Download presentation
1
연 속 확 률 분 포 5 균등분포 지수분포 감마분포 웨이블분포 베타분포 정규분포 정규분포에 관련된 연속분포들 1 2 3 4 5
6 정규분포 7 정규분포에 관련된 연속분포들

2
균등분포(uniform distribution)
1 균등분포(uniform distribution) 균등분포의 확률밀도함수와 분포함수 및 평균, 분산 그리고 균등분포에 대한 백분위수와 사분위수 등에 대하여 알아본다.
 균등분포의 확률밀도함수와 분포함수 및 평균, 분산 그리고 균등분포에 대한 백분위수와 사분위수 등에 대하여 알아본다.")
3
☞ ☞ 1) 확률밀도함수 2) 평균 X ~ U(a, b) f(x) = , a ≤ x ≤ b 1 b - a
m = E(X) = x f(x)dx = dx x b - a a b a+b 2 1 b - a x2 a b =
 = x f(x)dx = dx. x. b - a. a. b. a+b b - a. x2. a. b. =")
4
☞ ☞ 3) 분산 4) 분포함수 E(X2) x2 f(x)dx = dx a2 +ab + b2 3 1 b - a x3 =
s2 = Var(X) = E(X2) – E(X)2 - a2 +ab + b2 3 = a+b 2 (b – a)2 12 ☞ 4) 분포함수 x < a인 경우 : P(X ≤ x) = f(x)dx = du = 0 -∞ x x
 = E(X2) – E(X)2. - a2 +ab + b2. 3. = a+b. 2. (b – a) ☞ 4) 분포함수. x < a인 경우 : P(X ≤ x) = f(x)dx = 0 du = 0. -∞ x. x.")
5
a ≤ x < b인 경우 : x P(X ≤ x) = f(x)dx = 0 dx + du 1 b - a x - a =
-∞ x a x ≥ b인 경우 : P(X ≤ x) = f(x)dx = dx du du 1 b - a = 1 -∞ x a b 분포함수 : x - a b - a F(x) = P(X ≤ x) = , x < a , a ≤ x < b , x ≥ b
 = f(x)dx. = 0 dx + du + 0 du. 1. b - a. = 1. -∞ x. a. b. 분포함수 : x - a. b - a. F(x) = P(X ≤ x) = 0 , x < a. , a ≤ x < b. 1 , x ≥ b.")
6
☞ 5) 백분위수와 사분위수 0 < p < 1에 대하여
100p-백분위수 xp : [a, b]를 p : 1-p로 내분하는 점 xp=(1-p)a + pb 제1사분위수 Q1 = x0.25 = 0.75a b 제2사분위수 Q2 = Me = x0.5 = 0.5a + 0.5b 제3사분위수 Q3= x0.75 = 0.25a b 사분위수범위 I.Q.R = Q3 - Q1 = x x0.25 = 0.5b – 0.5a
a + pb. 제1사분위수 Q1 = x0.25 = 0.75a b. 제2사분위수 Q2 = Me = x0.5 = 0.5a + 0.5b. 제3사분위수 Q3= x0.75 = 0.25a b. 사분위수범위 I.Q.R = Q3 - Q1 = x x0.25 = 0.5b – 0.5a.")
7
X ~ U(0, 10)에 대하여 (1) X의 확률밀도함수와 분포함수 (2) X의 평균(m)와 분산(s2)
(3) P(m - s < X < m + s ) (4) 사분위수 Q1 , Q2 , Q3 (5) X의 최빈값 Mo = ? (1) X의 확률밀도함수 : X ~ U(0, 10)이므로 f(x) = , 0 < x < 10 1 10 X의 분포함수 : , x < 0 , x < 0 1 10 du x x 10 , 0 ≤ x < 10 , 0 ≤ x < 10 F(x) = P(X ≤ x) = = , x ≥ 10 , x ≥ 10
 P(m - s < X < m + s ) (4) 사분위수 Q1 , Q2 , Q3. (5) X의 최빈값 Mo = (1) X의 확률밀도함수 : X ~ U(0, 10)이므로. f(x) = , 0 < x < X의 분포함수 : 0 , x < 0. 0 , x < du. x. x. 10. , 0 ≤ x < 10. , 0 ≤ x < 10. F(x) = P(X ≤ x) = = 1 , x ≥ , x ≥ 10.")
8
m = E(X) = = 5, 0+10 2 s2 = Var(X) = = (10 - 0)2 12 (2) (3) s2 = 이므로 s = = 2.89 (m - s , m + s ) = (5 – 2.89, ) = (2.11, 7.89) P(m - s < X < m +s) = = 0.578 5.78 10 (4) 제1사분위수 Q1 = (0.75)•0 + (0.25) •(10) = 2.5 제2사분위수 Q2 = (0.5)•0 + (0.5) •(10) = 5.0 제3사분위수 Q3= (0.25)•0 + (0.75) •(10) = 7.5 1 10 (5) [0, 10]에서 f(x) = 이므로 f(x)의 최대값이 존재하지 않음. X의 최빈값이 없다.
 s2 = 이므로 s = = (m - s , m + s ) = (5 – 2.89, ) = (2.11, 7.89) P(m - s < X < m +s) = = (4) 제1사분위수 Q1 = (0.75)•0 + (0.25) •(10) = 2.5. 제2사분위수 Q2 = (0.5)•0 + (0.5) •(10) = 5.0. 제3사분위수 Q3= (0.25)•0 + (0.75) •(10) = (5) [0, 10]에서 f(x) = 이므로 f(x)의 최대값이 존재하지 않음. X의 최빈값이 없다.")
9
X ~ U(0, 1)에 대하여 Y = a + (b – a)X (a < b)라 할 때, (1) Y의 분포함수
(3) Y의 평균(m)와 분산(s2) (4) Y의 중앙값 Me = ? (1) X ~ U(0, 1)이므로 X의 분포함수 : , x < 0 , x < 0 x , 0 ≤ x < 1 x , 0 ≤ x < 1 FX(x) = P(X ≤ x) = 1 du = , x ≥ 1 , x ≥ 1 한편, y = a + (b – a)x이고 0 ≤ x ≤ 1이므로 a ≤ y ≤ b
 Y의 평균(m)와 분산(s2) (4) Y의 중앙값 Me = (1) X ~ U(0, 1)이므로. X의 분포함수 : 0 , x < 0. 0 , x < 0. x. , 0 ≤ x < 1. x , 0 ≤ x < 1. FX(x) = P(X ≤ x) = 1 du. = 1 , x ≥ 1. 1 , x ≥ 1. 한편, y = a + (b – a)x이고 0 ≤ x ≤ 1이므로 a ≤ y ≤ b.")
10
a ≤ y < b에 대하여 P(Y ≤ y) = P[a + (b – a)X ≤ y] y - a b - a = = P X ≤ = F = y - a b - a FY(x) = , y < a , a ≤ y < b , y ≥ b Y의 분포함수 : (2) Y의 확률밀도함수 : dx d dx d b - a y - a 1 fY(y) = FY(y) = = , a ≤ y ≤ b b - a
![a ≤ y < b에 대하여 P(Y ≤ y) = P[a + (b – a)X ≤ y] y - a. b - a. = = P X ≤ = F =](http://slidesplayer.org/slide/15320392/92/images/10/a+%E2%89%A4+y+%3C+b%EC%97%90+%EB%8C%80%ED%95%98%EC%97%AC+P%28Y+%E2%89%A4+y%29+%3D+P%5Ba+%2B+%28b+%E2%80%93+a%29X+%E2%89%A4+y%5D+y+-+a.+b+-+a.+%3D+%3D+P+X+%E2%89%A4+%3D+F+%3D.jpg "y - a. b - a. FY(x) = 0 , y < a. , a ≤ y < b. 1 , y ≥ b. Y의 분포함수 : (2) Y의 확률밀도함수 : dx. d. dx. d. b - a. y - a. 1. fY(y) = FY(y) = = , a ≤ y ≤ b. b - a.")
11
(3) Y ~ U(a, b)이므로 a+b s2 = Var(Y) = (b – a)2 12 m = E(Y) = 2 (4) Y ~ U(a, b)이므로 F(y0) = 0.5 = y0 - a b - a a+b 2 Me = y0 =

12
지수분포 (exponential distribution)
2 지수분포 (exponential distribution) 지수분포의 확률밀도함수와 평균, 분산을 비롯한 비기억성 성질 그리고 포아송과정과의 관계에 대하여 알아본다.
 지수분포의 확률밀도함수와 평균, 분산을 비롯한 비기억성 성질 그리고 포아송과정과의 관계에 대하여 알아본다.")
13
l의 비율로 사고가 발생할 때까지 걸리는 시간 또는 비율 l인 포아송과정에 따라 발생하는 사건 사이의 대기시간 등에 응용되는 확률분포를 모수 l인 지수분포라 한다.
☞ 1) 확률밀도함수 X ~ Exp(l) f(x) = le-lx , x > 0 , l> 0
 확률밀도함수. X ~ Exp(l) f(x) = le-lx , x > 0 , l> 0.")
14
☞ ☞ 2) 평균 3) 분산 m = E(X) = x f(x)dx = x le-lx dx lx + 1 l l 1
∞ ∞ m = E(X) = x f(x)dx = x le-lx dx u lx + 1 l l 1 = lim e-lx = u→∞ ☞ 3) 분산 ∞ ∞ E(X2) = x2 f(x)dx = x2 le-lx dx u l2x2 + 2lx + 2 l2 l2 2 = lim e-lx = x→∞ s2 = Var(X) = E(X2) – E(X)2 - = 2 l2 l 1
 = x f(x)dx = x le-lx dx. u. lx + 1. l. l. 1. = lim - e-lx = u→∞ ☞ 3) 분산. ∞ ∞ E(X2) = x2 f(x)dx = x2 le-lx dx. u. l2x2 + 2lx + 2. l2. l2. 2. = lim - e-lx = x→∞ s2 = Var(X) = E(X2) – E(X)2. - = 2. l2. l. 1.")
15
교차로에서 나타나는 교통사고 발생시간의 간격 X(단위:개월)
(1) 사고가 관측된 이후로 한 달이 지난 후에 다음 사고가 발생할 확률 (2) 두 달 안에 사고가 발생할 확률 (3) 한 달을 30일이라 할 때, 평균 몇 일만에 사고가 나는가? f(x) = 3e-3x , x > 0 1 ∞ ∞ (1) P(X > 1) = e-3x dx = (-1)e-3x = e-3 = 1 2 2 (2) P(X ≤ 2) = e-3x dx = (-1)e-3x = 1 - e-6 = (3) 사고일 수는 모수 l= 3인 기하분포이므로 월평균 사고발생 간격일 수는 m= 1/3, 즉 10일이다.
 사고가 관측된 이후로 한 달이 지난 후에 다음 사고가 발생할 확률. (2) 두 달 안에 사고가 발생할 확률. (3) 한 달을 30일이라 할 때, 평균 몇 일만에 사고가 나는가 f(x) = 3e-3x , x > ∞ ∞ (1) P(X > 1) = 3e-3x dx = (-1)e-3x = e-3 = 2. (2) P(X ≤ 2) = 3e-3x dx = (-1)e-3x = 1 - e-6 = (3) 사고일 수는 모수 l= 3인 기하분포이므로. 월평균 사고발생 간격일 수는 m= 1/3, 즉 10일이다.")
16
☞ 4) 분포함수 x < 0인 경우 : P(X ≤ x) = f(x)dx = 0 dx = 0 x ≥ 0인 경우 :
-∞ x x x ≥ 0인 경우 : x P(X ≤ x) = f(x)dx = dx le-lu du = - e-lu = 1- e-lx x -∞ x
 = f(x)dx. = 0 dx + le-lu du. = - e-lu = 1- e-lx. x. -∞ x.")
17
☞ ☞ 5) 생존함수(survival function)
분포함수 : F(x) = P(X ≤ x) = , x < 0 1- e-lx , x ≥ 0 ☞ 5) 생존함수(survival function) S(x) = P(X > x) = 1 – F(x) = e-lx , x > 0 ☞ 6) 위험률(hazard rate function), 실패율(failure rate function) h(x) = = l S(x) f(x)
 = P(X ≤ x) = 0 , x < e-lx , x ≥ 0. ☞ 5) 생존함수(survival function) S(x) = P(X > x) = 1 – F(x) = e-lx , x > 0. ☞ 6) 위험률(hazard rate function), 실패율(failure rate function) h(x) = = l. S(x) f(x)")
18
(1) X의 확률밀도함수와 분포함수를 구하여라. (2) X의 생존함수를 구하여라. (3) X의 위험률을 구하여라.
