Download presentation
1
데이터마이닝 데이터마이닝

2
데이터마이닝 Part I. 입문

3
데이터마이닝 제 1장 데이터마이닝 입문

4
데이터마이닝이란? * 통계적인 관점에서는 “ 대용량의 데이터로부터 이들 데이터 내에 존재하는
제 1 장 데이터마이닝 입문 데이터마이닝이란? “ 대용량의 데이터로부터 이들 데이터 내에 존재하는 관계, 패턴, 규칙 등을 탐색하고 모형화함으로써 유용한 지식을 추출하는 일련의 과정들” * 통계적인 관점에서는 “대용량 데이터에 대한 탐색적 데이터 분석 (Exploratory Data Analysis)”
")
5
데이터마이닝이란? * 통계적인 관점에서는 “ 대용량의 데이터로부터 이들 데이터 내에 존재하는
제 1 장 데이터마이닝 입문 데이터마이닝이란? “ 대용량의 데이터로부터 이들 데이터 내에 존재하는 관계, 패턴, 규칙 등을 탐색하고 모형화함으로써 유용한 지식을 추출하는 일련의 과정들” * 통계적인 관점에서는 “대용량 데이터에 대한 탐색적 데이터 분석 (Exploratory Data Analysis)”
")
6
왜 요즘 부각되는가? 자료의 효율적 저장을 위한 기술 (데이터 베이스, 압축, 통신)의 발달에 의한 데이터 양의 급속한 팽창
데이터마이닝 제 1 장 데이터마이닝 입문 왜 요즘 부각되는가? 자료의 효율적 저장을 위한 기술 (데이터 베이스, 압축, 통신)의 발달에 의한 데이터 양의 급속한 팽창 21세기 지식정보화 사회에서는 새로운 지식의 습득이 경쟁력의 원천 (예: 유전자 정보, 고객 정보 등) 거대한 데이터의 분석을 통하여 새로운 지식의 발견가능 컴퓨터 성능의 향상과 더불어 거대한 데이터의 실시간 분석 가능
의 발달에 의한 데이터 양의 급속한 팽창. 21세기 지식정보화 사회에서는 새로운 지식의 습득이 경쟁력의 원천 (예: 유전자 정보, 고객 정보 등) 거대한 데이터의 분석을 통하여 새로운 지식의 발견가능. 컴퓨터 성능의 향상과 더불어 거대한 데이터의 실시간 분석 가능.")
7
데이터마이닝 활용분야 1 데이터베이스 마케팅(Database Marketing)
제 1 장 데이터마이닝 입문 데이터마이닝 활용분야 1 데이터베이스 마케팅(Database Marketing) 데이터를 분석하여 획득한 정보를 이용하여 마케팅 전략 구축 예제: 목표마케팅(Target Marketing) 고객 세분화(Segmentation) 고객성향변동분석(Churn Analysis) 교차판매(Cross Selling) 시장바구니 분석(Market Basket Analysis)
 데이터를 분석하여 획득한 정보를 이용하여 마케팅. 전략 구축. 예제: 목표마케팅(Target Marketing) 고객 세분화(Segmentation) 고객성향변동분석(Churn Analysis) 교차판매(Cross Selling) 시장바구니 분석(Market Basket Analysis)")
8
데이터마이닝 활용분야 2 신용평가 (Credit Scoring) 특정인의 신용상태를 점수화하는 과정
제 1 장 데이터마이닝 입문 데이터마이닝 활용분야 2 신용평가 (Credit Scoring) 특정인의 신용상태를 점수화하는 과정 신용거래 대출한도를 결정하는 것이 주요 목표 이를 통하여 불량채권과 대손을 추정하여 최소화함 적용분야: 신용카드, 주택할부금융, 소비자 대출, 상업 대출
 특정인의 신용상태를 점수화하는 과정. 신용거래 대출한도를 결정하는 것이 주요 목표. 이를 통하여 불량채권과 대손을 추정하여 최소화함. 적용분야: 신용카드, 주택할부금융, 소비자 대출, 상업 대출.")
9
데이터마이닝 활용분야 3 통계적 풀질관리 (Statistical Process Control, SPC)
제 1 장 데이터마이닝 입문 데이터마이닝 활용분야 3 통계적 풀질관리 (Statistical Process Control, SPC) 불량품을 찾고 그 원인을 밝혀서 궁극적으로 이를 예방하는 것을 목적으로 함 예제 1: 의료보험조합에서는 불필요한 장기입원이나 보험료 과다청구를 탐지하려 SPC를 사용함 예제 2: 제조업체에서는 불량품 감소를 통한 이윤 증가 추구함.
 불량품을 찾고 그 원인을 밝혀서 궁극적으로 이를. 예방하는 것을 목적으로 함. 예제 1: 의료보험조합에서는 불필요한 장기입원이나. 보험료 과다청구를 탐지하려 SPC를 사용함. 예제 2: 제조업체에서는 불량품 감소를 통한 이윤. 증가 추구함.")
10
데이터마이닝 활용분야 4 부정행위 적발 (Fraud Detection) 고도의 사기행위를 발견할 수 있는 패턴을
제 1 장 데이터마이닝 입문 데이터마이닝 활용분야 4 부정행위 적발 (Fraud Detection) 고도의 사기행위를 발견할 수 있는 패턴을 자료로부터 획득 응용분야 : 신용카드 거래사기 탐지 부정수표 적발 전화카드거래사기 부당 또는 과다 보험료 청구 탐지
 고도의 사기행위를 발견할 수 있는 패턴을. 자료로부터 획득. 응용분야 : 신용카드 거래사기 탐지. 부정수표 적발. 전화카드거래사기. 부당 또는 과다 보험료 청구 탐지.")
11
데이터마이닝 활용분야 5 텍스트 마이닝 (Text Mining) 디지털화된 자료 (예: 전자우편, 신문기사 등)로 부터
제 1 장 데이터마이닝 입문 데이터마이닝 활용분야 5 텍스트 마이닝 (Text Mining) 디지털화된 자료 (예: 전자우편, 신문기사 등)로 부터 유용한 정보를 획득 응용분야: 자동응답시스템 전자도서관 Web surfing
 디지털화된 자료 (예: 전자우편, 신문기사 등)로 부터. 유용한 정보를 획득. 응용분야: 자동응답시스템. 전자도서관. Web surfing.")
12
데이터마이닝 활용분야 6 생물정보학 (Bioinformatics) 지놈(Genom)프로젝트로부터 얻은 방대한 양의
제 1 장 데이터마이닝 입문 데이터마이닝 활용분야 6 생물정보학 (Bioinformatics) 지놈(Genom)프로젝트로부터 얻은 방대한 양의 유정자 정보로부터 가치 있는 정보의 추출 예: 간암을 유발하는 유전자의 발견 응용분야: 신약개발 조기진단 유전자 치료
 지놈(Genom)프로젝트로부터 얻은 방대한 양의. 유정자 정보로부터 가치 있는 정보의 추출. 예: 간암을 유발하는 유전자의 발견. 응용분야: 신약개발. 조기진단. 유전자 치료.")
13
데이터마이닝의 특징 대용량의 관측 가능한 자료(비 계획적으로 모아진 자료)를 다룬다. 컴퓨터 중심의 기법이다.
제 1 장 데이터마이닝 입문 데이터마이닝의 특징 대용량의 관측 가능한 자료(비 계획적으로 모아진 자료)를 다룬다. 컴퓨터 중심의 기법이다. 경험적 방법이 중시된다. 일반화 (generalization)에 초점을 둔다. 즉, 현재의 자료보다 미래의 자료를 잘 설명할 수 있는 모형을 추구한다. 통계학과 컴퓨터공학 (특히, 인공지능)이 함께 방법론을 개발되고 이를 경영, 경제, 정보기술(IT)분야에서 사용한다.
를 다룬다. 컴퓨터 중심의 기법이다. 경험적 방법이 중시된다. 일반화 (generalization)에 초점을 둔다. 즉, 현재의 자료보다 미래의 자료를 잘 설명할 수 있는 모형을 추구한다. 통계학과 컴퓨터공학 (특히, 인공지능)이 함께 방법론을 개발되고 이를 경영, 경제, 정보기술(IT)분야에서 사용한다.")
14
데이터마이닝 관련분야 KDD (Knowledge Discovery in Database) 데이터베이스 안에서의 지식발견
제 1 장 데이터마이닝 입문 데이터마이닝 관련분야 KDD (Knowledge Discovery in Database) 데이터베이스 안에서의 지식발견 데이터마이닝과 가장 유사하게 사용 KDD는 지식을 추출하는 전 과정 (계획, 자료 획득, 분석, 해석 등)을 의미하고, 데이터마이닝은 KDD의 한 과정(자료의 분석)임 데이터 웨어하우징 (data warehousing), OLAP (On-Line Analytical Processing) 등도 KDD의 한 과정
 데이터베이스 안에서의 지식발견. 데이터마이닝과 가장 유사하게 사용. KDD는 지식을 추출하는 전 과정 (계획, 자료 획득, 분석, 해석 등)을 의미하고, 데이터마이닝은 KDD의 한 과정(자료의 분석)임. 데이터 웨어하우징 (data warehousing), OLAP (On-Line Analytical Processing) 등도 KDD의 한 과정.")
15
데이터마이닝 관련분야 기계학습 (Machine Learning)
제 1 장 데이터마이닝 입문 데이터마이닝 관련분야 기계학습 (Machine Learning) 인공지능 (Artificial intelligence)의 한 분야 입력되는 자료를 바탕으로 기계(컴퓨터)가 판단을 할 수 있는 방법에 대한 연구 패턴인식 (Pattern Recognition) 거대한 자료로부터 일정한 패턴을 찾아가는 과정 이미지 분류와 깊은 관련이 있음 통계학의 판별 및 분류 분석
 인공지능 (Artificial intelligence)의 한 분야. 입력되는 자료를 바탕으로 기계(컴퓨터)가 판단을 할 수 있는 방법에 대한 연구. 패턴인식 (Pattern Recognition) 거대한 자료로부터 일정한 패턴을 찾아가는 과정. 이미지 분류와 깊은 관련이 있음. 통계학의 판별 및 분류 분석.")
16
데이터마이닝 관련분야 통계학 많은 데이터마이닝 기법들이 통계학적 관점에서 비선형 함수추정 문제임 예 : 신경망 모형 대 PPR
제 1 장 데이터마이닝 입문 데이터마이닝 관련분야 통계학 많은 데이터마이닝 기법들이 통계학적 관점에서 비선형 함수추정 문제임 예 : 신경망 모형 대 PPR (Projection Pursuit Regression)
")
17
통계학과 기계학습 데이터마이닝의 용어 통 계 학 기계학습 통 계 학 기계학습 variable feature target
제 1 장 데이터마이닝 입문 데이터마이닝의 용어 통계학과 기계학습 통 계 학 기계학습 통 계 학 기계학습 dependent variable variable feature target predicted value regression/ classification supervised learning output independent variable unsupervised learning input clustering

18
데이터마이닝 기법들 OLAP (On-Line Analytic Processing)
제 1 장 데이터마이닝 입문 유전자 알고리즘 (Genetic Algorithm) OLAP (On-Line Analytic Processing) 군집분석 (Cluster Analysis) 의사 결정 나무 (Decision Tree) 데이터마이닝 기법들 인공신경망 (Artificial Neural Network) 연결분석 (Link Analysis) 사례 기반 추론(Case-Based Reasoning) 연관성 규칙발견(Association Rule Discovery, Market Basket Analysis)
 OLAP (On-Line Analytic Processing) 군집분석 (Cluster Analysis) 의사 결정 나무 (Decision Tree) 데이터마이닝. 기법들. 인공신경망 (Artificial Neural Network) 연결분석 (Link Analysis) 사례 기반 추론(Case-Based Reasoning) 연관성 규칙발견(Association Rule Discovery, Market Basket Analysis)")
19
지도학습과 자율학습 지 도 학 습 : Supervised Learning
데이터마이닝 제 1 장 데이터마이닝 입문 지도학습과 자율학습 지 도 학 습 : Supervised Learning 자 율 학 습 : Unsupervised Learning 목표변수(출력변수)가 존재하면 지도학습, 존재하지 않으면 자율학습
가 존재하면 지도학습, 존재하지 않으면 자율학습.")
20
지 도 학 습 회귀 및 분류모형 (regression and classification)
데이터마이닝 제 1 장 데이터마이닝 입문 지 도 학 습 회귀 및 분류모형 (regression and classification) 분석용 자료(입력과 출력값의 쌍)를 이용하여 주어진 입력변수에 대한 출력을 예측하는 규칙(모형)을 개발 기법: 판별분석, 회귀분석, 로지스틱 회귀분석, 의사결정나무, 신경망 등 예 : 특정 기업의 정보(재무제표 등)을 이용하여 1년 후의 회사의 파산 여부를 예측
 분석용 자료(입력과 출력값의 쌍)를 이용하여 주어진 입력변수에 대한 출력을 예측하는 규칙(모형)을 개발. 기법: 판별분석, 회귀분석, 로지스틱 회귀분석, 의사결정나무, 신경망 등. 예 : 특정 기업의 정보(재무제표 등)을 이용하여 1년. 후의 회사의 파산 여부를 예측.")
21
자 율 학 습 군집분석 (Clustering): 주어진 자료를 속성이 비슷 한 몇 개의 그룹으로 나눈다.
데이터마이닝 제 1 장 데이터마이닝 입문 자 율 학 습 군집분석 (Clustering): 주어진 자료를 속성이 비슷 한 몇 개의 그룹으로 나눈다. 연관성분석 (Association Rule): 자료들의 속성들 사이의 연관성을 파악한다. 방법: K-nearest method, SOM (Self Organizing Map) 등 예: 한국 성인 남자의 골격을 몇 개의 그룹으로 나눈 후 기성복 사이즈의 종류를 결정
: 주어진 자료를 속성이 비슷. 한 몇 개의 그룹으로 나눈다. 연관성분석 (Association Rule): 자료들의 속성들. 사이의 연관성을 파악한다. 방법: K-nearest method, SOM (Self Organizing Map) 등. 예: 한국 성인 남자의 골격을 몇 개의 그룹으로. 나눈 후 기성복 사이즈의 종류를 결정.")
22
SEMMA : 데이터마이닝의 5단계 Sampling Exploration Modification Modeling
제 1 장 데이터마이닝 입문 SEMMA : 데이터마이닝의 5단계 Sampling Exploration Modification Modeling Assessment

23
SEMMA : 데이터마이닝의 5단계 Sampling 단계 적절한 양의 표본을 원 자료로부터 추출하는 단계
제 1 장 데이터마이닝 입문 SEMMA : 데이터마이닝의 5단계 Sampling 단계 적절한 양의 표본을 원 자료로부터 추출하는 단계 시간과 비용의 절약과 함께 효율적인 모형의 구축에 필수적이다. 임의추출법, 층화추출법 등이 있다. Exploration 단계 여러 가지 자료의 탐색을 통해 기본적인 정보 (기초통계자료, 도수분포표, 평균, 분산, 비율 등)를 획득하는 단계
를 획득하는 단계.")
24
SEMMA : 데이터마이닝의 5단계 Modificaton 단계 데이터의 효율적인 사용을 위한 변수의 변환, 수량화, 그룹화
제 1 장 데이터마이닝 입문 SEMMA : 데이터마이닝의 5단계 Modificaton 단계 데이터의 효율적인 사용을 위한 변수의 변환, 수량화, 그룹화 등을 통하여 데이터를 변환하는 단계 예: 나이를 몇 개의 그룹으로 나눈다 (20대, 30대,…) Modeling 단계 데이터마이닝의 핵심 분석목적에 따라 적절한 기법을 사용하여 예측모형을 만드는 단계
 Modeling 단계. 데이터마이닝의 핵심. 분석목적에 따라 적절한 기법을 사용하여 예측모형을 만드는 단계.")
25
SEMMA : 데이터마이닝의 5단계 Assessment 단계 모형화의 결과에 대한 신뢰성, 유용성 등을 평가하는 단계
제 1 장 데이터마이닝 입문 SEMMA : 데이터마이닝의 5단계 Assessment 단계 모형화의 결과에 대한 신뢰성, 유용성 등을 평가하는 단계 도구: 리프트도표(Lift Chart), ROC(Reciever Operating Characteristic)곡선, 이익도표(Return on Investment)곡선 등
, ROC(Reciever Operating Characteristic)곡선, 이익도표(Return on Investment)곡선 등.")
26
데이터마이닝 제 1 장 데이터마이닝 입문 데이터마이닝 적용사례 1 소매업 적용사례 미국의 할인점 Wall Mart에서 매장내의 상품들과 고객들의 구매패턴의 연관성을 발견하기 위하여 연관성 규칙발견 알고리즘을 사용 데이터마이닝의 시작 기저귀와 맥주가 강한 연관성을 나타냄 기저귀와 맥주를 가까이 배치하여 매출이 증가

27
데이터마이닝 적용사례 2 신용카드회사적용사례 국내의 한 신용카드회사가 부정행위를 적발하고 이를 예방하기 위한 모형의 구축
제 1 장 데이터마이닝 입문 데이터마이닝 적용사례 2 신용카드회사적용사례 국내의 한 신용카드회사가 부정행위를 적발하고 이를 예방하기 위한 모형의 구축 기존의 카드소지자의 구매패턴을 분석하여 현재의 구매패턴이 카드소지자의 구매패턴과 틀린 경우 부정사용으로 의심 의사결정나무와 신경망 모형이 사용됨 카드의 부정사용 방지를 통하여 고객의 자산 보호 및 회사의 손해액 감소

28
데이터마이닝 제 1 장 데이터마이닝 입문 데이터마이닝 적용사례 3 의료분야 적용사례 종양의 악성/양성 판단에 의한 암 진단의 정확성을 높이기 위한 판별 및 분류분석 시행 과거의 환자들에 대해서 종양검사의 결과를 근거로(즉, 종양의 크기, 모양, 색깔 등 : 입력변수) 종양의 악성/양성 여부(출력변수)를 구별하는 분류모형을 만든 후, 새로운 환자에서 얻은 입력변수를 이용하여 암을 진단 지도학습방법 (신경망, 로지스틱 회귀모형, 의사결정나무 등)이 사용
 종양의 악성/양성 여부(출력변수)를 구별하는 분류모형을 만든 후, 새로운 환자에서 얻은 입력변수를 이용하여 암을 진단. 지도학습방법 (신경망, 로지스틱 회귀모형, 의사결정나무 등)이 사용.")
29
데이터마이닝 적용사례 4 제조업 적용사례 반도체회사에서 불량품 자동검색장치 개발 연관성 규칙과 군집분석 알고리즘을 사용
제 1 장 데이터마이닝 입문 데이터마이닝 적용사례 4 제조업 적용사례 반도체회사에서 불량품 자동검색장치 개발 연관성 규칙과 군집분석 알고리즘을 사용 정상인 반도체를 그 특성에 기반하여 몇 개의 군집으로 나눈 후, 새로운 제품이 정상제품의 군집의 범위밖에 있는 경우 불량으로 구정 불량품 감소로 인한 이익의 증대

