빅데이터 분산 처리 시스템 충북대학교 정보통신공학부 복경수 ksbok@chungbuk.ac.kr
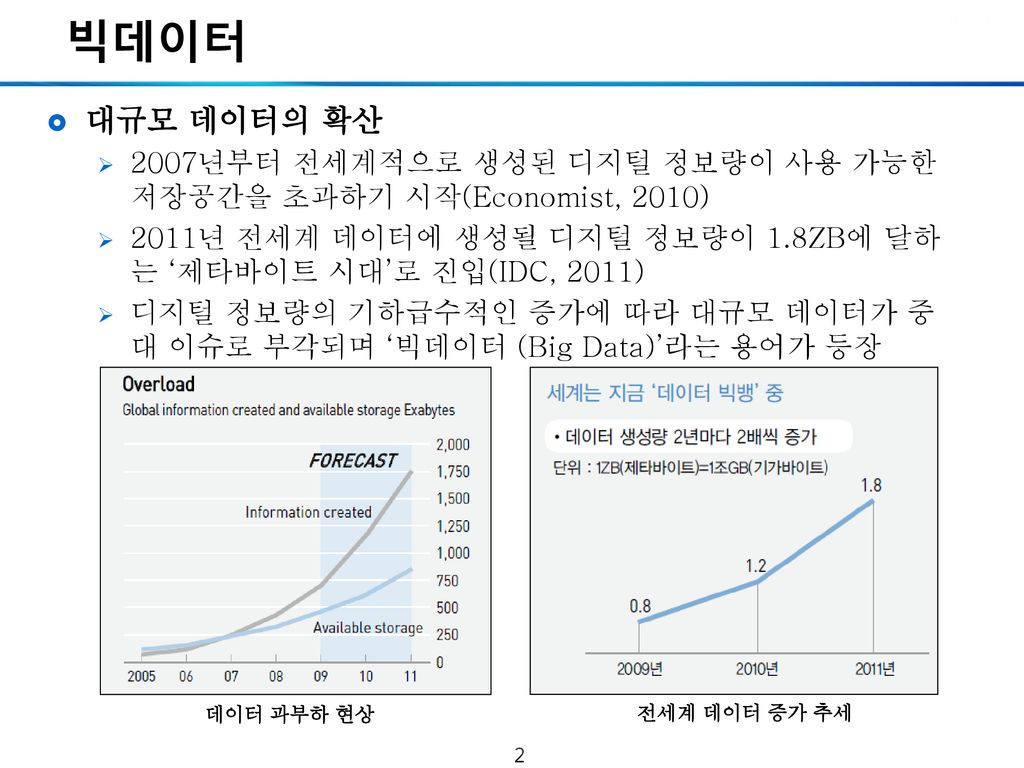
빅데이터 대규모 데이터의 확산 2007년부터 전세계적으로 생성된 디지털 정보량이 사용 가능한 저장공간을 초과하기 시작(Economist, 2010) 2011년 전세계 데이터에 생성될 디지털 정보량이 1.8ZB에 달하는 ‘제타바이트 시대’로 진입(IDC, 2011) 디지털 정보량의 기하급수적인 증가에 따라 대규모 데이터가 중대 이슈로 부각되며 ‘빅데이터 (Big Data)’라는 용어가 등장 데이터 과부하 현상 전세계 데이터 증가 추세
빅데이터 빅 데이터 출원 스마트 단말 확산, SNS 활성화, 사물네트워크(M2M) 확산으로 데이터 폭발이 더욱 가속화 되며 점차 빅데이터 기반이 확대 다양한 정보 채널의 등장과 이로 인한 정보의 생산, 유통, 보유량의 증가는 계속적으로 데이터의 기하급수적인 증가 새롭게 발생하는 데이터의 상당수는 비정형 데이터로서 기존의 기법으로는 분석에 한계가 존재 향후 M2M, IoT(Internet of Things), NFC 등의 활성화를 통해 이용자가 생성하지 않고, 인프라 자체가 다량의 데이터를 직접 생성
빅데이터 빅데이터 사례 구글, 아마존, 페이스북, 애플은 핵임 서비스를 통해 방대한 데이터를 수집 페이스북은 2012년 8월 기준 매일 25억개(500 TB) 이상의 데이터 발생하며 트위터는 2013년 1월 기준 매일 4억개 이상 데이터 발생
빅데이터 빅데이터(Big Data) 기존 데이터베이스 관리 도구의 데이터 수집, 저장, 관리, 분석하는 역량을 넘어서는 데이터 집합 센서 데이터, 웹 로그 데이터, 소셜 데이터 등 새로운 데이터가 생성됨에 따라 정형 데이터에서 비정형데이터로 분석 요구 거대한 데이터 양(volume), 빠른 데이터 유통 및 이용 속도(velocity), 데이터 다양성(variety)을 특징으로 함 데이터 특성에 따른 빅 데이터 프로세서 파워에 따른 컴퓨터구조
빅데이터 빅데이터의 4가지 구성 요소
빅데이터 ICT 주도권이 데이터로 이동 축적과 공유를 통해 유의미하게 분석할 수 있는 데이터 자원(빅데이터)이 쌓이자 데이터의 역할은‘분석과 추론(전망)’의 방향으로 진화 스마트 시대에는 데이터의 저장-검색-관리-공유-분석-추론의 전체적인 과정이 업그레이드되며 정보화 시대와 차별적으로 발전
빅데이터 미래사회의 특성과 빅데이터의 역할
빅데이터 세계 시장 전망 IDC는 세계 빅데이터 시장이 2010년 32억 달러에서 2015년에는 169억 달러 규모에 달할 것으로 전망 (IDC, 2012.3) 향후 5년간 연평균 39.4% 성장 : 전체 IT시장 성장률의 약 7배 2015년까지 소프트웨어 및 서비스 부문이 빅 데이터 시장의 대부분(65.9%)을 차지 (단위 : 백만 $) IDC의 빅데이터 세계시장 규모 전망(2010-2015)
빅데이터 국내 시장 전망 국내 IT 서비스 시장의 2013년 성장률이 4.1%로 전망되는 가운데 데이터가 IT 주요 트렌드로 선정 정보통신산업진흥원(NIPA)이 발표한 ‘ 2013년 10대 이슈’ 중 1위는 빅데이터의 도입 및 활용 (단위 : 백만 $) 국내 IT 서비스 시장 전망( 2010-2015)
