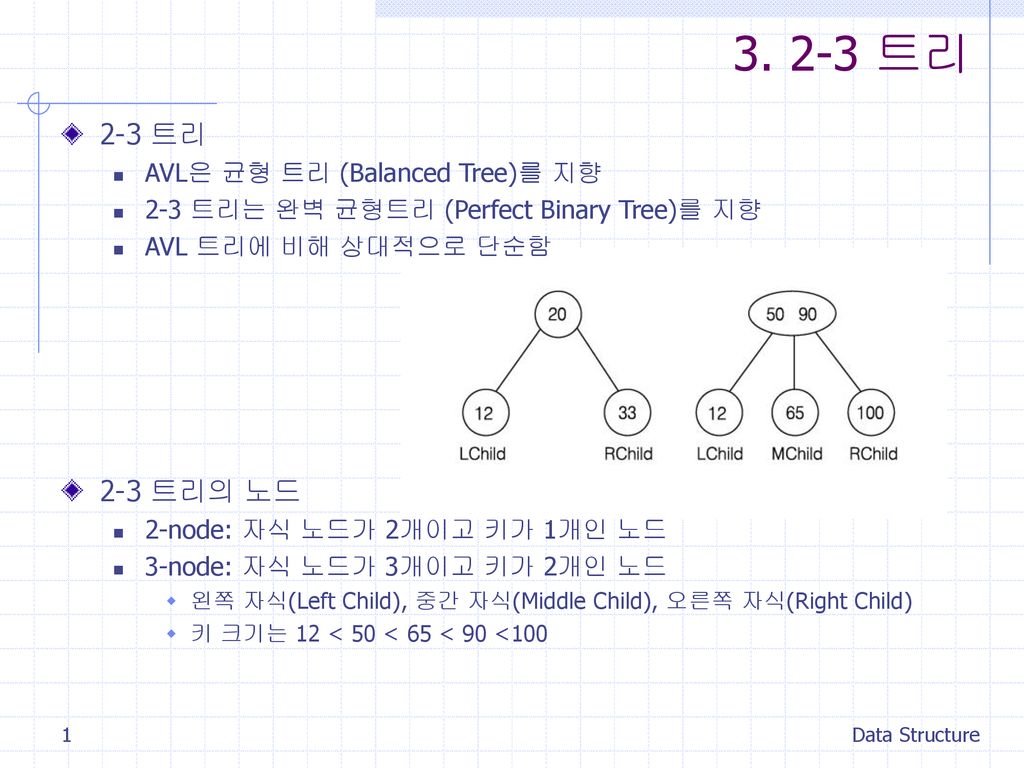
3. 2-3 트리 2-3 트리 2-3 트리의 노드 AVL은 균형 트리 (Balanced Tree)를 지향 2-3 트리는 완벽 균형트리 (Perfect Binary Tree)를 지향 AVL 트리에 비해 상대적으로 단순함 2-3 트리의 노드 2-node: 자식 노드가 2개이고 키가 1개인 노드 3-node: 자식 노드가 3개이고 키가 2개인 노드 왼쪽 자식(Left Child), 중간 자식(Middle Child), 오른쪽 자식(Right Child) 키 크기는 12 < 50 < 65 < 90 <100 Data Structure
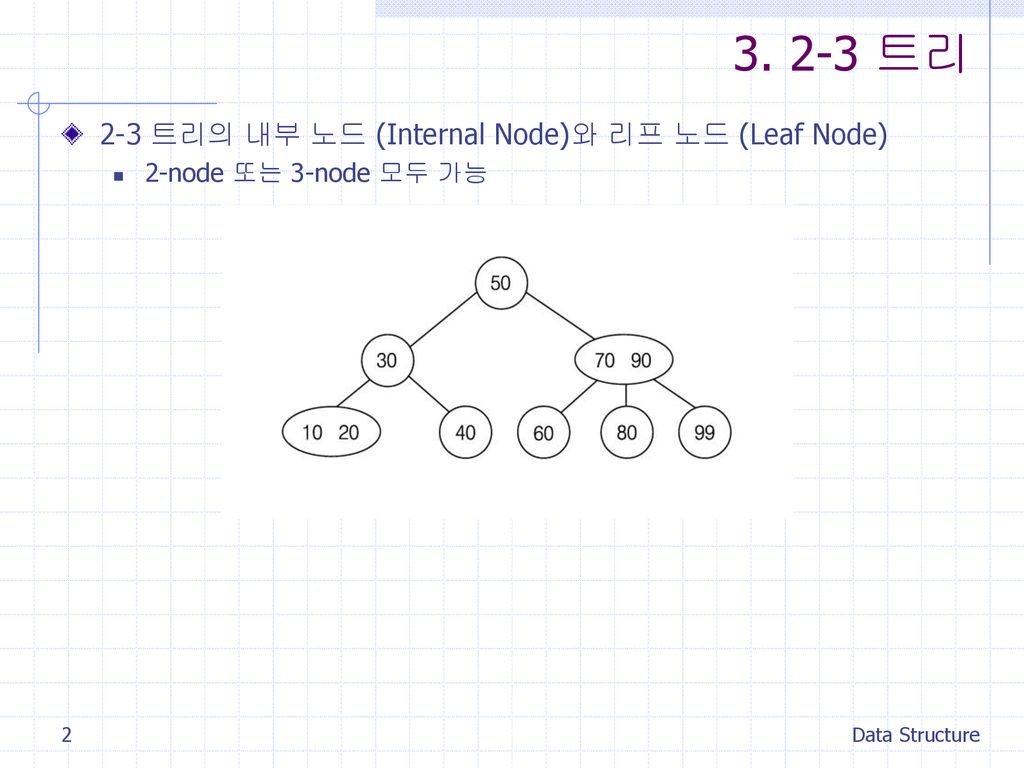
3. 2-3 트리 2-3 트리의 내부 노드 (Internal Node)와 리프 노드 (Leaf Node) 2-node 또는 3-node 모두 가능 Data Structure
3. 2-3 트리 2-3 트리에서의 삽입 항상 Leaf Node로 삽입된다. 해당 Leaf Node가 2-node라면 3-node로 만든다. 부모가 2-node 이므로 중간 값에 해당하는 39를 promote 하면서 부모 노드를 3-node로 변경한다. (Promote Middle) Promote Middle이 발생하면 그 중간 값이 있던 원 노드가 분리된다. 항상 Leaf Node로 삽입된다. 해당 Leaf Node가 2-node라면 3-node로 만든다. Data Structure
3. 2-3 트리 2-3 트리에서의 삽입 (Cont.) Promote Middle Promote Middle Data Structure
3. 2-3 트리 2-3 트리 에서의 삽입 (Cont.) Promote Middle Promote Middle Data Structure
3. 2-3 트리 2-3 트리에서 삽입예 II 5 12 5 12 2 8 17 2 4 8 17 Data Structure
Promote Middle & Split node Promote Middle & Split node 3. 2-3 트리 2-3 트리에서 삽입예 II 5 5 12 2 12 1 2 4 8 17 1 4 8 17 Promote Middle & Split node 2 5 12 Promote Middle & Split node 1 4 8 17 Data Structure
3. 2-3 트리 2-3 트리에서 삽입에 의한 높이 증가 BST vs. 2-3 트리 반복된 삽입에도 2-3 트리의 높이는 좀처럼 증가하지 않음. 3-노드를 사용해서 최대한 레코드를 수용. BST vs. 2-3 트리 BST에서는 삽입할 때마다 리프 노드 아래로 1만큼 자라나는 확률이 큼 높이 증가가 자주 일어남 2-3 트리의 높이는 삽입노드로부터 루트노드까지 경로가 3-노드로 꽉 찬 경우에 한해서 루트 위쪽으로 1만큼 자람. Data Structure
