Download presentation
Presentation is loading. Please wait.

1
Probability and Statistics for Computer Engineer
What is model? Type of Models Purpose of the Class Course Overview

2
Model Model Types of Models
Virtual system to explain phenomena or behavior Example Stock price and weather forecasting rule, Ohm’s law Types of Models Deterministic v.s. Statistic(Stochastic) Chaotic v.s. Non-chaotic Deterministic Model Differential Equations, Functions, Transform
 Chaotic v.s. Non-chaotic. Deterministic Model. Differential Equations, Functions, Transform.")
3
Model Uncertainty Probability Statistical Model
Not data but statistics(mean, variance, probability density function) Uncertainty Ambiguity due to lack of evidence Relative Frequency Vagueness inherent in language Probability Mathematical model of relative frequency
 Uncertainty. Ambiguity due to lack of evidence. Relative Frequency. Vagueness inherent in language. Probability. Mathematical model of relative frequency.")
4
Why we need to study? Purpose of Study
Tool for analyzing & understanding statistical models Related Courses in Computer Engineering Statistical Pattern Recognition and Machine Learning Data Mining Data Communication Artificial Intelligence Simulation Engineering Statistical Communication Theory Digital Signal Processing Image Processing

5
Lecture Plan Text Topics to be covered 확률,랜덤변수,통계 및 랜덤과정 이준환 저
확률,랜덤변수,통계 및 랜덤과정 이준환 저 Topics to be covered Descriptive Statistics Probability and Random Variables Statistical Estimation Hypothesis Test Random Process

6
Lecture Plan Grading Policy Midterm 35%, Final 40%
Home Work with Programming 15% Presence 10%

7
서술적 통계학 (Descriptive Statistics)
")
8
통계학(Statistics): 관찰 및 조사를 통해 얻은 데이터로부터, 응용 수학의 기법을 이용해 수치상의 성질, 규칙성 등을 찾아내는 학문분야 서술적 통계학(Descriptive Statistics): 데이터 표본의 주요 특징을 그저 정량적으로 표현하는데 사용되는 통계학의 학문분야 유추적 통계(Inferetial Statistics) 표본으로부터 모집단에 관한 다양한 정보를 추론하는 통계학
 표본으로부터 모집단에 관한 다양한 정보를 추론하는 통계학.")
9
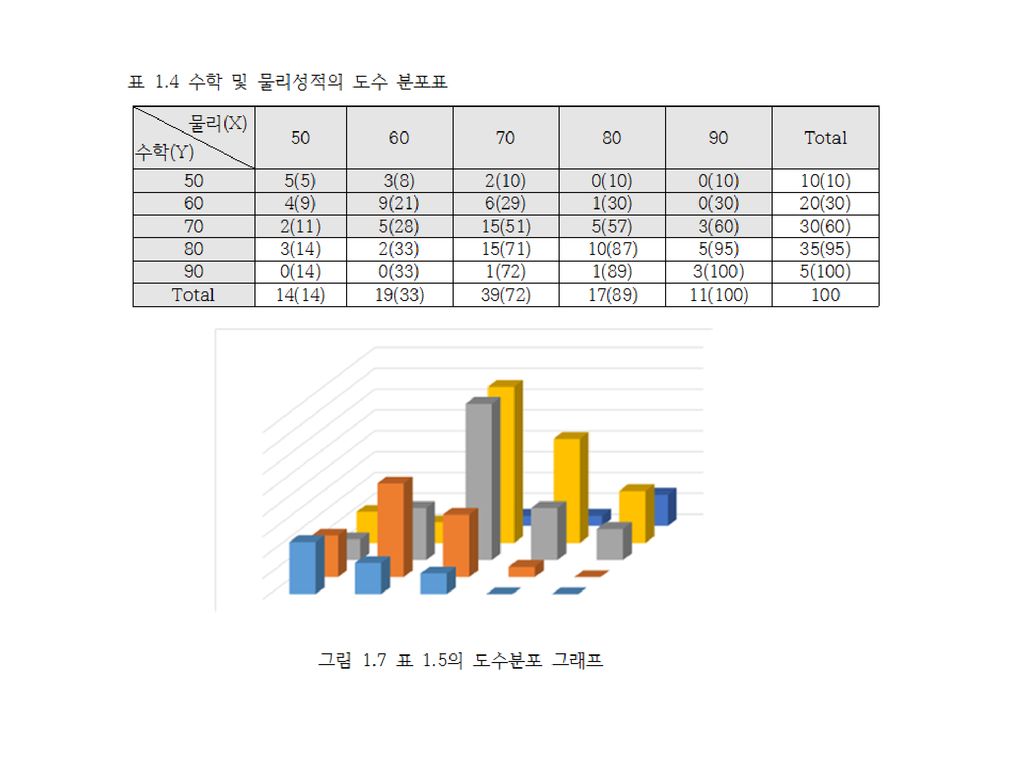
도수분포와 도수분포 그래프 주의도수분포와 그래프 빈도 및 상대도수(상대빈도) 누적상대도수(누적 상대빈도)
 누적상대도수(누적 상대빈도)")
10
막대가 표현하는 모든 빈도를 더하면 총 데이터의 수와 같 만약 이들을 상대빈도로 표현했다면 그 합은 1
(a) 도수분포의 막대그래프 (b) 누적 도수분포의 막대그래프 주의 막대가 표현하는 모든 빈도를 더하면 총 데이터의 수와 같 만약 이들을 상대빈도로 표현했다면 그 합은 1 계단의 차이는 해당 등급의 빈도 해당 등급에 빈도가 클 경우 기울기가 급함 해당 등급의 빈도가 0이면 기울기가 0이 된다. 그림 (b)에서 오른쪽 끝은 빈도 전체의 합 즉 데이터 수와 같으며 상대빈도로는 1
 도수분포의 막대그래프 (b) 누적 도수분포의 막대그래프. 주의. 막대가 표현하는 모든 빈도를 더하면 총 데이터의 수와 같. 만약 이들을 상대빈도로 표현했다면 그 합은 1. 계단의 차이는 해당 등급의 빈도. 해당 등급에 빈도가 클 경우 기울기가 급함. 해당 등급의 빈도가 0이면 기울기가 0이 된다. 그림 (b)에서 오른쪽 끝은 빈도 전체의 합 즉 데이터 수와 같으며 상대빈도로는 1.")
11
평균, 분산 및 표준편차 모집단과 표본 예: Height data of all the students in this class (Not sample, but population) Weights of sampled male students in CBNU (Sample) 표본평균 제곱오차의 합을 최소화하는 대표치(representatives) 간략하지만 데이터가 가진 충분한 정보를 담고 있지 않음
 표본평균. 제곱오차의 합을 최소화하는 대표치(representatives) 간략하지만 데이터가 가진 충분한 정보를 담고 있지 않음.")
12
주의: 표본평균은 Outlier (외톨이)에 민감
예: Mean = 91.2 Is it reasonable? 표본분산 및 표본 표준편차

