Download presentation
Presentation is loading. Please wait.

1
박시우 (email : park.si.u@gmail.com) http://cafe.naver.com/tech2u
업무에 바로 쓰는 SQL 튜닝 박시우 (

2
Chapter 1. 튜닝 기본 실행 계획(Execution Plan) 옵티마이저(Optimizer) 데이터베이스 튜닝 절차
 옵티마이저(Optimizer) 데이터베이스 튜닝 절차")
3
1. 실행 계획(Execution Plan) 사용자가 작성한 SQL이 요구한 데이터를 추출하기 위해 옵티마이저가 작업의 방법과 순서를 결정한 것 통계정보의 양 EXPLAIN PLAN < SET AUTOTRACE < tkprof(TRACE)
 .")
4
1.1 EXPLAIN PLAN 실행계획을 직접 검색하는 방법 실행계획을 저장 할 테이블 생성(PLAN_TABLE)
10g부터는 PLAN_TABLE이 임시 전역 테이블로 자동 생성되므로 별도로 생성 할 필요 없음 실행계획을 직접 검색하는 방법 실행계획을 저장 할 테이블 생성(PLAN_TABLE) 실행계획 생성 SQL> EXPLAIN PLAN SET STATEMENT_ID='TEST1' INTO PLAN_TABLE FOR SELECT A.ENAME, A.DEPTNO, B.DNAME FROM EMP A, DEPT B WHERE A.DEPTNO=B.DEPTNO; 윈도우 버전인 경우 @%ORACLE_HOME%\RDBMS\ADMIN\utlxplan.sql EXPLAIN PLAN 명령은 해당 문장을 실행하지 않고 실행 계획을 작성. 실제 사용 여부는 알 수 없음
 실행계획 생성. SQL> EXPLAIN PLAN. SET STATEMENT_ID= TEST1 INTO PLAN_TABLE FOR. SELECT A.ENAME, A.DEPTNO, B.DNAME. FROM EMP A, DEPT B. WHERE A.DEPTNO=B.DEPTNO; 윈도우 버전인 EXPLAIN PLAN 명령은 해당 문장을 실행하지 않고 실행 계획을 작성. 실제 사용 여부는 알 수 없음.")
5
실행계획 확인 SQL> SELECT LPAD(' ', 2*(LEVEL-1))||OPERATION AS OPERATION, OPTIONS, OBJECT_NAME, POSITION AS POS, OBJECT_INSTANCE AS INST, ID, PARENT_ID AS P_ID FROM PLAN_TABLE START WITH ID=0 AND STATEMENT_ID='TEST1' CONNECT BY PRIOR ID=PARENT_ID AND STATEMENT_ID='TEST1'; OPERATION OPTIONS OBJECT_NAM POS INST ID P_ID SELECT STATEMENT NESTED LOOPS TABLE ACCESS FULL EMP TABLE ACCESS BY INDEX ROWID DEPT INDEX UNIQUE SCAN PK_DEPT

6
스크립트 파일을 사용하는 방법(utlxpls.sql, utlxplp.sql)
SQL> EXPLAIN PLAN FOR SELECT A.ENAME, A.DEPTNO, B.DNAME FROM EMP A, DEPT B WHERE A.DEPTNO=B.DEPTNO; PLAN_TABLE_OUTPUT Plan hash value: | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | | 0 | SELECT STATEMENT | | | | (0)| 00:00:01 | | 1 | NESTED LOOPS | | | | (0)| 00:00:01 | | 2 | TABLE ACCESS FULL | EMP | | | (0)| 00:00:01 | | 3 | TABLE ACCESS BY INDEX ROWID| DEPT | | | (0)| 00:00:01 | |* 4 | INDEX UNIQUE SCAN | PK_DEPT | | | (0)| 00:00:01 | Predicate Information (identified by operation id): 4 - access("A"."DEPTNO"="B"."DEPTNO") 가장 최근에 수행된 실행계획 표시 윈도우 버전인 경우 @%ORACLE_HOME%\RDBMS\ADMIN\utlxpls.sql
| Time | | 0 | SELECT STATEMENT | | 14 | 308 | 4 (0)| 00:00:01 | | 1 | NESTED LOOPS | | 14 | 308 | 4 (0)| 00:00:01 | | 2 | TABLE ACCESS FULL | EMP | 14 | 126 | 3 (0)| 00:00:01 | | 3 | TABLE ACCESS BY INDEX ROWID| DEPT | 1 | 13 | 1 (0)| 00:00:01 | |* 4 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 (0)| 00:00:01 | Predicate Information (identified by operation id): access( A . DEPTNO = B . DEPTNO ) 가장 최근에 수행된 실행계획 표시. 윈도우 버전인")
7
DBMS_XPLAN 패키지를 사용하는 방법
SQL> EXPLAIN PLAN FOR SELECT A.ENAME, A.DEPTNO, B.DNAME FROM EMP A, DEPT B WHERE A.DEPTNO=B.DEPTNO; SQL> SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY); PLAN_TABLE_OUTPUT Plan hash value: | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | | 0 | SELECT STATEMENT | | | | (0)| 00:00:01 | | 1 | NESTED LOOPS | | | | (0)| 00:00:01 | | 2 | TABLE ACCESS FULL | EMP | | | (0)| 00:00:01 | | 3 | TABLE ACCESS BY INDEX ROWID| DEPT | | | (0)| 00:00:01 | |* 4 | INDEX UNIQUE SCAN | PK_DEPT | | | (0)| 00:00:01 | Predicate Information (identified by operation id): 4 - access("A"."DEPTNO"="B"."DEPTNO")
; PLAN_TABLE_OUTPUT Plan hash value: | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | | 0 | SELECT STATEMENT | | 14 | 308 | 4 (0)| 00:00:01 | | 1 | NESTED LOOPS | | 14 | 308 | 4 (0)| 00:00:01 | | 2 | TABLE ACCESS FULL | EMP | 14 | 126 | 3 (0)| 00:00:01 | | 3 | TABLE ACCESS BY INDEX ROWID| DEPT | 1 | 13 | 1 (0)| 00:00:01 | |* 4 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 (0)| 00:00:01 | Predicate Information (identified by operation id): access( A . DEPTNO = B . DEPTNO )")
8
10g부터는 PLAN_TABLE이 임시 전역 테이블로 자동 생성되므로 별도로 생성 할 필요 없음
1.2 SET AUTOTRACE 10g부터는 PLAN_TABLE이 임시 전역 테이블로 자동 생성되므로 별도로 생성 할 필요 없음 실행계획을 저장 할 테이블 생성(PLAN_TABLE) PLUSTRACE 롤 생성 및 사용자에게 롤 부여 SQL> CONN / AS SYSDBA SQL> GRANT PLUSTRACE TO SCOTT; 윈도우 버전인 경우 @%ORACLE_HOME%\RDBMS\ADMIN\utlxplan.sql 윈도우 버전인 경우 @%ORACLE_HOME%\sqlplus\admin\plustrce.sql
 PLUSTRACE 롤 생성 및 사용자에게 롤 부여. SQL> CONN / AS SYSDBA. SQL> GRANT PLUSTRACE TO SCOTT; 윈도우 버전인 윈도우 버전인")
9
SET AUTOTRACE TRACEONLY
SQL> SET AUTOTRACE ON SQL> SELECT A.ENAME, A.DEPTNO, B.DNAME 2 FROM EMP A, DEPT B 3 WHERE A.DEPTNO=B.DEPTNO; ENAME DEPTNO DNAME SMITH RESEARCH ALLEN SALES WARD SALES JONES RESEARCH MARTIN SALES BLAKE SALES CLARK ACCOUNTING SCOTT RESEARCH KING ACCOUNTING TURNER SALES ADAMS RESEARCH JAMES SALES FORD RESEARCH MILLER ACCOUNTING 14 개의 행이 선택되었습니다. (계속) SET AUTOTRACE TRACEONLY 출력 결과는 제외하고 실행 계획 및 통계만 출력
 SET AUTOTRACE TRACEONLY. 출력 결과는 제외하고 실행 계획 및 통계만 출력.")
10
Execution Plan Plan hash value: | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | | 0 | SELECT STATEMENT | | 14 | 308 | 4 (0)| 00:00:01 | | 1 | NESTED LOOPS | | 14 | 308 | 4 (0)| 00:00:01 | | 2 | TABLE ACCESS FULL | EMP | 14 | 126 | 3 (0)| 00:00:01 | | 3 | TABLE ACCESS BY INDEX ROWID| DEPT | 1 | 13 | 1 (0)| 00:00:01 | |* 4 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 (0)| 00:00:01 | Predicate Information (identified by operation id): access("A"."DEPTNO"="B"."DEPTNO") (계속)
| Time | | 0 | SELECT STATEMENT | | 14 | 308 | 4 (0)| 00:00:01 | | 1 | NESTED LOOPS | | 14 | 308 | 4 (0)| 00:00:01 | | 2 | TABLE ACCESS FULL | EMP | 14 | 126 | 3 (0)| 00:00:01 | | 3 | TABLE ACCESS BY INDEX ROWID| DEPT | 1 | 13 | 1 (0)| 00:00:01 | |* 4 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 (0)| 00:00:01 | Predicate Information (identified by operation id): access( A . DEPTNO = B . DEPTNO ) (계속)")
11
Statistics recursive calls 0 db block gets 24 consistent gets 8 physical reads 0 redo size 864 bytes sent via SQL*Net to client 384 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 14 rows processed
 0 sorts (disk) 14 rows processed")
12
1.3 EXECUTION PLAN 분석 SELECT ENAME, JOB, SAL, DNAME FROM EMP, DEPT WHERE EMP.DEPTNO=DEPT.DEPTNO AND EMP.EMPNO > 7800 AND EXISTS (SELECT * FROM SALGRADE WHERE EMP.SAL BETWEEN LOSAL AND HISAL);
;")
13
4->3->6->5->2->7->1->0
| Id | Operation | Name | | 0 | SELECT STATEMENT | | |* 1 | FILTER | | | 2 | NESTED LOOPS | | | 3 | TABLE ACCESS BY INDEX ROWID| EMP | |* 4 | INDEX RANGE SCAN | PK_EMP | | 5 | TABLE ACCESS BY INDEX ROWID| DEPT | |* 6 | INDEX UNIQUE SCAN | PK_DEPT | |* 7 | TABLE ACCESS FULL | SALGRADE | 4->3->6->5->2->7->1->0 실행계획을 보는 순서 테이블 액세스 프로세스와 그 테이블의 인덱스를 액세스하는 프로세스는 하나의 단위로 묶어서 생각함 여러 문장 중에서 들여쓰기가 많이 되어 있는 문장이 먼저 실행되는 문장이며, 들 여쓰기가 적은(한 레벨 위의) 상위 프로세스에 종속됨 들여쓰기가 같은 레벨이라면 위에 있는(먼저 나오는) 문장이 먼저 실행되는 문장 임
 상위 프로세스에 종속됨. 들여쓰기가 같은 레벨이라면 위에 있는(먼저 나오는) 문장이 먼저 실행되는 문장 임.")
14
실행계획으로부터 얻을 수 있는 정보 EMP 테이블의 경우 PK_EMP 인덱스를 RANGE SCAN하여 ROWID를 구한 후, EMP 테이블을 액세스 함 DEPT 테이블의 경우 PK_DEPT 인덱스를 UNIQUE SCAN하여 ROWID를 구한 후, DEPT 테이블을 액세스 함 ①과 ②의 두 집합을 NESTED LOOP 조인으로 처리하며 드라이빙 테이블은 ①의 집합 임 ③의 집합에서 각 행에 대하여 서브쿼리에 의해 FILTER 처리 서브쿼리 실행 시, SALGRADE 테이블의 경우 인덱스를 사용하지 않고 FULL TABLE SCAN을 수행

15
1.4 tkprof Utility Trace 파일을 생성 후, tkprof 유틸리티를 사용하여 SQL 분석
10g부터 deprecated 됨 EXEC DBMS_SESSION.SESSION_TRACE_ENABLE; EXEC DBMS_SESSION.SESSION_TRACE_DISABLE; 1.4 tkprof Utility Trace 파일을 생성 후, tkprof 유틸리티를 사용하여 SQL 분석 세션 단위에서 Trace 파일 생성 지정 SQL> ALTER SESSION SET SQL_TRACE = TRUE; 원하는 SQL을 실행 다음 명령을 실행하거나, SQL*Plus를 종료하면 Trace 파일 생성 완료 SQL> ALTER SESSION SET SQL_TRACE = FALSE; Trace 파일의 생성 위치는 USER_DUMP_DEST 파라메터에서 확인(관리자) SQL> SHOW PARAMETER USER_DUMP_DEST Trace 파일명을 확인하기 위해 프로세스 ID 확인 SQL> SELECT P.SPID FROM V$PROCESS P, V$SESSION S WHERE P.ADDR = S.PADDR AND S.AUDSID = USERENV('SESSIONID'); GRANT SELECT ON V_$PROCESS TO SCOTT; GRANT SELECT ON V_$SESSION TO SCOTT;
 SQL> SHOW PARAMETER USER_DUMP_DEST. Trace 파일명을 확인하기 위해 프로세스 ID 확인. SQL> SELECT P.SPID. FROM V$PROCESS P, V$SESSION S. WHERE P.ADDR = S.PADDR. AND S.AUDSID = USERENV( SESSIONID ); GRANT SELECT ON V_$PROCESS TO SCOTT; GRANT SELECT ON V_$SESSION TO SCOTT;")
16
tkprof Trace파일명 출력파일명 옵션=값
tkprof xe_ora_3476.trc result.txt sys=no explain=scott/tiger 출력 파일 확인 SELECT A.ENAME, A.DEPTNO, B.DNAME FROM EMP A, DEPT B WHERE A.DEPTNO=B.DEPTNO call count cpu elapsed disk query current rows Parse Execute Fetch total Misses in library cache during parse: 0 Optimizer mode: ALL_ROWS Parsing user id: 36 (SCOTT) (계속)
 (계속)")
17
Rows Row Source Operation NESTED LOOPS (cr=24 pr=0 pw=0 time=311 us) 14 TABLE ACCESS FULL EMP (cr=8 pr=0 pw=0 time=388 us) 14 TABLE ACCESS BY INDEX ROWID DEPT (cr=16 pr=0 pw=0 time=598 us) 14 INDEX UNIQUE SCAN PK_DEPT (cr=2 pr=0 pw=0 time=250 us)(object id 13636) Rows Execution Plan 0 SELECT STATEMENT MODE: ALL_ROWS 14 NESTED LOOPS 14 TABLE ACCESS MODE: ANALYZED (FULL) OF 'EMP' (TABLE) 14 TABLE ACCESS MODE: ANALYZED (BY INDEX ROWID) OF 'DEPT' (TABLE) 14 INDEX MODE: ANALYZED (UNIQUE SCAN) OF 'PK_DEPT' (INDEX(UNIQUE))
 14 TABLE ACCESS FULL EMP (cr=8 pr=0 pw=0 time=388 us) 14 TABLE ACCESS BY INDEX ROWID DEPT (cr=16 pr=0 pw=0 time=598 us) 14 INDEX UNIQUE SCAN PK_DEPT (cr=2 pr=0 pw=0 time=250 us)(object id 13636) Rows Execution Plan 0 SELECT STATEMENT MODE: ALL_ROWS 14 NESTED LOOPS 14 TABLE ACCESS MODE: ANALYZED (FULL) OF EMP (TABLE) 14 TABLE ACCESS MODE: ANALYZED (BY INDEX ROWID) OF DEPT (TABLE) 14 INDEX MODE: ANALYZED (UNIQUE SCAN) OF PK_DEPT (INDEX(UNIQUE))")
18
1.5 Trace 파일 분석 Trace 파일에서 얻을 수 있는 정보 CPU Time, Elapsed Time(총 경과시간)
Disk(물리적), Memory(논리적) 읽기에 의해 처리된 블록 수 추출된 Row의 수 SQL Parsing, Execute, Fetch를 수행한 횟수 라이브러리 캐시 Miss 횟수
, Memory(논리적) 읽기에 의해 처리된 블록 수. 추출된 Row의 수. SQL Parsing, Execute, Fetch를 수행한 횟수. 라이브러리 캐시 Miss 횟수.")
19
call count cpu elapsed disk query current rows
Parse Execute Fetch total Parse : SQL 문의 파싱 단계에 대한 통계를 나타내며, 새로 파싱 했거나 Shared SQL Area에서 찾은 것도 같이 포함. 단, PL/SQL이나 Pro*C에서 Hold Cursor를 지정한 경우에는 한번만 파싱됨 Execute : SQL문의 실행 단계에 대한 통계를 나타내며, 주로 INSERT, UPDATE, DELETE 문들의 경우 여기에 수행된 결과가 나타나고, Fetch에는 아주 적은 값이 나타남 Fetch : SQL 문이 실행되면서 Fetch된 단계에 대한 통계를 나타내며, 주로 SELECT 문들의 경우 여기에 많은 값들이 나타나고 Execute에는 아주 적은 값이 나타남

20
Count : SQL문의 Parse, Execute, Fetch가 수행된 횟수
Cpu : Parse, Execute, Fetch 시 실제로 사용한 CPU 시간(1/100초 단위) Elapsed : SQL문의 시작에서 종료 시까지 실제 소요된 시간 Disk : 디스크에서 읽혀진 데이터 블록의 수 Query : 메모리 내에서 변경되지 않은 블록을 읽거나 다른 세션에 의해 변 경되었으나 아직 Commit 되지 않아 복사해 둔 Snapshot 블록을 통해 읽혀 진 블록의 수로서, SELECT 문의 경우가 거의 여기에 해당되고 INSERT, UPDATE, DELETE 시에는 약간 발생 Current : 현재 세션에서 작업한 내용을 Commit 하지 않아 오직 자신에게 만 유효한 블록(Dirty Block)을 통해 액세스한 블록의 수로 INSERT, UPDATE, DELETE 시에 많이 발생하고, SELECT 문의 경우는 거의 없거나 약간 발생 Rows : SQL문을 수행한 결과에 의해 최종적으로 액세스한 로우의 수이며 서브쿼리에 의해서 추출된 로우는 제외됨
 Elapsed : SQL문의 시작에서 종료 시까지 실제 소요된 시간. Disk : 디스크에서 읽혀진 데이터 블록의 수. Query : 메모리 내에서 변경되지 않은 블록을 읽거나 다른 세션에 의해 변 경되었으나 아직 Commit 되지 않아 복사해 둔 Snapshot 블록을 통해 읽혀 진 블록의 수로서, SELECT 문의 경우가 거의 여기에 해당되고 INSERT, UPDATE, DELETE 시에는 약간 발생. Current : 현재 세션에서 작업한 내용을 Commit 하지 않아 오직 자신에게 만 유효한 블록(Dirty Block)을 통해 액세스한 블록의 수로 INSERT, UPDATE, DELETE 시에 많이 발생하고, SELECT 문의 경우는 거의 없거나 약간 발생. Rows : SQL문을 수행한 결과에 의해 최종적으로 액세스한 로우의 수이며 서브쿼리에 의해서 추출된 로우는 제외됨.")
21
1.6 DBMS_XPLAN 패키지 사용 관리자로 접속하여 해당 사용자에게 권한 부여
GRANT SELECT ON V_$SQL TO SCOTT; GRANT SELECT ON V_$SQL_PLAN_STATISTICS_ALL TO SCOTT; GRANT SELECT ON V_$SESSION TO SCOTT; GRANT SELECT ON V_$SQL_PLAN TO SCOTT; 힌트와 함께 분석 할 문장 수행 SELECT /*+ GATHER_PLAN_STATISTICS */ * FROM EMP, DEPT WHERE EMP.DEPTNO=DEPT.DEPTNO; 실행 계획 확인 SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST'));
);")
22
PLAN_TABLE_OUTPUT SQL_ID 30q6j6hjubbkd, child number 0 SELECT /*+ GATHER_PLAN_STATISTICS */ * FROM EMP, DEPT WHERE EMP.DEPTNO=DEPT.DEPTNO Plan hash value: | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | | 1 | TABLE ACCESS BY INDEX ROWID| EMP | | | |00:00:00.01 | | | 2 | NESTED LOOPS | | | | |00:00:00.01 | | | 3 | TABLE ACCESS FULL | DEPT | | | |00:00:00.01 | | |* 4 | INDEX RANGE SCAN | EMP_DEPTNO_IDX | | | |00:00:00.01 | | Predicate Information (identified by operation id): 4 - access("EMP"."DEPTNO"="DEPT"."DEPTNO")
: access( EMP . DEPTNO = DEPT . DEPTNO )")
23
2. 옵티마이저 2.1 RBO(Rule Based Optimizer)
SQL문에 대해 실행계획을 세우는 Oracle Server의 일부로서 SQL 문장을 수 행하는 가장 최적의 방법을 선택하는 오라클의 핵심 기술 2.1 RBO(Rule Based Optimizer) RBO는 다양한 액세스 경로(Access Path)를 과거의 경험에 기반하여 미리 순위를 부 여해두고, 이러한 우선순위에 따라 실행계획을 작성함 SQL 문을 실행하기 위한 액세스 경로가 하나 이상 있는 경우, RBO는 우선순위가 높 은 액세스 경로를 선택 일반적으로 우선순위가 높은 액세스 경로는 우선순위가 낮은 액세스 경로보다 더 빠 르게 실행되지만, 예외적인 경우도 발생 가능 RBO 모드의 경우, 수립될 실행계획의 예측이 가능하기 때문에 사용자가 원하는 실행 계획으로 유도하기가 용이함
 RBO는 다양한 액세스 경로(Access Path)를 과거의 경험에 기반하여 미리 순위를 부 여해두고, 이러한 우선순위에 따라 실행계획을 작성함. SQL 문을 실행하기 위한 액세스 경로가 하나 이상 있는 경우, RBO는 우선순위가 높 은 액세스 경로를 선택. 일반적으로 우선순위가 높은 액세스 경로는 우선순위가 낮은 액세스 경로보다 더 빠 르게 실행되지만, 예외적인 경우도 발생 가능. RBO 모드의 경우, 수립될 실행계획의 예측이 가능하기 때문에 사용자가 원하는 실행 계획으로 유도하기가 용이함.")
24
2.2 RANK RULE

25
Rank 1 : Single Row by Rowid SELECT /*+ RULE */ * FROM EMP
WHERE ROWID='AAADVFAAEAAAADkAAA'; RBO로 동작 Rank 4 : Single Row by Unique or Primary Key SELECT /*+ RULE */ * FROM EMP WHERE EMPNO=7844;

26
Rank 8 : Composite Column Index
CREATE INDEX EMP_JOB_DEPTNO_IDX ON EMP(JOB, DEPTNO); SELECT /*+ RULE */ * FROM EMP WHERE JOB='CLERK' AND DEPTNO=30; DROP INDEX EMP_JOB_DEPTNO_IDX;
; SELECT /*+ RULE */ * FROM EMP. WHERE JOB= CLERK AND DEPTNO=30; DROP INDEX EMP_JOB_DEPTNO_IDX;")
27
Rank 9 : Single Column Index
CREATE INDEX EMP_JOB_IDX ON EMP(JOB); SELECT /*+ RULE */ * FROM EMP WHERE JOB='CLERK'; DROP INDEX EMP_JOB_IDX;
; SELECT /*+ RULE */ * FROM EMP. WHERE JOB= CLERK ; DROP INDEX EMP_JOB_IDX;")
28
Rank 10 : Bounded Range Search on Indexed Columns
CREATE INDEX EMP_DEPTNO_IDX ON EMP(DEPTNO); SELECT /*+ RULE */ * FROM EMP WHERE DEPTNO BETWEEN 10 AND 40; DROP INDEX EMP_DEPTNO_IDX;
; SELECT /*+ RULE */ * FROM EMP. WHERE DEPTNO BETWEEN 10 AND 40; DROP INDEX EMP_DEPTNO_IDX;")
29
Rank 11 : Unbounded Range Search on Indexed Columns
CREATE INDEX EMP_DEPTNO_IDX ON EMP(DEPTNO); SELECT /*+ RULE */ * FROM EMP WHERE DEPTNO > 10; DROP INDEX EMP_DEPTNO_IDX;
; SELECT /*+ RULE */ * FROM EMP. WHERE DEPTNO > 10; DROP INDEX EMP_DEPTNO_IDX;")
30
Rank 15 : Full Table Scan SELECT /*+ RULE */ * FROM EMP WHERE SAL > 1000;

31
Quiz) 다음과 같은 인덱스가 정의되어 있고, SQL 문장이 다음과 같을 때 RBO가 선택할 액세스 경로는?
CREATE INDEX EMP_ENAME_IDX ON EMP(ENAME); SELECT /*+ RULE */ * FROM EMP WHERE EMPNO=7369 AND ENAME='SMITH'; DROP INDEX EMP_ENAME_IDX; 15위 FULL TABLE SCAN 4위 UNIQUE INDEX 9위 Single Column INDEX
; SELECT /*+ RULE */ * FROM EMP. WHERE EMPNO=7369 AND ENAME= SMITH ; DROP INDEX EMP_ENAME_IDX; 15위 FULL TABLE SCAN. 4위 UNIQUE INDEX. 9위 Single Column INDEX.")
32
8위 Composite Column INDEX
Quiz) 다음과 같은 인덱스가 정의되어 있고, SQL 문장이 다음과 같을 때 RBO가 선택할 액세스 경로는? CREATE INDEX EMP_JOB_IDX ON EMP(JOB); CREATE INDEX EMP_DEPTNO_JOB_IDX ON EMP(DEPTNO, JOB); SELECT /*+ RULE */ * FROM EMP WHERE DEPTNO=30 AND JOB='SALESMAN'; DROP INDEX EMP_JOB_IDX; DROP INDEX EMP_DEPTNO_JOB_IDX; 15위 FULL TABLE SCAN 8위 Composite Column INDEX 9위 Single Column INDEX
 다음과 같은 인덱스가 정의되어 있고, SQL 문장이 다음과 같을 때 RBO가 선택할 액세스 경로는 CREATE INDEX EMP_JOB_IDX ON EMP(JOB); CREATE INDEX EMP_DEPTNO_JOB_IDX ON EMP(DEPTNO, JOB); SELECT /*+ RULE */ * FROM EMP. WHERE DEPTNO=30 AND JOB= SALESMAN ; DROP INDEX EMP_JOB_IDX; DROP INDEX EMP_DEPTNO_JOB_IDX; 15위 FULL TABLE SCAN. 8위 Composite Column INDEX. 9위 Single Column INDEX.")
33
Quiz) 다음과 같은 인덱스가 정의되어 있고, SQL 문장이 다음과 같을 때 RBO가 선택할 액세 스 경로는?
CREATE INDEX EMP_DEPTNO_IDX ON EMP(DEPTNO); CREATE INDEX EMP_SAL_IDX ON EMP(SAL); SELECT /*+ RULE */ * FROM EMP WHERE DEPTNO BETWEEN 10 AND 20 AND SAL>=3000; DROP INDEX EMP_DEPTNO_IDX; DROP INDEX EMP_SAL_IDX; 15위 FULL TABLE SCAN 10위 Bounded Range 11위 Unbounded Range
; CREATE INDEX EMP_SAL_IDX ON EMP(SAL); SELECT /*+ RULE */ * FROM EMP. WHERE DEPTNO BETWEEN 10 AND 20. AND SAL>=3000; DROP INDEX EMP_DEPTNO_IDX; DROP INDEX EMP_SAL_IDX; 15위 FULL TABLE SCAN. 10위 Bounded Range. 11위 Unbounded Range.")
34
Quiz) 다음과 같은 인덱스가 정의되어 있고, SQL 문장이 다음과 같을 때 RBO가 선택할 액세스 경로는?
INDEX1 : 성별 INDEX2 : 급여 SELECT * FROM 사원 WHERE 성별=‘남’ AND 급여 >= ; 15위 FULL TABLE SCAN 9위 Single Column INDEX 11위 Unbounded Range

35
2.3 CBO(Cost Based Optimizer)
CBO는 요구된 Row 들을 처리하는데 필요한 자원의 사용을 최소화해서, 궁 극적으로 SQL 문장을 빨리 처리하는데 목적이 있음 CBO에 영향을 미치는 비용 산정 요소는 각종 통계 정보, SQL 형태, Hint, optimizer_mode, 연산자, Index, Cluster, DBMS 버전, CPU 용량, Memory 용량, Disk I/O 비용 등 매우 다양하며, 지속적으로 추가되고 있음 특히, Data Dictionary 내의 테이블, 인덱스 등에 대한 통계치와 데이터 분 포가 중요 I/O나 CPU 소요 시간뿐만 아니라 문장을 실행하기 위해 요구되는 메모리 까지 고려하여 비용을 계산하므로, 고비용의 실행계획은 저비용의 실행계 획보다 실행시간이 더 많이 필요하다고 판단하여 저비용의 실행계획을 선 택 통계 정보를 정기적으로 수집하는 것이 중요