30
데이터마이닝 적용사례 5 통신회사 적용사례 미국의 한 장거리 회사의 23%의 고객이 매년 이탈
제 1 장 데이터마이닝 입문 데이터마이닝 적용사례 5 통신회사 적용사례 미국의 한 장거리 회사의 23%의 고객이 매년 이탈 새로운 고객 한명을 유치하는데 필요한 비용이 $350. 고객성향변동관리(churn management)와 군집분석(clustering)을 이용하여 이탈의 원인을 파악 현재 고객의 40%가 이탈 가능성이 높음 이익분석(profit analysis)를 통하여 이탈가능성이 높은 고객을 상대로 한 마케팅이 효과적임이 입증 무료 통화서비스 등의 목표마케팅(target marketing)으로 이탈고객 감소와 이를 통한 이익의 증가
와 군집분석(clustering)을 이용하여 이탈의 원인을 파악. 현재 고객의 40%가 이탈 가능성이 높음. 이익분석(profit analysis)를 통하여 이탈가능성이 높은 고객을 상대로 한 마케팅이 효과적임이 입증. 무료 통화서비스 등의 목표마케팅(target marketing)으로 이탈고객 감소와 이를 통한 이익의 증가.")
31
데이터마이닝 적용시 문제점 장기적이고 구체적인 계획의 부족 데이터에 대한 준비 부족 시간차이 문제 적용상의 문제
제 1 장 데이터마이닝 입문 데이터마이닝 적용시 문제점 장기적이고 구체적인 계획의 부족 데이터에 대한 준비 부족 시간차이 문제 적용상의 문제 부서 및 프로젝트들 간의 비협조

32
데이터마이닝 솔루션들 SAS Enterprise Miner SPSS Clemetine (E-miner) Salford IBM
제 1 장 데이터마이닝 입문 데이터마이닝 솔루션들 SAS Enterprise Miner (E-miner) SPSS Clemetine IBM Intelligent Miner (I-miner) Salford CART & MARS Oracle Darwin
 SPSS. Clemetine. IBM. Intelligent Miner. (I-miner) Salford. CART & MARS. Oracle. Darwin.")
33
데이터마이닝 Part II. 지도학습

34
데이터마이닝 제 2 장 로지스틱모형 제 2장 로지스틱모형

35
데이터마이닝 제 2 장 로지스틱모형 2-1. 로지스틱 회귀모형 입문 4/23

36
로지스틱 회귀모형이란? 출력변수가 범주형 변수인 경우(분류문제)에 사용하는 회귀모형 중 하나이다.
데이터마이닝 제 2 장 로지스틱모형 로지스틱 회귀모형이란? 출력변수가 범주형 변수인 경우(분류문제)에 사용하는 회귀모형 중 하나이다. 범주가 두 개인 경우를 고려하자. 출력변수 y를 자료가 첫 번째 범주에 속하면 0으로 두 번째 범주에 속하면 1로 놓는다. 목적: 입력변수와 출력변수간의 관계를 잘 표현할 수 있는 모형 구축
에 사용하는 회귀모형. 중 하나이다. 범주가 두 개인 경우를 고려하자. 출력변수 y를 자료가 첫 번째 범주에 속하면 0으로 두 번째 범주에 속하면 1로 놓는다. 목적: 입력변수와 출력변수간의 관계를 잘 표현할 수 있는 모형 구축.")
37
선형회귀모형의 문제점 문제점 모형 y=a+bx+e
데이터마이닝 제 2 장 로지스틱모형 선형회귀모형의 문제점 모형 y=a+bx+e 문제점 a+bx=E(y|x)=0*Pr(Y=0|x)+1*Pr(Y=1|x)=Pr(Y=1|x)이고, 따라서 a+bx는 반드시 [0,1]사이의 값을 가져야 한다. 그러나,a+bx는 모든 실수의 어떤 값도 가질 수 있다. 오차 e의 분포가 정규분포가 아니다.
=0*Pr(Y=0|x)+1*Pr(Y=1|x)=Pr(Y=1|x)이고, 따라서 a+bx는 반드시 [0,1]사이의 값을 가져야 한다. 그러나,a+bx는 모든 실수의 어떤 값도 가질 수 있다. 오차 e의 분포가 정규분포가 아니다.")
38
선형회귀모형의 문제점의 해결 모형 Pr(Y=1|x)=F(a+bx)
데이터마이닝 제 2 장 로지스틱모형 선형회귀모형의 문제점의 해결 모형 Pr(Y=1|x)=F(a+bx) 여기서 함수 F(x)는 연속이고 증가하며 [0,1]사이에서 값을 갖는 함수이어야 한다. 여러 가지 F(x) 로지스틱 모형: F(x)=exp(x)/(1+exp(x)) 곰배르츠 모형: exp(-exp(x)) 프로빗 모형: F(x)가 표준정규분포의 분포함수(distribution function) 이중 로지스틱 모형이 계산의 편이성으로 인하여 가장 널리 쓰인다.
=F(a+bx) 여기서 함수 F(x)는 연속이고 증가하며 [0,1]사이에서 값을 갖는 함수이어야 한다. 여러 가지 F(x) 로지스틱 모형: F(x)=exp(x)/(1+exp(x)) 곰배르츠 모형: exp(-exp(x)) 프로빗 모형: F(x)가 표준정규분포의 분포함수(distribution function) 이중 로지스틱 모형이 계산의 편이성으로 인하여 가장 널리 쓰인다.")
39
Pr(Y=1|x)=exp(a+b*x)/(1+exp(a+b*x))
데이터마이닝 제 2 장 로지스틱모형 로지스틱 모형의 해석 모형 Pr(Y=1|x)=exp(a+b*x)/(1+exp(a+b*x)) 선형회귀모형과 마찬가지로 회귀계수 b가 가장 중요 b>0 경우에는 x가 증가하면서 y가 1이 될 확률(즉, 자료가 두 번째 범주에 속할 확률)이 커진다. 반대로, b<0 이면 x가 증가하면서 y가 1일 확률이 줄어든다.
=exp(a+b*x)/(1+exp(a+b*x)) 선형회귀모형과 마찬가지로 회귀계수 b가 가장 중요. b>0 경우에는 x가 증가하면서 y가 1이 될 확률(즉, 자료가 두 번째 범주에 속할 확률)이 커진다. 반대로, b<0 이면 x가 증가하면서 y가 1일 확률이 줄어든다.")
40
오즈비=Pr(Y=1|x+1)Pr(Y=0|x)/Pr(Y=0|x+1)Pr(Y=1|x)
데이터마이닝 제 2 장 로지스틱모형 오즈비 정의 오즈비=Pr(Y=1|x+1)Pr(Y=0|x)/Pr(Y=0|x+1)Pr(Y=1|x) 성질 오즈비=exp(b)
Pr(Y=0|x)/Pr(Y=0|x+1)Pr(Y=1|x) 성질. 오즈비=exp(b)")
41
오즈비의 의미 X가 한 단위 증가 할 때 y=1일 확률과 y=0일 확률의 비가 증가하는 양 예
데이터마이닝 제 2 장 로지스틱모형 오즈비의 의미 X가 한 단위 증가 할 때 y=1일 확률과 y=0일 확률의 비가 증가하는 양 예 x는 소득이고 y는 어떤 상품에 대한 구입여부(1=구입,0=미구입) b=3.72 소득이 한 단위 증가하면 물품을 구매하지 않을 확률에 대한 구매할 확률의 비(오즈비)가 exp(3.72)=42배 증가함을 의미한다. 오즈비는 사전확률에 의존하지 않는다. 즉, 자료의 분포가 모집단의 분포와 달라도, 오즈비는 추정할 수 있다.
 b=3.72. 소득이 한 단위 증가하면 물품을 구매하지 않을 확률에 대한 구매할 확률의 비(오즈비)가 exp(3.72)=42배 증가함을 의미한다. 오즈비는 사전확률에 의존하지 않는다. 즉, 자료의 분포가 모집단의 분포와 달라도, 오즈비는 추정할 수 있다.")
42
다중 로지스틱 회귀 입력변수가 2개 이상이고 출력변수가 범주형 자료 (범주가 2개)
데이터마이닝 제 2 장 로지스틱모형 다중 로지스틱 회귀 입력변수가 2개 이상이고 출력변수가 범주형 자료 (범주가 2개) 입력변수: x=(x1,…,xp), 출력변수:y 모형 여기서, F(x)=exp(x)/(1+exp(x)) 모수의 추정: 최대우도추정치 회귀계수의 유의성 검정: 우도비 검정을 이용
 입력변수: x=(x1,…,xp), 출력변수:y. 모형. 여기서, F(x)=exp(x)/(1+exp(x)) 모수의 추정: 최대우도추정치. 회귀계수의 유의성 검정: 우도비 검정을 이용.")
43
데이터마이닝 제 2 장 로지스틱모형 로지스틱 모형에서의 변수 선택 선형회귀모형과 마찬가지로 모든 가능한 모형, 전진선택법, 후진소거법 그리고 단계적방법 등을 모두 사용할 수 있다. 이때, 선형회귀모형에서 사용한 오차제곱합 대신에 로그우도함수 값을 사용한다. 예를 들면, 전진선택법에서는 각 단계마다 로그우도함수값의 증가량이 가장 큰 변수를 선택한다. 모형선택기준으로는 AIC(Akaike Information creteria)를 사용한다. AIC가 최대가 되는 모형을 선택한다.
를 사용한다. AIC가 최대가 되는 모형을 선택한다.")
44
예제 회사채의 신용등급(안정, 위험)과 여러 가지 재무자료들 사이의 관계를 규명한다. 입력변수: 여러 재무자료
데이터마이닝 제 2 장 로지스틱모형 예제 회사채의 신용등급(안정, 위험)과 여러 가지 재무자료들 사이의 관계를 규명한다. 입력변수: 여러 재무자료 x1: 자산대비 부채현황 지표 x2 : 현금회전율 x3: 종업원 수(50인 아하=0, 인=1, 100인 이상=2) 출력변수: 회사채 신용등급: 안정=1, 위험=0
과 여러 가지 재무자료들 사이의 관계를 규명한다. 입력변수: 여러 재무자료. x1: 자산대비 부채현황 지표. x2 : 현금회전율. x3: 종업원 수(50인 아하=0, 인=1, 100인 이상=2) 출력변수: 회사채 신용등급: 안정=1, 위험=0.")
45
예제: 가변수의 생성 x3변수가 질적변수 이므로 가변수가 필요하다. x3를 위한 가변수 z1과 z2 z1 z2 50인 이하
데이터마이닝 제 2 장 로지스틱모형 예제: 가변수의 생성 x3변수가 질적변수 이므로 가변수가 필요하다. x3를 위한 가변수 z1과 z2 z1 z2 50인 이하 50-100인 1 100인 이상

46
데이터마이닝 제 2 장 로지스틱모형 예제: 모형 가변수를 포함하는 로지스틱 회귀모형은 다음과 같다. 여기서

47
예제: 회귀계수의 추정 회귀계수의 추정 결과는 다음과 같다. 입력변수 회귀계수 표준오차 Chi-square 유의확률
데이터마이닝 제 2 장 로지스틱모형 예제: 회귀계수의 추정 회귀계수의 추정 결과는 다음과 같다. 입력변수 회귀계수 표준오차 Chi-square 유의확률 Intercept 3.5942 0.000 X1 0.3933 7.4389 0.006 X2 4.1313 7.7814 0.005 X3-1 0.6981 0.3571 3.9404 0.047 X3-2 2.6141 0.7915 0.001

48
예제: 결과의 해석 모든 변수가 작은 유의확률을 갖으므로 출력변수를 설명하는데 유의하게 작용한다.
데이터마이닝 제 2 장 로지스틱모형 예제: 결과의 해석 모든 변수가 작은 유의확률을 갖으므로 출력변수를 설명하는데 유의하게 작용한다. X1의 회귀계수의 부호가 음수인데, 이는 부채비율이 높을 수록 회사채의 신용이 낮음을 의미한다. X2의 회귀계수의 부호가 양수인데, 이는 현금회전율이 높을 수록 회사채의 신용이 높아짐을 의미한다. X3-1과 x3-2는 가변수 z1과 z2의 회귀계수의 추정치를 나타낸다.

49
데이터마이닝 제 2 장 로지스틱모형 예제: 결과의 해석(계속) X3-1의 회귀계수로부터 인 규모의 회사와 50인 미만의 회사의 회사채 신용등급의 오즈비를 구할 수 있다. 이는 exp(0.6981)=2.00으로 인 규모의 회사의 회사채가 50인 미만의 회사채에 비하여 약 2배정도 신용이 좋다고 볼 수 있다. 마찬가지로, X3-2의 회귀계수로부터 100인 이상 규모의 회사와 50인 미만의 회사의 회사채 신용등급의 오즈비를 구할 수 있다. 이는 exp(2.6141)=13.65으로 100인 이상 규모의 회사의 회사채가 50인 미만의 회사채에 비하여 약 13.65배정도 신용이 좋다고 볼 수 있다.
=2.00으로 인 규모의 회사의 회사채가 50인 미만의 회사채에 비하여 약 2배정도 신용이 좋다고 볼 수 있다. 마찬가지로, X3-2의 회귀계수로부터 100인 이상 규모의 회사와 50인 미만의 회사의 회사채 신용등급의 오즈비를 구할 수 있다. 이는 exp(2.6141)=13.65으로 100인 이상 규모의 회사의 회사채가 50인 미만의 회사채에 비하여 약 13.65배정도 신용이 좋다고 볼 수 있다.")
50
데이터마이닝 제 2 장 로지스틱모형 2-2. 로지스틱 모형을 이용한 분류 4/23

51
데이터마이닝 제 2 장 로지스틱모형 로지스틱 모형를 이용한 분류방법 주어진 입력변수 x에 대하여 로지스틱 함수를 이용하여 출력변수 Y가 1이 될 확률 P(Y=1|x) 를 추정한다. 0과 1사이의 적당한 수 c를 절단값 (cut-off value)으로 선택한다. P(Y=1|x)가 c보다 크면 자료를 Y=1인 그룹에 할당하고 P(Y=1|x)가 c보다 작으면 자료를 Y=0인 그룹에 할당한다.
으로 선택한다. P(Y=1|x)가 c보다 크면 자료를 Y=1인 그룹에 할당하고 P(Y=1|x)가 c보다 작으면 자료를 Y=0인 그룹에 할당한다.")
52
절단값의 선택 절단값 c의 결정은 여러 가지를 고려하여 결정한다. 고려사항 1: 사전정보
데이터마이닝 제 2 장 로지스틱모형 절단값의 선택 절단값 c의 결정은 여러 가지를 고려하여 결정한다. 고려사항 1: 사전정보 사전정보에 의하여 두번째 범주의 자료(y=1인 자료)가 많다면, 절단값을 작은 값으로 정한다. 고려사항 2: 손실함수 두 번째 범주의 자료를 잘못 분류(첫번째 범주로 분류)하는 손실이 첫 번째 범주의 자료를 잘못 분류하는 것에 비하여 손실 정도가 심각하게 큰 경우에는 절단값 c를 작게 잡는다. 그 외 고려사항: 전문가 의견, 민감도와 특이도 등
가 많다면, 절단값을 작은 값으로 정한다. 고려사항 2: 손실함수. 두 번째 범주의 자료를 잘못 분류(첫번째 범주로 분류)하는 손실이 첫 번째 범주의 자료를 잘못 분류하는 것에 비하여 손실 정도가 심각하게 큰 경우에는 절단값 c를 작게 잡는다. 그 외 고려사항: 전문가 의견, 민감도와 특이도 등.")
53
데이터마이닝 제 2 장 로지스틱모형 자료의 분석시 유의 사항 예: 여러 가지 재무자료를 이용하여 주어진 회사의 1년 후의 부도 가능성을 예측한다. 주어진 자료는 지난 10년간의 회사의 부도자료를 정리한 것인데, 자료 중 부도회사의 비율이 45%이다. 이 경우, 다음의 사항을 유의하여 자료를 분석하여야 한다. 자료의 분포가 모집단(우리나라 전체 기업)의 분포와 현저하게 다르다. 자료에서의 부도율은 45%인 반면에 모집단의 부도율은 3.5%(통계청 조사)이다. 부도율에 대한 사전정보(3.5%)가 이용 가능하다. 예측에 대한 손실이 현저히 다르다. 건전한 기업을 부도라고 예측하면 기회비용(대출에 대한 이자이익)의 상실만을 의미하지만, 부도기업을 건전기업으로 분류할 경우에는 대출금 전체를 손해를 본다. 따라서, 자료의 분류 시, 이러한 손실 정도의 불일치를 고려하여야 한다.
의 분포와 현저하게 다르다. 자료에서의 부도율은 45%인 반면에 모집단의 부도율은 3.5%(통계청 조사)이다. 부도율에 대한 사전정보(3.5%)가 이용 가능하다. 예측에 대한 손실이 현저히 다르다. 건전한 기업을 부도라고 예측하면 기회비용(대출에 대한 이자이익)의 상실만을 의미하지만, 부도기업을 건전기업으로 분류할 경우에는 대출금 전체를 손해를 본다. 따라서, 자료의 분류 시, 이러한 손실 정도의 불일치를 고려하여야 한다.")
54
p(y=1|x)=exp(a+bx)/(1+exp(a+bx)) p(y=1|x)=exp(a*+bx)/(1+exp(a*+bx))
데이터마이닝 제 2 장 로지스틱모형 사전정보의 고려 집단의 p(y=1)에 대한 사전정보를 p1이라 하자. 정리 자료에서의 입력변수와 출력변수와 관계가 p(y=1|x)=exp(a+bx)/(1+exp(a+bx)) 라 하자. 모집단의 사전정보를 고려하면 모집단에서의 입력변수와 출력변수와 관계는 p(y=1|x)=exp(a*+bx)/(1+exp(a*+bx)) 가 된다. 이때, a*=a+log(p1/(1-p1))
에 대한 사전정보를 p1이라 하자. 정리. 자료에서의 입력변수와 출력변수와 관계가. p(y=1|x)=exp(a+bx)/(1+exp(a+bx)) 라 하자. 모집단의 사전정보를 고려하면 모집단에서의 입력변수와. 출력변수와 관계는. p(y=1|x)=exp(a*+bx)/(1+exp(a*+bx)) 가 된다. 이때, a*=a+log(p1/(1-p1))")
55
데이터마이닝 제 2 장 로지스틱모형 사전정보의 고려(계속) 여기서, 재미있는 사실은 입력변수의 회귀계수 b는 변하지 않는다는 것이다. 즉, 입력변수와 출력변수와의 관계는 유지 된다. 이는, 앞의 강의에서 배운 내용으로, 사후추출법으로 추출된 자료인 경우에 오즈비는 변하지 않기 때문이다. 따라서, 관심이 부도확률의 추정이 아니라, 입력변수와 출력변수 사의 관계만을 조사하는 것이면, 사전확률 없이도 수행할 수 있다. 하지만, 부도 확률에 관심이 있는 경우에는 반드시 사전확률을 알아야 한다.