3. 2-3 트리 삭제 후 자신의 노드가 비면 반드시 자매노드 중 3-node가 있는 지 확인하여 빌려와 채운다 2-3 트리에서의 삭제 I [Rule of Thumb] 자매 노드로 부터 빌려와 채우기를 할 때 반드시 부모를 거쳐서 빌려온다. 즉, 자매노드 값은 부모로 가고 부모노드의 값이 내려온다. 삭제 후 자신의 노드도 비워지고 더 이상 빌려올 3-node 자매노드가 없다면 부모노드는 2-node가 되어야 한다. 즉, 부모 노드는 자식 노드쪽으로 1개의 key 값을 내려준다. 삭제 후 자신의 노드가 비면 반드시 자매노드 중 3-node가 있는 지 확인하여 빌려와 채운다 Data Structure
3. 2-3 트리 2-3 트리에서의 삭제 II 자매 노드로 부터 빌려와 채울 수가 없음 자매 노드로 부터 빌려와 채울 수가 없음 2-3 트리에서의 삭제 II 더 이상 2-node로 유지할 수 없음, 자식 노드와 합침 자매 노드로 부터 빌려와 채울 수가 없음 더 이상 2-node로 유지할 수 없음, 자식 노드와 합침 2-node로서 올바르게 유지하기 위하여 다른 자식 노드를 가지고 온다. Data Structure
3. 2-3 트리 2-3 트리의 구현시 고려점 일반적으로 이진 트리는 부모노드로부터 자식노드로 가는 포인터만 유지 삽입, 삭제를 위해서는 어떤 노드의 부모노드를 접근해야 함. 삽입 시에 중간 키를 올리기 위해서, 또 삭제 시에 부모 노드의 키를 아래로 내리기 위해서 부모 노드로 접근하는 포인터가 필요 구현 방법 1 모든 노드마다 부모 노드를 가리키는 포인터를 가지게 함 구현 방법 2 임의의 함수 내에서 Stack을 하나 생성하고, Root로부터 내려가면서 만나는 모든 노드를 가리키는 포인터 값을 계속적으로 Stack 에 Push해 놓으면 Pop에 의해 직전의 부모노드를 접근할 수 있음. Data Structure
3. 2-3 트리 2-3 트리의 탐색효율 모든 노드가 3-node일 때 가장 높이가 낮으며, 트리 높이 h는 최대 레벨 수와 일치하므로 결과적으로 h ≈ log3N 최악의 경우는 모든 노드가 2-node로서 트리의 높이 h ≈ log2N 2-3 트리에는 2-ndoe와 3-node가 섞여 있으므로 효율은 O(log2N)과 O(log3N) 사이에 존재. BST는 최악의 경우 O(N)으로 전락 2-3 트리는 항상 완전 균형트리를 유지하므로 최악의 경우에도 탐색 효율을 보장 Data Structure
3. 2-3 트리 2-3 트리의 단점 Faster searching? Easier to keep balanced? 3-node는 비교해야 할 키가 2 개이므로 비교의 횟수가 증가 3-ndoe는 자식을 가리키는 포인터가 3개 이므로 자식 노드가 없다면 2-node 에 비해 널 포인터가 차지하는 공간적 부담 널 포인터는 리프 노드에 다수가 분포 Faster searching? Actually, no. 2-3 tree is about as fast as an “equally balanced” binary tree, because you sometimes have to make 2 comparisons for a 3-node Easier to keep balanced? Yes, definitely. Insertion can split 3-nodes into 2-nodes, or promote 2-nodes to 3-nodes to keep tree approximately balanced! Data Structure
