Download presentation
1
스택(stack) SANGJI University Kwangman Ko
 SANGJI University Kwangman Ko")
2
1. 스택의 개요 스택(stack) 쌓아놓은 더미
 쌓아놓은 더미")
3
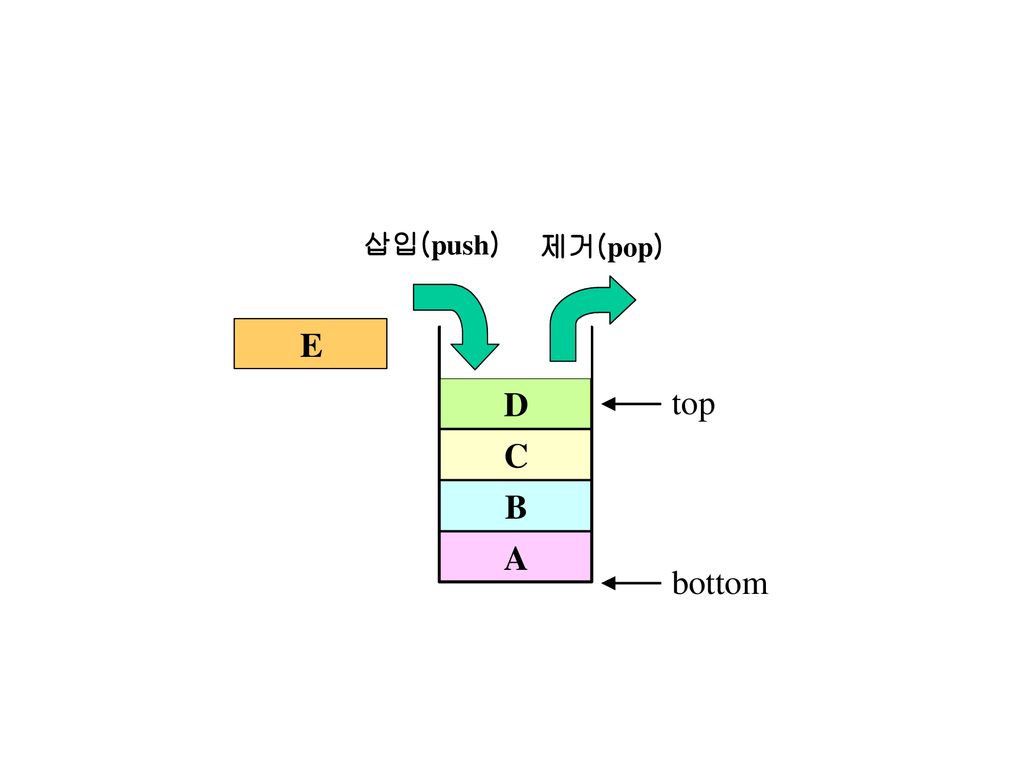
스택의 특징 스택의 동작 모든 원소의 삽입과 삭제가 top이라는 자료구조의 한 쪽 끝에서만 수행되는 제한된 리스트 구조
후입 선출 (Last-In-First-Out, LIFO) 방식 가장 마지막에 입력된 자료가 가장 먼저 출력 스택의 동작 top에서만 삽입(push)과 삭제(pop)가 발생 top의 위치는 동작에 따라 유동적으로 변함 top의 값이 스택 포인터(stack pointer)라고 하는 레지스터(register)에 저장 top의 반대편 끝을 bottom
 방식. 가장 마지막에 입력된 자료가 가장 먼저 출력. 스택의 동작. top에서만 삽입(push)과 삭제(pop)가 발생. top의 위치는 동작에 따라 유동적으로 변함. top의 값이 스택 포인터(stack pointer)라고 하는 레지스터(register)에 저장. top의 반대편 끝을 bottom.")
5
스택의 연산 삽입(push), 삭제(pop) push(A) push(B) push(C) pop() C B B B A A A A
초기상태