36
2.4 ANALYZE OBJECT 정보 ANALYZE 명령은 테이블, 인덱스 등의 통계 정보를 생성하며, 이 통계 정보 는 CBO가 가장 효율적인 실행계획을 수립하기 위하여 비용을 계산할 때 중요하게 사용됨 ANALYZE 명령에 의해 얻어지는 통계 정보는 대표적으로 다음과 같으며, USER_TABLES, USER_TAB_COLUMNS, USER_INDEXES, USER_CLUSTERS 등 의 데이터 딕셔너리 테이블에 저장됨

37
테이블 인덱스 컬럼 클러스터 총 Row 수, 총 Block 수 비어 있는 Block에 쓰여질 수 있는 빈 공간의 평균
Chain이 발생된 Row 수 인덱스 Row의 평균 길이 Index의 깊이 Leaf Block의 개수 Distinct Key의 수 Leaf Blocks/Key의 평균, Data Blocks/Key의 평균 Clustering Factor 가장 큰 Key의 값, 가장 작은 Key의 값 컬럼 Distinct한 값의 수 히스토그램 정보 클러스터 Cluster Key 당 길이의 평균

38
2.5 ANALYZE 실행 ANALYZE { TABLE / INDEX / CLUSTER } OBJECT_NAME
{ COMPUTE / ESTIMATE / DELETE } STATISTICS; 예) ANALYZE TABLE EMP COMPUTE STATISTICS; ANALYZE TABLE EMP ESTIMATE STATISTICS SAMPLE 10 PERCENT; ANALYZE TABLE EMP ESTIMATE STATISTICS SAMPLE 10 ROWS; ANALYZE TABLE EMP DELETE STATISTICS;
 ANALYZE TABLE EMP COMPUTE STATISTICS; ANALYZE TABLE EMP ESTIMATE STATISTICS SAMPLE 10 PERCENT; ANALYZE TABLE EMP ESTIMATE STATISTICS SAMPLE 10 ROWS; ANALYZE TABLE EMP DELETE STATISTICS;")
39
테이블을 ANALYZE 하면 INDEX 들은 같이 ANALYZE 됨
SELECT 'ANALYZE TABLE '||TABLE_NAME||' COMPUTE STATISTICS;' FROM USER_TABLES; ANALYZE 작업을 새로이 수행해야 하는 경우 - 테이블이 재생성된 경우 - 새로 클러스터링을 한 경우 - 인덱스를 추가 혹은 재생성한 경우 - 다량의 데이터를 SQL이나 배치 애플리케이션을 통해 작업한 경우 - 결산 작업이 끝난 경우 ANALYZE 작업 여부를 쉽게 알 수 있는 방법 SELECT TABLE_NAME, LAST_ANALYZED, NUM_ROWS

40
DBMS_STATS 패키지 DBMS_STATS.GATHER_TABLE_STATS(OWNNAME, TABNAME,
ESTIMATE_PERCENT, CASCADE, METHOD_OPT); 예) EXEC DBMS_STATS.GATHER_TABLE_STATS(USER, 'EMP'); EXEC DBMS_STATS.GATHER_TABLE_STATS(USER, 'DEPT', ESTIMATE_PERCENT=>NULL, CASCADE=>TRUE, METHOD_OPT=>'FOR ALL COLUMNS SIZE AUTO'); 통계를 COMPUTE Dependent object에 대해서 통계 수집 모든 컬럼에 히스토그램 생성(버킷 개수는 자동 결정)
; 예) EXEC DBMS_STATS.GATHER_TABLE_STATS(USER, EMP ); EXEC DBMS_STATS.GATHER_TABLE_STATS(USER, DEPT , ESTIMATE_PERCENT=>NULL, CASCADE=>TRUE, METHOD_OPT=> FOR ALL COLUMNS SIZE AUTO ); 통계를 COMPUTE. Dependent object에 대해서 통계 수집. 모든 컬럼에 히스토그램 생성(버킷 개수는 자동 결정)")
41
2.6 OPTIMIZER_MODE (1) OPTIMIZER_MODE의 종류 CHOOSE RULE FIRST_ROWS
통계정보가 존재하면 all_rows로 동작하고, 그렇지 않은 경우 rule 사용. 9i버전의 디폴트 10g의 경우, DBCA로 데이터베이스를 생성하거나, 수동 생성 시에 catproc.sql을 호출하면, 24 시간마다 통계정보가 없거나 오래된 통계정보를 가진 테이블에 대해 통계 정보를 수집하는 JOB을 자동 설치 RULE RBO(Rule Based Optimizer)의 사용. Deprecated 되었으며, 10g에서 지원 중단 FIRST_ROWS 9i에서 deprecated 되었음. 과거 버전과의 호환성을 위해 아직 제공됨. 전체 데이터 중에 첫 번째 로우를 가장 빨리 리턴 할 수 있는 실행계획을 찾기 위해 노력함. FIRST_ROWS_1과 같음 FIRST_ROWS_N N에는 1, 10, 100, 1000 등이 올 수 있음. 전체 데이터 중에 N개의 로우를 가장 빨리 리턴 할 수 있는 실행계획을 찾기 위해 노력함. 9i에서 최초 도입 ALL_ROWS 모든 로우를 가장 빨리 리턴 할 수 있는 실행계획을 찾기 위해 노력함. 10g의 디폴트
의 사용. Deprecated 되었으며, 10g에서 지원 중단. FIRST_ROWS. 9i에서 deprecated 되었음. 과거 버전과의 호환성을 위해 아직 제공됨. 전체 데이터 중에 첫 번째 로우를 가장 빨리 리턴 할 수 있는 실행계획을 찾기 위해 노력함. FIRST_ROWS_1과 같음. FIRST_ROWS_N. N에는 1, 10, 100, 1000 등이 올 수 있음. 전체 데이터 중에 N개의 로우를 가장 빨리 리턴 할 수 있는 실행계획을 찾기 위해 노력함. 9i에서 최초 도입. ALL_ROWS. 모든 로우를 가장 빨리 리턴 할 수 있는 실행계획을 찾기 위해 노력함. 10g의 디폴트.")
42
(2) 옵티마이저 모드의 레벨 별 설정 우선 순위 : Statement > Session > Instance
Instance Level의 OPTIMIZER_MODE ALTER SYSTEM SET OPTIMIZER_MODE={RULE / CHOOSE / FIRST_ROWS_N / ALL_ROWS} Session Level의 OPTIMIZER_MODE ALTER SESSION Statement Level의 OPTIMIZER_MODE SELECT /*+ RULE */ ENAME FROM EMP;

43
(3) 옵티마이저 모드 별 쿼리 분석 차이 SELECT /*+ RULE */ A.ENAME, B.DNAME
FROM EMP A, DEPT B WHERE A.DEPTNO=B.DEPTNO AND A.DEPTNO=10;

44
WHERE A.DEPTNO=B.DEPTNO AND A.DEPTNO=10;
SELECT A.ENAME, B.DNAME FROM EMP A, DEPT B WHERE A.DEPTNO=B.DEPTNO AND A.DEPTNO=10; SELECT A.ENAME, B.DNAME FROM EMP A, DEPT B WHERE B.DEPTNO=10 AND A.DEPTNO=10; 이행적 폐쇄 발생

45
3. 데이터베이스 튜닝 절차 모델링 단계의 튜닝 S/W 단계의 튜닝 H/W 단계의 튜닝

46
3.1 모델링 단계의 튜닝 비즈니스 규칙 튜닝 데이터 모델링 튜닝 업무 표준화 및 단순화 반복적 수작업의 전산화
일시적 작업의 수작업 전환 온라인 프로세스의 응답 시간 목표 단축 데이터 모델링 튜닝 데이터 중복 방지를 위한 정규화 잦은 조인 연산 제거를 위한 역정규화

47
3.2 S/W 단계의 튜닝 데이터베이스 Access 방식 튜닝 데이터베이스 Object 튜닝 옵티마이저 모드 결정
프로그래밍 언어 선택 배열 처리 및 부분 범위 처리 적용 여부의 결정 등 데이터베이스 Object 튜닝 인덱스의 추가 또는 변경 테이블의 컬럼이나 PK 변경 비트맵 인덱스, 함수 기반 인덱스, Reverse Key 인덱스, 클러스터 인덱스 등의 사용 고려 뷰, 시퀀스, 동의어, 사용자 함수, 프로시저의 활용

48
SQL 및 프로그램 튜닝 잘못된 SQL 문장의 수정 서브쿼리, 인라인 뷰, 조인 등의 선택 및 변환
동일 데이터의 중복 읽기 방지

49
<힌트(Hint)의 사용> 힌트는 해당 SQL 문에 한정되며 CBO를 사용. 옵티마이저가 100% 힌트를 받아들일 의무는 없으며, 자체적인 판단이 중요 요소로 작용 힌트는 한 SQL 문에 배타적인 내용이 아니라면 여러 개를 같이 사용 할 수 있으며, 서브쿼리, 인라인 뷰 단위로 중첩해서 사용 가능 힌트 구문인 /*+ Hint */ 의 경우 문법이 틀리거나 오타가 있어도 에러를 반환하지 않음. 힌트는 정확하게 사용하여야 하며, 적용 결과는 실행계획으 로 확인 가능 힌트는 대소문자를 구분하지 않으며, ‘/*+’는 붙여서 사용하되 힌트 내에는 빈칸이 있어도 상관 없음. 많이 틀리는 예로서 테이블에 Alias를 지정하고 힌트에는 Alias를 사용하지 않는 경우임

50
예제1) 힌트를 사용하지 않은 경우 SELECT. FROM EMP WHERE EMPNO > 0; 예제2) /. +
예제1) 힌트를 사용하지 않은 경우 SELECT * FROM EMP WHERE EMPNO > 0; 예제2) /*+ */ 힌트를 사용한 경우 SELECT /*+ FULL(EMP) */ * FROM EMP
 힌트를 사용하지 않은 경우 SELECT * FROM EMP WHERE EMPNO > 0; 예제2) /*+ */ 힌트를 사용한 경우 SELECT /*+ FULL(EMP) */ * FROM EMP")
51
예제3) 힌트를 중복해서 사용한 경우 SELECT /. + ALL_ROWS INDEX_DESC(EMP PK_EMP). /
예제3) 힌트를 중복해서 사용한 경우 SELECT /*+ ALL_ROWS INDEX_DESC(EMP PK_EMP) */ * FROM EMP WHERE EMPNO > 0; 예제4) 테이블의 Alias를 지정한 경우는 힌트에도 Alias를 사용해야 됨 SELECT /*+ ALL_ROWS FULL(A) */ * FROM EMP A
 힌트를 중복해서 사용한 경우 SELECT /*+ ALL_ROWS INDEX_DESC(EMP PK_EMP) */ * FROM EMP WHERE EMPNO > 0; 예제4) 테이블의 Alias를 지정한 경우는 힌트에도 Alias를 사용해야 됨 SELECT /*+ ALL_ROWS FULL(A) */ * FROM EMP A")
52
3.3 H/W 단계의 튜닝 메모리 튜닝 물리적 구조 및 디스크 I/O 튜닝 자원 경합에 대한 프로세스 튜닝
한정된 메모리 자원을 효율적으로 할당하여 캐시의 성능 개선 및 메모 리에 적재된 데이터의 활용률 증대 물리적 구조 및 디스크 I/O 튜닝 BLOCK_SIZE, PCTFREE, PCTUSED 등의 파라미터 설정 자원 경합에 대한 프로세스 튜닝 BLOCK I/O, SHARED POOL, LOCK, LATCH 경합 등의 완화 H/W 시스템에 특화된 튜닝 H/W, O/S 벤더에 특화된 부분의 튜닝

53
Chapter 2. INDEX 적용 B*TREE INDEX 인덱스의 선정 인덱스를 사용하지 못하는 경우
결합 인덱스(Composite Index) 기타 인덱스
 기타 인덱스.")
54
0. HEAP TABLE 0. 1 TABLE 구조 힙 테이블의 행들은 특별한 순서 없이 저장된다.
데이터베이스 내의 모든 객체는 블록(BLOCK) 단위로 저장되고, 블록 은 디스크 I/O의 기본 단위가 된다. 데이터베이스의 블록 사이즈는 DB_BLOCK_SIZE 파라메터로 확인 가 능하다. 관리자 접속 후, 다음 명령을 실행 SHOW PARAMETER DB_BLOCK_SIZE
 단위로 저장되고, 블록 은 디스크 I/O의 기본 단위가 된다. 데이터베이스의 블록 사이즈는 DB_BLOCK_SIZE 파라메터로 확인 가 능하다. 관리자 접속 후, 다음 명령을 실행. SHOW PARAMETER DB_BLOCK_SIZE.")
55
… … 예) 다음과 같은 가정 하에 지정된 테이블이 몇 개의 블록으로 구성 될 것인 지 개략적으로 계산해보자.
행의 평균 길이 : 80바이트 행의 개수 : 천만건(10,000,000) DB_BLOCK_SIZE : 8KB 테이블의 용량 = 80바이트 X 10,000,000건 = 약 800MB 블록의 개수 = (80바이트 X 10,000,000건) / 8KB = 약 100,000개 계산의 간소화를 위해 8KB를 8000 바이트로 가정 HWM(HIGH WATER MARK) … … 첫번째 블럭 십만번번째 블럭
 DB_BLOCK_SIZE : 8KB. 테이블의 용량 = 80바이트 X 10,000,000건 = 약 800MB. 블록의 개수 = (80바이트 X 10,000,000건) / 8KB = 약 100,000개. 계산의 간소화를 위해 8KB를 8000 바이트로 가정. HWM(HIGH WATER MARK) … … 첫번째 블럭. 십만번번째 블럭.")
56
0. 2 FULL TABLE SCAN 테이블에 할당된 첫 번째 블록부터 HWM로 지정된 블록까지 읽는 방식
FULL TABLE SCAN 방식은 특별히 MULTI BLOCK I/O를 수행 MULTI BLOCK I/O는 1회의 I/O 수행 시, 여러 개의 블록을 한번에 읽음 DB_FILE_MULTIBLOCK_READ_COUNT 파라메터에서 한 번에 읽을 블록 개수를 지정(SHOW PARAMETER DB_FILE_MULTIBLOCK_READ_COUNT) HWM(HIGH WATER MARK) : 테이블에 할당된 블록 중에 한번이라도 사용된 마지막 블록을 나타냄 HWM는 DELETE 명령으로 행을 삭제해도 블록 아래로 내려가지 않고, TRUNCATE TABLE 명령으로 테이블에 할당된 저장 공간을 해제해야만 첫번째 블록으로 내려감
 HWM(HIGH WATER MARK) : 테이블에 할당된 블록 중에 한번이라도 사용된 마지막 블록을 나타냄. HWM는 DELETE 명령으로 행을 삭제해도 블록 아래로 내려가지 않고, TRUNCATE TABLE 명령으로 테이블에 할당된 저장 공간을 해제해야만 첫번째 블록으로 내려감.")
57
예) 앞의 예제에서 FULL TABLE SCAN 수행시, 발생 할 DISK I/O의 횟수는? 행의 평균 길이 : 80바이트
행의 개수 : 천만건(10,000,000) DB_BLOCK_SIZE : 8KB DB_FILE_MULTIBLOCK_READ_COUNT : 10 테이블의 용량 = 80바이트 X 10,000,000건 = 약 800MB 블록의 개수 = (80바이트 X 10,000,000건) / 8KB = 약 100,000개 I/O 횟수 = 100,000 / 10 = 10,000 회 이 파라메터 값이 클수록 FULL TABLE SCAN 비용은 낮아진다. 즉, CBO가 FULL TABLE SCAN을 선호하게 됨 Cost
 DB_BLOCK_SIZE : 8KB. DB_FILE_MULTIBLOCK_READ_COUNT : 10. 테이블의 용량 = 80바이트 X 10,000,000건 = 약 800MB. 블록의 개수 = (80바이트 X 10,000,000건) / 8KB = 약 100,000개. I/O 횟수 = 100,000 / 10 = 10,000 회. 이 파라메터 값이 클수록. FULL TABLE SCAN 비용은 낮아진다. 즉, CBO가 FULL TABLE SCAN을 선호하게 됨. Cost.")
58
1. B*TREE INDEX 1. 1 B*Tree 구조 … … … … … … … …
CREATE INDEX 사원_사번_IDX ON 사원(사번); Root Block #450 … Branch Block #400 #410 #420 #430 #440 1001 1 1011 2 1021 3 … … … … … … … Leaf Block Block#1 #2 #3 #100 #150 #160 #301 #302 #303 1001 … 1002 … 1003 … … 1011 … 1012 … 1013 … … 1021 … 1022 … 1023 … … 7369 … 7499 … 7521 … … 7654 AAADmnAAEAAAADkAAA 7698 AAADmnAAEAAAADkAAB 7782 AAADmnAAEAAAADkAAC … 7839 … 7844 … 7876 … … 9971 … 9972 … 9973 … 9974 … 9981 … 9982 … 9983 … 9984 … 9991 … 9992 … 9993 … … … … … …
; Root Block. # … Branch Block. #400. #410. #420. #430. # … … … … … … … Leaf Block. Block#1. #2. #3. #100. #150. #160. #301. #302. # … 1002 … 1003 … … 1011 … 1012 … 1013 … … 1021 … 1022 … 1023 … … 7369 … 7499 … 7521 … … 7654 AAADmnAAEAAAADkAAA AAADmnAAEAAAADkAAB AAADmnAAEAAAADkAAC. … 7839 … 7844 … 7876 … … 9971 … 9972 … 9973 … 9974 … 9981 … 9982 … 9983 … 9984 … 9991 … 9992 … 9993 … … … … … …")
59
이상적인 B*Tree 구조의 장점 모든 Leaf 블록이 같은 깊이(Depth)에 존재하기 때문에 어떤 위치에 있 는 자료를 접근하더라도 거의 동일한 시간이 걸리게 됨 빠른 자료의 조회를 위해 Key 값이 정렬되도록 유지됨 B*Tree 인덱스는 자동적으로 노드간에 균형된 상태를 유지하려고 노력 함 B*Tree의 모든 블록은 평균적으로 ¾ 정도의 자료가 입력되므로 구조 자 체의 손실이 적음 B*Tree는 어떤 특정한 값을 찾아내는 질의문에서 일정 범위를 조회하는 질의문까지 다양한 형태의 질의에 대해 최상의 성능을 유지 할 수 있도 록 함 B*Tree 구조는 테이블의 크기가 증가하더라도 수행 속도가 현저히 저하 되지 않음

60
1.2 B*Tree 인덱스의 실제 구성 … … … … … … … … … … … …
CREATE UNIQUE INDEX EMP_EMPNO_IDX ON EMP(EMPNO); SELECT * FROM EMP WHERE EMPNO=7698; #450 … #400 #410 #420 #430 #440 1001 1 1011 2 1021 3 … … … … … … … Block#1 #2 #3 #100 #150 #160 #301 #302 #303 1001 … 1002 … 1003 … … 1011 … 1012 … 1013 … … 1021 … 1022 … 1023 … … 7369 … 7499 … 7521 … … 7654 AAADmnAAEAAAADkAAA 7698 AAADmnAAEAAAADkAAB 7782 AAADmnAAEAAAADkAAC … 7839 … 7844 … 7876 … … 9971 … 9972 … 9973 … 9974 … 9981 … 9982 … 9983 … 9984 … 9991 … 9992 … 9993 … … … … … … Index Unique Scan Root -> Branch -> Leaf -> Data Block 1001 … 1002 … 1003 … … 1011 … 1012 … 1013 … … 1021 … 1022 … 1023 … … 7369 … 7499 … 7521 … … 7654 MARTIN SALESMAN 7698 BLAKE MANAGER 7782 CLARK MANAGER … 7839 … 7844 … 7876 … … 9971 … 9972 … 9973 … 9974 … 9981 … 9982 … 9983 … 9984 … 9991 … 9992 … 9993 … … … … … …
; SELECT * FROM EMP WHERE EMPNO=7698; # … #400. #410. #420. #430. # … … … … … … … Block#1. #2. #3. #100. #150. #160. #301. #302. # … 1002 … 1003 … … 1011 … 1012 … 1013 … … 1021 … 1022 … 1023 … … 7369 … 7499 … 7521 … … 7654 AAADmnAAEAAAADkAAA AAADmnAAEAAAADkAAB AAADmnAAEAAAADkAAC. … 7839 … 7844 … 7876 … … 9971 … 9972 … 9973 … 9974 … 9981 … 9982 … 9983 … 9984 … 9991 … 9992 … 9993 … … … … … … Index Unique Scan. Root -> Branch -> Leaf -> Data Block … 1002 … 1003 … … 1011 … 1012 … 1013 … … 1021 … 1022 … 1023 … … 7369 … 7499 … 7521 … … 7654 MARTIN SALESMAN BLAKE MANAGER CLARK MANAGER … 7839 … 7844 … 7876 … … 9971 … 9972 … 9973 … 9974 … 9981 … 9982 … 9983 … 9984 … 9991 … 9992 … 9993 … … … … … …")
61
… … … … … … … … … … … … SELECT * FROM EMP WHERE EMPNO>=7698;
#450 … #400 #410 #420 #430 #440 1001 1 1011 2 1021 3 … … … … … … … Index Range Scan Block#1 #2 #3 #100 #150 #160 #301 #302 #303 1001 … 1002 … 1003 … … 1011 … 1012 … 1013 … … 1021 … 1022 … 1023 … … 7369 … 7499 … 7521 … … 7654 AAADmnAAEAAAADkAAA 7698 AAADmnAAEAAAADkAAB 7782 AAADmnAAEAAAADkAAC … 7839 … 7844 … 7876 … … 9971 … 9972 … 9973 … … 9981 … 9982 … 9983 … … 9991 … 9992 … 9993 … … … … … … 1001 … 1002 … 1003 … … 1011 … 1012 … 1013 … … 1021 … 1022 … 1023 … … 7369 … 7499 … 7521 … … 7654 MARTIN SALESMAN 7698 BLAKE MANAGER 7782 CLARK MANAGER … 7839 … 7844 … 7876 … … 9971 … 9972 … 9973 … … 9981 … 9982 … 9983 … … 9991 … 9992 … 9993 … … … … … … 61

62
1.3 ROWID in ORACLE 오라클에서 사용하는 자료형 중의 하나로써, 데이터베이스 내부에 있는 행 의 저장 위치를 나타냄 물리적 ROWID는 IOT(Index Organized Table)를 제외한 일반적인 테이블, 클러스터 테이블, 테이블 파티션과 서브 파티션, 인덱스, 인덱스 인덱스 파 티션과 서브 파티션에서 행의 고유한 위치를 지정하기 위해 사용 확장형(Extended) ROWID : 8 버전부터 사용 제한형(Restricted) ROWID : 이전 버전에 사용
를 제외한 일반적인 테이블, 클러스터 테이블, 테이블 파티션과 서브 파티션, 인덱스, 인덱스 인덱스 파 티션과 서브 파티션에서 행의 고유한 위치를 지정하기 위해 사용. 확장형(Extended) ROWID : 8 버전부터 사용. 제한형(Restricted) ROWID : 이전 버전에 사용.")
63
제한형(Restricted) ROWID
확장형(Extended) ROWID 10바이트 SELECT ROWID, EMPNO, ENAME FROM EMP; 18개 문자로 구성(AAADVFAAEAAAADkAAA) 1~6자리(32비트) : 데이터 오브젝트 번호(AAADVF) 7~9자리(10비트) : 데이터 파일 번호(AAE) 10~15자리(22비트) : 데이터 블록 번호(AAAADk) 16~18자리(16비트) : 블록 내부의 행번호(AAA) 64진수 제한형(Restricted) ROWID 데이터 블록(8자리).행번호(4자리).데이터파일(4자리)
 ROWID. 10바이트. SELECT ROWID, EMPNO, ENAME FROM EMP; 18개 문자로 구성(AAADVFAAEAAAADkAAA) 1~6자리(32비트) : 데이터 오브젝트 번호(AAADVF) 7~9자리(10비트) : 데이터 파일 번호(AAE) 10~15자리(22비트) : 데이터 블록 번호(AAAADk) 16~18자리(16비트) : 블록 내부의 행번호(AAA) 64진수. 제한형(Restricted) ROWID. 데이터 블록(8자리).행번호(4자리).데이터파일(4자리)")
64
… … 예) 다음과 같은 가정하에 FULL TABLE SCAN과 INDEX SCAN의 비용을 개략적으로 비교해보자.
테이블 명 : 주문(주문번호, 상품명, 수량, 배송지, 연락처) 행의 평균 길이 : 80바이트 행의 개수 : 천만건(10,000,000) DB_BLOCK_SIZE : 8KB DB_FILE_MULTIBLOCK_READ_COUNT : 10 테이블의 용량 = 80바이트 X 10,000,000건 = 약 800MB 블록의 개수 = (80바이트 X 10,000,000건) / 8KB = 약 100,000개 조회 쿼리 SELECT * FROM 주문 WHERE 주문번호=201101; FULL TABLE SCAN 수행 시, DISK I/O 발생 횟수 = 100,000 / 10 = 10,000 회 Cost No index … … 첫번째 블럭 10만번째 블럭
 행의 평균 길이 : 80바이트. 행의 개수 : 천만건(10,000,000) DB_BLOCK_SIZE : 8KB. DB_FILE_MULTIBLOCK_READ_COUNT : 10. 테이블의 용량 = 80바이트 X 10,000,000건 = 약 800MB. 블록의 개수 = (80바이트 X 10,000,000건) / 8KB = 약 100,000개. 조회 쿼리. SELECT * FROM 주문 WHERE 주문번호=201101; FULL TABLE SCAN 수행 시, DISK I/O 발생 횟수 = 100,000 / 10 = 10,000 회. Cost. No index. … … 첫번째 블럭. 10만번째 블럭.")
65
… … … … 인덱스 생성 : CREATE INDEX IDX ON 주문(주문번호);
인덱스 엔트리 : 주문번호(6바이트라고 가정) + ROWID(10바이트) 인덱스 엔트리의 개수 : 주문번호는 행의 개수와 동일하게 10,000,000건 리프 블록의 개수 = 16 바이트 X 10,000,000건 / 8KB = 20,000개 브랜치 블록의 인덱스 엔트리 : 주문번호(6바이트) + 블록번호(2바이트라고 가정) = 8바이 트 브랜치 블록의 개수 = 8 바이트 x 20,000개(리프 블록의 개수) / 8KB = 20개 루트 블록의 인덱스 엔트리 : 주문번호(6바이트) + 블록번호(2바이트라고 가정) = 8바이트 루트 블록의 개수 = 8 바이트 X 20개(브랜치 블록의 개수) / 8KB = 1개 루트 블록(1개) 브랜치 블록(20개) … 리프 블록(20,000개) … 데이터 블록(100,000개) … …
 + ROWID(10바이트) 인덱스 엔트리의 개수 : 주문번호는 행의 개수와 동일하게 10,000,000건. 리프 블록의 개수 = 16 바이트 X 10,000,000건 / 8KB = 20,000개. 브랜치 블록의 인덱스 엔트리 : 주문번호(6바이트) + 블록번호(2바이트라고 가정) = 8바이 트. 브랜치 블록의 개수 = 8 바이트 x 20,000개(리프 블록의 개수) / 8KB = 20개. 루트 블록의 인덱스 엔트리 : 주문번호(6바이트) + 블록번호(2바이트라고 가정) = 8바이트. 루트 블록의 개수 = 8 바이트 X 20개(브랜치 블록의 개수) / 8KB = 1개. 루트 블록(1개) 브랜치 블록(20개) … 리프 블록(20,000개) … 데이터 블록(100,000개) … …")
66
… … … … INDEX SCAN은 Single Block I/O를 수행
Single Block I/O는 1회의 I/O에 Block 1개를 읽음 다음 문장 실행 시, 읽어야 할 블록의 개수 SELECT * FROM 주문 WHERE 주문번호=201101; DISK I/O 발생 횟수 : 루트 블록 1개 + 브랜치 블록 1개 + 리프 블록 1개 + 데이터 블록 1개 = 4회 Cost 루트 블록(1개) 브랜치 블록(20개) … … 리프 블록(20,000개) … … 데이터 블록(100,000개)
 브랜치 블록(20개) … … 리프 블록(20,000개) … … 데이터 블록(100,000개)")
67
… … … … 다음 문장이 1000건의 결과를 리턴한다면, 개략적인 I/O 횟수는?
SELECT * FROM 주문 WHERE 주문번호 BETWEEN AND ; 루트 블록 1개 + 브랜치 블록 1개 리프 블록 2개 : 리프 블록당 500(=8KB / 16바이트)개의 엔트리가 있으므로 2개 읽음 1000개의 엔트리를 하나씩 읽으면서 테이블의 데이터 블록에 접근하여 1000회 전체 I/O 횟수 : = 1004 회 루트 블록(1개) 브랜치 블록(20개) … … 리프 블록(20,000개) … … 데이터 블록(100,000개)
개의 엔트리가 있으므로 2개 읽음. 1000개의 엔트리를 하나씩 읽으면서 테이블의 데이터 블록에 접근하여 1000회. 전체 I/O 횟수 : = 1004 회. 루트 블록(1개) 브랜치 블록(20개) … … 리프 블록(20,000개) … … 데이터 블록(100,000개)")
68
비용(Cost) 이란? 8i 에서 비용 산출 공식 (I/O 기준)
측정된 MRTime = 20ms, SRTime = 5ms 라고 가정하면 Multi Block I/O의 비용은 4배 증가 8i 에서 비용 산출 공식 (I/O 기준) Cost = Single Block I/O 횟수 + Multi Block I/O 횟수 9i 에서 비용 산출 공식 - 시스템 통계가 없는 경우 : 8i와 동일 - 시스템 통계가 있는 경우(Cpu costing이라고 함) Cost = Single Block I/O 횟수 + Multi Block I/O 횟수 X (MRTime / SRTime) + CPU 연산횟수 / (CPU Speed * SRTime) 10g에서 비용 산출 공식 - 시스템 통계가 없는 경우, 디폴트 값 이용 - 시스템 통계가 있는 경우, 위 공식과 동일 11g에서 비용 산출 공식 - 정확하게 알려진 바는 없으나, 위의 비용에 버퍼 캐시 비용까지 고려 Multi Block Read Time Single Block Read Time
 Cost = Single Block I/O 횟수 + Multi Block I/O 횟수. 9i 에서 비용 산출 공식. - 시스템 통계가 없는 경우 : 8i와 동일. - 시스템 통계가 있는 경우(Cpu costing이라고 함) Cost = Single Block I/O 횟수. + Multi Block I/O 횟수 X (MRTime / SRTime) + CPU 연산횟수 / (CPU Speed * SRTime) 10g에서 비용 산출 공식. - 시스템 통계가 없는 경우, 디폴트 값 이용. - 시스템 통계가 있는 경우, 위 공식과 동일. 11g에서 비용 산출 공식. - 정확하게 알려진 바는 없으나, 위의 비용에 버퍼 캐시 비용까지 고려. Multi Block Read Time. Single Block Read Time.")
69
2. 인덱스의 선정 인덱스는 일반적으로 5% 이내의 테이블 자료를 액세스 할 경우 효율적이 라고 알려져 있으며, 그 이상의 테이블 자료를 액세스 할 경우에는 FTS(Full Table Scan)가 더 나은 성능을 보여줌 인덱스를 사용하면 랜덤 액세스(Single Block I/O) 발생. 랜덤 액세스 : 데이터 블록 안에 있는 원하는 ROW를 직접 읽어 들인다는 개념. 한 블록 안에는 일반적인 경우 하나 이상의 ROW가 존재하므로 읽기 를 원하는 ROW와 필요 없는 ROW가 블록 안에 섞여 같이 읽어짐. FULL TABLE SCAN : 테이블에 할당되어 있는 모든 데이터 블록을 읽어 들 이는데 한번 읽을 때 여러 블록을 읽기(Multi Block I/O) 때문에 대량의 테 이블을 읽을 경우 유리
 발생. 랜덤 액세스 : 데이터 블록 안에 있는 원하는 ROW를 직접 읽어 들인다는 개념. 한 블록 안에는 일반적인 경우 하나 이상의 ROW가 존재하므로 읽기 를 원하는 ROW와 필요 없는 ROW가 블록 안에 섞여 같이 읽어짐. FULL TABLE SCAN : 테이블에 할당되어 있는 모든 데이터 블록을 읽어 들 이는데 한번 읽을 때 여러 블록을 읽기(Multi Block I/O) 때문에 대량의 테 이블을 읽을 경우 유리.")
70
CREATE INDEX EMP_JOB_IDX ON EMP(JOB); CREATE INDEX EMP_SAL_IDX ON EMP(SAL); SELECT EMPNO, ENAME, JOB, SAL FROM EMP WHERE JOB='SALESMAN' AND SAL > 1500; 어떤 인덱스를 사용해야 하는가? EMP_JOB_IDX 3건은 버림 4회의 랜덤 액세스