키 값의 크기는 10 < 30 < 65 < 75 < 80 < 95 < 100 4. 2-3-4 트리 2-3-4 트리 2-node 3-node 4-node: 자식 노드가 4개이고 키가 3개인 노드 왼쪽 자식(Left Child) 오른쪽 자식(Right Child) 왼쪽 중간자식(Left Middle Child) 오른쪽 중간자식(Right Middle Child) 키 값의 크기는 10 < 30 < 65 < 75 < 80 < 95 < 100 Data Structure
4. 2-3-4 트리 2-3-4 트리는 2-3 트리의 단순한 확장 (전체 트리의 높이만 조금 낮추는 효과) 인가 ? No! 단점도 많음 Leaf노드 근처의 널 포인터 공간이 2-3 트리에 비해서 더 많아 짐. 필요시 최대 3개의 키를 비교해야 하는 시간적 부담. 2-3-4 트리는 4-node deleting 작업에 의하여 삽입에 의한 double promote 가 일어나지 않음 삽입 방법 (Single-Pass Insertion) 삽입위치를 찾아서 루트로부터 내려가는 도중에 4-node를 만나면 무조건 제거하면서 내려감. 실제 삽입은 Leaf Node에 해당 값을 간단하게 추가만 하면 됨 반면에, 2-3 트리에서는 한번 삽입에 의하여 “promote middle” 현상이 연속하여 계속 일어나는 일이 존재 (Double-Pass Insertion) Data Structure
4. 2-3-4 트리 4-node deleting 작업 1) 루트가 4-node인 경우 중간 키인 Y가 올라가서 트리 높이 증가 2) 내려가면서 만난 4-node가 2-node의 자식노드일 경우. 중간 키를 올리되, 나머지 키들은 분리되어 부모노드의 왼쪽 자식과 중간 자식으로 붙게 됨. 높이는 그대로 유지. 3) 내려가면서 만난 4-node가 3-node의 자식노드일 경우. 부모 노드가 4-node로 바뀌면서 왼쪽 중간자식, 오른쪽 중간자식 으로 분리시켜 붙임. Data Structure
5. 레드 블랙 트리 레드 블랙 트리 (Red-Black Tree) 2-3-4 트리를 이진트리로 표현한 것 원래는 각 노드가 Black Node, Red Node로 나뉘어 짐 구현의 용이성을 위하여 레드 블랙 트리의 링크(Link)가 색깔을 지니게 함 Data Structure
5. 레드 블랙 트리 레드 블랙 트리 (Red-Black Tree) typedef struct { int key; Node struct 구성 방법 키에 해당하는 데이터 필드 LChild 포인터, RChild 포인터 각 포인터 변수에 색깔 속성을 추가하기 위하여 LColor, Rcolor (Boolean) 변수 색깔 변수 하나만 사용하려면 부모노드로부터 자신을 향한 포인터의 변수를 표시 typedef struct { int key; node* LChild; node* RChild; int LColor; int RColor; } node; typedef node* Nptr; typedef struct { int key; node* LChild; node* RChild; int Color; } node; typedef node* Nptr; vs. Data Structure
