Download presentation
Presentation is loading. Please wait.

1
제13장 로지스틱회귀분석

2
로지스틱회귀분석 로지스틱회귀분석(logistic regression)
독립변수의 선형결합을 이용하여 사건의 발생가능성(발생확률)을 예측하는데 사용되는 통계기법 독립변수의 선형결합으로 종속변수를 설명한다는 관점에서는 회귀분석, 판별분석과 유사함 종속변수는 명목척도로서 binary data이어야 함 <참고> 종속변수 독립변수 분산분석 간격/비율척도 명목척도 회귀분석 간격/비율척도 명목/서열/간격/비율척도 판별분석 명목척도 명목/서열/간격/비율척도 로지스틱회귀분석 명목척도 (binary) 명목/서열/간격/비율척도
을. 예측하는데 사용되는 통계기법. 독립변수의 선형결합으로 종속변수를 설명한다는 관점에서는. 회귀분석, 판별분석과 유사함. 종속변수는 명목척도로서 binary data이어야 함. <참고> 종속변수. 독립변수. 분산분석. 간격/비율척도. 명목척도. 회귀분석. 간격/비율척도. 명목/서열/간격/비율척도. 판별분석. 명목척도. 명목/서열/간격/비율척도. 로지스틱회귀분석. 명목척도. (binary) 명목/서열/간격/비율척도.")
3
공리적 확률(axiomatic probability)
사건 의 확률 이 다음의 3가지 공리를 만족하면 를 공리적 확률이라 함 ? 1. [질문] 2. ? 3. 여기서 는 표본공간 는 의 여사건 현대통계학에서 확률이라 함은 공리적 확률을 의미함 (참조) 공리적 확률은 A. N. Kolmogorov가 제시
 공리적 확률은 A. N. Kolmogorov가 제시.")
4
로지스틱회귀분석모형 p개의 독립변수로 사건 E가 발생할 확률을 예측하기 위한 모형 : 사건 E가 발생할 확률 : 독립변수의 선형결합 [질문] 사건 E가 발생하지 않을 확률
![로지스틱회귀분석모형 p개의 독립변수로 사건 E가 발생할 확률을 예측하기 위한 모형 : 사건 E가 발생할 확률 : 독립변수의 선형결합 [질문] 사건 E가 발생하지 않을 확률](http://slidesplayer.org/slide/11221059/60/images/4/%EB%A1%9C%EC%A7%80%EC%8A%A4%ED%8B%B1%ED%9A%8C%EA%B7%80%EB%B6%84%EC%84%9D%EB%AA%A8%ED%98%95+p%EA%B0%9C%EC%9D%98+%EB%8F%85%EB%A6%BD%EB%B3%80%EC%88%98%EB%A1%9C+%EC%82%AC%EA%B1%B4+E%EA%B0%80+%EB%B0%9C%EC%83%9D%ED%95%A0+%ED%99%95%EB%A5%A0%EC%9D%84+%EC%98%88%EC%B8%A1%ED%95%98%EA%B8%B0+%EC%9C%84%ED%95%9C+%EB%AA%A8%ED%98%95+%3A+%EC%82%AC%EA%B1%B4+E%EA%B0%80+%EB%B0%9C%EC%83%9D%ED%95%A0+%ED%99%95%EB%A5%A0+%3A+%EB%8F%85%EB%A6%BD%EB%B3%80%EC%88%98%EC%9D%98+%EC%84%A0%ED%98%95%EA%B2%B0%ED%95%A9+%5B%EC%A7%88%EB%AC%B8%5D+%EC%82%AC%EA%B1%B4+E%EA%B0%80+%EB%B0%9C%EC%83%9D%ED%95%98%EC%A7%80+%EC%95%8A%EC%9D%84+%ED%99%95%EB%A5%A0.jpg "로지스틱회귀분석모형 p개의 독립변수로 사건 E가 발생할 확률을 예측하기 위한 모형 : 사건 E가 발생할 확률 : 독립변수의 선형결합 [질문] 사건 E가 발생하지 않을 확률")
5
사건E의 발생확률과 독립변수 선형결합간의 관계
S자형 곡선 모형의 추정방법 최우추정법