6
삽입(push) 스택에 새로운 자료를 삽입하는 연산 항상 top에서 발생.
이미 수용할 수 있는 스택의 공간이 꽉 차있으면 오버플로우(overflow)가 발생
가 발생.")
7
삭제(pop) 스택에서 자료를 제거하는 연산 항상 top에서 발생.
top이 가리키고 있는 자료를 삭제한 후 top 값을 1 감소 top 값이 -1이라면 스택은 제거할 자료가 하나도 없는 공백(empty) 상태
 상태.")
8
is_empty(s) is_full(s) create() peek(s) 스택이 공백상태인지 검사 스택이 포화상태인지 검사
스택을 생성 peek(s) 스택의 top에 위치한 자료의 값을 단순히 읽어오는 연산 해당 자료를 제거하거나 top 값을 변경하지 않음. c.f.) pop 연산은 요소를 스택에서 완전히 삭제하면서 가져옴.
 스택의 top에 위치한 자료의 값을 단순히 읽어오는 연산. 해당 자료를 제거하거나 top 값을 변경하지 않음. c.f.) pop 연산은 요소를 스택에서 완전히 삭제하면서 가져옴.")
9
스택의 용도 입력과 역순의 출력이 필요한 경우 에디터에서 되돌리기(undo) 기능 함수호출에서 복귀주소 기억 sub2
1 20 100 150 200 int main() { int i=3; sub1(i); ... } int sub1(int a) int j=5; sub2(j); void sub2(int b) ... sub2 PC=200 b=5 sub1 PC=100 a=3 sub1 PC=150 a=3 j=5 sub1 PC=151 a=3 j=5 main PC=1 main PC=20 i=3 main PC=20 i=3 main PC=20 i=3 main PC=21 i=3 시스템 스택 시스템 스택 시스템 스택 시스템 스택 시스템 스택
 { int i=3; sub1(i); ... } int sub1(int a) int j=5; sub2(j); void sub2(int b) ... sub2. PC=200. b=5. sub1. PC=100. a=3. sub1. PC=150. a=3. j=5. sub1. PC=151. a=3. j=5. main. PC=1. main. PC=20. i=3. main. PC=20. i=3. main. PC=20. i=3. main. PC=21. i=3. 시스템 스택. 시스템 스택. 시스템 스택. 시스템 스택. 시스템 스택.")
10
배열을 이용한 스택 구현 1차원 배열, stack[ ] top 변수 : 스택에 가장 최근에 입력되었던 자료 포인터
4 top 4 4 3 3 3 top 2 2 2 1 1 1 top -1 -1 -1 포화상태
![배열을 이용한 스택 구현 1차원 배열, stack[ ] top 변수 : 스택에 가장 최근에 입력되었던 자료 포인터](http://slidesplayer.org/slide/14795881/90/images/10/%EB%B0%B0%EC%97%B4%EC%9D%84+%EC%9D%B4%EC%9A%A9%ED%95%9C+%EC%8A%A4%ED%83%9D+%EA%B5%AC%ED%98%84+1%EC%B0%A8%EC%9B%90+%EB%B0%B0%EC%97%B4%2C+stack%5B+%5D+top+%EB%B3%80%EC%88%98+%3A+%EC%8A%A4%ED%83%9D%EC%97%90+%EA%B0%80%EC%9E%A5+%EC%B5%9C%EA%B7%BC%EC%97%90+%EC%9E%85%EB%A0%A5%EB%90%98%EC%97%88%EB%8D%98+%EC%9E%90%EB%A3%8C+%ED%8F%AC%EC%9D%B8%ED%84%B0.jpg "4. top top top 포화상태.")
11
is_empty, is_full 연산 is_empty(S) if top = -1 then return TRUE
else return FALSE is_full(S) if top = (MAX_STACK_SIZE-1) then return TRUE else return FALSE 4 4 top 3 3 2 2 1 1 -1 top -1 공백상태 포화상태
 if top = (MAX_STACK_SIZE-1) then return TRUE. else return FALSE top top. -1. 공백상태. 포화상태.")
12
push 연산 push(S, x) if is_full(S) then error "overflow" else top←top+1
stack[top]←x 4 4 3 3 2 top 2 1 top 1

13
pop 연산 pop(S, x) if is_empty(S) then error "underflow"
else e←stack[top] top←top-1 return e 4 4 3 3 2 top 2 top 1 1

14
연결리스트로 스택 구현 연결된 스택(linked stack) 연결리스트를 이용하여 구현한 스택 장점: 크기가 제한되지 않음
단점: 구현이 복잡하고 삽입이나 삭제 시간이 오래 걸린다. 9 3 2 top 9 7 1 7 3 3 N

15
연결된 스택 정의 typedef int element; typedef struct StackNode {
typedef struct StackNode { element item; struct StackNode *link; } StackeNode; typedef struct { StackNode *top; } LinkedStackType;

