Download presentation
1
이혁재 /KASA 2010.08.14 NoSQL

2
요약 NoSQL 소개 데이타베이스 관련 문서 대상 : 클라이언트 프로그래머 NoSQL 소개 데이타베이스 관련 문서 대상 : 클라이언트 프로그래머

3
Online game 에서의 데이터저장소 File ( ISAM ) DBMS – mysql – mssql – oracle – memory DB File ( ISAM ) DBMS – mysql – mssql – oracle – memory DB
 DBMS – mysql – mssql – oracle – memory DB File ( ISAM ) DBMS – mysql – mssql – oracle – memory DB")
4
NoSQL NO SQL ? Not Only SQL ! 클래식한 rdb 와 다른 database( or datastore ) 학계에서는 structured storage 라는 용어를 사용 NO SQL ? Not Only SQL ! 클래식한 rdb 와 다른 database( or datastore ) 학계에서는 structured storage 라는 용어를 사용
 학계에서는 structured storage 라는 용어를 사용 NO SQL . Not Only SQL . 클래식한 rdb 와 다른 database( or datastore ) 학계에서는 structured storage 라는 용어를 사용.")
5
NoSQL

6
why NoSQL? 기존 RDB 에서의 해결할 수 없는 문제가 생김 Massive Data 에서 낮은 성능 – 대규모 문서를 indexing – 높은 트래픽의 웹사이트에서 데이타를 표시 – streaming 미디어를 전달 하드웨어 장애와 자동화된 복구 Data Model 이 문제 - Schema free RDBMS 를 사용하는 것보다 구현이 간단한 경우 기존 RDB 에서의 해결할 수 없는 문제가 생김 Massive Data 에서 낮은 성능 – 대규모 문서를 indexing – 높은 트래픽의 웹사이트에서 데이타를 표시 – streaming 미디어를 전달 하드웨어 장애와 자동화된 복구 Data Model 이 문제 - Schema free RDBMS 를 사용하는 것보다 구현이 간단한 경우

7
why NoSQL? ( twitter 의 문제 ) 7 TB/day ( 2+ PB/yr) 저장 = 10,000 CDs/day = 초당 80MB 7 TB/day ( 2+ PB/yr) 저장 = 10,000 CDs/day = 초당 80MB
 7 TB/day ( 2+ PB/yr) 저장 = 10,000 CDs/day = 초당 80MB 7 TB/day ( 2+ PB/yr) 저장 = 10,000 CDs/day = 초당 80MB.")
8
why NoSQL? ( facebook 의 문제 ) 5700 억 view / month 다른 모든 사진 사이트 (flickr 포함 ) 를 합친 것보다 많은 사진을 서비스 30 억 photo upload / month 5700 억 view / month 다른 모든 사진 사이트 (flickr 포함 ) 를 합친 것보다 많은 사진을 서비스 30 억 photo upload / month
 5700 억 view / month 다른 모든 사진 사이트 (flickr 포함 ) 를 합친 것보다 많은 사진을 서비스 30 억 photo upload / month 5700 억 view / month 다른 모든 사진 사이트 (flickr 포함 ) 를 합친 것보다 많은 사진을 서비스 30 억 photo upload / month.")
9
NoSQL 의 특징 테이블 스키마 없음 ( item 저장에 좋을 수도 ? ) join 오퍼레이션 없음 ( relation 이 없다. ) 컴퓨터를 늘려서 규모 가변적 내부구조 : 분산 hash table distributed key-value pair 나 assocative arrays 인터페이스 poor ACID( Atomic Consistency Isolation Durability ) 부수효과 : app 개발 생산성 open source 테이블 스키마 없음 ( item 저장에 좋을 수도 ? ) join 오퍼레이션 없음 ( relation 이 없다. ) 컴퓨터를 늘려서 규모 가변적 내부구조 : 분산 hash table distributed key-value pair 나 assocative arrays 인터페이스 poor ACID( Atomic Consistency Isolation Durability ) 부수효과 : app 개발 생산성 open source
 컴퓨터를 늘려서 규모 가변적 내부구조 : 분산 hash table distributed key-value pair 나 assocative arrays 인터페이스 poor ACID( Atomic Consistency Isolation Durability ) 부수효과 : app 개발 생산성 open source 테이블 스키마 없음 ( item 저장에 좋을 수도 . ) join 오퍼레이션 없음 ( relation 이 없다. ) 컴퓨터를 늘려서 규모 가변적 내부구조 : 분산 hash table distributed key-value pair 나 assocative arrays 인터페이스 poor ACID( Atomic Consistency Isolation Durability ) 부수효과 : app 개발 생산성 open source.")
10
분류 Key-value stores Document Database Wide column stores Graph databases Key-value stores Document Database Wide column stores Graph databases