71
SELECT EMPNO, ENAME, JOB, SAL FROM EMP WHERE JOB='SALESMAN' AND SAL > 1500;
어떤 인덱스를 사용해야 하는가? EMP_SAL_IDX 7건은 버림 8회의 랜덤 액세스

72
2.1 인덱스의 선정 절차 프로그램 개발에 이용된 모든 테이블에 대하여 Access Path 조사
인덱스 컬럼 선정 및 분포도 조사 Critical Access Path 결정 및 우선 순위 선정 인덱스 컬럼의 조합 및 순서 결정 시험 생성 및 테스트 결정된 인덱스를 기준으로 프로그램 반영 실제 적용

73
(1) 프로그램 개발에 이용된 모든 테이블에 대하여 접근 경로(Access Path) 조사
프로그램에 사용된 모든 질의문의 테이블을 조사하고, 해당 테이블의 경로를 다음과 같은 표를 통하여 도식화해서 표현

74
(2) 인덱스 컬럼 선정 및 분포도 조사 조사된 접근 경로 표를 기준으로 어떤 컬럼이 자주 사용되는지를 판단하고 해당 컬럼의 분포도를 조사 분포도 : 한 컬럼에 얼마나 다양한 값이 어떻게 분포되어 있는지를 나타냄 분포도가 좋은 컬럼 : 사원번호, ID, 구매요청번호, 접수번호 등 분포도가 나쁜 컬럼 : 성별(남/여)
")
75
<인덱스에 포함해야 할 컬럼과 포함하지 않을 컬럼>
WHERE 절에 자주 사용되는 컬럼 테이블 조인에 자주 사용되는 컬럼 분포도가 좋거나 유일한 컬럼 SELECT 문장의 MIN, MAX의 기준이 되거나 자주 사용되는 컬럼 포함하지 않아야 할 컬럼 분포도가 좋지 않은 컬럼 테이블의 Row 수가 적은 테이블의 컬럼 자주 수정하는 컬럼

76
(3) Critical Access Path 결정 및 우선 순위 선정
예) 하루 1000번 실행되는 쿼리의 응답 속도를 2초에서 1초로 줄이는 경우와 한달에 한번 사용되는 쿼리를 5분에서 1분으로 줄이는 경우 첫번째 예 : 1회 1초 X 1일 1000회 X 1개월 30일 = 30,000초(우선 튜닝 대상) 두번째 예 : 1회 4분(240초) X 1개월 1회 = 240초
 하루 1000번 실행되는 쿼리의 응답 속도를 2초에서 1초로 줄이는 경우와. 한달에 한번 사용되는 쿼리를 5분에서 1분으로 줄이는 경우. 첫번째 예 : 1회 1초 X 1일 1000회 X 1개월 30일 = 30,000초(우선 튜닝 대상) 두번째 예 : 1회 4분(240초) X 1개월 1회 = 240초.")
77
(4) 인덱스 컬럼의 조합 및 순서결정 분포도가 좋지 않은 컬럼을 결합하여 분포도가 개선된다면 결합 인덱스 구 성 고려
분포도가 좋은 컬럼들이 각각 인덱스로 구성되어 있고, 질의문에서 두 개의 컬럼을 사용하여 인덱스 머지가 발생하는 경우, 두 개의 컬럼을 하나로 결 합하는 결합 인덱스 구성을 고려 자주 사용되는 컬럼을 선두로 정의. 사번과 부서코드를 결합 인덱스로 구성 하는 경우, 사번의 Cardinality가 우수하지만 질의문에서 항상 부서 코드를 참조하는 경우라면 부서코드 컬럼을 선두로 정의해야 함 Equal(=) 연산자로 사용되는 컬럼을 선두로 정의. Equal 연산자로 사용되는 컬럼이 두 개 이상인 경우, 분포도가 좋은 컬럼을 선두로 정의해야 함
 연산자로 사용되는 컬럼을 선두로 정의. Equal 연산자로 사용되는 컬럼이 두 개 이상인 경우, 분포도가 좋은 컬럼을 선두로 정의해야 함.")
78
(5) 시험 생성 및 테스트 (6) 결정된 인덱스 기준으로 프로그램 반영 (7) 적용
인덱스를 생성할 각종 오브젝트의 파라미터 결정. 특히, 효율적인 저장 공 간을 할당하기 위해서는 Storage 파라미터(특히 PCTFREE)를 적절하게 결정 해야 함 인덱스 테이블스페이스는 연관 테이블이 저장된 테이블스페이스와는 분리 해야 함 (6) 결정된 인덱스 기준으로 프로그램 반영 인덱스를 공지하여 프로그램에 반영될 수 있도록 조치 (7) 적용 프로그램 수정 작업 완료 후, 일괄적으로 인덱스 생성
를 적절하게 결정 해야 함. 인덱스 테이블스페이스는 연관 테이블이 저장된 테이블스페이스와는 분리 해야 함. (6) 결정된 인덱스 기준으로 프로그램 반영. 인덱스를 공지하여 프로그램에 반영될 수 있도록 조치. (7) 적용. 프로그램 수정 작업 완료 후, 일괄적으로 인덱스 생성.")
79
2.2 인덱스의 선정 기준 분포도가 좋은 컬럼은 단독으로 생성하여 활용도 향상(5% 이내)
자주 조합되어 사용되는 컬럼의 경우에는 결합 인덱스 생성 고려 인덱스간의 역할 정의(즉, 가능한 모든 Access Path를 만족시킬 수 있는) 수정이 빈번히 일어나지 않는 컬럼을 인덱스로 사용 외래키(Foreign Key)로 사용된 컬럼에 대하여 인덱스 생성 정렬기준으로 자주 사용되는 컬럼에 대하여 인덱스 생성
 수정이 빈번히 일어나지 않는 컬럼을 인덱스로 사용. 외래키(Foreign Key)로 사용된 컬럼에 대하여 인덱스 생성. 정렬기준으로 자주 사용되는 컬럼에 대하여 인덱스 생성.")
80
2.3 인덱스의 고려 사항 인덱스가 추가된 경우, 기존 프로그램의 영향 검토
대용량의 트랜잭션이 발생하는 테이블에는 인덱스 생성 제한 분포도가 좋지 않은 컬럼에 인덱스 생성 제한 개별 컬럼의 분포도가 좋지 않지만 다른 컬럼과 결합되어 자주 사 용되고 결합시 분포도가 양호한 경우, 결합 인덱스 검토 분포도가 양호하지만 LIKE 또는 BETWEEN 조건이 자주 사용되는 경우, 질의문 작성시 주의 및 클러스터링 고려

81
2.4 인덱스의 사용 (1) 고유(Unique) 인덱스의 Equal(=) 검색
SELECT * FROM EMP WHERE EMPNO=7788; (2) 고유(Unique) 인덱스의 범위(Range) 검색 SELECT * FROM EMP WHERE EMPNO >= 7654; SELECT * FROM EMP WHERE EMPNO > 7654; SELECT * FROM EMP WHERE EMPNO <= 7654; SELECT * FROM EMP WHERE EMPNO < 7654;
 고유(Unique) 인덱스의 범위(Range) 검색. SELECT * FROM EMP WHERE EMPNO >= 7654; SELECT * FROM EMP WHERE EMPNO > 7654; SELECT * FROM EMP WHERE EMPNO <= 7654; SELECT * FROM EMP WHERE EMPNO < 7654;")
82
(3) 중복(Non-Unique) 인덱스의 범위(Range) 검색
CREATE INDEX EMP_JOB_IDX ON EMP(JOB); SELECT * FROM EMP WHERE JOB LIKE 'SALE%'; SELECT * FROM EMP WHERE JOB='SALESMAN'; DROP INDEX EMP_JOB_IDX;
; SELECT * FROM EMP WHERE JOB LIKE SALE% ; SELECT * FROM EMP WHERE JOB= SALESMAN ; DROP INDEX EMP_JOB_IDX;")
83
(4) OR & IN 조건 – 결과의 결합 SELECT * FROM EMP WHERE EMPNO IN (7654, 7788); SELECT * FROM EMP WHERE EMPNO=7654 OR EMPNO=7788; CBO RBO

84
(5) NOT BETWEEN 검색 CBO가 FTS를 선택한 이유는? SELECT * FROM EMP WHERE EMPNO NOT BETWEEN 7654 AND 7788; SELECT * FROM EMP WHERE EMPNO<7654 OR EMPNO>7788; CBO RBO

85
FTS와 비교할 때 고비용 SELECT /*+ USE_CONCAT */ * FROM EMP WHERE EMPNO NOT BETWEEN 7654 AND 7788;

86
3. 인덱스를 사용하지 못하는 경우 3.1 NOT 연산자 사용
SELECT * FROM EMP WHERE EMPNO!=7654; SELECT * FROM EMP WHERE EMPNO<>7654;

87
SELECT * FROM EMP WHERE EMPNO < 7654 OR EMPNO > 7654;
CBO 문장을 수정하여 인덱스를 사용 RBO SELECT /*+ USE_CONCAT */ * FROM EMP WHERE EMPNO < 7654 OR EMPNO > 7654; 인덱스를 경유하지만 비용은 고비용

88
3.2 IS NULL, IS NOT NULL 사용 SELECT * FROM EMP WHERE EMPNO IS NULL;

89
3.3 옵티마이저의 취사 선택 한 테이블의 여러 인덱스가 WHERE 절의 조건에 사용되는 경우
RBO : RANK를 기준으로 사용할 인덱스 선택 CBO : 통계치를 기준으로 사용할 인덱스 선택 선택되지 않은 인덱스의 WHERE 절 조건은 데이터의 체크 조건으 로 사용되고 인덱스로는 사용되지 않음 옵티마이저는 목표에 따라 인덱스를 경유하는 것보다 FTS(FULL TABLE SCAN)가 유리하다고 판단하면 인덱스를 사용하지 않음 옵티마이저 힌트 : 옵티마이저의 선택을 제어하기 위해 사용
가 유리하다고 판단하면 인덱스를 사용하지 않음. 옵티마이저 힌트 : 옵티마이저의 선택을 제어하기 위해 사용.")
90
3.4 외부적인 변형(External Suppressing)
SELECT * FROM EMP WHERE NVL(EMPNO,0)=7654;
=7654;")
91
CREATE INDEX EMP_JOB_IDX ON EMP(JOB); SELECT
CREATE INDEX EMP_JOB_IDX ON EMP(JOB); SELECT * FROM EMP WHERE RTRIM(JOB)='SALESMAN'; SELECT * FROM EMP WHERE JOB LIKE 'SALESMAN%'; DROP INDEX EMP_JOB_IDX;
; SELECT * FROM EMP WHERE RTRIM(JOB)= SALESMAN ; SELECT * FROM EMP WHERE JOB LIKE SALESMAN% ; DROP INDEX EMP_JOB_IDX;")
92
(1) SQL 작성의 오류 불필요한 함수를 사용한 경우 CREATE INDEX EMP_ENAME_IDX ON EMP(ENAME); SELECT * FROM EMP WHERE SUBSTR(ENAME, 1, 1)='M'; SELECT * FROM EMP WHERE ENAME LIKE 'M%'; DROP INDEX EMP_ENAME_IDX;
; SELECT * FROM EMP WHERE SUBSTR(ENAME, 1, 1)= M ; SELECT * FROM EMP WHERE ENAME LIKE M% ; DROP INDEX EMP_ENAME_IDX;")
93
문자열 결합 CREATE INDEX EMP_JOB_DEPTNO_IDX ON EMP(JOB, DEPTNO); SELECT
문자열 결합 CREATE INDEX EMP_JOB_DEPTNO_IDX ON EMP(JOB, DEPTNO); SELECT * FROM EMP WHERE JOB||DEPTNO='MANAGER10'; WHERE JOB='MANAGER' AND DEPTNO=10; DROP INDEX EMP_JOB_DEPTNO_IDX;
; SELECT * FROM EMP WHERE JOB||DEPTNO= MANAGER10 ; WHERE JOB= MANAGER AND DEPTNO=10; DROP INDEX EMP_JOB_DEPTNO_IDX;")
94
DATE 변수의 가공 CREATE INDEX EMP_HIREDATE_IDX ON EMP(HIREDATE); SELECT
DATE 변수의 가공 CREATE INDEX EMP_HIREDATE_IDX ON EMP(HIREDATE); SELECT * FROM EMP WHERE TO_CHAR(HIREDATE, 'RRMMDD')='801217'; WHERE HIREDATE=TO_CHAR('801217','RRMMDD'); DROP INDEX EMP_HIREDATE_IDX;
; SELECT * FROM EMP WHERE TO_CHAR(HIREDATE, RRMMDD )= ; WHERE HIREDATE=TO_CHAR( , RRMMDD ); DROP INDEX EMP_HIREDATE_IDX;")
95
산술식의 적용 CREATE INDEX EMP_SAL_IDX ON EMP(SAL); SELECT
산술식의 적용 CREATE INDEX EMP_SAL_IDX ON EMP(SAL); SELECT * FROM EMP WHERE SAL*12 > 40000; WHERE SAL > 40000/12; DROP INDEX EMP_SAL_IDX
; SELECT * FROM EMP WHERE SAL*12 > 40000; WHERE SAL > 40000/12; DROP INDEX EMP_SAL_IDX")
96
(2) 개발자의 의도에 의한 서프레싱 예 사례 1 CREATE TABLE INSA AS SELECT EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO, DECODE(ENAME, 'SCOTT', 'DD', 'AA') STATUS FROM EMP; DD : 퇴직자
 STATUS FROM EMP; DD : 퇴직자.")
97
SELECT /*+ RULE */ * FROM INSA WHERE RTRIM(STATUS)='AA';
CREATE INDEX INSA_STATUS_IDX ON INSA(STATUS); - 퇴직자 검색 SELECT /*+ RULE */ * FROM INSA WHERE STATUS='DD'; 14건 중 1건이므로 인덱스를 이용하는 것이 유리 14건 중 13건이므로 FTS를 수행하는 것이 유리 - 재직자 검색 SELECT /*+ RULE */ * FROM INSA WHERE RTRIM(STATUS)='AA';
; - 퇴직자 검색 SELECT /*+ RULE */ * FROM INSA WHERE STATUS= DD ; 14건 중 1건이므로 인덱스를. 이용하는 것이 유리. 14건 중 13건이므로 FTS를. 수행하는 것이 유리. - 재직자 검색. SELECT /*+ RULE */ * FROM INSA WHERE RTRIM(STATUS)= AA ;")
98
SELECT * FROM INSA WHERE STATUS='AA';
CBO는 어떤 선택을 할 것 인가? EXEC DBMS_STATS.GATHER_TABLE_STATS(USER, 'INSA'); - 퇴직자 검색 SELECT * FROM INSA WHERE STATUS='DD'; 인덱스를 경유 - 재직자 검색 SELECT * FROM INSA WHERE STATUS='AA'; FTS를 선택하지 않음. 테이블이 작아서 비용 차이가 없음 비용이 높아서 선택되지 않음 SELECT /*+ FULL(INSA) */ * FROM INSA WHERE STATUS='AA';
; - 퇴직자 검색 SELECT * FROM INSA WHERE STATUS= DD ; 인덱스를 경유. - 재직자 검색. SELECT * FROM INSA WHERE STATUS= AA ; FTS를 선택하지 않음. 테이블이 작아서 비용 차이가 없음. 비용이 높아서 선택되지 않음. SELECT /*+ FULL(INSA) */ * FROM INSA WHERE STATUS= AA ;")
99
STATUS 컬럼이 변형되어 인덱스 사용 불가
사례 2 CREATE INDEX INSA_EMPNO_IDX ON INSA(EMPNO); SELECT /*+ RULE */ * FROM INSA WHERE STATUS='AA' AND EMPNO = 7369; WHERE RTRIM(STATUS)='AA' AND EMPNO = 7369; INDEX MERGE 사용 STATUS 컬럼이 변형되어 인덱스 사용 불가
; SELECT /*+ RULE */ * FROM INSA WHERE STATUS= AA AND EMPNO = 7369; WHERE RTRIM(STATUS)= AA AND EMPNO = 7369; INDEX MERGE 사용. STATUS 컬럼이 변형되어 인덱스 사용 불가.")
100
INDEX MERGE 비용이 높아서 선택되지 않음
CBO의 선택은? SELECT * FROM INSA WHERE STATUS='AA' AND EMPNO = 7369; SELECT /*+ AND_EQUAL(INSA INSA_EMPNO_IDX INSA_STATUS_IDX) */ * FROM INSA EMPNO의 인덱스 사용 INDEX MERGE 비용이 높아서 선택되지 않음
 */ * FROM INSA EMPNO의 인덱스 사용. INDEX MERGE 비용이 높아서 선택되지 않음.")
101
사례 3. 조인 순서 변경 CREATE INDEX DEPT_DNAME_IDX ON DEPT(DNAME); CREATE INDEX EMP_SAL_IDX ON EMP(SAL); CREATE INDEX EMP_DEPTNO_IDX ON EMP(DEPTNO); SELECT /*+ RULE */ DNAME, ENAME FROM DEPT, EMP WHERE DEPT.DEPTNO=EMP.DEPTNO AND DNAME='ACCOUNTING' AND SAL > 2000; 우선 순위가 높음

102
SELECT /*+ RULE */ DNAME, ENAME FROM DEPT, EMP
SELECT /*+ RULE */ DNAME, ENAME FROM DEPT, EMP WHERE DEPT.DEPTNO=EMP.DEPTNO AND DNAME='ACCOUNTING' AND ROUND(SAL,0) > 2000; 컬럼 변형 SELECT /*+ RULE */ DNAME, ENAME FROM DEPT, EMP WHERE DEPT.DEPTNO=EMP.DEPTNO AND RTRIM(DNAME)='ACCOUNTING' AND SAL > 2000; 컬럼 변형
 > 2000; 컬럼 변형. SELECT /*+ RULE */ DNAME, ENAME FROM DEPT, EMP. WHERE DEPT.DEPTNO=EMP.DEPTNO. AND RTRIM(DNAME)= ACCOUNTING AND SAL > 2000; 컬럼 변형.")
103
CBO는 왜 DEPT -> EMP 순으로 조인을 했는가?
SELECT DNAME, ENAME FROM DEPT, EMP WHERE DEPT.DEPTNO=EMP.DEPTNO AND DNAME='ACCOUNTING' AND SAL > 2000; CBO는 왜 DEPT -> EMP 순으로 조인을 했는가? Table Prefetching 내부 루프를 1회 반복

104
DROP INDEX DEPT_DNAME_IDX; DROP INDEX EMP_SAL_IDX;
SELECT DNAME, ENAME FROM DEPT, EMP WHERE DEPT.DEPTNO=EMP.DEPTNO AND RTRIM(DNAME)='ACCOUNTING' AND SAL > 2000; 컬럼 변형 내부 루프를 10회 반복 DROP INDEX DEPT_DNAME_IDX; DROP INDEX EMP_SAL_IDX; DROP INDEX EMP_DEPTNO_IDX;
= ACCOUNTING AND SAL > 2000; 컬럼 변형. 내부 루프를 10회 반복. DROP INDEX DEPT_DNAME_IDX; DROP INDEX EMP_SAL_IDX; DROP INDEX EMP_DEPTNO_IDX;")
105
문자(CHAR 또는 VARCHAR2) 타입이 비교되면
3.5 내부적인 변형(Internal Suppressing) (1) 인덱스를 사용할 수 있는 내부적인 변형 NUMBER CHAR SELECT * FROM EMP WHERE EMPNO='7788'; 숫자(NUMBER) 타입과 문자(CHAR 또는 VARCHAR2) 타입이 비교되면 문자가 숫자로 암묵적 형변환 됨
 (1) 인덱스를 사용할 수 있는 내부적인 변형. NUMBER. CHAR. SELECT * FROM EMP WHERE EMPNO= 7788 ; 숫자(NUMBER) 타입과. 문자(CHAR 또는 VARCHAR2) 타입이 비교되면. 문자가 숫자로 암묵적 형변환 됨.")
106
(2) 인덱스를 사용할 수 없는 내부적인 변형 CREATE TABLE EMP2 AS SELECT TO_CHAR(EMPNO,'9999') EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO FROM EMP; CREATE INDEX EMP2_EMPNO_IDX ON EMP2(EMPNO); SELECT * FROM EMP2 WHERE EMPNO=7788; CHAR NUMBER
 EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO FROM EMP; CREATE INDEX EMP2_EMPNO_IDX ON EMP2(EMPNO); SELECT * FROM EMP2 WHERE EMPNO=7788; CHAR. NUMBER.")
107
날짜(DATE) 타입과 문자(CHAR) 타입을 비교하면
(3) 연산식(Expression Evaluation)의 유형 단순한 연산식 COMM + ‘500’ -> COMM + TO_NUMBER(‘500’) 함수에 사용 MOD(SAL, ‘1000’) -> MOD(SAL, TO_NUMBER(‘1000’)) BOOLEAN EXPRESSIONS BONUS > SAL / ‘10’ -> BONUS > SAL / TO_NUMBER(‘10’) WHERE 절 조건 WHERE HIREDATE = ‘ ’ -> WHERE HIREDATE = TO_CHAR(‘ ’, ‘YYYY-MM-DD’) 날짜(DATE) 타입과 문자(CHAR) 타입을 비교하면 문자가 날짜로 변환
 연산식(Expression Evaluation)의 유형. 단순한 연산식. COMM + ‘500’ -> COMM + TO_NUMBER(‘500’) 함수에 사용. MOD(SAL, ‘1000’) -> MOD(SAL, TO_NUMBER(‘1000’)) BOOLEAN EXPRESSIONS. BONUS > SAL / ‘10’ -> BONUS > SAL / TO_NUMBER(‘10’) WHERE 절 조건. WHERE HIREDATE = ‘ ’ -> WHERE HIREDATE = TO_CHAR(‘ ’, ‘YYYY-MM-DD’) 날짜(DATE) 타입과 문자(CHAR) 타입을 비교하면. 문자가 날짜로 변환.")
108
4. 결합 인덱스(Composite Index)
4.1 인덱스 머지(Index Merge) 개별 컬럼에 인덱스가 생성되어 있으면서, 모든 컬럼이 WHERE 절에서 Equal(=) 조건으로 사용 된 경우, 각 컬럼에 정의된 인덱스를 조합하여 자 료에 접근하는 방법 결합 인덱스(Composite Index)가 인덱스 머지보다 더 좋은 액세스 경로를 제공하지만, 인덱스를 추가할 수록 인덱스 관리 비용이 증가되므로 기존 인 덱스를 활용 할 수 있는 방법을 고려 할 필요가 있음
 개별 컬럼에 인덱스가 생성되어 있으면서, 모든 컬럼이 WHERE 절에서 Equal(=) 조건으로 사용 된 경우, 각 컬럼에 정의된 인덱스를 조합하여 자 료에 접근하는 방법. 결합 인덱스(Composite Index)가 인덱스 머지보다 더 좋은 액세스 경로를 제공하지만, 인덱스를 추가할 수록 인덱스 관리 비용이 증가되므로 기존 인 덱스를 활용 할 수 있는 방법을 고려 할 필요가 있음.")
109
CREATE INDEX EMP_JOB_IDX ON EMP(JOB); CREATE INDEX EMP_DEPTNO_IDX ON EMP(DEPTNO); SELECT /*+ AND_EQUAL(EMP EMP_JOB_IDX EMP_DEPTNO_IDX) */ * FROM EMP WHERE JOB='SALESMAN' AND DEPTNO=30; DROP INDEX EMP_JOB_IDX; DROP INDEX EMP_DEPTNO_IDX; Index Merge

110
EMP_JOB_IDX 인덱스에서 JOB=‘SALESMAN’인 인덱스 엔트리를 찾고, EMP_DEPTNO_IDX 인덱스에서 DEPTNO=30인 인덱스 엔트리를 검색한다.
각 인덱스 엔트리의 ROWID를 비교하여 일치하면, 해당 ROWID를 이용하여 테이 블의 행을 찾아 리턴한다. 각 인덱스에서 다음 인덱스 엔트리로 이동한다. 각 인덱스 엔트리의 ROWID를 비교하여 일치하지 않으면, ROWID가 작은 인덱스 쪽의 다음 인덱스 엔트리로 이동하여 ROWID를 다시 비교한다. 이 작업을 WHERE 절의 조건이 만족하는 모든 인덱스 엔트리에 대하여 반복한다.