6
승산비(odd ratio) 사건이 발생할 확률과 사건이 발생하지 않을 확률의 비율 로지스틱회귀분석모형으로부터 양변에 자연로그(ln)를 취하면
 사건이 발생할 확률과 사건이 발생하지 않을 확률의 비율 로지스틱회귀분석모형으로부터 양변에 자연로그(ln)를 취하면")
7
모형의 적합성 검토 적중률 분석 우도값 분석(likelihood value)
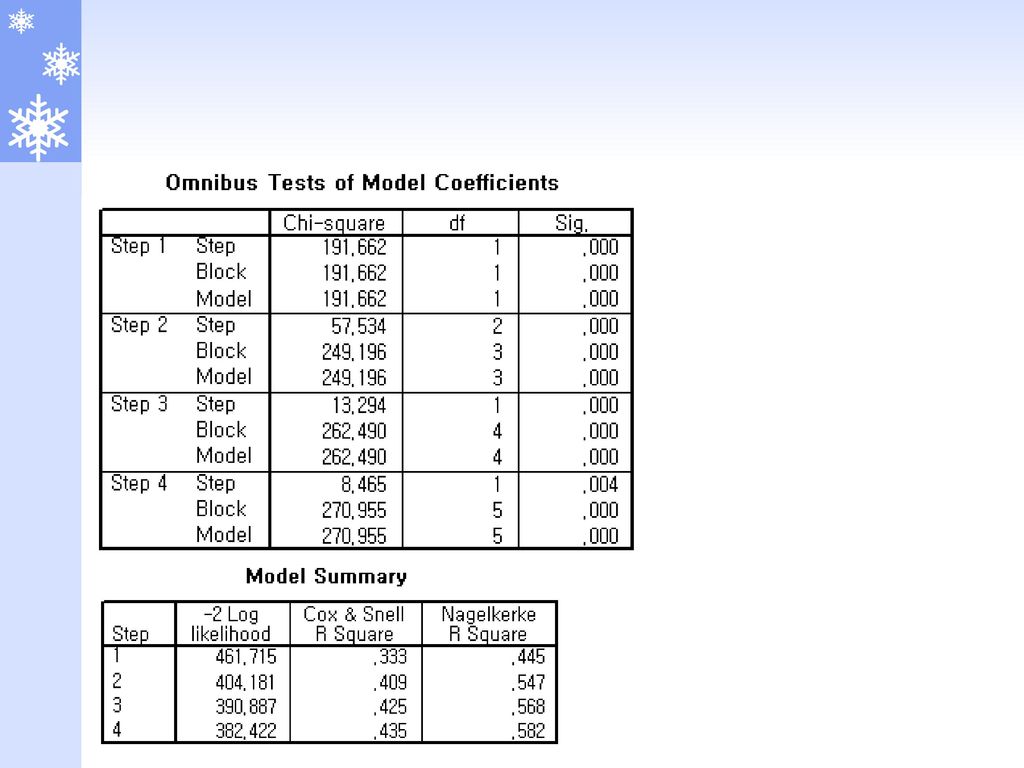
적합성 통계(goodness-of-fit statistic) 모형카이제곱(model chi-square) 개선도(improvement)
 모형카이제곱(model chi-square) 개선도(improvement)")
8
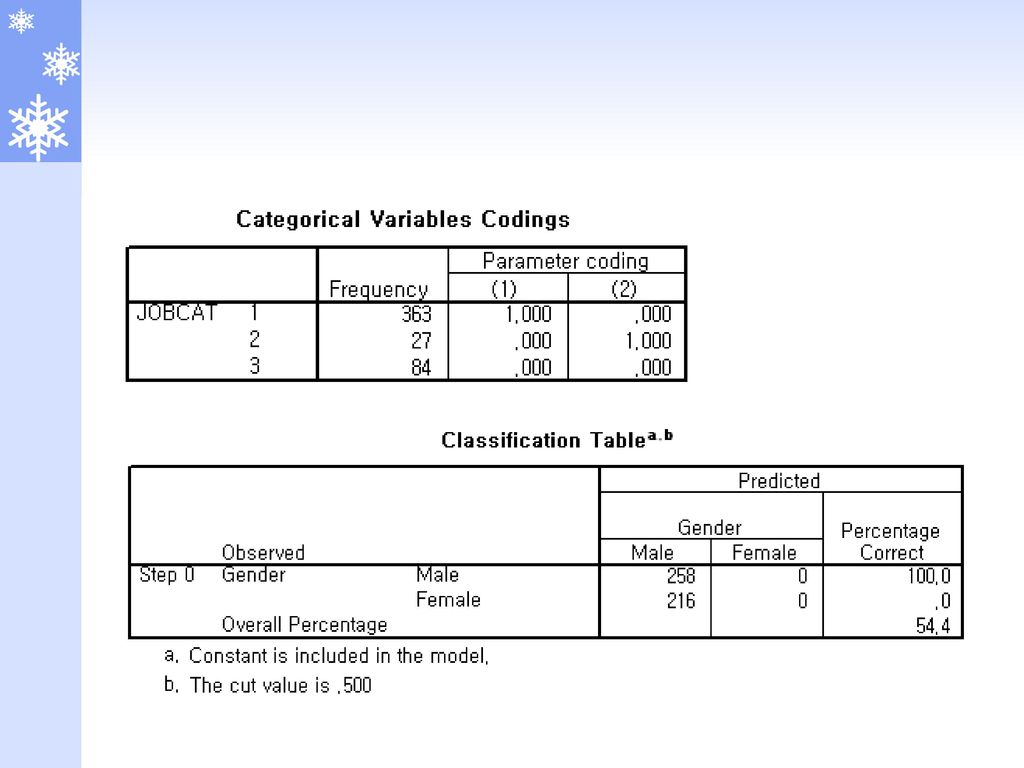
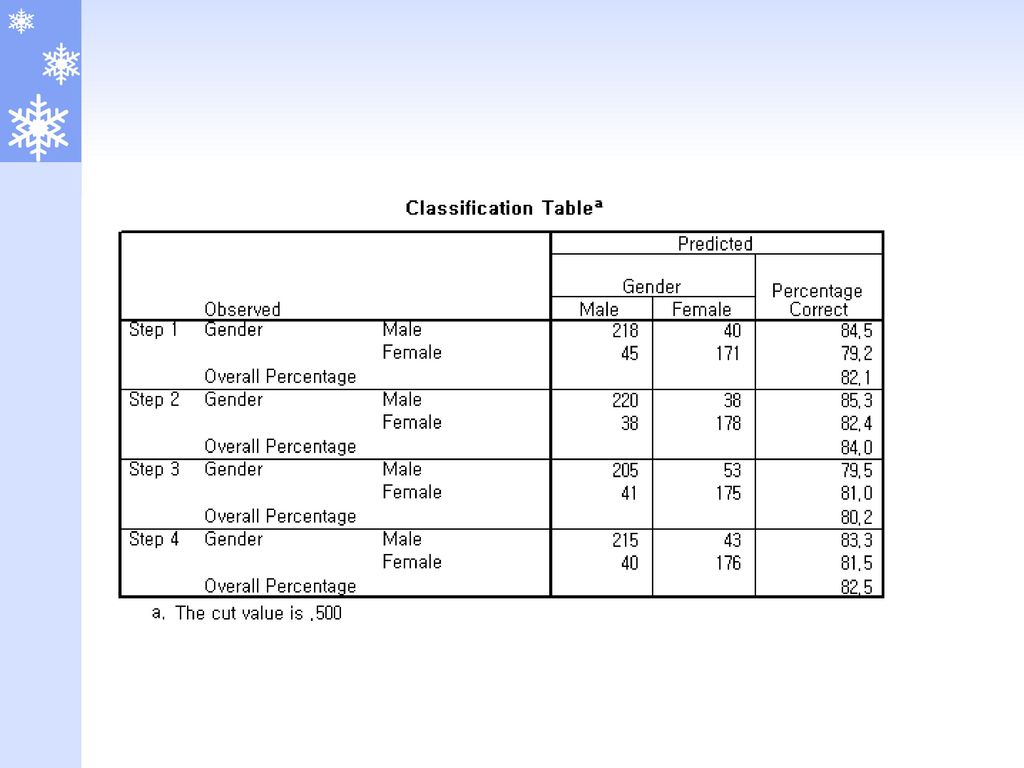
적중률 분석 케이스의 분류 추정확률이 0.5초과이면 사건이 발생하는 집단으로 분류함
추정확률이 0.5미만이면 사건이 발생하지 않는 집단으로 분류함 추정확률이 0.5이면 임의로 분류 적중률(hit ratio) 전체 케이스 중에서 추정확률로 정확히 분류된 케이스의 비율 적중률이 높을 수록 모형의 적합도가 높다고 할 수 있음 잘못 분류된 케이스의 추정확률이 0.5에서 크게 벗어나 있을 경우 추정모형에 문제가 있음을 의미함.
 전체 케이스 중에서 추정확률로 정확히 분류된 케이스의 비율. 적중률이 높을 수록 모형의 적합도가 높다고 할 수 있음. 잘못 분류된 케이스의 추정확률이 0.5에서 크게 벗어나 있을 경우. 추정모형에 문제가 있음을 의미함.")
9
우도값 분석 우도(likelihood) 주어진 추정계수로 관측값이 발생할 확률 우도를 이용한 적합도 검토
우도는 0과 1사이의 값을 취함 우도에 로그를 취하고 여기에 -2를 곱한 값 으로 적합도를 검토함 모형이 완전하게 적합하다면 우도는 1 -2LL은 0이 될 것임 : 관측값 : 예측값 우도가 0에 접근할 수록 적합도는 낮음을 나타냄 -2LL은 +inf로 접근

