연관분석 (Association)
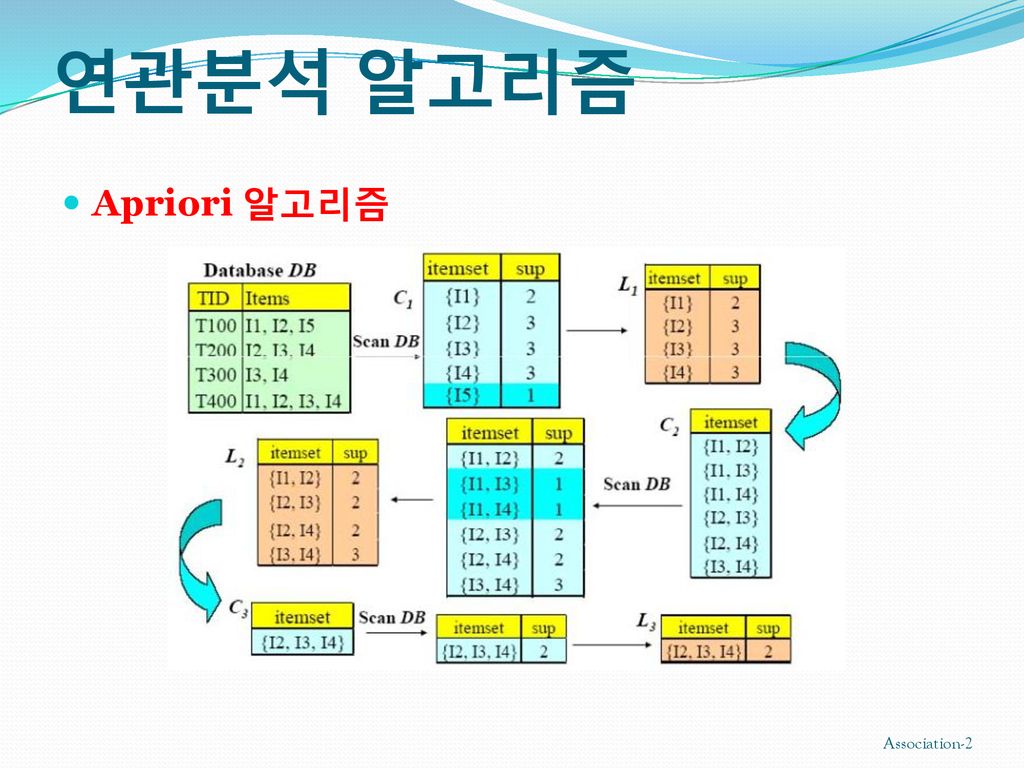
연관분석 알고리즘 Apriori 알고리즘
연관규칙 마이닝 (Association Mining) Basket (Transaction) data 측정치 (X -> Y) Support (지지도) : 전체 레코드에서 상품 X, Y에 대한 거래를 모두 포함하는 비율 => Supp(X, Y) Confidence (신뢰도) : 상품 X를 구매한 거래가 발생했을 경우 그 거래가 상품 Y를 포함하는 조건부 확률 => Conf (X->Y) = Supp(X,Y)/Supp(X) Lift (향상도) : 상품 X를 구매한 경우, 그 거래가 상품 Y를 포함하는 경우와 상품 Y가 상품 X에 관계없이 구매된 경우의 비율 => Lift (X->Y)=Supp(X,Y)/(Supp(X)∙Supp(Y)) = Conf(X->Y)/Supp(Y) 측정치 예 {Milk, Diaper} => Beer : Supp=2/5, Conf=2/3, Lift=(2/3)/(3/5)=1.1167 Transaction ID Iterms 1 Chips, Milk 2 Chips, Diaper, Beer, Cornflakes 3 Milk, Diaper, Beer, Pepsi 4 Chips, Milk, Diaper, Beer 5 Chips, Milk, Diaper, pepsi
연관분석 데이터 전처리 DVD 대여 데이터 transaction 테이블의 구성 library(arules); library(arulesViz) dvd <- read.csv("dvdtrans.csv", header = TRUE, as.is = TRUE); dvd dvd.list <- split(dvd$Item, dvd$ID); dvd.list dvd.trans <- as(dvd.list, "transactions") ID Items 1 Sixth Sense, LOTR1, Harry Potter1, Green Mile, LOTR2 2 Gladiator, Patriot, Braveheart 3 LOTR1, LOTR2 4 Gladiator, Patriot, Sixth Sense 5 ... transaction 테이블의 구성
연관분석 Transaction 테이블의 시각화 image(dvd.trans)
연관분석 Apriori 알고리즘의 적용 연관규칙 개수를 조절 또는 의미 있는 연관규칙을 선별하기 위해 support, confidence 값을 입력 dvd.rules <- apriori(dvd.trans, parameter = list(support = 0.2, confidence = 0.6)) inspect(dvd.rules)
연관분석 연관규칙의 시각화 plot(dvd.rules) plot(dvd.rules, measure=c("confidence", "lift"))
연관분석 연관규칙의 시각화 연관규칙의 개수 plot(dvd.rules, method = "grouped") 원의 크기 : Support 색상 진하기: Lift
연관규칙의 중심에Gladiator, 6th Sense, Patriot 이 있음 연관분석 연관규칙의 시각화 plot(dvd.rules, method = "graph") Item Set 연관규칙의 중심에Gladiator, 6th Sense, Patriot 이 있음
연관분석 연관규칙의 시각화 plot(dvd.rules, method = "graph", control = list(type = "items")) 원 : 연관 관계 원의 크기 : Support 색상진하기: Lift
연관분석 일반 데이타베이스에 대한 연관분석 : AdultUCI 연속형 숫자 속성 컬럼이 있으므로 데이터 가공이 필요 필요없는 속성 제거 # load the data and check it data("AdultUCI") dim(AdultUCI) AdultUCI[1:2,] ## remove attributes AdultUCI[["fnlwgt"]] <- NULL AdultUCI[["education-num"]] <- NULL
