D.jpg "# of non-zero elements << small. # of total elements")
4
2.4 희소행렬 추상데이터타입 Structure Sparse_Matrix
Objects : 3원소쌍 <행,열,값>의 집합이다. 여기서, 행과 열은 정수이고 이 조합은 유일하며, 값은 item 집합의 한 원소이다. Functions : 모든 a,b∈Sparse_Matrix, x∈item, i , j, max_col, max_row ∈index에 대해 Sparse_Matrix Create(max_row, max_col) ::= return max_items 까지 저장할 수 있는 Sparse_matrix, 여기서 최대 행의 수는 max_row이고 최대 열의 수는 max_col이라 할 때 max_items=max_row*max_col이다. Sparse_Matrix Transpose(a) ::= return 모든 3원소쌍의 행과 열의 값을 교환하여 얻은 행렬
 ::= return max_items. 까지 저장할 수 있는 Sparse_matrix, 여기서 최대 행의. 수는 max_row이고 최대 열의 수는 max_col이라 할 때. max_items=max_row*max_col이다. Sparse_Matrix Transpose(a) ::= return 모든 3원소쌍의 행과 열의. 값을 교환하여 얻은 행렬.")
5
2.4 희소행렬 추상데이터타입 Sparse_Matrix Add(a,b) ::= if a와 b의 차원이 같으면
return 대응항들, 즉 똑같은 행과 열의 값을 가진 항 들을 더해서 만들어진 행렬 else return 오류 Sparse_Matrix Multiply(a,b) ::= if a의 열의 수와 b의 행의 수가 같으면 return 다음 공식에 따라 a와 b를 곱해서 생성 된 행렬 d:d[i][j]=(a[i][j] *b[i][j]), 여기서 d[i][j]는 (i,j)번째 요소이다 else return 오류 end Sparse_Matrix
 ::= if a의 열의 수와 b의 행의 수가. 같으면 return 다음 공식에 따라 a와 b를 곱해서 생성. 된 행렬 d:d[i][j]=(a[i][j] *b[i][j]), 여기서. d[i][j]는 (i,j)번째 요소이다. else return 오류. end Sparse_Matrix.")
6
2.4 희소행렬 추상데이터타입 효율적 기억장소 사상 <i, j, value> : 3-tuples (triples)
효율적 기억장소 사상 <i, j, value> : 3-tuples (triples) no. of rows no. of columns no. of non-zero elements ordering(column major or row major)
 no. of rows. no. of columns. no. of non-zero elements. ordering(column major or row major)")
7
2.4 희소행렬 추상데이터타입 희소 행렬 0 0 11 0 0 0 0 0 0 0 0 0 0 0 0 0 0 91 0 0 0 0 0 0 0 0 0 row col value 0 1 1 1 1 11 2 3 -6 4 0 91 5 2 28 1 2 3 4 5 1 2 3 4 5

8
2.4 희소행렬 추상데이터타입 행렬을 위한 연산 행렬의 생성 덧셈 곱셈 전치

9
2.4 희소행렬 추상데이터타입 행렬의 전치(Matrix Transpose) for j← 1 to n do
for i←1 to m do B(j, i) ← A(i, j) end end
 ← A(i, j) end end.")
10
2.4 희소행렬 추상데이터타입 1 2 3 1 2 3 A(0, 6, 6, 8 B(0, 6, 6, 8 (1, 0, 0, 15 (1, 0, 0, 15 (2, 0, 3, 22 (2, 0, 4, 91 (3, 0, 5, -15 (3, 1, 1, 11 (4, 1, 1, 11 (4. 2, 1, 3 (5, 1, 2, 3 (5, 2, 5, 28 (6, 2, 3, -6 (6, 3, 0, 22 (7, 4, 0, 91 (7, 3, 2, -6 (8, 5, 2, 28 (8, 5, 0, -15 행내에서 => 행우선, 열내에서 => 열우선

11
2.4 희소행렬 추상데이터타입 희소 행렬의 전치 각 행 i에 대해서 원소 <i, j, 값>을 가져와서
전치행렬의 원소 <j, i, 값>으로 저장