10
적합성통계 적합성통계(goodness-of-fit statistic) [질문] 적합도가 높을 수록 이 접근하는 값?
![적합성통계 적합성통계(goodness-of-fit statistic) [질문] 적합도가 높을 수록 이 접근하는 값](http://slidesplayer.org/slide/11221059/60/images/10/%EC%A0%81%ED%95%A9%EC%84%B1%ED%86%B5%EA%B3%84+%EC%A0%81%ED%95%A9%EC%84%B1%ED%86%B5%EA%B3%84%28goodness-of-fit+statistic%29+%5B%EC%A7%88%EB%AC%B8%5D+%EC%A0%81%ED%95%A9%EB%8F%84%EA%B0%80+%EB%86%92%EC%9D%84+%EC%88%98%EB%A1%9D+%EC%9D%B4+%EC%A0%91%EA%B7%BC%ED%95%98%EB%8A%94+%EA%B0%92.jpg "적합성통계 적합성통계(goodness-of-fit statistic) [질문] 적합도가 높을 수록 이 접근하는 값")
11
모형카이제곱 모형카이제곱(model chi-square) 상수항만을 가진 모형의 -2LL값과 k개의 독립변수를 가진 모형의
: k개의 독립변수를 가진 모형의 -2LL값 모형카이제곱은 “k개의 독립변수들의 회귀계수가 모두 0”이라는 귀무가설을 검정하는데 사용함 cf. 회귀분석의 F검정에 해당함

