Download presentation
1
데이터 마이닝을 이용한 분류 분석

2
판별분석

3
판별분석 (DISCRIMINANT ANALYSIS)
사용목적(분석-분류분석-판별분석) - 판별분석은 일정한 특성 즉, 종속변수를 기준으로 모집단을 상호 배반관계(mutually exclusive)에 있는 2개 또는 그 이상의 집단으로 분류하는 통계적 기법 - 어느 집단에 속하는지 구별하는데 도움을 줄수 있는 판별변수들을 독립변수 중에서 선택 - 판별함수에 의해 집단들이 얼마나 정확하게 구별할 수 있는지의 정도를 나타냄 - 예 : 정당의 공천심사, 은행의 대출심사, 신용보증기금 및 한국은행의 보증 판별모형 등 기본 모형 - 판별분석은 분류되어 있는 집단간의 차이를 의미있게 설명해 줄 수 있는 독립변수들을 찾아내고 이들의 선형결합의 판별식으로 나타냄 - 귀무가설은 집단간 평균이 같다 - 판별분석은 집단내 분산에 대한 집단간 분산의 비율을 사용하며, 이를 극대화 시키는 독립변수의 선형결합을 찾아냄 Z = W1X1 + W2X2 + ….. + WnXn where, Z : 판별점수(명명척도) Xi : i번째 독립변수(비율 또는 등간 척도) Wi : i번째 독립변수의 가중치
 - 판별분석은 일정한 특성 즉, 종속변수를 기준으로 모집단을 상호 배반관계(mutually exclusive)에 있는 2개 또는 그 이상의 집단으로 분류하는 통계적 기법. - 어느 집단에 속하는지 구별하는데 도움을 줄수 있는 판별변수들을 독립변수 중에서 선택. - 판별함수에 의해 집단들이 얼마나 정확하게 구별할 수 있는지의 정도를 나타냄. - 예 : 정당의 공천심사, 은행의 대출심사, 신용보증기금 및 한국은행의 보증 판별모형 등. 기본 모형. - 판별분석은 분류되어 있는 집단간의 차이를 의미있게 설명해 줄 수 있는 독립변수들을 찾아내고 이들의 선형결합의 판별식으로 나타냄. - 귀무가설은 집단간 평균이 같다. - 판별분석은 집단내 분산에 대한 집단간 분산의 비율을 사용하며, 이를 극대화 시키는 독립변수의 선형결합을 찾아냄. Z = W1X1 + W2X2 + ….. + WnXn. where, Z : 판별점수(명명척도) Xi : i번째 독립변수(비율 또는 등간 척도) Wi : i번째 독립변수의 가중치.")
4
판별분석 (DISCRIMINANT ANALYSIS)
기본가정 - 모집단내에는 이미 알고 있는 2개 이상의 이산형 집단(discrete group)이 존재 - 분석대상 집단이 다변량 정규분포(multivariate normal distribution)을 이루고 분산, 공분산 매트릭스(variance-covariance matirx)는 동일하지만 이들의 평균치에는 차이가 있다. 두 집단 판별분석의 도해 -A,B 두 집단을 X1변수 하나로 분류할 경우 C1 만큼의 중복 확인 -A,B 두 집단을 X2변수 하나로 분류할 경우 C2 만큼의 중복 확인 -A,B 두 집단을 X1,X2 두개의 선형결합인 Z(판별식)라는 새로운 변수를 이용해 분류하면 C3 만큼의 중복확인
이 존재. - 분석대상 집단이 다변량 정규분포(multivariate normal distribution)을 이루고 분산, 공분산 매트릭스(variance-covariance matirx)는 동일하지만 이들의 평균치에는 차이가 있다. 두 집단 판별분석의 도해. -A,B 두 집단을 X1변수 하나로 분류할 경우 C1 만큼의 중복 확인. -A,B 두 집단을 X2변수 하나로 분류할 경우 C2 만큼의 중복 확인. -A,B 두 집단을 X1,X2 두개의 선형결합인 Z(판별식)라는 새로운 변수를 이용해 분류하면 C3 만큼의 중복확인.")
