조원 : 김영재(코딩) 이지영(스토리) 임병욱(그래픽) 리더: 박 근 용 조원 : 김영재(코딩) 이지영(스토리) 임병욱(그래픽)
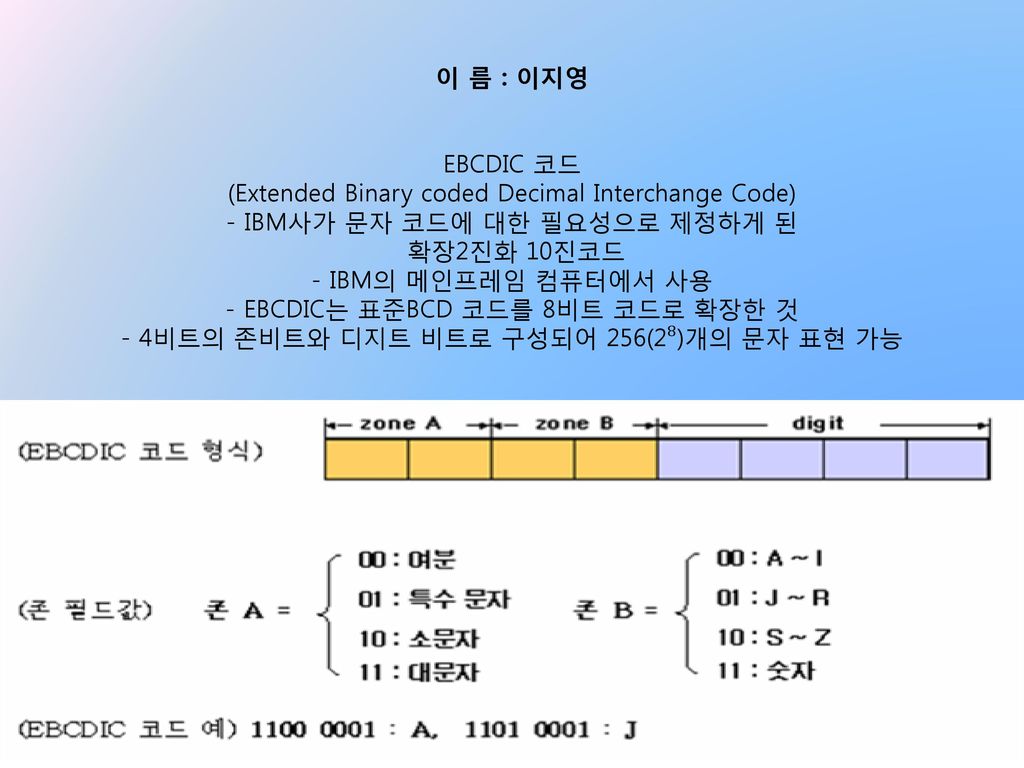
이 름 : 이지영 EBCDIC 코드 (Extended Binary coded Decimal Interchange Code) - IBM사가 문자 코드에 대한 필요성으로 제정하게 된 확장2진화 10진코드 - IBM의 메인프레임 컴퓨터에서 사용 - EBCDIC는 표준BCD 코드를 8비트 코드로 확장한 것 - 4비트의 존비트와 디지트 비트로 구성되어 256(2⁸)개의 문자 표현 가능
이 름 : 박 근용 문자코드의 종류 문자코드의 종류로는 ASCII코드, 유니코드, BCD코드, EBCDIC코드가 있다 이 름 : 박 근용 문자코드의 종류 문자코드의 종류로는 ASCII코드, 유니코드, BCD코드, EBCDIC코드가 있다. . ASCII 코드 ASCII(American Standard Code for information interchange)코드는 미국표준협회(ANSI, American National Standards Institute)가 제정한 데이터처리 및 통신시스템 상호 간의 정보 교환용 표준 코드다. 표현할 수 있는 문자는 영문 대문자 및 소문자. 구두점 기호, 숫자를 비롯해 128(2의7승)개다.7비트중 앞의 3비트는 존 비트를,뒤의 4비트는 디지트 비트를 나타낸다. 유니코드 국제표준으로 제정된 2바이트계의 만국 공통의 국제 문자부호 체계(UCS: Universal Code System)를 말한다. 데이터의 교환을 원활하게 하기 위하여 문자 1개에 부여되는 값을 16비트로 통일하였다. 코드의 1문자당 영어는 7비트, 비영어는 8비트, 한글이나 일본어는 16비트의 값을 지니는데, 이를 모두 16비트로 통일한 것이다. ISO/IEC 10646-1의 문자판에는 전 세계에서 사용하고 있는 26개 언어의 문자와 특수기호에 대해 일일이 코드값을 부여하고 있다. 문자 하나를 16비트로 표현하므로 65,536(2의16승)개의 문자와 기호를 나타낼 수 있다. 인코딩 방식은 UTF(USC Transformation Format)-8, UTF-16, UTF-32. 세 가지가 있다. UTF 뒤의 숫자는 문자 인코딩에 사용되는 비트 수를 나타낸다.