16
연결된 스택에서 push 연산 C top (1) B (2) D A temp NULL
 B (2) D A temp NULL")
17
void push(LinkedStackType *s, element item) {
StackNode *temp= (StackNode *)malloc(sizeof(StackNode)); if( temp == NULL ){ fprintf(stderr, "메모리 할당에러\n"); return; } else{ temp->item = item; temp->link = s->top; s->top = temp; }
malloc(sizeof(StackNode)); if( temp == NULL ){ fprintf(stderr, 메모리 할당에러\n ); return; } else{ temp->item = item; temp->link = s->top; s->top = temp; }")
18
연결된 스택에서 pop 연산 top C B A temp NULL

19
element pop(LinkedStackType *s) {
if( is_empty(s) ) { fprintf(stderr, "스택이 비어있음\n"); exit(1); } else{ StackNode *temp=s->top; int item = temp->item; s->top = s->top->link; free(temp); return item; }
 ) { fprintf(stderr, 스택이 비어있음\n ); exit(1); } else{ StackNode *temp=s->top; int item = temp->item; s->top = s->top->link; free(temp); return item; }")
20
스택 응용 : 수식의 계산 수식의 표기방법: 컴퓨터에서의 수식 계산순서
전위(prefix), 중위(infix), 후위(postfix) 컴퓨터에서의 수식 계산순서 중위표기식-> 후위표기식->계산 2+3*4 -> 234*+ -> 14 모두 스택을 사용 중위 표기법 전위 표기법 후위 표기법 2+3*4 +2*34 234*+ a*b+5 +5*ab ab*5+ (1+2)+7 +7+12 12+7+
, 중위(infix), 후위(postfix) 컴퓨터에서의 수식 계산순서. 중위표기식-> 후위표기식->계산. 2+3*4 -> 234*+ -> 14. 모두 스택을 사용. 중위 표기법. 전위 표기법. 후위 표기법. 2+3*4. +2* *+ a*b+5. +5*ab. ab*5+ (1+2)")
21
후위 표기식의 계산 방법 예, 82/3-32*+ 왼쪽에서 오른쪽으로 스캔 피연산자, 스택에 푸쉬
연산자, 피연산자를 스택에서 팝, 연산 실행 연산 결과를 다시 스택에 푸쉬 예, 82/3-32*+

22
토큰 스택 [0] [1] [2] [3] [4] [5] [6] 8 2 / 4 3 - 1 * 6 + 7
![토큰 스택 [0] [1] [2] [3] [4] [5] [6] 8 2 / * 6 + 7](http://slidesplayer.org/slide/14795881/90/images/22/%ED%86%A0%ED%81%B0+%EC%8A%A4%ED%83%9D+%5B0%5D+%5B1%5D+%5B2%5D+%5B3%5D+%5B4%5D+%5B5%5D+%5B6%5D+8+2+%2F+%2A+6+%2B+7.jpg "토큰 스택 [0] [1] [2] [3] [4] [5] [6] 8 2 / * 6 + 7")
23
1 2 3 8 / - 4 피연산자-> 삽입 연산자-> 8/2=4 삽입