5
판별분석 (DISCRIMINANT ANALYSIS)
판별분석의 절차 1) 변수의 선정 :종속변수(명목척도), 독립변수(비율,등간척도)…판별식의 조건 참조 2) 표본의 선정 : 판별식의 선정과 타당성을 검증할 때 분석표본과 유효표본으로 나누어 검증하는것이 바람직. 즉, 분석표본으로 판별식을 유도하고, 유효표본으로 타당성을 검증한다. 전체 표본을 판별식유도 및 타당성에 사용하면 실제보다 훨씬 의미있는 것으로 결과가 나타난다. 3) 판별식의 수 결정 :집단의 수나 독립변수의 수에 따라 판별식의 수가 결정 판별식의 수 = Min(집단의 수 -1, 독립변수의 수) 예를 들어 3개의 집단, 5개의 독립변수가 있다면 Min(3-1,5) 즉 2개의 판별식이 생긴다. 물론 첫번째 계산된 판별식이 가장 집단을 잘 구분해 준다.
 변수의 선정 :종속변수(명목척도), 독립변수(비율,등간척도)…판별식의 조건 참조. 2) 표본의 선정 : 판별식의 선정과 타당성을 검증할 때 분석표본과 유효표본으로 나누어 검증하는것이 바람직. 즉, 분석표본으로 판별식을 유도하고, 유효표본으로 타당성을 검증한다. 전체 표본을 판별식유도 및 타당성에 사용하면 실제보다 훨씬 의미있는 것으로 결과가 나타난다. 3) 판별식의 수 결정 :집단의 수나 독립변수의 수에 따라 판별식의 수가 결정. 판별식의 수 = Min(집단의 수 -1, 독립변수의 수) 예를 들어 3개의 집단, 5개의 독립변수가 있다면 Min(3-1,5) 즉 2개의 판별식이 생긴다. 물론 첫번째 계산된 판별식이 가장 집단을 잘 구분해 준다.")
6
판별분석의 사례 연구문제 - 가나다 자동차 회사는 30대 직장인 남성을 대상으로 레저용 차량에 대한 구체적인 계획을 가지고 있는 사람과 그렇지 않은 사람의 특성을 파악하고자 한다.(판별분석_차량구입.sav) - 종속변수는 레저용 차량의 구매의도 집단과 비구매의도 집단 독립변수는 가족수, 월급, 여행빈도 판별식의 도출 - 독립변수의 선택방법 : 동시투입방법과 단계적 투입방법이 있다. 단계적 투입방식에서 투입변수의 기준은 Wilk’s 람다값을 사용(집단내분산/총분산) 람다값이 가장 작은 값 부터 투입하여 남아있는 변수들의 F값이 정해진 기준값 이하가 될때 까지 반복한다.
 람다값이 가장 작은 값 부터 투입하여 남아있는 변수들의 F값이 정해진 기준값 이하가 될때 까지 반복한다.")
7
판별분석의 사례(계속) 판별식의 수 - 판별식의 수 = Min(집단의 수 -1, 독립변수의 수)에서 본사례의 경우 집단이 2개 독립변수가 3개 이므로 판별식은 1개가 된다. 판별식의 유의성 검증 - 정준상관계수(canonical correlation coefficient) 와 Wilk’s 람다값으로 검증 - 정준상관계수의 경우는 판별점수와 집단간의 상관관계를 나타내는 것으로 값이 클수록(1에 가까울수록) 판별식의 설명력은 높아진다. 사례에서는 0.664이고 이를 제곱한 0.441가 설명력이 된다. 즉, 판별함수에 의해 44.1%가 종속변수가 설명되고 있다. - Wilk’s람다값은 카이분포상에서 유의성을 검증해서 표로 나타낸다.
 와 Wilk’s 람다값으로 검증. - 정준상관계수의 경우는 판별점수와 집단간의 상관관계를 나타내는 것으로 값이 클수록(1에 가까울수록) 판별식의 설명력은 높아진다. 사례에서는 0.664이고 이를 제곱한 0.441가 설명력이 된다. 즉, 판별함수에 의해 44.1%가 종속변수가 설명되고 있다. - Wilk’s람다값은 카이분포상에서 유의성을 검증해서 표로 나타낸다.")
