Download presentation
1
자료구조 김현성

2
1.1 자료구조란? 자료를 효율적으로 사용하기 위해서 자료의 특성에 따라서 분류하여 구성하고 저장 및 처리하는 모든 작업

3
1.1 자료구조의 형태에 따른 분류

4
1.2 소프트웨어 생명주기 자료구조 알고리즘

5
1.3 알고리즘 명세 알고리즘 특정한 일을 수행하기 위한 명령어의 유한 집합
finite set of instructions performing specific task

6
1.3 알고리즘 명세 조건(criteria) 입력 : (외부) 원인 ≥ 0 출력 : 결과 ≥ 1
명백성(definiteness) : 모호하지 않은 명확한 명령 유한성(finiteness) : 유한한 단계 후에 종료 유효성(effectiveness) : 각 연산은 실행가능 명령
 : 모호하지 않은 명확한 명령. 유한성(finiteness) : 유한한 단계 후에 종료. 유효성(effectiveness) : 각 연산은 실행가능 명령.")
7
1.3 알고리즘 명세 자료 >> 알고리즘 절차 연산 [요리 재료]
스펀지케이크(20×20cm) 1개, 크림치즈 200g, 달걀 푼 물 2개 분량, 설탕 3큰술, 레몬즙·바닐라에센스 1큰술씩, 딸기시럽(딸기 500g, 설탕 1½ 컵, 레몬즙 1작은술), 딸기 1개, 플레인 요구르트 2큰술 [요리법] ① 케이크 틀의 가장자리에 필름을 돌린 다음 스펀지케이크를 놓는다. ② 볼에 크림치즈를 넣고 거품기로 젓다가 달걀 푼 물과 설탕 3큰술을 세번에 나누어 넣으면서 크림 상태로 만든다. ③ ②에 레몬즙과 바닐라에센스를 넣고 살짝 저은 다음 ①에 붓는다. 이것을 180℃의 오븐에 넣고 20분 정도 굽는다. ④ 냄비에 슬라이스한 딸기와 설탕 1½ 컵을 넣고 끓이다가 약한 불에서 눌어붙지 않도록 저으면서 거품을 걷어낸다. 되직해지면 레몬즙을 넣고 차게 식힌다. ⑤ 접시에 치즈케이크를 한 조각 담고 ④의 시럽을 뿌린 다음 플레인 요구르트와 딸기를 얹어낸다 >> 알고리즘 절차 연산
![1.3 알고리즘 명세 자료 >> 알고리즘 절차 연산 [요리 재료]](http://slidesplayer.org/slide/14570898/90/images/7/1.3+%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98+%EB%AA%85%EC%84%B8+%EC%9E%90%EB%A3%8C+%3E%3E+%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98+%EC%A0%88%EC%B0%A8+%EC%97%B0%EC%82%B0+%5B%EC%9A%94%EB%A6%AC+%EC%9E%AC%EB%A3%8C%5D.jpg "스펀지케이크(20×20cm) 1개, 크림치즈 200g, 달걀 푼 물 2개 분량, 설탕 3큰술, 레몬즙·바닐라에센스 1큰술씩, 딸기시럽(딸기 500g, 설탕 1½ 컵, 레몬즙 1작은술), 딸기 1개, 플레인 요구르트 2큰술. [요리법] ① 케이크 틀의 가장자리에 필름을 돌린 다음 스펀지케이크를 놓는다. ② 볼에 크림치즈를 넣고 거품기로 젓다가 달걀 푼 물과 설탕 3큰술을 세번에 나누어 넣으면서 크림 상태로 만든다. ③ ②에 레몬즙과 바닐라에센스를 넣고 살짝 저은 다음 ①에 붓는다. 이것을 180℃의 오븐에 넣고 20분 정도 굽는다. ④ 냄비에 슬라이스한 딸기와 설탕 1½ 컵을 넣고 끓이다가 약한 불에서 눌어붙지 않도록 저으면서 거품을 걷어낸다. 되직해지면 레몬즙을 넣고 차게 식힌다. ⑤ 접시에 치즈케이크를 한 조각 담고 ④의 시럽을 뿌린 다음 플레인 요구르트와 딸기를 얹어낸다. >> 알고리즘. 절차. 연산.")
8
1.3 알고리즘의 표현방법 자연어를 이용한 서술적 표현 방법 순서도(Flow chart)를 이용한 도식화 표현 방법
프로그래밍 언어를 이용한 구체화 방법 가상코드(Pseudo-code)를 이용한 추상화 방법
를 이용한 추상화 방법.")
9
1.3 데이타 추상화 뇌의 추상화 기능 기억할 대상의 구별되는 특징만을 단순화하여 기억

10
1.3 데이타 추상화 추상화와 구체화 추상화 : “무엇(what)인가?”를 논리적으로 정의
구체화 : “어떻게(how) 할 것인가?”를 실제적으로 표현
 할 것인가 를 실제적으로 표현.")
11
1.3 데이타 추상화 정의: 추상 자료형(ADT : abstract data type)
객체의 명세와 그 연산의 명세가 그 객체의 표현과 연산의 구현으로부터 분리된 자료형 - 명세와 구현을 명시적으로 구분 . Ada - package, C++ - Class

12
1.3 데이타 추상화 Structure Natural_Number
객체(objects): 0에서 시작해서 컴퓨터상의 최대 정수 값(INT_MAX)까지 순서화된 정수의 부분 범위이다. 함수(functions): for all x, y ∈ Nat_Number, TRUE, FALSE ∈ Boolean에 대해, 여기서 +, -, <, 그리고 == 는 일반적인 정수 연산자이다. Nat_No Zero() ::= 0 Boolean Is_Zero(x) ::= if (x) then FALSE else return TRUE Nat_No Add(x, y) ::= if ((x+y)<=INT_MAX) return x+y else return INT_MAX Boolean Equal(x,y) ::= if (x==y) return TRUE else return FALSE Nat_No Succesor(x) ::= if (x==INT_MAX) return x else return x+1 Nat_No Subtract(x,y) ::= if (x<y) return 0 else return x-y end Natural_Number
: 0에서 시작해서 컴퓨터상의 최대 정수 값(INT_MAX)까지 순서화된 정수의 부분 범위이다. 함수(functions): for all x, y ∈ Nat_Number, TRUE, FALSE ∈ Boolean에 대해, 여기서 +, -, <, 그리고 == 는 일반적인 정수 연산자이다. Nat_No Zero() ::= 0. Boolean Is_Zero(x) ::= if (x) then FALSE. else return TRUE. Nat_No Add(x, y) ::= if ((x+y)<=INT_MAX) return x+y. else return INT_MAX. Boolean Equal(x,y) ::= if (x==y) return TRUE. else return FALSE. Nat_No Succesor(x) ::= if (x==INT_MAX) return x. else return x+1. Nat_No Subtract(x,y) ::= if (x<y) return 0. else return x-y. end Natural_Number.")
13
1.4 성능분석 정의 • 공간 복잡도(space complexity) 프로그램을 실행시켜 완료하는데 필요한 공간의 양
정의 • 공간 복잡도(space complexity) 프로그램을 실행시켜 완료하는데 필요한 공간의 양 • 시간 복잡도(time complexity) 프로그램을 실행시켜 완료하는데 필요한 컴퓨터 시간의 양
 프로그램을 실행시켜 완료하는데 필요한 공간의 양. • 시간 복잡도(time complexity) 프로그램을 실행시켜 완료하는데 필요한 컴퓨터 시간의 양.")
14
1.4 성능분석(시간복잡도) [Big "oh"] [Omega] [Theta] 표기 : Ο
의미 : 상한값, f(n) ≤ cg(n) [Omega] 표기 : Ω 의미 : 하한값, f(n) ≥ cg(n) [Theta] 표기 : Θ 의미 : 평균값, C1g(n) ≤ f(n) ≤ C2g(n)
![1.4 성능분석(시간복잡도) [Big oh ] [Omega] [Theta] 표기 : Ο](http://slidesplayer.org/slide/14570898/90/images/14/1.4+%EC%84%B1%EB%8A%A5%EB%B6%84%EC%84%9D%28%EC%8B%9C%EA%B0%84%EB%B3%B5%EC%9E%A1%EB%8F%84%29+%5BBig+oh+%5D+%5BOmega%5D+%5BTheta%5D+%ED%91%9C%EA%B8%B0+%3A+%CE%9F.jpg "의미 : 상한값, f(n) ≤ cg(n) [Omega] 표기 : Ω. 의미 : 하한값, f(n) ≥ cg(n) [Theta] 표기 : Θ. 의미 : 평균값, C1g(n) ≤ f(n) ≤ C2g(n)")
15
1.4 성능분석(시간복잡도) Ο(1)<Ο(log n)<Ο(n)<Ο(n log n)<Ο(n2)<Ο(n3)<Ο(2n) 시간 이름 1 상수 log n 로그형 n 선형 nlgn 선.로 n^2 평방형 n^3 입방형 2^n 지수형 n! 계승형 *10^ *10^33

16
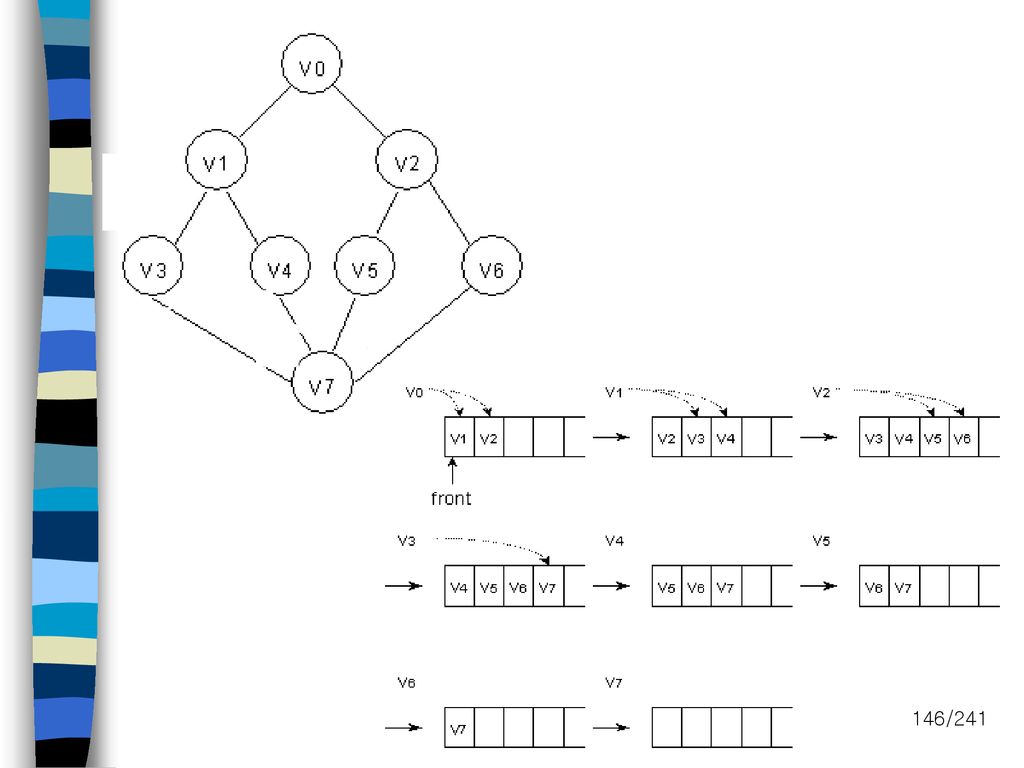
제2장 배열과구조

17
2.2 구조&유니언 배열 int i[3] 구조 struct person i[3]; int char name[10];
int age; float salary; } person; 2.2 구조&유니언 배열 int i[3] 구조 struct person i[3]; int char name[10]; int age; float salary; i[0] i[0] int char name[10]; int age; float salary; i[1] i[1] int char name[10]; int age; float salary; i[2] i[2]
![2.2 구조&유니언 배열 int i[3] 구조 struct person i[3]; int char name[10];](http://slidesplayer.org/slide/14570898/90/images/17/2.2+%EA%B5%AC%EC%A1%B0%26%EC%9C%A0%EB%8B%88%EC%96%B8+%EB%B0%B0%EC%97%B4+int+i%5B3%5D+%EA%B5%AC%EC%A1%B0+struct+person+i%5B3%5D%3B+int+char+name%5B10%5D%3B.jpg "int age; float salary; } person; 2.2 구조&유니언. 배열. int i[3] 구조. struct person i[3]; int. char name[10]; int age; float salary; i[0] i[0] int. char name[10]; int age; float salary; i[1] i[1] int. char name[10]; int age; float salary; i[2] i[2]")
18
2.2 구조&유니언 구조의 멤버 연산자=> “.” strcpy(man.name, "james"); man.age =10;
man.salary = 35000; struct { char name[10]; int age; float salary; } person; struct person man; char name[10]; int age; float salary;

19
2.2 구조&유니언 list item1, item2, item3; item1.data = 'a';
typedef struct list { char data; list *link; }; 2.2 구조&유니언 list item1, item2, item3; item1.data = 'a'; item2.data = 'b'; item3.data = 'c'; item1.link = item2.link = item3.link = NULL; item1.link = &item2; item2.link = &item3; Item3.link = &item3; data link a b c

20
2.3 순서리스트의 표현 순서리스트의 표현( 메모리 표현) i. 순차 사상 (sequential mapping)
- 물리적 인접성 (arrays) ii. 비순차 사상(non-sequential mapping) - 비연속적 기억장소 위치 - 리스트 : pointers(links)를 가지는 노드 집합
 ii. 비순차 사상(non-sequential mapping) - 비연속적 기억장소 위치. - 리스트 : pointers(links)를 가지는 노드 집합.")
21
제3장 스택과 큐

22
3.1 스택 추상 데이터 타입 스택(Stack) : 가장 마지막에 입력된 데이터가 가장 먼저 출력되는 후입선출 자료구조
LIFO(Last-in-First-out) 후입선출 : 한 끝에서 모든 데이터의 삽입과 삭제가 일어나는 구현원리 응용) Subroutine or recursive call
 후입선출. : 한 끝에서 모든 데이터의 삽입과 삭제가 일어나는 구현원리. 응용) Subroutine or recursive call.")
23
3.1 스택 추상 데이터 타입 데이터의 입력순서 A,B,C,D,E 데이터의 출력순서 E,D,C,B,A 초기상태 A입력
삭제 top E top D D C C top B B B top A A A A top