빅데이터 활용 빅 데이터의 활용 빅데이터 분석을 통해 현재의 상황 파악 및 가까운 미래를 예측할 수 있는 의미 있는 정보를 창출 의미 있는 해석을 도출할 수 없다면 빅 데이터의 존재 의미가 없음 다양한 사업, 이용자 행태분석 등에 이용할 수 있는 의미를 도출해 낼 수 있어야 함
빅데이터 활용 기업체 빅데이터 분석 활용 구분 내용 효과 웰마트 웹 사이트에서 발생하는 거래 데이터를 이용한 재고 예측 조사 시스템 구축 SNS 데이터를 실시간으로 분석하여 상품 판매를 촉진하고 고객 선호도 및 수요를 예측 리츠칼튼 고객 데이터 수집 및 분석을 통한 고객 요구 사항 파악 전세계 100만명의 고객 DB를 토대로 고객의 정보와 취향에 관한 정보를 종합하여 맞춤형 서비스 제공 포스코 철광석 가격 예측을 통해 최적의 구매 시스템 구축 생산 공정의 데이터를 분석하여 불량률을 감소 원료를 효율적으로 구매함으로써 가격 경쟁력을 향상 국내 물가 안정에 기여 SK 텔레콤 기업들이 원하는 키워드를 중심으로 온라인 여론을 분석하여 실시간으로 제공 효율적인 기업 홍보 및 마케팅 방법 제공 마케팅 효과에 대한 정량적인 측정 기준 마련 GS EPS 전력에 영향을 미치는 다양한 변수를 고려한 합리적 전력 시장 분석 및 예측 전력량을 실시간으로 모니터링하여 전력 수요량을 예측하고 시뮬레이션을 통해 비용 절감 및 이윤 극대화 아모레 퍼시픽 구매 정보부터 콜센터 불만 접수까지 모든 데이터 통합 고객의 취향에 맞는 맞춤화된 서비스를 제안
빅데이터 활용 구글, 독감 예보 서비스 검색 정보에 사용자의 현재 상태나 상황에 관한 내용이 담겨있으므로 실시간으로 무수히 많이 누적되는 정보 속에서 사회적인 변화나 흐름을 파악하는 것이 가능 구글 홈페이지에서 독감, 인플루엔자 등 독감과 관련된 검색어 쿼리의 빈도를 조사하여 독감 확산 조기 경보체계 마련 구글 독감 동향 구글 독감 동향과 실제 확산
빅데이터 활용 아마존, 상품 추천 서비스 물건을 구매한 내역을 통해 이용자들의 소비 패턴을 분석하여 이용자가 상품을 구매 시, 관련 상품을 추천 최근에는 Facebook 정보와 연계하여 이용자의 지인들이 구매 또는 원하는 상품을 추천하는 기능도 제공 Amazon 상품 검색
빅데이터 활용 밀라노, 교통정보 시스템 교통흐름에 영향을 주는 사건정보, 날씨정보, 도로교통 상황, 주변 건물 및 도로공상, 시위, 행사 등들을 종합적으로 분석하여 최적의 교통안내 서비스를 제공 실시간 교통 흐름에 바탕으로 정확한 길안내 서비스 제공 5분에서 15분 간격으로 수집된 데이터를 분석하여 향후 2~24시간을 예측 가능 밀나노 시내 교통 센서 지도 밀나노 시내 교통상황 서비스
빅데이터 활용 샌프란시스코, 범죄 예상 시스템 빈집, 빈차털이 등의 범죄는 사건 발생 현장 또는 그 인근에서 제2, 제3의 범행이 재발할 가능성 농후 과거 8년 동안 범죄가 발생했던 지역과 유형을 세밀하게 분석하여 후속 범죄 가능성을 예측함으로써 범죄를 사전 예보하는 방식을 이용 과거 범죄에 대한 통계 정보를 제공하는 것과 달리 새로운 범죄 가능성 정보를 제공 경찰청 범죄 지도