12
procedure TRANSPOSE(A,B)
//A is a matrix represented in sparse form// //B is set to be its transpose// 1 (m,n,t)←(A(0,1),A(0,2),A(0,3)) 2 (B(0,1),B(0,2),B(0,3))←(n,m,t) 3 if t<0 then return //check for zero matrix// 4 q←1 //q is position if next term in B// 5 for col←1 to n do //transpose by columns// 6 for p←1 to t do //for all nonzero terms do// 7 if A(p,2)=col //correct column// 8 then[(B(q,1),B(q,2),B(q,3)) ← //insert// 9 (A(p,2),A(p,1),A(p,3)) //next term// 10 q←q+1 ] 11 end 12 end 13 end TRANSPOSE
←(A(0,1),A(0,2),A(0,3)) 2 (B(0,1),B(0,2),B(0,3))←(n,m,t) 3 if t<0 then return //check for zero matrix// 4 q←1 //q is position if next term in B// 5 for col←1 to n do //transpose by columns// 6 for p←1 to t do //for all nonzero terms do// 7 if A(p,2)=col //correct column// 8 then[(B(q,1),B(q,2),B(q,3)) ← //insert// 9 (A(p,2),A(p,1),A(p,3)) //next term// 10 q←q+1 ] 11 end. 12 end. 13 end TRANSPOSE.")
13
void transpose(term a[], term b[])
/* a를 전치시켜 b를 생성 */ { int n, i, j, currentb; n = a[0].value; /* 총 원소 수 */ b[0].row = a[0].col; /* b의 행 수 = a의 열 수 */ b[0].col = a[0].row; /* b의 열 수 = a의 행 수 */ b[0].value = n; if (n > 0) { /* 0이 아닌 행렬 */ currentb = 1; for (i =0; i = a[0].col; i++) /* a에서 열별로 전치*/ for (j = 1; j <= n; j++) /* 현재의 열로부터 원소를 찾는다. */ if (a[j].col ==i { /* 현재 열에 있는 원소를 b에 첨가 */ b[currentb].row = a[j].col; b[currentb].col = a[j].row; b[currentb].value = a[j].value; currentb++; } O(columns * elements)
![void transpose(term a[], term b[])](http://slidesplayer.org/slide/14110307/86/images/13/void+transpose%28term+a%5B%5D%2C+term+b%5B%5D%29.jpg "/* a를 전치시켜 b를 생성 */ { int n, i, j, currentb; n = a[0].value; /* 총 원소 수 */ b[0].row = a[0].col; /* b의 행 수 = a의 열 수 */ b[0].col = a[0].row; /* b의 열 수 = a의 행 수 */ b[0].value = n; if (n > 0) { /* 0이 아닌 행렬 */ currentb = 1; for (i =0; i = a[0].col; i++) /* a에서 열별로 전치*/ for (j = 1; j <= n; j++) /* 현재의 열로부터 원소를 찾는다. */ if (a[j].col ==i { /* 현재 열에 있는 원소를 b에 첨가 */ b[currentb].row = a[j].col; b[currentb].col = a[j].row; b[currentb].value = a[j].value; currentb++; } O(columns * elements)")
14
void fast_transpose(term a[], term b[])
{ /* a를 전치시켜 b에 저장 */ int row_terms[MAX_COL], starting_pos[MAX_COL]; int i,j, num_col = a[0].col, num_terms = a[0].value; b[0].row = num_cols; b[0].col = a[0].row; b[0].value = num_terms; if (num_terms > 0) { /* 0이 아닌 행렬 */ for(i = 0; i < num_cols; i++) row_terms[i] = 0; for(i = 1; i <= num_terms; i++) row_terms[a[i].col]++; starting_pos[0] = 1; for(i = 1; i < num_cols; i++) starting_pos[i] = starting_pos[i-1] + row_terms[i-1]; for(i = 1; i <= num_terms; i++) { j = starting_pos[a[i].col]++; b[j].row = a[i].col; b[j].col = a[i].row; b[j].value = a[i].value; } } O(columns + elements)
![void fast_transpose(term a[], term b[])](http://slidesplayer.org/slide/14110307/86/images/14/void+fast_transpose%28term+a%5B%5D%2C+term+b%5B%5D%29.jpg "{ /* a를 전치시켜 b에 저장 */ int row_terms[MAX_COL], starting_pos[MAX_COL]; int i,j, num_col = a[0].col, num_terms = a[0].value; b[0].row = num_cols; b[0].col = a[0].row; b[0].value = num_terms; if (num_terms > 0) { /* 0이 아닌 행렬 */ for(i = 0; i < num_cols; i++) row_terms[i] = 0; for(i = 1; i <= num_terms; i++) row_terms[a[i].col]++; starting_pos[0] = 1; for(i = 1; i < num_cols; i++) starting_pos[i] = starting_pos[i-1] + row_terms[i-1]; for(i = 1; i <= num_terms; i++) { j = starting_pos[a[i].col]++; b[j].row = a[i].col; b[j].col = a[i].row; b[j].value = a[i].value; } } O(columns + elements)")