13
표본 분산과 표본표준편차의 성질 단위: standard deviation = Unit of data 일종의 데이터가 평균으로부터 퍼진 정도 평균에 분산을 덧붙인다 하더라도 데이터가 가진 정보를 충분히 표현 못함

14
스큐니스(Skewness)와 커토시스(Kurtosis)
모드가 평균으로부터 치우친 정도 커토시스 분포 상부의 펑퍼짐한 정도 주의: 평균, 분산, 스큐니스, 커토시스를 모두 지정해도 일반적으로 데이터 분포를 일의적으로 규정하지 못함. 무한대차 까지의 모멘트가 필요

15
도수 분포표에서 평균/분산 구하기 표 1.1의 예: 스큐니스, 커토시스도 위와 같이 변형 가능

16
도수분포와 척도들의 수학적 모델 주사위 실험의 예: 1200번, 시행회수를 늘려가면 약 1/6
대수의 법칙(Law of large number)
")
17
대표치(위치척도) 미디안(Median) 데이터를 크기 순으로 정렬 후 중간 값에 해당 예:
P = {50,75,60,55,70,200,55,55} 산술평균= 77.5, 미디안 = (55+60)/2 = 57.5 Outlier = 200
/2 = Outlier = 200.")
18
예: Mode(2,3,2,1,4) = 2, Mode(5,6,7,8) = None
4분위(quartile) 데이터와 윈저드 평균(winsored mean) 예: S = {5,6,7,8,9,11,13} 윈저드 데이터= {6,6,7,8,9,11,11} 윈저드 평균 = 58/7 최빈값(mode) 빈도가 가장 많은 데이터 도수분포 그래프에서 첨두치 또는 누적도수가 가장 크게 증가하는 부분 예: Mode(2,3,2,1,4) = 2, Mode(5,6,7,8) = None Mode(9,5,4,8,9,8) = 8 or 9
 데이터와 윈저드 평균(winsored mean) 예: S = {5,6,7,8,9,11,13} 윈저드 데이터= {6,6,7,8,9,11,11} 윈저드 평균 = 58/7. 최빈값(mode) 빈도가 가장 많은 데이터. 도수분포 그래프에서 첨두치 또는 누적도수가 가장 크게 증가하는 부분. 예: Mode(2,3,2,1,4) = 2, Mode(5,6,7,8) = None. Mode(9,5,4,8,9,8) = 8 or 9.")
19
분포와 대표치