24
structure Stack objects: 0개 이상의 원소를 가진 유한 순서 리스트 functions: 모든 stack∈ Stack, item∈ element, max_stack_size∈ positive integer Stack CreateS(max_stack_size) ::= 최대 크기가 max_stack_size인 공백 스택을 생성 Boolean IsFull(stack, max_stack_size) ::= if (stack의 원소수 == max_stack_size) return TRUE else return FALSE Stack Add(stack, item) ::= if (IsFull(stack)) stack_full else stack의 톱에 item을 삽입하고 return Boolean IsEmpty(stack) ::= if (stack == CreateS(max_stack_size)) return TRUE Element Delete(stack) ::= if (IsEmpty(stack)) return else 스택 톱의 item을 제거해서 반환
 ::= 최대 크기가 max_stack_size인 공백 스택을 생성. Boolean IsFull(stack, max_stack_size) ::= if (stack의 원소수 == max_stack_size) return TRUE. else return FALSE. Stack Add(stack, item) ::= if (IsFull(stack)) stack_full. else stack의 톱에 item을 삽입하고 return. Boolean IsEmpty(stack) ::= if (stack == CreateS(max_stack_size)) return TRUE. Element Delete(stack) ::= if (IsEmpty(stack)) return. else 스택 톱의 item을 제거해서 반환.")
25
3.1 스택 추상 데이터 타입 top Stack CreateS(max_stack_size) ::=
#define MAX_STACK_SIZE 100 /*최대스택크기*/ typedef struct { int key; /* 다른 필드 */ } element; element stack[MAX_STACK_SIZE]; int top = -1; Boolean IsEmpty(top) ::= top < 0; Boolean IsFull(top) ::= top >= MAX_STACK_SIZE-1; MAX_STACK_SIZE top
 ::= top < 0; Boolean IsFull(top) ::= top >= MAX_STACK_SIZE-1; MAX_STACK_SIZE. top.")
26
3.1 스택 추상 데이터 타입 스택의 삽입 연산 void add(int *top, element item) {
/* 전역 stack에 item을 삽입 */ if (IsFull(*top)) { stack_full(); return; } stack[++*top] = item; top A
) { stack_full(); return; } stack[++*top] = item; top. A.")
27
3.1 스택 추상 데이터 타입 스택의 삭제 연산 element delete(int *top) {
/* stack의 최상위 원소를 반환 */ if (IsEmpty(*top)) return stack_empty(); /* 오류 key를 반환 */ return stack[(*top)--]; } top D C B A
) return stack_empty(); /* 오류 key를 반환 */ return stack[(*top)--]; } top. D. C. B. A.")
28
3.1 스택 추상 데이터 타입 스택의 예 택시의 동전통 10원 500원 100원 100원 500원 10원

29
3.2 큐 추상 데이터 타입 Queue : 가장 먼저 입력된 데이터가 가장 먼저 출력되는 선입선출 자료구조
FIFO(First-in-First-out) 선입선출리스트 : 한쪽 끝에서 데이터가 입력되고 그 반대쪽 끝에서 출력이 일어나는 구현원리 응용) Job scheduling
 선입선출리스트. : 한쪽 끝에서 데이터가 입력되고 그 반대쪽 끝에서 출력이 일어나는 구현원리. 응용) Job scheduling.")
30
3.2 큐 추상 데이터 타입 데이터의 입력순서 A,B,C,D,E 데이터의 출력순서 A,B,C,D,E 초기상태 A입력 B입력 …
삭제 E rear E rear D D C C B rear B B A rear A A A front rear front front front front

31
structure Queue objects: 0개 이상의 원소를 가진 유한 순서 리스트 functions: 모든 queue∈Queue, item∈element, max_queue_size∈positive integer Queue CreateQ(max_queue_size) ::= 최대 크기가 max_queue_size인 공백 큐를 생성 Boolean IsFullQ(queue, max_queue_size ) ::= if (queue의 원소수 == max_queue_size) return TRUE else return FALSE Queue AddQ(queue, item) ::= if (IsFull(queue)) queue_full else queue의 뒤에 item을 삽입하고 이 queue를 반환 Boolean IsEmptyQ(queue) ::= if (queue == CreateQ(max_queue_size)) return TRUE Element DeleteQ(queue) ::= if (IsEmpty(queue)) return else queue의 앞에 있는 item을 제거해서 반환
 ::= 최대 크기가 max_queue_size인 공백 큐를 생성. Boolean IsFullQ(queue, max_queue_size ) ::= if (queue의 원소수 == max_queue_size) return TRUE. else return FALSE. Queue AddQ(queue, item) ::= if (IsFull(queue)) queue_full. else queue의 뒤에 item을 삽입하고 이 queue를 반환. Boolean IsEmptyQ(queue) ::= if (queue == CreateQ(max_queue_size)) return TRUE. Element DeleteQ(queue) ::= if (IsEmpty(queue)) return. else queue의 앞에 있는 item을 제거해서 반환.")
32
3.2 큐 추상 데이터 타입 Queue CreateQ(max_queue_size) ::=
#define MAX_QUEUE_SIZE 100 /* 큐의 최대크기 */ typedef struct { int key; /* 다른 필드 */ } element; element queue[MAX_QUEUE_SIZE]; int rear = -1; int front = -1; Boolean IsEmptyQ(front, rear) ::= front == rear Boolean IsFullQ(front, rear) ::= rear == MAX_QUEUE_SIZE-1 rear front
 ::= front == rear. Boolean IsFullQ(front, rear) ::= rear == MAX_QUEUE_SIZE-1. rear. front.")
33
3.2 큐 추상 데이터 타입 큐의 삽입연산 void addq(int *rear, element item) {
/* queue에 item을 삽입 */ if (IsFullQ(front, *rear)) queue_full(); return; } queue[++*rear] = item; A rear front
) queue_full(); return; } queue[++*rear] = item; A. rear. front.")
34
3.2 큐 추상 데이터 타입 큐의 삭제연산 element deleteq(int *front, int rear) {
/* queue의 앞에서 원소를 삭제 */ if (IsEmptyQ(*front, rear)) return queue_empty(); /* 에러 key를 반환 */ return queue[++*front]; } E rear D C B A front
) return queue_empty(); /* 에러 key를 반환 */ return queue[++*front]; } E. rear. D. C. B. A. front.")
35
3.2 큐 추상 데이터 타입 터널 터널, 줄서기 3 2 1 1 2 3

36
3.2 큐 추상 데이터 타입 문제점 입력시 rear 값의 증가, 출력시 front 값의 증가
=> Queue가 full될 경우 전체를 왼쪽으로 이동하여 front 값을 조정해야 함 E rear D front C B A

37
3.2 큐 추상 데이터 타입 해결책 : Circular queue를 사용 [7] [0] [6] [1] [5] [2] [4]
[3] rear=0 front=0 rear front
![3.2 큐 추상 데이터 타입 해결책 : Circular queue를 사용 [7] [0] [6] [1] [5] [2] [4]](http://slidesplayer.org/slide/14570898/90/images/37/3.2+%ED%81%90+%EC%B6%94%EC%83%81+%EB%8D%B0%EC%9D%B4%ED%84%B0+%ED%83%80%EC%9E%85+%ED%95%B4%EA%B2%B0%EC%B1%85+%3A+Circular+queue%EB%A5%BC+%EC%82%AC%EC%9A%A9+%5B7%5D+%5B0%5D+%5B6%5D+%5B1%5D+%5B5%5D+%5B2%5D+%5B4%5D.jpg "[3] rear=0. front=0. rear. front.")
38
3.2 큐 추상 데이터 타입 해결책 : Circular queue를 사용 front : 첫 번째 원소의 하나 앞을 가리킴
rear : 입력된 원소의 마지막 위치 Modular 연산자를 이용 *rear = (*rear+1) % Max_Queue_Size *front = (*front+1) % Max_Queue_Size rear front
 % Max_Queue_Size. *front = (*front+1) % Max_Queue_Size. rear. front.")
39
3.2 큐 추상 데이터 타입 [0] [7] [6] [1] [2] [5] [3] [4] 환형큐의 추가연산 void addq(int front, int *rear, element item) { /* queue에 item을 입력 */ *rear = (*rear+1) % MAX_QUEUE_SIZE; if (front == *rear) { queue_full(rear); /* rear를 리세트시키고 에러를 프린트 */ return; } queue[*rear] = item; rear=0 front=0
![3.2 큐 추상 데이터 타입 [0] [7] [6] [1] [2] [5] [3] [4] 환형큐의 추가연산. void addq(int front, int *rear, element item)](http://slidesplayer.org/slide/14570898/90/images/39/3.2+%ED%81%90+%EC%B6%94%EC%83%81+%EB%8D%B0%EC%9D%B4%ED%84%B0+%ED%83%80%EC%9E%85+%5B0%5D+%5B7%5D+%5B6%5D+%5B1%5D+%5B2%5D+%5B5%5D+%5B3%5D+%5B4%5D+%ED%99%98%ED%98%95%ED%81%90%EC%9D%98+%EC%B6%94%EA%B0%80%EC%97%B0%EC%82%B0.+void+addq%28int+front%2C+int+%2Arear%2C+element+item%29.jpg "{ /* queue에 item을 입력 */ *rear = (*rear+1) % MAX_QUEUE_SIZE; if (front == *rear) { queue_full(rear); /* rear를 리세트시키고 에러를 프린트 */ return; } queue[*rear] = item; rear=0. front=0.")
40
3.2 큐 추상 데이터 타입 환형큐의 삭제연산 void deleteq(int *front, int rear) {
[0] [7] [6] [1] [2] [5] [3] [4] 환형큐의 삭제연산 void deleteq(int *front, int rear) { element item; /* queue의 front 원소를 삭제하여 그것을 item에 놓음 */ if (*front == rear) return queue_empty(); /* queue_empty는 에러 키를 반환 */ *front = (*front+1) % MAX_QUEUE_SIZE; return queue[*front]; } rear=0 front=0
 { element item; /* queue의 front 원소를 삭제하여 그것을 item에 놓음 */ if (*front == rear) return queue_empty(); /* queue_empty는 에러 키를 반환 */ *front = (*front+1) % MAX_QUEUE_SIZE; return queue[*front]; } rear=0. front=0.")
41
Stack Ordered list in which all insertions and deletions are made at one end (top pointer)
LIFO(Last-In-First-Out) 제일 마지막에 입력된 데이터가 가장 먼저 출력 (응용) Subroutine or recursive call Queue Ordered list in which all insertions take place at one end, the rear, while all deletions take place at the other end, the front. FIFO(First-In-First-Out) 제일 처음에 입력된 데이터가 가장 먼저 출력 (응용) Job scheduling
 제일 마지막에 입력된 데이터가 가장 먼저 출력 (응용) Subroutine or recursive call. Queue Ordered list in which all insertions take place at one end, the rear, while all deletions take place at the other end, the front. FIFO(First-In-First-Out) 제일 처음에 입력된 데이터가 가장 먼저 출력 (응용) Job scheduling.")
42
3.3 미로문제 입구 막힌경로 통행경로 출구

43
3.3 미로문제 경로표현 ? 경계표현 ? 입구 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 막힌경로 1 1 1 1 1 1 통행경로 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 출구

44
3.3 미로문제 입구 1 1 1 1 1 1 1

45
3.3 미로문제 여덟방향이동을 위한구조 typedef struct { short int vert;
[row-1] [col-1] [row-1] [col] [row-1] [col+1] 3.3 미로문제 1 [row] [col-1] [row] [col+1] 여덟방향이동을 위한구조 typedef struct { short int vert; short int horiz; } offsets; offsets move[8]; [row+1] [col-1] [row+1] [col] [row+1] [col+1]

46
3.3 미로문제 현재의 위치 다음 이동할 위치? maze[row][col]
NW=7 N=0 NE=1 3.3 미로문제 [row-1] [col-1] [row-1] [col] [row-1] [col+1] 1 [row] [col-1] [row] [col+1] W=5 E=2 현재의 위치 maze[row][col] 다음 이동할 위치? next_row = row + move[dir].vert; next_col = col + move[dir].horiz; [row+1] [col-1] [row+1] [col] [row+1] [col+1] SW=4 SE=3
![3.3 미로문제 현재의 위치 다음 이동할 위치 maze[row][col]](http://slidesplayer.org/slide/14570898/90/images/46/3.3+%EB%AF%B8%EB%A1%9C%EB%AC%B8%EC%A0%9C+%ED%98%84%EC%9E%AC%EC%9D%98+%EC%9C%84%EC%B9%98+%EB%8B%A4%EC%9D%8C+%EC%9D%B4%EB%8F%99%ED%95%A0+%EC%9C%84%EC%B9%98+maze%5Brow%5D%5Bcol%5D.jpg "NW=7. N=0. NE= 미로문제. [row-1] [col-1] [row-1] [col] [row-1] [col+1] 1. [row] [col-1] [row] [col+1] W=5. E=2. 현재의 위치. maze[row][col] 다음 이동할 위치 next_row = row + move[dir].vert; next_col = col + move[dir].horiz; [row+1] [col-1] [row+1] [col] [row+1] [col+1] SW=4. SE=3.")
47
3.3 미로문제 경로의 탐색 현위치 저장후 방향 선택 : N에서 시계방향
잘못된 경로의 선택시는 backtracking후 다른 방향 시도 시도한 경로의 재시도 방지 mark[m+2][n+2] : 초기치 0 mark[row][col] = 1 /* 한번 방문한 경우 */ 경로 유지를 위해서 스택 사용

48
3.3 미로문제 경로 유지위한 스택 #define MAX-STACK-SIZE 100 /*스택의 최대크기*/
[row-1] [col-1] [col] [col+1] [row] [row+1] N=0 NE=1 E=2 NW=7 SE=3 SW=4 W=5 3.3 미로문제 경로 유지위한 스택 #define MAX-STACK-SIZE 100 /*스택의 최대크기*/ typedef struct { short int row; short int col; short int dir; } element; element stack[MAX_STACK_SIZE];