11
분류

12
분류 ( Key-value stores ) 하나의 키, 하나의 값, 중복없음, 빠름 value 는 binary 하나의 키, 하나의 값, 중복없음, 빠름 value 는 binary
 하나의 키, 하나의 값, 중복없음, 빠름 value 는 binary 하나의 키, 하나의 값, 중복없음, 빠름 value 는 binary")
13
분류 ( Document Database ) key-value 이지만 structred value data 에 대해서 query 할 수 있음 key-value 이지만 structred value data 에 대해서 query 할 수 있음
 key-value 이지만 structred value data 에 대해서 query 할 수 있음 key-value 이지만 structred value data 에 대해서 query 할 수 있음")
14
분류 ( Wide column stores ) sparse, distributed multi-dimensional sorted map Google BigTable, Cassandra … sparse, distributed multi-dimensional sorted map Google BigTable, Cassandra …
 sparse, distributed multi-dimensional sorted map Google BigTable, Cassandra … sparse, distributed multi-dimensional sorted map Google BigTable, Cassandra …")
15
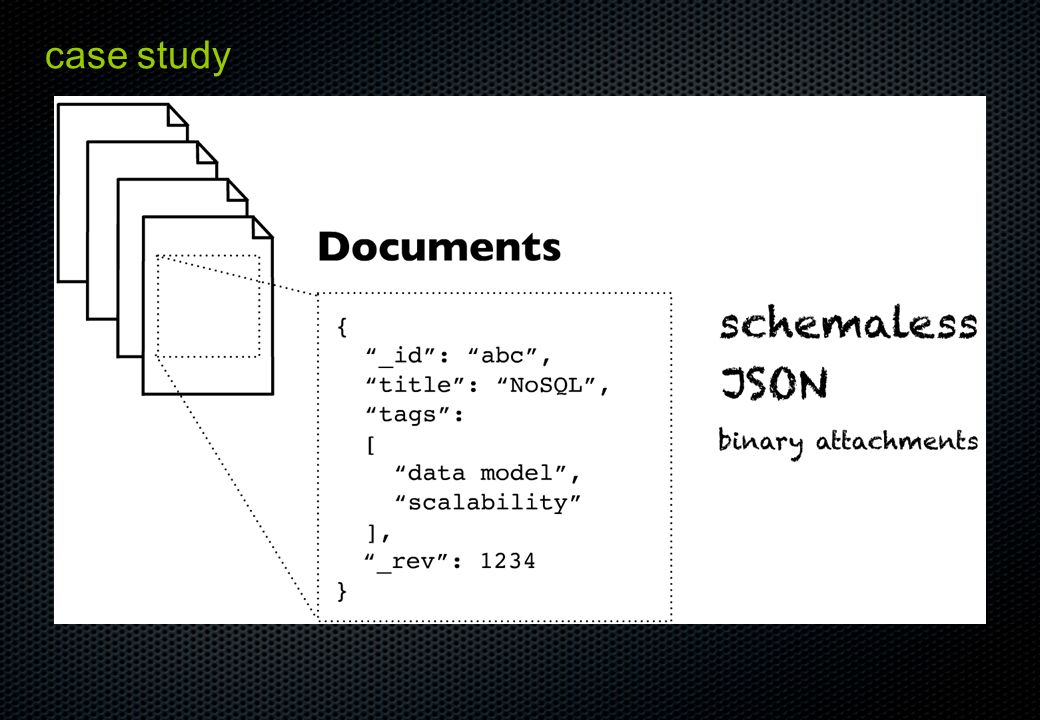
분류 ( Graph databases ) 데이터의 관계 ( 그래프 ) 를 저장하는 용도
 데이터의 관계 ( 그래프 ) 를 저장하는 용도")
16
case study