15
2.5 다차원 배열의 표현 배열의 원소 수 : a[upper0][upper1]....[uppern-1]
= ∏i=0,n-1 upperi - a[10][10][10] ⇨ 10・10・10 = 1000
![2.5 다차원 배열의 표현 배열의 원소 수 : a[upper0][upper1]....[uppern-1]](http://slidesplayer.org/slide/14110307/86/images/15/2.5+%EB%8B%A4%EC%B0%A8%EC%9B%90+%EB%B0%B0%EC%97%B4%EC%9D%98+%ED%91%9C%ED%98%84+%EB%B0%B0%EC%97%B4%EC%9D%98+%EC%9B%90%EC%86%8C+%EC%88%98+%3A+a%5Bupper0%5D%5Bupper1%5D....%5Buppern-1%5D.jpg "= ∏i=0,n-1 upperi - a[10][10][10] ⇨ 10・10・10 =")
16
2.5 다차원 배열의 표현 다차원 배열 표현 방법 - 행 우선 순서(row major order)
3,2 3,2 2.5 다차원 배열의 표현 다차원 배열 표현 방법 - 행 우선 순서(row major order) row0 row1 rowupper0-1 - 열 우선 순서(column major order) col0 col1 colupper1-1 A[0][0] A[0][1] … A[0][upper1-1] A[1][0] … A[0][0] A[1][0] … A[upper1-1][0] A[1][1] …
 row0 row1 rowupper 열 우선 순서(column major order) col0 col1 colupper1-1. A[0][0] A[0][1] … A[0][upper1-1] A[1][0] … A[0][0] A[1][0] … A[upper1-1][0] A[1][1] …")
17
2.5 다차원 배열의 표현 주소 계산 (2차원 배열 - 행우선 표현) α = A[0][0]의 주소
3,2 2.5 다차원 배열의 표현 주소 계산 (2차원 배열 - 행우선 표현) α = A[0][0]의 주소 A[i][0]의 주소 = α + i・upper1 A[i][j]의 주소 = α + i・upper1 + j
![2.5 다차원 배열의 표현 주소 계산 (2차원 배열 - 행우선 표현) α = A[0][0]의 주소](http://slidesplayer.org/slide/14110307/86/images/17/2.5+%EB%8B%A4%EC%B0%A8%EC%9B%90+%EB%B0%B0%EC%97%B4%EC%9D%98+%ED%91%9C%ED%98%84+%EC%A3%BC%EC%86%8C+%EA%B3%84%EC%82%B0+%282%EC%B0%A8%EC%9B%90+%EB%B0%B0%EC%97%B4+-+%ED%96%89%EC%9A%B0%EC%84%A0+%ED%91%9C%ED%98%84%29+%CE%B1+%3D+A%5B0%5D%5B0%5D%EC%9D%98+%EC%A3%BC%EC%86%8C.jpg "3, 다차원 배열의 표현. 주소 계산 (2차원 배열 - 행우선 표현) α = A[0][0]의 주소. A[i][0]의 주소 = α + i・upper1. A[i][j]의 주소 = α + i・upper1 + j.")
18
2.5 다차원 배열의 표현 주소 계산 (3차원 배열) : A[upper0][upper1][upper2]
3,2 주소 계산 (3차원 배열) : A[upper0][upper1][upper2] - 2차원 배열 upper1×upper2 ⇨ upper0 개 a[i][0][0] 주소 = α+i・upper1・upper2 a[i][j][k] 주소 = α+i・upper1・upper2+j・ upper2 + k
![2.5 다차원 배열의 표현 주소 계산 (3차원 배열) : A[upper0][upper1][upper2]](http://slidesplayer.org/slide/14110307/86/images/18/2.5+%EB%8B%A4%EC%B0%A8%EC%9B%90+%EB%B0%B0%EC%97%B4%EC%9D%98+%ED%91%9C%ED%98%84+%EC%A3%BC%EC%86%8C+%EA%B3%84%EC%82%B0+%283%EC%B0%A8%EC%9B%90+%EB%B0%B0%EC%97%B4%29+%3A+A%5Bupper0%5D%5Bupper1%5D%5Bupper2%5D.jpg "3,2. 주소 계산 (3차원 배열) : A[upper0][upper1][upper2] - 2차원 배열 upper1×upper2 ⇨ upper0 개. a[i][0][0] 주소 = α+i・upper1・upper2. a[i][j][k] 주소 = α+i・upper1・upper2+j・ upper2 + k.")
19
2.5 다차원 배열의 표현 A[upper0][upper1]...[uppern-1] α = A[0][0]...[0]의 주소
a[i0][0]...[0] 주소 = α + i0upper1upper2...uppern-1 a[i0][i1][0]...[0] 주소 = α+ i0upper1upper2...uppern-1 + i1upper2upper3...uppern-1 a[i0][i1]...[in-1] 주소 = α + i0upper1upper2...uppern-1 + i1upper2upper3...uppern-1 + i2upper3upper4...uppern-1 ⋮ + in-2uppern-1 + in-1
![2.5 다차원 배열의 표현 A[upper0][upper1]...[uppern-1] α = A[0][0]...[0]의 주소](http://slidesplayer.org/slide/14110307/86/images/19/2.5+%EB%8B%A4%EC%B0%A8%EC%9B%90+%EB%B0%B0%EC%97%B4%EC%9D%98+%ED%91%9C%ED%98%84+A%5Bupper0%5D%5Bupper1%5D...%5Buppern-1%5D+%CE%B1+%3D+A%5B0%5D%5B0%5D...%5B0%5D%EC%9D%98+%EC%A3%BC%EC%86%8C.jpg "a[i0][0]...[0] 주소 = α + i0upper1upper2...uppern-1. a[i0][i1][0]...[0] 주소 = α+ i0upper1upper2...uppern-1 + i1upper2upper3...uppern-1. a[i0][i1]...[in-1] 주소 = α + i0upper1upper2...uppern-1. + i1upper2upper3...uppern-1. + i2upper3upper4...uppern-1. ⋮ + in-2uppern-1. + in-1.")
20
제3장 스택과 큐