49
initiallize a stack to the maze's entrance coordinates and direction to north;
while (stack is not empty) { /* 스택의 톱에 있는 위치로 이동*/ <row, col, dir> = delete from top of stack; while (there are more moves from current position) { <next_row, next_col> = coordinate of next move; dir = direction of move; if ((next_row == EXIT_ROW) && (exit_col == EXIT_COL)) success; if (maze[next_row][next_col] == 1) && mark[next_row][next_col] == 0) { /* 가능하지만 아직 이동해보지 않은 이동 방향 */ mark[next_row][next_col] = 1; /* 현재의 위치와 방향을 저장 */ add <row, col, dir> to the top of the stack; row = next_row; col = next_col; dir = north; } printf("No path found\n");
 { /* 스택의 톱에 있는 위치로 이동*/ <row, col, dir> = delete from top of stack; while (there are more moves from current position) { <next_row, next_col> = coordinate of next move; dir = direction of move; if ((next_row == EXIT_ROW) && (exit_col == EXIT_COL)) success; if (maze[next_row][next_col] == 1) && mark[next_row][next_col] == 0) { /* 가능하지만 아직 이동해보지 않은 이동 방향 */ mark[next_row][next_col] = 1; /* 현재의 위치와 방향을 저장 */ add <row, col, dir> to the top of the stack; row = next_row; col = next_col; dir = north; } printf( No path found\n );")
50
3.3 미로문제 이동테이블 Name dir move[dir].vert move[dir].horiz N 0 -1 0
[row-1] [col-1] [col] [col+1] [row] [row+1] N=0 NE=1 E=2 NW=7 SE=3 SW=4 W=5 3.3 미로문제 이동테이블 Name dir move[dir].vert move[dir].horiz N NE E SE S SW W NW
![3.3 미로문제 이동테이블 Name dir move[dir].vert move[dir].horiz N](http://slidesplayer.org/slide/14570898/90/images/50/3.3+%EB%AF%B8%EB%A1%9C%EB%AC%B8%EC%A0%9C+%EC%9D%B4%EB%8F%99%ED%85%8C%EC%9D%B4%EB%B8%94+Name+dir+move%5Bdir%5D.vert+move%5Bdir%5D.horiz+N.jpg "[row-1] [col-1] [col] [col+1] [row] [row+1] N=0. NE=1. E=2. NW=7. SE=3. SW=4. W= 미로문제. 이동테이블. Name dir move[dir].vert move[dir].horiz. N NE E SE S SW W NW")
51
void path(void) { /* 미로를 통과하는 경로가 있으면 그 경로를 출력한다. */ int i, row, col, next_row, next_col, dir, found=FALSE; element position; mark[1][1]=1; top=0; stack[0].row=1; stack[0].col=1; stack[0].dir=1; while (top>-1 && !found) { position = delete(&top); row = position.row; col = position.col; dir = position.dir; while (dir<8 && !found) { next_row = row + move[dir].vert; /* dir 방향으로 이동 */ next_col = col + move[dir].horiz; if (next_row==EXIT_ROW && next_col==EXIT_COL) found = TRUE; else if (maze[next_row][next_col] && !mark[next_row][next_col]) { mark[next_row][next_col]) = 1; position.row = row; position.col = col; position.dir = ++dir; add(&top, position); row = next.row; col = next.col; dir = 0; } else ++dir;
 { position = delete(&top); row = position.row; col = position.col; dir = position.dir; while (dir<8 && !found) { next_row = row + move[dir].vert; /* dir 방향으로 이동 */ next_col = col + move[dir].horiz; if (next_row==EXIT_ROW && next_col==EXIT_COL) found = TRUE; else if (maze[next_row][next_col] && !mark[next_row][next_col]) { mark[next_row][next_col]) = 1; position.row = row; position.col = col; position.dir = ++dir; add(&top, position); row = next.row; col = next.col; dir = 0; } else ++dir;")
52
최악의 경우 연산시간 = O(mp) m : 행의 수 p : 열의 수 if (found) {
printf("The path is:\n"); printf("row col\n"); for (i=0; i<=top; i++) printf("%2d%5d", stack[i].row, stack[i].col"); printf("%2d%5d\n", row, col); printf("%2d%5d\n", EXIT_ROW, EXIT_COL); } else printf("The maze does not have a path\n"); 최악의 경우 연산시간 = O(mp) m : 행의 수 p : 열의 수
; printf( row col\n ); for (i=0; i<=top; i++) printf( %2d%5d , stack[i].row, stack[i].col ); printf( %2d%5d\n , row, col); printf( %2d%5d\n , EXIT_ROW, EXIT_COL); } else printf( The maze does not have a path\n ); 최악의 경우 연산시간 = O(mp) m : 행의 수. p : 열의 수.")
53
제4장 리스트

54
리스트의 개요 배열 구조 : 삽입/삭제가 비효율적 리스트 구조 : 포인터 개념을 이용하여 삽입/삭제 연산을 효율적으로 수행
리스트의 구성 : data field & link data field : 실제 자료가 저장 link field : 다음 노드에 대한 포인터가 저장 data data data data link link link link

55
배열 Int a[7] 3,4 삽입 a[0] 1 a[0] 1 a[0] 1 a[1] 2 a[1] 2 a[1] 2 a[2] 5
6 a[3] a[3] 4 a[4] a[4] 5 a[4] 5 a[5] a[5] 6 a[5] 6 a[6] a[6] a[6]
![배열 Int a[7] 3,4 삽입 a[0] 1 a[0] 1 a[0] 1 a[1] 2 a[1] 2 a[1] 2 a[2] 5](http://slidesplayer.org/slide/14570898/90/images/55/%EB%B0%B0%EC%97%B4+Int+a%5B7%5D+3%2C4+%EC%82%BD%EC%9E%85+a%5B0%5D+1+a%5B0%5D+1+a%5B0%5D+1+a%5B1%5D+2+a%5B1%5D+2+a%5B1%5D+2+a%5B2%5D+5.jpg "6. a[3] a[3] 4. a[4] a[4] 5. a[4] 5. a[5] a[5] 6. a[5] 6. a[6] a[6] a[6]")
56
리스트 3추가 1 1 1 4 4 4 2 2 2 3 3

57
4.1 포인터 동적기억장소 할당 => malloc 할당된 메모리 해제 => free free(pi);
int i, *pi; float f, *pf; pi = (int *) malloc(sizeof(int)); pf = (float *) malloc(sizeof(float)); *pi = 1024; *pf = 3.14; 할당된 메모리 해제 => free free(pi); free(pf);
 malloc(sizeof(int)); pf = (float *) malloc(sizeof(float)); *pi = 1024; *pf = 3.14; 할당된 메모리 해제 => free. free(pi); free(pf);")
58
4.3 동적연결 스택과 큐 \n front rear 10 10 15 20 \n top

59
4.3 동적연결 스택과 큐 스택과 큐에 대한 함수 작성 isFull isEmpty Add Delete

60
4.3 동적연결 스택과 큐 스택 typedef struct { int key; /*기타필드*/ }element;
typedef struct stack *stack_pointer; typedef struct stack { element item; stack_pointer link; }; Stack_pointer top; top

61
4.3 동적연결 스택과 큐 스택의 초기 조건 top=NULL 경계 조건 스택이 공백이면, top=NULL
메모리가 가득차면, IS_FULL(temp)
")
62
4.3 동적연결 스택과 큐 void add(stack_pointer *top, element item) {
/*스택의 톱에 원소를 삽입*/ stack_pointer temp=(stack_pointer) malloc(sizeof(stack)); if (IS_FULL(temp)){ fprintf(stderr,”The memory is full\n”); exit(1); } temp->item = item; temp->link = *top; *top = temp; \n top
 malloc(sizeof(stack)); if (IS_FULL(temp)){ fprintf(stderr, The memory is full\n ); exit(1); } temp->item = item; temp->link = *top; *top = temp; \n. top.")
63
4.3 동적연결 스택과 큐 Element delete(stack_pointer *top) { /*스택으로부터 원소를 삭제*/
stack_pointer temp = *top; element item; if (IS_EMPTY(temp)){ fprintf(stderr,”The stack is empty\n”); exit(1); } item = temp->item; *top = temp->link; free(temp); return item; \n top
){ fprintf(stderr, The stack is empty\n ); exit(1); } item = temp->item; *top = temp->link; free(temp); return item; \n. top.")
64
4.3 동적연결 스택과 큐 큐 typedef struct queue *queue_pointer;
element item; queue_pointer link; } queue_pointer front,rear;

65
4.3 동적연결 스택과 큐 초기조건 front=NULL 경계조건 큐가 공백이면, front=NULL
메모리가 가득차기만하면, IS_FULL(temp);
;")
66
front rear 10 10 15 20 \n void addq(queue_pointer *front, queue_pointer *rear, element item) { /*큐의 rear에 원소를 삽입*/ queue_pointer temp = (queue_pointer) malloc(sizeof (queue)); if(IS_FULL(temp)){ fprintf(stderr,”The memory is full\n”); exit(1); } temp->item = item; temp->link = NULL; if (*front) *rear->link = temp; else *front = temp; *rear = temp;
 malloc(sizeof (queue)); if(IS_FULL(temp)){ fprintf(stderr, The memory is full\n ); exit(1); } temp->item = item; temp->link = NULL; if (*front) *rear->link = temp; else *front = temp; *rear = temp;")
67
front rear 10 10 15 20 \n element deleteq(queue_pointer *front) { /*큐에서 원소를 삭제*/ queue_pointer temp = *front; element item; if (IS_EMPTY(*front)){ fprintf(stderr,”The queue is empty\n”); exit(1); } item = temp->item; *front = temp->link; free(temp); return item;
){ fprintf(stderr, The queue is empty\n ); exit(1); } item = temp->item; *front = temp->link; free(temp); return item;")
68
Available space list의 관리
poly_pointer get_node(void) { poly_pointer node; if (avail) { node = avail; avail = avail->link; } else { node = (poly_pointer)malloc(sizeof(poly_node)); if(IS_FULL(node)){ fprintf(stderr,”The memory is full\n”): exit(1); return node; avail \n
 { poly_pointer node; if (avail) { node = avail; avail = avail->link; } else { node = (poly_pointer)malloc(sizeof(poly_node)); if(IS_FULL(node)){ fprintf(stderr, The memory is full\n ): exit(1); return node; avail. \n.")
69
4.8 이중연결리스트 단순연결리스트 링크의 방향으로만 이동 가능 head \n

70
4.8 이중연결리스트 노드 구조 typedef struct node *node_pointer;
head \n 노드 구조 typedef struct node *node_pointer; typedef struct node { node_pointer llink; element item; node_pointer rlink; }

71
4.8 이중연결리스트 이중연결리스트의 특징 공백 리스트
ptr = ptr->llink->rlink = ptr->rlink->llink 공백 리스트 ptr ptr \n - \n

72
void dinsert(node_pointer node, node_pointer newnode) {
/* newnode를 node의 오른쪽에 삽입 */ newnode->llink = node; newnode->rlink = node->rlink; node->rlink->llink = newnode; node->rlink = newnode; }

73
node 1 newnode 2 node node 4 3 3 newnode newnode

74
void ddelete(node_pointer node, node_pointer deleted) {
/* 이중 연결 리스트에서 삭제 */ if (node == deleted) printf("Deletion of head node not permitted.\n"); else { deleted->llink->rlink = deleted->rlink; deleted->rlink->llink = deleted->llink; free(deleted); }
 printf( Deletion of head node not permitted.\n ); else { deleted->llink->rlink = deleted->rlink; deleted->rlink->llink = deleted->llink; free(deleted); }")
75
제5장 트리

76
라틴어 그리이스어 북부 게르만어 서부 게르만어 고대인도유럽어 이태리어 헬레니즘어 게르만어 오스코 움브리아어 오스코어 움브리
서반어 불어 이태 리어 아이슬 란드어 노르웨 이어 스웨 덴어 저지 독일어 고지 독일어 이디 시어

77
5.1 서론 정의 : 트리는 1개 이상의 노드로 이루어진 유한집합 노드 중에는 루트라고 하는 노드가 하나 있고
나머지 노드들은 n>=0개의 분리집합 T1,…, Tn으로 분리될 수 있다. 여기서 T1,…, Tn은 각각 하나의 트리이며 루트의 서브트리라고 함

78
레벨 1 2 3 4 A B C D E F G H I J K L M

79
5.1.2 트리의 표현 리스트 표현 (A(B(E(K,L),F),C (G),D(H(M),I,J))) =>가변수의 필드 A
Data Link1 Link2 … Linkn

80
5.1.2 트리의 표현 A B C D (2) 왼쪽자식-오른쪽형제 Data E F G H I J 왼쪽자식 오른쪽 형제 K L M
 왼쪽자식-오른쪽형제 Data E F G H I J 왼쪽자식 오른쪽 형제 K L M")
81
A B C D A E F G H I J B C D K L M E F G H I J K L M

82
5.2 이진트리 정의 : 공집합이거나 루트와 왼쪽 서브트리, 오른쪽 서브트리라고 부르는 두 개의 분리된 이진 트리로 구성된 노드의 유한집합

83
5.2 이진트리 링크표현 노드구조 typedef struct node *tree_pointer;
int data; tree_pointer left_child, right_child; }; 노드구조 Left_child data Right_child

84
5.2 이진트리 이진트리 vs 일반트리 0개의 노드트리 자식의 순서 이진트리(O), 일반트리(X)
이진트리(구별), 일반트리(구별안함) A A B B
, 일반트리(구별안함) A. A. B. B.")
85
A B I C F J M D E G H K L N O 보조정리 5.1 [최대노드수]
이진 트리의 레벨 i에서의 최대 노드수는 2i-1(i>=1)이다. 깊이가 k인 이진트리가 가질 수 있는 최대 노드수는 2k -1(k>=1)이다. A B I C F J M D E G H K L N O
![A B I C F J M D E G H K L N O 보조정리 5.1 [최대노드수]](http://slidesplayer.org/slide/14570898/90/images/85/A+B+I+C+F+J+M+D+E+G+H+K+L+N+O+%EB%B3%B4%EC%A1%B0%EC%A0%95%EB%A6%AC+5.1+%5B%EC%B5%9C%EB%8C%80%EB%85%B8%EB%93%9C%EC%88%98%5D.jpg "이진 트리의 레벨 i에서의 최대 노드수는 2i-1(i>=1)이다. 깊이가 k인 이진트리가 가질 수 있는 최대 노드수는 2k -1(k>=1)이다. A. B. I. C. F. J. M. D. E. G. H. K. L. N. O.")
86
5.2 이진트리 정의[포화이진트리] 깊이가 k인 포화이진트리(full binary tree)란 깊이 k의 노드수가 2k-1개인 이진트리
![5.2 이진트리 정의[포화이진트리] 깊이가 k인 포화이진트리(full binary tree)란 깊이 k의 노드수가 2k-1개인 이진트리](http://slidesplayer.org/slide/14570898/90/images/86/5.2+%EC%9D%B4%EC%A7%84%ED%8A%B8%EB%A6%AC+%EC%A0%95%EC%9D%98%5B%ED%8F%AC%ED%99%94%EC%9D%B4%EC%A7%84%ED%8A%B8%EB%A6%AC%5D+%EA%B9%8A%EC%9D%B4%EA%B0%80+k%EC%9D%B8+%ED%8F%AC%ED%99%94%EC%9D%B4%EC%A7%84%ED%8A%B8%EB%A6%AC%28full+binary+tree%29%EB%9E%80+%EA%B9%8A%EC%9D%B4+k%EC%9D%98+%EB%85%B8%EB%93%9C%EC%88%98%EA%B0%80+2k-1%EA%B0%9C%EC%9D%B8+%EC%9D%B4%EC%A7%84%ED%8A%B8%EB%A6%AC.jpg "5.2 이진트리 정의[포화이진트리] 깊이가 k인 포화이진트리(full binary tree)란 깊이 k의 노드수가 2k-1개인 이진트리")
87
5.2 이진트리 정의[완전이진트리] 깊이가 k이고 노드수가 n인 이진 트리가 만일 이 트리의 각 노드들이 깊이 k인 포화 이진 트리에서 1부터 n까지의 번호를 붙인 노드들과 일대일로 일치하면, 이 트리는 완전이진트리(Complete binary tree)이다. 또한 그 역도 성립한다.
![5.2 이진트리 정의[완전이진트리]](http://slidesplayer.org/slide/14570898/90/images/87/5.2+%EC%9D%B4%EC%A7%84%ED%8A%B8%EB%A6%AC+%EC%A0%95%EC%9D%98%5B%EC%99%84%EC%A0%84%EC%9D%B4%EC%A7%84%ED%8A%B8%EB%A6%AC%5D.jpg "깊이가 k이고 노드수가 n인 이진 트리가 만일 이 트리의 각 노드들이 깊이 k인 포화 이진 트리에서 1부터 n까지의 번호를 붙인 노드들과 일대일로 일치하면, 이 트리는 완전이진트리(Complete binary tree)이다. 또한 그 역도 성립한다.")
88
5.2 이진트리 1 2 3 4 5 6 7 8 9 10 11 12 13

89
5.2.3 이진트리의 표현 배열표현 노드에 1부터 n까지의 번호가 할당되므로 일차원 배열에 각 노드를 저장 1 A 1 A 2
B 2 B 3 - 3 C 4 C 4 D 5 - 5 E 6 - 6 F 7 - 7 G 8 D 8 H 9 - 9 I . . 16 E