20
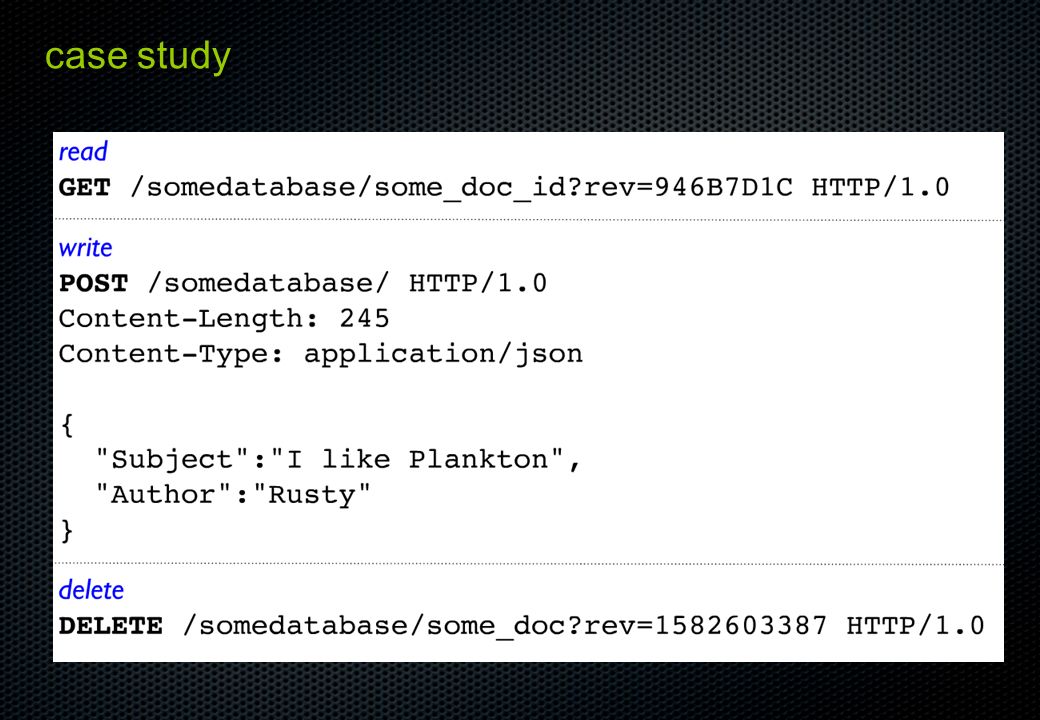
SQL 같은 질의는 어떻게 하는가 ? DBMS( SQL ) – SELECT `column` FROM `table` WHERE `id` = key; API – BigTable table.get(key, "column_family:column") – Cassandra keyspace.get("column_family", key, "column") Query-language MapReduce DBMS( SQL ) – SELECT `column` FROM `table` WHERE `id` = key; API – BigTable table.get(key, "column_family:column") – Cassandra keyspace.get("column_family", key, "column") Query-language MapReduce
 – SELECT `column` FROM `table` WHERE `id` = key; API – BigTable table.get(key, column_family:column ) – Cassandra keyspace.get( column_family , key, column ) Query-language MapReduce DBMS( SQL ) – SELECT `column` FROM `table` WHERE `id` = key; API – BigTable table.get(key, column_family:column ) – Cassandra keyspace.get( column_family , key, column ) Query-language MapReduce.")
21
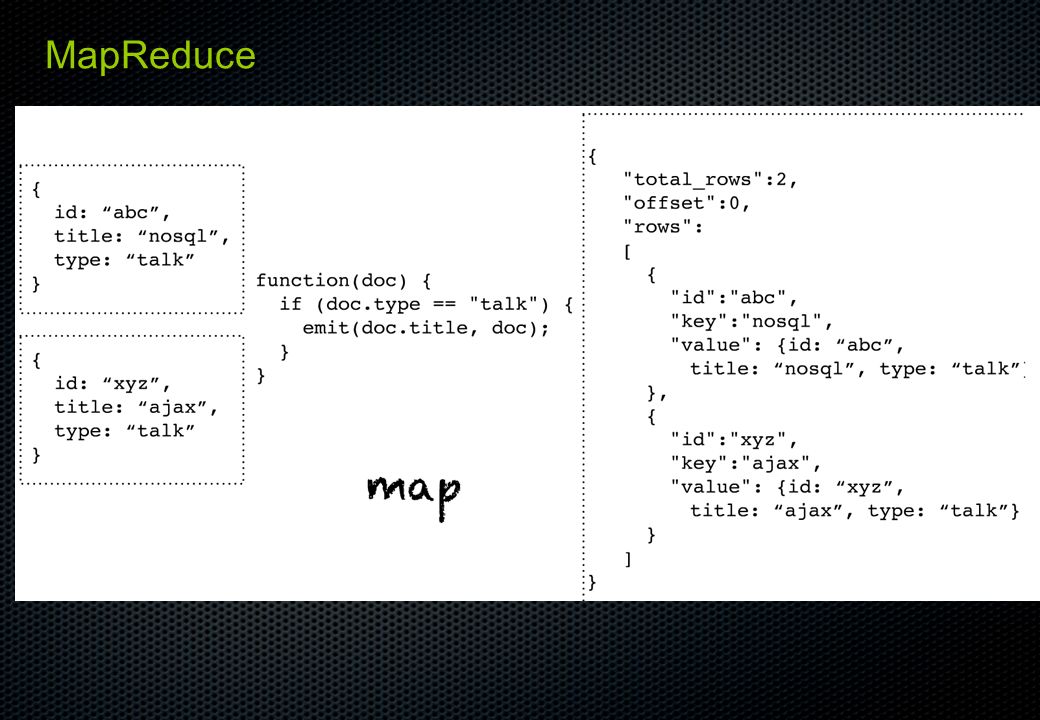
google 의 search 엔진에서 사용 – 논문 Simplified Data Processing On Large Cluster 데이터 처리 기술 – 프로그래밍 모델과 그 구현 함수형 프로그래밍에서 유래 google 의 search 엔진에서 사용 – 논문 Simplified Data Processing On Large Cluster 데이터 처리 기술 – 프로그래밍 모델과 그 구현 함수형 프로그래밍에서 유래