빅데이터 활용 일본, 웨더뉴스 평상시에 하루에 5만 건의 정보를 수집하며 한정된 지역에서 수시간 앞까지의 상황을 예측 기본적인 기상예보 외에도 회원이 자신이 속한 지역의 날씨를 올리면 10분 간격으로 1시간 뒤까지의 기상예보가 표시되는 시스템 웨더 뉴스 실행 화면
빅데이터 활용 미국, Trip Advisor Trip Advisor는 매달 5,000만 명의 여행객이 방문하는 소셜 사이트로 100% 여행객들의 자발적인 참여와 리뷰로 유지 개개인의 텍스트와 이미지 리뷰 분석을 통해 여행 목적별, 지역별, 취향별 등에 대한 개인 선호 스타일을 분석 비슷한 지역의 비슷한 연령대가 선호하는 여행 형태를 파악하며 각 여행자의 구미에 맞는 여행 상품을 제안하고 자세한 여행 정보를 함께 제공 Tripadvisor
빅데이터 활용 서울시, 심야버스 운행 심야버스가 만들어진 배경과 노선을 정하는 결정하기 위해 빅데이터를 활용 다산콜센터 민원 분석을 결과 문의에서 많은 부분을 차지하는 것 중 하나가 바로 '심야 교통수단' 문제 심야버스가 만들어진 배경과 노선을 정하는 결정하기 위해 빅데이터를 활용 KT 고객의 통화 기지국 위치와 청구지 주소를 활용해 유동인구를 검증 약 30억 건의 심야 시간대 통화 및 문자메시지를 분석하여 어느 지역에 버스가 필요한지 조사하고 잠재적인 수요층 파악 1시∼오전 5시 서울시내 유동인구 밀집도 심야 시내버스 노선
빅데이터 활용 한국, 2013 레스토랑 어워드 빅데이터를 이용하여 서울에서 가장 좋은 레스토랑을 발표 한국, 2013 레스토랑 어워드 빅데이터를 이용하여 서울에서 가장 좋은 레스토랑을 발표 온라인에서는 맛집 블로거의 글 60여만건과 레스토랑 평가 전문 웹사이트의 평가 40여만건을 수집 오프라인에서는 40여 종의 유명 맛집 소개 서적, 50여 종의 유명 잡지와, TV프로그램에서 총 108만 여건의 데이터를 수집 레드테이블 랭킹 알고리즘은 레스토랑 평가자들의 과거행동을 추적하여 개인별 활동점수와 영향력 점수를 부여 소셜레스토랑랭킹 레드테이블
빅데이터 처리 과정 빅 데이터 처리 과정 인프라 기술 : 데이터를 수집, 처리, 관리하는 데이터베이스, 분선 파일 시스템, 병렬 처리 시스템 분석 기술 : 데이터 마이닝, 확률/통계 기법, 자연어 처리, 기계 학습 등 분석 기술을 시각화하는 표현기술
빅데이터 처리 과정 포브스의 빅데이터 지도
빅데이터 처리 과정 빅데이터 오픈 소스 기술 구분 내용 오픈 소스 데이터수집 데이터 발생원으로부터 안정적인 저장소로 저장하는 기능 Flume, Scribe, Chukwa 데이터저장 수집된 데이터를 안정적으로 저장하는 저장소 비구조적 데이터 저장소로 주로 대용량 파일 저장소 Hadoop FileSystem MogileFS 트렌잭션 데이터 처리 원본 데이터를 실시간으로 저장, 조회 처리를 하기 위한 저장소 구조적 저장소 또는 검색 엔진 기술을 활용 NoSQL(Cloudata, HBase,Cassandra) Katta, ElasticSearch 실시간 분석 플랫폼 데이터 수집과 동시에 분석을 수행 복잡한 분석보다 count, sum 등 단순한 aggregation 연산 정도 수행 S4,Storm 배치 분석 전체 