12
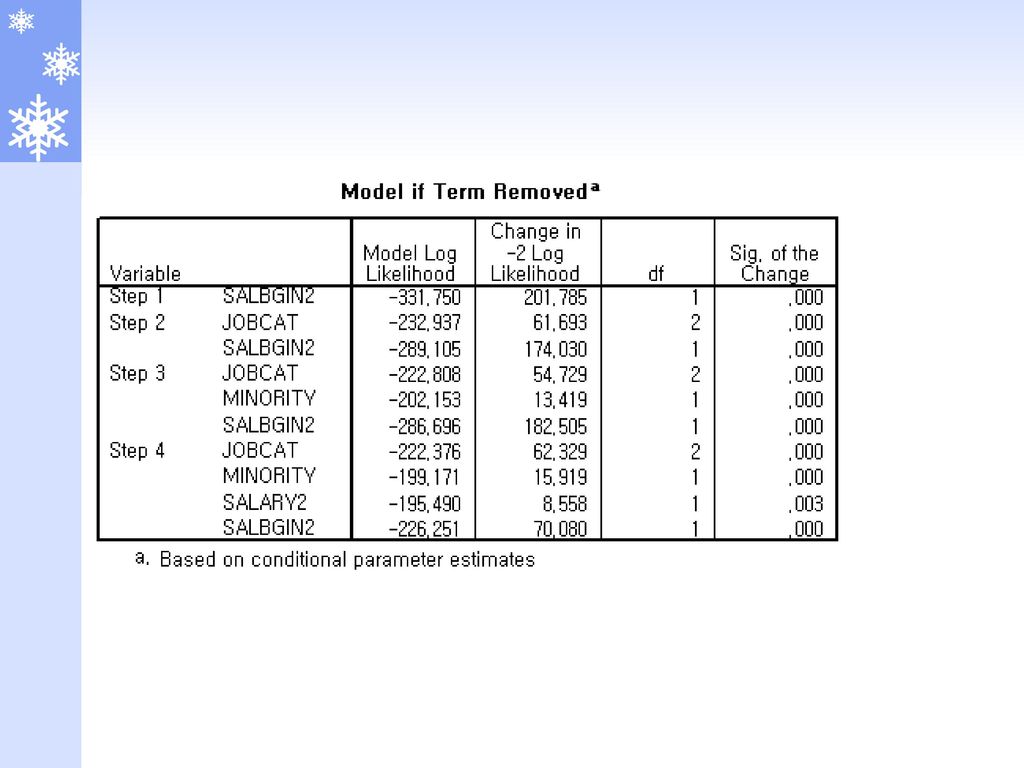
개선도 개선도(improvement) 단계적선택(stepwise)을 이용한 모형구축과정에서 현재모형의 -2LL값과
: 단계 t-1에서의 -2LL값 : 단계 t에서의 -2LL값 “단계 t에서 진입한 변수들의 회귀계수가 모두 0”이라는 귀무가설을 검정함