이름 : 임병욱 . ASCII 코드 ASCII(American Standard Code for information interchange)코드는 미국표준협회(ANSI, American National Standards Institute)가 제정한 데이터처리 및 통신시스템 상호 간의 정보 교환용 표준 코드다. 표현할 수 있는 문자는 영문 대문자 및 소문자. 구두점 기호, 숫자를 비롯해 128(2의7승)개다.7비트중 앞의 3비트는 존 비트를,뒤의 4비트는 디지트 비트를 나타낸다. 유니코드 국제표준으로 제정된 2바이트계의 만국 공통의 국제 문자부호 체계(UCS: Universal Code System)를 말한다. 데이터의 교환을 원활하게 하기 위하여 문자 1개에 부여되는 값을 16비트로 통일하였다. 코드의 1문자당 영어는 7비트, 비영어는 8비트, 한글이나 일본어는 16비트의 값을 지니는데, 이를 모두 16비트로 통일한 것이다. ISO/IEC 10646-1의 문자판에는 전 세계에서 사용하고 있는 26개 언어의 문자와 특수기호에 대해 일일이 코드값을 부여하고 있다. 문자 하나를 16비트로 표현하므로 65,536(2의16승)개의 문자와 기호를 나타낼 수 있다. 인코딩 방식은 UTF(USC Transformation Format)-8, UTF-16, UTF-32. 세 가지가 있다. UTF 뒤의 숫자는 문자 인코딩에 사용되는 비트 수를 나타낸다. BCD코드 문자 하나를 표현하기 위해 6비트를 사용하므로 64(2의6승)개의 문자를 표현할수 있다. 4비트의 디지트 비트에 2비트의 존 비트를 추가해 10진수 숫자와 문자를 표현한다. 디지트 비트는 0~9RK지의 수를 표현하는 가중치 코드로 자릿값을 갖기 때문에 8421코드라고도 한다.
이름 : 김영재 문자코드란 문자를 컴퓨터에서 이용할 수 있도록 일정한 규칙에 의해 구조화된 약속의 총칭이다 이름 : 김영재 문자코드란 문자를 컴퓨터에서 이용할 수 있도록 일정한 규칙에 의해 구조화된 약속의 총칭이다. 컴퓨터는 일종의 전기신호에 의해 처리되기 때문에 0과 1의 2진수 밖에는 사용할 수가 없다. 따라서 문자와 같은 많은 종류의 정보를 컴퓨터에서 처리하기 위해서는 0과 1의 조합으로 하나의 문자를 구성하게 된다. 이렇게 문자를 수치화 하여 컴퓨터가 처리할 수 있도록 하는 것을 ‘코드화’ 또는 ‘부호화’라고 하며, 복수의 문자를 일정한 규칙에 의해 조합한 세트를 ‘부호화 문자집합(Coded Character Set)’이라 한다. 그리고 이를 간단히 ‘문자집합’ 또는 ‘문자코드(Character Code)’라고 한다. 그러나 엄밀한 의미에서 이들 사이에는 약간의 차이가 있지만, 일반적으로 ‘문자부호화 형식’과 ‘부호화 문자집합’은 구별하지 않으며, ‘부호화 문자집합’이라는 말로 이 두 가지를 하나로 묶어서 다루고 있다. 또 부호화 문자집합은 ‘codeset’ 혹은 ‘charset’이라고도 한다. 이 외에 ‘부호화체계’ 또는 ‘인코딩 스키마(encoding scheme)’라는 용어도 ‘부호화 문자집합’이나 ‘부호화 형식’과 같은 의미로 사용하는 경우가 많다. 문자나 기호를 컴퓨터로 다루기 위하여, 문자나 기호 하나하나에 할당 시키는 고유의 숫자.
THANK YOU!