8
판별분석의 사례(계속) 분류함수(Fisher의 판별식)
- 구매의도 집단의 분류함수 : * 여행빈도 * 월급 – - 비구매의도 집단의 분류함수 : 1.268*여행빈도 * 월급 – - 응답자 1의 답변을 위식에 대입해 보면 과 이 나온다. 즉, 응답자 1은 구매의도 집단으로 분류된다. 정준판별함수 - 비표준화된 정준상관계수 : * 여행빈도 * 월급 – 5.645 (응답자 1의 답변을 위식에 대입하면 0.797이며 경계점이 0(함수집단중심점이 0.858과 / cutting score= (n1C1+n2C2)/(n1+n2))이기 때문에 구매의사집단으로 분류된다. - 표준화된 정준상관계수 : 0.571*여행빈도 * 월급 (독립변수들의 집단판별시 얼마나 기여하는가를 알수 있다. 위식에서는 월급이 여행빈도보다 더 큰 영향을 주고 있다.)
/(n1+n2))이기 때문에 구매의사집단으로 분류된다. - 표준화된 정준상관계수 : 0.571*여행빈도 * 월급. (독립변수들의 집단판별시 얼마나 기여하는가를 알수 있다. 위식에서는 월급이 여행빈도보다 더 큰 영향을 주고 있다.)")
9
판별분석의 사례(계속) 판별식의 타당성 검증 - 다변량정규분포 및 각 집단의 공분산이 같다는 가정을 충족하는지의 검증
- 다변량정규분포 및 각 집단의 공분산이 같다는 가정을 충족하는지의 검증 - 각 응답자의 실제선택과 예상선택 비교 - **는 오분류 케이스이며 적중률은 양 집단 모두 15명 중 12명을 적중했으므로 80%이다.

10
판별분석의 사례(계속) 판별식의 타당성 검증 계속
- 아래의 hit ratio 80%가 과연 어느정도 판별력을 갖는 것인지를 평가하는 기준 - C-max방법 과 C-proportional방법이 있음 C-max의 cutting score = 최대빈도 집단 표본수 / 전체표본수 = 15/30 = 50% C-proportional의 cutting score = Σ(집단 i의 빈도수 / 전체표본수)2 =(15/30)2 + (15/30)2 = 50% - 두 방법 모두 비교기준이 50%가 되므로 판별식에 의한 판별력 80%와 비교해보면 30%의 개선효과가 있음을 알수 있다. - 그러나 개선효과가 어느정도 이어야 한다는것에 대해서는 논란의 여지가 많다. 만일 극히 작은 개선이라도 상당히 중요한 의미를 갖을 수 있다면 판별식이 의미있게 되는것이고, 상당히 큰 개선이 이루어진다 하더라도 별다른 가치가 없거나 막대한 비용이 투입된다면 판별식이 무의미 할것 이다.(투입비용과 가치등을 종합적으로 고려해서 판별식에 가치를 부여해야함.
2 =(15/30)2 + (15/30)2 = 50% - 두 방법 모두 비교기준이 50%가 되므로 판별식에 의한 판별력 80%와 비교해보면 30%의 개선효과가 있음을 알수 있다. - 그러나 개선효과가 어느정도 이어야 한다는것에 대해서는 논란의 여지가 많다. 만일 극히 작은 개선이라도 상당히 중요한 의미를 갖을 수 있다면 판별식이 의미있게 되는것이고, 상당히 큰 개선이 이루어진다 하더라도 별다른 가치가 없거나 막대한 비용이 투입된다면 판별식이 무의미 할것 이다.(투입비용과 가치등을 종합적으로 고려해서 판별식에 가치를 부여해야함.")