90
5.2.3 이진트리의 표현 보조정리 5.3 : n개의노드를 가진 완전이진트리 가 순차적으로 표현되어 있다면, 인덱스i를 갖는 어떤 노드로부터도 다음의 정보를 구할 수 있다. i != 1이면 parent(i)는 floor(i/2)의 위치에 있게 된다. 만일 i=1이면 i는 루트이므로 부모가 없다. 2i <= n 이면 left_child(i)는 2i의 위치에 있게 된다. 만일 2i>n이면 i는 왼쪽 자식을 가질 수 없다. 2i+1 <= n이면 right_child(i)는 2i+1의 위치에 있게된다. 만일 2i+1>n이면 i는 오른쪽 자식을 가질 수 없다.
는 floor(i/2)의 위치에 있게 된다. 만일 i=1이면 i는 루트이므로 부모가 없다. 2i <= n 이면 left_child(i)는 2i의 위치에 있게 된다. 만일 2i>n이면 i는 왼쪽 자식을 가질 수 없다. 2i+1 <= n이면 right_child(i)는 2i+1의 위치에 있게된다. 만일 2i+1>n이면 i는 오른쪽 자식을 가질 수 없다.")
91
5.2.3 이진트리의 표현 (2) 링크표현 typedef struct node* tree_pointer;
int data; tree_pointer left_child, right_child; }; data Left_child data Right_child Left_child Right_child

92
5.2.3 이진트리의 표현 root root A NULL A B NULL B C C NULL D NULL E NULL NULL
F NULL NULL G NULL D NULL NULL H NULL NULL I NULL NULL E NULL

93
5.3 이진 트리 순회 순회 : 트리에 있는 모든 노드를 한번씩 방문하는 것 L : 왼쪽이동 V : 노드방문 R : 오른쪽이동
1 순회 : 트리에 있는 모든 노드를 한번씩 방문하는 것 L : 왼쪽이동 V : 노드방문 R : 오른쪽이동 2 4 5 8 9 10 11

94
5.3 이진 트리 순회 순회방법(데이터의 위치) 중위(inorder) : LVR 전위(preorder) : VLR
후위(postorder) : LRV 2 4 5 8 9 10 11
 : LRV")
95
5.3 이진 트리 순회 + * E 산술식의 이진트리 표현 A/B*C*D+E * D / C A B

96
5.3 이진 트리 순회 8 6 9 Output A/B*C*D+E 중위(inorder) : LVR 4 7 2 5 1 3
 : LVR")
97
5.3 이진 트리 순회 1 2 9 Output +**/ABCDE 전위(preorder) : VLR 3 8 4 7 5 6
 : VLR")
98
5.3 이진 트리 순회 9 7 8 Output AB/C*D*E+ 후위(postorder) : LRV 5 6 3 4 1 2
 : LRV")
99
5.3 이진 트리 순회 레벨순서순회 루트 먼저 방문 루트의 왼쪽 자식 루트의 오른쪽 자식 => 큐를 사용하는 순회 ptr
+ 레벨순서순회 루트 먼저 방문 루트의 왼쪽 자식 루트의 오른쪽 자식 => 큐를 사용하는 순회 * E * D / C A B

100
5.5 스레드 이진트리 이진트리 x1 실제 포인터보다 더 많은 널 링크 존재 2n개의 링크중 n+1개의 널링크 존재 x2
^ 5.5 스레드 이진트리 x1 ! 이진트리 실제 포인터보다 더 많은 널 링크 존재 2n개의 링크중 n+1개의 널링크 존재 이런 널 링크를 활용 <= 스레드(thread) (널링크=> 다른링크를 가리키는 포인터) x2
 (널링크=> 다른링크를 가리키는 포인터) x2.")
101
5.5 스레드 이진트리 스레드(thread) 널 링크 필드에 삽입된 포인터
ptr->left_child = NULL => ptr->left_child <=중위순회시 P의 predecessor에 대한 포인터 (2) ptr->right_child = NULL => ptr->right_child <=중위순회시 P의 successor에 대한 포인터
 ptr->right_child = NULL => ptr->right_child <=중위순회시 P의 successor에 대한 포인터.")
102
5.5 스레드 이진트리 A 중위순회 :HDIBEAFCG B C D E F G H I

103
5.5 스레드 이진트리 스레드 이진 트리의 기억장소 표현
left_thread = F left_child : normal pointer T left_child : thread right_thread = F right_child : normal pointer T right_child : thread left_thread left_child DATA right_child right_thread

104
5.5 스레드 이진트리 typedef struct threaded_tree *thread_pointer;
short int left_thread; threaded_pointer left_child; char data; threaded_pointer right_child; short int right_thread; }

105
ptr f . -- . f f . A . f f . B . f f . C . f f . D . f t . E . t t . F . t t . G . t t . H . t t . I . t

106
5.6 히프 정의 최대트리(max tree)는 각 노드의 키값이(자식이 있다면) 그 자식의 키값보다 작지 않은 트리.
최대히프(max heap)는 최대 트리이면서 완전 이진 트리. 최소트리(min tree)는 각 노드의 키값이(자식이 있다면) 그 자식의 키값보다 크지 않은 트리. 최소히프(min heap)는 최소 트리이면서 완전 이진 트리.
는 최대 트리이면서 완전 이진 트리. 최소트리(min tree)는 각 노드의 키값이(자식이 있다면) 그 자식의 키값보다 크지 않은 트리. 최소히프(min heap)는 최소 트리이면서 완전 이진 트리.")
107
5.6 히프 최대 히프에서 데이터의 삽입 20 15 2 21 14 10

108
5.6 히프 20 20 15 2 15 21 14 10 14 10 2

109
5.6 히프 20 21 15 21 15 20 14 10 2 14 10 2

110
20 5.6 히프 15 2 void insert_max_heap(element item, int *n) { /*n개의 원소를 갖는 최대 히프에 item을 삽입*/ int i; if (HEAP_FULL(*n)){ fprintf(stderr,”The heap is full.\n”); exit(1); } i = ++(*n); while((i!=1)&&(item.key>heap[i/2].key)){ heap[i] = heap[i/2]; i/=2; heap[i]=item; 14 5 n 10 20 15 2 14 10 n
){ fprintf(stderr, The heap is full.\n ); exit(1); } i = ++(*n); while((i!=1)&&(item.key>heap[i/2].key)){ heap[i] = heap[i/2]; i/=2; heap[i]=item; n n.")
111
5.6 히프(삭제) 20 15 2 14 10
")
112
5.6 히프(삭제) 20 10 15 2 15 2 14 10 14
")
113
5.6 히프(삭제) 10 15 15 10 15 2 2 14 2 14 14 10
")
114
5.7 이진탐색트리 데이터의 검색(10) 20 15 2 14 10
")
115
5.7 이진탐색트리 히프 임의의 원소 삭제 => O(n) 임의의 원소 탐색 => O(n)
비효율적 => 이진탐색트리

116
5.7 이진탐색트리 이진탐색트리 : 공백이 가능한 이진 트리이다. 만약 공백이 아니라면 다음 성질을 만족한다.
모든 원소는 키를 가지며, 어떤 두 원소도 동일한 키를 갖지 않는다. 즉 키는 유일한 값을 가진다. 공백이 아닌 왼쪽 서브트리에 있는 키들은 그 서브트리의 루트의 키보다 작아야 한다. 공백이 아닌 오른쪽 서브트리에 있는 키들은 그 서브트리의 루트의 키보다 커야 한다. 왼쪽과 오른쪽 서브트리도 이진 탐색 트리이다.

117
5.7 이진탐색트리 20 30 10 22 5 40 9 11 25 2

118
5.7 이진탐색트리 분석 높이가 h인 이진 탐색 트리에 대한 탐색에 걸리는 시간 => O(h) => O(log n)
 => O(log n)")
119
5.7 이진탐색트리(노드삽입) 1. 트리 탐색 2. 탐색이 실패하면 탐색이 종료된 그 지점에 원소를 삽입
동일한 키값 존재여부 확인 2. 탐색이 실패하면 탐색이 종료된 그 지점에 원소를 삽입

120
5.7 이진탐색트리 30 5 40 2

121
5.7 이진탐색트리 80 삽입 30 30 node 5 40 5 40 2 2 80

122
void insert_node(tree_pointer *node, int num)
{ /*트리내의 노드가 num을 가리키고 있으면 아무일도 하지 않음; 그렇지 않은 경우는 data=num인 새 노드를 첨가*/ tree_pointer ptr, temp=modified_search(*node, num); if (temp || !(*node)){ /* num이 트리내에 없음 */ ptr=(tree_pointer)malloc(sizeof(node)); if(IS_FULL(ptr)){ fprintf(stderr,”The memory is full\n”); exit(1); } ptr->data=num; ptr->left_child=ptr->right_child=NULL; if(*node) if(num<temp->data) temp->left_child = ptr; else temp->right_child = ptr; else *node=ptr;
; if (temp || !(*node)){ /* num이 트리내에 없음 */ ptr=(tree_pointer)malloc(sizeof(node)); if(IS_FULL(ptr)){ fprintf(stderr, The memory is full\n ); exit(1); } ptr->data=num; ptr->left_child=ptr->right_child=NULL; if(*node) if(num<temp->data) temp->left_child = ptr; else temp->right_child = ptr; else *node=ptr;")
123
5.7 이진탐색트리(노드삭제) 35 삭제 30 5 40 2 35 80
 35 삭제")
124
5.7 이진탐색트리 40 20 60 10 30 50 70 45 55 52

125
5.7 이진탐색트리 이진 탐색 트리의 높이 최악의 경우에도 높이가 O(logn)인탐색트리=>균형탐색트리
최악 => O(n) ex, 1,2,3,…n 순서로 입력 평균 => O(logn) 최악의 경우에도 높이가 O(logn)인탐색트리=>균형탐색트리 AVL트리 2-3트리 레드-블랙트리
 ex, 1,2,3,…n 순서로 입력. 평균 => O(logn) 최악의 경우에도 높이가 O(logn)인탐색트리=>균형탐색트리. AVL트리. 2-3트리. 레드-블랙트리.")
126
제6장 그래프

127
6.1 그래프 추상데이타타입 오일러 행로(Eulerian walk) : 각 다리를 한번씩만 건너서 시작점으로 돌아오는 경로
 : 각 다리를 한번씩만 건너서 시작점으로 돌아오는 경로")
128
6.1 그래프 추상데이타타입

129
6.1 그래프 추상데이타타입 G1 G2 G3 G1, G2 : 무방향 그래프 G3 : 방향 그래프 G2 : 트리

130
6.1 그래프 추상데이타타입 G1 G2 G3 V(G1)={0,1,2,3} V(G2)={0,1,2,3,4,5,6}
E(G1)={(0,1),(0,2),(0,3),(1,2),(1,3),(2,3)} E(G2)={(0,1),(0,2),(1,3),(1,4),(2,5),(2,6)} E(G3)={<0,1>,<1,0>,<1,2>}
={(0,1),(0,2),(0,3),(1,2),(1,3),(2,3)} E(G2)={(0,1),(0,2),(1,3),(1,4),(2,5),(2,6)} E(G3)={<0,1>,<1,0>,<1,2>}")
131
6.1 그래프 추상데이타타입 그래프의 제한 V(G), E(G)=집합 Self loof 는 허용 안됨
간선의 중복은 안됨 : 다중그래프(multigraph)
")
132
6.1 그래프 추상데이타타입 G의 부분그래프 G’ V(G’)V(G) E(G’)E(G)
V(G) E(G’)E(G)")
133
6.1 그래프 추상데이타타입 그래프 표현 인접행렬(adjacency matrix) n*n 배열 adj_mat
adj_mat[i][j]=1:(vi,vj)or(vj,vi) E(G) adj_mat[I][j]=0:otherwise 무방향:대칭, 방향:비대칭 공간 n2 무방향 그래프:n(n-1)/2로 감소(상위삼각행렬)
or(vj,vi) E(G) adj_mat[I][j]=0:otherwise. 무방향:대칭, 방향:비대칭. 공간 n2. 무방향 그래프:n(n-1)/2로 감소(상위삼각행렬)")
134
6.1 그래프 추상데이타타입 1 2 3 1 1 1 1 1 1 1 2 1 1 1 3 1 1 1 1 2 1 1 1 1 2

135
6.1 그래프 추상데이타타입 (2) 인접리스트(adjacent list) n개의 연결리스트(헤드노드) vi:
무방향그래프(e:간선의수):2e개의 리스트노드 방향그래프 : e개의 리스트 노드 vj link
:2e개의 리스트노드. 방향그래프 : e개의 리스트 노드. vj. link.")
136
6.1 그래프 추상데이타타입 headnode vertex link 1 2 3 1 2 3 2 3 1 3 1 2 1 2 1 2

137
6.1 그래프 추상데이타타입 인접리스트를 위한 C 선언문 #define MAX_VERTICES 50 //정점의 최대수
typedef struct node* node_pointer; typedef struct node{ int vertex; struct node *link; }; node_pointer graph[MAX_VERTICES]; int n=0; // 현재 사용중인 정점들

138
6.1 그래프 추상데이타타입 (3) 인접 다중리스트(adjacency multilists)
다중리스트 : 노드가 여러 리스트에 의해 공유 노드구조 : 간선, (v1, v2) marked v1 v2 path1 path2
 marked. v1. v2. path1. path2.")
139
6.1 그래프 추상데이타타입 headnode N1 edge(0,1) 1 2 3 1 N2 N4 N2 edge(0,2) 2 N3
1 2 3 1 N2 N4 N2 edge(0,2) 2 N3 N4 N3 edge(0,3) 3 NULL N5 N4 edge(1,2) 1 2 N5 N6 N5 edge(1,3) 1 3 NULL N6 N6 edge(2,3) 2 3 NULL NULL The lists are : vertex 0:N1->N2->N3 vertex 1:N1->N4->N5 vertex 2:N2->N4->N6 vertex 3:N3->N5->N6
 2. N3. N4. N3. edge(0,3) 3. NULL. N5. N4. edge(1,2) N5. N6. N5. edge(1,3) NULL. N6. N6. edge(2,3) NULL. NULL. The lists are : vertex 0:N1->N2->N3. vertex 1:N1->N4->N5. vertex 2:N2->N4->N6. vertex 3:N3->N5->N6.")
140
6.1 그래프 추상데이타타입 가중치 간선 네트워크 : 가중치 간선을 가진 그래프 그래프의 간선에 가중치(weights)를 부여
가중치는 한 정점에서 다른 정점까지의 거리나 한 정점에서 인접한 정점으로 가는 비용등을 표현 노드구조에 weights 필드 추가 네트워크 : 가중치 간선을 가진 그래프

141
6.2 그래프 연산 6.3 최소비용신장트리 6.4 최단경로와 이행적폐쇄 6.5 작업 네트워크
6장 그래프 6.2 그래프 연산 6.3 최소비용신장트리 6.4 최단경로와 이행적폐쇄 6.5 작업 네트워크

142
6.2 그래프 연산 깊이우선탐색(depth first search,DFS) G=(V,E) : 무방향그래프, n노드
자료구조 visited[MAX_VERTICES] : 배열 초기치 = FALSE visited[i]=TRUE : 정점 i 방문 인접리스트