X ~ Exp(1/600)에 대하여 (1) X의 확률밀도함수와 분포함수를 구하여라. (2) X의 생존함수를 구하여라. (3) X의 위험률을 구하여라. (4) X의 기대값과 분산 X ~ Exp(1/600) 이므로 ● X의 확률밀도함수 ● X의 분포함수 f(x) = e-x/600 , x > 0 600 1 F(x) = 1- e-x / , x ≥ 0 ● X의 생존함수 X의 위험률 ● h(x) = l = , x ≥ 0 600 1 S(x) = e-x/600 , x > 0 ● X의 평균 ● X의 분산 m = 1/ l = 600 s2 = 1/ l2 =
에 대하여. (1) X의 확률밀도함수와 분포함수를 구하여라. (2) X의 생존함수를 구하여라. (3) X의 위험률을 구하여라. (4) X의 기대값과 분산. X ~ Exp(1/600) 이므로. ● X의 확률밀도함수. ● X의 분포함수. f(x) = e-x/600 , x > F(x) = 1- e-x /600 , x ≥ 0. ● X의 생존함수. X의 위험률. ● h(x) = l = , x ≥ S(x) = e-x/600 , x > 0. ● X의 평균. ● X의 분산. m = 1/ l = 600. s2 = 1/ l2 =")
19
P(X < 150) = F(150) = 1- e-150/100 = 1 – 0.2231 = 0.7769
환자의 생존시간 : X ~ Exp(1/100) (1) 이 환자가 150일 이내에 사망할 확률 (2) 이 환자가 200일 이상 생존할 확률 f(x) = e-x/100 , x > 0 100 1 X의 분포함수 X의 생존함수 F(x) = 1- e-x/ , x ≥ 0 S(x) = e-x/100 , x > 0 (1) 이 환자가 150일 이내에 사망할 확률 : P(X < 150) = F(150) = 1- e-150/100 = 1 – = (2) 이 환자가 200일 이상 생존할 확률 : P(X ≥ 200) = S(200) = e-200/100 = e-2 =
 (1) 이 환자가 150일 이내에 사망할 확률. (2) 이 환자가 200일 이상 생존할 확률. f(x) = e-x/100 , x > X의 분포함수. X의 생존함수. F(x) = 1- e-x/100 , x ≥ 0. S(x) = e-x/100 , x > 0. (1) 이 환자가 150일 이내에 사망할 확률 : P(X < 150) = F(150) = 1- e-150/100 = 1 – = (2) 이 환자가 200일 이상 생존할 확률 : P(X ≥ 200) = S(200) = e-200/100 = e-2 =")
20
정리 1 비기억성 성질(memorylessness property) X ~ Exp(l)에 대하여 다음이 성립한다.
P(X > a+b | X > a) = P(X > b) , a, b > 0 정리 1 비기억성 성질(memorylessness property) P(X > a+b | X > a) = P(X > a) P(X > a+b) P(X > a+b, X > a) = 증명 ∞ ∞ P(X > a+b) = le-lx dx = (-1) e-lx = e-l(a+b) a+b a+b ∞ ∞ P(X > a) = le-lx dx = (-1) e-lx = e-la a a ∞ ∞ P(X > b) = le-lx dx = (-1) e-lx = e-lb b b P(X > a+b | X > a) = P(X > a) P(X > a+b) = e-l(a+b) e-la = e-lb = P(X > b) 증명 끝
 = P(X > b) , a, b > 0. 정리 1 비기억성 성질(memorylessness property) P(X > a+b | X > a) = P(X > a) P(X > a+b) P(X > a+b, X > a) = 증명. ∞ ∞ P(X > a+b) = le-lx dx = (-1) e-lx = e-l(a+b) a+b. a+b. ∞ ∞ P(X > a) = le-lx dx = (-1) e-lx = e-la. a. a. ∞ ∞ P(X > b) = le-lx dx = (-1) e-lx = e-lb. b. b. P(X > a+b | X > a) = P(X > a) P(X > a+b) = e-l(a+b) e-la. = e-lb = P(X > b) 증명 끝.")
21
어떤 기계의 일부 부품이 고장 날 때까지 걸리는 시간은 평균 1,000시간인 지수분포에 따른다고 한다.
(1) 이 기계를 500시간 이상 아무런 문제없이 사용한 후, 그 후로 다시100시간 이상 사용할 확률을 구하여라. (2) (1)의 조건에 대하여, 앞으로 x시간 이상 사용할 확률이 0.3이라면 x = ? (1) 부품이 고장 날 때까지 걸리는 시간 X는 평균 m = 1000인 지수분포에 따르므로 X ~ Exp(1/1000) 1000 1 X의 확률밀도함수 : f(x) = e-x/1000 , x > 0 ∞ 100 P(X ≥ 600 | X ≥ 500) = P(X ≥ 100) = e-x/1000 dx 1000 1 = (-1)e-x/ = e-0.1 =
 이 기계를 500시간 이상 아무런 문제없이 사용한 후, 그 후로 다시100시간. 이상 사용할 확률을 구하여라. (2) (1)의 조건에 대하여, 앞으로 x시간 이상 사용할 확률이 0.3이라면 x = (1) 부품이 고장 날 때까지 걸리는 시간 X는 평균 m = 1000인 지수분포에 따르므로 X ~ Exp(1/1000) X의 확률밀도함수 : f(x) = e-x/1000 , x > 0. ∞ 100. P(X ≥ 600 | X ≥ 500) = P(X ≥ 100) = e-x/1000 dx = (-1)e-x/1000 = e-0.1 = ")
22
(2) (1)의 조건 아래서, 이 기계를 고장 없이 사용한 전체 시간 : 500 + x
P(X ≥ x|X ≥ 500) = P(X ≥ x) = S(x) = e-x/1000 = 0.3 1000 x = ln (0.3) ; x = (-1000)ln (0.3) = -
 = P(X ≥ x) = S(x) = e-x/1000 = x. = ln (0.3) ; x = (-1000)ln (0.3) =")
23
☞ 포아송과정과의 관계 예 연간 지진이 발생하는 회수 : X ~ P(3)
T : 지금부터 다음 지진이 일어날 때까지 걸리는 시간 예 사건 [T > t ]의 의미 : 현재부터 t시간 이후에 지진이 발생함 [0, t]에서 지진이 발생하지 않음 ▶ 사건 [T > t ]의 확률 : P(T > t) = P[X(t) = 0] = e-3t ▶ T의 분포함수 : F(t) = P(T ≤ t) = 1 - P(T > t) = 1 - e-3t , t > 0 ▶ T의 밀도함수 : f(t) = 1 - F(t) = 3e-3t , t > 0
 = P[X(t) = 0] = e-3t. ▶ T의 분포함수 : F(t) = P(T ≤ t) = 1 - P(T > t) = 1 - e-3t , t > 0. ▶ T의 밀도함수 : f(t) = 1 - F(t) = 3e-3t , t > 0.")
24
(1) 비율 l를 가지고 포아송과정에 따라 어떤 사건이 발생한다면, 이웃하는 두 사건 사이의 대기시간 T는 모수 l인 지수분포를 이룬다.
(2) 비기억성 성질로 어느 한 사건이 발생한 후, 다음 사건이 발생할 때까지 걸리는 대기시간 T는 모수 l인 지수분포에 따라 다시 시작하므로, 이웃하는 사건 사이의 대기시간들 Ti는 i.i.d. Exp(l)이다.
 비기억성 성질로 어느 한 사건이 발생한 후, 다음 사건이 발생할 때까지 걸리는 대기시간 T는 모수 l인 지수분포에 따라 다시 시작하므로, 이웃하는 사건 사이의 대기시간들 Ti는 i.i.d. Exp(l)이다.")
25
시스템의 응답시간 T는 평균 m=10인 지수분포 신호에 대한 응답이 끝나면 곧 바로 다음 신호를 접수 X(t) : 시간 t동안 이루어진 검색 신호 횟수 (1) 어떤 한 건의 검색 신호에 대한 응답시간이 6초 이상 걸릴 확률 (2) 검색 신호에 대한 응답을 위하여 5초 이상 기다려야 한다면, 그 후로 응답을 받기 위하여 적어도 8초 이상 시간을 소비해야 할 확률이 (3) X(t)의 확률질량함수 (4) 처음 신호가 들어온 이후로부터 5초 사이에 2건의 검색 신호가 있을 확률 (1) 시스템의 응답시간 T는 평균 m = 10인 지수분포에 따르므로 T ~ Exp(1/10) T의 분포함수 : F(t) = 1 - e-t/10 , t > 0 구하고자 하는 확률 : P(T ≥ 6) = 1 - P(T < 6) = 1 – F(6) = e-6/10 = e-0.6 =
 검색 신호에 대한 응답을 위하여 5초 이상 기다려야 한다면, 그 후로 응답을. 받기 위하여 적어도 8초 이상 시간을 소비해야 할 확률이. (3) X(t)의 확률질량함수. (4) 처음 신호가 들어온 이후로부터 5초 사이에 2건의 검색 신호가 있을 확률. (1) 시스템의 응답시간 T는 평균 m = 10인 지수분포에 따르므로 T ~ Exp(1/10) T의 분포함수 : F(t) = 1 - e-t/10 , t > 0. 구하고자 하는 확률 : P(T ≥ 6) = 1 - P(T < 6) = 1 – F(6) = e-6/10 = e-0.6 =")
26
(2) P(T ≥ 13|T > 5) = P(T > 8) = 1 – F(8) = e-8/10 = e-0.8 = (3) X(t) ~ P(t/10)이므로 X(t)의 확률질량함수 : (t/10)x x! f(x) = e-t/10 , x = 0, 1, 2, … (4) t=5이므로 처음 5초 동안 검색 신호가 들어온 횟수 : X(t) ~ P(0.5) 구하고자 하는 확률 : (포아송 확률표로부터) P(X = 2) = P(X ≤ 2) – P(X ≤ 1) = – = 0.076
x. x! f(x) = e-t/10 , x = 0, 1, 2, … (4) t=5이므로 처음 5초 동안 검색 신호가 들어온 횟수 : X(t) ~ P(0.5) 구하고자 하는 확률 : (포아송 확률표로부터) P(X = 2) = P(X ≤ 2) – P(X ≤ 1) = – =")
27
감마분포 (gamma distribution)
3 감마분포 (gamma distribution) 감마분포의 확률밀도함수와 평균, 분산 그리고 카이제곱분포에 대하여 알아본다.
 감마분포의 확률밀도함수와 평균, 분산 그리고 카이제곱분포에 대하여 알아본다.")
28
일정한 비율로 발생하는 사고가 n건 발생할 때까지 걸리는 전체 시간에 관한 확률분포 감마함수 :
∞ 감마함수 : G(a) = ta-1 e-t dt , a > 0 ∞ G(a) 1 ta-1 e-t dt = 1 t = x/b ∞ G(a) 1 x b a-1 1 b e-x/b dx = 1 p.d.f. 조건을 만족 또는 G(a) ba 1 ∞ xa-1 e-x/b dx = 1
 = ta-1 e-t dt , a > 0. ∞ G(a) 1. ta-1 e-t dt = 1. t = x/b. ∞ G(a) 1. x. b. a b. e-x/b dx = 1. p.d.f. 조건을 만족. 또는. G(a) ba. 1. ∞ xa-1 e-x/b dx = 1.")
29
☞ ☞ 감마함수의 성질 1) 확률밀도함수 G(1) = 1 G(a+1) = aG(a), a > 0
G(n+1) = nG(n)= n!, n 은 자연수 G(1) = 1 G(1/2) = p ● ● ● ● ☞ 1) 확률밀도함수 X ~ G(a, b) xa-1 e-x/b, x > 0, a, b > 0 G(a) ba 1 f(x) = a: 형상모수(shape parameter) b : 척도모수(scale
 = nG(n)= n!, n 은 자연수. G(1) = 1. G(1/2) = p. ● ● ● ● ☞ 1) 확률밀도함수. X ~ G(a, b) xa-1 e-x/b, x > 0, a, b > 0. G(a) ba. 1. f(x) = a: 형상모수(shape. parameter) b : 척도모수(scale.")