또는 부분 데이터에 대해 복잡하고 다양한 분석 수행 대용량 처리를 위해 분산, 병렬 처리가 필요 단순 텍스트 분석부터 그래프 분석까지 다양한 분석 모델 지원 Hadoop MapReduce(Hive,Pig) Giraph, GoldenOrb 데이터마이닝/통계도구 Cluster, Classification 등과 같이데이터 마이닝을 위한 기본 알고리즘 라이브러리 및 도구 Mahout, R 클러스터관리 및 모니터링 대부분 분산 시스템으로 구성되기 때문에 전체 클러스터에 대한 관제 및 모니터링 ZooKeeper, HUE, Cloumon 데이터Serialization 이기종 플랫폼 및 다양한 종류의 솔루션을 사용하기 때문에 데이터 전송 및 처리에 대한 표준 프레임 워크 Thrift, Avro, ProtoBuf
빅데이터 처리 과정 빅데이터 분야별 주요 업체
빅데이터 처리 과정 글로벌 IT 기업 빅데이터 시장을 선점하고 주도권을 잡기 위해 데이터 분석 중심으로 조직을 개편하고 역량 강화 및 기술 개발 IBM, Oracle 등 글로벌 IT 기업은 인프라, 데이터 수집ㆍ관리, 분석, 의사결정 지원 등 빅데이터 전 부문을 담당
하둡 하둡의 역사 2003년 구글 GFS(Google File System), 2004년 MapReduce, 2006년 BigTable과 같은 대용량 데이터 처리 논문이 발표 이러한 논문을 바탕을 오픈 소스 프로젝트로 2002년 오픈 소스 검색엔진 너치(Nutch)가 탄생 2004년 NDFS(Nutch Distributed Filesysem)이라는 분산 파일시스템과 초기 맵리듀스 버전을 발표 2006년 야후의 지원으로 검색 서비스에 하둡 기술을 적용하는 프로젝트가 시작 2008년 Apache Top-level Project로 승격
하둡 하둡 대규모 클러스터에서 동작하는 분산 어플리케이션 개발을 위한 자바 오픈 소스 프로젝트 MapReduce와 HDFS(Hadoop Distributed File System)으로 구성 HDFS는 분산 저장, MapReduce는 분산 처리 기술을 제공 많은 컴포넌트 제공 (HBase, Zookeeper, Hive, Pig, …) 다른 언어로 만들어진 맵리듀스 프로그램을 Hadoop에서 동작 가능
하둡 HDFS 범용 하드웨어로 구성된 클러스터에서 실행되고 대용량 데이터를 저장할 수 있는 분산 파일 시스템 64MB 블록 단위로 구성되어 분산 컴퓨터에 저장 내부적으로 파일은 하나 또는 그 이상의 블록으로 쪼개지며 이러한 블록들은 데이터노드의 집합 안에 저장 각 블록은 데이터 유실의 위험이 신뢰성 향상을 위해 복제를 수행 마스터/슬래이브 구조로 구성
하둡 HDFS 구조
하둡 HDFS 구조 기능 네임노드 : 파일 시스템의 네임스페이스(namespace)를 관리하는 서버 데이터노드 보조 네임노드 파일 시스템의 트리, 모든 파일과 디렉토리 구조, 엑세스 권한 등의 메타데이터를 관리 블록에 대한 배치 정보를 관리 데이터노드 특정 파일에 대한 분할 블록을 저장 고정 크기의 분할 단위는 64MB 또는 128MB 크기로 관리 데이터 노드간에 데이터 복제를 통해 데이터를 신뢰성을 유지 보조 네임노드 네임노드에서 관리하는 파일시스템의 이미지 정보를 백업 네임스페이스 이미지와 주기적으로 병합하는 기능을 수행