22
3.1 스택 추상 데이터 타입 스택(Stack) : 가장 마지막에 입력된 데이터가 가장 먼저 출력되는 후입선출 자료구조
LIFO(Last-in-First-out) 후입선출 : 한 끝에서 모든 삽입과 삭제가 일어나는 구현원리 응용) Subroutine or recursive call
 후입선출. : 한 끝에서 모든 삽입과 삭제가 일어나는 구현원리. 응용) Subroutine or recursive call.")
23
3.1 스택 추상 데이터 타입 데이터의 입력순서 A,B,C,D,E 데이터의 출력순서 E,D,C,B,A 초기상태 A입력
삭제 top E top D D C C top B B B top A A A A top

24
structure Stack objects: 0개 이상의 원소를 가진 유한 순서 리스트 functions: 모든 stack∈ Stack, item∈ element, max_stack_size∈ positive integer Stack CreateS(max_stack_size) ::= 최대 크기가 max_stack_size인 공백 스택을 생성 Boolean IsFull(stack, max_stack_size) ::= if (stack의 원소수 == max_stack_size) return TRUE else return FALSE Stack Add(stack, item) ::= if (IsFull(stack)) stack_full else stack의 톱에 item을 삽입하고 return Boolean IsEmpty(stack) ::= if (stack == CreateS(max_stack_size)) return TRUE Element Delete(stack) ::= if (IsEmpty(stack)) return else 스택 톱의 item을 제거해서 반환
 ::= 최대 크기가 max_stack_size인 공백 스택을 생성. Boolean IsFull(stack, max_stack_size) ::= if (stack의 원소수 == max_stack_size) return TRUE. else return FALSE. Stack Add(stack, item) ::= if (IsFull(stack)) stack_full. else stack의 톱에 item을 삽입하고 return. Boolean IsEmpty(stack) ::= if (stack == CreateS(max_stack_size)) return TRUE. Element Delete(stack) ::= if (IsEmpty(stack)) return. else 스택 톱의 item을 제거해서 반환.")
25
3.1 스택 추상 데이터 타입 top Stack CreateS(max_stack_size) ::=
#define MAX_STACK_SIZE 100 /*최대스택크기*/ typedef struct { int key; /* 다른 필드 */ } element; element stack[MAX_STACK_SIZE]; int top = -1; Boolean IsEmpty(top) ::= top < 0; Boolean IsFull(top) ::= top >= MAX_STACK_SIZE-1; MAX_STACK_SIZE top
 ::= top < 0; Boolean IsFull(top) ::= top >= MAX_STACK_SIZE-1; MAX_STACK_SIZE. top.")
26
3.1 스택 추상 데이터 타입 스택의 삽입 연산 void add(int *top, element item) {
/* 전역 stack에 item을 삽입 */ if (IsFull(*top)) { stack_full(); return; } stack[++*top] = item; top A
) { stack_full(); return; } stack[++*top] = item; top. A.")
27
3.1 스택 추상 데이터 타입 스택의 삭제 연산 element delete(int *top) {
/* stack의 최상위 원소를 반환 */ if (IsEmpty(*top)) return stack_empty(); /* 오류 key를 반환 */ return stack[(*top)--]; } top D C B A
) return stack_empty(); /* 오류 key를 반환 */ return stack[(*top)--]; } top. D. C. B. A.")
28
3.1 스택 추상 데이터 타입 스택의 예 택시의 동전통 10원 500원 100원 100원 500원 10원