30
☞ 2) 평균 X ~ G(1, b) e-x/b , x > 0, b > 0 f(x) = b
X ~ Exp(1/b) 참고 ☞ 2) 평균 ∞ ∞ G(a) ba x m = E(X) = x f(x)dx = xa-1 e-x/b dx 1 = ∞ x(a+1)-1 e-x/b dx G(a) ba G(a+1) b ∞ 1 = x(a+1)-1 e-x/b dx G(a) G(a+1) ba+1 G(a+1) b aG(a) b = = = a b G(a) G(a)
 참고. ☞ 2) 평균. ∞ ∞ G(a) ba. x. m = E(X) = x f(x)dx = xa-1 e-x/b dx. 1. = ∞ x(a+1)-1 e-x/b dx. G(a) ba. G(a+1) b. ∞ 1. = x(a+1)-1 e-x/b dx. G(a) G(a+1) ba+1. G(a+1) b. aG(a) b. = = = a b. G(a) G(a)")
31
☞ 3) 분산 E(X2) = x2 f(x)dx = xa-1 e-x/b dx = x(a+2)-1 e-x/b dx
∞ ∞ G(a) ba x2 E(X2) = x2 f(x)dx = xa-1 e-x/b dx 1 = ∞ x(a+2)-1 e-x/b dx G(a) ba G(a+2)b2 = ∞ 1 x(a+2)-1 e-x/b dx G(a) G(a+2) ba+2 G(a+2)b2 a(a+1)G(a) b2 = = = a(a+1) b2 G(a) G(a) s2 = Var(X) = E(X2) – E(X)2 = a(a+1)b2 - (ab )2 = ab2
 ba. x2. E(X2) = x2 f(x)dx = xa-1 e-x/b dx. 1. = ∞ x(a+2)-1 e-x/b dx. G(a) ba. G(a+2)b2. = ∞ 1. x(a+2)-1 e-x/b dx. G(a) G(a+2) ba+2. G(a+2)b2. a(a+1)G(a) b2. = = = a(a+1) b2. G(a) G(a) s2 = Var(X) = E(X2) – E(X)2. = a(a+1)b2 - (ab )2 = ab2.")
32
감마분포와 지수분포 그리고 포아송과정 X1, X2, …, Xn ~ i.i.d. Exp(l)
S =X1 + X2 + …+ Xn ~ G(n, 1/l) (2) S : 비율 l인 포아송과정에 따라 n번째 사건이 발생할 때까지 걸리는 시간 비기억성 성질에 의하여 S ~ G(n, 1/l)
 (2) S : 비율 l인 포아송과정에 따라 n번째 사건이 발생할 때까지 걸리는 시간. 비기억성 성질에 의하여. S ~ G(n, 1/l)")
33
신호에 대한 응답이 끝나면 곧 바로 다음 신호를 접수 X : 오전 9:00부터 2건의 신호가 들어올 때까지 걸리는 시간
시스템의 응답시간 T는 평균 m=2인 지수분포 신호에 대한 응답이 끝나면 곧 바로 다음 신호를 접수 X : 오전 9:00부터 2건의 신호가 들어올 때까지 걸리는 시간 (1) X의 확률밀도함수 (2) 2건의 신호가 들어올 때까지 걸리는 평균 시간 (3) 2건의 검색요구가 3초 안에 이루어질 확률 (1) 시스템의 응답시간 T는 평균 m=2인 지수분포에 따르므로 T ~ Exp(1/2) T1 : 오전 9:00부터 처음 신호가 들어올 때까지 걸리는 시간 T2 : 처음 신호 이후에 두 번째 신호가 들어올 때까지 걸리는 시간 T1 ~ Exp(1/2) , T2 ~ Exp(1/2) X = T1 + T2 ~ G(2, 2) x2-1 e-x/2 = xe-x/ , x > 0 G(2) 22 1 f(x) = 4
 X의 확률밀도함수. (2) 2건의 신호가 들어올 때까지 걸리는 평균 시간. (3) 2건의 검색요구가 3초 안에 이루어질 확률. (1) 시스템의 응답시간 T는 평균 m=2인 지수분포에 따르므로 T ~ Exp(1/2) T1 : 오전 9:00부터 처음 신호가 들어올 때까지 걸리는 시간. T2 : 처음 신호 이후에 두 번째 신호가 들어올 때까지 걸리는 시간. T1 ~ Exp(1/2) , T2 ~ Exp(1/2) X = T1 + T2 ~ G(2, 2) x2-1 e-x/2 = xe-x/2 , x > 0. G(2) f(x) = 4.")
34
(2) (3) P(X < 3) = xe-x/2 dx = - e-x/2 = 1 - e-3/2 = 0.4421
m = a b = 2•2 = 4 1 4 P(X < 3) = xe-x/2 dx = e-x/2 = e-3/2 = x + 2 2 3 5
 = xe-x/2 dx = - e-x/2 = 1 - e-3/2 = x ")
35
카이제곱(c2)분포(chi-squared distribution)
모수 a = r/2, b = 2인 감마분포를 자유도(degree of freedom; d.f.) r 인 카이제곱분포라 하고, X ~ c2(r)로 나타낸다. ☞ 1) 확률밀도함수 X ~ c2(r) x(r/2)-1 e-x/2 , x > 0, r > 0 G(r/2) 2r/2 1 f(x) = 2) 평균 ☞ m = ab = • 2 = r r 2 3) 분산 s2 = ab2 = • 4 = 2r
 r 인. 카이제곱분포라 하고, X ~ c2(r)로 나타낸다. ☞ 1) 확률밀도함수. X ~ c2(r) x(r/2)-1 e-x/2 , x > 0, r > 0. G(r/2) 2r/2. 1. f(x) = 2) 평균. ☞ m = ab = • 2 = r. r. 2. 3) 분산. s2 = ab2 = • 4 = 2r.")
36
☞ 카이제곱분포의 백분위수 카이제곱분포의 100(1-a)% 백분위수 ca(r)
2 P(X ≤ x0 ) = 1 – a인 x0을 100(1-a)% 백분위수라 하고, ca(r)로 나타낸다. 2
 = 1 – a인 x0을 100(1-a)% 백분위수라 하고, ca(r)로 나타낸다. 2.")
37
에 대하여 P(X > c0.05 ) = 0.05를 만족하는 c0.05
X ~ ca(7) 2 에 대하여 P(X > c0.05 ) = 0.05를 만족하는 c0.05 d.f. = 7인 행과 a = 0.05인 열이 만나는 위치의 수 14.07 c0.05 = 14.07 2
 2. 에 대하여 P(X > c0.05 ) = 0.05를 만족하는 c0.05. d.f. = 7인 행과 a = 0.05인 열이 만나는 위치의 수 c0.05 =")
38
☞ 카이제곱분포의 성질 X ~ c2(5)에 대하여 P(X < x0) = 0.95 x0 = ?
P(X < x0) = 0.95이므로 P(X > x0) = 0.05 이고, 따라서 카이제곱표에서 d.f. = 5와 a = 0.05인 백분위수 x0 = c0.05 (5) = 11.07 2 ☞ 카이제곱분포의 성질 X ~ c2(r1), Y ~ c2(r2)이고 독립이면, X + Y ~ c2(r1 + r2)이다. X ~ c2(2), Y ~ c2(4) 이고 독립일 때, P(X + Y > x0) = x0 = ? X ~ c2(2), Y ~ c2(4) 이고 독립이므로 X + Y ~ c2(6)이다. 그러므로 x0 = c0.01 (6) = 16.81 2
 = 0.95이므로 P(X > x0) = 0.05 이고, 따라서 카이제곱표에서. d.f. = 5와 a = 0.05인 백분위수 x0 = c0.05 (5) = ☞ 카이제곱분포의 성질. X ~ c2(r1), Y ~ c2(r2)이고 독립이면, X + Y ~ c2(r1 + r2)이다. X ~ c2(2), Y ~ c2(4) 이고 독립일 때, P(X + Y > x0) = 0.01 x0 = X ~ c2(2), Y ~ c2(4) 이고 독립이므로 X + Y ~ c2(6)이다. 그러므로. x0 = c0.01 (6) =")
39
웨이블분포 (Weibull distribution)
4 웨이블분포 (Weibull distribution) 웨이블분포의 확률밀도함수와 평균, 분산에 대하여 알아본다.
 웨이블분포의 확률밀도함수와 평균, 분산에 대하여 알아본다.")
40
☞ 1) 확률밀도함수 의료사고 또는 폭풍 등으로 인한 재해에 대비하기 위한 재해보험에 대한 보험 급부금에 적합한 확률모형
X ~ Wei(a, b) f(x) = aba xa-1e-(bx) , x > 0 , a, b> 0 a
 f(x) = aba xa-1e-(bx) , x > 0 , a, b> 0. a.")
41
☞ ☞ ☞ 2) 분포함수 3) 생존함수 4) 실패율함수 F(x) = aba ua-1e-(bu) du
x F(x) = aba ua-1e-(bu) du = (-1) e-(bu) = 1 - e-(bx) , x > 0 a x a a ☞ 3) 생존함수 S(x) = 1 – F(x) = e-(bx) , x > 0 a ☞ 4) 실패율함수 f(x) S(x) aba xa-1e-(bx) a h(x) = = = aba xa-1 , x > 0 e-(bx) a
 = aba ua-1e-(bu) du. = (-1) e-(bu) = 1 - e-(bx) , x > 0. a. x. a. a. ☞ 3) 생존함수. S(x) = 1 – F(x) = e-(bx) , x > 0. a. ☞ 4) 실패율함수. f(x) S(x) aba xa-1e-(bx) a. h(x) = = = aba xa-1 , x > 0. e-(bx) a.")
42
X ~ Wei(2, 0.1)에 대하여 (1) X의 분포함수 = ? P(X ≤ 4) = ? (2) X의 생존함수 = ? P(X ≥ 10) = ? (3) X의 실패율함수 = ? (4) X의 중앙값 Me = ? (1) a = 2, b = 0.1이므로 F(x) = 1 – exp[-(x/10)2 ] , x > 0 P(X ≤ 4) = F(4) = 1 – exp[-(4/10)2 ]=
 X의 중앙값 Me = (1) a = 2, b = 0.1이므로 F(x) = 1 – exp[-(x/10)2 ] , x > 0. P(X ≤ 4) = F(4) = 1 – exp[-(4/10)2 ]=")
43
(2) S(x) = 1 - F(x) = exp[-(x/10)2 ], x > 0
P(X ≥ 10) = S(10) = exp[-(10/10)2 ] = (3) h(x) = abaxa = 2•(0.1)2 x2-1 = (0.02)x , x > 0 (4) F(x0) = 1 – exp[-(x0 /10)2 ] = ; exp[-(x0 /10)2 ] = ; -(x0 /10)2 = ln(0.5) = -ln 2 ; x0 /10 = ; x0 = Me = = a= 2, b = 0.1
![(2) S(x) = 1 - F(x) = exp[-(x/10)2 ], x > 0](http://slidesplayer.org/slide/15320392/92/images/43/%282%29+S%28x%29+%3D+1+-+F%28x%29+%3D+exp%5B-%28x%2F10%292+%5D%2C+x+%3E+0.jpg "P(X ≥ 10) = S(10) = exp[-(10/10)2 ] = (3) h(x) = abaxa-1 = 2•(0.1)2 x2-1 = (0.02)x , x > 0. (4) F(x0) = 1 – exp[-(x0 /10)2 ] = 0.5 ; exp[-(x0 /10)2 ] = 0.5 ; -(x0 /10)2 = ln(0.5) = -ln 2 ; x0 /10 = ; x0 = Me = 10 = a= 2, b = 0.1.")