143
1 2 3 4 5 6 7 1 2 3 4 5 6 1 7 1 7 2 7 2 7 3 4 5 6
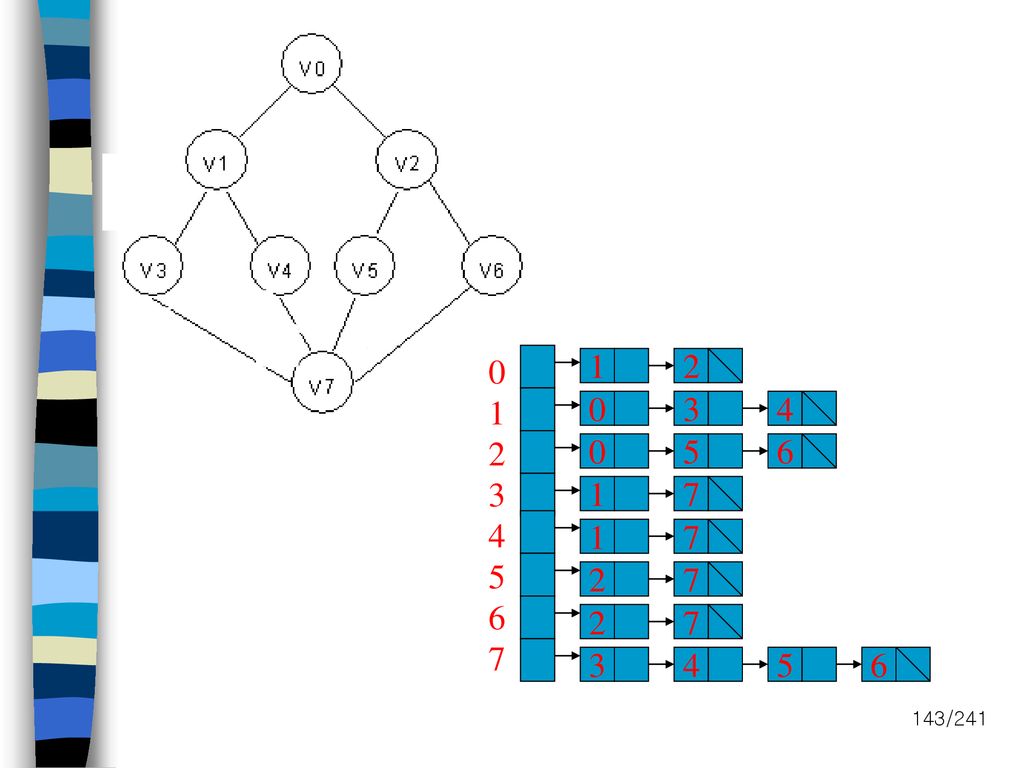
144
6.2 그래프 연산

145
6.2 그래프 연산 너비우선탐색(breadth first search,BFS) 정점 v에서 시작
=> 큐 이용

147
6.2 그래프 연산 연결요소(connected component) G의 모든 연결요소를 발견 DFS나 BFS의 사용
void connect(void) { /* 그래프의 연결요소결정 */ int i; for(i=0;i<n;i++) if(!visited[i]){ dfs(i); printf(“\n); }
 { /* 그래프의 연결요소결정 */ int i; for(i=0;i<n;i++) if(!visited[i]){ dfs(i); printf( \n); }")
148
6.2 그래프 연산 G의 신장트리 T 트리 : E(T)E(G) V(T)=V(G)
깊이우선 신장트리 : DFS를 사용한 트리 너비우선 신장트리 : BFS를 사용한 트리

149
6.3 최소비용신장트리 최소비용신장트리(minimum cost sapnning tree) : 간선의 비용합이 최소인 신장트리
Greedy algorithm 사용 Kruskal 알고리즘 Prim 알고리즘 Sollin 알고리즘

150
28 1 1 1 1 10 10 10 10 14 16 14 5 6 2 5 6 2 5 6 2 5 6 2 24 25 18 12 12 12 4 4 4 4 22 3 3 3 3 1 1 1 1 10 10 10 10 14 16 14 16 14 16 14 16 5 6 2 5 6 2 5 6 2 5 6 2 18 25 12 12 12 12 4 4 4 4 3 3 3 3 22 22
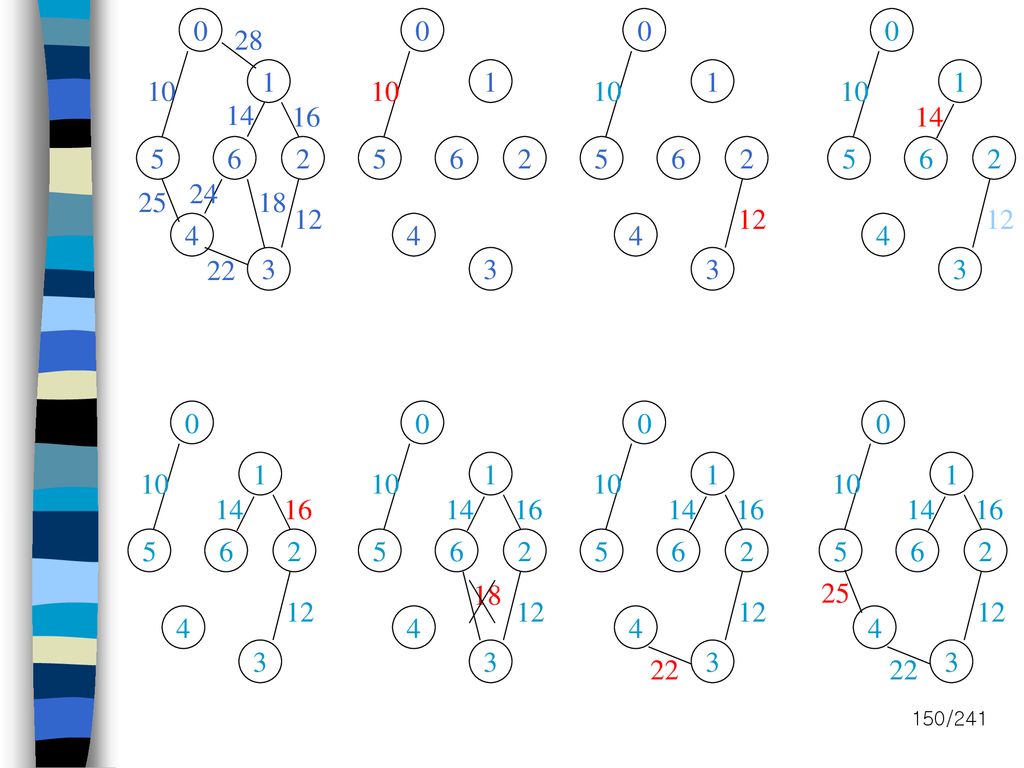
151
28 1 1 1 1 10 10 10 10 14 16 5 6 2 5 6 2 5 6 2 5 6 2 24 25 18 25 25 12 4 4 4 4 22 3 3 3 22 3 1 1 1 10 10 10 16 14 16 5 6 2 5 6 2 5 6 2 25 25 25 12 12 12 4 4 4 22 3 22 3 22 3
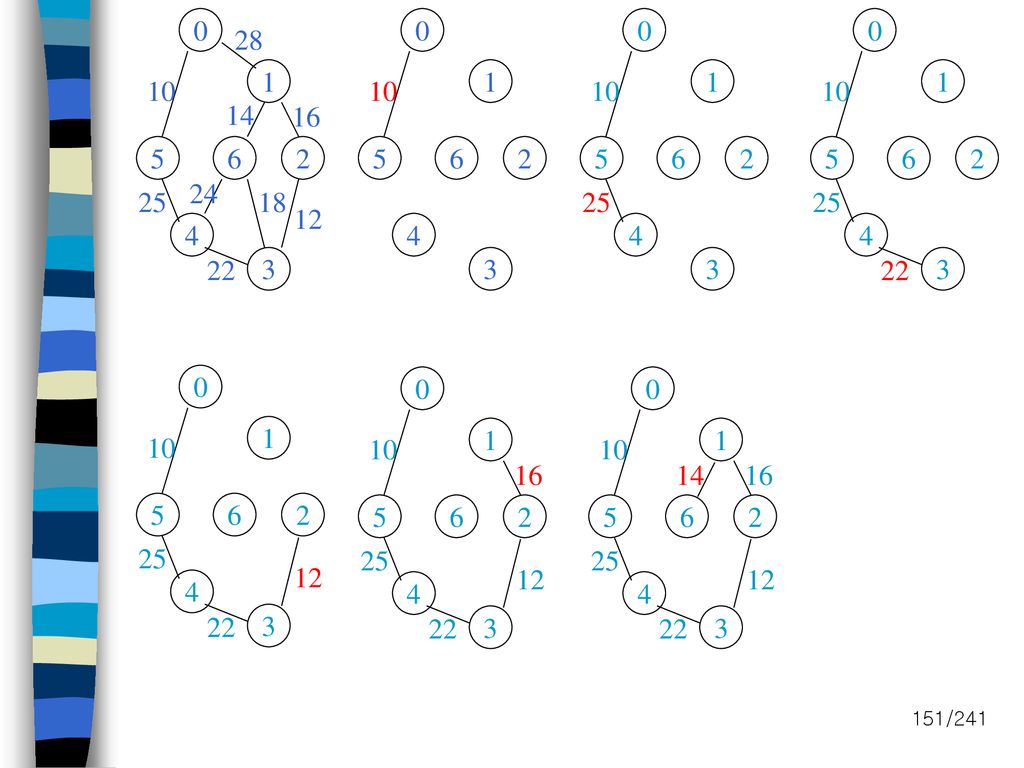
152
6.3 최소비용신장트리 각 정점에서 간선 선택 {0,5}트리 =>(5,4)
28 1 1 1 1 10 10 10 14 16 14 14 16 5 6 2 5 6 2 5 6 2 5 6 2 24 25 18 25 12 12 12 4 4 4 4 22 3 3 22 3 22 3 각 정점에서 간선 선택 (0,5),(1,6),(2,3),(3,2),(4,3) (5,0),(6,1) {0,5}트리 =>(5,4) 나머지트리=>(1,2)
,(1,6),(2,3),(3,2),(4,3) (5,0),(6,1) {0,5}트리 =>(5,4) 나머지트리=>(1,2)")
153
6.4 최단경로와 이행적 폐쇄

154
6.4 최단경로와 이행적 폐쇄 A로부터 B로 가는 길이 있는가? A로부터 B로 가는길이 있다면 어느길이 짧은가?
최단경로(shortest path) 단일 출발점 모든 도착지(single source all destinations) v0(source)에서 다른 모든 정점(도착지)까지의 최단경로 경로 길이의 증가순(방향그래프에서)
 단일 출발점 모든 도착지(single source all destinations) v0(source)에서 다른 모든 정점(도착지)까지의 최단경로. 경로 길이의 증가순(방향그래프에서)")
155
6.4 최단경로와 이행적 폐쇄

156
shortest + shortest => shortest
6.4 최단경로와 이행적 폐쇄 그래프 : 비용인접행렬(cost adjacency matrix)로 표현 최단경로 i-k=(vi,…,vj,vk) shortest + shortest => shortest
로 표현. 최단경로 i-k=(vi,…,vj,vk) shortest + shortest => shortest.")
157
6.4 최단경로와 이행적 폐쇄 cost 비용인접행렬 1 2 3 4 5 50 10 45 1 15 10 2 20 15 3 20
1 2 3 4 5 50 10 45 1 15 10 2 20 15 3 20 35 4 30 5 3
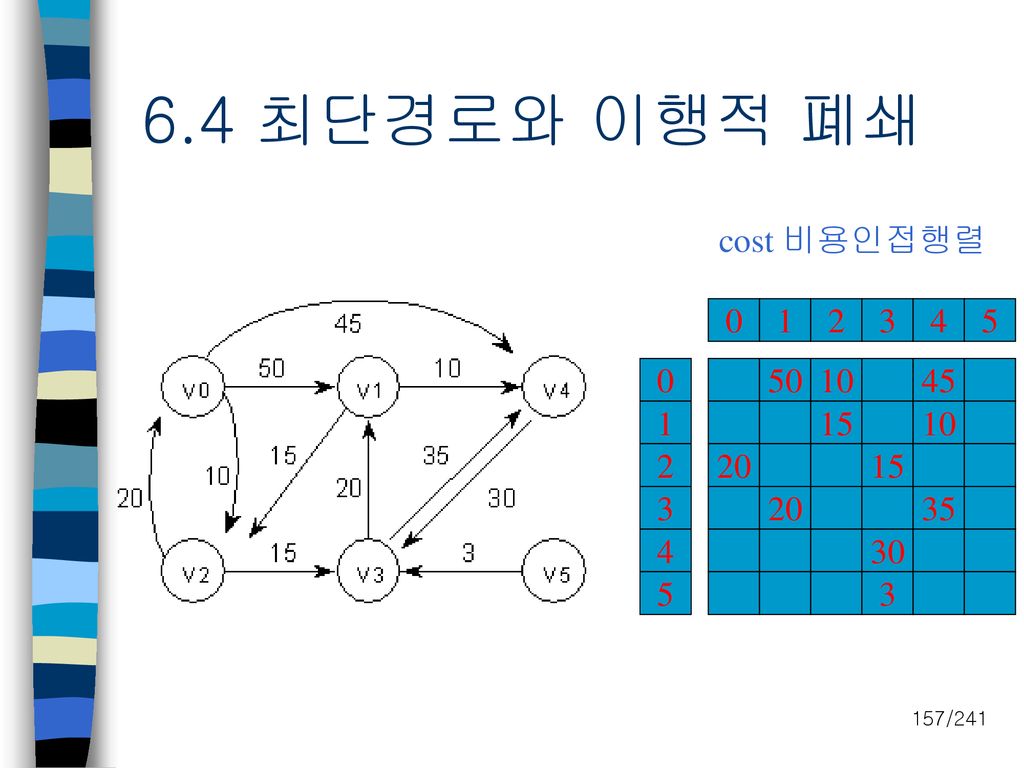
158
6.4 최단경로와 이행적 폐쇄 1. S={v0} : 초기는 공백 vertex 1 2 3 4 5 distance 50 10
1 2 3 4 5 distance 50 10 999 45 999 S 1

159
6.4 최단경로와 이행적 폐쇄 min vertex 1 2 3 4 5 distance 50 10 999 45 999 S 1

160
6.4 최단경로와 이행적 폐쇄 2. S=SU{v2} = {v0,v2} min vertex 1 2 3 4 5 distance
1 2 3 4 5 distance 50 10 999 45 999 S 1 1