56
데이터마이닝 제 2 장 로지스틱모형 사전 정보를 이용한 절단값 결정 일반적으로, 확률을 추정하여 분류를 하는 경우 절단값이 0.5인 경우가 베이즈 규칙이 된다. 즉, 확률이 높은 쪽의 그룹으로 자료를 할당하는 방법이 베이즈 규칙이다. 사전정보(사전확률)가 있는 경우에는 자료로부터 계산 된 확률을 정의에 의하여 수정한 후 절단값 0.5를 사용하여 분류를 한다. 이러한 방법은, 확률을 수정하지 않고, 절단값은 0.5에서 (1-p1)으로 변경하는 것과 같다.
가 있는 경우에는 자료로부터 계산 된 확률을 정의에 의하여 수정한 후 절단값 0.5를 사용하여 분류를 한다. 이러한 방법은, 확률을 수정하지 않고, 절단값은 0.5에서 (1-p1)으로 변경하는 것과 같다.")
57
데이터마이닝 제 2 장 로지스틱모형 손실함수를 이용한 절단값 결정 분류의 두 가지 오류에 대한 손실이 현저히 다른 경우에는 손실함수를 고려하여 절단값을 결정할 수 있다. C(1|0)를 0그룹의 자료를 1그룹으로 잘못 분류 하였을 때 발생되는 손실이라 하고 c(0|1)을 1그룹의 자료를 0그룹으로 오분류한 경우의 손실이라 하자. 이 경우, 최적의 절단값으로 기대 손실을 최소로 하는 값을 찾는다. 기대손실을 최소로 하는 절단값 c는 c=C(1|0)/(C(1|0)+C(0|1)) 로 주어진다.
를 0그룹의 자료를 1그룹으로 잘못 분류 하였을 때 발생되는 손실이라 하고 c(0|1)을 1그룹의 자료를 0그룹으로 오분류한 경우의 손실이라 하자. 이 경우, 최적의 절단값으로 기대 손실을 최소로 하는 값을 찾는다. 기대손실을 최소로 하는 절단값 c는. c=C(1|0)/(C(1|0)+C(0|1)) 로 주어진다.")
58
선형 분류 로지스틱 모형을 이용한 분류방법은 모든 같은 분류 방법이다. 1. Pr(Y=1|x)>c 이면 그룹 1에 분류
데이터마이닝 제 2 장 로지스틱모형 선형 분류 로지스틱 모형을 이용한 분류방법은 모든 같은 분류 방법이다. 1. Pr(Y=1|x)>c 이면 그룹 1에 분류 2. Pr(Y=1|x)/(1-Pr(Y=1|x))> (1+c)/c이면 그룹 1에 분류 3. log(Pr(Y=1|x)/(1-Pr(Y=1|x))>log (1+c)/c이면 그룹 1에 분류 4. a+bx > log c*이면 그룹 1에 분류 % 4번은 Pr(Y=1|x)=exp(a+bx)/(1+exp(a+bx))로부터 쉽게 유도된다.
>c 이면 그룹 1에 분류. 2. Pr(Y=1|x)/(1-Pr(Y=1|x))> (1+c)/c이면 그룹 1에 분류. 3. log(Pr(Y=1|x)/(1-Pr(Y=1|x))>log (1+c)/c이면 그룹 1에 분류. 4. a+bx > log c*이면 그룹 1에 분류. % 4번은 Pr(Y=1|x)=exp(a+bx)/(1+exp(a+bx))로부터 쉽게 유도된다.")
59
선형 분류(계속) 따라서, 로지스틱 모형을 이용한 경우 두 그룹을 나누는 경계가 선형으로 주어진다.
데이터마이닝 제 2 장 로지스틱모형 선형 분류(계속) 따라서, 로지스틱 모형을 이용한 경우 두 그룹을 나누는 경계가 선형으로 주어진다. 많은 자료는 경계가 선형이 아닌 매우 복잡한 형태의 비선형성을 나타낸다. 이러한 비선형성 경계는 다항 로지스틱 회귀모형으로 추정할 수 있다. 의사결정나무나 신경망모형 등은 비선형 분류 경계를 찾는 방법들이다.
 따라서, 로지스틱 모형을 이용한 경우 두 그룹을 나누는 경계가 선형으로 주어진다. 많은 자료는 경계가 선형이 아닌 매우 복잡한 형태의 비선형성을 나타낸다. 이러한 비선형성 경계는 다항 로지스틱 회귀모형으로 추정할 수 있다. 의사결정나무나 신경망모형 등은 비선형 분류 경계를 찾는 방법들이다.")
60
Pr(Y=1|x)=exp(a+bx)/(1+exp(a+bx))
데이터마이닝 제 2 장 로지스틱모형 출력변수 값의 변경 어떤 그룹의 자료에 출력변수 값을 1로 주느냐는 분석자 임의로 결정한다. 출력변수의 값을 바꾸면, 회귀계수의 부호가 바뀐다. Case 1: 출력변수(y)를 그룹 1의 자료에 1을, 그룹 0의 자료에 0을 할당한 경우의 모형 Pr(Y=1|x)=exp(a+bx)/(1+exp(a+bx))
를 그룹 1의 자료에 1을, 그룹 0의 자료에 0을 할당한 경우의 모형. Pr(Y=1|x)=exp(a+bx)/(1+exp(a+bx))")
61
데이터마이닝 제 2 장 로지스틱모형 출력변수 값의 변경 (계속) Case 2: 출력변수(y’)를 그룹 1의 자료에 0을, 그룹 0의 자료에 1을 할당한 경우의 모형 Pr(Y’=1|x)=exp(a’+b’x)/(1+exp(a’+b’x)) 그러면 Pr(Y=1|x)=1-Pr(Y’=1|x) exp(a+bx)/(1+exp(a+bx))=1/(1+exp(a’+b’x)) 1/(exp(-a-bx)+1)=1/(1+exp(a’+b’x)) 따라서, a’=-a, b’=-b이다.
=1-Pr(Y’=1|x) exp(a+bx)/(1+exp(a+bx))=1/(1+exp(a’+b’x)) 1/(exp(-a-bx)+1)=1/(1+exp(a’+b’x)) 따라서, a’=-a, b’=-b이다.")
62
로지스틱 분류방법의 특징과 제약 실제성과 친밀성 해석상의 편리 변수선택 가능 선형성
데이터마이닝 제 2 장 로지스틱모형 로지스틱 분류방법의 특징과 제약 실제성과 친밀성 선형회귀모형과의 유사성으로 인하여 사용이 쉽다. 해석상의 편리 회귀계수와 오즈비를 이용하여 입력변수와 출력변수와 관계를 쉽게 알 수 있다. 변수선택 가능 선형회귀모형과 마찬가지로 불필요한 변수를 제거하고 필요한 소수의 변 수만을 속아낼 수 있다. 이를 통하여 모형의 예측력과 해석력을 높일 수 선형성 로지스틱모형의 변수간의 관계는 기본적으로 선형모형이다. 비선형모형 을 고려하기 위하여는 다항 로지스틱회귀모형이나 의사결정나무, 신경망 모형 등의 비모수적 방법을 사용한다.

63
데이터마이닝 제 3 장 의사결정나무 제 3장 의사결정나무

64
데이터마이닝 제 3 장 의사결정나무 3-1. 의사결정나무란?

65
의사결정나무 개요 지도학습 (분류 및 예측)의 데이터마이닝 기법 적용결과에 의해 if-then으로 표현되는 규칙이 생성
제 3 장 의사결정나무 의사결정나무 개요 지도학습 (분류 및 예측)의 데이터마이닝 기법 적용결과에 의해 if-then으로 표현되는 규칙이 생성 규칙의 이해가 쉽고 SQL과 같은 DB언어로 표현 좋은 해석력으로 널리 쓰임
의 데이터마이닝 기법. 적용결과에 의해 if-then으로 표현되는 규칙이 생성. 규칙의 이해가 쉽고 SQL과 같은 DB언어로 표현. 좋은 해석력으로 널리 쓰임.")
66
데이터마이닝 제 3 장 의사결정나무 예측력과 해석력 예측력만이 중요한 경우 예: 홍보책자 발송회사가 기대집단의 사람들이 가장 많은 반응을 보일 고객 유치방안을 위한 예측 많은 분야에서는 결정을 내리게 된데 대한 이유를 설명하는 능력이 중요함 (해석력) 예: 은행의 대출심사 결과 부적격 판정이 나온 경우 고객에게 부적격 이유를 설명하여야 함 의사결정나무는 좋은 해석력을 갖는다.
 예: 은행의 대출심사 결과 부적격 판정이 나온 경우 고객에게 부적격 이유를 설명하여야 함. 의사결정나무는 좋은 해석력을 갖는다.")
67
의사결정나무의 예 데이터마이닝 제 3 장 의사결정나무 Credit status Bad: 168 (52.0 %)
Good: 155 (48.0%) Total: 323 (100.0%) Income < 2130$ Bad: (86.7 %) Good: 22 (13.3%) Total: 165 (51.1%) Income >= 2130$ Bad: 25 (15.8 %) Good: 133 (84.2%) Total: 323 (48.9%) Job: C,D,E,F Bad: (90.5 %) Good: 15 (9.5%) Total: 158 (48.9%) Job: A,B Bad: 0 (0.0 %) Good: 7 (100.0%) Total: 7 (2.2%) Age < 25 yr Bad: 24 (49.0 %) Good: 25 (51.0%) Total: 49 (15.2%) Age >= 25 yr Bad: 1 (0.9 %) Good: 108 (99.1%) Total: 109 (33.8%) Job: D,E,F Bad: 5 (55.5 %) Good: 4 (45.5%) Total: 9 (2.8%) Job: A,B,C Bad: 19 (47.3 %) Good: 21 (52.7%) Total: 39 (12.4%)
 Total: 323 (100.0%) Income < 2130$ Bad: 143 (86.7 %) Good: 22 (13.3%) Total: 165 (51.1%) Income >= 2130$ Bad: 25 (15.8 %) Good: 133 (84.2%) Total: 323 (48.9%) Job: C,D,E,F. Bad: 143 (90.5 %) Good: 15 (9.5%) Total: 158 (48.9%) Job: A,B. Bad: 0 (0.0 %) Good: 7 (100.0%) Total: 7 (2.2%) Age < 25 yr. Bad: 24 (49.0 %) Good: 25 (51.0%) Total: 49 (15.2%) Age >= 25 yr. Bad: 1 (0.9 %) Good: 108 (99.1%) Total: 109 (33.8%) Job: D,E,F. Bad: 5 (55.5 %) Good: 4 (45.5%) Total: 9 (2.8%) Job: A,B,C. Bad: 19 (47.3 %) Good: 21 (52.7%) Total: 39 (12.4%)")
68
의사결정나무의 구성요소들 뿌리마디(root node): 나무구조가 시작되는 마디로 전체 자료로 이루어져 있다.
데이터마이닝 제 3 장 의사결정나무 의사결정나무의 구성요소들 뿌리마디(root node): 나무구조가 시작되는 마디로 전체 자료로 이루어져 있다. 자식마디(child node): 하나의 마디로부터 분리되어 나간 2개 이상의 마디들 부모마디(parent node): 주어진 마디의 상위마디 끝마디(terminal node): 자식마디가 없는 마디 중간마디(internal node): 부모마디와 자식마디가 모두 있는 마디 가지 (branch): 한의 마디로부터 끝마디 까지 연결된 일련의 마디들. 깊이 (depth): 뿌리마디부터 끝마디 까지의 중간마디의 수
: 나무구조가 시작되는 마디로 전체 자료로 이루어져 있다. 자식마디(child node): 하나의 마디로부터 분리되어 나간 2개 이상의 마디들. 부모마디(parent node): 주어진 마디의 상위마디. 끝마디(terminal node): 자식마디가 없는 마디. 중간마디(internal node): 부모마디와 자식마디가 모두 있는 마디. 가지 (branch): 한의 마디로부터 끝마디 까지 연결된 일련의 마디들. 깊이 (depth): 뿌리마디부터 끝마디 까지의 중간마디의 수.")
69
의사결정나무의 구성요소들 뿌리마디 중간마디 끝마디 데이터마이닝 제 3 장 의사결정나무 Credit status
Bad: (52.0 %) Good: 155 (48.0%) Total: 323 (100.0%) Income < 2130$ Bad: (86.7 %) Good: 22 (13.3%) Total: 165 (51.1%) Income >= 2130$ Bad: 25 (15.8 %) Good: 133 (84.2%) Total: 323 (48.9%) Job: C,D,E,F Bad: (90.5 %) Good: 15 (9.5%) Total: 158 (48.9%) Job: A,B Bad: 0 (0.0 %) Good: 7 (100.0%) Total: 7 (2.2%) Age < 25 yr Bad: 24 (49.0 %) Good: 25 (51.0%) Total: 49 (15.2%) Age >= 25 yr Bad: 1 (0.9 %) Good: 108 (99.1%) Total: 109 (33.8%) Job: D,E,F Bad: 5 (55.5 %) Good: 4 (45.5%) Total: 9 (2.8%) Job: A,B,C Bad: 19 (47.3 %) Good: 21 (52.7%) Total: 39 (12.4%) 뿌리마디 (1) 중간마디 (2) (3) (4) (5) (6) (7) 끝마디 (9) (8)
 Good: 155 (48.0%) Total: 323 (100.0%) Income < 2130$ Bad: 143 (86.7 %) Good: 22 (13.3%) Total: 165 (51.1%) Income >= 2130$ Bad: 25 (15.8 %) Good: 133 (84.2%) Total: 323 (48.9%) Job: C,D,E,F. Bad: 143 (90.5 %) Good: 15 (9.5%) Total: 158 (48.9%) Job: A,B. Bad: 0 (0.0 %) Good: 7 (100.0%) Total: 7 (2.2%) Age < 25 yr. Bad: 24 (49.0 %) Good: 25 (51.0%) Total: 49 (15.2%) Age >= 25 yr. Bad: 1 (0.9 %) Good: 108 (99.1%) Total: 109 (33.8%) Job: D,E,F. Bad: 5 (55.5 %) Good: 4 (45.5%) Total: 9 (2.8%) Job: A,B,C. Bad: 19 (47.3 %) Good: 21 (52.7%) Total: 39 (12.4%) 뿌리마디. (1) 중간마디. (2) (3) (4) (5) (6) (7) 끝마디. (9) (8)")
70
데이터마이닝 제 3 장 의사결정나무 3-2. 의사결정나무 구축방법

71
의사결정나무 구축을 위한 질문들 앞에서 소개된 의사결정나무를 보면 다음과 같은 질문을 던질 수 있다.
데이터마이닝 제 3 장 의사결정나무 의사결정나무 구축을 위한 질문들 앞에서 소개된 의사결정나무를 보면 다음과 같은 질문을 던질 수 있다. 뿌리마디의 질문이 왜 소득인가? 4번, 5번, 7번 마디들은 끝마디인 반면 6번 마디는 왜 중간마디인가? 7번 마디에 속하는 자료는 신용상태를 어떻게 결정하여야 하는가?

72
의사결정나무 구축을 위한 질문들 즉, 의사결정나무의 생성요소는 다음과 같다. 분할 기준 (splitting rule)의 선택
데이터마이닝 제 3 장 의사결정나무 의사결정나무 구축을 위한 질문들 즉, 의사결정나무의 생성요소는 다음과 같다. 분할 기준 (splitting rule)의 선택 분할을 계속할 것인지 그만 할 것 인지를 결정 (stopping rule and pruning rule) 각 끝마디에 예측값의 할당
의 선택. 분할을 계속할 것인지 그만 할 것 인지를 결정 (stopping rule and pruning rule) 각 끝마디에 예측값의 할당.")
73
데이터마이닝 제 3 장 의사결정나무 의사결정나무의 형성과정 나무의 성장(growing): 각 마디에서 적절한 최적의 분리규칙을 찾아서 나무를 성장 시킨다. 정지규칙을 만족하면 성장을 중단한다. 가지치기(pruning): 분류오류를 크게 할 위험이 높거나 부적절한 추론규칙을 가지고 있는 가지를 제거한다. 또한, 불필요한 가지를 제거한다. 타당성 평가: 이익도표(gain chart)나 위험도표(risk chart) 또는 검증용 자료 (test sample)의 사용, 또는 교차타당성 (cross validation) 등을 이용하여 의사결정나무를 평가한다. 해석 및 예측: 구축된 나무모형을 해석하고 예측모형을 설정한다.
: 분류오류를 크게 할 위험이 높거나 부적절한 추론규칙을 가지고 있는 가지를 제거한다. 또한, 불필요한 가지를 제거한다. 타당성 평가: 이익도표(gain chart)나 위험도표(risk chart) 또는 검증용 자료 (test sample)의 사용, 또는 교차타당성 (cross validation) 등을 이용하여 의사결정나무를 평가한다. 해석 및 예측: 구축된 나무모형을 해석하고 예측모형을 설정한다.")
74
데이터마이닝 제 3 장 의사결정나무 분리규칙 각 마디에서 분리규칙은 분리에 사용될 입력변수 (분리변수, split variable)의 선택과 분리가 이루어 질 기준 (분리 기준, split criteria)를 정해야 한다. 분리에 사용될 변수(X)가 연속 변수인 경우에는 분리 기준(c)은 하나의 숫자로 주어지며, 일반적으로 분리변수 X가 c보다 작으면 왼쪽 자식마디로 X가 c보다 크면 오른쪽 자식마디로 자료를 분리한다. 분리변수가 범주형인 경우에는 분리기준은 전체 범주를 두 개의 부분집합으로 나누는 것이 된다. 예를 들면, 전체 범주가 {1,2,3,4}이면 분리기준의 예로는 {1,2,4}과 {3}이 되고 이때는 분리변수가 범주 {1,2,4}에 속하면 왼쪽자식마디로 범주 {3}에 속하면 오른쪽 자식마디로 자료를 분리한다.
가 연속 변수인 경우에는 분리 기준(c)은 하나의 숫자로 주어지며, 일반적으로 분리변수 X가 c보다 작으면 왼쪽 자식마디로 X가 c보다 크면 오른쪽 자식마디로 자료를 분리한다. 분리변수가 범주형인 경우에는 분리기준은 전체 범주를 두 개의 부분집합으로 나누는 것이 된다. 예를 들면, 전체 범주가 {1,2,3,4}이면 분리기준의 예로는 {1,2,4}과 {3}이 되고 이때는 분리변수가 범주 {1,2,4}에 속하면 왼쪽자식마디로 범주 {3}에 속하면 오른쪽 자식마디로 자료를 분리한다.")
75
순수도 각 마디에서 분리변수와 분리기준은 목표변수의 분포를 가장 잘 구별해주는 쪽으로 정한다.
데이터마이닝 제 3 장 의사결정나무 순수도 각 마디에서 분리변수와 분리기준은 목표변수의 분포를 가장 잘 구별해주는 쪽으로 정한다. 목표변수의 분포를 얼마나 잘 구별하는가에 대한 측정치로 순수도 (purity) 또는 불순도 (impurity)를 사용한다. 예를 들어 그룹0과 그룹 1의 비율이 45%와 55%인 마디는 각 그룹의 비율이 90%와 10%인 마디에 비하여 순수도가 낮다 (또는 불순도가 높다)라고 이야기 한다. 각 마디에서 분리변수와 분리 기준의 설정은 생성된 두 개의 자식마디의 순수도의 합이 가장 큰 분리변수와 분리기준을 선택한다.
 또는 불순도 (impurity)를 사용한다. 예를 들어 그룹0과 그룹 1의 비율이 45%와 55%인 마디는 각 그룹의 비율이 90%와 10%인 마디에 비하여 순수도가 낮다 (또는 불순도가 높다)라고 이야기 한다. 각 마디에서 분리변수와 분리 기준의 설정은 생성된 두 개의 자식마디의 순수도의 합이 가장 큰 분리변수와 분리기준을 선택한다.")
76
불순도 측정량 분류모형 카이제곱 통계량 (chi-square statistics) 지니지수 (Gini index)
데이터마이닝 제 3 장 의사결정나무 불순도 측정량 분류모형 카이제곱 통계량 (chi-square statistics) 지니지수 (Gini index) 엔트로피지수 (Entropy index) 회귀모형 분산분석에 의한 F- 통계량( F-Statistics) 분산의 감소량
 지니지수 (Gini index) 엔트로피지수 (Entropy index) 회귀모형. 분산분석에 의한 F- 통계량( F-Statistics) 분산의 감소량.")
77
정지규칙 현재의 마디가 더 이상 분리가 일어나지 못하게 하는 규칙이다. 규칙의 종류로는 모든 자료가 한 그룹에 속할 떄
데이터마이닝 제 3 장 의사결정나무 정지규칙 현재의 마디가 더 이상 분리가 일어나지 못하게 하는 규칙이다. 규칙의 종류로는 모든 자료가 한 그룹에 속할 떄 마디에 속하는 자료가 일정 수 이하일 때 불순도의 감소량이 아주 작을 때 뿌리마디로부터의 깊이가 일정 수 이상일 때 등이 있다.