44
☞ ☞ 2) 평균 3) 분산 m = E(X) = x f(x)dx = abaxae-(bx) dx a
∞ ∞ m = E(X) = x f(x)dx = abaxae-(bx) dx a u = (bx)a 1 b ∞ 1 b 1 a m = u [(1/a) +1]-1 e-u du = G 1 + ☞ 3) 분산 동일한 방법에 의하여 ∞ ∞ 1 2 a E(X2) = x2 f(x)dx = aba xa+1e-(bx) dx = G 1 + a b2 s2 = Var(X) = E(X2) – E(X)2 2 1 2 a 1 a = G 1 + - G 1 + b2
 = x f(x)dx = abaxae-(bx) dx. a. u = (bx)a. 1. b. ∞ 1. b. 1. a. m = u [(1/a) +1]-1 e-u du = G 1 + ☞ 3) 분산. 동일한 방법에 의하여. ∞ ∞ a. E(X2) = x2 f(x)dx = aba xa+1e-(bx) dx = G 1 + a. b2. s2 = Var(X) = E(X2) – E(X) a. 1. a. = G G 1 + b2.")
45
배우자가 재혼할 때까지 걸리는 시간 X ~ Wei(a, b) X의 실패율 함수 : h(x) = cx, x > 0
(1) P(X > 5) = e-1/4 = 을 만족하는 상수 c = ? (2) X의 밀도함수 = ? 배우자가 6개월 이내에 재혼할 확률 = ? (3) X의 평균 = ? X의 분산 = ? (1) 생존함수는 h(x) = aba xa-1 = cx , x > 0이므로 a = 2, aba = c ∞ 5 ∞ P(X > 5) = b2 xe-(bx) dx = - e-(bx) = e-25b = e-1/4 2 2 2 5 25 b2 = 1/4 b = 0.1, c = aba = 2•(0.1)2 = 0.02
 P(X > 5) = e-1/4 = 을 만족하는 상수 c = (2) X의 밀도함수 = 배우자가 6개월 이내에 재혼할 확률 = (3) X의 평균 = X의 분산 = (1) 생존함수는 h(x) = aba xa-1 = cx , x > 0이므로. a = 2, aba = c. ∞ 5. ∞ P(X > 5) = 2b2 xe-(bx) dx = - e-(bx) = e-25b = e-1/ b2 = 1/4. b = 0.1, c = aba = 2•(0.1)2 =")
46
(2) X의 밀도함수 : a = 2 , b = 0.1이므로 x2 f(x) = (0.02)x exp - , x > 0
100 6개월은 0.5년이므로 0.5 x2 100 P(X < 0.5) = (0.02)x exp dx = (-1) exp = = x2 100 0.5 (3) X의 평균 = ? X의 분산 = ? m = G = (10)• • G = = 1 2 0.1 p s2 = G(2) = 25(4 – p) = 1 100 p 4
 = (0.02)x exp - dx. = (-1) exp - = = x (3) X의 평균 = X의 분산 = m = G 1 + = (10)• • G = 5 = p. s2 = G(2) - = 25(4 – p) = p. 4.")
47
베타분포 (beta distribution)
5 베타분포 (beta distribution) 베타분포의 확률밀도함수와 평균, 분산에 대하여 알아본다.
 베타분포의 확률밀도함수와 평균, 분산에 대하여 알아본다.")
48
제조과정에서 불량품의 비율 또는 서비스에 만족하는 고객의 비율, 전체 보험증권의 한계 금액에 대한 손실비율 등과 같이 0%와 100% 사이에서 값을 가지는 비율에 대한 확률모형
1 베타함수 : Beta(a, b) = xa-1 (1 - x)b-1 dx , a, b > 0 1 1 Beta(a, b) xa-1 (1 - x)b-1 dx = 1 p.d.f. 조건을 만족 f(x) = xa-1 (1 - x)b-1 , 0 < x < 1 1 Beta(a, b) 확률밀도함수 :
 = xa-1 (1 - x)b-1 dx , a, b > 1. Beta(a, b) xa-1 (1 - x)b-1 dx = 1. p.d.f. 조건을 만족. f(x) = xa-1 (1 - x)b-1 , 0 < x < Beta(a, b) 확률밀도함수 :")
49
☞ ☞ 베타함수와 감마함수 1) 확률밀도함수 G(a)G(b) Beta(a, b) = G(a + b) X ~ Beta(a, b)
f(x) = xa-1 (1 – x)b-1 , 0 < x < 1, a, b > 0 G(a)G(b) G(a + b)
 = xa-1 (1 – x)b-1 , 0 < x < 1, a, b > 0. G(a)G(b) G(a + b)")
50
☞ 베타분포의 특성 (1) 동일한 모수 a에 대하여 b가 커지면 왼쪽으로 치우치고, 동일한 모수 b에 대하여 a가 커지면 오른쪽으로 치우친다. (2) a = b이면 x = 0.5를 중심으로 대칭이고, a와 b가 커질수록 종모양에 가까워지며 x = 0.5에 집중한다. (3) a = b = 1이면, 즉 X ∼ Beta (1, 1) ⇒ X ∼ U(0, 1) (4) X ∼ Beta (a, b) ⇒ 1-X ∼ Beta (b, a) 0.5
 a = b이면 x = 0.5를 중심으로 대칭이고, a와 b가 커질수록 종모양에 가까워지며 x = 0.5에 집중한다. (3) a = b = 1이면, 즉 X ∼ Beta (1, 1) ⇒ X ∼ U(0, 1) (4) X ∼ Beta (a, b) ⇒ 1-X ∼ Beta (b, a) 0.5.")
51
☞ ☞ 2) 평균 3) 분산 G(a)G(b) G(a + b)
1 1 G(a)G(b) G(a + b) m = E(X) = x f(x)dx = x(a+1)-1 (1 – x)b-1 dx G(a)G(b) G(a + b) G(a + 1)G(b) 1 G(a + b +1) = x(a+1)-1 (1 – x)b-1 dx G(a + b +1) G(a + 1)G(b) G(a)G(b) G(a + b) G(a + 1)G(b) G(a + b +1) = Beta(a + 1, b)인 p.d.f. G(a)G(b) G(a + b) aG(a)G(b) a a + b = = (a + b)G(a + b ) ☞ 3) 분산 동일한 방법에 의하여 s2 = Var(X) = E(X2) – E(X)2 ab (a+b+1) (a+b)2 = ab (a+b+1) (a+b) E(X2) =
G(b) G(a + b) m = E(X) = x f(x)dx = x(a+1)-1 (1 – x)b-1 dx. G(a)G(b) G(a + b) G(a + 1)G(b) 1. G(a + b +1) = x(a+1)-1 (1 – x)b-1 dx. G(a + b +1) G(a + 1)G(b) G(a)G(b) G(a + b) G(a + 1)G(b) G(a + b +1) = Beta(a + 1, b)인 p.d.f. G(a)G(b) G(a + b) aG(a)G(b) a. a + b. = = (a + b)G(a + b ) ☞ 3) 분산. 동일한 방법에 의하여. s2 = Var(X) = E(X2) – E(X)2. ab. (a+b+1) (a+b)2. = ab. (a+b+1) (a+b) E(X2) =")
52
전화 문의를 한 고객의 비율 : X ~ Beta(3, 4)에 대하여 (1) X의 밀도함수 = ?
(2) X의 평균 = ? X의 분산 = ? (3) 한 달 동안에 고객의 70%이상이 전화로 문의했을 확률 (1) a = 3, b = 4이므로 X의 밀도함수 : f(x) = x2 (1 – x)3 = 60 x2 (1 – x)3 , 0 < x < 1 G(3)G(4) G(7) (2) X의 평균 : X의 분산 : 3 7 3•4 72•8 m = = s2 = = (3) P(X ≥ 0.7) = x2 (1 – x)3 dx = 0.7 1
 X의 평균 = X의 분산 = (3) 한 달 동안에 고객의 70%이상이 전화로 문의했을 확률. (1) a = 3, b = 4이므로. X의 밀도함수 : f(x) = x2 (1 – x)3 = 60 x2 (1 – x)3 , 0 < x < 1. G(3)G(4) G(7) (2) X의 평균 : X의 분산 : •4. 72•8. m = = s2 = = (3) P(X ≥ 0.7) = 60 x2 (1 – x)3 dx = ")
53
정규분포 (normal distribution)
6 정규분포 (normal distribution) 정규분포, 표준정규분포의 확률밀도함수와 평균, 분산을 비롯한 특성과 중심극한정리, 이항분포의 정규근사 등에 대하여 알아본다.
 정규분포, 표준정규분포의 확률밀도함수와 평균, 분산을 비롯한 특성과 중심극한정리, 이항분포의 정규근사 등에 대하여 알아본다.")
54
☞ 1) 확률밀도함수 부록 A-4.2로부터 e-z /2 dz = 피적분함수가 우함수이므로 e-z /2 dz =
∞ 2 2 p 부록 A-4.2로부터 e-z /2 dz = 피적분함수가 우함수이므로 -∞ ∞ 2 e-z /2 dz = 2 p -∞ ∞ 1 2 e-z /2 dz = 1 x - m s z = p.d.f. 조건을 만족 -∞ < m < ∞, s > 0 ( x - m )2 2s2 -∞ ∞ 1 s exp dx = 1
2. 2s2. -∞ ∞ 1. s. exp - dx = 1.")
55
☞ ☞ 2) 평균 : 3) 분산 : 확률밀도함수 : X ~ N(m, s2) ( x - m )2
1 f(x) = , -∞ < x< ∞, -∞ < m< ∞, s > 0 exp - s 2s2 모수 m과 s2 인 정규분포 ☞ 2) 평균 : m = m ※ 평균 m이고, 분산 s2 임을 보이는 것은 생략한다. ☞ 3) 분산 : s2 = s2 m = 0과 s2 = 1인 경우 확률밀도함수 : Z ~ N(0, 1) 표준정규분포 f(z) = e –z /2 , -∞ < z< ∞ 2 1 p
 = , -∞ < x< ∞, -∞ < m< ∞, s > 0. exp - s. 2s2. 모수 m과 s2 인 정규분포. ☞ 2) 평균 : m = m. ※ 평균 m이고, 분산 s2 임을 보이는. 것은 생략한다. ☞ 3) 분산 : s2 = s2. m = 0과 s2 = 1인 경우. 확률밀도함수 : Z ~ N(0, 1) 표준정규분포. f(z) = e –z /2 , -∞ < z< ∞ p.")
56
☞ ☞ 정규확률함수의 성질 표준정규확률함수의 성질
(1) f(x)는 x=m에 관하여 좌우대칭이고, 따라서 X의 중앙값은 Me = m이다. (2) f(x)는 x=m에서 최대값을 가지고, 따라서 X의 최빈값은 Mo = m이다. (3) x= m-s, m+s에서 f(x)는 변곡점을 가지며, x= m-3s, m+3s에서 x-축에 거의 접하는 모양을 가지고 x→ -∞, x→ +∞이면 f(x)→ 0이다. ☞ 표준정규확률함수의 성질 (1) f(z)는 z=0에 관하여 좌우대칭이고, 따라서 Z의 중앙값은 Me = 0이다. (2) f(z)는 z=0에서 최대값을 가지고, 따라서 Z의 최빈값은 Mo = 0이다. (3) z=-1, 1에서 f(z)는 변곡점을 가지며, z=-3, 3에서 z-축에 거의 접하는 모양을 가지고 z→ -∞, z→ +∞이면 f(z)→ 0이다.
 f(x)는 x=m에 관하여 좌우대칭이고, 따라서 X의 중앙값은 Me = m이다. (2) f(x)는 x=m에서 최대값을 가지고, 따라서 X의 최빈값은 Mo = m이다. (3) x= m-s, m+s에서 f(x)는 변곡점을 가지며, x= m-3s, m+3s에서 x-축에 거의 접하는 모양을 가지고 x→ -∞, x→ +∞이면 f(x)→ 0이다. ☞ 표준정규확률함수의 성질. (1) f(z)는 z=0에 관하여 좌우대칭이고, 따라서 Z의 중앙값은 Me = 0이다. (2) f(z)는 z=0에서 최대값을 가지고, 따라서 Z의 최빈값은 Mo = 0이다. (3) z=-1, 1에서 f(z)는 변곡점을 가지며, z=-3, 3에서 z-축에 거의 접하는. 모양을 가지고 z→ -∞, z→ +∞이면 f(z)→ 0이다.")