24
1 2 3 4 8 / - 피연산자-> 삽입 연산자-> 4-1=1 삽입 종료->전체 연산 결과=1

25
후위 표기식 계산 알고리즘 스택 s를 생성하고 초기화한다. for 항목 in 후위표기식 do if (항목이 피연산자이면)
push(s, item) if (항목이 연산자 op이면) then second ← pop(s) first ← pop(s) result ← first op second push(s, result) final_result ← pop(s);
 if (항목이 연산자 op이면) then second ← pop(s) first ← pop(s) result ← first op second. push(s, result) final_result ← pop(s);")
26
eval(char exp[]) { int op1, op2, value, i=0; int len = strlen(exp); char ch; StackType s; init(&s); for( i=0; i<len; i++){ ch = exp[i]; if( ch != '+'&& ch != '-' && ch != '*' && ch != '/' ){ value = ch - '0'; // 입력이 피연산자이면 push(&s, value); } else{ //연산자이면 피연산자를 스택에서 제거 op2 = pop(&s); op1 = pop(&s); switch(ch){ //연산을 수행하고 스택에 저장 case '+': push(&s,op1+op2); break; case '-': push(&s,op1-op2); break; case '*': push(&s,op1*op2); break; case '/': push(&s,op1/op2); break; } } return pop(&s);
![eval(char exp[]) { int op1, op2, value, i=0; int len = strlen(exp); char ch; StackType s; init(&s);](http://slidesplayer.org/slide/14795881/90/images/26/eval%28char+exp%5B%5D%29+%7B+int+op1%2C+op2%2C+value%2C+i%3D0%3B+int+len+%3D+strlen%28exp%29%3B+char+ch%3B+StackType+s%3B+init%28%26s%29%3B.jpg "for( i=0; i<len; i++){ ch = exp[i]; if( ch != + && ch != - && ch != * && ch != / ){ value = ch - 0 ; // 입력이 피연산자이면. push(&s, value); } else{ //연산자이면 피연산자를 스택에서 제거. op2 = pop(&s); op1 = pop(&s); switch(ch){ //연산을 수행하고 스택에 저장. case + : push(&s,op1+op2); break; case - : push(&s,op1-op2); break; case * : push(&s,op1*op2); break; case / : push(&s,op1/op2); break; } } return pop(&s);")
27
중위표기식->후위표기식 중위표기와 후위표기 알고리즘 중위 표기법과 후위 표기법의 공통점은 피연산자의 순서는 동일
중위표기와 후위표기 중위 표기법과 후위 표기법의 공통점은 피연산자의 순서는 동일 연산자들의 순서만 다름(우선순위순서) 연산자만 스택에 저장했다가 출력 2+3*4 -> 234*+ 알고리즘 피연산자를 만나면 그대로 출력 연산자를 만나면 스택에 저장했다가 스택보다 우선 순위가 낮은 연산자가 나오면 그때 출력 왼쪽 괄호는 우선순위가 가장 낮은 연산자로 취급 오른쪽 괄호가 나오면 스택에서 왼쪽 괄호위에 쌓여있는 모든 연산자를 출력
 연산자만 스택에 저장했다가 출력. 2+3*4 -> 234*+ 알고리즘. 피연산자를 만나면 그대로 출력. 연산자를 만나면 스택에 저장했다가 스택보다 우선 순위가 낮은 연산자가 나오면 그때 출력. 왼쪽 괄호는 우선순위가 가장 낮은 연산자로 취급. 오른쪽 괄호가 나오면 스택에서 왼쪽 괄호위에 쌓여있는 모든 연산자를 출력.")
28
( a + b ) * c (
 * c (")
29
( a + b ) * c a (
 * c a (")
30
( a + b ) * c a + (
 * c a + (")
31
( a + b ) * c a b + (
 * c a b + (")
32
( a + b ) * c a b +
 * c a b +")
33
( a + b ) * c a b + *
 * c a b + *")
34
( a + b ) * c a b + c *
 * c a b + c *")
35
( a + b ) * c a b + c *
 * c a b + c *")
36
infix_to_postfix(exp)
while (exp에 처리할 문자가 남아 있으면) ch ← 다음에 처리할 문자 switch (ch) case 연산자: while ( peek(s)의 우선순위 ≥ ch의 우선순위 ) do e ← pop(s) e를 출력 push(s, ch); break; case 왼쪽 괄호: case 오른쪽 괄호: e ← pop(s); while( e ≠ 왼쪽괄호 ) do e를 출력 e ← pop(s) case 피연산자: ch를 출력 while( not is_empty(s) ) do e ← pop(s) e를 출력
 ch ← 다음에 처리할 문자. switch (ch) case 연산자: while ( peek(s)의 우선순위 ≥ ch의 우선순위 ) do e ← pop(s) e를 출력 push(s, ch); break; case 왼쪽 괄호: case 오른쪽 괄호: e ← pop(s); while( e ≠ 왼쪽괄호 ) do e를 출력. e ← pop(s) case 피연산자: ch를 출력. while( not is_empty(s) ) do e ← pop(s) e를 출력.")
37
Chap. 6 : 큐(queue) SANGJI University Kwangman Ko
 SANGJI University Kwangman Ko")
38
큐(QUEUE) 특징 먼저 들어온 데이터가 먼저 나가는 자료구조 선입선출(FIFO: First-In First-Out)
예, 매표소의 대기열 Ticket Box 전단(front) 후단(rear)
 후단(rear)")
39
큐의 응용 직접적인 응용 간접적인 응용 시뮬레이션의 대기열(공항에서의 비행기들, 은행에서의 대기열)
통신에서의 데이터 패킷들의 모델링에 이용 프린터와 컴퓨터 사이의 버퍼링 간접적인 응용 스택과 마찬가지로 프로그래머의 도구 많은 알고리즘에서 사용됨 data QUEUE 생산자 버퍼 소비자