22
MapReduce

25
twitter 의 해결책 ( NoSQL 과 연관 없는 것도 포함 ) log 문제 – 처음엔 syslog 사용 – 크기가 커짐에 따라 scale 이 안됨 – 데이타를 잃어버림 log 문제 – 처음엔 syslog 사용 – 크기가 커짐에 따라 scale 이 안됨 – 데이타를 잃어버림
 log 문제 – 처음엔 syslog 사용 – 크기가 커짐에 따라 scale 이 안됨 – 데이타를 잃어버림 log 문제 – 처음엔 syslog 사용 – 크기가 커짐에 따라 scale 이 안됨 – 데이타를 잃어버림")
26
twitter 의 해결책 scribe – FB 도 같은 문제를 겪음, open-source – 로그를 분류를 갖추어 쓰면 나머지는 알아서 scribe 가 모아줌 – twitter 개발자도 개발에 기여 – http://github.com/facebook/scribe scribe – FB 도 같은 문제를 겪음, open-source – 로그를 분류를 갖추어 쓰면 나머지는 알아서 scribe 가 모아줌 – twitter 개발자도 개발에 기여 – http://github.com/facebook/scribe

27
twitter 의 해결책 Hadoop – 7TB/day 를 어떻게 쓸 것인가에서 시작 – 자동화된 복제와 오류복구 – MapReduce-based – 1TB 임의의 정수 데이타를 62 초에만에 정렬 – 평판, pagerank, 관계계산에 사용 – 5 분만에 120 억 tweet 을 count – 트위터 엔지니어들이 LZO 로 압축저장하게 기여함 http://github.com/kevinweil/hadoop-lzo Hadoop – 7TB/day 를 어떻게 쓸 것인가에서 시작 – 자동화된 복제와 오류복구 – MapReduce-based – 1TB 임의의 정수 데이타를 62 초에만에 정렬 – 평판, pagerank, 관계계산에 사용 – 5 분만에 120 억 tweet 을 count – 트위터 엔지니어들이 LZO 로 압축저장하게 기여함 http://github.com/kevinweil/hadoop-lzo

28
twitter 의 해결책 Pig – SQL 보다 쉬운 데이타 처리 언어 – 데이타 분석에 사용 어떤 기능이 유저를 낚이게 하는가 ? 확률적 봇 탐지 – http://hadoop.apache.org/pig/ Pig – SQL 보다 쉬운 데이타 처리 언어 – 데이타 분석에 사용 어떤 기능이 유저를 낚이게 하는가 ? 확률적 봇 탐지 – http://hadoop.apache.org/pig/

29
twitter 의 해결책 Pig sample

30
twitter 의 해결책 HBase – BigTable 의 clone ( HDFS 위에서 동작 ) – Find People 기능에 사용 – 많은 기능이 HBase 사용하여 구축되어지고 있음 – cassandra 와 비교됨 cassandra - 낮은 지연시간에 강점 HBase - 배치작업에 강점 – http://hbase.apache.org HBase – BigTable 의 clone ( HDFS 위에서 동작 ) – Find People 기능에 사용 – 많은 기능이 HBase 사용하여 구축되어지고 있음 – cassandra 와 비교됨 cassandra - 낮은 지연시간에 강점 HBase - 배치작업에 강점 – http://hbase.apache.org
 – Find People 기능에 사용 – 많은 기능이 HBase 사용하여 구축되어지고 있음 – cassandra 와 비교됨 cassandra - 낮은 지연시간에 강점 HBase - 배치작업에 강점 – HBase – BigTable 의 clone ( HDFS 위에서 동작 ) – Find People 기능에 사용 – 많은 기능이 HBase 사용하여 구축되어지고 있음 – cassandra 와 비교됨 cassandra - 낮은 지연시간에 강점 HBase - 배치작업에 강점 –")
31
twitter 의 해결책 FlockDB – 유저 간의 follow 관계 그래프 디비 – 일반적 rdb 로는 어려움이 많아서 자체 제작 join 으로 해결안됨 join 하려해도 메모리도 문제 – http://github.com/twitter/flockdb FlockDB – 유저 간의 follow 관계 그래프 디비 – 일반적 rdb 로는 어려움이 많아서 자체 제작 join 으로 해결안됨 join 하려해도 메모리도 문제 – http://github.com/twitter/flockdb

32
twitter 의 해결책 Cassandra – tweet 저장에 사용 – facebook 에서 만듬 – 예전 시스템 MySQL 로 분할 저장 memcached( consistency 문제가 생김, 복제 문제도 생김 ) application 에서도 처리해야 함 테이블을 고칠 수 없음 땜방이 필요 MySQL 의 write 한계에 종종 도달 – cassandra 를 사용하니 모두 해결 !!! – http://cassandra.apache.org Cassandra – tweet 저장에 사용 – facebook 에서 만듬 – 예전 시스템 MySQL 로 분할 저장 memcached( consistency 문제가 생김, 복제 문제도 생김 ) application 에서도 처리해야 함 테이블을 고칠 수 없음 땜방이 필요 MySQL 의 write 한계에 종종 도달 – cassandra 를 사용하니 모두 해결 !!! – http://cassandra.apache.org
 application 에서도 처리해야 함 테이블을 고칠 수 없음 땜방이 필요 MySQL 의 write 한계에 종종 도달 – cassandra 를 사용하니 모두 해결 !!. –")
33
facebook 의 해결책 Cassandra, Scribe, HADOOP 은 twitter 와 동일 PHP, Linux, MySQL – 모두 facebook 에 맞추어 변경 또는 최적화 Cassandra, Scribe, HADOOP 은 twitter 와 동일 PHP, Linux, MySQL – 모두 facebook 에 맞추어 변경 또는 최적화