57
모수 m는 분포의 중심을 나타내며, s는 흩어진 정도를 나타낸다.
Note m1≠ m2 s1 = s2 m1= m2 s1≠ s2

58
☞ 표준정규분포의 성질 (1) P(Z ≤ 0 ) = P(Z ≥ 0 ) = 0.5
(2) P(Z ≤ -z0 ) = P(Z ≥ z0 ) = 1- P(Z < z0), z0 > 0 (3) P(Z ≤ z0 ) = P(0 < Z < z0 ), P(Z ≥ z0) = P(0 < Z < z0), z0 > 0 (4) P(|Z|≤ z0 ) = P(-z0 < Z < z0 ) = 2P(0 < Z < z0), z0 > 0 P(Z < z0), z0 > 0
 P(Z ≤ -z0 ) = P(Z ≥ z0 ) = 1- P(Z < z0), z0 > 0. (3) P(Z ≤ z0 ) = P(0 < Z < z0 ), P(Z ≥ z0) = P(0 < Z < z0), z0 > 0. (4) P(|Z|≤ z0 ) = P(-z0 < Z < z0 ) = 2P(0 < Z < z0), z0 > 0. P(Z < z0), z0 > 0.")
59
(5) P(|Z|≤ 1.645 ) = 0.9, P(|Z|≤ 1.96 ) = 0.95, P(|Z|≤ 2.58 ) = 0.99
0.05 0.025 0.005
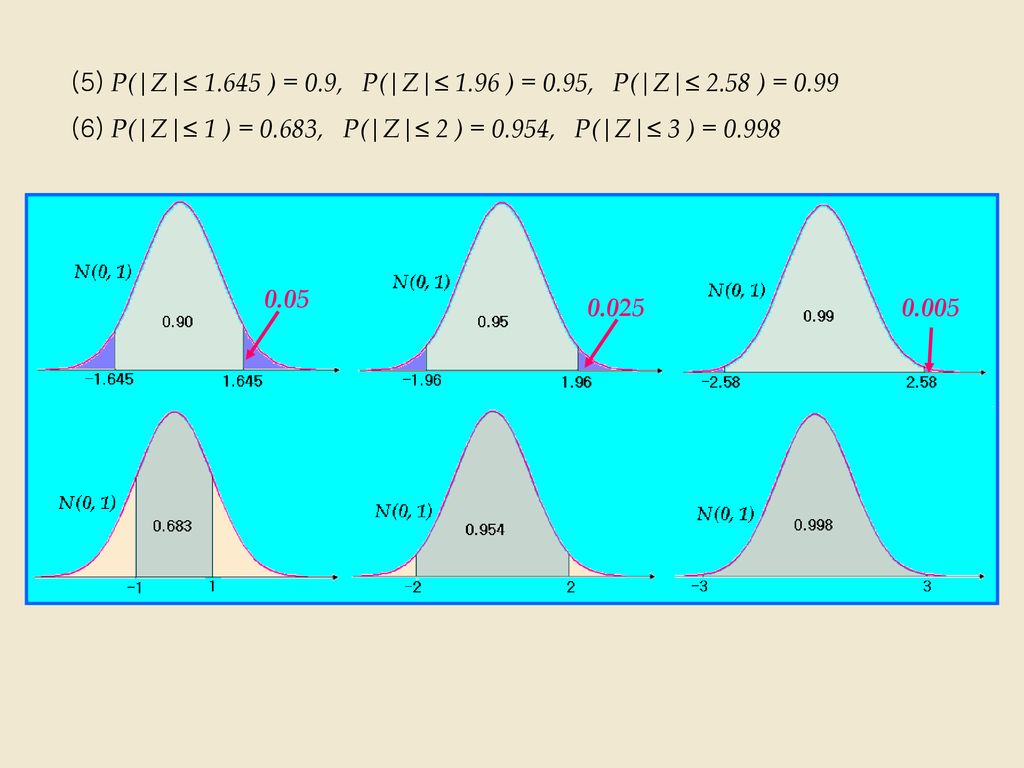
60
☞ 표준정규분포의 분포함수 F(z) = f(u)du
-∞ z F(z) = f(u)du (7) 1 - F(z0 ) = P(Z ≥ z0 ) = P(Z ≤ -z0 ) = F(-z0 ) , z0 > 0 X - m s Z = (8) X ~ N(m, s2) ~ N(0, 1) x0 - m s z0 = (9) P(X < x0) = P(Z < z0) = F(z0) ,
 = f(u)du. (7) 1 - F(z0 ) = P(Z ≥ z0 ) = P(Z ≤ -z0 ) = F(-z0 ) , z0 > 0. X - m. s. Z = (8) X ~ N(m, s2) ~ N(0, 1) x0 - m. s. z0 = (9) P(X < x0) = P(Z < z0) = F(z0) ,")
61
( ) ( ) ( ) ( ) (10) P(a < X < b) = F - F b - m s a - m
( ) ; P(a < X < b) = P a - m s b - m ( ) X - m < < = P < Z < ( ) = F F ( ) (11) P(m + as < X < m + bs) = P(a < Z < b) = F(b) – F(a) (12) P(m - s < X < m + s) = P(-1 < Z < 1) = 0.683 P(m - 2s < X < m + 2s) = P(-2 < Z < 2) = 0.954 P(m - 3s < X < m + 3s) = P(-3 < Z < 3) = 0.998
 ; P(a < X < b) = P. a - m. s. b - m. ( ) X - m. < < = P < Z < ( ) = F - F. ( ) (11) P(m + as < X < m + bs) = P(a < Z < b) = F(b) – F(a) (12) P(m - s < X < m + s) = P(-1 < Z < 1) = P(m - 2s < X < m + 2s) = P(-2 < Z < 2) = P(m - 3s < X < m + 3s) = P(-3 < Z < 3) =")
62
☞ 표준정규분포의 백분위수 표준정규분포의 100(1-a)% 백분위수 : za
P(Z ≤ z0 ) = 1 – a인 z0을 100(1-a)% 백분위수라 하고, za로 나타낸다.
 = 1 – a인 z0을 100(1-a)% 백분위수라 하고, za로 나타낸다.")
63
☞ 표준정규확률표 사용방법 P(Z ≤ 1.36) = ? Z < 1.36의 소숫점 이하 첫째 자리인 1.3을 z열에서 선택하고, 소숫점 이하 둘째 자리인 .06을 z행에서 선택하여 만나는 값 을 선택한다.

64
( ) ( ) 예 X ~ N(3, 4) (1) P(X ≤ 4.5) = F = F(0.75) = 0.7734 4.5 - 3 2
( ) 2 F(-0.75) = 1 - F(0.75) = 1 – = P(1.5 ≤ X ≤ 5.5) = F(1.25) - F(-0.75) = – = 2 ( ) (2) P(1.5 ≤ X ≤ 5.5) = F F = F(1.25) - F(-0.75)
 F(-0.75) = 1 - F(0.75) = 1 – = P(1.5 ≤ X ≤ 5.5) = F(1.25) - F(-0.75) = – = ( ) (2) P(1.5 ≤ X ≤ 5.5) = F - F = F(1.25) - F(-0.75)")
65
표준정규확률표를 이용하여 (1) P(0 < Z < 1.54) (2) P(-1.10 < Z < 1.10) (3) P(Z < -1.78) (4) P(Z > -1.23) (1) P(0 < Z < 1.54) = P(Z < 1.54) – 0.5 = – 0.5 = (2) P(-1.10 < Z < 1.10) = 2P(0 < Z < 1.10) = 2[P(Z < 1.10) – 0.5)] = 2( ) = (3) P(Z < -1.78) = P(Z > 1.78) = 1 - P(Z < 1.78) = 1 – = (4) P(Z > -1.23) = P(Z < 1.23) =
 P(0 < Z < 1.54) = P(Z < 1.54) – 0.5 = – 0.5 = (2) P(-1.10 < Z < 1.10) = 2P(0 < Z < 1.10) = 2[P(Z < 1.10) – 0.5)] = 2( ) = (3) P(Z < -1.78) = P(Z > 1.78) = 1 - P(Z < 1.78) = 1 – = (4) P(Z > -1.23) = P(Z < 1.23) =")
66
X ~ N(5, 4)에 대하여 (1) P(X < 6.4) (2) P(X < x0) = 인 x0 = ? (3) P(3 < X < x0) = 0.756인 x0 =? (1) m = 5, s = 2이므로 X를 표준화 하면 ( ) 2 P(X ≤ 6.4) = P Z < = F(0.70) = (2) X를 표준화 하면 ( ) x0 - 5 2 P(X < x0) = P Z < 표준정규확률표로부터 P(Z < 1.96) = x0 - 5 2 = ; x0 = 5 + 2•(1.96) = 8.92
 m = 5, s = 2이므로 X를 표준화 하면. ( ) P(X ≤ 6.4) = P Z < = F(0.70) = (2) X를 표준화 하면. ( ) x P(X < x0) = P Z < 표준정규확률표로부터. P(Z < 1.96) = x = 1.96 ; x0 = 5 + 2•(1.96) =")
67
( ) x0 - 5 2 3 - 5 2 X - 5 2 (3) P(3 < X < x0) = P < < ( ) x0 - 5 = P -1 < Z < 2 x0 - 5 ( ) = P Z < P(Z < -1) 2 한편, P(Z < -1) = P(Z > 1) = 1 – P( Z < 1) = 1 – = x0 - 5 2 ( ) P(3 < X < x0) = P Z < = 0.756 x0 - 5 2 ( ) P Z < = = 표준정규확률표로부터 P(Z < z0 ) = 에 대하여 약 z0 = 1.37 x0 - 5 2 = ; x0 = 5 + 2•(1.37) = 7.74
 x = P -1 < Z < 2. x ( ) = P Z < - P(Z < -1) 2. 한편, P(Z < -1) = P(Z > 1) = 1 – P( Z < 1) = 1 – = x ( ) P(3 < X < x0) = P Z < = x ( ) P Z < = = 표준정규확률표로부터 P(Z < z0 ) = 에 대하여 약 z0 = x = 1.37 ; x0 = 5 + 2•(1.37) =")
68
( ) ( ) 성인의 혈압은 평균 128.4, 표준편차 19.6인 정규분포
(1) 임의로 선정된 사람의 혈압이 100 이하일 확률 (2) 임의로 선정된 사람의 혈압이 134 이상일 확률 (3) 임의로 선정된 사람의 혈압이 110에서 130 사이일 확률 (1) X ~ N(128.4, 19.62)이므로 P(X ≤ 100) = P ≤ ( ) X – 128.4 19.6 100 – 128.4 (2) P(X ≥ 134) = P ≥ ( ) 134 – 128.4 = P(Z ≥ 0.29) = 1 – P(Z < 0.29) = 1 – = = P(Z ≤ -1.45) = 1 – P(Z ≤ 1.45) = 1 – =
 임의로 선정된 사람의 혈압이 100 이하일 확률. (2) 임의로 선정된 사람의 혈압이 134 이상일 확률. (3) 임의로 선정된 사람의 혈압이 110에서 130 사이일 확률. (1) X ~ N(128.4, 19.62)이므로. P(X ≤ 100) = P ≤ ( ) X – – (2) P(X ≥ 134) = P ≥ ( ) 134 – = P(Z ≥ 0.29) = 1 – P(Z < 0.29) = 1 – = = P(Z ≤ -1.45) = 1 – P(Z ≤ 1.45) = 1 – =")
69
(3) X ~ N(128.4, 19.62)이므로 = P(-0.94 ≤ Z ≤ 0.08) = P(Z ≤ 0.08) – P(Z < -0.94) = P(Z ≤ 0.08) – [1-P(Z < 0.94)] = – ( ) = P(110 ≤ X ≤ 130) = P ≤ ≤ ( ) X – 128.4 19.6 130 – 128.4 110 – 128.4
![(3) X ~ N(128.4, 19.62)이므로 = P(-0.94 ≤ Z ≤ 0.08) = P(Z ≤ 0.08) – P(Z < -0.94) = P(Z ≤ 0.08) – [1-P(Z < 0.94)]](http://slidesplayer.org/slide/15320392/92/images/69/%283%29+X+%7E+N%28128.4%2C+19.62%29%EC%9D%B4%EB%AF%80%EB%A1%9C+%3D+P%28-0.94+%E2%89%A4+Z+%E2%89%A4+0.08%29+%3D+P%28Z+%E2%89%A4+0.08%29+%E2%80%93+P%28Z+%3C+-0.94%29+%3D+P%28Z+%E2%89%A4+0.08%29+%E2%80%93+%5B1-P%28Z+%3C+0.94%29%5D.jpg "= – ( ) = P(110 ≤ X ≤ 130) = P ≤ ≤ ( ) X – – –")
70
☞ 정규분포의 성질 X ~ N(m1, s2) , Y ~ N(m2, s2) : 독립이면 (aX + b) - (am1 + b)
|a|s1 ~ N(0, 1) aX + b ~ N(am1 + b, a2 s2 ) X + Y ~ N(m1 + m2 , s2 + s2 ) X - Y ~ N(m1 - m2 , s2 + s2 ) (X + Y) –( m1 + m2 ) s2 + s2 - (1) (2) (3) (4) (5)
 aX + b ~ N(am1 + b, a2 s2 ) X + Y ~ N(m1 + m2 , s2 + s2 ) X - Y ~ N(m1 - m2 , s2 + s2 ) (X + Y) –( m1 + m2 ) s2 + s2. - (1) (2) (3) (4) (5)")
71
( ) ( ) 전자공학개론 교재의 무게 : X ~N(1.59, 0.582),
일반물리학 교재의 무게 : Y ~ N(2.18, 0.812) (1) 구입한 전자공학 개론 교재의 무게가 2.35(kg) 이하일 확률 (2) 구입한 두 교재의 전체 무게가 5.04(kg) 이상일 확률 (3) 일반물리학 교재와 전자공학개론 교재의 무게 차이가 0.35(kg) 이하일 확률 (1) X ~ N(1.59, 0.582)이므로 ( ) X – 1.59 0.58 2.35 – 1.59 0.58 P(X ≤ 2.35) = P ≤ = P(Z ≤ 1.31) = P(S ≥ 5.04) = P ≥ ( ) S – 3.77 0.9962 5.04 – 3.77 = P(Z ≥ 1.27) = 1 – P(Z < 1.27) = 1 – = 0.102 (2) S = X + Y ~ N(3.77, )이므로
 (1) 구입한 전자공학 개론 교재의 무게가 2.35(kg) 이하일 확률. (2) 구입한 두 교재의 전체 무게가 5.04(kg) 이상일 확률. (3) 일반물리학 교재와 전자공학개론 교재의 무게 차이가 0.35(kg) 이하일 확률. (1) X ~ N(1.59, 0.582)이므로. ( ) X – – P(X ≤ 2.35) = P ≤ = P(Z ≤ 1.31) = P(S ≥ 5.04) = P ≥ ( ) S – – = P(Z ≥ 1.27) = 1 – P(Z < 1.27) = 1 – = (2) S = X + Y ~ N(3.77, )이므로.")