78
가지치기 지나치게 많은 마디를 가지는 의사결정나무는 새로운 자료에 적용할 때 예측오차가 매우 클 가능성이 있다.
데이터마이닝 제 3 장 의사결정나무 가지치기 지나치게 많은 마디를 가지는 의사결정나무는 새로운 자료에 적용할 때 예측오차가 매우 클 가능성이 있다. 성장이 끝난 나무의 가지를 적당히 제거하여 적당한 크기를 갖는 나무모형을 최종적인 예측모형으로 선택하는 것이 예측력의 향상에 도움이 된다. 적당한 크기를 결정하는 방법은 평가용 자료(validation data)를 사용하거나 교차확인을 이용하여 예측에러를 구하고 이 예측에러가 가장 작은 나무모형을 선택한다.
를 사용하거나 교차확인을 이용하여 예측에러를 구하고 이 예측에러가 가장 작은 나무모형을 선택한다.")
79
데이터마이닝 제 3 장 의사결정나무 3-3. 여러 가지 의사결정나무 알고리즘

80
CART Classification And Regression Tree의 준말 1984년 Breiman과 그의 동료들이 발명
데이터마이닝 제 3 장 의사결정나무 CART Classification And Regression Tree의 준말 1984년 Breiman과 그의 동료들이 발명 기계학습(machine learning) 실험의 산물 가장 널리 사용되는 의사결정나무 알고리즘
 실험의 산물. 가장 널리 사용되는 의사결정나무 알고리즘.")
81
C4.5 호주의 연구원 J. Ross Quinlan에 의하여 개발
데이터마이닝 제 3 장 의사결정나무 C4.5 호주의 연구원 J. Ross Quinlan에 의하여 개발 초기버전은 ID 3 (Iterative Dichotomizer 3)로 1986년에 개발 CART와는 다르게 각 마디에서 다지분리 (multiple split)가 가능하다. 범주형 입력변수에 대해서는 범주의 수만큼 분리가 일어난다. 불순도함수로 엔트로피 지수를 사용한다. 가지치기를 사용할 때 학습자료를 사용한다.
로 1986년에 개발. CART와는 다르게 각 마디에서 다지분리 (multiple split)가 가능하다. 범주형 입력변수에 대해서는 범주의 수만큼 분리가 일어난다. 불순도함수로 엔트로피 지수를 사용한다. 가지치기를 사용할 때 학습자료를 사용한다.")
82
CHAID Chi-squared Automatic Interaction Detection 의 준말
데이터마이닝 제 3 장 의사결정나무 CHAID Chi-squared Automatic Interaction Detection 의 준말 1975년 J.A. Hartigan이 발표 1963년 J.A. Morgan과 N.A. Souquist에 의해 서술된 AID의 후신 CHAID는 가지치기를 하지 않고 나무를 적당한 크기에서 성장을 중지시킨다. 입력변수가 반드시 범주형이어야 한다. 불순도함수로는 카이제곱통계량을 사용한다.

83
데이터마이닝 제 3 장 의사결정나무 3-4. 의사결정나무의 장/단점

84
의사결정나무의 장점 이해하기 쉬운 규칙을 생성시켜 준다. 분류작업이 용이하다.
데이터마이닝 제 3 장 의사결정나무 의사결정나무의 장점 이해하기 쉬운 규칙을 생성시켜 준다. 분류작업이 용이하다. 연속형변수와 범주형 변수를 모두 다 취급할 수 있다. 가장 좋은 변수를 명확히 알아낸다. (SAS E-Miner의 Variable selection노드에서 카이제곱 통계량을 이용한 변수 선택은 바로 CHAID를 이용한 것이다.) 이상치에 덜 민감하다. 모형의 가정 (선형성, 등분산성 등)이 필요 없다. 즉, 비모수적 모형이다.
 이상치에 덜 민감하다. 모형의 가정 (선형성, 등분산성 등)이 필요 없다. 즉, 비모수적 모형이다.")
85
의사결정나무의 단점 목표변수가 연속형인 회귀모형에서는 그 예측력이 떨어진다.
데이터마이닝 제 3 장 의사결정나무 의사결정나무의 단점 목표변수가 연속형인 회귀모형에서는 그 예측력이 떨어진다. 나무가 너무 깊은 경우에는 예측력의 저하뿐 아니라 해석도 하기가 쉽지 않다. 계산량이 많을 수 있다. 비사각영역에서 문제가 있다. 결과가 불안정하다. 선형성 또는 주효과의 결여

86
데이터마이닝 제 4 장 신경망모형 제 4장 신경망모형

87
데이터마이닝 제 4 장 신경망모형 4-1. 신경망모형 소개

88
신경망 모형이란? 인간의 두뇌구조를 모방한 지도학습 방법
데이터마이닝 제 4 장 신경망모형 신경망 모형이란? 인간의 두뇌구조를 모방한 지도학습 방법 여러 개의 뉴런들이 상호 연결하여 입력에 상응하는 최적의 출력값을 예측 장점: 좋은 예측력 단점: 해석의 어려움

89
신경망 모형의 배경 1940년대 McCulloch와 Pits에 의해 인간 뇌의 신경노드의 작동 모형 구축
데이터마이닝 제 4 장 신경망모형 신경망 모형의 배경 1940년대 McCulloch와 Pits에 의해 인간 뇌의 신경노드의 작동 모형 구축 1950년대 Rosenblat에 의하여 지도학습에 응용될 수 있는 단층 신경망 Perceptron 개발 1980년대 이전에는 컴퓨터 성능의 저하로 그리 널리 쓰이지 않음 1980년대에 Hopfield에 의해 다시 각광을 받기 시작함 다층 신경망 모형 (multi-layer perceptron)과 역전의 (Back propagation) 알고리즘의 결합은 신경망 모형의 응용분야를 크게 넓힘.
과 역전의 (Back propagation) 알고리즘의 결합은 신경망 모형의 응용분야를 크게 넓힘.")
90
인간 신경세포 세포체 (Cell body) 시냅스 축색(Axon) 수상돌기 (Dendrites) 데이터마이닝
제 4 장 신경망모형 인간 신경세포 축색(Axon) 수상돌기 (Dendrites) 세포체 (Cell body) 시냅스
 수상돌기 (Dendrites) 세포체 (Cell body) 시냅스.")
91
신경망 모형의 구조 은닉계층 (hidden layer) 출력계층 (output layer) 입력계층 (input layer)
데이터마이닝 제 4 장 신경망모형 신경망 모형의 구조 은닉계층 (hidden layer) 출력계층 (output layer) 입력계층 (input layer) X Y
 출력계층 (output layer) 입력계층 (input layer) X. Y.")
92
용어 정리 MLP (Multi-layer perceptron): 입력층, 은닉층, 출력층으로 구성된 신경망 모형
데이터마이닝 제 4 장 신경망모형 용어 정리 MLP (Multi-layer perceptron): 입력층, 은닉층, 출력층으로 구성된 신경망 모형 SLP (Single-layer perceptron): 입력층과 출력층으로만 구성된 신경망 모형 입력층: 각 입력변수에 대응되는 노드로 구성. 노드의 수는 입력변수의 개수와 같다. 은닉층: 입력층으로부터 전달되는 변수값들의 선형결합을 비선형함수로 처리하여 출력층 또는 다른 은닉층에 전달한다. 출력층: 목표변수에 대응되는 노드. 분류모형에서는 그룹의 수 만큼의 출력노드가 생성
: 입력층, 은닉층, 출력층으로 구성된 신경망 모형. SLP (Single-layer perceptron): 입력층과 출력층으로만 구성된 신경망 모형. 입력층: 각 입력변수에 대응되는 노드로 구성. 노드의 수는 입력변수의 개수와 같다. 은닉층: 입력층으로부터 전달되는 변수값들의 선형결합을 비선형함수로 처리하여 출력층 또는 다른 은닉층에 전달한다. 출력층: 목표변수에 대응되는 노드. 분류모형에서는 그룹의 수 만큼의 출력노드가 생성.")
93
데이터마이닝 제 4 장 신경망모형 다층 신경망 (MLP) 1 X1 X2 X3 output 입력층 은닉층 출력층
 1 X1 X2 X3 output 입력층 은닉층 출력층")
94
다층신경망의 함수구조 함수구조 Output 함수 f1과 f2를 활성함수라고 함
데이터마이닝 제 4 장 신경망모형 다층신경망의 함수구조 함수구조 Output 함수 f1과 f2를 활성함수라고 함 회귀모형(출력변수가 연속형인 경우에는)는 f2(x)=x가 많이 쓰인다. 분류모형인 경우에는 f2에 시그모이드 (sigmoid) 함수가 많이 사용된다. f1에는 시그모이드 함수가 사용된다.
는 f2(x)=x가 많이 쓰인다. 분류모형인 경우에는 f2에 시그모이드 (sigmoid) 함수가 많이 사용된다. f1에는 시그모이드 함수가 사용된다.")
95
시그모이드 (sigmoid) 함수 시그모이드 함수는 단극성, 양극성 두 종류가 있다. 단극성 시그모이드 함수:
데이터마이닝 제 4 장 신경망모형 시그모이드 (sigmoid) 함수 시그모이드 함수는 단극성, 양극성 두 종류가 있다. 단극성 시그모이드 함수: 증가함수이며 출력값이 0과 1사이의 값을 갖는다. 로지스틱함수와 유사하다. 양극성 시그모이드 함수 증가함수이며 출력값이 -1과 1사이의 값을 가지며, f(0)=0이다.
 함수. 시그모이드 함수는 단극성, 양극성 두 종류가 있다. 단극성 시그모이드 함수: 증가함수이며 출력값이 0과 1사이의 값을 갖는다. 로지스틱함수와 유사하다. 양극성 시그모이드 함수. 증가함수이며 출력값이 -1과 1사이의 값을 가지며, f(0)=0이다.")
96
시그모이드 (sigmoid) 함수 그림 f(x) x 단극성 시그모이드 함수 양극성 시그모이드 함수 1 0.5 -1 데이터마이닝
제 4 장 신경망모형 시그모이드 (sigmoid) 함수 그림 f(x) 1 0.5 x -1 단극성 시그모이드 함수 양극성 시그모이드 함수
 함수 그림. f(x) x. -1. 단극성 시그모이드 함수. 양극성 시그모이드 함수.")
97
다양한 MLP 은닉노드의 수가 k개 인 일반적인 MLP의 함수구조는 다음과 같이 주어진다. Output
데이터마이닝 제 4 장 신경망모형 다양한 MLP 은닉노드의 수가 k개 인 일반적인 MLP의 함수구조는 다음과 같이 주어진다. Output 활성함수, 특히 은닉노드의 활성함수를 바꿈으로써 여러 가지 신경망 모형을 만들 수 있다. 예로는 RBF (Radial Basis function) 신경망이 있다. 은닉 층이 두 개 이상인 신경망 모형도 생각할 수 있으나, 그 모형이 너무 복잡하여 실제 자료분석에서는 널리 쓰이지 않는다. 또한, 이론적으로 하나의 은닉층을 갖는 신경망 모형으로 충분하다.
 신경망이 있다. 은닉 층이 두 개 이상인 신경망 모형도 생각할 수 있으나, 그 모형이 너무 복잡하여 실제 자료분석에서는 널리 쓰이지 않는다. 또한, 이론적으로 하나의 은닉층을 갖는 신경망 모형으로 충분하다.")
98
목적함수 신경망 모형을 구축하는 방법은 크게 두 단계로 이루어 진다. 1단계: 적절한 수의 은닉층과 은닉노드의 수 결정
데이터마이닝 제 4 장 신경망모형 목적함수 신경망 모형을 구축하는 방법은 크게 두 단계로 이루어 진다. 1단계: 적절한 수의 은닉층과 은닉노드의 수 결정 2 단계: 연결강도 (weight)를 추정 연결강도의 추정을 위하여는 적절한 목적함수가 필요하다. 즉, 연결강도의 추정은 주어진 목적함수의 최소화 (또는 최대화)를 통하여 추정한다.
를 추정. 연결강도의 추정을 위하여는 적절한 목적함수가 필요하다. 즉, 연결강도의 추정은 주어진 목적함수의 최소화 (또는 최대화)를 통하여 추정한다.")
99
목적함수(계속) 일반적으로 많이 쓰이는 목적함수로는 산형모형에 쓰이는 오차제곱합이라 불리는 다음과 같은 함수이다.
데이터마이닝 제 4 장 신경망모형 목적함수(계속) 일반적으로 많이 쓰이는 목적함수로는 산형모형에 쓰이는 오차제곱합이라 불리는 다음과 같은 함수이다. 여기서 Yi는 i번째 패턴의 실제 값이고 Pi는 i번쨰 패턴의 예측값이다. 이 목적함수를 앞의 예에 대하여 표현하면 다음과 같이 된다.
 일반적으로 많이 쓰이는 목적함수로는 산형모형에 쓰이는 오차제곱합이라 불리는 다음과 같은 함수이다. 여기서 Yi는 i번째 패턴의 실제 값이고 Pi는 i번쨰 패턴의 예측값이다. 이 목적함수를 앞의 예에 대하여 표현하면 다음과 같이 된다.")
100
목적함수(계속) 오차제곱합 목적함수는 분류모형에서는 적절하지 않을 수 있다.
데이터마이닝 제 4 장 신경망모형 목적함수(계속) 오차제곱합 목적함수는 분류모형에서는 적절하지 않을 수 있다. 분류 모형에서 사용되는 또 다른 목적함수로는 로그우도함수 (log likelihood)를 사용한다. 그룹이 두 개인 분류모형의 로그우도함수는 다음과 같이 정의 된다.
 오차제곱합 목적함수는 분류모형에서는 적절하지 않을 수 있다. 분류 모형에서 사용되는 또 다른 목적함수로는 로그우도함수 (log likelihood)를 사용한다. 그룹이 두 개인 분류모형의 로그우도함수는 다음과 같이 정의 된다.")
101
역전의(Back propagation) 알고리즘
데이터마이닝 제 4 장 신경망모형 역전의(Back propagation) 알고리즘 신경망의 목적함수는 연결강도에 대하여 비선형 함수이다. 비선형 함수를 최적화 하는 알고리즘으로는 Back propagation method, Quickprop method, Conjugate gradient method, Modified Newton method, Doubly degleg method, Lebenburg-Marguardt method등이 있다. 이중, 신경망 모형의 목적함수의 최적화를 위하여는 Back propagation (역전의) 방법이 널리 사용되고 있다.
 알고리즘. 신경망의 목적함수는 연결강도에 대하여 비선형 함수이다. 비선형 함수를 최적화 하는 알고리즘으로는 Back propagation method, Quickprop method, Conjugate gradient method, Modified Newton method, Doubly degleg method, Lebenburg-Marguardt method등이 있다. 이중, 신경망 모형의 목적함수의 최적화를 위하여는 Back propagation (역전의) 방법이 널리 사용되고 있다.")
102
데이터마이닝 제 4 장 신경망모형 4-2. SLP versus MLP

103
데이터마이닝 제 4 장 신경망모형 단층신경망 (SLP) 단층신경망 (SLP, Single layer perceptron): 입력층과 출력층으로만 이루어진 신경망 모형 단층신경망 예 1 X1 output X2 X3 출력층 입력층

104
단측신경망 (계속) 단층신경망 모형의 함수 구조 Output = 여기서 f는 활성함수이다.
데이터마이닝 제 4 장 신경망모형 단측신경망 (계속) 단층신경망 모형의 함수 구조 Output = 여기서 f는 활성함수이다. 회귀모형에서는 출력값은 f(x)로 예측하며, 분류문제(그룹이 2개인 경우)인 경우에는 f(x)가 분류값 c보다 크면 그룹 1에, f(x)가 분류값 c보다 작으면 그룹 0에 할당한다.
 단층신경망 모형의 함수 구조. Output = 여기서 f는 활성함수이다. 회귀모형에서는 출력값은 f(x)로 예측하며, 분류문제(그룹이 2개인 경우)인 경우에는 f(x)가 분류값 c보다 크면 그룹 1에, f(x)가 분류값 c보다 작으면 그룹 0에 할당한다.")
105
데이터마이닝 제 4 장 신경망모형 단측신경망 (계속) 단측신경망은 회귀모형인 경우에는 다중선형회귀모형과 같고, 분류모형인 경우에는 선형의사결정경계(linear decision boundary)를 제공한다. 로지스틱회귀모형도 선형의사결정경계를 제공한다는 측면에서 단측신경망과 로지스틱회귀모형과 유사하다. 선형의사결정 경계는 AND, OR 연산등에는 분리가 가능하나 XOR등의 복잡한 문제에서는 그 분리가 불가능하다.