161
vertex 1 2 3 4 5 distance 50 10 999 45 999 S 1 1 2. S=SU{v2} = {v0,v2}
1 2 3 4 5 distance 50 10 999 45 999 S 1 1 2. S=SU{v2} = {v0,v2} distance(1)<-min{distance(1),distance(2)+(v2,v1,999)} 50 distance(3)<-min{distance(3),distance(2)+(v2,v3,15)} 25 distance(4)<-min{distance(4),distance(2)+(v2,v4,999)} 45 distance(5)<-min{distance(5),distance(2)+(v2,v5,999)} 999 vertex 1 2 3 4 5 distance 50 10 25 45 999 S 1 1
<-min{distance(1),distance(2)+(v2,v1,999)} 50. distance(3)<-min{distance(3),distance(2)+(v2,v3,15)} 25. distance(4)<-min{distance(4),distance(2)+(v2,v4,999)} 45. distance(5)<-min{distance(5),distance(2)+(v2,v5,999)} 999. vertex distance S")
162
vertex 1 2 3 4 5 distance 50 10 25 45 999 S 1 1 vertex 1 2 3 4 5
1 2 3 4 5 distance 50 10 25 45 999 S 1 1 3. S=SU{v3}={v0,v2,v3} distance(1)<-min{distance(1),distance(3)+(v3,v1,20)} 45 distance(4)<-min{distance(4),distance(3)+(v3,v4,35)} 45 distance(5)<-min{distance(5),distance(3)+(v3,v5,999)} 999 vertex 1 2 3 4 5 distance 45 10 25 45 999 S 1 1 1
<-min{distance(1),distance(3)+(v3,v1,20)} 45. distance(4)<-min{distance(4),distance(3)+(v3,v4,35)} 45. distance(5)<-min{distance(5),distance(3)+(v3,v5,999)} 999. vertex distance S")
163
vertex 1 2 3 4 5 distance 45 10 25 45 999 S 1 1 1 vertex 1 2 3 4 5
1 2 3 4 5 distance 45 10 25 45 999 S 1 1 1 4. S=SU{v1}={v0,v1,v2,v3} Distance(4)<-min{distance(4),distance(1)+(v1,v4,10)} 45 Distance(5)<-min{distance(5),distance(3)+(v3,v5,999)} 999 vertex 1 2 3 4 5 distance 45 10 25 45 999 S 1 1 1 1
<-min{distance(4),distance(1)+(v1,v4,10)} 45. Distance(5)<-min{distance(5),distance(3)+(v3,v5,999)} 999. vertex distance S")
164
vertex 1 2 3 4 5 distance 45 10 25 45 999 S 1 1 1 1 vertex 1 2 3 4 5
1 2 3 4 5 distance 45 10 25 45 999 S 1 1 1 1 5. S=SU{v4}={v0,v1,v2,v3,v4} Distance(5)<-min{distance(5),distance(4)+(v3,v5,999)}999 vertex 1 2 3 4 5 distance 45 10 25 45 999 S 1 1 1 1 1
<-min{distance(5),distance(4)+(v3,v5,999)}999. vertex distance S")
165
vertex 1 2 3 4 5 distance 45 10 25 45 999 S 1 1 1 1 1 vertex 1 2 3 4 5
1 2 3 4 5 distance 45 10 25 45 999 S 1 1 1 1 1 6. S=SU{v5}={v0,v1,v2,v3,v4,v5} vertex 1 2 3 4 5 distance 45 10 25 45 999 S 1 1 1 1 1 1

166
6.4 최단경로와 이행적 폐쇄 모든쌍의 최단경로 음수의 가중치를 가지는 사이클은 없음 비용인접행렬 cost[i][i]=0
cost[i][j]=weight if <i,j>E(G) cost[I][j]= otherwise A-1[i][j]=cost[i][j] Ak[i][j]=k보다 더 큰 중간정점을 지나지 않는 i->j최단경로 An-1[i][j]=i->j 최단경로 A-1, A0, A1,… An-1
![6.4 최단경로와 이행적 폐쇄 모든쌍의 최단경로 음수의 가중치를 가지는 사이클은 없음 비용인접행렬 cost[i][i]=0](http://slidesplayer.org/slide/14570898/90/images/166/6.4+%EC%B5%9C%EB%8B%A8%EA%B2%BD%EB%A1%9C%EC%99%80+%EC%9D%B4%ED%96%89%EC%A0%81+%ED%8F%90%EC%87%84+%EB%AA%A8%EB%93%A0%EC%8C%8D%EC%9D%98+%EC%B5%9C%EB%8B%A8%EA%B2%BD%EB%A1%9C+%EC%9D%8C%EC%88%98%EC%9D%98+%EA%B0%80%EC%A4%91%EC%B9%98%EB%A5%BC+%EA%B0%80%EC%A7%80%EB%8A%94+%EC%82%AC%EC%9D%B4%ED%81%B4%EC%9D%80+%EC%97%86%EC%9D%8C+%EB%B9%84%EC%9A%A9%EC%9D%B8%EC%A0%91%ED%96%89%EB%A0%AC+cost%5Bi%5D%5Bi%5D%3D0.jpg "cost[i][j]=weight if <i,j>E(G) cost[I][j]= otherwise. A-1[i][j]=cost[i][j] Ak[i][j]=k보다 더 큰 중간정점을 지나지 않는 i->j최단경로. An-1[i][j]=i->j 최단경로. A-1, A0, A1,… An-1.")
167
6.4 최단경로와 이행적 폐쇄 for k>=1, Ak[i][j]=min(Ak-1[i][j], Ak-1[i][k]+ Ak-1[k][j]) A-1[i][j]= cost[i][j]
![6.4 최단경로와 이행적 폐쇄 for k>=1, Ak[i][j]=min(Ak-1[i][j], Ak-1[i][k]+ Ak-1[k][j]) A-1[i][j]= cost[i][j]](http://slidesplayer.org/slide/14570898/90/images/167/6.4+%EC%B5%9C%EB%8B%A8%EA%B2%BD%EB%A1%9C%EC%99%80+%EC%9D%B4%ED%96%89%EC%A0%81+%ED%8F%90%EC%87%84+for+k%3E%3D1%2C+Ak%5Bi%5D%5Bj%5D%3Dmin%28Ak-1%5Bi%5D%5Bj%5D%2C+Ak-1%5Bi%5D%5Bk%5D%2B+Ak-1%5Bk%5D%5Bj%5D%29+A-1%5Bi%5D%5Bj%5D%3D+cost%5Bi%5D%5Bj%5D.jpg "6.4 최단경로와 이행적 폐쇄 for k>=1, Ak[i][j]=min(Ak-1[i][j], Ak-1[i][k]+ Ak-1[k][j]) A-1[i][j]= cost[i][j]")
168
6.4 최단경로와 이행적 폐쇄 A-1 1 2 4 11 1 6 2 2 3

169
6.4 최단경로와 이행적 폐쇄 A-1 1 2 4 11 1 6 2 2 3 k=0 A0(0,1)=min{A-1(0,1), A-1(0,0)+A-1(0,1)} A0(0,2)=min{A-1(0,2), A-1(0,0)+A-1(0,2)} A0(1,0)=min{A-1(1,0), A-1(1,0)+A-1(0,0)} A0(1,2)=min{A-1(1,2), A-1(1,0)+A-1(0,2)} A0(2,0)=min{A-1(2,0), A-1(2,0)+A-1(0,0)} A0(2,1)=min{A-1(2,1), A-1(2,0)+A-1(0,1)} A0 1 2 4 11 1 6 2 2 3 7
=min{A-1(0,2), A-1(0,0)+A-1(0,2)} A0(1,0)=min{A-1(1,0), A-1(1,0)+A-1(0,0)} A0(1,2)=min{A-1(1,2), A-1(1,0)+A-1(0,2)} A0(2,0)=min{A-1(2,0), A-1(2,0)+A-1(0,0)} A0(2,1)=min{A-1(2,1), A-1(2,0)+A-1(0,1)} A")
170
6.4 최단경로와 이행적 폐쇄 A0 1 2 4 11 1 6 2 2 3 7 A1 1 2 A2 1 2 4 6 4 6 1 6 2 1 5 2 2 3 7 2 3 7

171
6.4 최단경로와 이행적 폐쇄 [정의] 이행적폐쇄행렬 A+ 방향그래프 G에서 [정의] 반사 이행적폐쇄행렬 A*
i->j로의 길이 > 0인 경로존재 : A+[i][j]=1 그렇지 않으면 :A+[i][j]=0 [정의] 반사 이행적폐쇄행렬 A* i->j로의 길이 >= 0인 경로존재 : A*[i][j]=1 그렇지 않으면 :A*[i][j]=0
![6.4 최단경로와 이행적 폐쇄 [정의] 이행적폐쇄행렬 A+ 방향그래프 G에서 [정의] 반사 이행적폐쇄행렬 A*](http://slidesplayer.org/slide/14570898/90/images/171/6.4+%EC%B5%9C%EB%8B%A8%EA%B2%BD%EB%A1%9C%EC%99%80+%EC%9D%B4%ED%96%89%EC%A0%81+%ED%8F%90%EC%87%84+%5B%EC%A0%95%EC%9D%98%5D+%EC%9D%B4%ED%96%89%EC%A0%81%ED%8F%90%EC%87%84%ED%96%89%EB%A0%AC+A%2B+%EB%B0%A9%ED%96%A5%EA%B7%B8%EB%9E%98%ED%94%84+G%EC%97%90%EC%84%9C+%5B%EC%A0%95%EC%9D%98%5D+%EB%B0%98%EC%82%AC+%EC%9D%B4%ED%96%89%EC%A0%81%ED%8F%90%EC%87%84%ED%96%89%EB%A0%AC+A%2A.jpg "i->j로의 길이 > 0인 경로존재 : A+[i][j]=1. 그렇지 않으면 :A+[i][j]=0. [정의] 반사 이행적폐쇄행렬 A* i->j로의 길이 >= 0인 경로존재 : A*[i][j]=1. 그렇지 않으면 :A*[i][j]=0.")
172
6.5 작업 네트워크 AOV 네트워크 : AOV(activity on vertex)네트워크 방향그래프 정점은 작업을 표현
간선은 작업간의 우선관계 표현 정점 i가 j의 선행자(predecessor) 정점 j가 i의 후속자(successor) iff i에서 j까지의 방향경로존재 : <i,j>E(G) => i는 j의 직속 선행자(immediate predecessor) j는 i의 직속 후행자(immediate successor)
 정점 j가 i의 후속자(successor) iff i에서 j까지의 방향경로존재 : <i,j>E(G) => i는 j의 직속 선행자(immediate predecessor) j는 i의 직속 후행자(immediate successor)")
173
6.5 작업 네트워크

174
6.5 작업 네트워크 AOE(activity on edge) 네트워크 정점 : 사건(event)-작업의 시작 또는 종료
간선 : 작업(필요 시간 명시)
")
175
6.5 작업 네트워크 프로젝트의 성능평가에 유효 프로젝트 완료를 위한 최소 시간 프로젝트의 완료까지의 최소 시간
어느작업이 병목현상을 유발하는가? PERT:performance evaluation and review technique CPM:critical path method RAMPS:resource allocation and multi-project scheduling 프로젝트 완료를 위한 최소 시간 시작정점에서 최종정점까지의 가장 긴 경로의 길이

176
6.5 작업 네트워크 임계경로(critical path) 가장긴경로 길이 : 경로상의 시간의 합 18
<v0,v1,v4,v7,v8> <v0,v1,v4,v6,v8> 길이 : 경로상의 시간의 합 18

177
사건 vi가 발생할 수 있는 가장 이른(earliest) 시간
v0에서 vi로의 최장경로 vi에서 시작하는 작업(간선) aj의 가장 이른 시작 시간(earliest start time) early(i)=v0에서 vi로의 최장경로 early(4)=? early(7)=?
 aj의 가장 이른 시작 시간(earliest start time) early(i)=v0에서 vi로의 최장경로. early(4)= early(7)=")
178
vi에서 시작하는 작업 aj의 가장 늦은(latest)시간
전체 완료시간에 영향없이 연기 가능한 최대시간 late(j)=완료시간-vi에서 최종노드까지의 최장경로길이(vi는 aj에 인접) late(5)=8 ->{<v0,v1,v4,v7,v8>=18,<v3,v5,v7,v8>=10 late(10)=?
=완료시간-vi에서 최종노드까지의 최장경로길이(vi는 aj에 인접) late(5)=8. ->{<v0,v1,v4,v7,v8>=18,<v3,v5,v7,v8>=10. late(10)=")
179
6.5 작업 네트워크 임계작업(critical activity) : early(i)=late(i)
임계경로 분석의 목적=>임계작업의 식별 * 임계 경로상의 작업이 중요 =>비임계작업의속도증가!=전체완료시간감소 작업의 임계도(criticality):late(i)-early(i)
:late(i)-early(i)")
180
제7장 정렬

181
내부정렬 정렬의 필요성 정렬방법 대부분의 기관에서 자료 정렬에 20%-50% 계산시간을 소비
내부정렬(internal sorting) : 메인 메모리 내에서 정렬 외부정렬(external sorting) : 자료의 양이 방대하여 보조기억 장치를 활용하여정렬
 : 메인 메모리 내에서 정렬. 외부정렬(external sorting) : 자료의 양이 방대하여 보조기억 장치를 활용하여정렬.")
182
내부정렬 내부정렬방법 Bubble sorting Insertion sorting Quick sorting
Shell sorting Heap sorting Bucket sorting Radix sorting

183
내부정렬(Bubble sorting) list 15 4 8 3 50 9 20 4 8 3 15 9 20 50 4 3 8 9 15
last swap occured 3 4 8 9 15 20 50 3 4 8 9 15 20 50

184
내부정렬(Bubble sorting) Bubble 정렬의 시간 분석 loop number of comparison 1 n-1
n 전체 시간 복잡도 : O(n2)
")
185
내부정렬(insertion sort) Input sequence 15 4 8 3 50 9 20 15 4 15 4 8 15 3
 Input sequence")
186
내부정렬 Insertion sort의 시간 분석 거의 정렬된 리스트에서는 효율적인 처리 Best case : O(n)
Worst case : O(n2) 거의 정렬된 리스트에서는 효율적인 처리
 거의 정렬된 리스트에서는 효율적인 처리.")
187
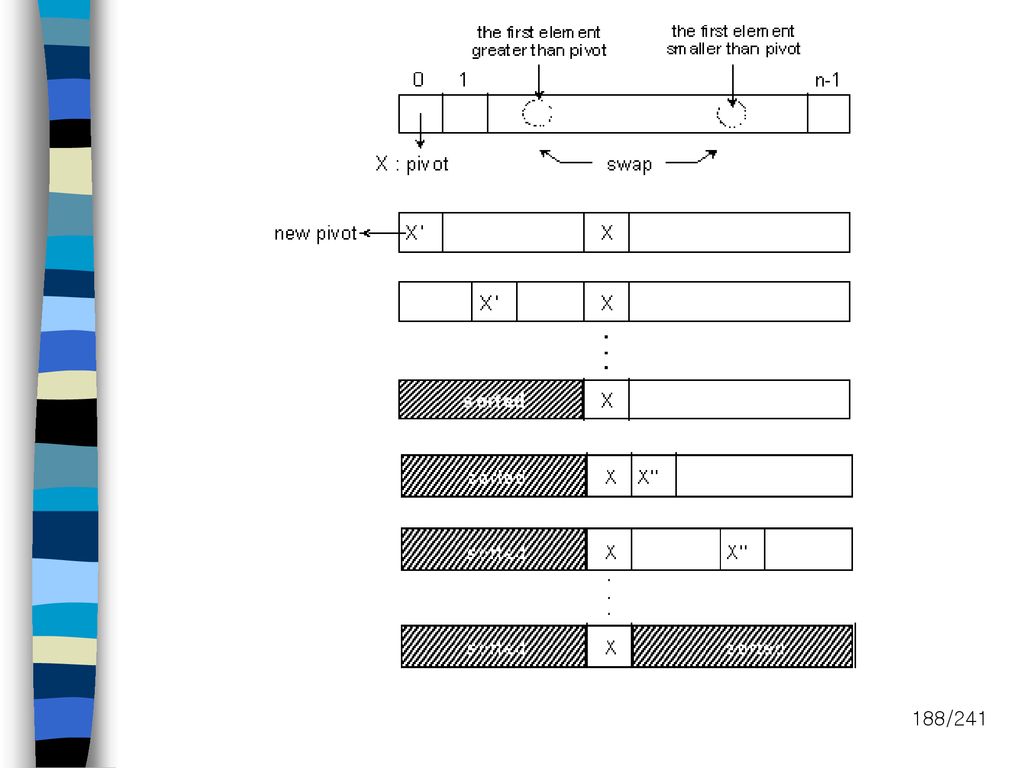
내부정렬(quick sort) Divide and conquer 방법에 의해 항상 두개의 phase로 구성
피봇 키를 사용하여 리스트를 분할 Recursion을 사용하므로 스택이 필요 Average time : O(nlogn)
")
189
Input file : 10 records (26, 5, 37, 1, 61, 11, 59, 15, 48, 19) R0 R1 R2 R3 R4 R5 R6 R7 R8 R9 left right [ ] [ ] [ ] [ ] [ ] [ ] [ ] [ ] [ ] [ ] [ ] [ ]