20
산포척도 분산과 같이 데이터가 평균치로부터 흩어진 정도를 표현 평균편차(mean deviation)
변동계수 (coefficient of variation) z-점수 (z-score) 상자수염 그림(box-wisker plot)
 z-점수 (z-score) 상자수염 그림(box-wisker plot)")
22
다변량 데이터 이변량(bivariate) 데이터의 예 - 가로 또는 세로 축 방향으로 데이터를 투영하면 단일변량 데이터
변량을 동시에 고려해 분석 (예: 남편과 아내 나이의 상관관계, 남편나이에 따른 아내나이의 추정) 이변량(bivariate) 데이터의 도수분포표
 이변량(bivariate) 데이터의 도수분포표.")
24
이변량(bivariate) 데이터의 평균과 분산, 공분산, 상관계수
평균과 분산: 각각의 변량의 평균들과 분산들 공분산(covariance): 공분산(covariance) 구하기와 의미: 1상한-3상한(+), 2상한-4상한(-)
: 공분산(covariance) 구하기와 의미: 1상한-3상한(+), 2상한-4상한(-)")
25
Population and Sample Population (모집단) Sample (표본) 예: 스마트 폰 공장의 불량검사
관심의 대상이 되는 모든 가능한 관측치나 측정값의 집단 유한모집단(선거인), 무한모집단(자연수 공간) Sample (표본) 일정기준에 의해 추출한 모집합의 부분집합 예: 스마트 폰 공장의 불량검사 Population: 생산된 모든 스마트 폰 Sample: 임의로 추출된 일정 대수의 스마트 폰
, 무한모집단(자연수 공간) Sample (표본) 일정기준에 의해 추출한 모집합의 부분집합. 예: 스마트 폰 공장의 불량검사. Population: 생산된 모든 스마트 폰. Sample: 임의로 추출된 일정 대수의 스마트 폰.")
26
상관계수(correlation coefficient)
")
27
조건부 평균(conditional mean)과 추정
표 1.4의 예: 물리성적 70점이라는 가정하래 수학성적의 추정 평균제곱오차 관점에서 최적이지만 외톨이 데이터에 민감 일반적으로 비선형적인 관계 회귀 분석(regression analysis)과 주성분 분석(principal component analysis) 회귀식(regressor) 선형 회귀식
과 주성분 분석(principal component analysis) 회귀식(regressor) 선형 회귀식.")
29
조건부 평균은 선형이 아님. 주성분 분석: 평균을 빼고 분산을 최대로 하는 방향

30
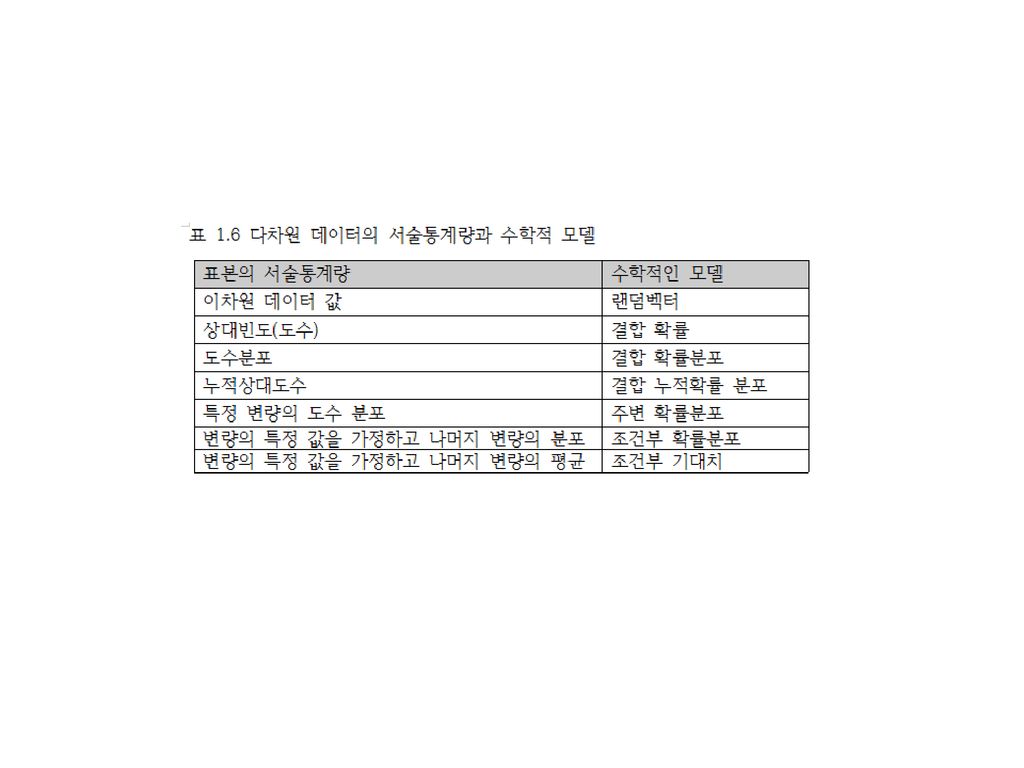
일반적인 다차원 데이터의 경우 다차원 배열로 표현 한 변량만을 고려하면 단일변량 데이터 평균과 분산은 다차원 벡터 공분산은 한 변량과 다른 한 변량 사이의 관계 표현

Similar presentations




 -. 통계적사고 -. 모집단과 표본. 통계적 사고 모든 작업은 상호연관된 프로세스의 시스템 예 ) 열처리 작업 공정 원료 투입 공정가열 공정 냉각 공정 모든 프로세스에는 산포가 존재 가피원인 불가피원인 동일 원료동일 생산공정 동일 작업자동일.>")
 통계량 (statistic) 표본자료의 함수 즉 모집단 … … 표본 표본추출 … … 통계량 계산.>")










>")
>")


 2016. 5. 20 서구원 한양사이버대학교 미디어MBA.>")