5. 레드 블랙 트리 2-3-4 Tree RB Tree 변환 모든 2-3-4 트리는 레드 블랙 트리로 표현 가능 2-node는 그대로. 3-node는 왼쪽 또는 오른쪽 키를 루트로 하는 이진트리로. 따라서 트리 모양이 유일하지는 않음. 4-node의 레드 블랙 표현은 유일함. 빨강 링크는 원래 3-node, 4-node에서 같은 노드에 속했었다는 사실을 나타냄. Data Structure
5. 레드 블랙 트리 RB Tree의 속성 1) 트리를 내려오면서 빨강 링크 2개가 연속적으로 나올 수 없다. 2) 임의의 노드로부터 같은 레벨에 위치한 후손노드까지 검정 링크의 수는 모두 동일하다. 3) 2개의 자식노드가 모두 빨강 링크일 때만 4-노드에 해당한다 이것만 허용됨 Data Structure
5. 레드 블랙 트리 RB Tree가 사용되는 이유 2-3-4 트리의 단점 RB Tree는 BST의 함수를 거의 그대로 사용 복잡한 노드 구조 복잡한 삽입, 삭제 코딩의 복잡 RB Tree는 BST의 함수를 거의 그대로 사용 2-3-4 트리의 장점인 단일 패스 삽입/삭제 (Single Pass Insertion/Delete) 가 그대로 레드 블랙 트리에도 적용. Data Structure
5. 레드 블랙 트리 단순한 4-node deleting 작업 Case 1) (a')의 레드 블랙 트리는 구조적으로 이미 처음부터 (b)의 모양이 갖춰져 있음 링크의 색깔만 빨강에서 검정으로 뒤집음 (Color Flip: 색상 반전) Data Structure
5. 레드 블랙 트리 단순한 4-node deleting 작업 Case 2) (a)를 나타내는 레드 블랙 트리는 (a') 키 X를 중심으로 부모와 자식의 링크 색상을 반전. (b')을 루트를 중심으로 오른쪽으로 회전시켜 (b’’)를 만들어도 동일한 2-3-4 트리를 나타냄 Data Structure
5. 레드 블랙 트리 단순한 4-node deleting 작업 Case 3) 4-노드인 W를 중심으로 부모와 자식 링크에 대해 색상을 반전 Z-Y-W로 이어지는 빨강 링크가 연속으로 2개 연속적인 2개의 빨강 링크를 허용하지 않으므로 이를 피하기 위해 회전(RR Rotation)을 가함. Data Structure
5. 레드 블랙 트리 RB Tree의 삽입과 트리 구성 2개의 Red 링크가 연속되므로 회전 [Rule of Thumb] 새로운 노드 추가시에는 부모의 Red 노드로서 추가됨 회전의 결과 RB Tree의 올바른 4-node 표시가 됨 RB Tree 속성 2)에 의하여 LChild도 Red로 변경 40이 추가될 때 연속된 Red 링크 출현. 회전에 의하여도 해결이 안됨. 그러면, 색깔 반전!!! 2개의 Red 링크가 연속됨. 회전에 의하여 해결 가능 60이 추가될 때 연속된 Red 링크 출현. 회전에 의하여도 해결이 안됨. 그래서, 색깔 반전이 필요 Data Structure
5. 레드 블랙 트리 이전 페이지에서 BST 인 경우 RB Tree 탐색 효율 MUST READ BST의 높이는 거의 O(log2N)에 근접 레드 블랙 트리는 회전에 의해서 어느 정도 균형을 이룸. AVL은 회전시기를 판단하기 위해 복잡한 코드 실행. 회전방법 역시 복잡한 코드 실행. 그에 따를 실행시간 증가 레드 블랙 트리는 빨강 링크의 위치만으로 회전시기를 쉽게 판단, 회전방법도 간단. 하지만, 탐색 성능은 AVL이 더 빠름. 이유는? MUST READ http://kldp.org/node/3175 Data Structure