11
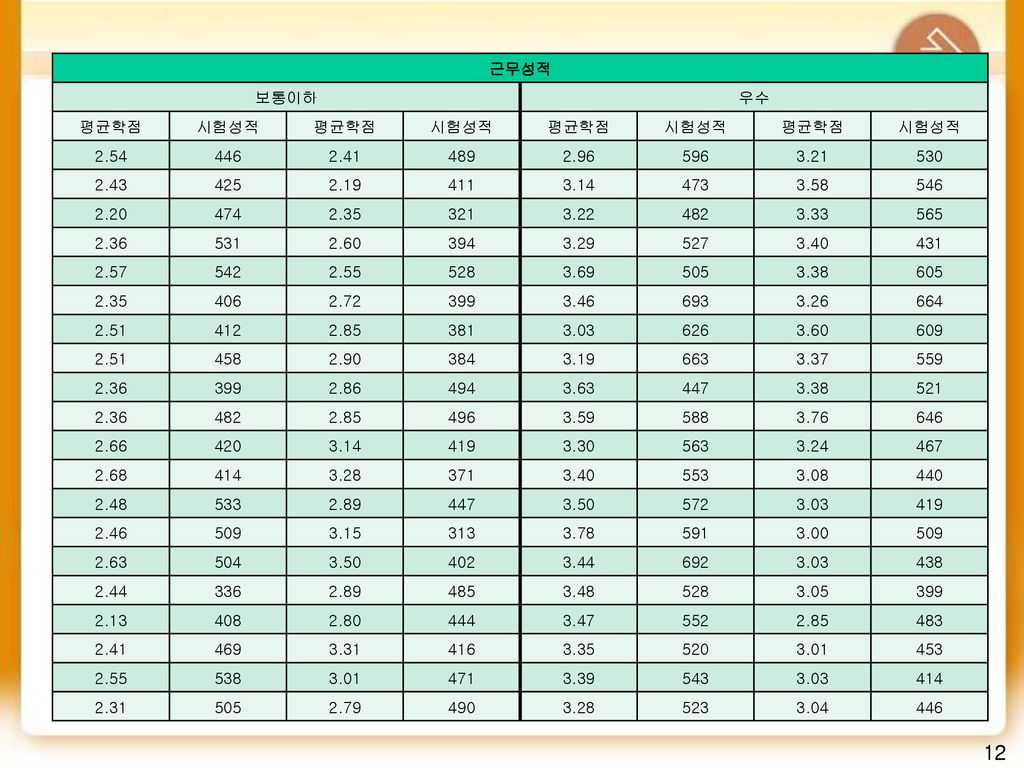
판별분석의 사례(계속) 교통그룹에서는 대졸 신입사원을 모집하고 있다.
선발기준으로는 대학교의 평균학점(4.0기준)과 입사시험성적(면접포함)이다. 인사담당자는 최근에 입사한 80명의 입사성적과 입사후 근무실적평가에 관한 자료를 가지고 있다. 이 자료를 이용하여 지원자가 입사후에 어떤 실적을 올릴 것인가를 판별하여 우수한 실적 집단으로 판별된 자만을 선발하고자 한다. 판별함수를 유도하고 적중율을 구하시오. 또한 평균학점이 3.0이고 입사성적이 520저인 응시자는 선발되겠는가?
과 입사시험성적(면접포함)이다. 인사담당자는 최근에 입사한 80명의 입사성적과 입사후 근무실적평가에 관한 자료를 가지고 있다. 이 자료를 이용하여 지원자가 입사후에 어떤 실적을 올릴 것인가를 판별하여 우수한 실적 집단으로 판별된 자만을 선발하고자 한다. 판별함수를 유도하고 적중율을 구하시오. 또한 평균학점이 3.0이고 입사성적이 520저인 응시자는 선발되겠는가")
12
근무성적 보통이하 우수 평균학점 시험성적 2.54 446 2.41 489 2.96 596 3.21 530 2.43 425 2.19 411 3.14 473 3.58 546 2.20 474 2.35 321 3.22 482 3.33 565 2.36 531 2.60 394 3.29 527 3.40 431 2.57 542 2.55 528 3.69 505 3.38 605 406 2.72 399 3.46 693 3.26 664 2.51 412 2.85 381 3.03 626 3.60 609 458 2.90 384 3.19 663 3.37 559 2.86 494 3.63 447 521 496 3.59 588 3.76 646 2.66 420 419 3.30 563 3.24 467 2.68 414 3.28 371 553 3.08 440 2.48 533 2.89 3.50 572 2.46 509 3.15 313 3.78 591 3.00 2.63 504 402 3.44 692 438 2.44 336 485 3.48 3.05 2.13 408 2.80 444 3.47 552 483 469 3.31 416 3.35 520 3.01 453 538 471 3.39 543 2.31 2.79 490 523 3.04
13
군집분석(Cluster Analysis)
")
14
군집분석 (CLUSTER ANALYSIS)
사용목적(분석-분류분석-이단계, K-평균, 계층적 군집분석) - 군집분석은 다변량 자료를 각 특성의 유사성에 따라 여러 그룹으로 나누는 통계적 분석기법. 즉, 각 개체나 변수가 미리 정해진 기준에 맞추어 각 군집 내에 유사한 것끼리 모이도록 분류. - 판별함수는 이미 알려진 그룹의 구조와 수대로 나누어 각 그룹에 새로운 개체를 할당 - 군집분석은 그룹의 수나 구조가 가정되어 있지 않고 유사성 또는 근접성에 근거하여 그룹핑(클러스터)함 - 예 : 생물학에서 동식물 분류, 의학에서 환자를 대상으로 질병의 종류 및 상태를 분류, 마케팅조사에서 소비자의 상품구매형태나 생활양식에 따라 소비자군으로 분류한 후 시장세분화 전략을 수립할 경우 사용, 설문지에서 의미없는 대답(장난스러운 대답 등) 즉 무성의한 대답의 군집을 제거하여 유용한 자료만을 취할때 기본 절차 1. 설명변수선택 2. 변수들의 측정단위 동일(동일하지 않은 경우 Z-SCORE) 3. 유사성거리 측정 4. 군집화 5. 해석 6. 결과만족 7. 만족하지 않으면 1번으로 피드백