13
편회귀계수 검정

14
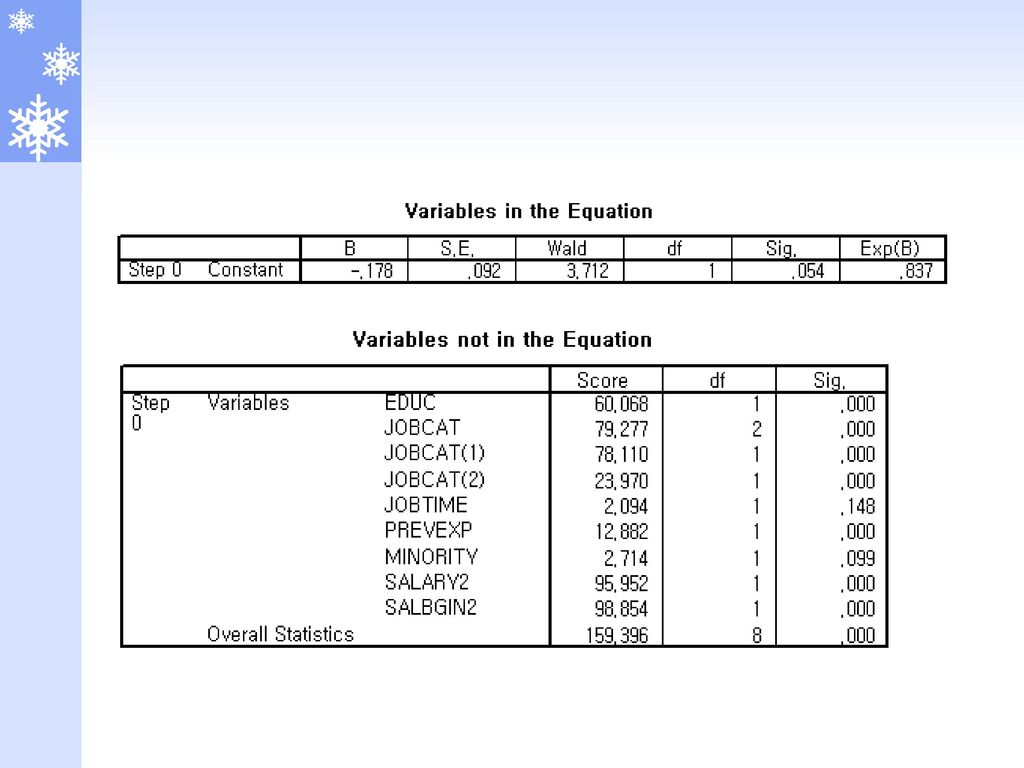
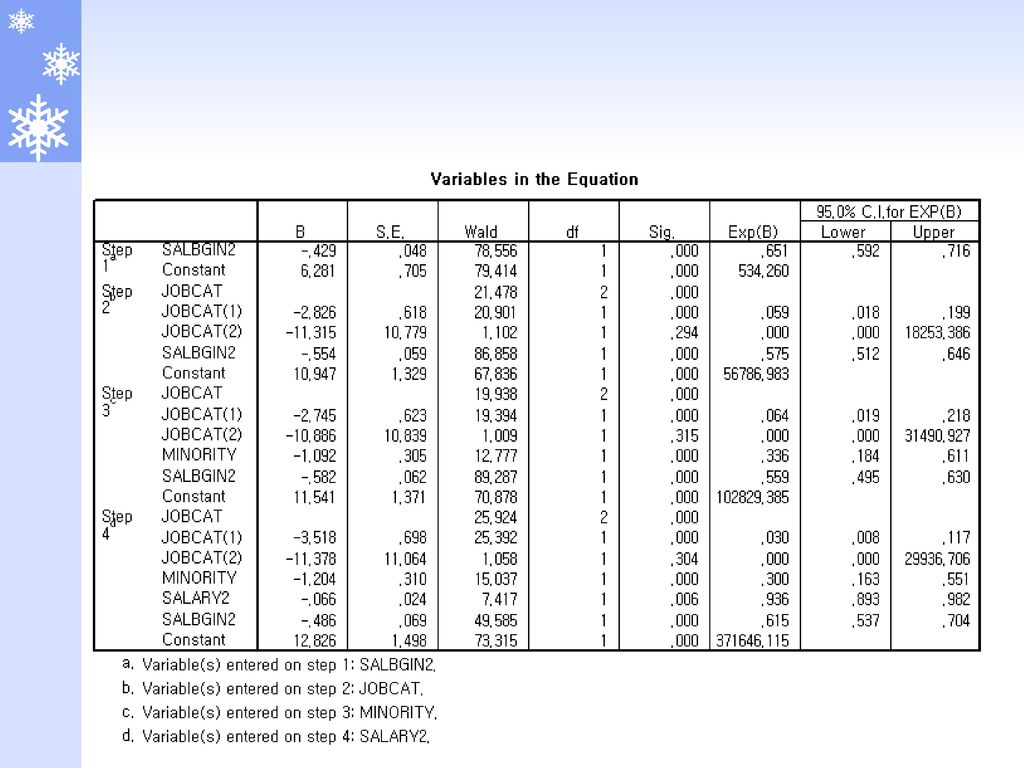
왈드통계량 왈드통계량(Wald statistic) 독립변수가 범주형이 아닌 경우 : 에 대한 최우추정치 :
의 분산에 대한 추정치 chi-square분포를 따름 회귀계수의 절대값이 크면 추정한 표준오차의 값도 커져 “회귀계수가 0”이라는 귀무가설을 기각하지 못하는 바람직하지 못한 성향을 가지고 있음 이를 개선한 것이 우도비통계량

15
우도비통계량 축소모형(reduced model) j번째 변수가 제외된 모형 포화모형(full model)
현 단계의 모든 변수가 포함된 모형 : 축소모형의 우도값 : 축소모형의 로그우도값 : 포화모형의 우도값 : 포화모형의 로그우도값 우도비통계량 j번째 변수가 유의하지 않다면 값은 1에 접근함 값은 0에 접근함

16
조건부통계량 : 포화모형의 로그우도값 : 에서 평가한 로그우도값 : 를 제외한 나머지 회귀계수 추정치
조건부통계량(conditional statistic) 우도비통계량과의 차이점 우도비통계량에서는 축소모형의 회귀계수를 재추정함 조건부통계량에서는 축소모형의 회귀계수를 재추정하지 않음
 우도비통계량과의 차이점. 우도비통계량에서는 축소모형의 회귀계수를 재추정함. 조건부통계량에서는 축소모형의 회귀계수를 재추정하지 않음.")
17
점수통계량(score statistic)
왈드통계량, 우도비통계량, 조건부통계량 등은 변수를 제거하는 기준으로 사용되는 반면 점수통계량은 변수의 진입을 결정하는 기준으로 사용됨 점수통계량 계산방식은 매우 복잡 생략 점수통계량의 유의수준이 낮을 변수부터 진입