30
3.2 큐 추상 데이터 타입 Queue : 가장 먼저 입력된 데이터가 가장 먼저 출력되는 선입선출 자료구조
FIFO(First-in-First-out) 선입선출리스트 : 한쪽 끝에서 데이터가 입력되고 그 반대쪽 끝에서 출력이 일어나는 구현원리 응용) Job scheduling
 선입선출리스트. : 한쪽 끝에서 데이터가 입력되고 그 반대쪽 끝에서 출력이 일어나는 구현원리. 응용) Job scheduling.")
31
3.2 큐 추상 데이터 타입 데이터의 입력순서 A,B,C,D,E 데이터의 출력순서 A,B,C,D,E 초기상태 A입력 B입력 …
삭제 E rear E rear D D C C B rear B B A rear A A A front rear front front front front

32
structure Queue objects: 0개 이상의 원소를 가진 유한 순서 리스트 functions: 모든 queue∈Queue, item∈element, max_queue_size∈positive integer Queue CreateQ(max_queue_size) ::= 최대 크기가 max_queue_size인 공백 큐를 생성 Boolean IsFullQ(queue, max_queue_size ) ::= if (queue의 원소수 == max_queue_size) return TRUE else return FALSE Queue AddQ(queue, item) ::= if (IsFull(queue)) queue_full else queue의 뒤에 item을 삽입하고 이 queue를 반환 Boolean IsEmptyQ(queue) ::= if (queue == CreateQ(max_queue_size)) return TRUE Element DeleteQ(queue) ::= if (IsEmpty(queue)) return else queue의 앞에 있는 item을 제거해서 반환
 ::= 최대 크기가 max_queue_size인 공백 큐를 생성. Boolean IsFullQ(queue, max_queue_size ) ::= if (queue의 원소수 == max_queue_size) return TRUE. else return FALSE. Queue AddQ(queue, item) ::= if (IsFull(queue)) queue_full. else queue의 뒤에 item을 삽입하고 이 queue를 반환. Boolean IsEmptyQ(queue) ::= if (queue == CreateQ(max_queue_size)) return TRUE. Element DeleteQ(queue) ::= if (IsEmpty(queue)) return. else queue의 앞에 있는 item을 제거해서 반환.")
33
3.2 큐 추상 데이터 타입 Queue CreateQ(max_queue_size) ::=
#define MAX_QUEUE_SIZE 100 /* 큐의 최대크기 */ typedef struct { int key; /* 다른 필드 */ } element; element queue[MAX_QUEUE_SIZE]; int rear = -1; int front = -1; Boolean IsEmptyQ(front, rear) ::= front == rear Boolean IsFullQ(front, rear) ::= rear == MAX_QUEUE_SIZE-1 rear front
 ::= front == rear. Boolean IsFullQ(front, rear) ::= rear == MAX_QUEUE_SIZE-1. rear. front.")
34
3.2 큐 추상 데이터 타입 큐의 삽입연산 void addq(int front, int *rear, element item)
{ /* queue에 item을 삽입 */ if (IsFullQ(front, *rear)) queue_full(); return; } queue[++*rear] = item; A rear front
) queue_full(); return; } queue[++*rear] = item; A. rear. front.")
35
3.2 큐 추상 데이터 타입 큐의 삭제연산 element deleteq(int *front, int rear) {
/* queue의 앞에서 원소를 삭제 */ if (IsEmptyQ(*front, rear)) return queue_empty(); /* 에러 key를 반환 */ return queue[++*front]; } E rear D C B A front
) return queue_empty(); /* 에러 key를 반환 */ return queue[++*front]; } E. rear. D. C. B. A. front.")
36
3.2 큐 추상 데이터 타입 터널 터널, 줄서기 3 2 1 1 2 3

37
3.2 큐 추상 데이터 타입 큐의 예 작업 스케쥴링 운영체제에 의한 작업 큐의 생성 시스템에 진입한 순서대로 처리
front rear Q[0] Q[1] Q[2] Q[3] 설명 공백큐 J Job1의 진입 J J Job2의 진입 J J J Job3의 진입 J J Job1의 진출 J Job2의 진출

38
3.2 큐 추상 데이터 타입 문제점 입력시 rear 값의 증가, 출력시 front 값의 증가
=> Queue가 full될 경우 전체를 왼쪽으로 이동하여 front 값을 조정해야 함 E rear D front C B A