 - 군집분석은 다변량 자료를 각 특성의 유사성에 따라 여러 그룹으로 나누는 통계적 분석기법. 즉, 각 개체나 변수가 미리 정해진 기준에 맞추어 각 군집 내에 유사한 것끼리 모이도록 분류. - 판별함수는 이미 알려진 그룹의 구조와 수대로 나누어 각 그룹에 새로운 개체를 할당. - 군집분석은 그룹의 수나 구조가 가정되어 있지 않고 유사성 또는 근접성에 근거하여 그룹핑(클러스터)함. - 예 : 생물학에서 동식물 분류, 의학에서 환자를 대상으로 질병의 종류 및 상태를 분류, 마케팅조사에서 소비자의 상품구매형태나 생활양식에 따라 소비자군으로 분류한 후 시장세분화 전략을 수립할 경우 사용, 설문지에서 의미없는 대답(장난스러운 대답 등) 즉 무성의한 대답의 군집을 제거하여 유용한 자료만을 취할때. 기본 절차. 1. 설명변수선택 2. 변수들의 측정단위 동일(동일하지 않은 경우 Z-SCORE) 3. 유사성거리 측정 4. 군집화 5. 해석 6. 결과만족 7. 만족하지 않으면 1번으로 피드백.")
15
군집분석 (CLUSTER ANALYSIS)
설명변수의 선정 - 군집분석에서 가장 중요한 문제로 중요한 변수가 제외되거나 불필요한 변수가 추가될 경우 유사성거리가 제대로 측정되지 못함 - 회귀분석이나 판별분석의 경우에는 유의하지 않은 변수를 제거하는 기능이 있지만 군집분석에는 의미없는 변수를 제거하는 기능이 없음. 즉, 최종결과에 대한 유의성 검정이 없음. - 군집분석을 하기 전에 요인분석(Factor Anaysis)을 통해 변수들간의 중복부분을 제거할 수 있고, 제거한 요인점수들을 도출하여 군집분석의 설명변수로 사용가능 유사성 거리의 측정 1. 유클리드 거리 – 변수값 차이를 제곱하여 합산한 거리로 다차원공간에서 직선최단거리를 말함.가장 일반적인 방법(단위가 상이한 경우 표준화) Distance(O1, O2) = sqrt((x1-x2)2 + (y1-y2)2)) 2. 유클리드 제곱거리(spss 기본값) Distance(O1, O2) = (x1-x2)2 + (y1-y2)2) 3. Chebychev distance, Minkowski distance, 등등
을 통해 변수들간의 중복부분을 제거할 수 있고, 제거한 요인점수들을 도출하여 군집분석의 설명변수로 사용가능. 유사성 거리의 측정. 1. 유클리드 거리 – 변수값 차이를 제곱하여 합산한 거리로 다차원공간에서 직선최단거리를 말함.가장 일반적인 방법(단위가 상이한 경우 표준화) Distance(O1, O2) = sqrt((x1-x2)2 + (y1-y2)2)) 2. 유클리드 제곱거리(spss 기본값) Distance(O1, O2) = (x1-x2)2 + (y1-y2)2) Chebychev distance, Minkowski distance, 등등.")