111
4.2 결합 인덱스 (Composite Index)
한 테이블의 여러 컬럼을 조합하여 인덱스를 생성 결합 인덱스에 사용되는 컬럼은 테이블에 생성되어 있는 컬럼 의 순서와 무관 결합 인덱스에는 32개 컬럼을 포함 할 수 있으며, 비트맵 구조 를 사용하는 경우 30개 컬럼을 포함 할 수 있음

112
CREATE INDEX EMP_JOB_DEPTNO_IDX ON EMP(JOB, DEPTNO); SELECT
CREATE INDEX EMP_JOB_DEPTNO_IDX ON EMP(JOB, DEPTNO); SELECT * FROM EMP WHERE JOB='SALESMAN' AND DEPTNO=30; DROP INDEX EMP_JOB_DEPTNO_IDX;
; SELECT * FROM EMP WHERE JOB= SALESMAN AND DEPTNO=30; DROP INDEX EMP_JOB_DEPTNO_IDX;")
113
(1) 인덱스 머지와 결합 인덱스의 비교 결합 인덱스의 비용이 저렴
 인덱스 머지와 결합 인덱스의 비교 결합 인덱스의 비용이 저렴")
114
(2) 결합 인덱스의 사용 1. 결합 인덱스 컬럼의 선택
WHERE 절에서 AND 조건으로 자주 결합되어 사용되며, 각 컬럼의 분포도 보다 두 개 이상의 컬럼이 결합되었을 때 분포도가 양호해 지는 컬럼들의 조합 다른 테이블과 조인의 연결고리로 자주 사용되는 컬럼들 하나 이상의 키 컬럼 조건으로 같은 집합의 컬럼들이 자주 조회되 는 경우, 이러한 컬럼을 모두 포함한 인덱스 구성 가능

115
2. 결합 인덱스 생성 3. 결합 인덱스의 사용 4. 결합 인덱스의 미사용
CREATE INDEX EMP_PAY_X1 ON EMP_PAY(급여년월, 급여코드, 사원번호); 3. 결합 인덱스의 사용 WHERE 급여년월 = ‘200210’ WHERE 급여년월 = ‘200210’ AND 급여코드 = ‘정기급여’ WHERE 급여년월 = ‘200210’ AND 급여코드 = ‘정기급여’ AND 사원번호 = ‘ ’ 4. 결합 인덱스의 미사용 WHERE 급여코드 = ‘정기급여’ WHERE 사원번호 = ‘ ’ WHERE 사원번호 = ‘ ’ AND 급여코드 = ‘정기급여’
; 3. 결합 인덱스의 사용. WHERE 급여년월 = ‘200210’ WHERE 급여년월 = ‘200210’ AND 급여코드 = ‘정기급여’ WHERE 급여년월 = ‘200210’ AND 급여코드 = ‘정기급여’ AND 사원번호 = ‘ ’ 4. 결합 인덱스의 미사용. WHERE 급여코드 = ‘정기급여’ WHERE 사원번호 = ‘ ’ WHERE 사원번호 = ‘ ’ AND 급여코드 = ‘정기급여’")
116
예) 다음 문장이 인덱스를 사용 할 수 있는지 확인해보자
CREATE INDEX EMP_DEPTNO_JOB_SAL_IDX ON EMP(DEPTNO, JOB, SAL); SELECT * FROM EMP WHERE DEPTNO=30 AND JOB='SALESMAN' AND SAL=3000; SELECT * FROM EMP WHERE DEPTNO=30; SELECT * FROM EMP WHERE JOB='SALESMAN'; SELECT * FROM EMP WHERE SAL=3000; SELECT * FROM EMP WHERE DEPTNO=30 AND SAL=3000; SELECT /*+ INDEX_SS(EMP EMP_DEPTNO_JOB_SAL_IDX) */ * FROM EMP WHERE JOB='SALESMAN'; DROP INDEX EMP_DEPTNO_JOB_SAL_IDX; Index Skip Scan : 결합 인덱스의 선두 컬럼이 조건절에 포함되지 않아도 인덱스를 사용하는 연산
; SELECT * FROM EMP WHERE DEPTNO=30 AND JOB= SALESMAN AND SAL=3000; SELECT * FROM EMP WHERE DEPTNO=30; SELECT * FROM EMP WHERE JOB= SALESMAN ; SELECT * FROM EMP WHERE SAL=3000; SELECT * FROM EMP WHERE DEPTNO=30 AND SAL=3000; SELECT /*+ INDEX_SS(EMP EMP_DEPTNO_JOB_SAL_IDX) */ * FROM EMP WHERE JOB= SALESMAN ; DROP INDEX EMP_DEPTNO_JOB_SAL_IDX; Index Skip Scan. : 결합 인덱스의 선두 컬럼이 조건절에 포함되지 않아도 인덱스를 사용하는 연산.")
117
5. 결합 인덱스의 범위 검색 사용 WHERE 급여년월 LIKE ‘2002%’ AND 급여코드 = ‘정기급여’
결합 인덱스의 첫번째 컬럼인 급여년월의 조건이 Equal(=)이 아닌 범위 연산자인 LIKE ‘2002%’ 조건을 사용했으므로, 인덱스의 두번째 컬럼인 급여코드에 대한 조건을 인덱스에서 찾기가 어려워짐 결합 인덱스는 각 컬럼별로 정렬되어 있지 않고, 첫 번째, 두 번째, 세 번째 컬럼이 결 합되어 정렬되어 있기 때문 위 조건에서 급여코드에 대한 조건은 인덱스를 찾아가는 검색 조건이 아닌 인덱스 값 이 조건에 맞는지 여부를 검증하는 체크 조건이 됨 WHERE 급여년월 = ‘200210’ AND 사원번호 = ‘ ’ 첫 번째 조건은 인덱스의 첫 번째 컬럼이므로 검색 조건이 되며, 두 번째 조건은 인덱 스의 세 번째 조건이므로 체크 조건이 됨
이 아닌 범위 연산자인 LIKE ‘2002%’ 조건을 사용했으므로, 인덱스의 두번째 컬럼인 급여코드에 대한 조건을 인덱스에서 찾기가 어려워짐. 결합 인덱스는 각 컬럼별로 정렬되어 있지 않고, 첫 번째, 두 번째, 세 번째 컬럼이 결 합되어 정렬되어 있기 때문. 위 조건에서 급여코드에 대한 조건은 인덱스를 찾아가는 검색 조건이 아닌 인덱스 값 이 조건에 맞는지 여부를 검증하는 체크 조건이 됨. WHERE 급여년월 = ‘200210’ AND 사원번호 = ‘ ’ 첫 번째 조건은 인덱스의 첫 번째 컬럼이므로 검색 조건이 되며, 두 번째 조건은 인덱 스의 세 번째 조건이므로 체크 조건이 됨.")
118
(3) 결합 인덱스 결합 순서 Access Path 조건에 많이 사용되어지는 컬럼을 우선 ‘=’로 사용되는 컬럼을 우선
분포도가 좋은 컬럼을 우선 자주 이용되는 Sort의 순서로 결정

119
예1) Equal(=) 조건의 컬럼을 선두에 배치 CREATE INDEX EMP_JOB_DEPTNO_IDX ON EMP(JOB, DEPTNO); SELECT * FROM EMP WHERE JOB='MANAGER‘ AND DEPTNO>=20;
 Equal(=) 조건의 컬럼을 선두에 배치 CREATE INDEX EMP_JOB_DEPTNO_IDX ON EMP(JOB, DEPTNO); SELECT * FROM EMP WHERE JOB= MANAGER‘ AND DEPTNO>=20;")
120
예2) Non-equal 조건의 컬럼을 선두에 배치 CREATE INDEX EMP_DEPTNO_JOB_IDX ON EMP(DEPTNO, JOB); SELECT * FROM EMP WHERE DEPTNO>=20 JOB='MANAGER'; JOB 컬럼의 조건은 인덱스 액세스 범위를 줄여주지 못함 JOB=‘MANAGER’가 아닌 인덱스를 읽고 버림 테이블로의 Random Access는 최소화

121
예3) Equal(=) 조건의 컬럼을 선두에 배치 CREATE INDEX EMP_DEPTNO_SAL_JOB_IDX ON EMP(DEPTNO, SAL, JOB); SELECT * FROM EMP WHERE DEPTNO=20;
 Equal(=) 조건의 컬럼을 선두에 배치 CREATE INDEX EMP_DEPTNO_SAL_JOB_IDX ON EMP(DEPTNO, SAL, JOB); SELECT * FROM EMP WHERE DEPTNO=20;")
122
예4) None-qual(=) 조건의 컬럼을 중간 컬럼에 배치 CREATE INDEX EMP_DEPTNO_SAL_JOB_IDX ON EMP(DEPTNO, SAL, JOB); SELECT * FROM EMP WHERE DEPTNO=20 AND SAL>1000 AND JOB='ANAYST'; JOB 컬럼의 조건은 인덱스 액세스 범위를 줄여주지 못함 JOB=‘ANALYST’가 아닌 인덱스를 읽고 버림 테이블로의 Random Access는 최소화

123
예5) 인덱스의 일부 컬럼이 조건에서 누락 CREATE INDEX EMP_DEPTNO_SAL_JOB_IDX ON EMP(DEPTNO, SAL, JOB); SELECT * FROM EMP WHERE DEPTNO=20 AND JOB='MANAGER'; JOB 컬럼의 조건은 인덱스 액세스 범위를 줄여주지 못함 JOB=‘MANAGER’가 아닌 인덱스를 읽고 버림 테이블로의 Random Access는 최소화

124
실습) 다음과 같은 테이블을 생성하고, 각 문장에 대한 비용을 확인하시오
실습) 다음과 같은 테이블을 생성하고, 각 문장에 대한 비용을 확인하시오. CREATE TABLE T1 AS SELECT LEVEL C1, TRUNC(DBMS_RANDOM.VALUE(0, 1000)) C2, TRUNC(DBMS_RANDOM.VALUE(0, 1000)) C3, TRUNC(DBMS_RANDOM.VALUE(0, 1000)) C4, TRUNC(DBMS_RANDOM.VALUE(0, 1000)) C5, DBMS_RANDOM.STRING('U', 100) C6 FROM DUAL CONNECT BY LEVEL <= ; EXEC DBMS_STATS.GATHER_TABLE_STATS(USER, 'T1'); 다음 페이지에 계속
 다음과 같은 테이블을 생성하고, 각 문장에 대한 비용을 확인하시오. CREATE TABLE T1 AS SELECT LEVEL C1, TRUNC(DBMS_RANDOM.VALUE(0, 1000)) C2, TRUNC(DBMS_RANDOM.VALUE(0, 1000)) C3, TRUNC(DBMS_RANDOM.VALUE(0, 1000)) C4, TRUNC(DBMS_RANDOM.VALUE(0, 1000)) C5, DBMS_RANDOM.STRING( U , 100) C6 FROM DUAL CONNECT BY LEVEL <= ; EXEC DBMS_STATS.GATHER_TABLE_STATS(USER, T1 ); 다음 페이지에 계속")
125
SELECT * FROM T1 WHERE C1=1; CREATE INDEX T1_C1_IDX ON T1(C1); DROP INDEX T1_C1_IDX; SELECT * FROM T1 WHERE C2=1 AND C3=1; CREATE INDEX T1_C2_IDX ON T1(C2); DROP INDEX T1_C2_IDX; CREATE INDEX T1_C2_C3_IDX ON T1(C2, C3); DROP INDEX T1_C2_C3_IDX; 다음 페이지에 계속 FULL TABLE SCAN INDEX SCAN FULL TABLE SCAN C2 컬럼의 인덱스를 사용하여 테이블에 접근하지만, 읽고 버리는 행이 많다. C2 + C3 컬럼의 결합 인덱스를 사용하여 접근하므로, 테이블에서 읽고 버리는 행이 없다.

126
CREATE INDEX T1_IDX ON T1(C2, C3, C4); SELECT
CREATE INDEX T1_IDX ON T1(C2, C3, C4); SELECT * FROM T1 WHERE C2=1; SELECT * FROM T1 WHERE C3=1; SELECT * FROM T1 WHERE C4=1; SELECT * FROM T1 WHERE C2=1 AND C3>=990; SELECT * FROM T1 WHERE C2>=990 AND C3=1; SELECT * FROM T1 WHERE C2=1 AND C3=1 AND C4>=990; SELECT * FROM T1 WHERE C2=1 AND C3>=990 AND C4=1; SELECT * FROM T1 WHERE C2=1 AND C3=1; SELECT * FROM T1 WHERE C2=1 AND C4=1; SELECT * FROM T1 WHERE C2=1 AND C5=1; DROP INDEX T1_IDX; 결합 인덱스의 선두 컬럼이 WHERE 절에 기술되어야 한다. 부등호 조건 뒤의 조건들은 액세스 범위를 줄이는데 기여하지 못한다. 결합 인덱스의 중간 컬럼이 WHERE 절에서 누락되면, 뒤의 조건들은 액세스 범위를 줄이는데 기여하지 못한다.
; SELECT * FROM T1 WHERE C2=1; SELECT * FROM T1 WHERE C3=1; SELECT * FROM T1 WHERE C4=1; SELECT * FROM T1 WHERE C2=1 AND C3>=990; SELECT * FROM T1 WHERE C2>=990 AND C3=1; SELECT * FROM T1 WHERE C2=1 AND C3=1 AND C4>=990; SELECT * FROM T1 WHERE C2=1 AND C3>=990 AND C4=1; SELECT * FROM T1 WHERE C2=1 AND C3=1; SELECT * FROM T1 WHERE C2=1 AND C4=1; SELECT * FROM T1 WHERE C2=1 AND C5=1; DROP INDEX T1_IDX; 결합 인덱스의 선두 컬럼이 WHERE 절에 기술되어야 한다. 부등호 조건 뒤의 조건들은 액세스 범위를 줄이는데 기여하지 못한다. 결합 인덱스의 중간 컬럼이 WHERE 절에서 누락되면, 뒤의 조건들은 액세스 범위를 줄이는데 기여하지 못한다.")
127
4.3 인덱스 매칭률 RBO에서 하나의 테이블에 두 개 이상의 인덱스가 존재 할 경우 실행계획에 사용될 인덱스의 선택 기준
인덱스 매칭률을 고려해야 하는 경우 테이블에 두 개 이상의 인덱스가 존재하고, 그 인덱스에 해당되는 조건을 질의문의 WHERE 절에 사용하는 경우 하나 이상의 인덱스가 존재하는 테이블에 또 다른 신규 인덱스를 생성하는 경우 기존의 인덱스에 하나 이상의 컬럼을 추가로 삽입 할 경우

128
(1) 옵티마이저의 선택 기준 SALES 테이블에 다음과 같은 인덱스가 정의 되어 있다고 가정
IX1_SALES : 부서 + 기준일자 IX2_SALES : 품목 인덱스를 다음과 같이 변경 IX1_SALES : 부서 + 기준일자 + 순번(추가) 아래 문장이 사용 할 인덱스는 ? SELECT * FROM SALES WHERE 부서 = ‘843’ AND 기준일자 = ‘970518’ AND 품목 = ‘B023’;
 아래 문장이 사용 할 인덱스는 SELECT * FROM SALES WHERE 부서 = ‘843’ AND 기준일자 = ‘970518’ AND 품목 = ‘B023’;")
129
인덱스 매칭률 = Equal(=) 조건으로 사용되는 WHERE 절의 컬럼 중에서 메칭률이 높은 것을 선택 - 인덱스 변경 전 인덱스 매칭률 IX1_SALES : (부서 + 기준일자) / (부서 + 기준일자) = 2 / 2 = 100% IX2_SALES : 품목 / 품목 = 1 / 1 = 100% - 인덱스 변경 후 인덱스 매칭률 IX1_SALES : (부서 + 기준일자) / (부서 + 기준일자 + 순번) = 2 / 3 = 66% 질의문에서 Equal(=) 조건으로 사용된 인덱스 컬럼 개수 인덱스를 구성하는 컬럼 개수
 / (부서 + 기준일자 + 순번) = 2 / 3 = 66% 질의문에서 Equal(=) 조건으로 사용된 인덱스 컬럼 개수. 인덱스를 구성하는 컬럼 개수.")
130
인덱스 컬럼의 매칭률이 같을 경우에는 인덱스에 사용된 컬럼 수가 많 은 것을 선택
인덱스 매칭률을 계산할 때 선행하는 컬럼(첫번째 컬럼 포함) 순서로 연 속된 경우만을 인정. 최초로 등장하는 부등호 조건까지 해당. 예의 WHERE 절 조건에서 선행 컬럼인 부서에 대한 조건이 없다면 후행 컬 럼에 Equal(=)이 있더라도 0%가 됨 WHERE 기준일자 = ‘970518’ AND 품목 = ‘B023’ 의 경우, 인덱스 IX1_SALES의 매칭률은 기준일자 조건이 있더라도 0% 임 인덱스 컬럼의 매칭률이 같을 경우에는 인덱스에 사용된 컬럼 수가 많 은 것을 선택 인덱스 변경 전, IX1_SALES와 IX2_SALES의 매칭률은 100%로 동일하지만 IX1_SALES가 선택 인덱스 컬럼의 매칭률과 인덱스에 사용된 컬럼 수가 같을 경우에는 최 근에 생성된 것을 선택
 순서로 연 속된 경우만을 인정. 최초로 등장하는 부등호 조건까지 해당. 예의 WHERE 절 조건에서 선행 컬럼인 부서에 대한 조건이 없다면 후행 컬 럼에 Equal(=)이 있더라도 0%가 됨. WHERE 기준일자 = ‘970518’ AND 품목 = ‘B023’ 의 경우, 인덱스 IX1_SALES의 매칭률은 기준일자 조건이 있더라도 0% 임. 인덱스 컬럼의 매칭률이 같을 경우에는 인덱스에 사용된 컬럼 수가 많 은 것을 선택. 인덱스 변경 전, IX1_SALES와 IX2_SALES의 매칭률은 100%로 동일하지만 IX1_SALES가 선택. 인덱스 컬럼의 매칭률과 인덱스에 사용된 컬럼 수가 같을 경우에는 최 근에 생성된 것을 선택.")
131
Quiz) 인덱스의 구성이 다음과 같다. CREATE INDEX EMP_DEPTNO_JOB_SAL_IDX ON EMP(DEPTNO, JOB, SAL); 아래 문장의 인덱스 매칭률을 계산하시오. SELECT * FROM EMP WHERE DEPTNO=20 AND JOB='ANALYST'; SELECT * FROM EMP WHERE DEPTNO>=20 AND JOB='MANAGER'; SELECT * FROM EMP WHERE DEPTNO=20 AND SAL <= 2000; SELECT * FROM EMP WHERE JOB='MANAGER'; SELECT * FROM EMP WHERE JOB='MANAGER' AND SAL=3000; 2/3 1/3 1/3 0/3 0/3

132
매칭률이 모두 100%이지만 두 개의 컬럼으로 구성된 인덱스 선택
예제) CREATE INDEX EMP_JOB_DEPTNO_IDX ON EMP(JOB, DEPTNO); CREATE INDEX EMP_JOB_IDX ON EMP(JOB); SELECT /*+ RULE */ * FROM EMP WHERE JOB='SALESMAN' AND DEPTNO=30; 인덱스 매칭률 : 100% 인덱스 매칭률 : 100% 매칭률이 모두 100%이지만 두 개의 컬럼으로 구성된 인덱스 선택
 CREATE INDEX EMP_JOB_DEPTNO_IDX ON EMP(JOB, DEPTNO); CREATE INDEX EMP_JOB_IDX ON EMP(JOB); SELECT /*+ RULE */ * FROM EMP WHERE JOB= SALESMAN AND DEPTNO=30; 인덱스 매칭률 : 100% 인덱스 매칭률 : 100% 매칭률이 모두 100%이지만 두 개의 컬럼으로 구성된 인덱스 선택.")
133
SELECT * FROM EMP WHERE JOB='SALESMAN' AND DEPTNO=30;
CBO는 최종 비용을 고려한다.

134
DROP INDEX EMP_JOB_DEPTNO_IDX; CREATE INDEX EMP_JOB_DEPTNO_HIREDATE_IDX ON EMP(JOB, DEPTNO, HIREDATE); SELECT /*+ RULE */ * FROM EMP WHERE JOB='SALESMAN' AND DEPTNO=30; DROP INDEX EMP_JOB_DEPTNO_HIREDATE_IDX; DROP INDEX EMP_JOB_IDX; 인덱스 매칭률 : 67% 매칭률이 높은 인덱스 선택

135
SELECT. FROM EMP WHERE JOB='SALESMAN' AND DEPTNO=30; SELECT /
SELECT * FROM EMP WHERE JOB='SALESMAN' AND DEPTNO=30; SELECT /*+ INDEX(EMP EMP_JOB_IDX) */ * FROM EMP CBO는 다른 선택 ? 테이블로의 랜덤 액세스 1번 테이블로의 랜덤 액세스 4번
 */ * FROM EMP CBO는 다른 선택 테이블로의 랜덤 액세스 1번. 테이블로의 랜덤 액세스 4번.")
136
예제) 사원 테이블은 다음과 같이 정의되었다. 인덱스는 없음
예제) 사원 테이블은 다음과 같이 정의되었다. 인덱스는 없음. 사원(사번, 이름, 급여, 직급, 성별, 거주지, 소속부서) 사원 테이블을 검색하는 쿼리는 다음과 같다. 아래 문장이 최소의 비용으로 결 과 집합을 리턴 할 수 있도록 인덱스를 설계하시오. 단, 사원 테이블은 트랜잭션 이 과도하므로 인덱스의 개수를 최소화하여야 한다. SELECT * FROM 사원 WHERE 사번= ; SELECT * FROM 사원 WHERE 소속부서=‘총무과’ AND 직급>=4; SELECT * FROM 사원 WHERE 직급=6 AND 급여 > ; SELECT * FROM 사원 WHERE 소속부서=‘인사과’ AND 성별=‘여’ AND 직급>=6; SELECT * FROM 사원 WHERE 소속부서=‘감사팀’ AND 이름 LIKE ‘김%’;
 사원 테이블은 다음과 같이 정의되었다. 인덱스는 없음. 사원(사번, 이름, 급여, 직급, 성별, 거주지, 소속부서) 사원 테이블을 검색하는 쿼리는 다음과 같다. 아래 문장이 최소의 비용으로 결 과 집합을 리턴 할 수 있도록 인덱스를 설계하시오. 단, 사원 테이블은 트랜잭션 이 과도하므로 인덱스의 개수를 최소화하여야 한다. SELECT * FROM 사원 WHERE 사번= ; SELECT * FROM 사원 WHERE 소속부서=‘총무과’ AND 직급>=4; SELECT * FROM 사원 WHERE 직급=6 AND 급여 > ; SELECT * FROM 사원 WHERE 소속부서=‘인사과’ AND 성별=‘여’ AND 직급>=6; SELECT * FROM 사원 WHERE 소속부서=‘감사팀’ AND 이름 LIKE ‘김%’;")
137
5. 기타 인덱스 5.1 함수 기준 인덱스(Function Based Index)
인덱스로 사용되는 컬럼의 변환된 모습이나 연산식의 결과 값을 인덱스에 저장한 것 함수 기준 인덱스는 옵티마이저 모드 중 비용 기준(Cost Based) 모드에서만 사용가능
 모드에서만 사용가능.")
138
(1) FBI의 사용 주로 특정 컬럼에 대하여 대소문자를 구분하지 않는 검색(Case Insensitive Search)에서 자주 사용 CREATE INDEX UPPER_CASE_IDX ON EMP(UPPER(ENAME)); 또는 CREATE INDEX LOWER_CASE_IDX ON EMP(LOWER(ENAME)); SELECT * FROM EMP WHERE LOWER(ENAME)='scott'; 인덱스 사용
); SELECT * FROM EMP WHERE LOWER(ENAME)= scott ; 인덱스 사용.")
139
CREATE INDEX EMP_SAL12_IDX ON EMP(SAL*12);
옵티마이저는 질의문 내의 조건식에 대하여 Parsing을 수행하여 함수 기 준 인덱스의 연산식에 대한 Tree 구조와 비교함. 이러한 비교는 대소문자 를 구분하지 않으며, 연산자 간의 공백은 함수 기준 인덱스 사용에 영향 을 주지 않음 CREATE INDEX EMP_SAL12_IDX ON EMP(SAL*12); SELECT * FROM EMP WHERE SAL * 12 = 30000; 인덱스 사용
; SELECT * FROM EMP. WHERE SAL * 12 = 30000; 인덱스 사용.")
140
5.1 Cluster Index 클러스터 : 클러스터 키라고 부르는 공통된 컬럼을 기준으 로 하나 이상의 테이블 데이터를 동일한 데이터 블록에 모 아서 저장 클러스터의 종류 인덱스 클러스터 : 클러스터 키에 인덱스를 정의 해시 클러스터 : 클러스터 키에 해시 함수 적용

141
힙 테이블과 B-트리 인덱스 SELECT EMPNO, ENAME, JOB, SAL, DEPTNO FROM EMP
검색된 인덱스 엔트리 당 1회의 블록 액세스 발생 SELECT EMPNO, ENAME, JOB, SAL, DEPTNO FROM EMP WHERE DEPTNO = 10;

142
CREATE CLUSTER DEPT_NO(DEPTNO NUMBER(4));
인덱스 클러스터 생성 CREATE CLUSTER DEPT_NO(DEPTNO NUMBER(4)); CREATE INDEX DEPT_NO_IDX ON CLUSTER DEPT_NO; CREATE TABLE C_EMP (EMPNO NUMBER(4) CONSTRAINT EMP_EMPNO_PK PRIMARY KEY, ENAME VARCHAR2(20), JOB VARCHAR2(20), SAL NUMBER(4), DEPTNO NUMBER(4)) CLUSTER DEPT_NO(DEPTNO); INSERT INTO C_EMP SELECT EMPNO, ENAME, JOB, SAL, DEPTNO FROM EMP; 클러스터 인덱스 생성 인덱스 클러스터에 테이블 생성
); CREATE INDEX DEPT_NO_IDX ON CLUSTER DEPT_NO; CREATE TABLE C_EMP. (EMPNO NUMBER(4) CONSTRAINT EMP_EMPNO_PK PRIMARY KEY, ENAME VARCHAR2(20), JOB VARCHAR2(20), SAL NUMBER(4), DEPTNO NUMBER(4)) CLUSTER DEPT_NO(DEPTNO); INSERT INTO C_EMP. SELECT EMPNO, ENAME, JOB, SAL, DEPTNO FROM EMP; 클러스터 인덱스 생성. 인덱스 클러스터에 테이블 생성.")
143
인덱스 클러스터와 클러스터 인덱스의 구조 SELECT EMPNO, ENAME, JOB, SAL, DEPTNO
BLOCK # 215 BLOCK # 216 검색된 인덱스 엔트리 당 1회의 블록 액세스 발생 BLOCK # 217 SELECT EMPNO, ENAME, JOB, SAL, DEPTNO FROM C_EMP WHERE DEPTNO = 10; BLOCK # 218

144
SELECT EMPNO, ENAME, JOB, SAL, DEPTNO FROM C_EMP WHERE DEPTNO = 10;

145
클러스터 인덱스(Cluster Index)
일반 인덱스와 클러스터 인덱스의 비교 일반 인덱스(Regular Index) 클러스터 인덱스(Cluster Index) NULL 저장하지 않음 NULL 저장 KEY – Rowid 저장 KEY – 1st Data Block 주소 저장 Rowid를 통한 ROW 액세스 KEY에 대한 데이터 Block 액세스 ROW 별로 독립적인 엔트리 클러스터 키당 하나의 엔트리 생성은 선택적임 클러스터 사용을 위한 필수
 클러스터 인덱스(Cluster Index) NULL 저장하지 않음. NULL 저장. KEY – Rowid 저장. KEY – 1st Data Block 주소 저장. Rowid를 통한 ROW 액세스. KEY에 대한 데이터 Block 액세스. ROW 별로 독립적인 엔트리. 클러스터 키당 하나의 엔트리. 생성은 선택적임. 클러스터 사용을 위한 필수.")
146
Chapter 3. JOIN의 이해 NESTED LOOP JOIN DRIVING TABLE SORT MERGE JOIN
HASH JOIN JOIN 비교 SET OPERATOR SUBQUERY SCALAR SUBQUERY TOP-N QUERY VIEW INLINE VIEW STANDARD SQL

147
1. NESTED LOOP JOIN 1.1 NESTED LOOP 조인의 개념
두 개 이상의 테이블에서, 하나의 테이블을 기준으로 순차적으로 상대방 테이블의 행을 결합하여 원하는 결과를 추출하는 테이블 연결 방식 - Driving 테이블(Outer 테이블) : 기준 테이블 - Drived 테이블(Inner 테이블) : 기준 테이블과 결합되는 테이블
 : 기준 테이블 - Drived 테이블(Inner 테이블) : 기준 테이블과 결합되는 테이블")
148
1.2 NESTED LOOP 조인의 절차 다음 문장이 NL 조인이 수행될 때, 실행계획은? SELECT /*+ USE_NL(dept emp) */ empno, ename, dname FROM dept, emp WHERE dept.deptno=emp.deptno AND job='MANAGER';
 */ empno, ename, dname FROM dept, emp WHERE dept.deptno=emp.deptno AND job= MANAGER ;")
149
EMP DEPT PK_DEPT JOB=‘MANAGER’ 조건을 만족하지 않으면 다음 행으로…
DEPT.DEPTNO=EMP.DEPTNO인 행의 ROWID를 인덱스에서 검색

150
다음 문장이 NL 조인이 수행될 때, 실행계획은. SELECT /. + USE_NL(dept emp) ORDERED
다음 문장이 NL 조인이 수행될 때, 실행계획은? SELECT /*+ USE_NL(dept emp) ORDERED */ empno, ename, dname FROM dept, emp WHERE dept.deptno=emp.deptno AND job='MANAGER';
 ORDERED */ empno, ename, dname FROM dept, emp WHERE dept.deptno=emp.deptno AND job= MANAGER ;")
151
JOB=‘MANAGER’ AND EMP.DEPTNO=DEPT.DEPTNO 조건을
만족하지 않으면 다음 행으로 DEPT EMP DEPT 테이블에서 1건을 읽음 DEPT 테이블의 모든 행에 대해서 반복

152
1.3 NESTED LOOP 조인의 예 다음 문장이 NL 조인이 수행될 때, 실행계획은? SELECT /*+ USE_NL(a b) */ a.empno, a.job, b.deptno, b.dname FROM emp a, dept b WHERE a.deptno=b.deptno AND a.hiredate>=TO_DATE(' ', 'YYYYMMDD' ); 인덱스가 없는 테이블이 driving PK_DEPT 인덱스 존재
 */ a.empno, a.job, b.deptno, b.dname FROM emp a, dept b WHERE a.deptno=b.deptno AND a.hiredate>=TO_DATE( , YYYYMMDD ); 인덱스가 없는 테이블이 driving. PK_DEPT 인덱스 존재.")
153
1.4 NESTED LOOP 조인의 장단점 Nested Loop 조인은 데이터를 랜덤 액세스에 의해 접근하기 때문 에 그 결과 집합이 많다면 수행속도가 저하된다. Driving 테이블은 크기가 작거나, WHERE 조건을 사용하여 적절히 결과 집합을 제한 할 수 있어야 한다. Drived 테이블에는 조인을 위한 적절한 인덱스가 생성되어 있어야 한다. 연결고리가 되는 컬럼은 사원번호, 주문번호와 같이 고유한 속성을 가진 컬럼의 인덱스를 이용하거나, 분포도가 좋은 컬럼의 인덱스를 이용 할 수록 수행 속도는 좋아진다.