18
R통계량 : j번째 독립변수의 자유도 범주형변수가 아니면 = 1 범주형변수 이면 = 범주의 수 - 1
: 상수항만을 가진 모형의 로그우도값 R통계량 R통계량의 부호는 j번째 독립변수의 회귀계수의 부호와 같은 절대값이 0에 가까울 수록 모형에 대한 공헌도가 낮음을 나타냄

19
정성적 변수의 처리 회귀분석이나 판별분석과 마찬가지로 로지스틱 회귀분석에서도
이진수의 가상변수를 도입하여 정성적 변수를 독립변수로 사용할 수 있음 정성적 변수를 독립변수로 사용하는 이유는 정성적 변수가 나타내는 집단간의 비교를 위한 것임 정성적 변수의 값이 0-1 이진수변수인 경우 값이 0인 집단은 준거집단으로 비교대상임 값이 1인 집단의 로지스틱 회귀계수는 승산비의 로그값의 차이로 해석할 수 있음

20
정성적 변수가 3개 이상의 집단을 나타내는 경우 (c – 1)개의 이진수 가상변수를 도입하여 사용함 계산 결과에 나타나지 않는 집단을 (c-1)개 가상변수의 값이 모두 0인 것으로 나타냄 (indicator coding) (c-1)개 가상변수의 값이 모두 -1인 것으로 나타냄 (effect coding) 지표코딩에서는 가상변수 값이 모두 0인 집단의 평균이 비교기준이 되며 효과코딩의 경우 전체집단의 평균이 비교기준이 됨
개 가상변수의 값이 모두 -1인 것으로 나타냄 (effect coding) 지표코딩에서는 가상변수 값이 모두 0인 집단의 평균이 비교기준이 되며. 효과코딩의 경우 전체집단의 평균이 비교기준이 됨.")
21
모형의 구축 모형구축방법 Enter(입력) Forward(전진단계적선택) Backward(후진단계적선택)
 Forward(전진단계적선택) Backward(후진단계적선택)")
22
Forward 회귀분석에서의 Stepwise와 같은 방식임 상수항만으로 모형을 시작하여 각 단계마다 독립변수가 하나씩 모형에 추가되거나 모형에서 제거됨 SPSS에서는 왈드 통계량, 우도비 통계량, 조건부 통계량 중 하나를 진입과 제거의 기준으로 활용할 수 있음 각 단계마다 모형에 들어있지 않은 변수들 중에서 선택한 통계량의 유의수준이 진입기준보다 낮은 경우에 유의확률이 가장 낮은 변수를 다음 단계의 진입변수로 선정함 매 단계마다 모형에 이미 선정되어 있는 독립변수에 대해 모형에서 제외할 것인지를 검토함 모형에 있는 독립변수들 중 지정한 통계량의 유의확률이 제거기준을 초과하는 변수가 있는 경우 유의확률이 가장 큰 변수를 제거함