190
내부정렬(quick sort) 시간 복잡도 분석 가정 : 두개의 분할이 같은 크기라 가정
Average case : O(nlogn) T(n):n개의 레코드를 정렬하기 위한 평균시간 T(n) <= c.n+2.T(n/2) <= c.n+2(c.n/2+2.T(n/4)) <= 2c.n+4.T(n/4)) … <= c.n.logn+n.T(1) = O(nlogn) Worst case : O(n2)
 T(n):n개의 레코드를 정렬하기 위한 평균시간. T(n) <= c.n+2.T(n/2) <= c.n+2(c.n/2+2.T(n/4)) <= 2c.n+4.T(n/4)) … <= c.n.logn+n.T(1) = O(nlogn) Worst case : O(n2)")
191
최적 정렬 시간 N개의 레코드를 어느정도 빨리 정렬할 수 있겠는가? 최적 가능시간 : O(nlogn)
")
192
최적 정렬 시간 최적 정렬 => 결정트리(decision tree)사용
사용")
193
최적 정렬 시간 적어도 log(n!)+1의 높이를 가지는 n개의 엘리먼트를 소트하는 어떤 결정 트리에서 n!개의 리프를 가짐
높이가 k일 경우 최대 2k-1 개의 리프를 가짐 k=log(n!)+1
+1.")
194
최적 정렬 시간 정리 비교를 이용한 어떠한 소팅 알고리즘도 최악의 경우 O(nlogn)의 계산이 요구됨
의 계산이 요구됨")
195
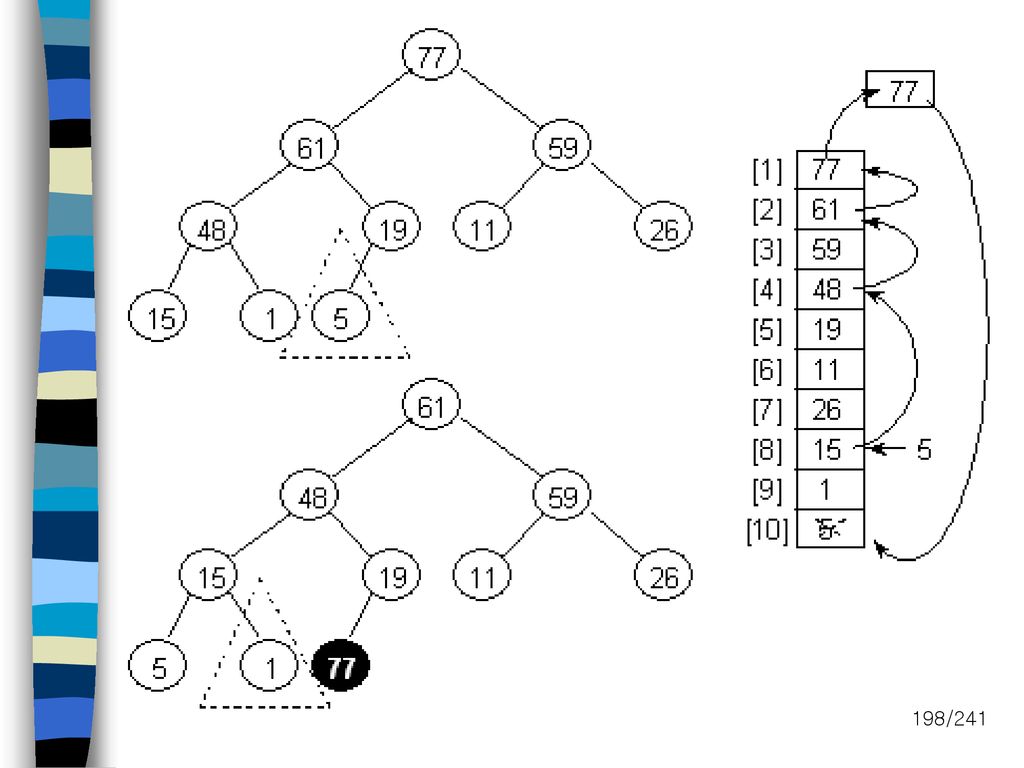
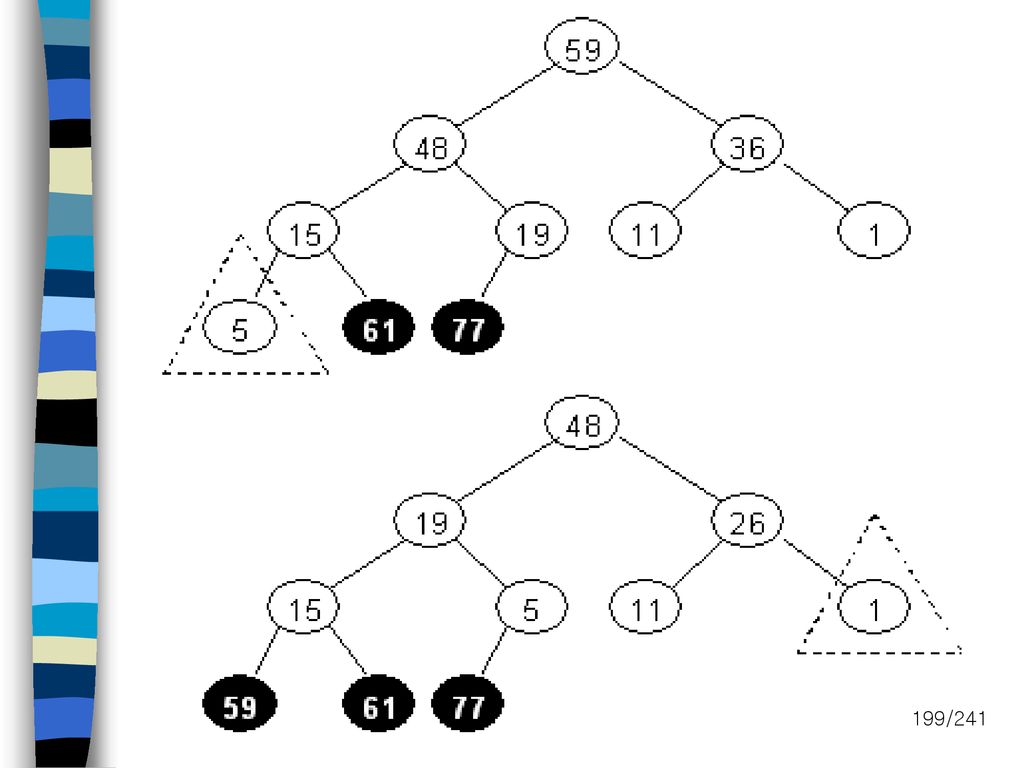
내부정렬(heap sort) Heap sort Max heap 구조를 이용한 정렬 배열을 사용하여 max heap 을 구성
시간 복잡도 Average case : O(nlogn) Worst case : O(nlogn) Heap을 구성하기 위해서 이진 트리를 재조정 O(d), d: 트리의 depth
 Worst case : O(nlogn) Heap을 구성하기 위해서 이진 트리를 재조정. O(d), d: 트리의 depth.")
196
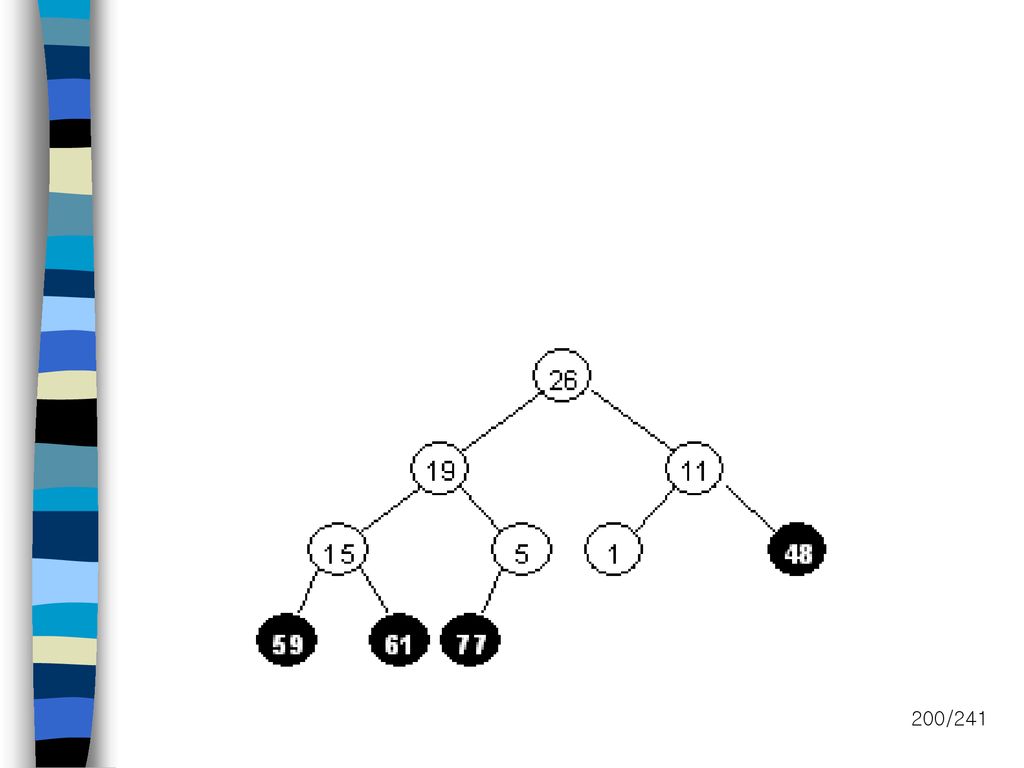
내부정렬(heap sort) Input list (26,5,77,1,61,11,59,15,48,19)
 Input list (26,5,77,1,61,11,59,15,48,19)")
197
정렬규칙 루트 값과 마지막 값을 교환 후에 max heap을 재구성 위쪽부터 큰쪽 자식을 따라 내려 옴

201
내부정렬(heap sort) Worst case time complexity logn+log(n-1)+…+log(2)
 Worst case time complexity logn+log(n-1)+…+log(2)")
202
내부정렬(기수정렬) 정렬 리스트 하나의 키 값 여러 개의 키 값 K0,K1,..,Kr-1 예제) 카드뭉치 정렬
K1[숫자] : 2<3<4<…<10<J<Q<K<A 정렬된 카드 =>2,…,A,2,…,A

203
내부정렬(기수정렬) 정렬방법 LSD 방법이 MSD 방법보다 오버헤드가 적음
MSD(Most Significant Digit)정렬 무늬에 의한 정렬 LSD(Least Significant Digit)정렬 숫자에 의한 정렬 빈을 이용 LSD 방법이 MSD 방법보다 오버헤드가 적음
정렬. 무늬에 의한 정렬. LSD(Least Significant Digit)정렬. 숫자에 의한 정렬. 빈을 이용. LSD 방법이 MSD 방법보다 오버헤드가 적음.")
204
179->208->306->93->859->984->55->9->271->33
271->93->33->984->55->306->208->179->859->9 f[0] NULL r[0] f[1] 271 NULL r[1] f[2] NULL r[2] f[3] 93 33 NULL r[3] f[4] 984 NULL r[4] f[5] 55 NULL r[5] f[6] 306 NULL r[6] f[7] NULL r[7] f[8] 208 NULL r[8] f[9] 179 859 9 NULL r[9]

205
271->93->33->984->55->306->208->179->859->9
306->208->9->33->55->859->271->179->984->93 f[0] 306 208 9 NULL r[0] f[1] NULL r[1] f[2] NULL r[2] f[3] 33 NULL r[3] f[4] NULL r[4] f[5] 55 859 NULL r[5] f[6] NULL r[6] f[7] 271 179 NULL r[7] f[8] 984 NULL r[8] f[9] 93 NULL r[9]

206
306->208->9->33->55->859->271->179->984->93
9->33->55->93->179->208->271->306->859->984 f[0] 9 33 55 93 NULL r[0] f[1] 179 NULL r[1] f[2] 208 271 NULL r[2] f[3] 306 NULL r[3] f[4] NULL r[4] f[5] NULL r[5] f[6] NULL r[6] f[7] NULL r[7] f[8] 859 NULL r[8] f[9] 984 NULL r[9]

207
내부정렬(안정성) [안정성]입력 리스트에서 i<j이고 Ki=Kj이면 정렬된 리스트에서도 Ki가 Kj 앞에 위치
이런 순열을 생성하는 정렬 기법은 안정(stable)되었다고 함 Stable 정렬 알고리즘? Selection, Bubble, Insertion, Quick, Shell, Heap, Bucket, Radix
![내부정렬(안정성) [안정성]입력 리스트에서 i<j이고 Ki=Kj이면 정렬된 리스트에서도 Ki가 Kj 앞에 위치](http://slidesplayer.org/slide/14570898/90/images/207/%EB%82%B4%EB%B6%80%EC%A0%95%EB%A0%AC%28%EC%95%88%EC%A0%95%EC%84%B1%29+%5B%EC%95%88%EC%A0%95%EC%84%B1%5D%EC%9E%85%EB%A0%A5+%EB%A6%AC%EC%8A%A4%ED%8A%B8%EC%97%90%EC%84%9C+i%3Cj%EC%9D%B4%EA%B3%A0+Ki%3DKj%EC%9D%B4%EB%A9%B4+%EC%A0%95%EB%A0%AC%EB%90%9C+%EB%A6%AC%EC%8A%A4%ED%8A%B8%EC%97%90%EC%84%9C%EB%8F%84+Ki%EA%B0%80+Kj+%EC%95%9E%EC%97%90+%EC%9C%84%EC%B9%98.jpg "이런 순열을 생성하는 정렬 기법은 안정(stable)되었다고 함. Stable 정렬 알고리즘 Selection, Bubble, Insertion, Quick, Shell, Heap, Bucket, Radix.")
208
제8장 검색