154
선행 테이블에서 리턴되는 행의 개수를 줄여야 한다.
Nested Loops의 비용을 줄이는 방법은? DRIVED 테이블의 액세스 조건 DRIVED 테이블의 필터 조건 DRIVING 테이블의 액세스 조건 선행 테이블에서 리턴되는 행의 개수를 줄여야 한다. 조인 횟수를 줄여야 한다. 읽고 버리는 행이 많다.

155
Nested Loops의 비용을 줄이는 방법은?
DRIVING 테이블의 액세스 조건 DRIVED 테이블의 액세스 조건 DRIVED 테이블의 필터 조건 DRIVED 테이블의 필터 조건 -> 나쁜 선택도를 가져야 함(높은 선택도) DRIVING 테이블의 액세스 조건 -> 좋은 선택도를 가져야 함(낮은 선택도)
 DRIVING 테이블의 액세스 조건. -> 좋은 선택도를 가져야 함(낮은 선택도)")
156
1.5 NESTED LOOP 조인 파라미터 OPTIMIZER_INDEX_CACHING
: 인덱스를 경유하여 읽은 블록이 메모리에 캐시 되어 있을 확률 : 디폴트는 0이며, 0~100의 값을 지정 할 수 있다. 80~95%가 적당하지만 정답은 없다. : 이 값이 클수록 FTS(Full Table Scan)보다 인덱스 액세스가 선호되므로, Sort Merge 조인, Hash 조인에 비해 NL 조인이 더 많이 선택된다. OPTIMIZER_INDEX_COST_ADJ : 인덱스 액세스의 비용을 지정된 비율만큼 감소시킨다. : 디폴트는 100이며, 0~100의 값을 지정 할 수 있다. 5~10 정도가 적당하지만 정답은 없다. : 이 값을 50으로 지정하면, 인덱스 액세스 비용을 50% 감소시키기 때문에 FTS보다 인덱스 액세스가 선호된다.
보다 인덱스 액세스가 선호되므로, Sort Merge 조인, Hash 조인에 비해 NL 조인이 더 많이 선택된다. OPTIMIZER_INDEX_COST_ADJ. : 인덱스 액세스의 비용을 지정된 비율만큼 감소시킨다. : 디폴트는 100이며, 0~100의 값을 지정 할 수 있다. 5~10 정도가 적당하지만 정답은 없다. : 이 값을 50으로 지정하면, 인덱스 액세스 비용을 50% 감소시키기 때문에. FTS보다 인덱스 액세스가 선호된다.")
157
CREATE TABLE T1 AS SELECT LEVEL C1, 'X' C2 FROM DUAL CONNECT BY LEVEL <= 10000; CREATE INDEX T1_C1_IDX ON T1(C1); CREATE TABLE T2 CREATE INDEX T2_C1_IDX ON T2(C1); EXEC DBMS_STATS.GATHER_TABLE_STATS(USER, 'T1'); EXEC DBMS_STATS.GATHER_TABLE_STATS(USER, 'T2');
; CREATE TABLE T2 CREATE INDEX T2_C1_IDX ON T2(C1); EXEC DBMS_STATS.GATHER_TABLE_STATS(USER, T1 ); EXEC DBMS_STATS.GATHER_TABLE_STATS(USER, T2 );")
158
ALTER SESSION SET OPTIMIZER_INDEX_CACHING=0; ALTER SESSION SET OPTIMIZER_INDEX_COST_ADJ=100; SELECT /*+ USE_NL(T1 T2) */ * FROM T1, T2 WHERE T1.C1=T2.C1; ALTER SESSION SET OPTIMIZER_INDEX_CACHING=25; ALTER SESSION SET OPTIMIZER_INDEX_COST_ADJ=100;

159
ALTER SESSION SET OPTIMIZER_INDEX_CACHING=75; ALTER SESSION SET OPTIMIZER_INDEX_COST_ADJ=100;

160
ALTER SESSION SET OPTIMIZER_INDEX_CACHING=0; ALTER SESSION SET OPTIMIZER_INDEX_COST_ADJ=100;

161
ALTER SESSION SET OPTIMIZER_INDEX_CACHING=0; ALTER SESSION SET OPTIMIZER_INDEX_COST_ADJ=50;

162
2. DRIVING TABLE 2.1 드라이빙 테이블의 원리 SELECT * FROM DEPT, EMP
WHERE DEPT.DEPTNO=EMP.DEPTNO AND DNAME='SALES' AND JOB='SALESMAN'; DEPT->EMP 드라이빙 테이블에서 검색된 행의 갯수만큼 내부 루프를 반복 총 1회

163
총 4회 드라이빙 테이블에서 검색된 행의 갯수만큼 내부 루프를 반복

164
EMP를 먼저 읽어야 Driving 테이블의 결과 집합을 제한 할 수 있다.
2.2 드라이빙 테이블 예 CREATE INDEX EMP_DEPTNO_IDX ON EMP(DEPTNO); SELECT /*+ RULE */ EMPNO, ENAME, DNAME FROM EMP A, DEPT B WHERE A.EMPNO=7844 AND A.DEPTNO=B.DEPTNO; 외래키에 인덱스 정의 EMP를 먼저 읽어야 Driving 테이블의 결과 집합을 제한 할 수 있다. 조인 컬럼에 각각 인덱스 정의 EMP, DEPT 모두 Driving 가능
; SELECT /*+ RULE */ EMPNO, ENAME, DNAME. FROM EMP A, DEPT B. WHERE A.EMPNO=7844 AND A.DEPTNO=B.DEPTNO; 외래키에 인덱스 정의. EMP를 먼저 읽어야 Driving 테이블의 결과 집합을 제한 할 수 있다. 조인 컬럼에 각각 인덱스 정의. EMP, DEPT 모두 Driving 가능.")
165
(1) 서프레싱 효과 CREATE INDEX DEPT_DNAME_IDX ON DEPT(DNAME);
CREATE INDEX EMP_SAL_IDX ON EMP(SAL); SELECT /*+ RULE */ EMPNO, ENAME, DNAME FROM EMP A, DEPT B WHERE A.DEPTNO=B.DEPTNO AND B.DNAME='SALES' AND A.SAL > 2000; Equal 조건의 우선순위가 높음 CBO는 선택도가 높은 인덱스를 선택한다.
; SELECT /*+ RULE */ EMPNO, ENAME, DNAME. FROM EMP A, DEPT B. WHERE A.DEPTNO=B.DEPTNO. AND B.DNAME= SALES AND A.SAL > 2000; Equal 조건의 우선순위가 높음. CBO는 선택도가 높은 인덱스를 선택한다.")
166
SAL에 정의된 인덱스를 사용하도록 의도 SELECT /*+ RULE */ EMPNO, ENAME, DNAME FROM EMP A, DEPT B WHERE A.DEPTNO=B.DEPTNO AND RTRIM(B.DNAME)='SALES' AND A.SAL > 2000;
= SALES AND A.SAL > 2000;")
167
(2) 비용 기준 옵티마이저의 경우 EXEC DBMS_STATS.GATHER_TABLE_STATS(USER, 'DEPT');
EXEC DBMS_STATS.GATHER_TABLE_STATS(USER, 'EMP'); SELECT EMPNO, ENAME, DNAME FROM EMP A, DEPT B WHERE A.DEPTNO=B.DEPTNO AND B.DNAME='SALES' AND A.SAL > 2000; 선택도가 우수
; SELECT EMPNO, ENAME, DNAME. FROM EMP A, DEPT B. WHERE A.DEPTNO=B.DEPTNO. AND B.DNAME= SALES AND A.SAL > 2000; 선택도가 우수.")
168
SELECT /*+ ORDERED USE_NL(A B) */ EMPNO, ENAME, DNAME
FROM EMP A, DEPT B WHERE A.DEPTNO=B.DEPTNO AND B.DNAME='SALES' AND A.SAL > 2000;

169
(3) 규칙 기준 옵티마이저의 경우 SELECT /*+ RULE */ EMPNO, ENAME, DNAME
FROM EMP A, DEPT B WHERE A.DEPTNO=B.DEPTNO AND B.DNAME='SALES' AND A.SAL = 3000; 바깥 쪽에서 안쪽으로 조인 두 조건의 우선순위가 같음

170
SELECT /*+ RULE */ EMPNO, ENAME, DNAME
FROM DEPT B, EMP A WHERE A.DEPTNO=B.DEPTNO AND B.DNAME='SALES' AND A.SAL=3000; DROP INDEX EMP_SAL_IDX; DROP INDEX EMP_DEPTNO_IDX; DROP INDEX DEPT_DNAME_IDX;

171
2.3 조인에 대한 연결 고리 SELECT /*+ RULE */ EMPNO, ENAME, DNAME FROM EMP, DEPT
WHERE EMP.DEPTNO=DEPT.DEPTNO; 인덱스 없음 기본키 인덱스 연결고리에 인덱스가 없는 테이블을 먼저 Driving 하도록 고정

172
SELECT /*+ RULE */ EMPNO, ENAME, DNAME FROM EMP, DEPT
WHERE EMP.DEPTNO=ROUND(DEPT.DEPTNO, 0); 인덱스 없음 인덱스 사용 못함 연결 고리가 없어서 다른 방식으로 조인
; 인덱스 없음. 인덱스 사용 못함. 연결 고리가 없어서 다른 방식으로 조인.")
173
3. SORT MERGE JOIN 3.1 SORT MERGE 조인의 개념
조인 될 테이블들을 각각 조인 컬럼을 기준으로 정렬하고, 정렬 된 값을 기준으로 머지하는 방법 조인 컬럼으로 각 테이블을 정렬해야 하므로 정렬을 수행 할 공 간이 필요 조인 컬럼에 인덱스가 정의되어 있다면, 정렬을 회피 할 수 있으 므로 효율을 높을 수 있음

174
3.2 SORT MERGE 조인의 절차 CREATE TABLE M_DEPT AS SELECT * FROM DEPT; CREATE TABLE M_EMP AS SELECT * FROM EMP; SELECT DNAME, ENAME FROM M_DEPT, M_EMP WHERE M_DEPT.DEPTNO=M_EMP.DEPTNO; 조인 컬럼에 인덱스 없음

175
M_DEPT.DEPTNO=M_EMP.DEPTNO의 조건이 만족하도록 머지
SORT SORT M_DEPT.DEPTNO=M_EMP.DEPTNO의 조건이 만족하도록 머지

176
SELECT /. + RULE. / DNAME, ENAME FROM M_DEPT, M_EMP WHERE DEPT
SELECT /*+ RULE */ DNAME, ENAME FROM M_DEPT, M_EMP WHERE DEPT.DEPTNO=EMP.DEPTNO; RBO의 선택

177
EXEC DBMS_STATS. GATHER_TABLE_STATS(USER, 'M_EMP'); EXEC DBMS_STATS
EXEC DBMS_STATS.GATHER_TABLE_STATS(USER, 'M_EMP'); EXEC DBMS_STATS.GATHER_TABLE_STATS(USER, 'M_DEPT'); SELECT DNAME, ENAME FROM M_DEPT, M_EMP WHERE M_DEPT.DEPTNO=M_EMP.DEPTNO; 통계 수집 후, CBO의 선택은? CBO는 HASH 조인 선택?
; EXEC DBMS_STATS.GATHER_TABLE_STATS(USER, M_DEPT ); SELECT DNAME, ENAME FROM M_DEPT, M_EMP WHERE M_DEPT.DEPTNO=M_EMP.DEPTNO; 통계 수집 후, CBO의 선택은 CBO는 HASH 조인 선택")
178
SELECT /. + USE_MERGE(M_DEPT M_EMP)
SELECT /*+ USE_MERGE(M_DEPT M_EMP) */ DNAME, ENAME FROM M_DEPT, M_EMP WHERE M_DEPT.DEPTNO=M_EMP.DEPTNO; HASH 조인보다 고비용
 */ DNAME, ENAME FROM M_DEPT, M_EMP WHERE M_DEPT.DEPTNO=M_EMP.DEPTNO; HASH 조인보다 고비용.")
179
조인 컬럼에 인덱스가 존재하면 SORT MERGE 조인은 선택되지 않음
CREATE INDEX M_DEPT_DEPTNO_IDX ON M_DEPT(DEPTNO); CREATE INDEX M_EMP_DEPTNO_IDX ON M_EMP(DEPTNO); SELECT /*+ RULE */ DNAME, ENAME FROM M_DEPT, M_EMP WHERE M_DEPT.DEPTNO=M_EMP.DEPTNO; 조인 컬럼에 인덱스가 존재하면 SORT MERGE 조인은 선택되지 않음
; CREATE INDEX M_EMP_DEPTNO_IDX ON M_EMP(DEPTNO); SELECT /*+ RULE */ DNAME, ENAME FROM M_DEPT, M_EMP WHERE M_DEPT.DEPTNO=M_EMP.DEPTNO; 조인 컬럼에 인덱스가 존재하면 SORT MERGE 조인은 선택되지 않음.")
180
SELECT DNAME, ENAME FROM M_DEPT, M_EMP WHERE M_DEPT. DEPTNO=M_EMP
SELECT DNAME, ENAME FROM M_DEPT, M_EMP WHERE M_DEPT.DEPTNO=M_EMP.DEPTNO; CBO도 SORT MERGE 조인보다 NESTED LOOP 조인을 선택

181
조인 컬럼의 인덱스를 사용하면 정렬을 생략 할 수 있지 않은가?
SELECT /*+ USE_MERGE(M_DEPT M_EMP) */ DNAME, ENAME FROM M_DEPT, M_EMP WHERE M_DEPT.DEPTNO=M_EMP.DEPTNO; SORT MERGE 조인의 비용이 높음 조인 컬럼의 인덱스를 사용하면 정렬을 생략 할 수 있지 않은가?
 */ DNAME, ENAME FROM M_DEPT, M_EMP WHERE M_DEPT.DEPTNO=M_EMP.DEPTNO; SORT MERGE 조인의 비용이 높음. 조인 컬럼의 인덱스를 사용하면 정렬을 생략 할 수 있지 않은가")
182
SELECT /. + USE_MERGE(M_DEPT M_EMP) INDEX(M_EMP M_EMP_DEPTNO_IDX)
SELECT /*+ USE_MERGE(M_DEPT M_EMP) INDEX(M_EMP M_EMP_DEPTNO_IDX) */ DNAME, ENAME FROM M_DEPT, M_EMP WHERE M_DEPT.DEPTNO=M_EMP.DEPTNO; 비용은 감소 ?
 INDEX(M_EMP M_EMP_DEPTNO_IDX) */ DNAME, ENAME FROM M_DEPT, M_EMP WHERE M_DEPT.DEPTNO=M_EMP.DEPTNO; 비용은 감소.")
183
3.4 SORT MERGE 조인의 장단점 조인 컬럼에 인덱스가 생성되어 있지 않은 경우에 사용
조인 컬럼에 인덱스가 생성되어 있지 않으면, NESTED LOOP 조 인은 Drived 테이블을 반복적으로 Full Table Scan을 수행함 SORT MERGE 조인은 Driving 테이블과 Drived 테이블을 단 1번 씩만 읽어서 조인 수행 정렬 작업에 많은 메모리가 필요

184
3.4 SORT MERGE 조인 파라메터 DB_FILE_MULTIBLOCK_READ_COUNT
: Full Table Scan 또는 Index Fast Full Scan을 수행하는 경우, 1회의 입출력에 처리하는 블록의 개수 : 이 값이 크면 FTS가 선택되는 경향이 높아지며, 이 값이 작으면 Index Scan이 선택되는 경향이 높아진다. SORT_AREA_SIZE : 정렬 작업에 필요한 메모리 공간의 크기 : 9i부터는 PGA_AGGREGATE_TARGET 사용 권장

185
4. HASH JOIN 4.1 HASH JOIN 조인의 개념
두 테이블 중에 작은 테이블을 Build 테이블, 큰 테이블을 Probe 테이블이라고 정의 Build 테이블을 읽고, 조인 컬럼을 해시(Hash) 함수에 입력 후, 그 결과에 따라 지정된 메모리 블록에 해당 행을 저장 Probe 테이블을 읽고, 조인 컬럼을 해시 함수에 입력 후, 그 결 과를 이용하여 메모리 상의 build 테이블에 직접 접근
 함수에 입력 후, 그 결과에 따라 지정된 메모리 블록에 해당 행을 저장. Probe 테이블을 읽고, 조인 컬럼을 해시 함수에 입력 후, 그 결 과를 이용하여 메모리 상의 build 테이블에 직접 접근.")
186
4. HASH JOIN 4.2 HASH JOIN 조인의 절차
CREATE TABLE H_DEPT AS SELECT * FROM DEPT; CREATE TABLE H_EMP AS SELECT * FROM EMP; SELECT DNAME, ENAME FROM H_DEPT, H_EMP WHERE H_DEPT.DEPTNO=H_EMP.DEPTNO;

187
해시 함수(예 : f(x) = x/10) 해시값 : 20/10 = 2 메모리의 해당 블록에 행을 저장 159번 블록으로 이동
 = x/10) 해시값 : 20/10 = 2 메모리의 해당 블록에 행을 저장 159번 블록으로 이동")
188
SORT MERGE 조인은 왜 선택되지 않았나?
4.3 HASH 조인의 예 SELECT DNAME, ENAME FROM H_DEPT, H_EMP WHERE H_DEPT.DEPTNO=H_EMP.DEPTNO; 조인 컬럼에 인덱스 없음 SORT MERGE 조인은 왜 선택되지 않았나?

189
SELECT /. + USE_MERGE(H_DEPT, H_EMP)
SELECT /*+ USE_MERGE(H_DEPT, H_EMP) */ DNAME, ENAME FROM H_DEPT, H_EMP WHERE H_DEPT.DEPTNO=H_EMP.DEPTNO; HASH 조인에 비해 고비용
 */ DNAME, ENAME FROM H_DEPT, H_EMP WHERE H_DEPT.DEPTNO=H_EMP.DEPTNO; HASH 조인에 비해 고비용.")
190
4.4 HASH JOIN의 장단점 Equi-Join에서만 가능
인덱스가 반드시 필요하지는 않지만, 조인되는 집합을 줄이 기 위한 조건으로 인덱스를 사용 가능 메모리와 CPU 자원이 많이 필요

191
4.5 HASH 조인 파라메터 _HASH_JOIN_ENABLED : HASH 조인의 사용 여부를 지정
파라메터에 _ 가 붙는 히든 파라메터는 설정 변경을 권장하지 않음 _HASH_JOIN_ENABLED : HASH 조인의 사용 여부를 지정 HASH_AREA_SIZE : 해시 테이블 구성을 위한 메모리 크기 : 9i 부터 PGA_AGGREGATE_TARGET 파라메터 사용 권장 _HASH_MULTIBLOCK_IO_COUNT : HASH 조인을 수행 할 때 한 번의 I/O 작업에 읽는 블록 수 지정

192
5. JOIN 비교 NESTED LOOP 조인은 연결고리에 인덱스가 있으며, 기준이 되 는 Driving 집합의 크기가 적은 경우에 효율적 SORT MERGE 조인은 연결고리에 인덱스가 없거나, 조인 된 결 과 집합이 큰 경우에 효율적 HASH 조인은 SORT MERGE 조인과 유사한 상황에서 선택되지 만, 결합되는 두 조인 집합의 크기가 차이가 나는 경우에 효율적

193
6. SET OPERATOR 두 개의 질의 결과를 하나로 결합해 주는 연산자
복합 질의문(Compound Query) 작성에 사용
 작성에 사용.")
194
6.1 SET 연산자의 종류 UNION : 합집합 연산 UNION ALL : 합집합 연산(중복된 행을 제거하지 않음)
INTERSECT : 교집합 연산 MINUS : 차집합 연산

195
6.2 SET 연산자의 수행 SELECT empno, ename, job, sal FROM emp WHERE job='MANAGER'; FROM emp WHERE sal BETWEEN 2500 AND 3000;

196
SELECT empno, ename, job, sal FROM emp WHERE job='MANAGER' UNION FROM emp WHERE sal BETWEEN 2500 AND 3000; 중복된 행은 1번만 리턴 정렬 발생

197
SELECT empno, ename, job, sal FROM emp WHERE job='MANAGER' UNION ALL FROM emp WHERE sal BETWEEN 2500 AND 3000; 정렬 불필요

198
SELECT empno, ename, job, sal FROM emp WHERE job='MANAGER' INTERSECT FROM emp WHERE sal BETWEEN 2500 AND 3000; 정렬 필요

199
SELECT empno, ename, job, sal FROM emp WHERE job='MANAGER' MINUS FROM emp WHERE sal BETWEEN 2500 AND 3000; 정렬 필요

200
6.3 SET 연산자의 장단점 수학적 개념의 집합 연산 수행 가능 UNION ALL을 사용하면 N개의 질의문을 결합 가능
인덱스 키 컬럼에 대하여 INTERSECT 연산을 수행하는 경우, IN 또는 EXISTS에 비해 빠를 수 있음 두 질의문에 중복된 행이 존재하지 않는 경우, UNION 대신 UNION ALL을 사용하는 것이 빠름 UNION은 UNION ALL 수행 후, UNIQUE 정렬 수행 중복된 행이 없는 경우라면, 정렬 작업을 회피하기 위해 UNION ALL 사용 집합 연산에 사용된 FIRST_ROWS_N 힌트는 무시 FULL OUTER JOIN을 수행하기 위해, UNION 또는 UNION ALL 사용 가능

201
6.4 SET 연산자의 제약 사항 SELECT 절에 연산식이 포함되어 있으면, 컬럼 별칭을 사용하여야 ORDER BY 절에서 사용 가능 집합 연산자가 포함된 서브쿼리에서 ORDER BY 사용 불가 FOR UPDATE 절 사용 불가 BLOB, CLOB, BFILE, VARRAY 같은 자료형에 집합 연산자 사용 불가 LONG 자료형의 컬럼에 UNION, INTERSECT, MINUS 연산자 사용 불가

202
7. SUBQUERY 7.1 Subquery의 종류 Inline View : FROM 절에 사용되는 서브쿼리
Nested/Correlated 서브쿼리 : WHERE 절에 사용되는 서브쿼리 Scalar 서브쿼리 : 하나의 값만을 출력하는 서브쿼리

203
SELECT EMPNO, ENAME FROM EMP WHERE DEPTNO = (SELECT DEPTNO FROM DEPT WHERE DNAME='SALES');
CBO

204
2. 전달받은 행에서 DEPTNO 컬럼의 값을 대입
7.2 Correlated Subquery 서브쿼리가 독립적으로 실행되지 못하고, 메인 쿼리의 도움을 받아야 실행 가능한 쿼리. 서브쿼리를 메인쿼리와 조인하는 방식으로 처리. 이 방식이 불가능한 경우는 FILTER 처리 된다. SELECT E1.ENAME FROM EMP E1 WHERE E1.SAL > (SELECT AVG(E2.SAL) FROM EMP WHERE E2.DEPTNO=E1.DEPTNO); 1. EMP의 첫번째 행을 서브쿼리에 전달 3. 서브쿼리의 결과를 메인 쿼리에 전달 2. 전달받은 행에서 DEPTNO 컬럼의 값을 대입
 FROM EMP WHERE E2.DEPTNO=E1.DEPTNO); 1. EMP의 첫번째 행을 서브쿼리에 전달. 3. 서브쿼리의 결과를 메인 쿼리에 전달. 2. 전달받은 행에서 DEPTNO 컬럼의 값을 대입.")
205
SELECT E1. ENAME FROM EMP E1 WHERE E1. SAL > (SELECT AVG(E2
SELECT E1.ENAME FROM EMP E1 WHERE E1.SAL > (SELECT AVG(E2.SAL) FROM EMP E2 WHERE E2.DEPTNO=E1.DEPTNO); CBO는 조인? RBO는 필터 처리
 FROM EMP E2 WHERE E2.DEPTNO=E1.DEPTNO); CBO는 조인 RBO는 필터 처리.")
206
Correlated 서브쿼리에 지정 /*+ UNNEST */ : 메인 쿼리와 결합(JOIN으로 재작성) /*+ NO_UNNEST */ : 메인 쿼리와 결합하지 않음(FILTER 처리) SELECT E1.ENAME FROM EMP E1 WHERE E1.SAL > (SELECT /*+ NO_UNNEST */ AVG(E2.SAL) FROM EMP E2 WHERE E2.DEPTNO=E1.DEPTNO); FILTER 처리하면 고비용
 FROM EMP E2 WHERE E2.DEPTNO=E1.DEPTNO); FILTER 처리하면 고비용.")
207
SELECT EMPNO, ENAME FROM EMP WHERE EXISTS (SELECT 1 FROM DEPT WHERE DEPTNO=EMP.DEPTNO AND DNAME='SALES'); CBO는 조인으로 실행계획을 수립한다. RBO는 FILTER 처리

208
SELECT EMPNO, ENAME FROM EMP WHERE EXISTS (SELECT /. + NO_UNNEST
SELECT EMPNO, ENAME FROM EMP WHERE EXISTS (SELECT /*+ NO_UNNEST */ 1 FROM DEPT WHERE DEPTNO=EMP.DEPTNO AND DNAME='SALES'); FILTER는 고비용
; FILTER는 고비용.")
209
8. SCALAR SUBQUERY 8.1 Scalar Subquery의 특성
SELECT EMPNO, ENAME, DNAME FROM DEPT B, EMP A WHERE A.DEPTNO=B.DEPTNO;