40
배열을 이용한 큐 선형큐 배열을 선형으로 사용하여 큐를 구현 삽입을 계속하기 위해서는 요소들을 이동시켜야 함
문제점이 많아 사용되지 않음 [0] [-1] [1] [2] [3] [4] [5] front rear

41
원형큐 배열을 원형으로 사용하여 큐를 구현 [0] [1] [2] [3] [MAX_SIZE-1] [MAX_SIZE-2] …
![원형큐 배열을 원형으로 사용하여 큐를 구현 [0] [1] [2] [3] [MAX_SIZE-1] [MAX_SIZE-2] …](http://slidesplayer.org/slide/14795881/90/images/41/%EC%9B%90%ED%98%95%ED%81%90+%EB%B0%B0%EC%97%B4%EC%9D%84+%EC%9B%90%ED%98%95%EC%9C%BC%EB%A1%9C+%EC%82%AC%EC%9A%A9%ED%95%98%EC%97%AC+%ED%81%90%EB%A5%BC+%EA%B5%AC%ED%98%84+%5B0%5D+%5B1%5D+%5B2%5D+%5B3%5D+%5BMAX_SIZE-1%5D+%5BMAX_SIZE-2%5D+%E2%80%A6.jpg "원형큐 배열을 원형으로 사용하여 큐를 구현 [0] [1] [2] [3] [MAX_SIZE-1] [MAX_SIZE-2] …")
42
큐의 구조 큐 전단과 후단을 관리하기 위한 2개의 변수 필요 front: 첫번째 요소 하나 앞의 인덱스
rear: 마지막 요소의 인덱스 1 2 3 4 5 6 7 front rear A B

43
1 2 3 4 5 6 7 front rear A (a) 초기상태 (b) A 삽입
 초기상태 (b) A 삽입")
44
1 2 3 4 5 6 7 front rear A B (c) B 삽입 (d) A 삭제
 B 삽입 (d) A 삭제")
45
공백상태, 포화상태 공백상태: front == rear 포화상태: front % M==(rear+1) % M
공백상태와 포화상태를 구별하기 위하여 하나의 공간은 항상 비워둔다. 3 3 3 4 4 4 C D C D 2 2 2 5 5 5 B E B E F F A A 1 6 1 6 1 6 G G H 7 7 7 rear front rear front front rear (a) 공백상태 (b) 포화상태 (c) 오류상태
 공백상태. (b) 포화상태. (c) 오류상태.")
46
큐의 연산 // 공백 상태 검출 함수 int is_empty(QueueType *q) {
return (q->front == q->rear); } // 포화 상태 검출 함수 int is_full(QueueType *q) return ((q->rear+1)%MAX_QUEUE_SIZE == q->front);
; } // 포화 상태 검출 함수. int is_full(QueueType *q) return ((q->rear+1)%MAX_QUEUE_SIZE == q->front);")
47
// 삽입 함수 void enqueue(QueueType *q, element item) { if( is_full(q) ) error("큐가 포화상태입니다"); q->rear = (q->rear+1) % MAX_QUEUE_SIZE; q->queue[q->rear] = item; } // 삭제 함수 element dequeue(QueueType *q) { if( is_empty(q) ) error("큐가 공백상태입니다"); q->front = (q->front+1) % MAX_QUEUE_SIZE; return q->queue[q->front];
 { if( is_empty(q) ) error( 큐가 공백상태입니다 ); q->front = (q->front+1) % MAX_QUEUE_SIZE; return q->queue[q->front];")
48
연결된 큐 연결된 큐(linked queue) 연결리스트로 구현된 큐 front 포인터 : 삭제 rear 포인터 : 삽입
큐에 요소가 없는 경우에는 front와 rear는 NULL. A B NULL C D front rear