23
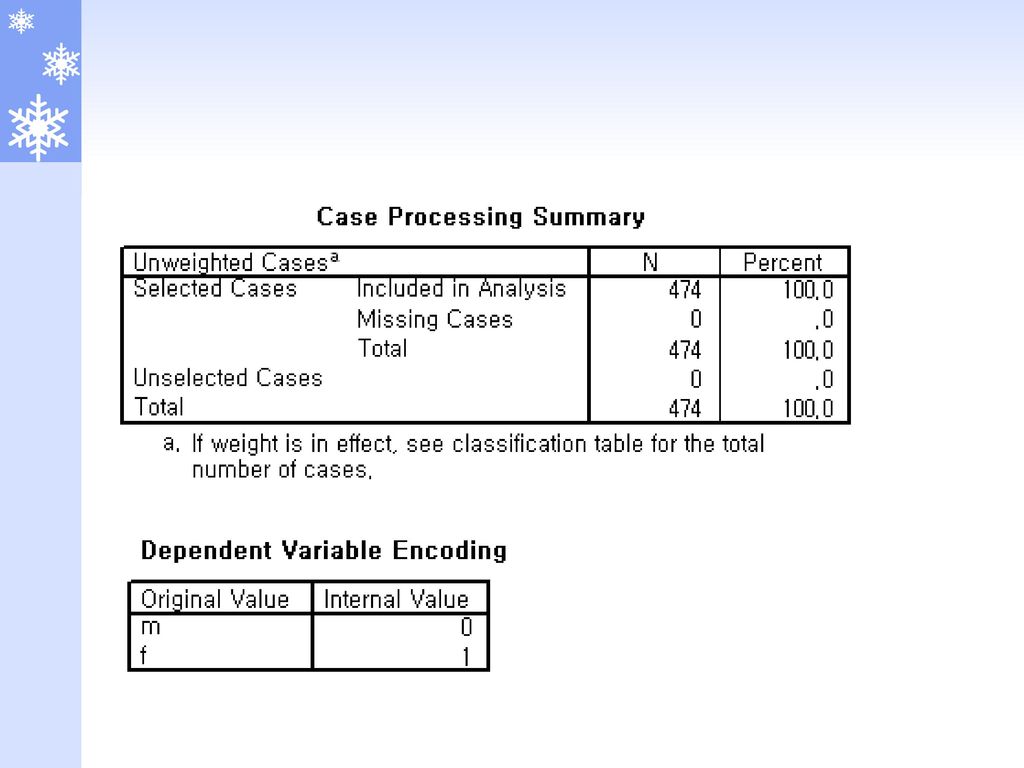
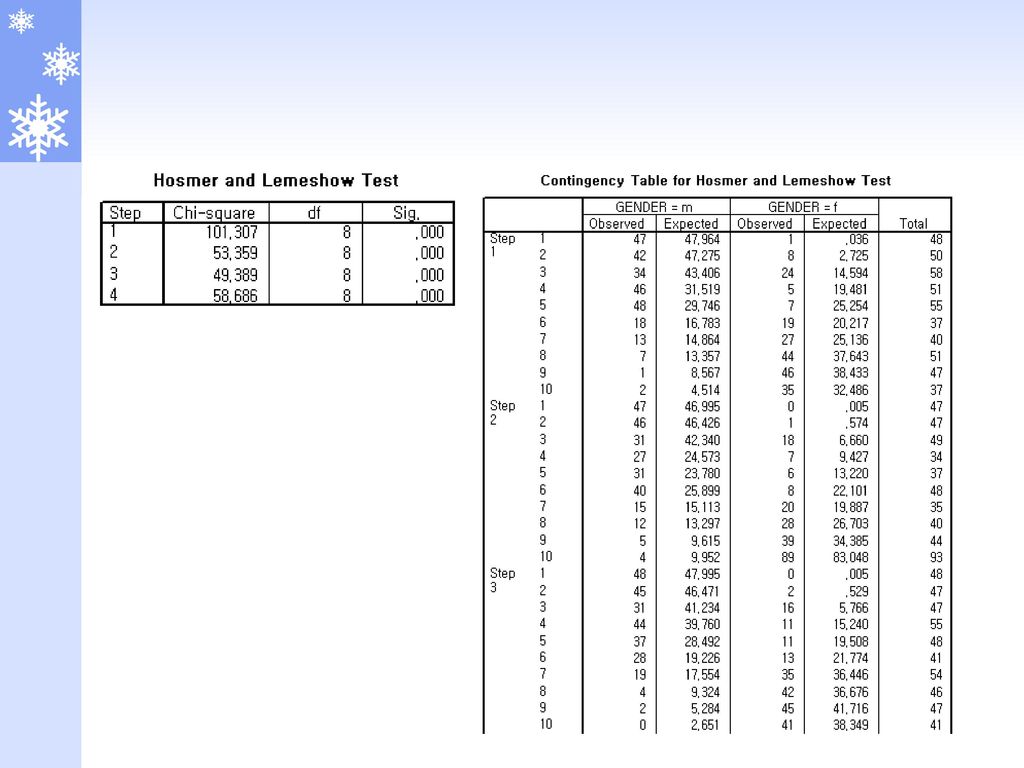
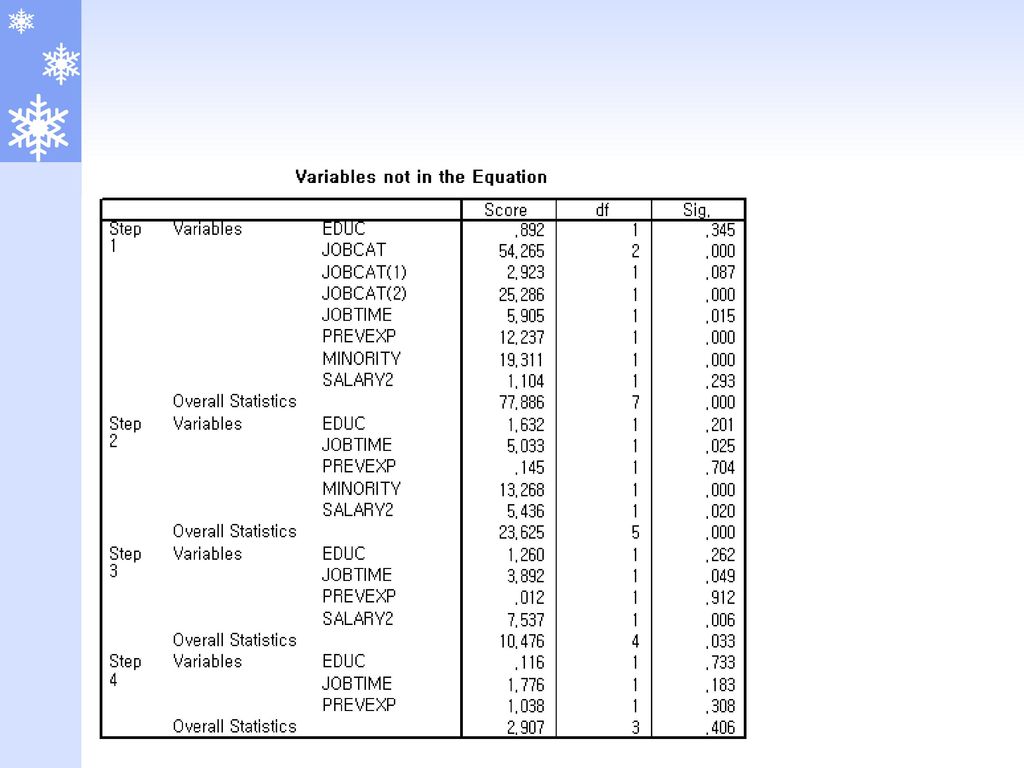
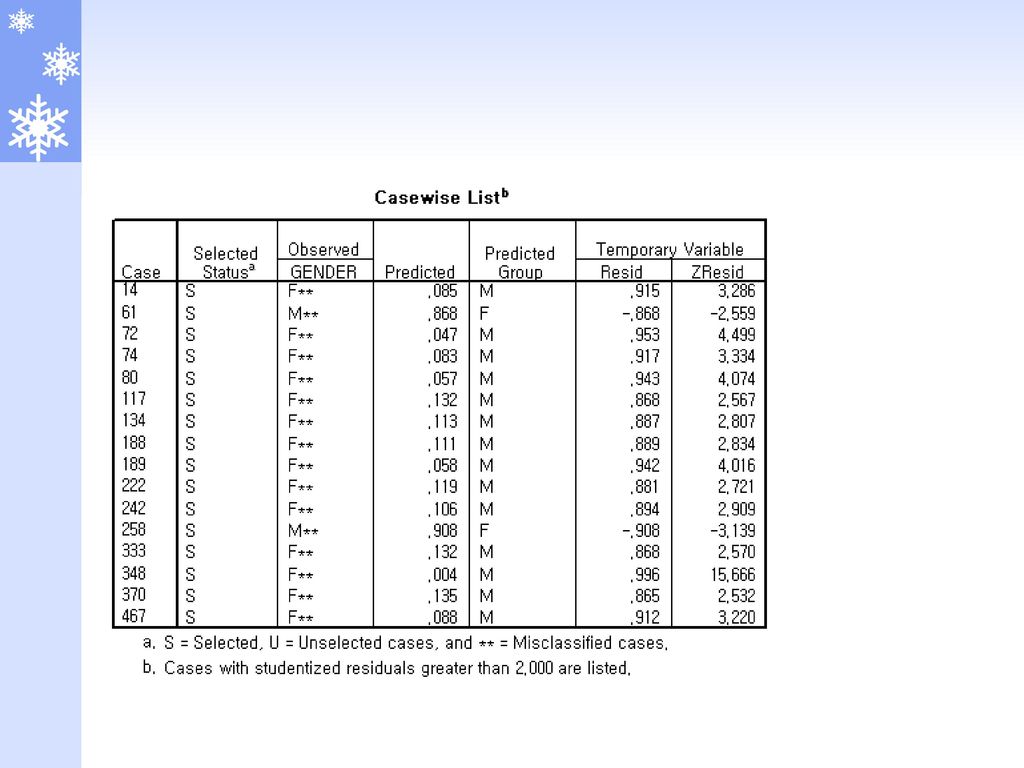
종속변수 : gender 0 : male, 1 : female
독립변수 : educ(교육수준), salary2(현재급여), salbgin2(최초급여), jobtime(입사후경력), prevexp(입사전경력), jobcat(직종), minority(소수민족여부) method : forward:conditional
, salary2(현재급여), salbgin2(최초급여), jobtime(입사후경력), prevexp(입사전경력), jobcat(직종), minority(소수민족여부) method : forward:conditional.")
Similar presentations

 계산 컴퓨터에서 숫자를 표기하는 방법 가수 (Fraction) : 부호화된 고정소수점 숫자 지수 (Exponent) : 소수점의 위치를 표시 ( 예 )10 진수 +6132.789 를 표기하면 Fraction Exponent.>")

 통계량 (statistic) 표본자료의 함수 즉 모집단 … … 표본 표본추출 … … 통계량 계산.>")


>")

. 고장률은 확률이 아니며 따라서 1 보다 커도 상관없다. 고장이 발생하기 쉬운 정도를 표시하는 척도. 일반으로 고장률은 순간고장률과 평균고장률을 사용하고 있지만.>")
 에서 같은 첨자가 있는 곳은 비워두고, 그 밖에 cell에 수준수 (level) 또는 반복수를 기입>")





 2016. 5. 20 서구원 한양사이버대학교 미디어MBA.>")