하둡 MapReduce 분산 병렬 처리를 위한 프레임워크 범용 컴퓨터 클러스터에서 수행되는 분산 데이터 처리 모델과 실행 환경을 제공 MapReduce 프레임워크에 맞춰 프로그래밍하고 하둡에서 실행하면 하둡이 자동으로 분산 처리를 수행
하둡 MapReduce 처리 과정 Map Reduce Job Tracker Tack Tracker 입력데이터를 받아 key, value 형태로 분류 Map(k1,v1)->list(k2, v2) Reduce 중복된 데이터를 제거하여 원하는 데이터를 추출 Reduce(k2, list(v2)->list(v3) Job Tracker 마스터 노드에서 Task Tracker에 작업 할당하고 관리 전체 작업을 관리하는 마스터 역할을 수행 Job는 분산처리를 하는 전체 작업을 의미 Tack Tracker Worker Node이며 할당 받은 작업을 데이터 노드가 실행 Task는 mapper 또는 reducer 1개를 수행하는 작업
하둡 잡 할당
하둡 Word Count 예제
하둡 스케쥴링 FIFO 스케쥴러 Capacity 스케쥴러 원래 JobTracker에 통합되어있는 스케쥴링 알고리즘이며 따로 설정하지 않을시 디폴트 스케쥴러 잡트레커는 작업 대기큐에서 가장 먼저 입력된 job을 수행 Capacity 스케쥴러 페어스케쥴러를 도입하기 전까지 사용했던 스케쥴러. 야후에서 개발했다. 페어스케쥴러와 다른 차이점은 선점이 안된다. 하지만 풀 대신 여러 대기큐가 만들어지고 각 대기큐에서 사용될 맵 슬롯 과 리듀스 슬롯 갯수를 조절 하여 자원을 관리할 수 있다. 즉 클러스터 전체 용량은 각 큐의 슬롯의 합계다. 이럴경우 대기큐마다 약간씩 노는 자원이 생길 수 있는데 이경우 여분의 자원을 다른 큐에 잠시 빌려주는 일도 가능하다. 또한 작업에 따라 우선순위를 조절할 수 있어서 작업의 펜딩시간을 우선순위에 맞춰 조절 할 수 있다(페어도 동일).나중에는 우선순위에 맞쳐서 선점 기능까지 지원할 예정이라고 한다. 또한 사용자별 큐에대한 접근 권한을 부여하여 자원을 조절할 수 있다. 그외 HOD (hadoop On Demand)라는 방법도 있으니 관심이 있으면 알아보면 좋겠다.
하둡 스케쥴링 Fair 스케줄러 Delay 스케쥴러 facebook에서 제안된 기법으로 자원을 작업당 동일한 비율로 할애 어떤 작업이 자원을 과도하게 잡고 있다면 선점을 통하여(이경우 task를 kill함) 어느정도 균등한 자원분배를 가능 논리적인 방법은 배치 job들을 일련의 풀에 넣어두고 스케쥴러가 수행될 잡을 선택하는 방식 각 풀은 작업 리소스가 모두 동일하도록 할당되고 기본적인 풀의 점유율은 모두 같지만 구성을 조절하여 유형에 따라 자원의 공유양을 늘리거나 줄일 수 있음 Delay 스케쥴러 가용 노드(free node)에 데이터 지역성이 성립하는지 확인 데이터 지역성을 만족하지 못할 경우 다음 순서의 잡에게 태스크 할당 기회를 이양 잡 태스크 할당이 지연된 잡은 다음 가용 노드가 발생시 태스크 우선 순위가 가장 높아짐
하둡 스케쥴링
하둡에코시스템 하둡에코시스템
하둡에코시스템 하둡에코시스템 구성요소