39
3.2 큐 추상 데이터 타입 해결책 : Circular queue를 사용 [7] [0] [6] [1] [5] [2] [4]
[3] rear=0 front=0 rear front
![3.2 큐 추상 데이터 타입 해결책 : Circular queue를 사용 [7] [0] [6] [1] [5] [2] [4]](http://slidesplayer.org/slide/14110307/86/images/39/3.2+%ED%81%90+%EC%B6%94%EC%83%81+%EB%8D%B0%EC%9D%B4%ED%84%B0+%ED%83%80%EC%9E%85+%ED%95%B4%EA%B2%B0%EC%B1%85+%3A+Circular+queue%EB%A5%BC+%EC%82%AC%EC%9A%A9+%5B7%5D+%5B0%5D+%5B6%5D+%5B1%5D+%5B5%5D+%5B2%5D+%5B4%5D.jpg "[3] rear=0. front=0. rear. front.")
40
3.2 큐 추상 데이터 타입 해결책 : Circular queue를 사용 front : 첫 번째 원소의 하나 앞을 가리킴
rear : 입력된 원소의 마지막 위치 Modular 연산자를 이용 *rear = (*rear+1) % Max_Queue_Size *front = (*front+1) % Max_Queue_Size rear front
 % Max_Queue_Size. *front = (*front+1) % Max_Queue_Size. rear. front.")
41
3.2 큐 추상 데이터 타입 [0] [7] [6] [1] [2] [5] [3] [4] 환형큐의 추가연산 void addq(int front, int *rear, element item) { /* queue에 item을 입력 */ *rear = (*rear+1) % MAX_QUEUE_SIZE; if (front == *rear) { queue_full(rear); /* rear를 리세트시키고 에러를 프린트 */ return; } queue[*rear] = item; rear=0 front=0
![3.2 큐 추상 데이터 타입 [0] [7] [6] [1] [2] [5] [3] [4] 환형큐의 추가연산. void addq(int front, int *rear, element item)](http://slidesplayer.org/slide/14110307/86/images/41/3.2+%ED%81%90+%EC%B6%94%EC%83%81+%EB%8D%B0%EC%9D%B4%ED%84%B0+%ED%83%80%EC%9E%85+%5B0%5D+%5B7%5D+%5B6%5D+%5B1%5D+%5B2%5D+%5B5%5D+%5B3%5D+%5B4%5D+%ED%99%98%ED%98%95%ED%81%90%EC%9D%98+%EC%B6%94%EA%B0%80%EC%97%B0%EC%82%B0.+void+addq%28int+front%2C+int+%2Arear%2C+element+item%29.jpg "{ /* queue에 item을 입력 */ *rear = (*rear+1) % MAX_QUEUE_SIZE; if (front == *rear) { queue_full(rear); /* rear를 리세트시키고 에러를 프린트 */ return; } queue[*rear] = item; rear=0. front=0.")
42
3.2 큐 추상 데이터 타입 환형큐의 삭제연산 element deleteq(int *front, int rear) {
[0] [7] [6] [1] [2] [5] [3] [4] 환형큐의 삭제연산 element deleteq(int *front, int rear) { element item; /* queue의 front 원소를 삭제하여 그것을 item에 놓음 */ if (*front == rear) return queue_empty(); /* queue_empty는 에러 키를 반환 */ *front = (*front+1) % MAX_QUEUE_SIZE; return queue[*front]; } rear=0 front=0
 { element item; /* queue의 front 원소를 삭제하여 그것을 item에 놓음 */ if (*front == rear) return queue_empty(); /* queue_empty는 에러 키를 반환 */ *front = (*front+1) % MAX_QUEUE_SIZE; return queue[*front]; } rear=0. front=0.")
43
공백큐 [0] [7] [6] [1] [2] [5] [3] [4] rear=0 front=0 [0] [7] [6] [1] [2] [5] [3] [4] rear=3 front=0 J1 J2 J3 포화큐 포화큐 [0] [7] [6] [1] [2] [5] [3] [4] rear=7 front=0 [0] [7] [6] [1] [2] [5] [3] [4] rear=2 front=3 J7 J7 J8 J6 J6 J9 J1 J5 J2 J5 J10 J4 J3 J4
![공백큐 [0] [7] [6] [1] [2] [5] [3] [4] rear=0. front=0. [0] [7] [6] [1] [2] [5] [3] [4]](http://slidesplayer.org/slide/14110307/86/images/43/%EA%B3%B5%EB%B0%B1%ED%81%90+%5B0%5D+%5B7%5D+%5B6%5D+%5B1%5D+%5B2%5D+%5B5%5D+%5B3%5D+%5B4%5D+rear%3D0.+front%3D0.+%5B0%5D+%5B7%5D+%5B6%5D+%5B1%5D+%5B2%5D+%5B5%5D+%5B3%5D+%5B4%5D.jpg "rear=3. front=0. J1. J2. J3. 포화큐. 포화큐. [0] [7] [6] [1] [2] [5] [3] [4] rear=7. front=0. [0] [7] [6] [1] [2] [5] [3] [4] rear=2. front=3. J7. J7. J8. J6. J6. J9. J1. J5. J2. J5. J10. J4. J3. J4.")
44
Stack Ordered list in which all insertions and deletions are made at one end (top pointer)
LIFO(Last-In-First-Out) 제일 마지막에 입력된 데이터가 가장 먼저 출력 (응용) Subroutine or recursive call Queue Ordered list in which all insertions take place at one end, the rear, while all deletions take place at the other end, the front. FIFO(First-In-First-Out) 제일 처음에 입력된 데이터가 가장 먼저 출력 (응용) Job scheduling
 제일 마지막에 입력된 데이터가 가장 먼저 출력 (응용) Subroutine or recursive call. Queue Ordered list in which all insertions take place at one end, the rear, while all deletions take place at the other end, the front. FIFO(First-In-First-Out) 제일 처음에 입력된 데이터가 가장 먼저 출력 (응용) Job scheduling.")
45
3.3 미로문제 입구 막힌경로 통행경로 출구