72
(3) D = Y - X ~ N(0.59, )이므로 ( ) D – 0.59 0.35 – 0.59 P(D ≤ 0.35) = P ≤ 0.9962 0.9962 = P(Z ≤ -0.24) = 1 – P(Z < 0.24) = 1 – =
 = 1 – P(Z < 0.24) = 1 – =")
73
☞ 표본평균(sample mean) X1 , X2 , …, Xn : 독립 확률변수
Xi ~ N(mi , si ), i = 1, 2, …, n 2 Y = a1X1 + a2X2 + … + anXn ~ N(m , s2 ) , m = a1 m1 + a2 m2 + … + an mn , s2 = a1 s1 + a2 s2 + … + an sn ai = , i = 1, 2, …, n 1 n Y = (X1 + X2 + … + Xn ) ~ N(m , s2 ) , m = ( m1 + m2 + … + mn ) , s2 = (s1 + s2 + … + sn ) n2
, i = 1, 2, …, n. 2. Y = a1X1 + a2X2 + … + anXn ~ N(m , s2 ) , m = a1 m1 + a2 m2 + … + an mn. , s2 = a1 s1 + a2 s2 + … + an sn. ai = , i = 1, 2, …, n. 1. n. Y = (X1 + X2 + … + Xn ) ~ N(m , s2 ) , m = ( m1 + m2 + … + mn ) , s2 = (s1 + s2 + … + sn ) n2.")
74
( ) ( ) 표본평균(sample mean) : Xi ~ i.i.d. N(m , s2 ), i = 1, 2, …, n 1
( ) n s2 Y = (X1 + X2 + … + Xn ) ~ N m , 표본평균(sample mean) : 평균 m, 분산 s2인 i.i.d. 확률변수들 Xi , i = 1, 2, …, n 에 대하여 X = (X1 + X2 + … + Xn ) 1 n 을 표본평균이라 한다. Xi ~ i.i.d. N(m , s2), i = 1, 2, …, n 1 n ( ) n s2 X = (X1 + X2 + … + Xn ) ~ N m ,
 n. s2. Y = (X1 + X2 + … + Xn ) ~ N m , 표본평균(sample mean) : 평균 m, 분산 s2인 i.i.d. 확률변수들 Xi , i = 1, 2, …, n 에 대하여. X = (X1 + X2 + … + Xn ) 1. n. 을 표본평균이라 한다. Xi ~ i.i.d. N(m , s2), i = 1, 2, …, n. 1. n. ( ) n. s2. X = (X1 + X2 + … + Xn ) ~ N m ,")
75
( ) 정리 2 중심극한정리(central limit theorm)
평균 m, 분산 s2인 임의의 i.i.d. 확률변수들 Xi , i = 1, 2, …, n 에 대하여 n이 충분히 크다면, 표본평균 X는 평균 m, 분산 s2/n인 정규분포에 가까워진다. 즉, 다음이 성립한다. X = (X1 + X2 + … + Xn ) N m , 1 n s2 ( ) ~ X1 + X2 + … + Xn N( nm , ns2 ) ~ 평균 m, 분산 s2인 임의의 i.i.d. 확률변수들 Xi , i = 1, 2, …, n 에 대하여 n이 충분히 크다면, 중심극한정리로부터
 N m , 1. n. s2. ( ) ~ X1 + X2 + … + Xn N( nm , ns2 ) ~ 평균 m, 분산 s2인 임의의 i.i.d. 확률변수들 Xi , i = 1, 2, …, n 에 대하여 n이 충분히 크다면, 중심극한정리로부터.")
76
예 X1 , X2 ~ i.i.d. f(x)= 1/6, x=1, 2, 3, 4, 5, 6 의 확률분포 ?
X = (X1 + X2 ) 1 2 X1 , X2 의 결합분포
 X1 , X2 의 결합분포.")
77
의 확률분포 ? X = (X1 + X2 + X3 ) 1 3 의 확률분포 ? X = (X1 + X2 + X3 + X4 ) 1 4
 1 3 의 확률분포 X = (X1 + X2 + X3 + X4 ) 1 4")
79
( ) 각 증권 당 연간 보험금 지급액이 평균 19,400(만원), 표준편차 5,000(만원)
보험회사는 올해 1,000개의 자동차보험증권을 판매 (1) 전체 보험 지급액에 대한 근사확률분포 (2) 전체 보험 지급액이 19,800,000(만원)을 초과할 근사확률 (3) 가입한 증권에 대한 평균 보험 지급액에 대한 근사확률분포 (4) 평균이 19,600(만원)을 초과할 확률 (1) Xi , i = 1, 2, …, 1000 : 각 증권 당 연간 지급액 각 증권 당 연간 보험금 지급액이 평균 19,400이고 표준편차 5,000이므로 중심극한정리에 의하여 X = S Xi ~ N[(19.4)•106, (2.5)•1010 ] i=1 1000 ~ ( ) X – (19.4)•106 (2.5)•1010 (19.8)•106 – (19.4)•106 (2.5)•1010 (2) P[X ≥ (19.8)•106 ] = P ≥ = P(Z ≥ 2.53) = 1 – F(2.53) = 1 – = .
 전체 보험 지급액에 대한 근사확률분포. (2) 전체 보험 지급액이 19,800,000(만원)을 초과할 근사확률. (3) 가입한 증권에 대한 평균 보험 지급액에 대한 근사확률분포. (4) 평균이 19,600(만원)을 초과할 확률. (1) Xi , i = 1, 2, …, 1000 : 각 증권 당 연간 지급액. 각 증권 당 연간 보험금 지급액이 평균 19,400이고 표준편차 5,000이므로. 중심극한정리에 의하여. X = S Xi ~ N[(19.4)•106, (2.5)•1010 ] i= ~ ( ) X – (19.4)•106. (2.5)•1010. (19.8)•106 – (19.4)•106. (2.5)•1010. (2) P[X ≥ (19.8)•106 ] = P ≥ = P(Z ≥ 2.53) = 1 – F(2.53) = 1 – =")
80
( ) ( ) (3) 각 증권 당 연간 보험금 지급액이 평균 19,400이고 표준편차 5,000이므로
표본평균은 평균 19,400이고 분산 (5000)2/1000 = 인 정규분포에 근사함. X P(19400, 25000) ~ P(X ≥ 19600) = P ≥ X – 19400 2.5 100 19600 – 19400 ( ) = P Z ≥ = P(Z ≥ 1.266) ( ) . = 1 - P(Z < 1.266) = = (4) P(Z≤ 1.26) = , P(Z ≤ 1.27) = 편차 : P(Z ≤ 1.27) - P(Z≤ 1.26) = 편차를 10등분하여 6번째 값 을 이용 P(Z < 1.266) = =
2/1000 = 인 정규분포에 근사함. X P(19400, 25000) ~ P(X ≥ 19600) = P ≥ X – – ( ) = P Z ≥ = P(Z ≥ 1.266) ( ) . = 1 - P(Z < 1.266) = = (4) P(Z≤ 1.26) = , P(Z ≤ 1.27) = 편차 : P(Z ≤ 1.27) - P(Z≤ 1.26) = 편차를 10등분하여 6번째 값 을 이용. P(Z < 1.266) = =")
81
☞ 이항분포의 정규근사(normal approximation)
시행횟수 n이 커질수록 이항분포는 평균 m = np, 분산 s2 = np(1-p)인 정규분포에 가까워지며, 일반적으로 np ≥ 5, n(1-p) ≥ 5일 때 이항분포 B(n, p)와 정규분포 N(np, np(1-p))가 거의 일치한다. X N(np, np(1-p)) ~ X - np npq N(0, 1) 또는
인 정규분포에 가까워지며, 일반적으로 np ≥ 5, n(1-p) ≥ 5일 때 이항분포 B(n, p)와 정규분포 N(np, np(1-p))가 거의 일치한다. X N(np, np(1-p)) ~ X - np. npq. N(0, 1) 또는.")
82
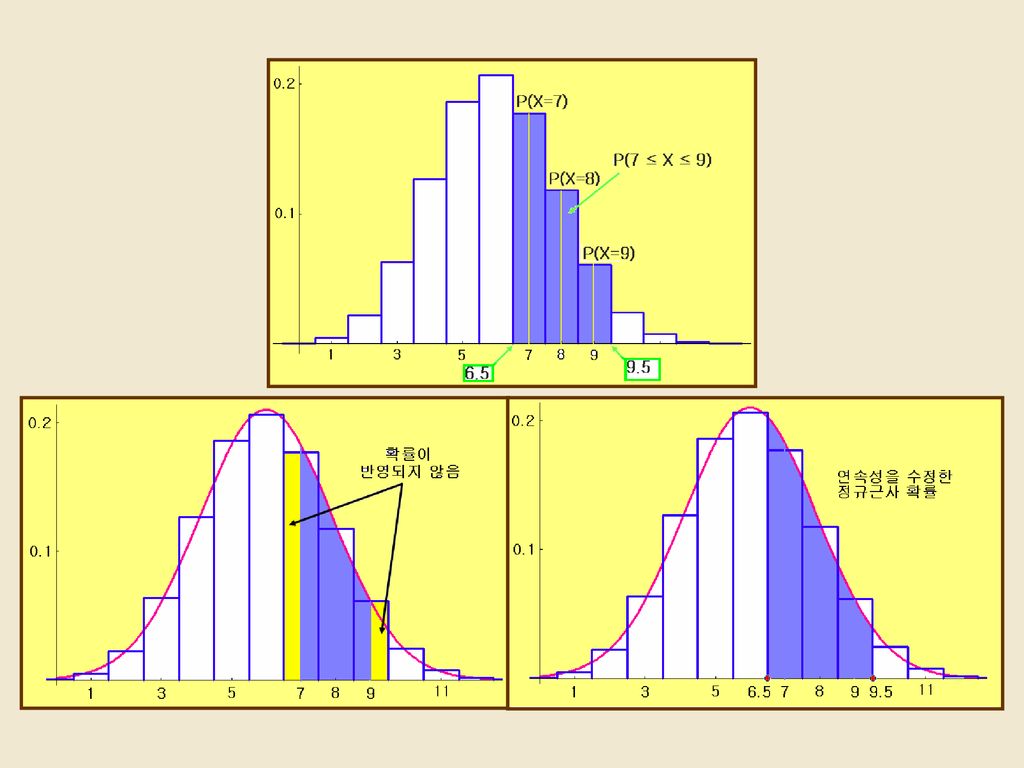
( ) ( ) X ~ B(15, 0.4)에 대하여 (1) 이항확률표에 의한 P(7 ≤ X ≤ 9) = ?