210
SELECT EMPNO, ENAME, (SELECT DNAME FROM DEPT WHERE DEPTNO = A
SELECT EMPNO, ENAME, (SELECT DNAME FROM DEPT WHERE DEPTNO = A.DEPTNO) FROM EMP A;
 FROM EMP A;")
211
8.2 SCALAR SUBQUERY 사용 SELECT LIST 항목
SELECT EMPNO, ENAME, (SELECT GRADE FROM SALGRADE WHERE SAL BETWEEN LOSAL AND HISAL) FROM EMP;
 FROM EMP;")
212
함수의 인자 SELECT EMPNO, ENAME, SUBSTR((SELECT DNAME FROM DEPT WHERE DEPTNO=E.DEPTNO), 1, 3) FROM EMP E;
, 1, 3) FROM EMP E; .")
213
WHERE 절의 조건 SELECT EMPNO, ENAME FROM EMP E WHERE (SELECT DNAME FROM DEPT WHERE DEPTNO = E.DEPTNO) = (SELECT DNAME FROM DEPT WHERE DEPTNO=E.DEPTNO);
;")
214
ORDER BY 절의 조건 SELECT EMPNO, ENAME, DEPTNO FROM EMP E ORDER BY (SELECT DNAME FROM DEPT WHERE DEPTNO=E.DEPTNO);
; .")
215
CASE 조건 절 SELECT EMPNO, ENAME, DEPTNO FROM EMP E ORDER BY (SELECT DNAME FROM DEPT WHERE DEPTNO=E.DEPTNO);
; .")
216
CASE 결과 절 SELECT EMPNO, ENAME, DEPTNO, (CASE WHEN DEPTNO=20 THEN (SELECT DNAME FROM DEPT WHERE DEPTNO=10) ELSE (SELECT DNAME FROM DEPT WHERE DEPTNO=30) END) FROM EMP E;
 END) FROM EMP E;")
217
8.3 SCALAR SUBQUERY의 데이터가 없는 경우
SELECT EMPNO, NVL((SELECT ENAME FROM EMP B WHERE B.EMPNO=A.MGR), 'NULL') AS MANAGER FROM EMP A WHERE DEPTNO=10 ORDER BY MGR;
, NULL ) AS MANAGER FROM EMP A WHERE DEPTNO=10 ORDER BY MGR;")
218
8.4 SCALAR SUBQUERY를 사용 할 수 없는 경우
컬럼에 대한 기본(default) 값 Check 제약조건 함수 기반 인덱스 START WITH와 CONNECT BY 절 DML 문장의 RETURN 절 클러스터에 대한 HASH 표현식 질의문과는 상관 없는 CREATE PROFILE 같은 문장
 값. Check 제약조건. 함수 기반 인덱스. START WITH와 CONNECT BY 절. DML 문장의 RETURN 절. 클러스터에 대한 HASH 표현식. 질의문과는 상관 없는 CREATE PROFILE 같은 문장.")
219
9. TOP-N QUERY 급여가 많은 순서로 N 명 수학점수가 높은 순서로 N 명
과거(Oracle 7)에는 인라인 뷰에 ORDER BY 절을 사용 할 수 없었기 때문에 TOP-N 쿼리가 어려웠지만, 현재는 사용 가능하므로 간단하게 TOP-N 처리 가 쉬어짐.
에는 인라인 뷰에 ORDER BY 절을 사용 할 수 없었기 때문에 TOP-N 쿼리가 어려웠지만, 현재는 사용 가능하므로 간단하게 TOP-N 처리 가 쉬어짐.")
220
9.1 인라인 뷰 내의 ORDER BY 사용 SELECT ROWNUM, EMPNO, SAL FROM (SELECT EMPNO, SAL FROM EMP ORDER BY SAL DESC) WHERE ROWNUM <= 3;
 WHERE ROWNUM <= 3;")
221
- 잘 못 사용하는 경우 SELECT EMPNO, SAL FROM EMP WHERE ROWNUM <= 3 ORDER BY SAL DESC;
테이블에서 임의의 3건을 검색하여 정렬

222
9.2 ROWNUM 가상 컬럼(Pseudo Column)
SELECT * FROM EMP WHERE ROWNUM < 10;

223
인덱스를 경유하여 테이블을 액세스하기 때문에
SELECT /*+ INDEX(EMP PK_EMP) */ * FROM EMP WHERE ROWNUM < 10 ORDER BY EMPNO; 인덱스를 경유하여 테이블을 액세스하기 때문에 EMPNO가 정렬된 결과 9건
 */ * FROM EMP WHERE ROWNUM < 10 ORDER BY EMPNO; 인덱스를 경유하여 테이블을 액세스하기 때문에. EMPNO가 정렬된 결과 9건.")
224
SELECT /. + NO_INDEX(EMP PK_EMP). /
SELECT /*+ NO_INDEX(EMP PK_EMP) */ * FROM EMP WHERE ROWNUM < 10 ORDER BY EMPNO; EMPNO에서 10개의 임의 행을 가져와와 정렬
 */ * FROM EMP WHERE ROWNUM < 10 ORDER BY EMPNO; EMPNO에서 10개의 임의 행을 가져와와 정렬.")
225
ROWNUM을 순번으로 사용 SELECT * FROM EMP WHERE ROWNUM = 1; (O) SELECT * FROM EMP WHERE ROWNUM > 1; (X) SELECT * FROM EMP WHERE ROWNUM = 2; (X) SELECT * FROM EMP WHERE ROWNUM BETWEEN 2 AND 10; (X) SEQUENCE의 대용 UPDATE TEST_TEMP SET EMPNO=ROWNUM;
 SEQUENCE의 대용. UPDATE TEST_TEMP SET EMPNO=ROWNUM;")
226
9.3 연관된 서브쿼리를 이용한 TOP-N 처리 예) EMP 테이블에서 급여가 많은 순서대로 3명을 출력 SELECT A.EMPNO, A.SAL FROM EMP A WHERE 3 > (SELECT COUNT(*) FROM EMP WHERE SAL > A.SAL) ORDER BY A.SAL DESC;
 EMP 테이블에서 급여가 많은 순서대로 3명을 출력 SELECT A.EMPNO, A.SAL FROM EMP A WHERE 3 > (SELECT COUNT(*) FROM EMP WHERE SAL > A.SAL) ORDER BY A.SAL DESC;")
227
예) EMP 테이블에서 급여가 많은 순서대로 2명을 출력 SELECT A. EMPNO, A
예) EMP 테이블에서 급여가 많은 순서대로 2명을 출력 SELECT A.EMPNO, A.SAL FROM EMP A WHERE 2 > (SELECT COUNT(*) FROM EMP WHERE SAL > A.SAL) ORDER BY A.SAL DESC; 급여가 3000인 사원이 2명이므로 3명이 출력된다. 2명만 출력하려면 다음과 같이 ROWNUM을 사용해야 한다. SELECT B.EMPNO, B.SAL FROM (SELECT A.EMPNO, A.SAL ORDER BY A.SAL DESC) B WHERE ROWNUM <= 2;
 EMP 테이블에서 급여가 많은 순서대로 2명을 출력 SELECT A.EMPNO, A.SAL FROM EMP A WHERE 2 > (SELECT COUNT(*) FROM EMP WHERE SAL > A.SAL) ORDER BY A.SAL DESC; 급여가 3000인 사원이 2명이므로 3명이 출력된다. 2명만 출력하려면 다음과 같이 ROWNUM을 사용해야 한다. SELECT B.EMPNO, B.SAL FROM (SELECT A.EMPNO, A.SAL ORDER BY A.SAL DESC) B WHERE ROWNUM <= 2;")
229
9.4 분석함수를 이용한 TOP-N 처리 SELECT EMPNO, ENAME, SAL, RANK() OVER (ORDER BY SAL DESC, EMPNO) AS RNK FROM EMP;
 OVER (ORDER BY SAL DESC, EMPNO) AS RNK FROM EMP;")
230
SELECT EMPNO, ENAME, SAL, RANK() OVER (ORDER BY SAL DESC, EMPNO) AS RNK FROM EMP;
 OVER (ORDER BY SAL DESC, EMPNO) AS RNK FROM EMP;")
231
10. VIEW 테이블 또는 다른 뷰의 데이터를 사용자가 원하는 방식으로 표 현하기 위한 데이터베이스 객체
사용자에게 질의문의 결과를 테이블처럼 처리하도록 도와주며 SQL 문장으로 구성

232
10.1 VIEW의 생성 Base Table View

233
10.2 VIEW의 저장 공간 데이터베이스에서 물리적인 저장 공간을 차지하지 않고, 데이터도 보관하지 않음
데이터베이스에서 물리적인 저장 공간을 차지하지 않고, 데이터도 보관하지 않음 질의문으로 정의되며 사용 될 때, 뷰가 참조하는 테이블에서 자료 를 추출 뷰가 참조하는 테이블을 BASE 테이블이라고 함 가상 테이블 또는 저장된 질의문으로 가정

234
10.3 VIEW의 사용 목적 테이블 자료에 대한 접근 제한(보안) 데이터의 구조 단순화 사용자를 위한 단순한 인터페이스
복잡한 질의문을 저장 뷰를 사용하지 않고는 처리될 수 없는 질의문을 표현 테이블 구조 변경에 의한 영향으로부터 프로그램 분리

235
10.4 VIEW의 실행 원리 뷰는 질의문(SQL)을 데이터 딕셔너리(USER_VIEWS)에 텍스트 형태로 저장하고 있으며, 질의문에 뷰가 사용된 경우, 다음과 같은 두 가지 방식 중 하나로 처리됨 Merge : 뷰의 정의를 뷰를 참조하는 질의문에 병합( /*+ MERGE */) No-merge : 뷰의 정의를 뷰를 참조하는 질의문과 병합하지 않음(/*+ NO_MERGE */)
 No-merge : 뷰의 정의를 뷰를 참조하는 질의문과 병합하지 않음(/*+ NO_MERGE */)")
236
View의 병합 실행 뷰를 정의하고 있는 질의문을 포함하여 질의문을 병합(Merge)
공유된 SQL 영역에 결합된 질의문을 해석(Parse) 질의문 실행
 질의문 실행.")
237
SELECT ENAME FROM EMP_VIEW WHERE EMPNO=7788;
CREATE OR REPLACE VIEW EMP_VIEW AS SELECT EMPNO, ENAME, SAL, LOC FROM EMP, DEPT WHERE DEPT.DEPTNO=EMP.DEPTNO AND DEPT.DEPTNO=20; SELECT ENAME FROM EMP_VIEW WHERE EMPNO=7788; CBO는 이행적 폐쇄 발생 조인 조건에 필터 조건이 있는 경우 외부 조건이 뷰 내로 진입

238
SELECT E.ENAME, E.DEPTNO, V.SUM_SAL FROM EMP E, V_SUM_BY_DEPTNO V
CREATE OR REPLACE VIEW V_SUM_BY_DEPTNO AS SELECT DEPTNO, SUM(SAL) SUM_SAL FROM EMP GROUP BY DEPTNO; SELECT E.ENAME, E.DEPTNO, V.SUM_SAL FROM EMP E, V_SUM_BY_DEPTNO V WHERE E.DEPTNO=V.DEPTNO; 뷰 머지 안됨
 SUM_SAL FROM EMP GROUP BY DEPTNO; SELECT E.ENAME, E.DEPTNO, V.SUM_SAL. FROM EMP E, V_SUM_BY_DEPTNO V. WHERE E.DEPTNO=V.DEPTNO; 뷰 머지 안됨.")
239
SELECT /*+ MERGE(V) */ E.ENAME, E.DEPTNO, V.SUM_SAL
FROM EMP E, V_SUM_BY_DEPTNO V WHERE E.DEPTNO=V.DEPTNO;

240
View의 병합을 사용하지 않는 경우 VIEW MERGE가 일어날 수 없는 경우 ROWNUM 가상 컬럼을 포함한 경우
SELECT LIST에 집계 함수(AVG, COUNT, MAX, MIN, SUM)가 포함되어 있는 경우 SET 연산자(UNION, UNION ALL, INTERSECT, MINUS)를 포함한 경우 ORDER BY, GROUP BY, DISTINCT CONNECT BY 절을 포함한 경우
가 포함되어 있는 경우. SET 연산자(UNION, UNION ALL, INTERSECT, MINUS)를 포함한 경우. ORDER BY, GROUP BY, DISTINCT. CONNECT BY 절을 포함한 경우.")
241
CREATE OR REPLACE VIEW EMP_VIEW_ROWNUM AS SELECT EMPNO, ENAME, SAL, LOC FROM EMP, DEPT WHERE DEPT.DEPTNO=EMP.DEPTNO AND DEPT.DEPTNO=20 AND ROWNUM < 10; SELECT ENAME FROM EMP_VIEW_ROWNUM WHERE EMPNO=7788;

242
11. INLINE VIEW FROM 절에 사용한 서브쿼리 WHERE 절에 사용된 서브쿼리와는 달리 레벨 제한이 없음

243
11.1 INLINE VIEW와 ALIAS 인라인 뷰 내에서 함수를 사용하거나 연산식을 사용한 컬럼의 결과 값을 상 위 레벨 질의문에서 사용하고자 하는 경우, 반드시 ALIAS를 지정해주어야 함 SELECT EMPNO, DEPTNO, SAL/SAL_AVG AS SAL_RATIO FROM EMP A, (SELECT DEPTNO, AVG(SAL) AS SAL_AVG FROM EMP GROUP BY DEPTNO) B WHERE A.DEPTNO=B.DEPTNO;
 AS SAL_AVG FROM EMP GROUP BY DEPTNO) B WHERE A.DEPTNO=B.DEPTNO;")
244
11.2 INLINE VIEW의 사용 조인의 대체 SELECT A.EMPNO, A.DEPTNO, A.SAL, AVG(B.SAL), (A.SAL/AVG(B.SAL)) AS SAL_RATIO FROM EMP A, EMP B WHERE A.DEPTNO=B.DEPTNO GROUP BY A.EMPNO, A.DEPTNO, A.SAL;

245
SELECT EMPNO, A. DEPTNO, A. SAL, B. SAL_AVG, (A. SAL/B
SELECT EMPNO, A.DEPTNO, A.SAL, B.SAL_AVG, (A.SAL/B.SAL_AVG) AS SAL_RATIO FROM EMP A, (SELECT DEPTNO, AVG(SAL) AS SAL_AVG FROM EMP GROUP BY DEPTNO) B WHERE A.DEPTNO=B.DEPTNO; 뷰에서 그룹핑 후, 조인
 AS SAL_RATIO FROM EMP A, (SELECT DEPTNO, AVG(SAL) AS SAL_AVG FROM EMP GROUP BY DEPTNO) B WHERE A.DEPTNO=B.DEPTNO; 뷰에서 그룹핑 후, 조인.")
246
SELECT EMPNO, A. DEPTNO, A. SAL, B. SAL_AVG, (A. SAL/B
SELECT EMPNO, A.DEPTNO, A.SAL, B.SAL_AVG, (A.SAL/B.SAL_AVG) AS SAL_RATIO FROM EMP A, (SELECT /*+ MERGE */DEPTNO, AVG(SAL) AS SAL_AVG FROM EMP GROUP BY DEPTNO) B WHERE A.DEPTNO=B.DEPTNO; 조인 후, 그룹핑
 AS SAL_RATIO FROM EMP A, (SELECT /*+ MERGE */DEPTNO, AVG(SAL) AS SAL_AVG FROM EMP GROUP BY DEPTNO) B WHERE A.DEPTNO=B.DEPTNO; 조인 후, 그룹핑.")
247
조인 회수의 감소 SELECT A.DNAME, A.DEPTNO, AVG(B.SAL) FROM DEPT A, EMP B WHERE A.DEPTNO=B.DEPTNO GROUP BY A.DNAME, A.DEPTNO;

248
SELECT A. DNAME, A. DEPTNO, B
SELECT A.DNAME, A.DEPTNO, B.SAL_AVG FROM DEPT A, (SELECT DEPTNO, AVG(SAL) AS SAL_AVG FROM EMP GROUP BY DEPTNO) B WHRE A.DEPTNO=B.DEPTNO;
 AS SAL_AVG FROM EMP GROUP BY DEPTNO) B WHRE A.DEPTNO=B.DEPTNO;")
249
JOB별 평균 급여를 10% 초과하는 사원은 급여의 5% 차감
11.3 절차성을 위한 인라인 뷰의 활용 SELECT ENAME, SAL, JOB_AVG, OVER_PCT, DECODE(SIGN(OVER_PCT-110), 1, SAL*0.05, 0) AS MINUS_SAL FROM (SELECT ENAME, SAL, JOB_AVG, SAL*100/JOB_AVG AS OVER_PCT FROM EMP A, (SELECT JOB, AVG(SAL) AS JOB_AVG FROM EMP GROUP BY JOB) B WHERE A.JOB=B.JOB AND A.SAL > B.JOB_AVG); JOB별 평균 급여를 10% 초과하는 사원은 급여의 5% 차감 JOB별 평균 급여 JOB별 평균 급여보다 급여가 높은 사원
, 1, SAL*0.05, 0) AS MINUS_SAL FROM (SELECT ENAME, SAL, JOB_AVG, SAL*100/JOB_AVG AS OVER_PCT FROM EMP A, (SELECT JOB, AVG(SAL) AS JOB_AVG FROM EMP GROUP BY JOB) B WHERE A.JOB=B.JOB AND A.SAL > B.JOB_AVG); JOB별 평균 급여를 10% 초과하는 사원은 급여의 5% 차감. JOB별 평균 급여. JOB별 평균 급여보다 급여가 높은 사원.")
250
11.4 TOP-N 질의문에 ROWNUM을 다시 부여
SELECT EMPNO, SAL FROM (SELECT EMPNO, SAL FROM EMP ORDER BY SAL DESC) WHERE ROWNUM <= 5; 11.5 뷰를 대신하는 임시(ad hoc) 질의에 사용 - 필요할 때마다 매번 뷰를 생성하여 사용하는 경우, 뷰 관리가 어려움
 WHERE ROWNUM <= 5; 11.5 뷰를 대신하는 임시(ad hoc) 질의에 사용. - 필요할 때마다 매번 뷰를 생성하여 사용하는 경우, 뷰 관리가 어려움.")
251
12. STANDARD SQL Classical Form : 조인 연산 수행 시, FROM 절 뒤의 테이블 목록을 나열하 고 WHERE 절에 조인 조건을 기술하는 방식 SQL 1999 Join : ANSI 표준 SQL 문으로 조인 문장의 기능 및 성능 개선 CROSS JOIN NATURAL JOIN USING JOIN ON JOIN OUTER JOIN

252
12.1 CROSS JOIN Classical Form SELECT ename, dname FROM dept, emp;
SQL 1999 Join FROM dept CROSS JOIN dept;

253
12.2 NATURAL JOIN Classical Form SELECT ename, dname FROM dept, emp
WHERE dept.deptno=emp.deptno; SQL 1999 Join FROM dept NATURAL JOIN emp; dept, emp에서 컬럼명과 컬럼의 데이터 타입이 일치되는 컬럼을 찾아서 조인 주의. 원하지 않는 컬럼들이 조인 될 수 있음.

254
12.3 USING JOIN Classical Form SELECT ename, dname FROM dept, emp
WHERE dept.deptno=emp.deptno; SQL 1999 Join FROM dept JOIN emp USING (deptno); dept, emp에서 컬럼명은 일치되지만, 컬럼의 데이터 타입이 일치되지 않아서 NATURAL JOIN이 불가능한 경우에 사용
; dept, emp에서 컬럼명은 일치되지만, 컬럼의 데이터 타입이 일치되지 않아서 NATURAL JOIN이 불가능한 경우에 사용.")
255
12.4 ON JOIN Classical Form SELECT ename, dname FROM dept, emp
WHERE dept.deptno=emp.deptno; SQL 1999 Join FROM dept JOIN emp ON dept.deptno=emp.deptno; dept, emp에서 컬럼명과 컬럼의 데이터 타입이 일치되지 않아서 NATURAL JOIN, USING JOIN이 불가능한 경우에 사용

256
12.5 OUTER JOIN Classical Form SELECT ename, dname FROM dept, emp
WHERE dept.deptno=emp.deptno(+); SQL 1999 Join FROM dept LEFT OUTER JOIN emp ON dept.deptno=emp.deptno; dept, emp에서 PK와 FK가 일치되는 행들과 dept 테이블에서 조인되지 않는 행들도 출력
; SQL 1999 Join. FROM dept LEFT OUTER JOIN emp. ON dept.deptno=emp.deptno; dept, emp에서 PK와 FK가 일치되는 행들과. dept 테이블에서 조인되지 않는 행들도 출력.")
257
dept, emp에서 PK와 FK가 일치되는 행들과
Classical Form SELECT ename, dname FROM dept, emp WHERE dept.deptno(+)=emp.deptno; SQL 1999 Join FROM dept RIGHT OUTER JOIN emp ON dept.deptno=emp.deptno; dept, emp에서 PK와 FK가 일치되는 행들과 emp 테이블에서 조인되지 않는 행들도 출력
=emp.deptno; SQL 1999 Join. FROM dept RIGHT OUTER JOIN emp. ON dept.deptno=emp.deptno; dept, emp에서 PK와 FK가 일치되는 행들과. emp 테이블에서 조인되지 않는 행들도 출력.")
258
LEFT OUTER JOIN 과 RIGHT OUTER JOIN 의 합집합
Classical Form SELECT ename, dname FROM dept, emp WHERE dept.deptno(+)=emp.deptno UNION WHERE dept.deptno=emp.deptno(+) SQL 1999 Join FROM dept FULL OUTER JOIN emp ON dept.deptno=emp.deptno; LEFT OUTER JOIN 과 RIGHT OUTER JOIN 의 합집합
=emp.deptno. UNION. WHERE dept.deptno=emp.deptno(+) SQL 1999 Join. FROM dept FULL OUTER JOIN emp. ON dept.deptno=emp.deptno; LEFT OUTER JOIN 과 RIGHT OUTER JOIN 의 합집합.")
259
Chapter 4. 튜닝 활용 CASE 함수 SUM(DECODE) Cartesian Product Rollup과 Cube 함수
Grouping Sets Analytic Functions Multi-tables Insert Merge

260
1. CASE 함수 IF-THEN-ELSE 논리의 구현 DECODE(8i 이전)의 개선
DECODE는 CASE와 비교할 때, 범위 조건을 사용하기가 번거로우며, 내부 정렬이 수행되므로 속도가 다소 느림

261
예제> EMP 테이블에서 DEPTNO가 10이면 ACCOUNTING, 20이면 RESEARCH, 30이면 SALES, 40이면 OPERATIONS, 그 외에는 UNKNOWN을 출력하시오. SELECT empno, ename, deptno, DECODE(deptno, 10, 'ACCOUNTING', 20, 'RESEARCH', 30, 'SALES', 40, 'OPERATIONS', 'UNKNOWN') FROM emp; SELECT empno, ename, deptno, CASE deptno WHEN 10 THEN ' ACCOUNTING’ WHEN 20 THEN 'RESEARCH' WHEN 30 THEN 'SALES' WHEN 40 THEN 'OPERATIONS' ELSE 'UNKNOWN' END
 FROM emp; SELECT empno, ename, deptno, CASE deptno WHEN 10 THEN ACCOUNTING’ WHEN 20 THEN RESEARCH WHEN 30 THEN SALES WHEN 40 THEN OPERATIONS ELSE UNKNOWN END .")
262
예제> EMP 테이블에서 SAL이 2000 미만이면 LOW, 3000 미만이면 AVERAGE, 3000 이 상이면 HIGH를 출력하시오. SELECT empno, ename, sal, DECODE(SIGN(sal-2000), -1, 'LOW', DECODE(SIGN(sal-3000), -1, 'AVERAGE', 'HIGH')) FROM emp; - 참고 : SIGN 함수는 인자가 음수이면 -1, zero이면 0, 양수이면 1을 리턴한다. CASE WHEN sal < 2000 THEN 'LOW' WHEN sal < 3000 THEN 'AVERAGE' ELSE 'HIGH' END
, -1, LOW , DECODE(SIGN(sal-3000), -1, AVERAGE , HIGH )) FROM emp; - 참고 : SIGN 함수는 인자가 음수이면 -1, zero이면 0, 양수이면 1을 리턴한다. CASE WHEN sal < 2000 THEN LOW WHEN sal < 3000 THEN AVERAGE ELSE HIGH END .")
263
1. 1 CASE 함수의 활용 1.1.1 중첩 CASE 문 SELECT ename, sal, CASE WHEN sal > 2000 THEN 1000 ELSE (CASE WHEN sal > 1000 THEN 500 ELSE 0 END) END AS BONUS FROM emp;
 END AS BONUS FROM emp;")
264
1. 1 CASE 함수의 활용 1.1.1 GROUP BY 절에 사용된 CASE 문
SELECT CASE WHEN deptno < 21 THEN 'Part I' ELSE 'Part II' END AS GRAND_PART, AVG(CASE WHEN sal > 2000 THEN sal ELSE (CASE WHEN sal > 1500 THEN 1000 ELSE 0 END) END) AS REVISED_SALARY FROM emp GROUP BY CASE WHEN deptno < 21 ELSE 'Part II' END;
 END) AS REVISED_SALARY FROM emp GROUP BY CASE WHEN deptno < 21 ELSE Part II END;")
265
2. SUM(DECODE) PIVOT 테이블 형식의 출력을 만드는 방법
 PIVOT 테이블 형식의 출력을 만드는 방법")
266
아래와 같은 형식으로 폭은 길고, 길이는 짧은 형태의 보고서를 만드는 방법은?
예제> EMP 테이블에서 deptno 및 job 별 사원들의 sal 합계를 출력하시오. SELECT deptno, job, SUM(sal) FROM emp GROUP BY deptno, job; 아래와 같은 형식으로 폭은 길고, 길이는 짧은 형태의 보고서를 만드는 방법은?
 FROM emp GROUP BY deptno, job; 아래와 같은 형식으로 폭은 길고, 길이는 짧은 형태의 보고서를 만드는 방법은")
267
예제> EMP 테이블에서 DEPTNO 및 입사월별 평균 SAL을 출력하시오. 출력은 다음과 같은 형식이어야 한다.
1단계 : 필요한 데이터를 준비한다. 참고. EXTRACT는 날짜형의 입력값에서 지정된 부 분을 추출 SELECT ename, deptno, EXTRACT(MONTH FROM hiredate) MONTH, sal FROM emp;
 MONTH, sal FROM emp;")
268
2단계 : 출력 형식에서 GROUP BY를 수행해야 할 컬럼인 deptno와 입사월 중에 가로로 펼쳐질 컬럼 (입사월)을 DECODE 혹은 CASE를 이용하여 분류한다.
SELECT ename, deptno, DECODE(month, 1, sal) m01, DECODE(month, 2, sal) m02, DECODE(month, 3, sal) m03, DECODE(month, 4, sal) m04, DECODE(month, 5, sal) m05, DECODE(month, 6, sal) m06, DECODE(month, 7, sal) m07, DECODE(month, 8, sal) m08, DECODE(month, 9, sal) m09, DECODE(month, 10, sal) m10, DECODE(month, 11, sal) m11, DECODE(month, 12, sal) m12 FROM (SELECT ename, deptno, EXTRACT(MONTH FROM hiredate) month, sal FROM emp);
 m01, DECODE(month, 2, sal) m02, DECODE(month, 3, sal) m03, DECODE(month, 4, sal) m04, DECODE(month, 5, sal) m05, DECODE(month, 6, sal) m06, DECODE(month, 7, sal) m07, DECODE(month, 8, sal) m08, DECODE(month, 9, sal) m09, DECODE(month, 10, sal) m10, DECODE(month, 11, sal) m11, DECODE(month, 12, sal) m12. FROM (SELECT ename, deptno, EXTRACT(MONTH FROM hiredate) month, sal FROM emp);")
269
3단계 : GROUP BY 해야 할 나머지 컬럼인 deptno로 분류한다.
SELECT deptno, AVG(DECODE(month, 1, sal)) m01, AVG(DECODE(month, 2, sal)) m02, AVG(DECODE(month, 3, sal)) m03, AVG(DECODE(month, 4, sal)) m04, AVG(DECODE(month, 5, sal)) m05, AVG(DECODE(month, 6, sal)) m06, AVG(DECODE(month, 7, sal)) m07, AVG(DECODE(month, 8, sal)) m08, AVG(DECODE(month, 9, sal)) m09, AVG(DECODE(month, 10, sal)) m10, AVG(DECODE(month, 11, sal)) m11, AVG(DECODE(month, 12, sal)) m12 FROM (SELECT ename, deptno, EXTRACT(MONTH FROM hiredate) month, sal FROM emp) GROUP BY deptno ORDER BY deptno;
) m01, AVG(DECODE(month, 2, sal)) m02, AVG(DECODE(month, 3, sal)) m03, AVG(DECODE(month, 4, sal)) m04, AVG(DECODE(month, 5, sal)) m05, AVG(DECODE(month, 6, sal)) m06, AVG(DECODE(month, 7, sal)) m07, AVG(DECODE(month, 8, sal)) m08, AVG(DECODE(month, 9, sal)) m09, AVG(DECODE(month, 10, sal)) m10, AVG(DECODE(month, 11, sal)) m11, AVG(DECODE(month, 12, sal)) m12. FROM (SELECT ename, deptno, EXTRACT(MONTH FROM hiredate) month, sal FROM emp) GROUP BY deptno. ORDER BY deptno;")
270
예제> EMP 테이블에서 deptno 및 job 별 사원들의 sal 합계를 출력하시오.
1단계 : 연산에 필요한 데이터 준비 SELECT deptno, job, sal FROM emp;