209
검색(Search) 컴퓨터에 저장된 자료 중에서 원하는 항목을 찾는 작업 탐색키를 가진 항목을 찾는 작업
검색성공 : 원하는 항목을 찾은 경우 검색실패 : 원하는 항목을 찾지 못한 경우 탐색키를 가진 항목을 찾는 작업 탐색키(search key) : 자료를 구별하여 인식할 수 있는 키 삽입/삭제 작업에서의 검색 데이터를 삽입하거나 삭제할 위치를 찾기 위해서 검색 연산 수행
 : 자료를 구별하여 인식할 수 있는 키. 삽입/삭제 작업에서의 검색. 데이터를 삽입하거나 삭제할 위치를 찾기 위해서 검색 연산 수행.")
210
검색방법 검색 방식에 따른 분류 비교검색(Comparison search method)
검색대상의 키를 비교하여 검색하는 방법 순차검색, 이진검색, 트리검색 계산검색(non-comparison method) 계수적인 성질을 이용한 계산으로 검색하는 방법 해싱
 계수적인 성질을 이용한 계산으로 검색하는 방법. 해싱.")
211
순차검색 순차검색(sequential search, 선형검색(linear search))
일렬로 된 자료를 처음부터 마지막까지 순서대로 검색 가장 간단하고 직접적인 검색 방법 배열이나 연결 리스트로 구현된 순차 자료 구조에서 원하는 항목을 찾는 방법 검색 대상 자료가 많은 경우에 비효율적이지만 알고리즘이 단순하여 구현이 용이

212
순차검색 순차검색(정렬안된 데이터) 검색방법
첫번째 원소부터 시작하여 마지막 원소까지 순서대로 키 값이 일치하는 원소가 있는지 비교 예)
")
213
순차검색 순차검색(정렬된 데이터) 검색방법 순서대로 검색하면서 키 값 비교
원소의 키 값이 찾는 키 값보다 크면 찾는 원소가 없는 것임 예)
")
214
순차검색 색인 순차 검색(index sequential search)
정렬되어 있는 자료에 대한 인덱스 테이블(index table)을 추가로 사용하여 탐색 효율을 높인 검색법 인덱스 테이블 배열에 정렬되어 있는 자료 중에서 일정한 간격으로 떨어져 있는 원소들을 저장한 테이블 배열크기 n, 인덱스 테이블 크기 m, n/m간격 저장 검색방법 indexTable[i].key <= key < indexTable[i+1].key
을 추가로 사용하여 탐색 효율을 높인 검색법. 인덱스 테이블. 배열에 정렬되어 있는 자료 중에서 일정한 간격으로 떨어져 있는 원소들을 저장한 테이블. 배열크기 n, 인덱스 테이블 크기 m, n/m간격 저장. 검색방법. indexTable[i].key <= key < indexTable[i+1].key.")
215
순차검색 색인 순차 검색 검색대상 자료 : {1, 2, 8, 9, 11, 19, 29} 크기가 3인 인덱스 테이블 작성
n = 7, m = 3, n/m = 2

216
순차검색 색인 순차 검색의 성능 인덱스 테이블의 크기에 따라 결정 색인 순차 검색의 시간 복잡도
큰 인덱스 테이블 : 검색범위가 작아짐 작은 인덱스 테이블 : 검색범위가 커짐 색인 순차 검색의 시간 복잡도 O(m+n/m) 배열의 크기 : n, 인덱스 테이블의 크기 : m
 배열의 크기 : n, 인덱스 테이블의 크기 : m.")
217
검색방법 검색 방식에 따른 분류 비교검색(Comparison search method)
검색대상의 키를 비교하여 검색하는 방법 순차검색, 이진검색, 트리검색 계산검색(non-comparison method) 계수적인 성질을 이용한 계산으로 검색하는 방법 해싱
 계수적인 성질을 이용한 계산으로 검색하는 방법. 해싱.")
218
이진검색 이진검색(binary search, 이분검색, 보간검색(interpolation search))
자료의 가운데에 있는 항목을 키 값과 비교하여 다음 검색 위치를 결정 찾는키 값 > 원소의 키 값 : 오른쪽 부분 검색 찾는키 값 < 원소의 키 값 : 왼쪽 부분 검색 키를 찾을 때까지 이진 검색을 순환 반복 정렬되어 있는 자료에 대해서 수행하는 검색 방법

219
이진검색 검색의 예

220
검색방법 검색 방식에 따른 분류 비교검색(Comparison search method)
검색대상의 키를 비교하여 검색하는 방법 순차검색, 이진검색, 트리검색 계산검색(non-comparison method) 계수적인 성질을 이용한 계산으로 검색하는 방법 해싱
 계수적인 성질을 이용한 계산으로 검색하는 방법. 해싱.")
221
이진트리검색 이진트리검색(binary tree search) 이진 탐색 트리를 사용한 검색 방법
원소의 삽입이나 삭제 연산에 대해서 항상 이진 탐색 트리를 재구성 하는 작업이 필요

222
검색방법 검색 방식에 따른 분류 비교검색(Comparison search method)
검색대상의 키를 비교하여 검색하는 방법 순차검색, 이진검색, 트리검색 계산검색(non-comparison method) 계수적인 성질을 이용한 계산으로 검색하는 방법 해싱
 계수적인 성질을 이용한 계산으로 검색하는 방법. 해싱.")
223
해싱 해싱(hashing) 산술적인 연산을 이용하여 키가 있는 위치를 계산하여 바로 찾아가는 계산 검색 방식 검색방법
키 값에 대해서 해싱 함수를 계산하여 주소를 구함 구한 주소에 해당하는 해시 테이블로 이동 해당 주소에 찾는 항목이 있으면 검색 성공, 없으면 실패 해싱함수(hashing function) 키 값을 원소의 위치로 변환하는 함수 해시테이블(hash table) 해싱함수에 의해서 계산된 주소의 위치에 항목을 저장한 표
 키 값을 원소의 위치로 변환하는 함수. 해시테이블(hash table) 해싱함수에 의해서 계산된 주소의 위치에 항목을 저장한 표.")
224
해싱 해싱 검색 수행 방법

225
해싱 해싱의 예 : 도서관에서 도서검색

226
해싱 해싱의 예 : 강의실 좌석 배정

227
해싱 용어 충돌 서로 다른 키 값에 대해서 해싱 함수에 의해 주어진 버킷 주소가 같은 경우
충돌이 발생한 경우에 비어있는 슬롯에 동거자 관계로 키 값 저장 동거자 서로 다른 키 값을 가지지만 해싱함수에 의해 같은 버킷에 저장된 키 값들 오버플로우 버킷에 비어있는 슬롯이 없는 포화 버킷 상태에서 충돌이 발생하여 해당 버킷에 키 값을 저장할 수 없는 상태

228
해싱 해싱 함수 함수의 조건 계산이 쉬워야 함 충돌이 적어야 함 해시 테이블에 고르게 분포할 수 있도록 주소를 만들어야 함
비교 검색 방법을 사용하여 키 값의 비교연산을 수행하는 시간보다 해싱 함수를 사용하여 계산하는 시간이 빨라야 함 충돌이 적어야 함 비어있는 버킷이 많은데도 어떤 버킷은 오버플로우가 발생할 수 있는 상황을 만들 수도 있음 해시 테이블에 고르게 분포할 수 있도록 주소를 만들어야 함

229
해싱 해싱 함수 중간 제곱 함수 키 값을 제곱한 결과 값에서 중간에 있는 적당한 비트를 주소로 사용
제곱한 값의 중간 비트들은 대개 키의 모든 값과 관련이 있기 때문에 서로 다른 키 값은 서로 다른 중간 제곱 함수 값을 갖게 됨 예)키 값 의 해시주소 X 해시 주소
키 값 의 해시주소 X 해시 주소.")
230
해싱 해싱 함수 제산 함수 승산 함수 함수는 나머지 연산자 mod (C에서의 %)를 이용
키 값 k를 해시 테이블의 크기 M으로 나눈 나머지를 해시 주소로 사용 제산함수 : h(k)=k mod M M으로 나눈 나머지 값은 0~(M-1)의 값이 되므로 해시 테이블의 인덱스로 사용 M은 적당한 크기의 소수 사용이 효율적 승산 함수 곱하기 연산을 사용하는 방법 키 값 k와 정해진 실수 α를 곱한 결과에서 소수점 이하 부분만을 테이블의 크기 M과 곱하여 그 정수 값을 주소로 사용
=k mod M. M으로 나눈 나머지 값은 0~(M-1)의 값이 되므로 해시 테이블의 인덱스로 사용. M은 적당한 크기의 소수 사용이 효율적. 승산 함수. 곱하기 연산을 사용하는 방법. 키 값 k와 정해진 실수 α를 곱한 결과에서 소수점 이하 부분만을 테이블의 크기 M과 곱하여 그 정수 값을 주소로 사용.")
231
해싱 해싱 함수 접지함수 키의 비트 수가 해시 테이블 인덱스 비트 수보다 큰 경우에 주로 사용 이동 접지 함수
각 분할 부분을 이동시켜서 오른쪽 끝자리가 일치하도록 맞추고 더하는 방법 예) 해시테이블 인덱스가 3자리이고 키 값 k가 인 경우
 해시테이블 인덱스가 3자리이고 키 값 k가 인 경우.")
232
해싱 해싱 함수 접지함수 경계 접지 함수 분할된 각 경계를 기준으로 접으면서 서로 마주보도록 배치하고 더하는 방법
예) 해시 테이블 인덱스가 3자리이고 키 값 k가 인 경우
 해시 테이블 인덱스가 3자리이고 키 값 k가 인 경우.")
233
해싱 해싱 함수 숫자 분석 함수 키 값을 이루고 있는 각 자릿수의 분포를 분석하여 해시 주소로 사용하는 방법
각 키 값을 적절히 선택한 진수로 변환한 후 각 자릿수의 분포를 분석하여 가장 편중된 분산을 가진 자릿수는 생략하고, 가장 고르게 분포된 자릿수부터 해시 테이블 주소의 자릿수만큼 차례로 뽑아서 만든 수를 역순으로 바꾸어서 주소로 사용 예) 키 값이 학번이고 해시 테이블 주소의 자릿수가 3자리인 경우
 키 값이 학번이고 해시 테이블 주소의 자릿수가 3자리인 경우.")
234
해싱 해싱 함수 진법 변환 함수 키 값이 10진수가 아닌 다른 진수일 때, 10진수로 변환하고 해시 테이블 주소로 필요한 자릿수 만큼만 하위 자리의 수를 사용하는 방법 비트 추출 함수 해시 테이블의 크기가 2k일 때 키 값을 이진 비트로 놓고 임의의 위치에 있는 비트들을 추출하여 주소로 사용하는 방법 비트 추출 함수를 이용한 방법은 충돌 발생 가능성이 높으므로 테이블의 일부에 주소가 편중되지 않도록 키 값들의 비트들을 사전에 분석하여 사용해야 함

235
해싱 오버플로우 처리 방법 선형 개방 주소법(선형 조사법(linear probing))
해싱 함수로 구한 버킷에 빈 슬롯이 없어서 오버플로우가 발생하면 그 다음 버킷에 빈 슬롯이 있는지 조사 빈 슬롯이 있으면 : 키 값을 저장 빈 슬롯이 없으면 : 다시 그 다음 버킷을 조사 해시 테이블 내에 빈 슬롯을 순차적으로 사용하여 오버플로우 문제를 처리

236
해싱 오버플로우 처리방법 선형 개방 주소법(예) 해시 테이블의 크기 : 5 해시함수 : 제산함수 h(k)=k mod 5
저장할 키 값 : {45, 9, 10, 96, 25} 키 값 45 저장 : h(45) = 45 mod 5 = 0 => 해시테이블 0번에 45 저장 키 값 9 저장 : h(9) = 9 mod 5 = 4 => 해시테이블 4번에 9 저장 키 값 10 저장 : h(10) = 10 mod 5 = 0 => 충돌발생 => 해시테이블의 다음 버킷 중 비어있는 버킷 1에 저장 키 값 96 저장 : h(96) = 96 mod 5 = 1 => 충돌발생 => 해시테이블의 다음 버킷 중 비어있는 버킷 2에 저장 키 값 25 저장 : h(25) = 25 mod 5 = 0 => 충돌발생 => 해시 테이블의 다음 버킷 중 비어있는 버킷 3에 저장
 = 45 mod 5 = 0 => 해시테이블 0번에 45 저장. 키 값 9 저장 : h(9) = 9 mod 5 = 4 => 해시테이블 4번에 9 저장. 키 값 10 저장 : h(10) = 10 mod 5 = 0 => 충돌발생 => 해시테이블의 다음 버킷 중 비어있는 버킷 1에 저장. 키 값 96 저장 : h(96) = 96 mod 5 = 1 => 충돌발생 => 해시테이블의 다음 버킷 중 비어있는 버킷 2에 저장. 키 값 25 저장 : h(25) = 25 mod 5 = 0 => 충돌발생 => 해시 테이블의 다음 버킷 중 비어있는 버킷 3에 저장.")
237
해싱 {45, 9, 10, 96, 25}

238
해싱 오버플로우 처리 방법 체이닝 해시테이블의 구조를 변경하여 각 버킷에 하나 이상의 키 값을 저장할 수 있도록 하는 방법
버킷에 슬롯을 동적으로 삽입하고 삭제하기 위해서 연결 리스트 사용 각 버킷에 대한 헤드노드를 1차원 배열로 만들고 각 버킷에 대한 헤드노드는 슬롯들을 연결 리스트로 가지고 있어서 슬롯의 삽입이나 삭제 연산을 쉽게 수행할 수 있음 버킷 내에서 원하는 슬롯을 검색하기 위해서는 버킷의 연결 리스트를 선형으로 검색

239
해싱 오버플로우 처리 방법 체이닝(예) 해시테이블의 크기 : 5 해시함수 : 제산함수 h(k)=k mod 5
저장할 키 값 : {45, 9, 10, 96, 25} 키 값 45 저장 : h(45) = 45 mod 5 = 0 => 해시테이블 0번에 노드를 삽입하고 45 저장 키 값 9 저장 : h(9) = 9 mod 5 = 4 => 해시테이블 4번에 노드를 삽입하고 9 저장 키 값 10 저장 : h(10) = 10 mod 5 = 0 => 해시테이블의 0번에 노드를 삽입하고 10 저장 키 값 96 저장 : h(96) = 96 mod 5 = 1 => 충돌발생 => 해시테이블의 1번에 노드를 삽입하고 96 저장 키 값 25 저장 : h(25) = 25 mod 5 = 0 => 충돌발생 => 해시 테이블의 0번에 노드를 삽입하고 25 저장
 = 45 mod 5 = 0 => 해시테이블 0번에 노드를 삽입하고 45 저장. 키 값 9 저장 : h(9) = 9 mod 5 = 4 => 해시테이블 4번에 노드를 삽입하고 9 저장. 키 값 10 저장 : h(10) = 10 mod 5 = 0 => 해시테이블의 0번에 노드를 삽입하고 10 저장. 키 값 96 저장 : h(96) = 96 mod 5 = 1 => 충돌발생 => 해시테이블의 1번에 노드를 삽입하고 96 저장. 키 값 25 저장 : h(25) = 25 mod 5 = 0 => 충돌발생 => 해시 테이블의 0번에 노드를 삽입하고 25 저장.")
240
해싱 {45, 9, 10, 96, 25}

241
1.1 자료구조의 형태에 따른 분류


.>")
 자료구조의 개요 1) 자료구조 ① 일련의 자료들을 조직하고 구조화하는 것 ② 자료의 표현과 그것과 관련된 연산 2) 자료구조에 따라 저장공간의 효율성과 프로그램의 실행시간이 달라짐 3) 어떠한 자료구조에서도 필요한 모든 연산들을 처리하는 것이.>")

>")





(1/2)>")
 알고리즘 개요 (효율, 분석, 차수) Part 1 강원대학교 컴퓨터과학전공 문양세.>")

 09. 04. 07.>")






.>")