106
단측신경망 (계속) 다음의 모형을 생각하자. 입력변수 : 출력변수 : AND 연산 : 선형의사결정경계로 분리 가능
데이터마이닝 제 4 장 신경망모형 단측신경망 (계속) 다음의 모형을 생각하자. 입력변수 : 출력변수 : AND 연산 : 선형의사결정경계로 분리 가능 y= x1 AND x2 x1 x2 1 1 x1 x2
 다음의 모형을 생각하자. 입력변수 : 출력변수 : AND 연산 : 선형의사결정경계로 분리 가능. y= x1 AND x2. x1. x x1. x2.")
107
단측신경망 (계속) OR 연산 : 선형의사결정경계로 분리 가능 y= x1 OR x2 1 데이터마이닝 제 4 장 신경망모형 x1
x1 x2 1 1 1 x1

108
단측신경망 (계속) 1 XOR 연산 : 선형의사결정경계로 분리 불가능 y= x1 XOR x2 데이터마이닝 제 4 장 신경망모형
1 1 x1 x2 1 x1

109
다층신경망을 통한 XOR의 분리 다음 두개의 연산을 생각하자.
데이터마이닝 제 4 장 신경망모형 다층신경망을 통한 XOR의 분리 다음 두개의 연산을 생각하자. (1) Z1=X1 AND not X2, (2) Z2=not X1 AND X2 1 x1 x2 1 x1 x2 z1 z2 z1과 z2는 선형으로 분리 가능한 연산이다.
 Z1=X1 AND not X2, (2) Z2=not X1 AND X2. 1. x1. x2. 1. x1. x2. z1. z2. z1과 z2는 선형으로 분리 가능한 연산이다.")
110
다층신경망을 통한 XOR의 분리 이제, 출력을 z1 OR z2로 놓으면, 이 결과는 x1 XOR x2와 같게 된다. 1 1 1
데이터마이닝 제 4 장 신경망모형 다층신경망을 통한 XOR의 분리 이제, 출력을 z1 OR z2로 놓으면, 이 결과는 x1 XOR x2와 같게 된다. 1 x1 x2 1 x1 x2 1 x1 x2 OR = z2 z1 z1 OR z2 OR 연산은 선형분리 가능 연산이다.

111
다층신경망을 통한 XOR의 분리 앞의 XOR 예제는 선형분리 불가능인 연산을 선형가능 연산을 두번 사용하여 분리하는 예이다.
데이터마이닝 제 4 장 신경망모형 다층신경망을 통한 XOR의 분리 앞의 XOR 예제는 선형분리 불가능인 연산을 선형가능 연산을 두번 사용하여 분리하는 예이다. 선형 가능 연산을 두 번 썼다 함은, 두개의 선형 분리 가능 연산 z1과 z2의 결과를 두번째 선형가능 연산인 OR가 입력을 받아서 최종 출력을 만듦을 의미한다. 이상과 같이, 선형 분리 가능 연산의 결과를 다시 입력으로 받아서 선형분리 가능연산을 적용하면, 원래는 선형분리 불가능인 연산도 불리가 가능하다. 이것이 다층신경망(MLP) 모형의 기본 아이디어이다.
 모형의 기본 아이디어이다.")
112
다층신경망을 통한 XOR의 분리 주어진 입력 x=(x1,…,xp)에 대하여 다음의 k개의 선형분류함수를 생각하자.
데이터마이닝 제 4 장 신경망모형 다층신경망을 통한 XOR의 분리 주어진 입력 x=(x1,…,xp)에 대하여 다음의 k개의 선형분류함수를 생각하자. 즉, i번째 분류함수는 zi의 값이 1인 자료를 그룹 1에 zi의 값이 0인 자료를 그룹 0 에 할당한다. 다음에는, 이 k 개의 선형분류함수의 결과를 입력으로 받는 선형분류함수를 생각하자. 마지막으로, p값을 이용하여 주어진 자료를 분리한다.
에 대하여 다음의 k개의 선형분류함수를 생각하자. 즉, i번째 분류함수는 zi의 값이 1인 자료를 그룹 1에 zi의 값이 0인 자료를 그룹 0 에 할당한다. 다음에는, 이 k 개의 선형분류함수의 결과를 입력으로 받는 선형분류함수를 생각하자. 마지막으로, p값을 이용하여 주어진 자료를 분리한다.")
113
다층신경망을 통한 XOR의 분리 앞의 모형은 가장 간단한 다층신경망 모형이다.
데이터마이닝 제 4 장 신경망모형 다층신경망을 통한 XOR의 분리 앞의 모형은 가장 간단한 다층신경망 모형이다. 이러한 다층 신경망 모형은 실제적으로 잘 쓰이지 않는데, 그 이유는 분류함수들이 미분이 불능하여 목적함수를 최적으로 하는 연결강도를 찾는 것이 매우 어렵다. 이러한 문제점을 보완하기 위해, indicator 함수 (I(.))대신에 I(.)와 비슷하면서 부드러운 함수를 사용한다. 이때, 가장 널리 사용되는 함수가 바로 시그모이드 함수이다. 앞 교안의 모형에서 I(.)대신 시그모이드 함수를 이용하면 바로 앞에서 배운 MLP 모형이 된다.
)대신에 I(.)와 비슷하면서 부드러운 함수를 사용한다. 이때, 가장 널리 사용되는 함수가 바로 시그모이드 함수이다. 앞 교안의 모형에서 I(.)대신 시그모이드 함수를 이용하면 바로 앞에서 배운 MLP 모형이 된다.")
114
데이터마이닝 제 4 장 신경망모형 4-3. 여러 가지 신경망모형

115
RBF 신경망 RBF ( radial basis function) 신경망
데이터마이닝 제 4 장 신경망모형 RBF 신경망 RBF ( radial basis function) 신경망 MLP와 다른 점은 활성 함수가 시그모이드 함수가 아니라 RBF를 사용한다. P개의 입력변수에 대한 RBF함수는 와 같이 주어진다. 추정을 위하여는 일단 중심 RBF에 있는 중심 (c1,…,cp)와 거리 r2를 자율학습으로 추정한 후 연결강도를 추정한다.
 신경망. MLP와 다른 점은 활성 함수가 시그모이드 함수가 아니라 RBF를 사용한다. P개의 입력변수에 대한 RBF함수는. 와 같이 주어진다. 추정을 위하여는 일단 중심 RBF에 있는 중심 (c1,…,cp)와 거리 r2를 자율학습으로 추정한 후 연결강도를 추정한다.")
116
신경망 모형의 여러 가지 대안 신경망 모형의 대안으로 여러 가지 통계적 모형들이 있다.
데이터마이닝 제 4 장 신경망모형 신경망 모형의 여러 가지 대안 신경망 모형의 대안으로 여러 가지 통계적 모형들이 있다. GAM : Generalized Additive Model PPR: Project Pursuit regression MARS: Multivariate Adaptive Regression Spline

117
데이터마이닝 제 4 장 신경망모형 4-4. 신경망모형 구축 및 유의사항

118
신경망모형의 구축 4단계 자료의 선택 및 적절한 변환 신경망모형의 은닉층의 노드 수와 활성함수의 결정 (신경망모형 선택)
데이터마이닝 제 4 장 신경망모형 신경망모형의 구축 4단계 자료의 선택 및 적절한 변환 신경망모형의 은닉층의 노드 수와 활성함수의 결정 (신경망모형 선택) 연결강도의 최적화 결과의 해석
 연결강도의 최적화. 결과의 해석.")
119
데이터마이닝 제 4 장 신경망모형 신경망모형 선택 방법 1. Trial and error: 은닉층 수, 은닉층의 노드 수, 활성함수를 변화시켜 가면서 가장 좋은 모형을 찾는다. 비용과 시간이 많이 소요 된다. 다른 복잡도를 갖는 여러 개의 신경망모형들의 비교가 쉽지 않다. 사용자가 숙련되어 있으면, 매우 복잡한 신경망 모형을 만들 수 있다. 실제 분석에서는 가장 많이 쓰이는 방법이다.

120
데이터마이닝 제 4 장 신경망모형 신경망모형 선택 방법 2. Constructive algorithm: 선형모형에서 단계적 변수 선택방법처럼 작은 모형에서 시작하여 큰 모형으로 키워나가는 방법이다. 특히, 은닉층의 노드의 수를 결정 할 때 많이 사용된다. 다른 수의 은닉 노드를 갖는 신경망들을 비교할 수 있는 통계량이 필요하다. 실제 분석에서는 노드 수를 증가하며 학습에러의 감소량을 측정하고 이 감소량이 급격히 줄어드는 곳의 노드 수를 최종 모형으로 선택한다.

121
데이터마이닝 제 4 장 신경망모형 신경망모형 선택 방법 3. Pruning: 선형모형에서의 후진소거법 처럼 큰 모형에서 시작하여 작은 모형으로 축소시키는 방법이다. 의사결정나무의 pruning(가지치기) 방법과 유사하다. 일반적으로, pruning (후진소거법)이 constructive algorithm (전진선택법)에 비하여 좋은 결과를 제공한다. 하지만, pruning방법은 큰 모형을 결정하는 문제가 쉽지 않으며, 큰 모형에는 많은 수의 모수가 있어서 그 추정이 쉽지 않다.
이 constructive algorithm (전진선택법)에 비하여 좋은 결과를 제공한다. 하지만, pruning방법은 큰 모형을 결정하는 문제가 쉽지 않으며, 큰 모형에는 많은 수의 모수가 있어서 그 추정이 쉽지 않다.")
122
신경망모형 선택 방법 4. Regularization: 복잡도의 크기에 비례하는 벌칙항을 넣은 적합도 함수를 최소화 한다.
데이터마이닝 제 4 장 신경망모형 신경망모형 선택 방법 4. Regularization: 복잡도의 크기에 비례하는 벌칙항을 넣은 적합도 함수를 최소화 한다. 선형모형에서 사용되는 Mallow’s Cp나 AIC의 사용과 유사하다. 벌칙항을 결정하기가 쉽지 않다. 벌칙항에 따라, 최종 결과가 많은 차이를 보인다.

123
입력자료 선택 신경망모형은 그 모형의 복잡성으로 인하여 입력자료의 선택에 매우 민감하게 반응한다.
데이터마이닝 제 4 장 신경망모형 입력자료 선택 신경망모형은 그 모형의 복잡성으로 인하여 입력자료의 선택에 매우 민감하게 반응한다. 따라서, 좋은 입력자료의 선택은 신경망모형의 성공에 매우 중요하다. 좋은 입력자료란 범주형 입력변수가 모든 범주에서 일정 빈도 이상의 값을 갖는다. 연속형 입력변수 값들의 범위가 변수 간에 많은 차이가 없다. 입력변수의 수가 너무 많지 않다. (물론, 너무 적어도 안된다.) 범주형 출력값의 각 범주의 빈도가 비슷하다.
 범주형 출력값의 각 범주의 빈도가 비슷하다.")
124
데이터마이닝 제 4 장 신경망모형 입력자료 선택(계속) 범주형 입력변수의 빈도: 입력변수의 범주가 지나치게 많은 경우에는 빈도가 적은 여러 범주를 합병하여 사용한다. 연속형 변수의 범위: 표준화를 시행하거나, 입력변수를 0과 1 사이의 수로 그 크기를 조절한다. 입력변수의 개수: 미리 유의한 변수를 선택한 후 신경망모형을 적합한다. 출력변수의 빈도: 출력변수의 빈도가 현저하게 차이가 있는 경우에는, 사후추출법을 이용하여 출력변수의 빈도를 적절히 조절한다. 그러나, 이때 결과의 해석에 신경을 써야 한다.

125
자료의 변환 적절한 자료의 변환은 신경망 모형 성공의 필수 조건이다. 자료의 변환에는 연속형 변수의 범위의 조절
데이터마이닝 제 4 장 신경망모형 자료의 변환 적절한 자료의 변환은 신경망 모형 성공의 필수 조건이다. 자료의 변환에는 연속형 변수의 범위의 조절 연속형 변수의 변환 연속형 변수의 범주형화 새로운 변수의 생성 범주형 변수의 가변수화

126
데이터마이닝 제 4 장 신경망모형 4-5. 신경망모형의 특징

127
신경망 모형의 특징 범용근사자 (Universal approximator):
데이터마이닝 제 4 장 신경망모형 신경망 모형의 특징 범용근사자 (Universal approximator): 범용근사자란, 어떠한 분류함수도 근사적으로 표현할 수 있는 모형을 말한다. 은닉층이 하나인 MLP는 범용근사자임이 알려져 있다. 최적화와 비 수렴성 신경망모형의 최적화는 역전파 알고리즘을 사용하는데, 이 역전파 알고리즘이 제공하는 모형이 최적이 모형이 아닌 경우가 많이 발생한다. 특히, 역전파 알고리즘의 초기값에 따라, 최종모형이 달라진다. 실제 분석에서는, 초기 값을 바꾸어 가며 여러 개의 신경망 모형을 만든 후 그 중 최적의 모형을 선택한다.
: 범용근사자란, 어떠한 분류함수도 근사적으로 표현할 수 있는 모형을 말한다. 은닉층이 하나인 MLP는 범용근사자임이 알려져 있다. 최적화와 비 수렴성. 신경망모형의 최적화는 역전파 알고리즘을 사용하는데, 이 역전파 알고리즘이 제공하는 모형이 최적이 모형이 아닌 경우가 많이 발생한다. 특히, 역전파 알고리즘의 초기값에 따라, 최종모형이 달라진다. 실제 분석에서는, 초기 값을 바꾸어 가며 여러 개의 신경망 모형을 만든 후 그 중 최적의 모형을 선택한다.")
128
신경망 모형의 특징 해석의 어려움 입력변수와 출력변수와의 관계를 파악하는 것이 거의 불가능하다. 즉, 결과의 해석이 어렵다.
데이터마이닝 제 4 장 신경망모형 신경망 모형의 특징 해석의 어려움 입력변수와 출력변수와의 관계를 파악하는 것이 거의 불가능하다. 즉, 결과의 해석이 어렵다. 신경망모형은 선형모형이나 의사결정나무에 비해 예측력은 뛰어나다. 실제 분석에서는 신경망과 의사결정나무를 같이 사용하는 방법도 고려할 수 있다. 과적합 신경망모형에서 적절한 크기의 모형을 선택하기란 그리 쉽지 않다. 앞에서 배운 4가지 방법 중 가장 많이 쓰이는 방법이 trial and error 방법이다. 따라서, 비 숙련자가 사용하기가 어렵고, 많은 경우 과적합의 위험이 있다.

129
데이터마이닝 Part III. 자율학습

130
데이터마이닝 제 5 장 군집분석 제 5장 군집분석

131
군집분석의 정의 군집분석은 모집단 또는 범주에 대한 사전 정보가 없는 경우에
데이터마이닝 제 5 장 군집분석 군집분석의 정의 군집분석은 모집단 또는 범주에 대한 사전 정보가 없는 경우에 주어진 관측값들 사이의 거리 또는 유사성 을 이용하여 전체를 몇 개의 집단으로 그룹화 하여 각 집단의 성격을 파악함으로써 데이터 전체의 구조에 대한 이해를 돕고자 하는 분석법이다.

132
데이터마이닝 제 5 장 군집분석 군집화 군집화의 기준 동일한 군집에 속하는 개체 (또는 개인)는 여러 속성이 비슷하고, 서로 다른 군집에 속한 관찰치는 그렇지 않도록 군집을 구성 군집화를 위한 변수: 전체 개체(개인)의 속성을 판단하기 위한 기준 예: 고객세분화 인구통계적 변인 (성별, 나이, 거주지, 직업, 소득, 교육, 종교,…) 구매패턴 변인 (상품, 주기, 거래액,…) 생활패턴 변인 (라이프스타일, 성격, 취미, 가치관,…)
의 속성을 판단하기 위한 기준. 예: 고객세분화. 인구통계적 변인 (성별, 나이, 거주지, 직업, 소득, 교육, 종교,…) 구매패턴 변인 (상품, 주기, 거래액,…) 생활패턴 변인 (라이프스타일, 성격, 취미, 가치관,…)")
133
군집분석의 활용 고객 세분화 고객이 기업의 수익에 기여하는 정도를 통한 고객세분화 우수고객의 인구통계적 요인, 생활패턴 파악
데이터마이닝 제 5 장 군집분석 군집분석의 활용 고객 세분화 고객이 기업의 수익에 기여하는 정도를 통한 고객세분화 우수고객의 인구통계적 요인, 생활패턴 파악 개별고객에 대한 맞춤관리 고객의 구매패턴에 따른 고객세분화 신상품 판촉, 교차판매를 위한 표적집단 구성