6. B-트리 B-트리(B-Tree) 외부 탐색(External Search) 방법에 B-Tree를 이용 2-3 트리, 2-3-4 트리 개념의 확장 최대 링크 수가 M 개인 트리 M이 커질수록 하나의 노드 내부에서 비교의 횟수가 증가하고 또, 빈 포인터 공간도 많아지지만 트리의 높이는 그만큼 낮아진다. 외부 탐색(External Search) 방법에 B-Tree를 이용 외부 저장장치인 파일로부터 찾는 레코드를 읽어오기 위함. 데이터 베이스 탐색방법의 일종 파일로부터 메인 메모리로 읽혀지는 기본 단위를 페이지(Page)라 함. 외부 탐색에서 알고리즘의 효율을 좌우하는 것은 입출력 시간 입출력 시간은 페이지를 몇 번 입출력 했는가에 좌우 즉, 외부 탐색은 입출력 횟수를 줄이는 것에 주안점을 둠 M 웨이 트리(M-way Tree): 모든 노드의 자식이 M개인 트리 Data Structure
6. B-트리 B-트리와 메모리, 디스크 모습 외부 입출력이 일어나는 횟수 = 트리의 높이+1 처음에 루트 노드는 메인 메모리에 올려 놓고 탐색 시작 포인터는 디스크 번호와 페이지 번호로 표시. 루트의 LChild인 노드 B는 디스크 1번의 페이지 0에 저장. 외부 입출력이 일어나는 횟수 = 트리의 높이+1 Data Structure
6. B-트리 검색 효율 B-트리의 변형 2-노드, 3-노드, ..., M-노드를 모두 감안하면 평균적인 링크 수는 M/2 O(log(M/2)N) B-트리의 변형 레코드 자체가 차지하는 공간으로 인해 하나의 노드 즉, 하나의 페이지 안에 들어갈 수 있는 레코드 수가 제한됨. 자식노드를 가리키는 포인터 수가 제한됨. 레코드 크기가 커질수록 한 페이지에 많은 내용을 넣을 수 없음. 하나의 노드가 가질 수 있는 자식의 수인 M 값이 작아지면… 트리의 높이가 커지고 입출력(Page I/O) 횟수가 증가함. 트리를 따라 내려오면서 만나는 페이지가 많아짐 그래서… 내부노드에는 key 값만 넣고, 실제 레코드는 리프 노드 에 몰아 넣음. 리프 노드는 외부 저장 장치에 있음 내부노드의 key는 리프 노드의 레코드를 찾기 위한 일종의 인덱스로 기능을 수행 M의 값을 대폭 증가하여 트리 높이를 대폭 감소시킴. Data Structure
6. B-트리 B-Tree Example Data Structure
6. B-트리 고정된 M을 사용 레벨별 M 값의 변화 B-Tree M-way Tree 1, M, M2, M3...으로 기하급수적으로 늘어남. 레코드가 몇 개 없는 페이지, 사용되지 않는 페이지로 인한 공간낭비 사용이 잘 안됨 레벨별 M 값의 변화 B-Tree 트리의 위에서 아래로 내려오면서 검색범위를 적절히 축소. 루트 근처의 M 값을 2048, 리프 근처의 M 값은 1024로 했을 때, 10억 개의 레코드에 대해서 3번 정도의 페이지 입출력으로 끝낼 수 있음. 211 210 210 = 231 = 2,147,483,648 (약 20억) Data Structure