271
2단계 : GROUP BY 해야 할 컬럼 중에 가로로 펼쳐질 컬럼인 job을 CASE 또는 DECODE로 분류
SELECT deptno, CASE job WHEN 'CLERK' THEN sal END "CLERK", CASE job WHEN 'MANAGER' THEN sal END "MANAGER", CASE job WHEN 'PRESIDENT' THEN sal END "PRESIDENT", CASE job WHEN 'ANALYST' THEN sal END "ANALYST", CASE job WHEN 'SALESMAN' THEN sal END "SALESMAN" FROM emp;

272
3단계 : GROUP BY 해야 할 나머지 컬럼인 deptno로 분류
SELECT deptno, SUM(CASE job WHEN 'CLERK' THEN sal END) "CLERK", SUM(CASE job WHEN 'MANAGER' THEN sal END) "MANAGER", SUM(CASE job WHEN 'PRESIDENT' THEN sal END) "PRESIDENT", SUM(CASE job WHEN 'ANALYST' THEN sal END) "ANALYST", SUM(CASE job WHEN 'SALESMAN' THEN sal END) "SALESMAN" FROM emp GROUP BY deptno;
 CLERK , SUM(CASE job WHEN MANAGER THEN sal END) MANAGER , SUM(CASE job WHEN PRESIDENT THEN sal END) PRESIDENT , SUM(CASE job WHEN ANALYST THEN sal END) ANALYST , SUM(CASE job WHEN SALESMAN THEN sal END) SALESMAN FROM emp. GROUP BY deptno;")
273
참고 : 가장 오른쪽 컬럼에 Sub-total을 포함시키는 방법
SELECT deptno, SUM(CASE job WHEN 'CLERK' THEN sal END) "CLERK", SUM(CASE job WHEN 'MANAGER' THEN sal END) "MANAGER", SUM(CASE job WHEN 'PRESIDENT' THEN sal END) "PRESIDENT", SUM(CASE job WHEN 'ANALYST' THEN sal END) "ANALYST", SUM(CASE job WHEN 'SALESMAN' THEN sal END) "SALESMAN“ SUM(sal) "TOTAL" FROM emp GROUP BY deptno;
 CLERK , SUM(CASE job WHEN MANAGER THEN sal END) MANAGER , SUM(CASE job WHEN PRESIDENT THEN sal END) PRESIDENT , SUM(CASE job WHEN ANALYST THEN sal END) ANALYST , SUM(CASE job WHEN SALESMAN THEN sal END) SALESMAN SUM(sal) TOTAL FROM emp. GROUP BY deptno;")
274
참고 : 가장 마지막 라인에 Sub-total을 포함시키는 방법
SELECT deptno, SUM(CASE job WHEN 'CLERK' THEN sal END) "CLERK", SUM(CASE job WHEN 'MANAGER' THEN sal END) "MANAGER", SUM(CASE job WHEN 'PRESIDENT' THEN sal END) "PRESIDENT", SUM(CASE job WHEN 'ANALYST' THEN sal END) "ANALYST", SUM(CASE job WHEN 'SALESMAN' THEN sal END) "SALESMAN“ SUM(sal) "TOTAL" FROM emp GROUP BY ROLLUP(deptno);
 CLERK , SUM(CASE job WHEN MANAGER THEN sal END) MANAGER , SUM(CASE job WHEN PRESIDENT THEN sal END) PRESIDENT , SUM(CASE job WHEN ANALYST THEN sal END) ANALYST , SUM(CASE job WHEN SALESMAN THEN sal END) SALESMAN SUM(sal) TOTAL FROM emp. GROUP BY ROLLUP(deptno);")
275
2.1 효율적인 함수 사용법 집계함수 혹은 그룹함수는 입력값으로 NULL이 포함되면 NULL은 제외하고 연산을 수행한다.
예제 > emp 테이블에서 comm 컬럼의 전체 합계를 출력하시오. 출력 결과가 NULL인 경우는 0을 출력하시오. SELECT SUM(NVL(comm, 0)) FROM emp; 비효율 발생 : emp 테이블에 저장된 행만큼 NVL을 반복 수행한다. SELECT NVL(SUM(comm)) FROM emp; 집계 함수는 NULL 값을 제외하고 연산하므로, 집계 함수 적용 전에 NVL을 함수를 적용할 필요는 없고, 집계 결과에 대해서만 한번 적용하면 된다.
) FROM emp; 비효율 발생 : emp 테이블에 저장된 행만큼 NVL을 반복 수행한다. SELECT NVL(SUM(comm)) FROM emp; 집계 함수는 NULL 값을 제외하고 연산하므로, 집계 함수 적용 전에 NVL을 함수를 적용할 필요는 없고, 집계 결과에 대해서만 한번 적용하면 된다.")
276
3. CARTESIAN PRODUCT 3.1 CARTESIAN PRODUCT에 대한 개요
- 모든 가능한 행들의 조합이 표시된다. - 첫 번째 테이블의 모든 행들은 두 번째 테이블의 모든 행들과 조인된다. Cartesian Product가 발생하는 경우 - WHERE 조건이 없는 조인 - WHERE 조건은 있으나, 테이블 간 조인 조건이 없는 조인

277
예제> SELECT e.ename, d.dname FROM dept d, emp e; -- 4건(dept) X 14건(emp) -> 56건
 X 14건(emp) -> 56건")
278
3.2 CARTESIAN PRODUCT에 있어 자주 사용하는 방법
DEPT 테이블의 행들을 2벌의 복제본을 만들려면, DEPT 테이블과 2건의 행 과 Cartesian Product를 수행하면 된다. SELECT d.deptno, d.dname, d.loc, t.no FROM dept d, (SELECT rownum no FROM dept where rownum<=2) t;
 t;")
279
N개의 복사본을 만들기 위해서는 N개의 행을 가진 테이블이 필요
예제> DEPT 테이블의 모든 행을 2번 복제하시오 임의의 테이블에 대하여 ROWNUM 조건 활용 SELECT d.deptno, d.dname, d.loc, t.no FROM dept d, (SELECT rownum no FROM dept where rownum<=2) t; DUAL 활용 FROM dept d, (SELECT 1 no FROM dual UNION ALL SELECT 2 no FROM dual) t;
 t; DUAL 활용. FROM dept d, (SELECT 1 no FROM dual UNION ALL. SELECT 2 no FROM dual) t;")
280
임시 테이블을 만들어 활용 CREATE TABLE copy_t 부터 100의 값을 갖는 테이블 생성 AS SELECT ROWNUM col1 FROM emp, emp WHERE ROWNUM<=100; CREATE INDEX copy_t_col1_idx ON copy_t(col1); -- 인덱스 정의 SELECT d.deptno, d.dname, d.loc, t.col1 FROM dept d, copy_t WHERE col1 <= 2; DUAL과 CONNECT BY 사용 SELECT d.deptno, d.dname, d.loc, t.no FROM dept d, (SELECT level no FROM dual CONNECT BY level <= 2);
; -- 인덱스 정의. SELECT d.deptno, d.dname, d.loc, t.col1. FROM dept d, copy_t. WHERE col1 <= 2; DUAL과 CONNECT BY 사용. SELECT d.deptno, d.dname, d.loc, t.no. FROM dept d, (SELECT level no FROM dual CONNECT BY level <= 2);")
281
예제> 다음 문장은 UNION ALL로 결합된 문장이 각각 수행되므로, 각 문장 별로 EMP 테이블이 매번 읽혀진다
예제> 다음 문장은 UNION ALL로 결합된 문장이 각각 수행되므로, 각 문장 별로 EMP 테이블이 매번 읽혀진다. 데이터 복제를 수행하여 EMP 테이블을 한번만 읽고 처리되도록 수정해보자. SELECT '직군별' class, job, COUNT(*) FROM emp GROUP BY job UNION ALL SELECT '부서별' class, TO_CHAR(deptno) deptno, count(*) GROUP BY deptno SELECT '총인원' class, NULL, COUNT(*) FROM emp;
 FROM emp GROUP BY job UNION ALL SELECT 부서별 class, TO_CHAR(deptno) deptno, count(*) GROUP BY deptno SELECT 총인원 class, NULL, COUNT(*) FROM emp;")
283
3.2.1 다른 SQL 상에서 사용하고 있는 테이블과 ROWNUM 조건 활용
SELECT /*+ rule */ DECODE(t.rn, 1, '직군별', 2, '부서별', '총인원') class, DECODE(t.rn, 1, job, 2, deptno, NULL) deptno, COUNT(*) FROM emp, (SELECT ROWNUM rn FROM dept WHERE ROWNUM<=3) t GROUP BY DECODE(t.rn, 1, '직군별', 2, '부서별', '총인원'), DECODE(t.rn, 1, job, 2, deptno, NULL) ORDER BY 1, 2;
 class, DECODE(t.rn, 1, job, 2, deptno, NULL) deptno, COUNT(*) FROM emp, (SELECT ROWNUM rn FROM dept WHERE ROWNUM<=3) t. GROUP BY DECODE(t.rn, 1, 직군별 , 2, 부서별 , 총인원 ), DECODE(t.rn, 1, job, 2, deptno, NULL) ORDER BY 1, 2;")
285
3.2.2 DUAL 활용 SELECT DECODE(t.rn, 1, '직군별', 2, '부서별', '총인원') class, DECODE(t.rn, 1, job, 2, deptno, NULL) deptno, COUNT(*) FROM emp, (SELECT 1 rn FROM dual UNION ALL SELECT 2 rn FROM dual UNION ALL SELECT 3 rn FROM dual) t GROUP BY DECODE(t.rn, 1, '직군별', 2, '부서별', '총인원'), DECODE(t.rn, 1, job, 2, deptno, NULL) ORDER BY 1, 2;
 class, DECODE(t.rn, 1, job, 2, deptno, NULL) deptno, COUNT(*) FROM emp, (SELECT 1 rn FROM dual UNION ALL SELECT 2 rn FROM dual UNION ALL SELECT 3 rn FROM dual) t GROUP BY DECODE(t.rn, 1, 직군별 , 2, 부서별 , 총인원 ), DECODE(t.rn, 1, job, 2, deptno, NULL) ORDER BY 1, 2;")
287
3.2.3 임시성 테이블 활용 SELECT DECODE(t.rn, 1, '직군별', 2, '부서별', '총인원') class, DECODE(t.rn, 1, job, 2, deptno, NULL) deptno, COUNT(*) FROM emp, (SELECT col1 rn FROM copy_t WHERE col1 <= 3) t GROUP BY DECODE(t.rn, 1, '직군별', 2, '부서별', '총인원'), DECODE(t.rn, 1, job, 2, deptno, NULL) ORDER BY 1, 2;
 class, DECODE(t.rn, 1, job, 2, deptno, NULL) deptno, COUNT(*) FROM emp, (SELECT col1 rn FROM copy_t WHERE col1 <= 3) t GROUP BY DECODE(t.rn, 1, 직군별 , 2, 부서별 , 총인원 ), DECODE(t.rn, 1, job, 2, deptno, NULL) ORDER BY 1, 2;")
289
3.3 Cross Join을 이용한 레코드 생성 Cross Join을 이용하여 열을 행으로 복제
비정규형 데이터를 정규형 데이터로 변환 SUM(DECODE)와 반대 개념 예제> 다음과 같은 테이블을 생성하자. emp_sal은 사원들의 분기별 급여 합계이다. CREATE TABLE emp_sal AS SELECT 'JSC' ename, 1000 Q1, 2000 Q2, 3000 Q3, 4000 Q4 FROM DUAL UNION ALL SELECT 'JYJ', 1500, 2500, 3500, 4500 FROM DUAL; SELECT * FROM emp_sal;
와 반대 개념. 예제> 다음과 같은 테이블을 생성하자. emp_sal은 사원들의 분기별 급여 합계이다. CREATE TABLE emp_sal. AS SELECT JSC ename, 1000 Q1, 2000 Q2, 3000 Q3, 4000 Q4 FROM DUAL. UNION ALL. SELECT JYJ , 1500, 2500, 3500, 4500 FROM DUAL; SELECT * FROM emp_sal;")
290
1) EMP_SAL 테이블의 모든 행을 4번 복제해야 하므로, 4건 이상의 행이 저장된 테이블이 필요함
1) EMP_SAL 테이블의 모든 행을 4번 복제해야 하므로, 4건 이상의 행이 저장된 테이블이 필요함. -> 다양한 방법이 있지만 임시 테이블(CROSS_TAB)을 생성하는 방법을 사용 CREATE TABLE cross_tab AS SELECT ROWNUM no, LPAD(ROWNUM, 3, '0') no2 FROM emp, emp WHERE ROWNUM <= 100; CREATE INDEX cross_tab_no_idx ON cross_tab(no); CREATE INDEX cross_tab_no2_idx ON cross_tab(no2); SELECT * FROM cross_tab;
 EMP_SAL 테이블의 모든 행을 4번 복제해야 하므로, 4건 이상의 행이 저장된 테이블이 필요함. -> 다양한 방법이 있지만 임시 테이블(CROSS_TAB)을 생성하는 방법을 사용 CREATE TABLE cross_tab AS SELECT ROWNUM no, LPAD(ROWNUM, 3, 0 ) no2 FROM emp, emp WHERE ROWNUM <= 100; CREATE INDEX cross_tab_no_idx ON cross_tab(no); CREATE INDEX cross_tab_no2_idx ON cross_tab(no2); SELECT * FROM cross_tab;")
291
2) EMP_SAL을 CROSS_TAB과 Cartesian Product로 복제하고, DECODE를 사용하여 결과를 가공 SELECT a.ename, b.no qtr_gbn, DECODE(b.no, 1, q1, 2, q2, 3, q3, 4, q4) sal FROM emp_sal a, cross_tab b WHERE b.no < 5 ORDER BY 1, 2;
 EMP_SAL을 CROSS_TAB과 Cartesian Product로 복제하고, DECODE를 사용하여 결과를 가공 SELECT a.ename, b.no qtr_gbn, DECODE(b.no, 1, q1, 2, q2, 3, q3, 4, q4) sal FROM emp_sal a, cross_tab b WHERE b.no < 5 ORDER BY 1, 2;")
292
4. ROLLUP & CUBE 다양한 소계(Sub-total)을 연산 할 수 있는 함수
ROLLUP, CUBE를 GROUP BY에 사용 예제> 아래 3개의 문장을 하나의 문장으로 결합 할 수 없는가? SELECT deptno, job, SUM(sal) FROM emp GROUP BY deptno, job; SELECT job, SUM(sal) FROM emp GROUP BY job; SELECT SUM(sal) FROM emp;
 FROM emp. GROUP BY deptno, job; SELECT job, SUM(sal) FROM emp. GROUP BY job; SELECT SUM(sal) FROM emp;")
293
- UNION ALL을 사용하는 방법. EMP 테이블을 여러 번 읽는다
- UNION ALL을 사용하는 방법. EMP 테이블을 여러 번 읽는다. SELECT deptno, job, SUM(sal) FROM emp GROUP BY deptno, job UNION ALL SELECT NULL, job, SUM(sal) FROM emp GROUP BY job SELECT NULL, NULL, SUM(sal) FROM emp;
 FROM emp GROUP BY deptno, job UNION ALL SELECT NULL, job, SUM(sal) FROM emp GROUP BY job SELECT NULL, NULL, SUM(sal) FROM emp;")
294
- ROLLUP을 사용하는 방법 SELECT deptno, job, SUM(sal) FROM emp GROUP BY ROLLUP(deptno, job);
 FROM emp GROUP BY ROLLUP(deptno, job);")
295
- ROLLUP(a, b) SELECT … FROM … GROUP BY a, b UNION ALL GROUP BY a
- CUBE(a, b) SELECT … FROM … GROUP BY a, b UNION ALL GROUP BY a GROUP BY b
 SELECT … FROM … GROUP BY a, b. UNION ALL. GROUP BY a. GROUP BY b.")
296
- CUBE SELECT deptno, job, SUM(sal) FROM emp GROUP BY CUBE(deptno, job);
 FROM emp GROUP BY CUBE(deptno, job);")
297
4.1 GROUP BY DNAME, JOB DEPT와 EMP를 조인하여 DNAME 및 JOB 별 인원수, 급여 합계를 출력하시오. SELECT dname, job, COUNT(*) "Total Empl", SUM(sal) "Total Sal" FROM emp, dept WHERE emp.deptno=dept.deptno GROUP BY dname, job; DNAME 별 인원합계, 급여합계와 전체 인원, 전체 급여 합계를 추가하려면
 Total Empl , SUM(sal) Total Sal FROM emp, dept WHERE emp.deptno=dept.deptno GROUP BY dname, job; DNAME 별 인원합계, 급여합계와. 전체 인원, 전체 급여 합계를 추가하려면.")
298
SELECT dname, job, COUNT(
SELECT dname, job, COUNT(*) "Total Empl", SUM(sal) "Total Sal" FROM emp, dept WHERE emp.deptno=dept.deptno GROUP BY dname, job UNION ALL SELECT dname, NULL, COUNT(*) "Total Empl", SUM(sal) "Total Sal" GROUP BY dname SELECT NULL, NULL, COUNT(*) "Total Empl", SUM(sal) "Total Sal" ORDER BY 1, 2;
 Total Empl , SUM(sal) Total Sal FROM emp, dept WHERE emp.deptno=dept.deptno GROUP BY dname, job UNION ALL SELECT dname, NULL, COUNT(*) Total Empl , SUM(sal) Total Sal GROUP BY dname SELECT NULL, NULL, COUNT(*) Total Empl , SUM(sal) Total Sal ORDER BY 1, 2;")
299
EMP 테이블을 여러 번 반복해서 읽어야 하며, 조인 연산도 반복되므로 비효율적이다.

300
4.2 GROUP BY ROLLUP(DNAME, JOB)
SELECT dname, job, COUNT(*) "Total Empl", SUM(sal) "Total Sal" FROM emp, dept WHERE emp.deptno=dept.deptno GROUP BY ROLLUP(dname, job) ORDER BY 1, 2;
 Total Empl , SUM(sal) Total Sal FROM emp, dept WHERE emp.deptno=dept.deptno GROUP BY ROLLUP(dname, job) ORDER BY 1, 2;")
301
4.3 GROUP BY CUBE(DNAME, JOB)
SELECT dname, job, COUNT(*) "Total Empl", SUM(sal) "Total Sal" FROM emp, dept WHERE emp.deptno=dept.deptno GROUP BY CUBE(dname, job) ORDER BY 1, 2;
 Total Empl , SUM(sal) Total Sal FROM emp, dept WHERE emp.deptno=dept.deptno GROUP BY CUBE(dname, job) ORDER BY 1, 2;")
302
5. GROUPING SETS ROLLUP, CUBE는 지정된 규칙에 따라 소계(Sub-total)을 연산
을 연산")
303
5.1 합성 컬럼의 활용 SELECT dname, job, mgr, SUM(sal) "Total Sal" FROM emp, dept WHERE dept.deptno=emp.deptno GROUP BY ROLLUP(dname, (job, mgr)); GROUP BY dname, job, mgr GROUP BY dname GROUP BY {}

304
SELECT dname, job, mgr, SUM(sal) "Total Sal" FROM emp, dept WHERE dept
SELECT dname, job, mgr, SUM(sal) "Total Sal" FROM emp, dept WHERE dept.deptno=emp.deptno GROUP BY dname, job, mgr UNION ALL SELECT dname, NULL, NULL, SUM(sal) "Total Sal" GROUP BY dname SELECT NULL, NULL, NULL, SUM(sal) "Total Sal" FROM emp, dept WHERE dept.deptno=emp.deptno;
 Total Sal FROM emp, dept WHERE dept.deptno=emp.deptno GROUP BY dname, job, mgr UNION ALL SELECT dname, NULL, NULL, SUM(sal) Total Sal GROUP BY dname SELECT NULL, NULL, NULL, SUM(sal) Total Sal FROM emp, dept WHERE dept.deptno=emp.deptno;")
305
5.2 CUBE 함수와 ROLLUP 함수의 동시 사용
SELECT dname, job, mgr, SUM(sal) "Total Sal" FROM emp, dept WHERE dept.deptno=emp.deptno GROUP BY dname, CUBE(job), ROLLUP(mgr)); GROUP BY dname, job, mgr GROUP BY dname, mgr GROUP BY dname, job GROUP BY dname
 Total Sal FROM emp, dept WHERE dept.deptno=emp.deptno GROUP BY dname, CUBE(job), ROLLUP(mgr)); GROUP BY dname, job, mgr. GROUP BY dname, mgr. GROUP BY dname, job. GROUP BY dname.")
306
SELECT dname, job, mgr, SUM(sal) "Total Sal" FROM emp, dept WHERE dept
SELECT dname, job, mgr, SUM(sal) "Total Sal" FROM emp, dept WHERE dept.deptno=emp.deptno GROUP BY dname, job, mgr UNION ALL SELECT dname, job, NULL, SUM(sal) GROUP BY dname, job SELECT dname, null, mgr, SUM(sal) GROUP BY dname, mgr SELECT dname, NULL, NULL, SUM(sal) GROUP BY dname;
 Total Sal FROM emp, dept WHERE dept.deptno=emp.deptno GROUP BY dname, job, mgr UNION ALL SELECT dname, job, NULL, SUM(sal) GROUP BY dname, job SELECT dname, null, mgr, SUM(sal) GROUP BY dname, mgr SELECT dname, NULL, NULL, SUM(sal) GROUP BY dname;")
308
5.3 GROUPING SETS를 이용한 합성 컬럼의 사용
SELECT dname, job, mgr, SUM(sal) "Total Sal" FROM emp, dept WHERE dept.deptno=emp.deptno GROUP BY GROUPING SETS((dname, job, mgr), (dname, job), (job, mgr)); GROUP BY dname, job, mgr GROUP BY dname, job GROUP BY job, mgr
 Total Sal FROM emp, dept WHERE dept.deptno=emp.deptno GROUP BY GROUPING SETS((dname, job, mgr), (dname, job), (job, mgr)); GROUP BY dname, job, mgr. GROUP BY dname, job. GROUP BY job, mgr.")
309
SELECT dname, job, mgr, SUM(sal) "Total Sal" FROM emp, dept WHERE dept
SELECT dname, job, mgr, SUM(sal) "Total Sal" FROM emp, dept WHERE dept.deptno=emp.deptno GROUP BY dname, job, mgr UNION ALL SELECT dname, job, NULL, SUM(sal) GROUP BY dname, job SELECT null, job, mgr, SUM(sal) GROUP BY job, mgr;
 Total Sal FROM emp, dept WHERE dept.deptno=emp.deptno GROUP BY dname, job, mgr UNION ALL SELECT dname, job, NULL, SUM(sal) GROUP BY dname, job SELECT null, job, mgr, SUM(sal) GROUP BY job, mgr;")
311
6. Analytic Function 6.1 Syntax 복잡한 비즈니스 로직의 구현이 편리 데이터 웨어하우스에서 많이 활용
8.1.7 버전 이상에서만 사용 가능 SELECT Analytic_Function(Arguments) OVER( [Partition By 컬럼, …] [Order By 컬럼, …] [Windowing] ) FROM 테이블명 WHERE 조건… ; Analytical_Function : 분석 함수명 Arguments : 함수의 입력인자 Partition By : 지정된 컬럼을 기준으로 소그룹 구성. 생략되면 전체 테이블이 하나의 그룹 Order By : 지정된 컬럼으로 정렬 Windowing : 함수가 처리할 대상 행의 범위 6.1 Syntax
 OVER( [Partition By 컬럼, …] [Order By 컬럼, …] [Windowing] ) FROM 테이블명. WHERE 조건… ; Analytical_Function : 분석 함수명. Arguments : 함수의 입력인자. Partition By : 지정된 컬럼을 기준으로 소그룹 구성. 생략되면 전체 테이블이 하나의 그룹. Order By : 지정된 컬럼으로 정렬. Windowing : 함수가 처리할 대상 행의 범위. 6.1 Syntax.")
312
Windowing 옵션 (ROWS는 레코드를 기준으로 함) ROWS UNBOUNDED PRECEDING
ROWS N PRECEDING ROWS CURRENT ROW ROWS BETWEEN AND UNBOUNDED PRECEDING N PRECEDING CURRENT ROW N FOLLOWING UNBOUNDED FOLLOWING UNBOUNDED PRECEDING N PRECEDING CURRENT ROW N FOLLOWING UNBOUNDED FOLLOWING UNBOUNDED PRECEDING 5 PRECEDING CURRENT ROW 5 FOLLOWING UNBOUNDED FOLLOWING

313
예제> SELECT empno, ename, sal, SUM(sal) OVER (ORDER BY sal ROWS UNBOUNDED PRECEDING) c1, SUM(sal) OVER (ORDER BY sal ROWS CURRENT ROW) c2, SUM(sal) OVER (ORDER BY sal ROWS 3 PRECEDING) c3 FROM emp; = =1300 =

314
예제> SELECT empno, ename, sal, SUM(sal) OVER (ORDER BY sal ROWS BETWEEN UNBOUNDED PRECEDING AND 3 PRECEDING) c1, SUM(sal) OVER (ORDER BY sal ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) c2, SUM(sal) OVER (ORDER BY sal ROWS BETWEEN CURRENT ROW AND 2 FOLLOWING) c3, SUM(sal) OVER (ORDER BY sal ROWS BETWEEN 3 FOLLOWING AND UNBOUNDED FOLLOWING) c4 FROM emp; = = = =

315
Windowing 옵션 (RANGE는 값을 기준으로 함) RANGE UNBOUNDED PRECEDING
RANGE N PRECEDING RANGE CURRENT ROW RANGE BETWEEN AND UNBOUNDED PRECEDING N PRECEDING CURRENT ROW N FOLLOWING UNBOUNDED FOLLOWING UNBOUNDED PRECEDING N PRECEDING CURRENT ROW N FOLLOWING UNBOUNDED FOLLOWING

316
예제> SELECT empno, ename, sal, SUM(sal) OVER (ORDER BY sal RANGE UNBOUNDED PRECEDING) c1, SUM(sal) OVER (ORDER BY sal RANGE CURRENT ROW) c2, SUM(sal) OVER (ORDER BY sal RANGE 500 PRECEDING) c3 FROM emp; Sal이 1250이하인 값들의 합계 = =1300 Sal이 1000이상 1500이하인 값들의 합계 =

317
예제> SELECT empno, ename, sal, SUM(sal) OVER (ORDER BY sal RANGE BETWEEN UNBOUNDED PRECEDING AND 300 PRECEDING) c1, SUM(sal) OVER (ORDER BY sal RANGE BETWEEN 300 PRECEDING AND CURRENT ROW) c2, SUM(sal) OVER (ORDER BY sal RANGE BETWEEN CURRENT ROW AND 300 FOLLOWING) c3, SUM(sal) OVER (ORDER BY sal RANGE BETWEEN 300 FOLLOWING AND UNBOUNDED FOLLOWING) c4 FROM emp; Sal이 1200(= )이하인 합계 = Sal이 1300(= )이상이고 1600이하인 합계 = Sal이 2450이상이고 2750(= )이하인 합계 =2450 Sal이 3150(= )이상인 합계 =5000
이하인 합계. = Sal이 1300(= )이상이고 1600이하인 합계. = Sal이 2450이상이고 2750(= )이하인 합계. =2450. Sal이 3150(= )이상인 합계. =5000.")
318
6.2 Analytic Function의 종류 그룹 내 순위 관련 RANK, DENSE_RANK, ROW_NUMBER
일반 그룹 함수 관련 AVG, SUM, MAX, MIN, COUNT 그룹 내 데이터 순서 관련 FIRST_VALUE, LAST_VALUE, LAG, LEAD 그룹 내 비율 관련 RATIO_TO_REPORT, PERCENT_RANK, CUME_DIST, NTILE 통계 분석 관련 CORR, COVAR_POP, COVAR_SAMP, STDDEV, STDDEV_POP, STDDEV_SAMP, VARIANCE, VAR_POP, VAR_SAMP 선형 분석 관련 REGR_SLOPE, REGR_INTERCEPT, REGR_COUNT, REGR_R2, REGR_AVGX, REGR_AVGY, REGR_SXX, REGR_SYY, REGR_SXY