(1) P(7 ≤ X ≤ 9) = P(X ≤ 9) – P(X ≤ 6) = = (2) np = 6, npq = X N(6, 3.6) ~ ~ ( ) P(7 ≤ X ≤ 9) = P ≤ ≤ X - 6 3.6 9 - 6 7 - 6 = P(0.527 ≤ Z ≤ 1.581) = P(Z ≤ 1.581) - P(Z ≤ 0.527) = – = 0.241 . P(6.5 ≤ X ≤ 9.5) = P ≤ ≤ X - 6 3.6 ( ) = P(0.263 ≤ Z ≤ 1.845) = P(Z ≤ 1.845) - P(Z ≤ 0.263) = – = (3) .
 P(7 ≤ X ≤ 9) = P(X ≤ 9) – P(X ≤ 6) = = (2) np = 6, npq = 3.6 X N(6, 3.6) ~ ~ ( ) P(7 ≤ X ≤ 9) = P ≤ ≤ X = P(0.527 ≤ Z ≤ 1.581) = P(Z ≤ 1.581) - P(Z ≤ 0.527) = – = P(6.5 ≤ X ≤ 9.5) = P ≤ ≤ X ( ) = P(0.263 ≤ Z ≤ 1.845) = P(Z ≤ 1.845) - P(Z ≤ 0.263) = – = (3) .")
84
( ) ( ) 결 론 X ~ B(n, p), Z ~ N(0, 1)에 대하여 np ≥ 5, n(1-p) ≥ 5이면 .
결 론 X ~ B(n, p), Z ~ N(0, 1)에 대하여 np ≥ 5, n(1-p) ≥ 5이면 . P(a≤ X ≤ b) = F F b -np npq a -np ( ) F F ( ) b np a np ; 정규근사 ; 연속성 수정 정규근사
, Z ~ N(0, 1)에 대하여 np ≥ 5, n(1-p) ≥ 5이면. . P(a≤ X ≤ b) = F - F. b -np. npq. a -np. ( ) F - F. ( ) b np. a np. ; 정규근사. ; 연속성 수정 정규근사.")
85
( ) ( ) ( ) X ~ B(30, 0.2)에 대하여 (1) 확률질량함수를 이용한 P(X = 4) = ?
f(x) = (0.2)x (0.8)30-x , x = 0, 1, 2, …, 30 30 x ( ) P(X = 4) = f(4) = (0.2)4 (0.8)26 = 30 x ( ) P(X = 4) = P(3.5 ≤ X ≤ 4.5) ( ) = P ≤ ≤ X - 6 4.8 = F(-0.68) – F(-1.14) = – = . (2) np = 6, npq = X N(6, 4.8) ~
 = (0.2)x (0.8)30-x , x = 0, 1, 2, …, x. ( ) P(X = 4) = f(4) = (0.2)4 (0.8)26 = x. ( ) P(X = 4) = P(3.5 ≤ X ≤ 4.5) ( ) = P ≤ ≤ X = F(-0.68) – F(-1.14) = – = (2) np = 6, npq = 4.8 X N(6, 4.8) ~")
86
( ) ( ) ☞ 포아송분포의 정규근사 포아송분포의 평균 m가 충분히 커지면, 정규분포 N(m, m)에 가까워진다. X – m
~ m X N(m, m) ~ 또는 X ~ P(m), Z ~ N(0, 1)에 대하여 m가 충분히 커지면 . P(a≤ X ≤ b) = F F b - m a - m ( ) F F ( ) b m a m ; 정규근사 ; 연속성 수정 정규근사 m
 ~ 또는. X ~ P(m), Z ~ N(0, 1)에 대하여 m가 충분히 커지면. . P(a≤ X ≤ b) = F - F. b - m. a - m. ( ) F - F. ( ) b m. a m. ; 정규근사. ; 연속성 수정 정규근사. m.")
87
X ~ P(20)과 X ~ N(20, 20)의 비교 9,500명의 각 보험 종류별로 가입자 수와 가입 기간에 따른 보험금 청구 횟수 표 1년 동안 이들 보험에 가입한 2,000명 중에서 보험금을 청구한 가입자가 228명 이하일 근사확률 ? 단, 보험의 종류는 독립적이고, 보험금 청구 횟수 ~ 포아송 분포

88
( ) 각 보험 종류별로 보험금 청구 횟수의 연간 비율 : 0.0099, 0.0045, 0.080, 0185
보험종류 가입자 수 가입기간 보험금 청구횟수 화재보험 1,520 1 15 건강보험 2,355 4 42 자동차보험 4,325 345 여행자보험 1,300 0.5 12 각 보험 종류별로 보험금 청구 횟수의 연간 비율 : , , 0.080, 0185 전체 9,500개의 보험증권 중에 대한 보험금 청구비율 : 가입자 2,000명에 대한 기대 청구 횟수 : 2000•(0.1129) = 226 보험금 청구 횟수 : X ~ P(226) X N(226, 226) ~ P(X ≤ 228) = F = F(0.166) = 226 ( )
 = 226. 보험금 청구 횟수 : X ~ P(226) X N(226, 226) ~ P(X ≤ 228) = F = F(0.166) = ( )")
89
7 정규분포에 관련된 연속분포들 로그정규분포, t –분포, F-분포, 이변량정규분포의 확률밀도함수와 평균, 분산을 비롯한 특성에 대하여 알아본다.

90
로그정규분포 투자에 대한 환원 또는 보험 청구금액과 같이 대칭성을 갖지도 않으며 또한 양의 왜도를 가지는 확률모형에 사용되는 확률분포 Y ~ N(m, s2) fY(y) = , -∞ < y< ∞ exp - ( y - m )2 2s2 Y의 밀도함수 : 1 s X = eY fX (x)= , -∞ < x< ∞ exp - ( lnx - m )2 2s2 X의 밀도함수 : 1 sx
 = , -∞ < y< ∞ exp - ( y - m )2. 2s2. Y의 밀도함수 : 1. s. X = eY. fX (x)= , -∞ < x< ∞ exp - ( lnx - m )2. 2s2. X의 밀도함수 : 1. sx.")
91
☞ 1) 확률밀도함수 X ~ LogN (m, s2) ( lnx - m )2
f(x) = , -∞ < x< ∞, -∞ < m< ∞, s > 0 1 exp - sx 2s2 모수에 따른 로그정규분포함수의 개형
 = , -∞ < x< ∞, -∞ < m< ∞, s > exp - sx. 2s2. 모수에 따른 로그정규분포함수의 개형.")
92
☞ ☞ ☞ ☞ ( ) ( ) ( ) 2) 분포함수 3) 평균 4) 분산 5) 100(1-a)% 백분위수 su F(x) =
exp - (ln u – m)2 2s2 du = F , x > 0 ln x – m s ( ) x ☞ mX = exp m + s2 2 ( ) 3) 평균 ☞ 4) 분산 sX = (es - 1) exp(2m + s2) 2 ☞ 5) 100(1-a)% 백분위수 lnxa - m s ( ) F(xa) = F = 1- a ; = za ; xa = exp(m + s za)
2. 2s2. du = F , x > 0. ln x – m. s. ( ) x. ☞ mX = exp m + s2. 2. ( ) 3) 평균. ☞ 4) 분산. sX = (es - 1) exp(2m + s2) 2. ☞ 5) 100(1-a)% 백분위수. lnxa - m. s. ( ) F(xa) = F. = 1- a ; = za ; xa = exp(m + s za)")
93
( ) ( ) 지급 요구된 보험금 : X ~ LogN(6.95, 0.64)
(1) 보험가입자에 의하여 요구된 보험금의 평균과 표준편차 (2) 신청 금액이 1,750(만원) 이상일 확률 ( ) s2 2 (1) mX = exp m + = (만원) m=6.95 s2 = 0.64 sX = (es - 1) exp(2m + s2) 2 m=6.95 s2 = 0.64 = ( )•( ) = (만원) P(X ≥ 1750) = 1 – F(1750) = 1 - F = 1- F(0.65) = 1 – = (ln 1750) – 6.95 0.8 ( ) (2)
 보험가입자에 의하여 요구된 보험금의 평균과 표준편차. (2) 신청 금액이 1,750(만원) 이상일 확률. ( ) s2. 2. (1) mX = exp m + = (만원) m=6.95. s2 = sX = (es - 1) exp(2m + s2) 2. m=6.95. s2 = = ( )•( ) = (만원) P(X ≥ 1750) = 1 – F(1750) = 1 - F. = 1- F(0.65) = 1 – = (ln 1750) – ( ) (2)")
94
☞ ☞ ☞ ( ) 카이제곱분포 1) 평균 2) 분산 3) 카이제곱분포의 성질
Zi ~ N(0, 1), i = 1, 2, …, n : 독립 V = Z1 + Z2 + … + Zn ~ c2(n) 2 ☞ 1) 평균 mV = n ☞ s2 = 2n V 2) 분산 ☞ 3) 카이제곱분포의 성질 (3) Vi ~ c2(ri ), i = 1, 2, …, n : 독립이면, V1 +V2 +…+Vn ~ c2(r1 +…+ rn ) (1) X ~ N(m, s2)이면 ~ c2(n), 즉 Z ~ N(0, 1)이면 Z2 ~ c2(1) X - m s ( ) 2 (2) Xi ~ N(mi , s2), i = 1, 2, …, n : 독립이면 S ~ c2(n) i Xi - mi si i = 1 n
, i = 1, 2, …, n : 독립. V = Z1 + Z2 + … + Zn ~ c2(n) 2. ☞ 1) 평균. mV = n. ☞ s2 = 2n. V. 2) 분산. ☞ 3) 카이제곱분포의 성질. (3) Vi ~ c2(ri ), i = 1, 2, …, n : 독립이면, V1 +V2 +…+Vn ~ c2(r1 +…+ rn ) (1) X ~ N(m, s2)이면 ~ c2(n), 즉 Z ~ N(0, 1)이면 Z2 ~ c2(1) X - m. s. ( ) 2. (2) Xi ~ N(mi , s2), i = 1, 2, …, n : 독립이면 S ~ c2(n) i. Xi - mi. si. i = 1. n.")
95
t – 분포(t-distribution)
V/r Z Z ~ N(0, 1), V ~ c2(r) : 독립 T = 의 확률분포를 자유도 r인 t-분포라 하고, T ~ t(r)로 나타낸다. ☞ 1) 확률밀도함수 f(t) = r G(1/2) G(r/2) G((r + 1)/2) t2 1 + ( ) -(r + 1)/2 , t > 0 ☞ 2) 평균 m = 0 ☞ r r - 2 3) 분산 s2 = , r > 2
, V ~ c2(r) : 독립. T = 의 확률분포를 자유도 r인. t-분포라 하고, T ~ t(r)로. 나타낸다. ☞ 1) 확률밀도함수. f(t) = r. G(1/2) G(r/2) G((r + 1)/2) t ( ) -(r + 1)/2. , t > 0. ☞ 2) 평균. m = 0. ☞ r. r ) 분산. s2 = , r > 2.")