number -> factor로 변환 “age”컬럼의 값들을 변경 연관분석 구간값을 순서있는 요소로 전환 number -> factor로 변환 일반 데이타베이스에 대한 연관분석 : AdultUCI 연속형 실수값을 구간값으로 변환 구간 ## map metric attributes AdultUCI[["age"]] <- ordered(cut(AdultUCI[["age"]], c(15,25,45,65,100)), labels = c("Young", "Middle-aged", "Senior", "Old")) AdultUCI[["hours-per-week"]] <- ordered(cut(AdultUCI[["hours-per-week"]], c(0,25,40,60,168)), labels = c("Part-time", "Full-time", "Over-time", "Workaholic")) AdultUCI[["capital-gain"]] <- ordered(cut(AdultUCI[["capital-gain"]], c(-Inf,0,median(AdultUCI[["capital-gain"]][AdultUCI[["capital-gain"]]>0]),Inf)), labels = c("None", "Low", "High")) AdultUCI[["capital-loss"]] <- ordered(cut(AdultUCI[["capital-loss"]], c(-Inf,0, median(AdultUCI[["capital-loss"]][AdultUCI[["capital-loss"]]>0]), Inf)),
연관분석 함수형 언어: median 값 찾기 AdultUCI[["capital-gain"]]>0 “capital-gain” 컬럼의 값들이 0 이상인지 여부 (TRUE/FALSE)를 출력 결국 TRUE/FALSE 값을 가지는 vector를 출력 AdultUCI[["capital-gain"]] [AdultUCI[["capital-gain"]]>0] “capital-gain” 컬럼의 값들 중에서 0을 초과한 것만을 추려냄 median( AdultUCI[["capital-gain"]] [AdultUCI[["capital-gain"]]>0] ) “capital-gain” 컬럼의 값이 0을 초과한 것들에서 ‘median 값’을 찾아냄
연관분석 일반 데이타베이스에 대한 연관분석 : AdultUCI transaction 데이타 포맷으로 변경 {} -> Y 형태 제거 일반 데이타베이스에 대한 연관분석 : AdultUCI transaction 데이타 포맷으로 변경 Apriori 알고리즘으로 연관분석 수행 RHS 부분의 값을 고정하는 경우 Adult <- as(AdultUCI, "transactions") adult_rules <- apriori(Adult, parameter = list(supp = 0.7, conf = 0.9, minlen=2, target = "rules")); inspect(adult_rules) adult_rules.sorted <- sort(adult_rules, by="lift"); inspect(adult_rules.sorted) plot(adult_rules, method = "graph") adult_rules <- apriori(Adult, parameter = list(supp=0.35, conf=0.8, minlen=2, target="rules"), appearance = list(rhs=c(“income=small", “income=large"), default="lhs")) adult_rules.sorted <- sort(adult_rules, by="lift"); inspect(adult_rules.sorted)
연관분석 중복 규칙이 다수 존재
연관분석 집합X의 각 원소(규칙)이 집합Y에 포함되는 규칙이 있다면 TRUE, 아니면 FALSE를 리턴 중복 규칙의 제거 # find redundant rules subset.matrix <- is.subset(adult_rules.sorted, adult_rules.sorted) subset.matrix[lower.tri(subset.matrix, diag=T)] <- NA redundant <- colSums(subset.matrix, na.rm=T) >= 1 which(redundant) # remove redundant rules adult_rules.pruned <- adult.rules.sorted[!redundant] inspect(adult_rules.pruned) plot(adult_rules, method = "graph") TRUE이면 TRUE가 저장
중복규칙의 제거 T ... T ... T ... T T T ... ... ... T ... T T T ... T is.subset 함수를 통해 얻은 matrix
연관분석