319
그룹 내 순위 관련 SELECT deptno, ename, sal, ROW_NUMBER() OVER (PARTITION BY deptno ORDER BY sal DESC) AS rk1, RANK() OVER (PARTITION BY deptno ORDER BY sal DESC) AS rk2, DENSE_RANK() OVER (PARTITION BY deptno ORDER BY sal DESC) AS rk3 FROM emp;
 OVER (PARTITION BY deptno ORDER BY sal DESC) AS rk2, DENSE_RANK() OVER (PARTITION BY deptno ORDER BY sal DESC) AS rk3. FROM emp;")
320
일반 그룹 함수 관련 SELECT mgr, ename, hiredate, sal, AVG(sal) OVER (PARTITION BY mgr ORDER BY hiredate ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS c_mavg FROM emp;
 AS c_mavg. FROM emp;")
321
SELECT mgr, ename, sal, SUM(sal) OVER (PARTITION BY mgr ORDER BY sal ASC ROWS UNBOUNDED PRECEDING) l_csum FROM emp;
 OVER (PARTITION BY mgr ORDER BY sal ASC ROWS UNBOUNDED PRECEDING) l_csum FROM emp;")
322
SELECT mgr, ename, sal FROM (SELECT mgr, ename, sal, MAX(sal) OVER (PARTITION BY mgr) AS rmax_sal FROM emp) WHERE sal=rmax_sal;
 OVER (PARTITION BY mgr) AS rmax_sal FROM emp) WHERE sal=rmax_sal;")
323
SELECT ename, sal, COUNT(
SELECT ename, sal, COUNT(*) OVER (ORDER BY sal ASC RANGE BETWEEN 50 PRECEDING AND 150 FOLLOWING) AS mov_cnt FROM emp;
 OVER (ORDER BY sal ASC RANGE BETWEEN 50 PRECEDING AND 150 FOLLOWING) AS mov_cnt FROM emp;")
324
그룹 내 데이터 순서 관련 SELECT deptno, ename, sal, FIRST_VALUE(ename) OVER (PARTITION BY deptno ORDER BY sal DESC ROWS UNBOUNDED PRECEDING) AS rich_emp FROM emp;

325
Sal이 같은 경우, 이전 인라인 뷰의 순서를 따른다.
인라인 뷰 사용 예 SELECT deptno, empno, ename, sal, FIRST_VALUE(ename) OVER (ORDER BY sal DESC ROWS UNBOUNDED PRECEDING) AS rich_emp FROM (SELECT * FROM emp WHERE deptno=20 ORDER BY empno); Sal이 같은 경우, 이전 인라인 뷰의 순서를 따른다.
 OVER (ORDER BY sal DESC. ROWS UNBOUNDED PRECEDING) AS rich_emp. FROM (SELECT * FROM emp WHERE deptno=20 ORDER BY empno); Sal이 같은 경우, 이전 인라인 뷰의 순서를 따른다.")
326
SELECT deptno, empno, ename, sal, FIRST_VALUE(ename) OVER (ORDER BY sal DESC ROWS UNBOUNDED PRECEDING) AS rich_emp FROM (SELECT * FROM emp WHERE deptno=20 ORDER BY empno DESC);
 OVER (ORDER BY sal DESC ROWS UNBOUNDED PRECEDING) AS rich_emp FROM (SELECT * FROM emp WHERE deptno=20 ORDER BY empno DESC);")
327
- 그룹 내 데이터 순서 관련 SELECT ename, hiredate, LEAD(hiredate, 1) OVER (ORDER BY hiredate) AS "NextHired" FROM emp;
 OVER (ORDER BY hiredate) AS NextHired FROM emp;")
328
- 그룹 내 비율 관련 SELECT ename, sal, RATIO_TO_REPORT(sal) OVER () AS rr FROM emp WHERE job='SALESMAN';
 OVER () AS rr FROM emp WHERE job= SALESMAN ;")
329
7. MULTI-TABLE INSERT 원본(source) 테이블의 데이터를 여러 개의 목표(target) 테이블로 한 번에 전송하는 기능 원본 테이블을 매번 읽을 필요가 없으므로 효율적 종류 1. 무조건부(unconditional) INSERT ALL 2. 조건부(conditional) INSERT ALL 3. 조건부(conditional) INSERT FIRST
 INSERT ALL. 2. 조건부(conditional) INSERT ALL. 3. 조건부(conditional) INSERT FIRST.")
330
7.1 무조건부 INSERT ALL INTO 다음에 지정한 모든 목표 테이블에 대해서 INSERT 작업을 수행
CREATE TABLE job_yr_sal (work VARCHAR2(20), no NUMBER(6), total NUMBER(6)); CREATE TABLE job_av_com (work VARCHAR2(20), no NUMBER(6), average NUMBER(8,2)); INSERT ALL INTO job_yr_sal VALUES(job, cnt, tot_sal) INTO job_av_com VALUES(job, cnt, avg_com) SELECT job, COUNT(*) cnt, SUM(sal) tot_sal, AVG(comm) avg_com FROM emp, dept WHERE emp.deptno=dept.deptno GROUP BY job; 10건 중에 job, cnt, tot_sal 컬럼만 입력 10건 중에 job, cnt, avg_com 컬럼만 입력 10건
, no NUMBER(6), total NUMBER(6)); CREATE TABLE job_av_com. (work VARCHAR2(20), no NUMBER(6), average NUMBER(8,2)); INSERT ALL. INTO job_yr_sal VALUES(job, cnt, tot_sal) INTO job_av_com VALUES(job, cnt, avg_com) SELECT job, COUNT(*) cnt, SUM(sal) tot_sal, AVG(comm) avg_com. FROM emp, dept. WHERE emp.deptno=dept.deptno. GROUP BY job; 10건 중에 job, cnt, tot_sal 컬럼만 입력. 10건 중에 job, cnt, avg_com 컬럼만 입력. 10건.")
331
7.2 조건부 INSERT ALL INSERT ALL
CREATE TABLE regular_emp (no NUMBER(6), name VARCHAR2(20), dno NUMBER(6)); CREATE TABLE sale_emp (no NUMBER(6), name VARCHAR2(20), work VARCHAR2(20)); INSERT ALL WHEN deptno IN (SELECT deptno FROM dept) THEN INTO regular_emp VALUES(empno, ename, deptno) WHEN job IN (CLERK, SALESMAN) THEN INTO sale_emp VALUES(empno, ename, job) SELECT empno, ename, job, deptno FROM emp; 14건 중에 조건에 일치하는 14건 입력 14건 중에 조건에 일치하는 8건만 입력 14건
, name VARCHAR2(20), dno NUMBER(6)); CREATE TABLE sale_emp. (no NUMBER(6), name VARCHAR2(20), work VARCHAR2(20)); INSERT ALL. WHEN deptno IN (SELECT deptno FROM dept) THEN. INTO regular_emp VALUES(empno, ename, deptno) WHEN job IN (CLERK, SALESMAN) THEN. INTO sale_emp VALUES(empno, ename, job) SELECT empno, ename, job, deptno FROM emp; 14건 중에 조건에 일치하는 14건 입력. 14건 중에 조건에 일치하는 8건만 입력. 14건.")
332
7.3 조건부 INSERT FIRST 첫 번째로 만족하는 조건에 지정한 테이블에 대해서만 INSERT 작업 수행
CREATE TABLE special_empno (no NUMBER(6), salary NUMBER(6)); CREATE TABLE high_empno AS SELECT * FROM special_empno; CREATE TABLE normal_empno CREATE TABLE low_empno INSERT FIRST WHEN sal > THEN INTO special_empno VALUES(empno, sal) WHEN sal > 5000 THEN INTO high_empno VALUES(empno, sal) WHEN sal > 3000 THEN INTO normal_empno VALUES(empno, sal) ELSE INTO low_empno VALUES(empno, sal) SELECT empno, sal FROM emp; 0건 0건 1건 13건 14건
, salary NUMBER(6)); CREATE TABLE high_empno. AS SELECT * FROM special_empno; CREATE TABLE normal_empno. CREATE TABLE low_empno. INSERT FIRST. WHEN sal > THEN. INTO special_empno VALUES(empno, sal) WHEN sal > 5000 THEN. INTO high_empno VALUES(empno, sal) WHEN sal > 3000 THEN. INTO normal_empno VALUES(empno, sal) ELSE. INTO low_empno VALUES(empno, sal) SELECT empno, sal FROM emp; 0건. 0건. 1건. 13건. 14건.")
333
8. MERGE(UPDATE + INSERT)
두 개의 테이블을 병합 조인 조건이 만족하면 UPDATE, 만족하지 않으면 INSERT 수행 예제> 다음과 같은 테이블을 작성하시오. CREATE TABLE master_emp AS SELECT empno, ename, sal FROM emp; CREATE TABLE new_emp(empno, ename, sal) AS SELECT empno, ename, sal*1.1 FROM emp WHERE job='SALESMAN' UNION ALL SELECT 8001, 'KIM', 3000 FROM dual SELECT 8002, 'PARK', 2800 FROM dual;
 AS SELECT empno, ename, sal*1.1 FROM emp. WHERE job= SALESMAN UNION ALL. SELECT 8001, KIM , 3000 FROM dual. SELECT 8002, PARK , 2800 FROM dual;")
334
empno가 일치하면 sal을 update
new_emp master_emp empno가 존재하지 않으면 insert

335
MERGE INTO master_emp m USING new_emp n ON (m. empno=n
MERGE INTO master_emp m USING new_emp n ON (m.empno=n.empno) WHEN MATCHED THEN UPDATE SET m.sal=n.sal WHEN NOT MATCHED THEN INSERT VALUES(n.empno, n.ename, n.sal); 변경 전 master_emp 변경 후 master_emp
 WHEN MATCHED THEN UPDATE SET m.sal=n.sal WHEN NOT MATCHED THEN INSERT VALUES(n.empno, n.ename, n.sal); 변경 전 master_emp. 변경 후 master_emp.")
336
Chapter 5. 부록 최대값/최소값 구하기 SELECT MAX(SAL) FROM EMP;
CREATE INDEX EMP_SAL_IDX ON EMP(SAL); SELECT /*+ INDEX_DESC(EMP EMP_SAL_IDX) */ SAL FROM EMP WHERE ROWNUM = 1 AND SAL > 0;
; SELECT /*+ INDEX_DESC(EMP EMP_SAL_IDX) */ SAL FROM EMP. WHERE ROWNUM = 1 AND SAL > 0;")
337
정렬 작업 회피 CREATE INDEX EMP_SAL_IDX ON EMP(SAL); SELECT * FROM EMP ORDER BY SAL DESC; SELECT /*+ INDEX_DESC(EMP EMP_SAL_IDX) */ * FROM EMP WHERE SAL > 0;

338
실행 계획 분리하기 CREATE INDEX EMP_DEPTNO_IDX ON EMP(DEPTNO); SELECT * FROM EMP WHERE DEPTNO BETWEEN 10 AND 30; SELECT * FROM EMP WHERE DEPTNO IN (10, 20, 30);
;")
339
테이블 접근 회피 I CREATE INDEX EMP_ENAME_IDX ON EMP(ENAME); CREATE INDEX EMP_SAL_IDX ON EMP(SAL); ALTER TABLE EMP MODIFY (ENAME NOT NULL); ALTER TABLE EMP MODIFY (SAL NOT NULL); SELECT /*+ INDEX_JOIN(EMP EMP_ENAME_IDX EMP_SAL) */ ENAME, SAL FROM EMP;
; SELECT /*+ INDEX_JOIN(EMP EMP_ENAME_IDX EMP_SAL) */ ENAME, SAL FROM EMP;")
340
테이블 접근 회피 II CREATE INDEX EMP_ENAME_SAL_IDX ON EMP(ENAME, SAL); ALTER TABLE EMP MODIFY (ENAME NOT NULL); ALTER TABLE EMP MODIFY (SAL NOT NULL); SELECT /*+ INDEX(EMP EMP_ENAME_SAL_IDX) */ ENAME, SAL FROM EMP; SELECT /*+ INDEX_FFS(EMP EMP_ENAME_SAL_IDX) */ ENAME, SAL FROM EMP;
; SELECT /*+ INDEX(EMP EMP_ENAME_SAL_IDX) */ ENAME, SAL FROM EMP; SELECT /*+ INDEX_FFS(EMP EMP_ENAME_SAL_IDX) */ ENAME, SAL FROM EMP;")
341
FULL OUTER JOIN SELECT DNAME, ENAME FROM EMP E, DEPT D WHERE E.DEPTNO=D.DEPTNO(+) UNION WHERE E.DEPTNO(+)=D.DEPTNO;
 UNION. WHERE E.DEPTNO(+)=D.DEPTNO; .")
342
SELECT DNAME, ENAME FROM EMP E, DEPT D WHERE E. DEPTNO=D
SELECT DNAME, ENAME FROM EMP E, DEPT D WHERE E.DEPTNO=D.DEPTNO(+) UNION ALL WHERE E.DEPTNO(+)=D.DEPTNO AND E.DEPTNO IS NULL;
 UNION ALL WHERE E.DEPTNO(+)=D.DEPTNO AND E.DEPTNO IS NULL;")
343
SELECT DNAME, ENAME FROM EMP E FULL OUTER JOIN DEPT D ON E. DEPTNO=D
SELECT DNAME, ENAME FROM EMP E FULL OUTER JOIN DEPT D ON E.DEPTNO=D.DEPTNO;

Similar presentations
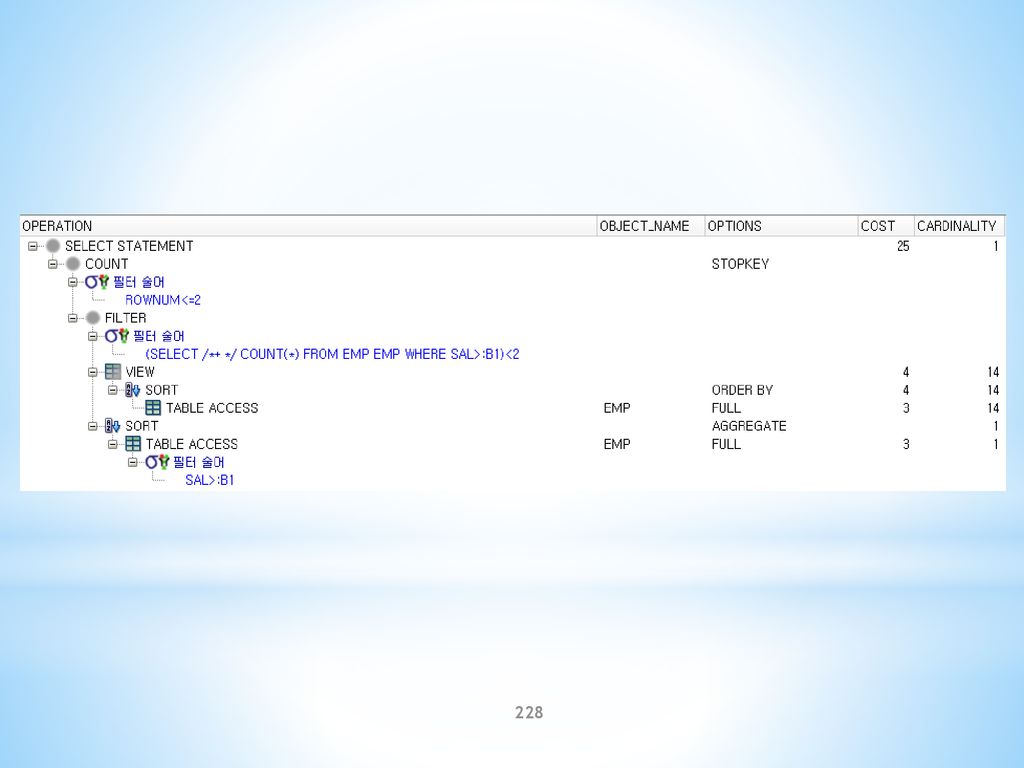
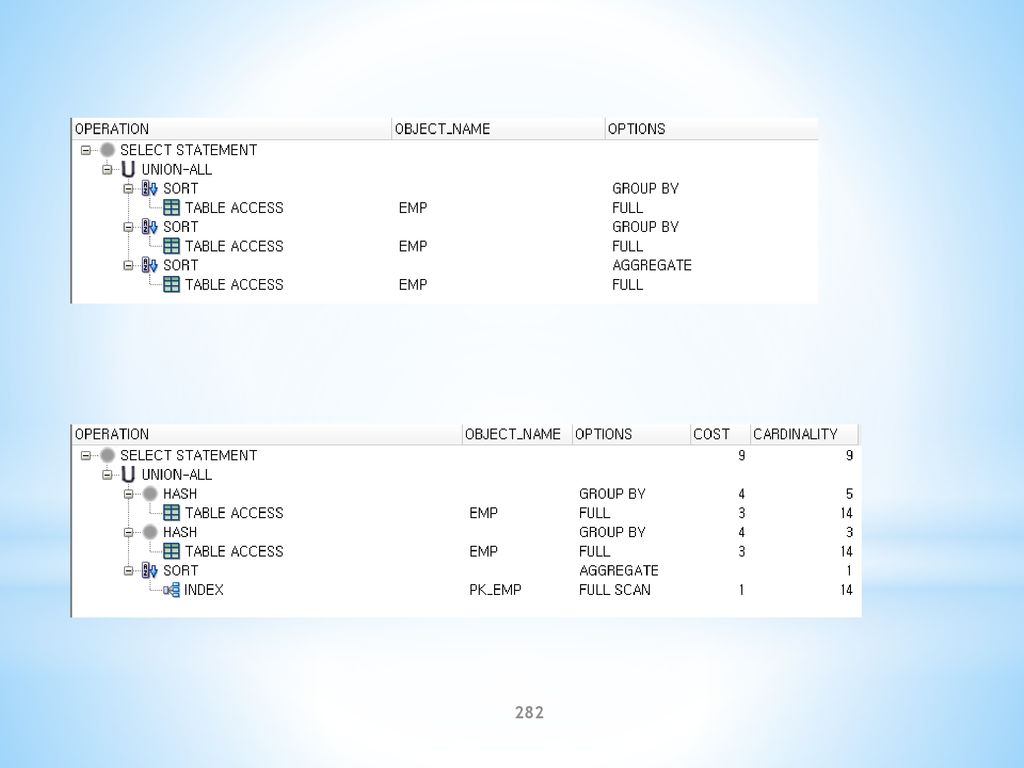
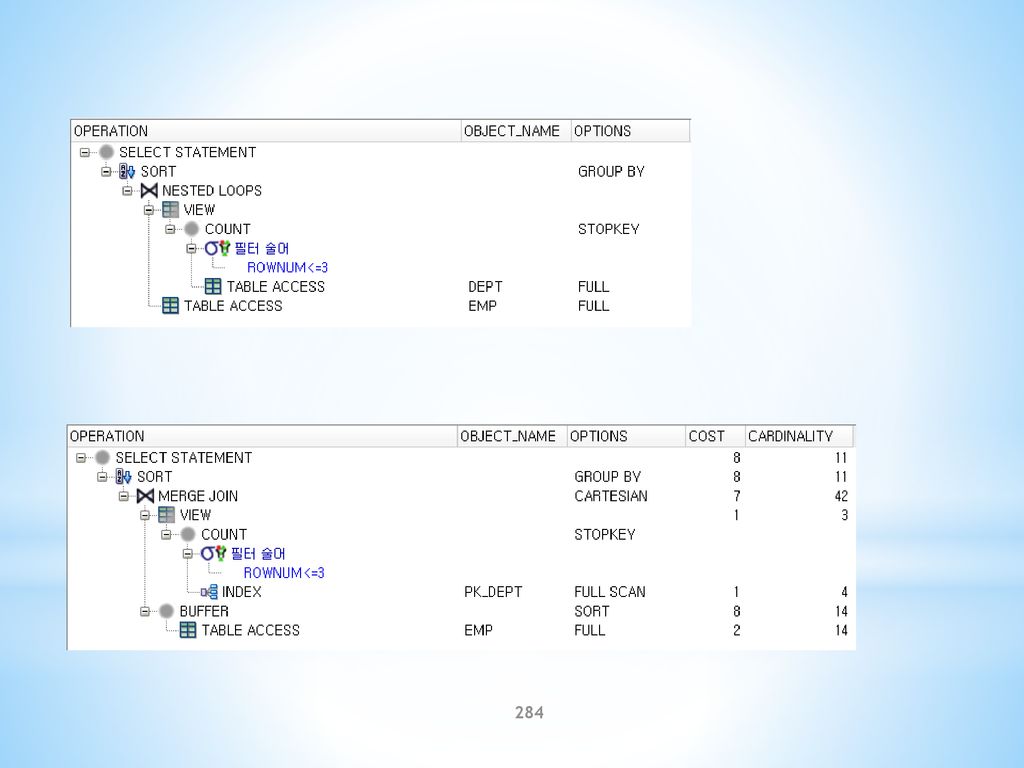
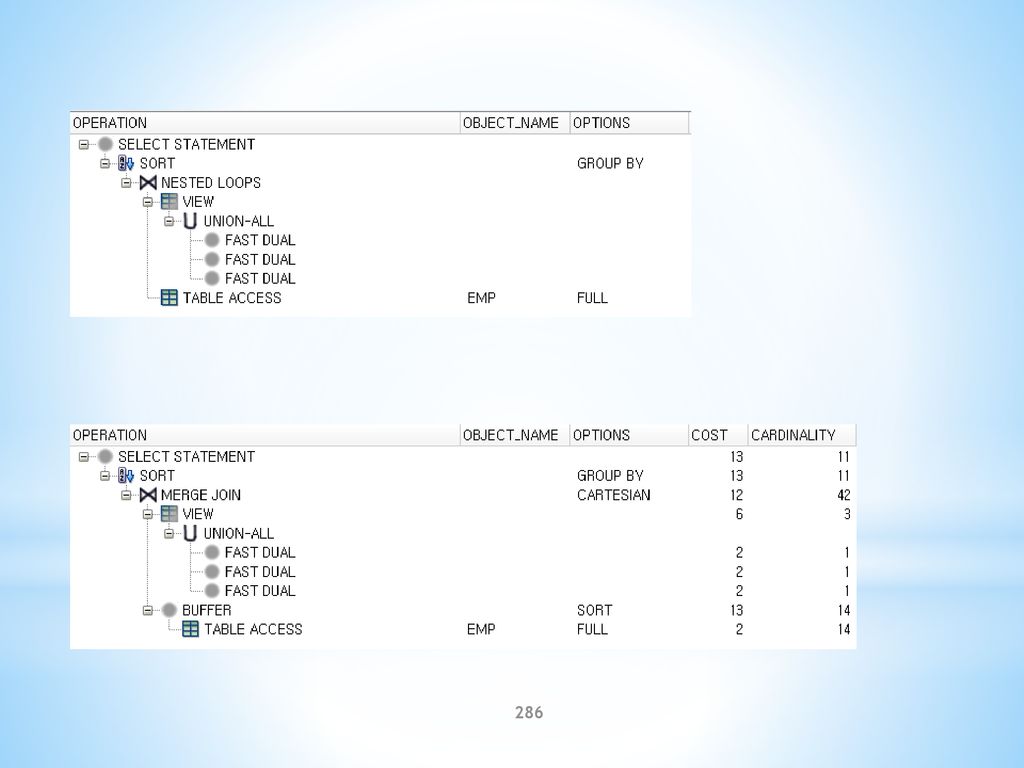
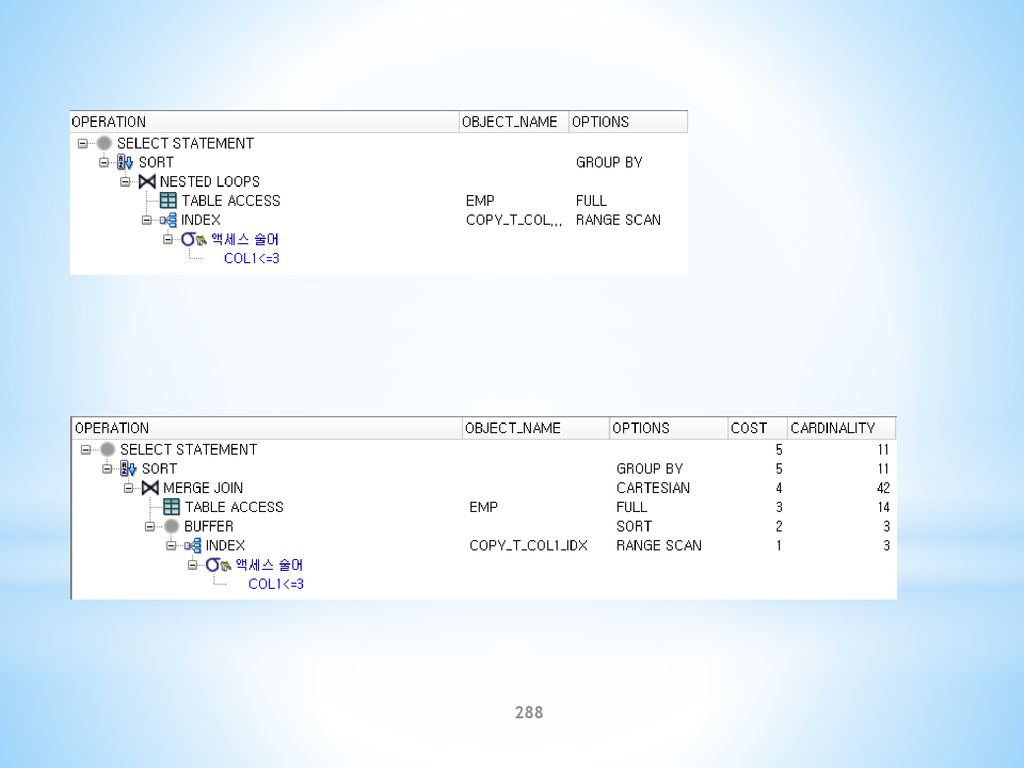

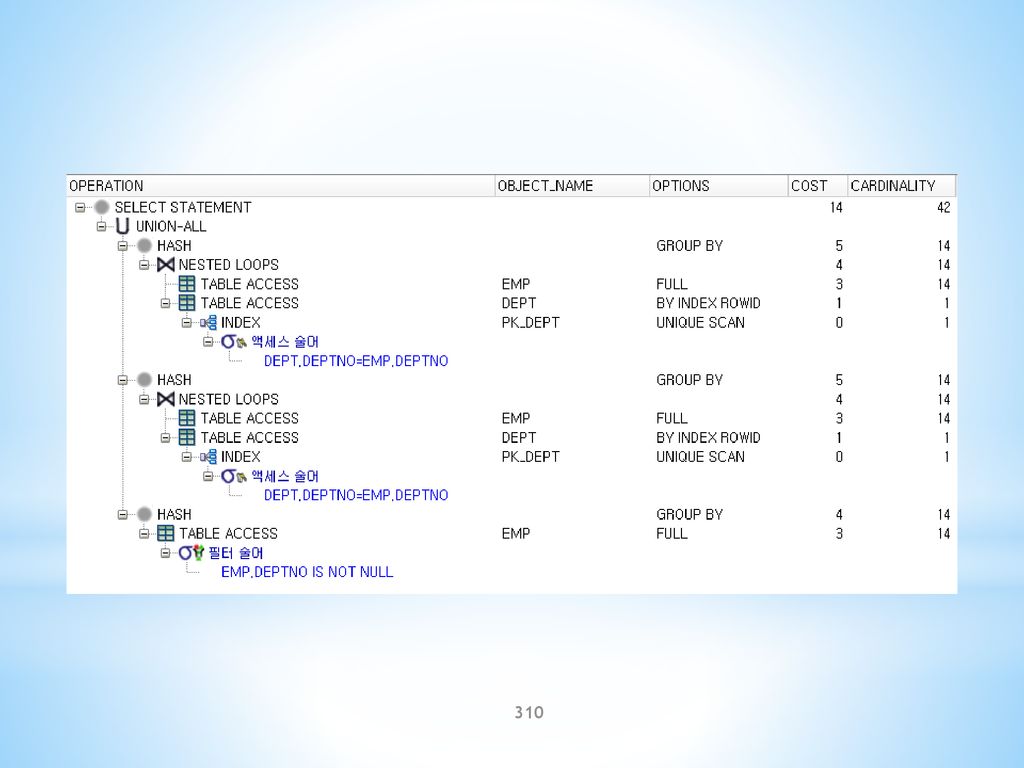
 Instance Database Buffer Cache Redo Log Buffer Library Cache Shared.>")







별,(코드)별,전체총액을 한번에>")