49
연결된 큐에서의 삽입 rear front temp A B C D NULL rear front A B C D NULL

50
연결된 큐에서의 삭제 A B C D front rear NULL temp

51
덱(DEQUE) 덱(deque) Double-Ended QUEue
큐의 전단(front)와 후단(rear)에서 모두 삽입과 삭제가 가능 전단(front) 후단(rear) add_front delete_front get_front add_rear delete_rear get_rear
와 후단(rear)에서 모두 삽입과 삭제가 가능. 전단(front) 후단(rear) add_front. delete_front. get_front. add_rear. delete_rear. get_rear.")
52
연산의 종류 ∙객체: n개의 element형으로 구성된 요소들의 순서있는 모임 ∙연산: ▪ create() ::= 덱을 생성.
▪ init(dq) ::= 덱을 초기화. ▪ is_empty(dq) ::= 덱이 공백 상태인지를 검사. ▪ is_full(dq) ::= 덱이 포화상태인지를 검사. ▪ add_front(dq, e) ::= 덱의 앞에 요소를 추가. ▪ add_rear(dq, e) ::= 덱의 뒤에 요소를 추가. ▪ delete_front(dq) ::= 덱의 앞에 있는 요소를 반환한 다음 삭제 ▪ delete_rear(dq) ::= 덱의 뒤에 있는 요소를 반환한 다음 삭제. ▪ get_front(q) ::= 덱의 앞에서 삭제하지 않고 앞에 있는 요소를 반환. ▪ get_rear(q) ::= 덱의 뒤에서 삭제하지 않고 뒤에 있는 요소를 반환.
 ::= 덱을 초기화. ▪ is_empty(dq) ::= 덱이 공백 상태인지를 검사. ▪ is_full(dq) ::= 덱이 포화상태인지를 검사. ▪ add_front(dq, e) ::= 덱의 앞에 요소를 추가. ▪ add_rear(dq, e) ::= 덱의 뒤에 요소를 추가. ▪ delete_front(dq) ::= 덱의 앞에 있는 요소를 반환한 다음 삭제. ▪ delete_rear(dq) ::= 덱의 뒤에 있는 요소를 반환한 다음 삭제. ▪ get_front(q) ::= 덱의 앞에서 삭제하지 않고 앞에 있는 요소를 반환. ▪ get_rear(q) ::= 덱의 뒤에서 삭제하지 않고 뒤에 있는 요소를 반환.")
53
덱의 연산 front rear front rear C A B D A front(dq, A) ddd_rear(dq, D)
ddd_rear(dq, B) delete_front(dq) front rear front rear A B C A B delete_rear(dq) front(dq, C)
 delete_front(dq) front. rear. front. rear. A. B. C. A. B. delete_rear(dq) front(dq, C)")
54
덱의 구현 이중 연결리스트를 이용한 구현 양쪽끝에서 삽입, 삭제가 가능 typedef int element; // 요소의 타입
typedef struct DlistNode { // 노드의 타입 element data; struct DlistNode *llink; struct DlistNode *rlink; } DlistNode; typedef struct DequeType { // 덱의 타입 DlistNode *head; DlistNode *tail; } DequeType;

55
덱에서의 삽입 연산

56
void add_rear(DequeType *dq, element item)
{ DlistNode *new_node = create_node(dq->tail, item, NULL); if( is_empty(dq)) dq->head = new_node; else dq->tail->rlink = new_node; dq->tail = new_node; }
; if( is_empty(dq)) dq->head = new_node; else. dq->tail->rlink = new_node; dq->tail = new_node; }")
57
void add_front(DequeType *dq, element item)
{ DlistNode *new_node = create_node(NULL, item, dq->head); if( is_empty(dq)) dq->tail = new_node; else dq->head->llink = new_node; dq->head = new_node; }
; if( is_empty(dq)) dq->tail = new_node; else. dq->head->llink = new_node; dq->head = new_node; }")
58
덱에서의 삭제 연산

59
// 전단에서의 삭제 element delete_front(DequeType *dq) { element item; DlistNode *removed_node; if (is_empty(dq)) error("공백 덱에서 삭제"); else { removed_node = dq->head; // 삭제할 노드 item = removed_node->data; // 데이터 추출 dq->head = dq->head->rlink; // 헤드 포인터 변경 free(removed_node); // 메모리 공간 반납 if (dq->head == NULL) // 공백상태이면 dq->tail = NULL; else // 공백상태가 아니면 dq->head->llink=NULL; } return item;
; // 메모리 공간 반납. if (dq->head == NULL) // 공백상태이면. dq->tail = NULL; else // 공백상태가 아니면. dq->head->llink=NULL; } return item;")

.>")


>")







(1/2)>")

 09. 04. 07.>")





(1/2)>")