34
facebook 의 해결책 Memcached – 웹서버와 MySQL 서버 cache layer – distributed memory cache – http://memcached.org Memcached – 웹서버와 MySQL 서버 cache layer – distributed memory cache – http://memcached.org

35
facebook 의 해결책 HipHop – PHP 를 C++ 로 convert, g++ compile 해서 바이너리로 만들어줌 – 웹 서버의 평균 CPU 사용량을 50% 정도 다운 – http://github.com/facebook/hiphop-php HipHop – PHP 를 C++ 로 convert, g++ compile 해서 바이너리로 만들어줌 – 웹 서버의 평균 CPU 사용량을 50% 정도 다운 – http://github.com/facebook/hiphop-php

36
facebook 의 해결책 Haystack – 건초 더미 ? – Photo Infrastructure HTTP server ( libevent 안의 프로그램 내장형 http 서버 ) Photo Store Haystack Object Store Filesystem Storage Haystack – 건초 더미 ? – Photo Infrastructure HTTP server ( libevent 안의 프로그램 내장형 http 서버 ) Photo Store Haystack Object Store Filesystem Storage
 Photo Store Haystack Object Store Filesystem Storage Haystack – 건초 더미 . – Photo Infrastructure HTTP server ( libevent 안의 프로그램 내장형 http 서버 ) Photo Store Haystack Object Store Filesystem Storage.")
37
facebook 의 해결책 BigPipe – 웹페이지를 pagelet 이라는 단위로 쪼개서 처리하는 server side system – 병렬적으로 pagelet 을 처리 BigPipe – 웹페이지를 pagelet 이라는 단위로 쪼개서 처리하는 server side system – 병렬적으로 pagelet 을 처리

38
facebook 의 해결책 Thrift – 서로 다른 언어를 사용한 개발을 가능하게 해줌 – software framework – RPC 서버와 클라이언트를 생성해줌 – http://incubator.apache.org/thrift/ – facebook 은 C++, Erlang, Java, Python, PHP 등을 백앤드에서 사용 Thrift – 서로 다른 언어를 사용한 개발을 가능하게 해줌 – software framework – RPC 서버와 클라이언트를 생성해줌 – http://incubator.apache.org/thrift/ – facebook 은 C++, Erlang, Java, Python, PHP 등을 백앤드에서 사용

39
reference http://en.wikipedia.org/wiki/NoSQL http://www.slideshare.net/kevinweil/nosql-at-twitter- nosql-eu-2010d8 http://royal.pingdom.com/2010/06/18/the-software- behind-facebook/ http://www.slideshare.net/mmarth/no-sql-3657930 http://www.slideshare.net/harrikauhanen/nosql- 3376398 http://enzine.tistory.com/entry/HipHop-for-PHP- 더 - 빠른 -PHP 를 - 위해 http://en.wikipedia.org/wiki/NoSQL http://www.slideshare.net/kevinweil/nosql-at-twitter- nosql-eu-2010d8 http://royal.pingdom.com/2010/06/18/the-software- behind-facebook/ http://www.slideshare.net/mmarth/no-sql-3657930 http://www.slideshare.net/harrikauhanen/nosql- 3376398 http://enzine.tistory.com/entry/HipHop-for-PHP- 더 - 빠른 -PHP 를 - 위해

40
Q&A




 서비스 사업부 / 기술지원팀. 목차 구조 일반적 특징 객체지향 특징 ORDB 개념을 이용한 스키마 ORDB 개념을 이용한 질의.>")

 201440130 장수용. MYSQL 이란 ? -MySQL 은 DBMS( 데이터베이스 관리 시스템 ) 이다. - MySQL 은 RDBMS( 관계형 데이터베이스 ) 이다. - MySQL 은 오픈소스이다. - MySQL 은 빠르고, 안정적이고.>")


 한국에스리 고객지원센터.>")

 II. Requirement Prioritization III. AHP(Analytical Hierarchy Process) IV. Requirement Negotiation Q & A.>")





 Hadoop Distributed File System (HDFS) Zookeeper (Coordination) Hbase (Column.>")