134
데이터마이닝 제 5 장 군집분석 군집분석의 활용 Brandy Royalty Income 집단 A 집단 B 마케팅 공략 대상

135
비유사성의 척도: 거리 군집분석에서는 관측값들이 서로 얼마나 유사한지 또는 유사하지 않은지를 측정할 수 있는 측도가 필요하다.
데이터마이닝 제 5 장 군집분석 비유사성의 척도: 거리 군집분석에서는 관측값들이 서로 얼마나 유사한지 또는 유사하지 않은지를 측정할 수 있는 측도가 필요하다. 군집분석에서는 보통 유사성(similarity)보다는 비유사성(dissimilarity)를 기준으로 하며 거리(distance)를 사용한다. 거리의 정의: 두 점 x와 y의 거리 d(x,y)는 다음을 만족한다. d(x,y)=0 => x=y d(x,y) >= 0 d(x,y)=d(y,x) d(x,y) <= d(x,z)+d(z,y) (triangular inequality)
보다는 비유사성(dissimilarity)를 기준으로 하며 거리(distance)를 사용한다. 거리의 정의: 두 점 x와 y의 거리 d(x,y)는 다음을 만족한다. d(x,y)=0 => x=y. d(x,y) >= 0. d(x,y)=d(y,x) d(x,y) <= d(x,z)+d(z,y) (triangular inequality)")
136
거리 측도의 종류들 유클리드(Euclid) 거리
데이터마이닝 제 5 장 군집분석 거리 측도의 종류들 유클리드(Euclid) 거리 p차원 공간에서 주어진 두 점 x=(x1,…,xp) 와 y=(y1,…,yp)사이의 유클리드 거리 d(x,y)는 로 정의 된다. p=2인 경우 x=(x1,x2) y=(y1,y2)
 거리. p차원 공간에서 주어진 두 점 x=(x1,…,xp) 와 y=(y1,…,yp)사이의 유클리드 거리 d(x,y)는. 로 정의 된다. p=2인 경우. x=(x1,x2) y=(y1,y2)")
137
데이터마이닝 제 5 장 군집분석 거리 측도의 종류들(계속) Minkowski 거리 표준화 거리 Mahalanobis 거리
 Minkowski 거리 표준화 거리 Mahalanobis 거리")
138
범주형 자료의 거리 불일치 항목수 예 d(A,B)=2, d(A,C)=1, d(B,C)=3 개체 성별 학력 출신지역 A 남자
데이터마이닝 제 5 장 군집분석 범주형 자료의 거리 불일치 항목수 예 개체 성별 학력 출신지역 A 남자 고졸 경기 B 여자 전남 C 대졸 d(A,B)=2, d(A,C)=1, d(B,C)=3
=2, d(A,C)=1, d(B,C)=3.")
139
군집분석의 유형 상호배반적(disjoint) 군집 각 관찰치가 상호배반적인 여러 군집 중 오직 하나에만 속함
데이터마이닝 제 5 장 군집분석 군집분석의 유형 상호배반적(disjoint) 군집 각 관찰치가 상호배반적인 여러 군집 중 오직 하나에만 속함 예: 한국인, 중국인, 일본인 계보적(hierarchical) 군집 한 군집이 다른 군집의 내부에 포함되는 형태로 군집간의 중복은 없으며, 군집들이 매 단계 계층적인(나무) 구조를 이룬다. 예: 전자제품 -> 주방용 -> 냉장고
 군집. 각 관찰치가 상호배반적인 여러 군집 중 오직 하나에만 속함. 예: 한국인, 중국인, 일본인. 계보적(hierarchical) 군집. 한 군집이 다른 군집의 내부에 포함되는 형태로 군집간의 중복은 없으며, 군집들이 매 단계 계층적인(나무) 구조를 이룬다. 예: 전자제품 -> 주방용 -> 냉장고.")
140
군집분석의 유형(계속) 중복(overlapping) 군집 두 개 이상의 군집에 한 관찰치가 동시에 포함되는 것을 허용
데이터마이닝 제 5 장 군집분석 군집분석의 유형(계속) 중복(overlapping) 군집 두 개 이상의 군집에 한 관찰치가 동시에 포함되는 것을 허용 퍼지 (fuzzy) 군집 관찰치가 소속되는 특정한 군집을 표현하는 것이 아니라, 각 군집에 속할 가능성을 표현 Pr( 개체가 군집 A에 속함)=0.7, Pr( 개체가 군집 B에 속함)=0.3
 중복(overlapping) 군집. 두 개 이상의 군집에 한 관찰치가 동시에 포함되는 것을 허용. 퍼지 (fuzzy) 군집. 관찰치가 소속되는 특정한 군집을 표현하는 것이 아니라, 각 군집에 속할 가능성을 표현. Pr( 개체가 군집 A에 속함)=0.7, Pr( 개체가 군집 B에 속함)=0.3.")
141
군집분석의 특징 군집분석은 그 기준의 설정, 즉 유사성이나 혹은 비유사성의 정의나 군집의 형태 등 매우 다양한 방법이 있다.
데이터마이닝 제 5 장 군집분석 군집분석의 특징 군집분석은 그 기준의 설정, 즉 유사성이나 혹은 비유사성의 정의나 군집의 형태 등 매우 다양한 방법이 있다. 군집분석은 자료의 사전정보 없이 자료를 파악하는 방법으로, 분석자의 주관에 결과가 달라질 수 있다. 따라서, 군집분석은 한번에 분석이 끝나는 것이 아니고, 매회 결과를 잘 관찰하여 의미 있는 정보요약을 얻어내야 한다. 특이값을 갖는 개체의 발견, 결측값의 보정 등에 군집분석이 사용될 수 있다. 군집분석에서 군집을 분석하는 중요한 변수의 선택이 중요하다.

142
데이터마이닝 제 5 장 군집분석 계층적 군집분석의 개요 가까운 관측값들 끼리 묶는 병합(agglomeration)방법과 먼 관측값들을 나누어가는 분할(division) 방법으로 나눌 수 있다. 계층적 군집분석에서는 주로 병합 방법이 주로 사용된다. 계층적 군집분석의 결과는 나무구조인 덴드로그램(dendrogram)을 통해 간단하게 나타낼 수 있고, 이를 이용하여 전체 군집들간의 구조적 관계를 쉽게 살펴볼 수 있다.
을 통해 간단하게 나타낼 수 있고, 이를 이용하여 전체 군집들간의 구조적 관계를 쉽게 살펴볼 수 있다.")
143
병합방법 처음에 n개의 자료를 각각 하나의 군집으로 생각한다. 즉 군집의 수는 n이다.
데이터마이닝 제 5 장 군집분석 병합방법 처음에 n개의 자료를 각각 하나의 군집으로 생각한다. 즉 군집의 수는 n이다. 이 n개의 군집 중 가장 거리가 가까운 두 개의 군집을 병합하여 n-1개의 군집으로 군집을 줄인다. 그 다음, n-1개의 군집 중 가장 가까운 두 군집을 병합하여 군집을 n-2개로 줄인다. 이를 반복하여 계속하여 군집의 수를 줄여 나간다. 이 과정은 시작부분에는 군집의 크기는 작고 동질적이며, 끝부분에서는 군집의 크기는 커지고 이질적이 된다.

144
병합방법(계속) 군집들간의 거리를 측정하는 방법에 따라 다양한 종류의 방법이 있다.
데이터마이닝 제 5 장 군집분석 병합방법(계속) 군집들간의 거리를 측정하는 방법에 따라 다양한 종류의 방법이 있다. 최단거리, 최장거리, 평균거리 방법 등이 있다.
 군집들간의 거리를 측정하는 방법에 따라 다양한 종류의 방법이 있다. 최단거리, 최장거리, 평균거리 방법 등이 있다.")
145
최단연결법(Single Linkage Method)
데이터마이닝 제 5 장 군집분석 최단연결법(Single Linkage Method) 두 군집 사이의 거리를 각 군집에서 하나씩 관측값을 뽑았을 때 나타날 수 있는 거리의 최소값으로 측정 유리 위에 떨어진 물방울들이 서로 뭉치는 현상과 비슷 같은 군집에 속하는 관측치는 다른 군집에 속하는 관측치에 비하여 거리가 가까운 변수를 적어도 하나는 갖고있다. 군집이 고리형태로 연결되어 있는 경우에는 부적절한 결과를 제공한다. 고립된 군집을 찾는데 중점을 둔 방법이다.
 두 군집 사이의 거리를 각 군집에서 하나씩 관측값을 뽑았을 때 나타날 수 있는 거리의 최소값으로 측정. 유리 위에 떨어진 물방울들이 서로 뭉치는 현상과 비슷. 같은 군집에 속하는 관측치는 다른 군집에 속하는 관측치에 비하여 거리가 가까운 변수를 적어도 하나는 갖고있다. 군집이 고리형태로 연결되어 있는 경우에는 부적절한 결과를 제공한다. 고립된 군집을 찾는데 중점을 둔 방법이다.")
146
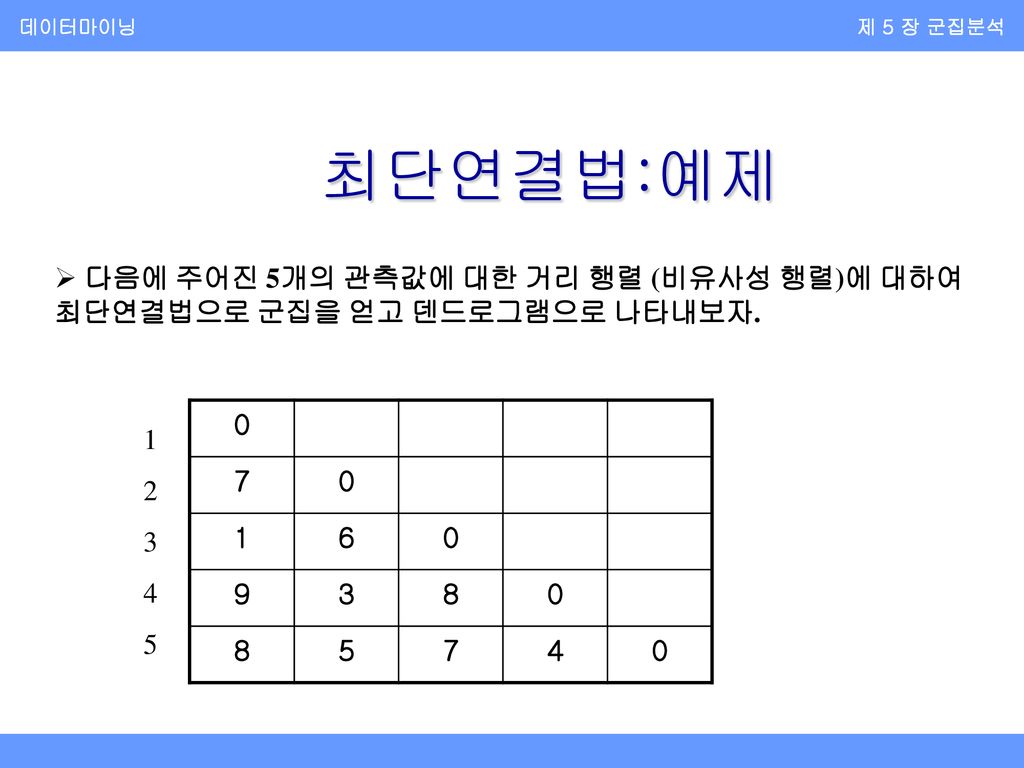
데이터마이닝 제 5 장 군집분석 최단연결법:예제 다음에 주어진 5개의 관측값에 대한 거리 행렬 (비유사성 행렬)에 대하여 최단연결법으로 군집을 얻고 덴드로그램으로 나타내보자. 7 1 6 9 3 8 5 4 1 2 3 4 5
147
최단연결법:예제(계속) 1단계 거리 행렬에서 d(1,3)=1이 최소이므로 관측값 1과 3을 묶어 군집 (1,3)을 만든다.
데이터마이닝 제 5 장 군집분석 최단연결법:예제(계속) 1단계 거리 행렬에서 d(1,3)=1이 최소이므로 관측값 1과 3을 묶어 군집 (1,3)을 만든다. 군집 (1,3)과 관측값 2,4,5와의 거리 d((2),(1,3))=min{d(2,1),d(2,3)}=d(2,3)=6 d((4),(1,3))=min{d(4,1),d(4,3)}=d(4,3)=8 d((5),(1,3))=min{d(5,1),d(5,3)}=d(5,3)=7 를 구하여 다음과 같은 거리 행렬을 만든다.
 1단계. 거리 행렬에서 d(1,3)=1이 최소이므로 관측값 1과 3을 묶어 군집 (1,3)을 만든다. 군집 (1,3)과 관측값 2,4,5와의 거리. d((2),(1,3))=min{d(2,1),d(2,3)}=d(2,3)=6. d((4),(1,3))=min{d(4,1),d(4,3)}=d(4,3)=8. d((5),(1,3))=min{d(5,1),d(5,3)}=d(5,3)=7. 를 구하여 다음과 같은 거리 행렬을 만든다.")
148
데이터마이닝 제 5 장 군집분석 최단연결법:예제(계속) (1,3) 2 6 4 8 3 5 7 2단계 다음의 거리 행렬에서 d(2,4)=3이 최소값을 가지므로 관측값 2와 4를 묶어 군집 (2,4)를 만든다.
=3이 최소값을 가지므로 관측값 2와 4를 묶어 군집 (2,4)를 만든다.")
149
최단연결법:예제(계속) 2단계 (계속) 군집 (2,4)와 군집 (1,3), (5)와의 거리를 구한 후
데이터마이닝 제 5 장 군집분석 최단연결법:예제(계속) 2단계 (계속) 군집 (2,4)와 군집 (1,3), (5)와의 거리를 구한 후 d((2,4),(1,3))=min{d((2),(1,3)),d((4),(1,3))}=d((2),(1,3)}=6 d((5),(2,4))=min{d(5,2),d(5,4)}=d(5,4)=4, 거리 행렬을 다시 다음과 같이 만든다. (1,3) (2,4) 6 5 7 4
 2단계 (계속) 군집 (2,4)와 군집 (1,3), (5)와의 거리를 구한 후. d((2,4),(1,3))=min{d((2),(1,3)),d((4),(1,3))}=d((2),(1,3)}=6. d((5),(2,4))=min{d(5,2),d(5,4)}=d(5,4)=4, 거리 행렬을 다시 다음과 같이 만든다. (1,3) (2,4)")
150
데이터마이닝 제 5 장 군집분석 최단연결법:예제(계속) 3단계 d((5),(2,4))=4이 최소값을 가지므로 군집 (2,4)와 (5)를 묶어 (2,4,5)를 만든 후 d((1,3),(2,4,5))=d(2,3)=6을 이용하여 다음의 거리행렬을 얻는다. (1,3) (2,4,5) 6
 (2,4,5) 6.")
151
데이터마이닝 제 5 장 군집분석 최단연결법:예제(계속) 4단계 마지막 단계로 전체가 하나의 군집을 이룬다.
 4단계 마지막 단계로 전체가 하나의 군집을 이룬다.")
152
데이터마이닝 제 5 장 군집분석 최단연결법:예제(계속) 덴드로그램을 그리면 다음과 같다.
 덴드로그램을 그리면 다음과 같다.")
153
최장(완전)연결법(Complete Linkage Method)
데이터마이닝 제 5 장 군집분석 최장(완전)연결법(Complete Linkage Method) 두 군집 사이의 거리를 각 군집에서 하나씩 관측값을 뽑았을 때 나타날 수 있는 거리의 최대값으로 측정 같은 군집에 속하는 관측치는 알려진 최대 거리보다 짧다. 군집들의 내부 응집성에 중점을 둔다.
연결법(Complete Linkage Method) 두 군집 사이의 거리를 각 군집에서 하나씩 관측값을 뽑았을 때 나타날 수 있는 거리의 최대값으로 측정. 같은 군집에 속하는 관측치는 알려진 최대 거리보다 짧다. 군집들의 내부 응집성에 중점을 둔다.")
154
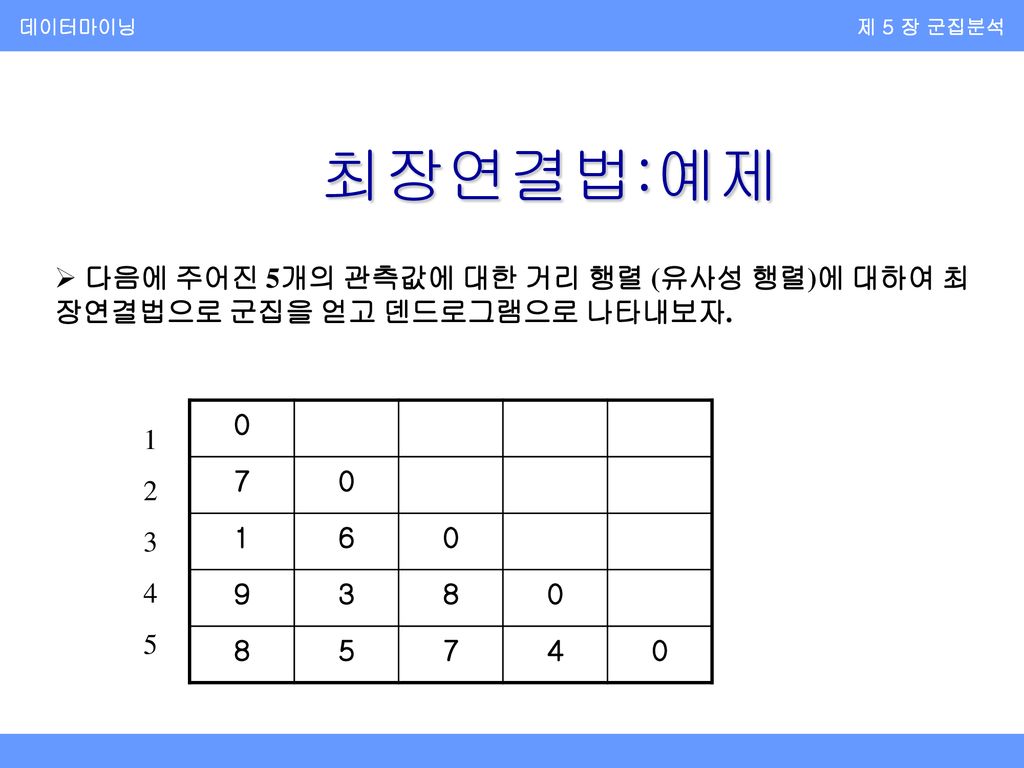
데이터마이닝 제 5 장 군집분석 최장연결법:예제 다음에 주어진 5개의 관측값에 대한 거리 행렬 (유사성 행렬)에 대하여 최장연결법으로 군집을 얻고 덴드로그램으로 나타내보자. 7 1 6 9 3 8 5 4 1 2 3 4 5
155
데이터마이닝 제 5 장 군집분석 최장연결법:예제(계속) 1단계 1단계는 최단연결법의 1단계와 같다. 즉, 관측값 1과 3이 최단거리에 위치하고 이를 묶어서 새로운 군집 (1,3)을 만든다. 군집 (1,3)과 관측값 2,4,5와의 거리 d((2),(1,3))=max{d(2,1),d(2,3)}=d(2,1)=7 d((4),(1,3))=max{d(4,1),d(4,3)}=d(4,1)=9 d((5),(1,3))=max{d(5,1),d(5,3)}=d(5,1)=8 를 구하여 다음과 같은 거리 행렬을 만든다.
과 관측값 2,4,5와의 거리. d((2),(1,3))=max{d(2,1),d(2,3)}=d(2,1)=7. d((4),(1,3))=max{d(4,1),d(4,3)}=d(4,1)=9. d((5),(1,3))=max{d(5,1),d(5,3)}=d(5,1)=8. 를 구하여 다음과 같은 거리 행렬을 만든다.")
156
데이터마이닝 제 5 장 군집분석 최장연결법:예제(계속) (1,3) 2 7 4 9 3 5 8 2단계 다음의 거리 행렬에서 d(2,4)=3이 최소값을 가지므로 관측값 2와 4를 묶어 군집 (2,4)를 만든다.
=3이 최소값을 가지므로 관측값 2와 4를 묶어 군집 (2,4)를 만든다.")
157
최장연결법:예제(계속) 2단계 (계속) 군집 (2,4)와 군집 (1,3), (5)와의 거리를 구한 후
데이터마이닝 제 5 장 군집분석 최장연결법:예제(계속) 2단계 (계속) 군집 (2,4)와 군집 (1,3), (5)와의 거리를 구한 후 d((2,4),(1,3))=max{d((2),(1,3)),d((4),(1,3))}=d((4),(1,3)}=9 d((5),(2,4))=max{d(5,2),d(5,4)}=d(2,4)=5, 거리 행렬을 다시 다음과 같이 만든다. (1,3) (2,4) 9 5 7
 2단계 (계속) 군집 (2,4)와 군집 (1,3), (5)와의 거리를 구한 후. d((2,4),(1,3))=max{d((2),(1,3)),d((4),(1,3))}=d((4),(1,3)}=9. d((5),(2,4))=max{d(5,2),d(5,4)}=d(2,4)=5, 거리 행렬을 다시 다음과 같이 만든다. (1,3) (2,4)")
158
데이터마이닝 제 5 장 군집분석 최장연결법:예제(계속) 3단계 d((5),(2,4))=4이 최소값을 가지므로 군집 (2,4)와 (5)를 묶어 (2,4,5)를 만든 후 d((1,3),(2,4,5))=d(1,4)=9을 이용하여 다음의 거리행렬을 얻는다. (1,3) (2,4,5) 9
 (2,4,5) 9.")
159
데이터마이닝 제 5 장 군집분석 최장연결법:예제(계속) 4단계 마지막 단계로 전체가 하나의 군집을 이룬다.
 4단계 마지막 단계로 전체가 하나의 군집을 이룬다.")
160
데이터마이닝 제 5 장 군집분석 최장연결법:예제(계속) 덴드로그램을 그리면 다음과 같다.
 덴드로그램을 그리면 다음과 같다.")
161
비계층적 군집분석의 개요 비계층적 군집분석에는 흔히 관측값들을 몇 개의 군집으로 나누기 위하여 주어진 판정기준을 최적화 한다.
데이터마이닝 제 5 장 군집분석 비계층적 군집분석의 개요 비계층적 군집분석에는 흔히 관측값들을 몇 개의 군집으로 나누기 위하여 주어진 판정기준을 최적화 한다. 따라서, 최적분리 군집분석이라고 한다. 대표적인 비계층적 군집분석 방법이 k- 평균 방법이다.