46
3.3 미로문제 경로표현 ? 경계표현 ? 입구 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 막힌경로 1 1 1 1 1 1 통행경로 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 출구

47
3.3 미로문제 입구 1 1 1 1 1 1 1

48
3.3 미로문제 여덟방향이동을 위한구조 typedef struct { short int vert;
[row-1] [col-1] [row-1] [col] [row-1] [col+1] 3.3 미로문제 1 [row] [col-1] [row] [col+1] 여덟방향이동을 위한구조 typedef struct { short int vert; short int horiz; } offsets; offsets move[8]; [row+1] [col-1] [row+1] [col] [row+1] [col+1]

49
3.3 미로문제 현재의 위치 다음 이동할 위치? maze[row][col]
NW=7 N=0 NE=1 3.3 미로문제 [row-1] [col-1] [row-1] [col] [row-1] [col+1] 1 [row] [col-1] [row] [col+1] W=5 E=2 현재의 위치 maze[row][col] 다음 이동할 위치? next_row = row + move[dir].vert; next_col = col + move[dir].horiz; [row+1] [col-1] [row+1] [col] [row+1] [col+1] SW=4 SE=3
![3.3 미로문제 현재의 위치 다음 이동할 위치 maze[row][col]](http://slidesplayer.org/slide/14110307/86/images/49/3.3+%EB%AF%B8%EB%A1%9C%EB%AC%B8%EC%A0%9C+%ED%98%84%EC%9E%AC%EC%9D%98+%EC%9C%84%EC%B9%98+%EB%8B%A4%EC%9D%8C+%EC%9D%B4%EB%8F%99%ED%95%A0+%EC%9C%84%EC%B9%98+maze%5Brow%5D%5Bcol%5D.jpg "NW=7. N=0. NE= 미로문제. [row-1] [col-1] [row-1] [col] [row-1] [col+1] 1. [row] [col-1] [row] [col+1] W=5. E=2. 현재의 위치. maze[row][col] 다음 이동할 위치 next_row = row + move[dir].vert; next_col = col + move[dir].horiz; [row+1] [col-1] [row+1] [col] [row+1] [col+1] SW=4. SE=3.")
50
3.3 미로문제 경로의 탐색 현위치 저장후 방향 선택 : N에서 시계방향
잘못된 경로의 선택시는 backtracking후 다른 방향 시도 시도한 경로의 재시도 방지 mark[m+2][n+2] : 초기치 0 mark[row][col] = 1 /* 한번 방문한 경우 */ 경로 유지를 위해서 스택 사용

51
3.3 미로문제 경로 유지위한 스택 #define MAX-STACK-SIZE 100 /*스택의 최대크기*/
[row-1] [col-1] [col] [col+1] [row] [row+1] N=0 NE=1 E=2 NW=7 SE=3 SW=4 W=5 3.3 미로문제 경로 유지위한 스택 #define MAX-STACK-SIZE 100 /*스택의 최대크기*/ typedef struct { short int row; short int col; short int dir; } element; element stack[MAX_STACK_SIZE];