96
☞ t – 분포와 표준정규분포 (1) 표준정규분포와 동일하게 종 모양을 이룬다.
(3) 자유도 r 이 증가하면 표준정규분포에 근사한다.
 자유도 r 이 증가하면 표준정규분포에 근사한다.")
97
☞ ☞ 4) 100(1-a)% 백분위수 : ta(r) 5) t – 분포의 성질
P(T > t0) = 1- a ; t0 = ta(r) ☞ 5) t – 분포의 성질 (1) P(T > ta(r)) = P(T < -ta(r)) = a (2) P(|T| < ta/2(r)) = 1 - a
 = 1- a ; t0 = ta(r) ☞ 5) t – 분포의 성질. (1) P(T > ta(r)) = P(T < -ta(r)) = a. (2) P(|T| < ta/2(r)) = 1 - a.")
98
P(T > t0.025(4)) = 0.025인 임계점 t0.025(4)를 구하는 방법 :
d.f. = 4와 a = .025가 만나는 위치의 수 2.776을 선택한다. 즉 t0.025(4) = 2.776, P(T > 2.776) = 0.025
 = 2.776, P(T > 2.776) =")
99
T ~ t(3)에 대하여 (1) P(T > t0.025) = t0.025 = ? (2) P(|T| < t0) = t0 = ? (1) d.f. = 3이고 a = 0.025이므로 t0.025 = 3.182 (2) P(|T| < t0) = P(-t0 < T < t0) = 0.99이므로 P(|T| ≥ t0) = 0.01 P(T ≤ -t0) = P(T ≥ t0) = 0.005 t0 = t0.005(3) = 5.841
 d.f. = 3이고 a = 0.025이므로 t0.025 = (2) P(|T| < t0) = P(-t0 < T < t0) = 0.99이므로 P(|T| ≥ t0) = P(T ≤ -t0) = P(T ≥ t0) = t0 = t0.005(3) =")
100
F – 분포(F-distribution)
U ~ c2(m) , V ~ c2(n) : 독립 F = 의 확률분포를 분자•분모의자유도 (m, n)인 F-분포라 하고, F ~ F(m, n)으로 나타낸다. U/m V/n ☞ 1) 확률밀도함수 f(x) = G(m/2) G(n/2) G((m + n)/2) ( ) , x > 0 m n m/2 x(m/2) - 1 1 + ( ) -(m + n) /2 x ☞ m = n n - 2 , n ≥ 3 2) 평균 s2 = , n ≥ 5 m(n - 2)2(n - 4) 2n2(m + n - 2) ☞ 3) 분산
 , V ~ c2(n) : 독립. F = 의 확률분포를 분자•분모의자유도 (m, n)인 F-분포라 하고, F ~ F(m, n)으로 나타낸다. U/m. V/n. ☞ 1) 확률밀도함수. f(x) = G(m/2) G(n/2) G((m + n)/2) ( ) , x > 0. m. n. m/2. x(m/2) ( ) -(m + n) /2. x. ☞ m = n. n - 2. , n ≥ 3. 2) 평균. s2 = , n ≥ 5. m(n - 2)2(n - 4) 2n2(m + n - 2) ☞ 3) 분산.")
101
☞ F – 분포의 성질 (1) 분모의 자유도가 커질수록 m = 1, s2 = 2/m
(2) 일반적으로 왼쪽으로 치우친 모양을 나타낸다. (3) 자유도 m, n 이 증가하면 분포의 중심이 m = 1을 중심으로 대칭인 정규분포 곡선에 근사한다. .
 일반적으로 왼쪽으로 치우친 모양을 나타낸다. (3) 자유도 m, n 이 증가하면 분포의 중심이 m = 1을 중심으로 대칭인 정규분포 곡선에 근사한다. .")
102
☞ ☞ 4) 100(1-a)% 백분위수 fa(m, n) 5) F – 분포의 성질
P(F > f0) = 1- a ; f0 = fa(m, n)) ☞ 5) F – 분포의 성질 (1) P(F > fa(m, n)) = a (2) P(f1-a/2(m, n)) < F < fa/2(m, n)) = 1 – a (3) F ~ F(m, n)이면 1/F ~ F(n, m) f1-a(m, n) = 1/fa(n, m)
 = 1- a ; f0 = fa(m, n)) ☞ 5) F – 분포의 성질. (1) P(F > fa(m, n)) = a. (2) P(f1-a/2(m, n)) < F < fa/2(m, n)) = 1 – a. (3) F ~ F(m, n)이면 1/F ~ F(n, m) f1-a(m, n) = 1/fa(n, m)")
103
F ~ F(5, 4)에서 P(F > f0.05(5, 4)) = 0.05인 임계점 f0.05(5, 4)를 구하는 방법 :
분모의 자유도 4의 a = 0.05인 행과 분자의 자유도 5인 열이 만나는 위치의 수 6.26을 선택한다. 즉, f0.05(5, 4) = 6.26, P(F > 6.26) = 0.05
 = 6.26, P(F > 6.26) =")
104
F ~ F(4, 5)에 대하여 (1) P(F > f0.025) = 0.025인 f0.025 = ? (2) f0.95(4, 5) = ? (1) F-분포표로부터 f0.025 = 7.39 (2) f0.95(4, 5) = = = f0.05(5, 4) 1 6.26 1
 f0.95(4, 5) = = = f0.05(5, 4)")
105
이변량정규분포(bivariate normal distribution)
상수 sX > 0, sY > 0, -∞ < mX , mY < ∞, -1 < r < 1에 대하여 Q = 1 – r2 1 ( ) x - mX sX 2 y - mY sY -2r + [ ] ☞ 1) 결합확률밀도함수 (X, Y ) ~ N(mX, mY, sX, sY, r) 2 2 f(x, y) = 1 - r2 2p sX sY 1 e-Q/2 , ∞ < x, y < ∞ 여기서, r = Corr(X, Y )
 x - mX. sX. 2. y - mY. sY. -2r. + [ ] ☞ 1) 결합확률밀도함수. (X, Y ) ~ N(mX, mY, sX, sY, r) f(x, y) = 1 - r2. 2p sX sY. 1. e-Q/2 , -∞ < x, y < ∞ 여기서, r = Corr(X, Y )")
106
[ ] X와 Y가 독립인 경우 : f(x, y) = 2p sX sY 1 , -∞ < x, y < ∞ exp
(x – mX )2 2sX (y – mY )2 2sY 2 - [ ] mX =0, mY = 0, sX =1, sY =1, r =0
![[ ] X와 Y가 독립인 경우 : f(x, y) = 2p sX sY 1 , -∞ < x, y < ∞ exp](http://slidesplayer.org/slide/15320392/92/images/106/%5B+%5D+X%EC%99%80+Y%EA%B0%80+%EB%8F%85%EB%A6%BD%EC%9D%B8+%EA%B2%BD%EC%9A%B0+%3A+f%28x%2C+y%29+%3D+2p+sX+sY+1+%2C+-%E2%88%9E+%3C+x%2C+y+%3C+%E2%88%9E+exp.jpg "(x – mX )2. 2sX. (y – mY )2. 2sY [ ] mX =0, mY = 0, sX =1, sY =1, r =0.")
107
☞ 이변량정규분포의 성질 (1) r > 0이면, X와 Y가 양의 상관관계에 있으므로 X와 Y의 결합밀도함수는 직선 y = x에 근접하는 영역에 집중된다. (2) r < 0이면, X와 Y가 음의 상관관계에 있으므로 X와 Y의 결합밀도함수는 직선 y = -x에 근접하는 영역에 집중된다. mX =0, mY = 0, sX =1, sY =1, r =0.8 mX =0, mY = 0, sX =1, sY =1, r = -0.8
 r < 0이면, X와 Y가 음의 상관관계에 있으므로 X와 Y의 결합밀도함수는 직선 y = -x에 근접하는 영역에 집중된다. mX =0, mY = 0, sX =1, sY =1, r =0.8. mX =0, mY = 0, sX =1, sY =1, r =")
108
☞ ( ) ☞ ( ) 2) 주변확률밀도함수 3) 조건부 확률밀도함수 fX(x) = 1 , -∞ < x < ∞ exp
sX 2p (x – mX )2 2sX 2 ( ) - ~ N(mX, sX ) fY(y) = , -∞ < y < ∞ sY (y – mY )2 2sY ~ N(mY, sY ) ☞ 3) 조건부 확률밀도함수 , -∞ < x < ∞ exp f(x|y) = = fY(y) f(x, y) 1 - r2 sX 2p 1 ( ) (x – bX )2 2sX (1 – r2) 2 - , -∞ < y < ∞ f(y|x) = = fX(x) 1 -r2 sY (y – bY )2 2sY (1 – r2) bX = mX + r (y – mY) sX sY bY = mY + r (x – mX) sY sX
2. 2sX. 2. ( ) - ~ N(mX, sX ) fY(y) = , -∞ < y < ∞ sY. (y – mY )2. 2sY. ~ N(mY, sY ) ☞ 3) 조건부 확률밀도함수. , -∞ < x < ∞ exp. f(x|y) = = fY(y) f(x, y) 1 - r2. sX. 2p. 1. ( ) (x – bX )2. 2sX (1 – r2) 2. - , -∞ < y < ∞ f(y|x) = = fX(x) 1 -r2. sY. (y – bY )2. 2sY (1 – r2) bX = mX + r (y – mY) sX. sY. bY = mY + r (x – mX) sY. sX.")
109
☞ ☞ 4) 조건부 평균 5) 조건부 분산 sX E(X|Y=y) = mX + r (y – mY) sY sY
E(Y|X=x) = mY + r (x – mX) sY sX ☞ 5) 조건부 분산 Var(X|Y=y) = sX (1 – r2) 2 Var(Y|X=x) = sY (1 – r2)
 = mY + r (x – mX) sY. sX. ☞ 5) 조건부 분산. Var(X|Y=y) = sX (1 – r2) 2. Var(Y|X=x) = sY (1 – r2)")
110
( ) 신혼부부를 대상으로 한 모집단에서 남편의 키(X)와 아내의 키(Y)
(X, Y ) ~ N(176, 160, 1.0, 1.52, 0.6) (1) 남편의 키가 173cm일 때, Y의 조건부 확률분포 (2) P(154 < Y < 158|X = 173) = ? (1) (X, Y ) ~ N(176, 160, 1.0, 1.52, 0.6) 이므로 E(Y|X=173) = mY + r (x – mX) sY sX = (0.6)•(1.5)•(173 – 176) = 157.3 Y의 조건부 평균 : Y의 조건부 분산 : Var(Y|X=173) = sY (1 – r2) = (2.25)•(0.64) = 1.44 2 Y의 조건부 확률분포 : Y|X=173 ~ N(157.3, 1.44) ( ) 154 – 157.3 1.2 158 – 157.3 1.2 (2) P(154 < Y < 158|X = 173) = P < Z < = P(-2.75 < Z< 0.58) = F(0.58) – F(-2.75) = =
 ~ N(176, 160, 1.0, 1.52, 0.6) (1) 남편의 키가 173cm일 때, Y의 조건부 확률분포. (2) P(154 < Y < 158|X = 173) = (1) (X, Y ) ~ N(176, 160, 1.0, 1.52, 0.6) 이므로. E(Y|X=173) = mY + r (x – mX) sY. sX. = (0.6)•(1.5)•(173 – 176) = Y의 조건부 평균 : Y의 조건부 분산 : Var(Y|X=173) = sY (1 – r2) = (2.25)•(0.64) = Y의 조건부 확률분포 : Y|X=173 ~ N(157.3, 1.44) ( ) 154 – – (2) P(154 < Y < 158|X = 173) = P < Z < = P(-2.75 < Z< 0.58) = F(0.58) – F(-2.75) = =")
111
제 5 장


 통계량 (statistic) 표본자료의 함수 즉 모집단 … … 표본 표본추출 … … 통계량 계산.>")










>")
>")

. 고장률은 확률이 아니며 따라서 1 보다 커도 상관없다. 고장이 발생하기 쉬운 정도를 표시하는 척도. 일반으로 고장률은 순간고장률과 평균고장률을 사용하고 있지만.>")


>")