162
K-평균 군집방법 사전에 결정된 군집수 k에 기초하여 전체 데이터를 상대적으로 유사한 k개의 군집으로 구분한다.
데이터마이닝 제 5 장 군집분석 K-평균 군집방법 사전에 결정된 군집수 k에 기초하여 전체 데이터를 상대적으로 유사한 k개의 군집으로 구분한다. k-평균 군집법은 계보적 군집법에 비하여 계산량이 적다. 따라서, 대용량 데이터를 빠르게 처리할 수 있다.

163
K-평균 군집법의 알고리즘 군집수 k를 결정한다. 초기 k개 군집의 중심을 선택한다.
데이터마이닝 제 5 장 군집분석 K-평균 군집법의 알고리즘 군집수 k를 결정한다. 초기 k개 군집의 중심을 선택한다. 각 관찰치를 그 중심과 가장 가까운 거리에 있는 군집에 할당한다. 위의 과정을 기존의 중심과 새로운 중심의 차이가 없을 때까지 반복한다.

164
데이터마이닝 제 5 장 군집분석 알고리즘 설명 다음의 그림을 생각하자

165
알고리즘 설명(계속) 그림 7-3은 거리를 표현하는 변수가 x1,x2로 하여 2차원으로 표현한 각 관찰치의 위치이다.
데이터마이닝 제 5 장 군집분석 알고리즘 설명(계속) 그림 7-3은 거리를 표현하는 변수가 x1,x2로 하여 2차원으로 표현한 각 관찰치의 위치이다. 그림을 보고 먼저, 군집수를 3으로 결정한다. 자료를 임의로 3등분하여 각각의 평균을 각 군집의 평균으로 정한다. 그림 7-4와 같이 주어진 군집의 중심을 기준으로 관찰치를 가장 가까운 군집에 할당한다. 새로운 군집의 생기면 각 새로운 군집의 중심을 각 군집의 평균으로 갱신한다. 그림 7-4에서 회색점이 과거 중심이고 검은점이 갱신된 중심이다.
 그림 7-3은 거리를 표현하는 변수가 x1,x2로 하여 2차원으로 표현한 각 관찰치의 위치이다. 그림을 보고 먼저, 군집수를 3으로 결정한다. 자료를 임의로 3등분하여 각각의 평균을 각 군집의 평균으로 정한다. 그림 7-4와 같이 주어진 군집의 중심을 기준으로 관찰치를 가장 가까운 군집에 할당한다. 새로운 군집의 생기면 각 새로운 군집의 중심을 각 군집의 평균으로 갱신한다. 그림 7-4에서 회색점이 과거 중심이고 검은점이 갱신된 중심이다.")
166
초기군집수의 결정 K-평균 군집분석법의 결과는 초기 군집수 k의 결정에 민감하게 반응한다.
데이터마이닝 제 5 장 군집분석 초기군집수의 결정 K-평균 군집분석법의 결과는 초기 군집수 k의 결정에 민감하게 반응한다. 실제 자료의 분석에서는 여러 가지의 k값을 선택하여 군집분석을 수행한 후 가장 좋다고 생각되는 k값을 이용한다. 여러 개의 군집분석 결과 중 어떤 결과가 좋은가 하는 문제는 관측값 간의 평균 거리와 군집간의 평균거리를 비교함으로써 수행한다. 가장 좋은 방법은 자료의 시각화를 통한 최적 군집수의 결정인데, 자료의 시각화를 위하여는 차원의 축소가 필수적이고, 이를 위하여 주성분 분석방법이 널리 사용된다. 시각화가 어려운 경우에는 , 여러 가지 통계량을 사용하는데, 예를 들면, 각 그룹의 산포행렬의 행렬식을 최소로 하는 군집수를 찾는다.

167
단위 변환 군집분석은 자료 사이의 거리를 이용하여 수행되기 때문에, 각 자료의 단위가 결과에 큰 영향을 미친다.
데이터마이닝 제 5 장 군집분석 단위 변환 군집분석은 자료 사이의 거리를 이용하여 수행되기 때문에, 각 자료의 단위가 결과에 큰 영향을 미친다. 예를 들면, (x,y,z) 세 개의 변수가 어떤 거리를 측정하였다고 했을 때, 그 단위가 x는 야드, y는 센티미터, z는 마일로 측정되었다면, 그 거리의 계산에 유의 하여야 한다. z의 단위 1의 차이는 y의 단위 185,200의 차이와 같고, x의 2,025와 같다. 만약, 서로 다른 종류의 측정치로 자료가 구성되어 있으면, 위와 같은 상대적인 평가도 불가능 하다. 예를 들면, 대지면적, 수입, 건평 등으로 이루어진 자료는 각 변수가 서로 비교될 수 가 없다.
 세 개의 변수가 어떤 거리를 측정하였다고 했을 때, 그 단위가 x는 야드, y는 센티미터, z는 마일로 측정되었다면, 그 거리의 계산에 유의 하여야 한다. z의 단위 1의 차이는 y의 단위 185,200의 차이와 같고, x의 2,025와 같다. 만약, 서로 다른 종류의 측정치로 자료가 구성되어 있으면, 위와 같은 상대적인 평가도 불가능 하다. 예를 들면, 대지면적, 수입, 건평 등으로 이루어진 자료는 각 변수가 서로 비교될 수 가 없다.")
168
단위 변환(계속) 이러한 문제를 해결하기 위하여, 가장 널리 쓰이는 방법이 표준화 방법이다.
데이터마이닝 제 5 장 군집분석 단위 변환(계속) 이러한 문제를 해결하기 위하여, 가장 널리 쓰이는 방법이 표준화 방법이다. 표준화 방법이란 각 변수의 관찰값으로부터 그 변수의 평균을 빼고, 그 변수의 표준편차로 나누는 것이다. 표준화된 자료는 모든 변수가 평균이 0이고 표준편차가 1이 된다. 표준화된 자료의 유클리드거리는 표준화거리와 같다.
 이러한 문제를 해결하기 위하여, 가장 널리 쓰이는 방법이 표준화 방법이다. 표준화 방법이란 각 변수의 관찰값으로부터 그 변수의 평균을 빼고, 그 변수의 표준편차로 나누는 것이다. 표준화된 자료는 모든 변수가 평균이 0이고 표준편차가 1이 된다. 표준화된 자료의 유클리드거리는 표준화거리와 같다.")
169
데이터마이닝 제 5 장 군집분석 가중치 부여 자료의 분석 전에 각 변수의 중요도가 같지 않음을 안다면, 적절한 가중치를 이용하여 각 변수의 중요도를 조절할 수 있다. 예를 들면, 같은 수입을 가지는 두 가족이 같은 대지면적을 가지는 두 가족보다 공통점이 많다고 생각이 드는 경우가 있다. 이 경우에는, 수입 변수에 높은 가중치를 주고 대지면적 변수에 낮은 가중치를 줌으로써 해결한다. 가중치는 대부분의 경우 단위변환(표준화)를 수행한 후 부여한다. 가중치에 대한 군집의 영향을 평가 하기 위하여는 여러 가지의 가중치에 대하여 군집분석의 결과를 구하고 이 결과들을 비교한다.
를 수행한 후 부여한다. 가중치에 대한 군집의 영향을 평가 하기 위하여는 여러 가지의 가중치에 대하여 군집분석의 결과를 구하고 이 결과들을 비교한다.")
170
군집 평가 군집분석에는 분석 전에 정해야 하는 사항이 많다 (예: 초기군집수, 가중치 등)
데이터마이닝 제 5 장 군집분석 군집 평가 군집분석에는 분석 전에 정해야 하는 사항이 많다 (예: 초기군집수, 가중치 등) 분석자의 주관에 의하여 결정되는 이러한 사항들이 군집분석의 결과에 어떻게 영향을 미치는 가를 알아보기 위하여는, 군집분석 결과의 평가가 필수적이다. 좋은 결과는 각 군집 안에서의 분산이 최소로 되는 것이다. 또는, 사용되어진 거리의 측도를 이용하여 군집내의 거리의 평균과 군집간의 거리의 평균을 비교할 수 있다. 즉, 군집내의 거리의 평균이 군집간의 거리의 평균 보다 작으면 좋은 결과이다.
 분석자의 주관에 의하여 결정되는 이러한 사항들이 군집분석의 결과에 어떻게 영향을 미치는 가를 알아보기 위하여는, 군집분석 결과의 평가가 필수적이다. 좋은 결과는 각 군집 안에서의 분산이 최소로 되는 것이다. 또는, 사용되어진 거리의 측도를 이용하여 군집내의 거리의 평균과 군집간의 거리의 평균을 비교할 수 있다. 즉, 군집내의 거리의 평균이 군집간의 거리의 평균 보다 작으면 좋은 결과이다.")
171
변수 선택 찾아진 각 군집은 어떠한 변수에 의하여 군집이 형성됐는가를 파악하는 것을 목적으로 한다.
데이터마이닝 제 5 장 군집분석 변수 선택 찾아진 각 군집은 어떠한 변수에 의하여 군집이 형성됐는가를 파악하는 것을 목적으로 한다. 각 변수에 대한 그룹내의 거리의 평균과 그룹간의 거리의 평균을 측정한다. 그룹내의 거리가 그룹간의 거리에 비하여 아주 작은 변수가, 그 군집을 형성하는데 크게 기여하는 변수이다. 예를 들면, 군집분석을 수행한 결과 특정한 군집에는 소득이 비슷한 사람들이 많이 모여 있음을 알 수 있다. 이를 통하여, 소득이 자료의 패턴에 큰 영향을 주는 것을 확인 할 수 있다.

172
자기영상 군집분석 군집분석에서 오직 하나만의 군집이 존재하는 경우에 아주 유용하게 사용될 수 있다.
데이터마이닝 제 5 장 군집분석 자기영상 군집분석 군집분석에서 오직 하나만의 군집이 존재하는 경우에 아주 유용하게 사용될 수 있다. 예를 들면, 모터제조 공장에서 모터의 불량원인을 알고자 한다. 이 경우, 정상적인 모터의 자료를 이용하여 군집분석을 수행하면, 하나의 군집이 찾아진다. 새로운 모터와 이 군집과의 거리가 크면, 이 새로운 모터를 불량모터라고 의심한다. 또 다른 예로는, 위조지폐 탐지가 있다.

173
군집분석의 장점 탐색적인 기법: 주어진 자료의 내부구조에 대한 사전정보 없이 의미있는 자료구조를 찾아낼 수 있다.
데이터마이닝 제 5 장 군집분석 군집분석의 장점 탐색적인 기법: 주어진 자료의 내부구조에 대한 사전정보 없이 의미있는 자료구조를 찾아낼 수 있다. 다양한 형태의 데이터에 적용가능: 거리만 잘 정의되면, 모든 종류의 자료에 적용할 수 있다. 예를 들면, 신문기사와 같은 텍스트 자료도 그 거리만 잘 정의하면 얼마든지 군집분석을 사용할 수 있다. 분석방법의 적용 용이성: 자료의 사전정보를 필요로 하지 않아서 누구나 쉽게 분석할 수 있다.

174
군집분석의 단점 가중치와 거리 정의: 가중치와 거리를 어떻게 정의하는 가에 따라 군집분석의 결과가 아주 민감하게 반응한다.
데이터마이닝 제 5 장 군집분석 군집분석의 단점 가중치와 거리 정의: 가중치와 거리를 어떻게 정의하는 가에 따라 군집분석의 결과가 아주 민감하게 반응한다. 초기 군집수 k의 결정이 쉽지 않다. 결과의 해석이 어렵다. 특히, 찾아진 군집이 무엇을 의미 하는지 데이터만을 이용해서는 알 수가 없다.

175
데이터마이닝 제 6 장 연관성분석 제 6장 연관성분석

176
연관성 분석이란? 데이터 안에 존재하는 항목간의 연관규칙 (association rule)을 발견하는 과정 연관규칙이란
데이터마이닝 제 6 장 연관성분석 연관성 분석이란? 데이터 안에 존재하는 항목간의 연관규칙 (association rule)을 발견하는 과정 연관규칙이란 상품을 구매하거나 서비스를 받는 등의 일련의 거래나 사건들의 연관성에 대한 규칙이다. 연관성 분석을 마케팅에서 손님의 장바구니에 들어있는 품목간의 관계를 알아본다는 의미에서 장바구니분석 (market basket analysis)이라고도 한다.
을 발견하는 과정. 연관규칙이란. 상품을 구매하거나 서비스를 받는 등의 일련의 거래나 사건들의 연관성에 대한 규칙이다. 연관성 분석을 마케팅에서 손님의 장바구니에 들어있는 품목간의 관계를 알아본다는 의미에서 장바구니분석 (market basket analysis)이라고도 한다.")
177
연관성 분석의 개념의 이해 슈퍼마켓에서 구입한 고객의 물건들이 담겨져 있는 장바구니의 정보를 생각하자
데이터마이닝 제 6 장 연관성분석 연관성 분석의 개념의 이해 슈퍼마켓에서 구입한 고객의 물건들이 담겨져 있는 장바구니의 정보를 생각하자 연관성 분석은, 특정한 상품을 구입한 고객이 어떤 부류에 속하는지, 그들이 왜 그런 구매를 했는지를 알기 위해서 고객들이 구매한 상품에 대한 자료를 분석하는 것. 이러한 분석을 통하여 효율적인 매장진열, 패키지 상품의 개발, 교차판매전략 구사, 기획상품의 결정 등에 응용할 수 있다.

178
연관성 분석의 응용 백화점이나 호텔에서 고객들이 다음에 원하는 서비스를 미리 알 수 있다.
데이터마이닝 제 6 장 연관성분석 연관성 분석의 응용 백화점이나 호텔에서 고객들이 다음에 원하는 서비스를 미리 알 수 있다. 신용카드, 대출 등의 은행서비스 내역으로 부터 특정한 서비스를 받을 가능성이 높은 고객의 탐지 가능 의료보험금이나 상해보험금 청구가 특이한 경우 보험사기의 징조가 될 수 있고 추가적인 조사 필요 환자의 의무기록에서 여러 치료가 같이 이루어진 경우 합병증 발생의 징후 탐지

179
연관성 규칙의 예 목요일 식료품 가게를 찾는 고객은 아기 기저귀와 맥주를 함께 구입하는 경향이 있다.
데이터마이닝 제 6 장 연관성분석 연관성 규칙의 예 목요일 식료품 가게를 찾는 고객은 아기 기저귀와 맥주를 함께 구입하는 경향이 있다. 한 회사의 전자제품을 구매하던 고객은 전자제품을 살 때 같은 회사의 제품을 사는 경향이 있다. 새로 연 건축 자재점에서는 변기덮개가 많이 팔린다.