52
initiallize a stack to the maze's entrance coordinates and direction to north;
while (stack is not empty) { /* 스택의 톱에 있는 위치로 이동*/ <row, col, dir> = delete from top of stack; while (there are more moves from current position) { <next_row, next_col> = coordinate of next move; dir = direction of move; if ((next_row == EXIT_ROW) && (next_col == EXIT_COL)) success; if (maze[next_row][next_col] == 1) && mark[next_row][next_col] == 0) { /* 가능하지만 아직 이동해보지 않은 이동 방향 */ mark[next_row][next_col] = 1; /* 현재의 위치와 방향을 저장 */ add <row, col, dir> to the top of the stack; row = next_row; col = next_col; dir = north; } printf("No path found\n");
 { /* 스택의 톱에 있는 위치로 이동*/ <row, col, dir> = delete from top of stack; while (there are more moves from current position) { <next_row, next_col> = coordinate of next move; dir = direction of move; if ((next_row == EXIT_ROW) && (next_col == EXIT_COL)) success; if (maze[next_row][next_col] == 1) && mark[next_row][next_col] == 0) { /* 가능하지만 아직 이동해보지 않은 이동 방향 */ mark[next_row][next_col] = 1; /* 현재의 위치와 방향을 저장 */ add <row, col, dir> to the top of the stack; row = next_row; col = next_col; dir = north; } printf( No path found\n );")
53
3.3 미로문제 이동테이블 Name dir move[dir].vert move[dir].horiz N 0 -1 0
[row-1] [col-1] [col] [col+1] [row] [row+1] N=0 NE=1 E=2 NW=7 SE=3 SW=4 W=5 3.3 미로문제 이동테이블 Name dir move[dir].vert move[dir].horiz N NE E SE S SW W NW
![3.3 미로문제 이동테이블 Name dir move[dir].vert move[dir].horiz N](http://slidesplayer.org/slide/14110307/86/images/53/3.3+%EB%AF%B8%EB%A1%9C%EB%AC%B8%EC%A0%9C+%EC%9D%B4%EB%8F%99%ED%85%8C%EC%9D%B4%EB%B8%94+Name+dir+move%5Bdir%5D.vert+move%5Bdir%5D.horiz+N.jpg "[row-1] [col-1] [col] [col+1] [row] [row+1] N=0. NE=1. E=2. NW=7. SE=3. SW=4. W= 미로문제. 이동테이블. Name dir move[dir].vert move[dir].horiz. N NE E SE S SW W NW")
54
void path(void) { /* 미로를 통과하는 경로가 있으면 그 경로를 출력한다. */ int i, row, col, next_row, next_col, dir, found=FALSE; element position; mark[1][1]=1; top=0; stack[0].row=1; stack[0].col=1; stack[0].dir=1; while (top>-1 && !found) { position = delete(&top); row = position.row; col = position.col; dir = position.dir; while (dir<8 && !found) { next_row = row + move[dir].vert; /* dir 방향으로 이동 */ next_col = col + move[dir].horiz; if (next_row==EXIT_ROW && next_col==EXIT_COL) found = TRUE; else if (maze[next_row][next_col] && !mark[next_row][next_col]) { mark[next_row][next_col]) = 1; position.row = row; position.col = col; position.dir = ++dir; add(&top, position); row = next.row; col = next.col; dir = 0; } else ++dir;
 { position = delete(&top); row = position.row; col = position.col; dir = position.dir; while (dir<8 && !found) { next_row = row + move[dir].vert; /* dir 방향으로 이동 */ next_col = col + move[dir].horiz; if (next_row==EXIT_ROW && next_col==EXIT_COL) found = TRUE; else if (maze[next_row][next_col] && !mark[next_row][next_col]) { mark[next_row][next_col]) = 1; position.row = row; position.col = col; position.dir = ++dir; add(&top, position); row = next.row; col = next.col; dir = 0; } else ++dir;")
55
최악의 경우 연산시간 = O(mp) m : 행의 수 p : 열의 수 if (found) {
printf("The path is:\n"); printf("row col\n"); for (i=0; i<=top; i++) printf("%2d%5d", stack[i].row, stack[i].col"); printf("%2d%5d\n", row, col); printf("%2d%5d\n", EXIT_ROW, EXIT_COL); } else printf("The maze does not have a path\n"); 최악의 경우 연산시간 = O(mp) m : 행의 수 p : 열의 수
; printf( row col\n ); for (i=0; i<=top; i++) printf( %2d%5d , stack[i].row, stack[i].col ); printf( %2d%5d\n , row, col); printf( %2d%5d\n , EXIT_ROW, EXIT_COL); } else printf( The maze does not have a path\n ); 최악의 경우 연산시간 = O(mp) m : 행의 수. p : 열의 수.")
56
과제물 배열의 전치를 위한 두가지 알고리즘 P/G
다섯개의 입력 : A,B,C,D,E 에 해당하는 입력과 출력의 과정을 각각 Stack과 Queue, 그리고 환형 Queue를 이용하여 프로그래밍 미로찾기 프로그램 프로그래밍






.>")

 연속된 메모리 위치의 집합 <index, value>쌍의 집합>")
>")

>")

![희소 행렬(sparse matrix) mn matrix A ≡ A[MAX_ROWS][MAX_COLS] 희소행렬](/86/14110206/big_thumb.jpg "희소 행렬(sparse matrix) mn matrix A ≡ A[MAX_ROWS][MAX_COLS] 희소행렬>")



.>")

 연속된 메모리 위치의 집합 <index, value>쌍의 집합>")
 2개의 스택, stk1, stk2를 이용하여 큐를 구현하라.>")
 09. 04. 07.>")