180
연관성 규칙의 예: (계속) 첫 번째 규칙은 유용한 규칙으로 이를 이용하여 식료품 가게의 매출을 증가시킬 수 있다.
데이터마이닝 제 6 장 연관성분석 연관성 규칙의 예: (계속) 첫 번째 규칙은 유용한 규칙으로 이를 이용하여 식료품 가게의 매출을 증가시킬 수 있다. 두 번째 규칙은 자명한 규칙으로, 대부분의 사람들이 이미 알고 있다. 자명한 규칙의 발견은 기존의 정보를 재 확인 하는 의미가 있다 세 번째 규칙은 설명이 불가능한 규칙이며, 좀더 세밀한 조사가 필요하다.
 첫 번째 규칙은 유용한 규칙으로 이를 이용하여 식료품 가게의 매출을 증가시킬 수 있다. 두 번째 규칙은 자명한 규칙으로, 대부분의 사람들이 이미 알고 있다. 자명한 규칙의 발견은 기존의 정보를 재 확인 하는 의미가 있다. 세 번째 규칙은 설명이 불가능한 규칙이며, 좀더 세밀한 조사가 필요하다.")
181
연관규칙의 탐색 및 평가 연관성분석은 하나 이상의 제품이나 서비스를 포함하는 거래 내 역을 가지고 시작한다.
데이터마이닝 제 6 장 연관성분석 연관규칙의 탐색 및 평가 연관성분석은 하나 이상의 제품이나 서비스를 포함하는 거래 내 역을 가지고 시작한다. 연관성 분석은 분석 목적상 제조업에서 생성된 제품이나 서비스 를 품목 (item)이라 한다. 다음의 표는 5개 제품을 취급하는 편의점에 대한 5번의 거래 내역 이다.
이라 한다. 다음의 표는 5개 제품을 취급하는 편의점에 대한 5번의 거래 내역. 이다.")
182
식료품에 대한 거래 내역 고객번호 품목 1 2 3 4 5 오렌지 쥬스,사이다 우유, 오렌지 쥬스, 식기세척제
데이터마이닝 제 6 장 연관성분석 식료품에 대한 거래 내역 고객번호 품목 1 2 3 4 5 오렌지 쥬스,사이다 우유, 오렌지 쥬스, 식기세척제 오렌지 쥬스, 세제 오렌지 쥬스, 세제, 사이다 식기 세척제, 사이다

183
데이터마이닝 제 6 장 연관성분석 동시구매표의 작성 오렌지 쥬스 식기 세척제 우유 사이다 세제 4 1 2 3

184
동시구매표의 작성(계속) 동시구매표는 대칭행렬의 모형을 보인다.
데이터마이닝 제 6 장 연관성분석 동시구매표의 작성(계속) 동시구매표는 대칭행렬의 모형을 보인다. 동시구매표를 보면 두 상품이 몇 번이나 함께 팔렸는지 알 수 있다. 예를 들면, 사이다 행과 오렌지 쥬스 열이 교차하는 값을 살펴보면 두 상품이 두 번 같이 구매되었음을 알 수 있다. 동시구매표의 대각선 상의 자료 값은 바로 그 품목을 포함하는 총 거래수를 나타낸다. 예를 들면, 오렌지 쥬스는 4번 구매되었다.
 동시구매표는 대칭행렬의 모형을 보인다. 동시구매표를 보면 두 상품이 몇 번이나 함께 팔렸는지 알 수 있다. 예를 들면, 사이다 행과 오렌지 쥬스 열이 교차하는 값을 살펴보면 두 상품이 두 번 같이 구매되었음을 알 수 있다. 동시구매표의 대각선 상의 자료 값은 바로 그 품목을 포함하는 총 거래수를 나타낸다. 예를 들면, 오렌지 쥬스는 4번 구매되었다.")
185
연관 규칙의 조건 동시구매표로 부터 간단한 규칙 (예: 사이다를 구입하는 고객은 오렌지 쥬스를 산다)을 만들 수 있다.
데이터마이닝 제 6 장 연관성분석 연관 규칙의 조건 동시구매표로 부터 간단한 규칙 (예: 사이다를 구입하는 고객은 오렌지 쥬스를 산다)을 만들 수 있다. 두 품목을 함께 산 경우는 총 5번의 구매 중 2번 일어났으며 사이다를 산 3번의 구매 중 오렌지 쥬스가 2번 구매되었다. 연관 규칙은 “If A, then B”와 같은 형식으로 표현된다. 모든 “if-then” 규칙이 유용한 규칙이 아니다. 찾아진 규칙이 유용하게 사용되기 위하여는 두 품목 (품목 A와 품목 B) 이 함께 구매한 경우의 수가 일정 수준 이상 이여야 하며(일정 이상의 지지도) 품목 A를 포함하는 거래 중 품목 B를 구입하는 경우의 수가 일정수준 이상 이여야 한다 (일정 이상의 신뢰도)
을 만들 수 있다. 두 품목을 함께 산 경우는 총 5번의 구매 중 2번 일어났으며 사이다를 산 3번의 구매 중 오렌지 쥬스가 2번 구매되었다. 연관 규칙은 If A, then B 와 같은 형식으로 표현된다. 모든 if-then 규칙이 유용한 규칙이 아니다. 찾아진 규칙이 유용하게 사용되기 위하여는. 두 품목 (품목 A와 품목 B) 이 함께 구매한 경우의 수가 일정 수준 이상 이여야 하며(일정 이상의 지지도) 품목 A를 포함하는 거래 중 품목 B를 구입하는 경우의 수가 일정수준 이상 이여야 한다 (일정 이상의 신뢰도)")
186
데이터마이닝 제 6 장 연관성분석 지지도(Support) 두 품목 A와 B의 지지도는 전체 거래항목 중 항목 A와 항목 B가 동시에 포함하는 거래의 비율 B A*B A 지지도=Pr(A*B)= A와 B가 동시에 포함된 거래수/ 전체 거래수
= A와 B가 동시에 포함된 거래수/ 전체 거래수.")
187
신뢰도(Confidence) B A*B A 연관성 규칙 “If A, then B”의 신뢰도는
데이터마이닝 제 6 장 연관성분석 신뢰도(Confidence) 연관성 규칙 “If A, then B”의 신뢰도는 B A*B A 신뢰도=P(A*B) = 품목 A와 B를 동시에 포함하는 거래 수 P(A) 품목 A를 포함하는 거래 수
 연관성 규칙 If A, then B 의 신뢰도는. B. A*B. A. 신뢰도=P(A*B) = 품목 A와 B를 동시에 포함하는 거래 수. P(A) 품목 A를 포함하는 거래 수.")
188
예제 연관성 규칙 “오렌지 쥬스를 사면 사이다를 구매한다”의 지지도와 신뢰도를 구해보자. 지지도= 2/5 신뢰도= 2/4.
데이터마이닝 제 6 장 연관성분석 예제 연관성 규칙 “오렌지 쥬스를 사면 사이다를 구매한다”의 지지도와 신뢰도를 구해보자. 지지도= 2/5 신뢰도= 2/4. 연관성 규칙 “우유와 오렌지 쥬스를 사면 식기세척제를 산다”의 지지도와 신뢰도를 구하면 지지도= 1/5 신뢰도=1/1

189
지지도와 신뢰도: 예제 다음은 세 품목 A,B,C 의 동시거래 내역이다. 전체거래 회수 =2000 항목 거래의 수 A 100
데이터마이닝 제 6 장 연관성분석 지지도와 신뢰도: 예제 다음은 세 품목 A,B,C 의 동시거래 내역이다. 항목 거래의 수 A 100 A+C 300 B 150 B+C 200 C A+B+C A+B 400 추가 안함 550 전체거래 회수 =2000

190
지지도와 신뢰도: 예제 각 품목의 조합에 대한 지지도 항목 품목이 포함된 총 거래의 수 확률 A 900 0.450 A+C
데이터마이닝 제 6 장 연관성분석 지지도와 신뢰도: 예제 각 품목의 조합에 대한 지지도 항목 품목이 포함된 총 거래의 수 확률 A 900 0.450 A+C 400 0.200 B 850 0.425 B+C 300 0.150 C 800 0.400 A+B+C 100 0.05 A+B 500 0.250

191
지지도와 신뢰도: 예제 모든 연관성 규칙에 대한 신뢰도 규칙 P(A*B) P(A) 신뢰도 A B 25 45 0.556 B A
데이터마이닝 제 6 장 연관성분석 지지도와 신뢰도: 예제 모든 연관성 규칙에 대한 신뢰도 규칙 P(A*B) P(A) 신뢰도 A B 25 45 0.556 B A 42.5 0.588 C B 15 40 0.375 B C 0.353 A C 규칙 P(A*B) P(A) 신뢰도 C A 20 40 0.500 (A+B) C 5 25 0.200 (B+C) A 15 0.333 (A+C) B 0.250
 P(A) 신뢰도. A B B A C B B C A C. 규칙. P(A*B) P(A) 신뢰도. C A (A+B) C (B+C) A (A+C) B")
192
향상도 (Lift) 3가지 품목을 포함하는 연관성 규칙 중 가장 신뢰도가 높은 규칙은 “B와 C를 구입하면 A도 구매한다”
데이터마이닝 제 6 장 연관성분석 향상도 (Lift) 3가지 품목을 포함하는 연관성 규칙 중 가장 신뢰도가 높은 규칙은 “B와 C를 구입하면 A도 구매한다” 이며, 이 연관성 규칙의 신뢰도는 0.333이다. 그러나, 이 연관성 규칙 실질적으로 의미 있는 규칙이 못 된다. 왜냐하면, 전체 거래에서 품목 A의 거래가 일어날 가능성은 0.45이기 때문이다. 즉, 위의 연관성 규칙은 규칙이 없는 경우보다 못한 결과를 준다. 이러한, 연관성 규칙의 성질을 향상도를 통하여 파악할 수 있다.
 3가지 품목을 포함하는 연관성 규칙 중 가장 신뢰도가 높은 규칙은. B와 C를 구입하면 A도 구매한다 이며, 이 연관성 규칙의 신뢰도는 0.333이다. 그러나, 이 연관성 규칙 실질적으로 의미 있는 규칙이 못 된다. 왜냐하면, 전체 거래에서 품목 A의 거래가 일어날 가능성은 0.45이기 때문이다. 즉, 위의 연관성 규칙은 규칙이 없는 경우보다 못한 결과를 준다. 이러한, 연관성 규칙의 성질을 향상도를 통하여 파악할 수 있다.")
193
향상도: 정의 연관성 규칙 “A이면 B이다”의 향상도는 향상도= 품목 A와 B를 포함하는 거래 수 * 전체 거래 수
데이터마이닝 제 6 장 연관성분석 향상도: 정의 연관성 규칙 “A이면 B이다”의 향상도는 향상도= 품목 A와 B를 포함하는 거래 수 * 전체 거래 수 품목 A를 포함하는 거래 수* 품목 B를 포함하는 거래 수 = P(A*B) = P(B|A) = 신뢰도 P(A)P(B) P(B) P(B) 즉, 향상도는 품목 A가 주어지지 않았을 때의 품목 B의 확률 대비 품목 A가 주어졌을 때의 품목 B의 확률의 증가 비율 이다. 이 값이 클 수로, 품목 A의 구매여부가 품목 B의 구매 여부에 큰 영향을 미친다.
 = P(B|A) = 신뢰도. P(A)P(B) P(B) P(B) 즉, 향상도는 품목 A가 주어지지 않았을 때의 품목 B의 확률 대비 품목 A가 주어졌을 때의 품목 B의 확률의 증가 비율 이다. 이 값이 클 수로, 품목 A의 구매여부가 품목 B의 구매 여부에 큰 영향을 미친다.")
194
향상도: 해석 품목 A와 품목 B의 구매가 상호 관련이 없다면 P(B|A)와 P(B)와 같게 되어 향상도가 1이 된다.
데이터마이닝 제 6 장 연관성분석 향상도: 해석 품목 A와 품목 B의 구매가 상호 관련이 없다면 P(B|A)와 P(B)와 같게 되어 향상도가 1이 된다. 어떤 규칙의 향상도가 1보다 크면, 이 규칙은 결과를 예측하는데 있어서 우연적 기회 (random chance)보다 우수하다는 것을 의미하고 향상도가 1보다 작으면 이러한 규칙은 결과를 예측하는데 있어서 우연적 기회보다 나쁠 것이다. 향상도 의미 1 두 품목이 독립적인 관계 < 1 두 품목이 서로 음의 상관 관계 > 1 두 품목이 서로 양의 상관 관계
와 P(B)와 같게 되어 향상도가 1이 된다. 어떤 규칙의 향상도가 1보다 크면, 이 규칙은 결과를 예측하는데 있어서 우연적 기회 (random chance)보다 우수하다는 것을 의미하고. 향상도가 1보다 작으면 이러한 규칙은 결과를 예측하는데 있어서 우연적 기회보다 나쁠 것이다. 향상도. 의미. 1. 두 품목이 독립적인 관계. < 1. 두 품목이 서로 음의 상관 관계. > 1. 두 품목이 서로 양의 상관 관계.")
195
연관성분석의 절차 연관성 분석의 3단계 첫 번째 단계: 적절한 품목의 선택
데이터마이닝 제 6 장 연관성분석 연관성분석의 절차 연관성 분석의 3단계 첫 번째 단계: 적절한 품목의 선택 두 번째 단계: 동시구매표를 이용하여 연관규칙을 찾아내는 단계 세 번째 단계: 품목의 수가 너무 많아서 생기는 문제점들의 해결

196
올바른 품목의 선택 어떤 품목을 선택할 것이냐는 문제는 전적으로 분석의 목적에 달려있다.
데이터마이닝 제 6 장 연관성분석 올바른 품목의 선택 어떤 품목을 선택할 것이냐는 문제는 전적으로 분석의 목적에 달려있다. 예를 들면, 대형 할인점에서는 술을 하나의 상위 품목으로 고려할 수 있다. 그러나, 어떤 경우에는 술을 세분화 하여 술을 소주, 양주, 맥주, 포도주, 막걸리 등의 술의 종류로 선택 할 수 있다. 더욱 세분화 하여 포도주를 적색포도주와 백색포도주로 분류할 수 있고, 또한, 제조사의 상호를 기반으로 하여 분류할 수도 있다.

197
올바른 품목의 선택(계속) 탐색해야 할 규칙의 수는 고려되는 품목의 수에 따라 지수적으로 증가한다.
데이터마이닝 제 6 장 연관성분석 올바른 품목의 선택(계속) 탐색해야 할 규칙의 수는 고려되는 품목의 수에 따라 지수적으로 증가한다. 품목의 수를 줄이는 방법중의 하나가, 품목의 분류를 상위수준으로 일반화 한다. (모든 종류의 술을 하나의 품목으로 분석) 다른 한편으로는, 품목을 세분화 하면 결과의 활용성이 높아진다. 예를 들면, 특정한 상표의 술에 대한 정보는 그 회사의 미래 마케팅 전략에 사용될 수 있다. 일반적인 방법은, 일차단계에서 상위수준의 품목 분류를 이용하여 규칙을 찾은 후 이를 바탕으로 세분화된 품목으로 분석을 진행시켜 나간다.
 탐색해야 할 규칙의 수는 고려되는 품목의 수에 따라 지수적으로 증가한다. 품목의 수를 줄이는 방법중의 하나가, 품목의 분류를 상위수준으로 일반화 한다. (모든 종류의 술을 하나의 품목으로 분석) 다른 한편으로는, 품목을 세분화 하면 결과의 활용성이 높아진다. 예를 들면, 특정한 상표의 술에 대한 정보는 그 회사의 미래 마케팅 전략에 사용될 수 있다. 일반적인 방법은, 일차단계에서 상위수준의 품목 분류를 이용하여 규칙을 찾은 후 이를 바탕으로 세분화된 품목으로 분석을 진행시켜 나간다.")
198
데이터마이닝 제 6 장 연관성분석 올바른 품목의 선택(계속) 연관성분석은 각 품목들의 거래회수가 비슷한 경우에 가장 효율적으로 수행될 수 있다. 분류체계를 이용하여, 거래회수가 비교적으로 작은 품목은 상위수준의 분류체계를 사용하고, 거래회수가 많은 품목은 세분화 하여 거래회수를 줄인다. 가상 품목을 지정하여 사용할 수 있다. 예를 들면, 디자이너 레벨(예: Calvin Klein), 저지방과 무지방 제품, 에너지 절약형 옵션, 현금 또는 신용카드 등을 들 수 있다. 하지만, 이러한 가상 품목은 품목의 개수를 지나치게 많게 할 수 있는 위험이 있다. 따라서, 가상 품목의 지정에 신중을 기하여야 한다.
, 저지방과 무지방 제품, 에너지 절약형 옵션, 현금 또는 신용카드 등을 들 수 있다. 하지만, 이러한 가상 품목은 품목의 개수를 지나치게 많게 할 수 있는 위험이 있다. 따라서, 가상 품목의 지정에 신중을 기하여야 한다.")
199
연관규칙 발견 규칙을 어떻게 표현 하느냐가 중요하다.
데이터마이닝 제 6 장 연관성분석 연관규칙 발견 규칙을 어떻게 표현 하느냐가 중요하다. “아기 기저귀와 목요일이 주어지면 맥주가 결과”인 규칙이 “목요일이면 아기 기저귀와 맥주” 보다 유익하다. 향상도가 1보다 작은 경우에는 결과를 역으로 나타내는 것이 좋다. 시차에 따라 이루어지는 구매에서는 시차 연관성분석을 하는 것이 바람직하다.

200
현실적 문제의 해결 품목의 수가 증가하면 계산량은 기하급수적으로 증가하게 된다.
데이터마이닝 제 6 장 연관성분석 현실적 문제의 해결 품목의 수가 증가하면 계산량은 기하급수적으로 증가하게 된다. 이것을 해결하는 방법으로 가지치기 (pruning)을 이용하여 불필요한 부분을 간략하게 한다. 가지치기는 각 단계에서 문턱기준(threshold criterion)을 만족하지 못하는 조합을 버리는 것이다. 가장 보편적인 가지치기방법은 최소지지도 가지치기(Minimum Support Pruning, MSP)이다. 즉, 지지도가 문턱기준보다 작은 품목의 조합은 더 이상 품목을 추가하지 않는다.
을 이용하여 불필요한 부분을 간략하게 한다. 가지치기는 각 단계에서 문턱기준(threshold criterion)을 만족하지 못하는 조합을 버리는 것이다. 가장 보편적인 가지치기방법은 최소지지도 가지치기(Minimum Support Pruning, MSP)이다. 즉, 지지도가 문턱기준보다 작은 품목의 조합은 더 이상 품목을 추가하지 않는다.")
201
음의 연관규칙 향상도가 1보다 작으면, 결과를 역으로 나타내는 것이 좋다.
데이터마이닝 제 6 장 연관성분석 음의 연관규칙 향상도가 1보다 작으면, 결과를 역으로 나타내는 것이 좋다. 음의 연관규칙은 결과에 `이다’ 대신에 `아니다’를 쓴다. 예를 들면, “B와 C이면 A이다”의 신뢰도가 33%이면 “B와 c이면 A가 아니다”의 신뢰도는 67%가 된다. 향상도가 1보다 작은 규칙의 음의 규칙은 1보다 큰 향상도를 갖는다. 그러나, 음의 연관규칙은 원래의 연관규칙만큼 유용하지 않을 수 있다.

202
시차 연관규칙 연관성 규칙은 동시에 일어나는 품목에 대해서 다루었다.
데이터마이닝 제 6 장 연관성분석 시차 연관규칙 연관성 규칙은 동시에 일어나는 품목에 대해서 다루었다. 시계열자료와 같이 사건들이 어떤 순서로 일어나고, 이 사건들 사이의 연관성을 알아내는 것이 시차 연관성분석이다. 예를 들어, 카드 결재 청구가 평소보다 많다는 것과 다음달에 현금서비스를 받는 것과 연관성이 있다. 시차연관성 분석은 흔히, 같은 고객의 구매 패턴을 기반으로 구매 패턴이 시간에 따라 연관이 있는지를 알려고 할 때 사용된다.

203
연관성 분석의 장점 결과가 분명하다 (If-then 규칙) 거대 자료의 분석의 시작으로 적합하다.
데이터마이닝 제 6 장 연관성분석 연관성 분석의 장점 결과가 분명하다 (If-then 규칙) 거대 자료의 분석의 시작으로 적합하다. 변수의 개수가 많은 경우에 쉽게 사용될 수 있다. 계산이 용이하다.
 거대 자료의 분석의 시작으로 적합하다. 변수의 개수가 많은 경우에 쉽게 사용될 수 있다. 계산이 용이하다.")
204
연관성 분석의 단점 품목 수의 증가에 따라 계산량이 폭증한다.
데이터마이닝 제 6 장 연관성분석 연관성 분석의 단점 품목 수의 증가에 따라 계산량이 폭증한다. 자료의 속성에 제한이 있다. 예를 들면, 구매자의 개인정보 중 나이 등의 연속형 변수를 사용할 수 없다. 적절한 품목을 결정하기가 어렵다. 거래가 드문 품목에 대한 정보를 찾기가 어렵다.



 : 다수의 대상들 ( 소비자, 제품, 기타 ) 을 그들이 소유하는 특 성을 토대로 유사한 대상들끼리 그룹핑하는 다변량 통계기법 → 군집내의 구성원들은 가급 적.>")






>")

 학기.>")




 2014년 가을학기 강원대학교 컴퓨터과학전공 문양세.>")