16
군집분석 (CLUSTER ANALYSIS)
군집화 방법 - 군집분석에서 가장 중요한 문제로 중요한 변수가 제외되거나 불필요한 변수가 추가될 경우 유사성거리가 제대로 측정되지 못함 - 최단연결법, 단일연결법(Single Linkage Method, Nearest Neighbor Method) 이제 예를 들어 최단연결법을 설명하겠다. 5개의 객체들간의 유사성거리가 다음과 같은 거리행렬로 주어졌다고 했을때, 첫 단계로 d13=1이 최소거리이므로 객체 1과 객체 3을 묶어 군집(1,3)을 만든다. 다음으로 군집 (1,3)과 나머지 객체들 2,4,5와의 거리는 d {(2)(1,3)}=min{d 21, d 23} = min(7, 6) = d 23 = 6 d {(4)(1,3)}=min{d 41, d 43} = min(9, 8) = d 43 = 8 d {(5)(1,3)}=min{d 51, d 53} = min(8, 7) = d 53 = 7 이므로, 다음과 같은 거리행렬 D1을 얻는다. D=
 이제 예를 들어 최단연결법을 설명하겠다. 5개의 객체들간의 유사성거리가 다음과 같은 거리행렬로 주어졌다고 했을때, 첫 단계로 d13=1이 최소거리이므로 객체 1과 객체 3을 묶어 군집(1,3)을 만든다. 다음으로 군집 (1,3)과 나머지 객체들 2,4,5와의 거리는. d {(2)(1,3)}=min{d 21, d 23} = min(7, 6) = d 23 = 6. d {(4)(1,3)}=min{d 41, d 43} = min(9, 8) = d 43 = 8. d {(5)(1,3)}=min{d 51, d 53} = min(8, 7) = d 53 = 7. 이므로, 다음과 같은 거리행렬 D1을 얻는다 D=")
17
군집분석 (CLUSTER ANALYSIS)
이므로, 다음과 같은 거리행렬 D1을 얻는다. 두 번째 단계로서 d24=3이 최소거리가 되므로 객체 2와 책체 4를 묶어 군집(2,4)를 만든다. 그러면 d {(1,3)(2,4) = min[d {(2)(1,3)}] = d{(2)(1,3)} = 6 d { (5)(2,4)} = min{d 52, d 54} = d 54 = 4 이므로 다음 거리행렬 D2를 얻는다. (1,3) (1,3) D1= (1,3) (2,4) 5 (1,3) (2,4) D2=
를 만든다. 그러면. d {(1,3)(2,4) = min[d {(2)(1,3)}] = d{(2)(1,3)} = 6. d { (5)(2,4)} = min{d 52, d 54} = d 54 = 4. 이므로 다음 거리행렬 D2를 얻는다. (1,3) (1,3) D1= (1,3) (2,4) 5. (1,3) (2,4) D2=")
18
군집분석 (CLUSTER ANALYSIS)
세 번째 단계로서 d{(2,4)(5)} = 4가 최소거리가 되므로 군집(2,4)와 객체 5를 묶어 군집 (2,4,5)를 이루고 최종적으로 전체가 한 군집을 이루게 된다. 이와 같은 군집과정을 덴드로그램(dendrogram)으로 나타내면 다음과 같다. 거 리 6 4 3 1 객 체 응집 계층적 군집방법에는 단일연결법(최소거리), 완전연결법(최장거리), 평균연결법(평균거리) 등이 있다.
(5)} = 4가 최소거리가 되므로 군집(2,4)와 객체 5를 묶어 군집 (2,4,5)를 이루고 최종적으로 전체가 한 군집을 이루게 된다. 이와 같은 군집과정을 덴드로그램(dendrogram)으로 나타내면 다음과 같다. 거 리 객 체. 응집 계층적 군집방법에는 단일연결법(최소거리), 완전연결법(최장거리), 평균연결법(평균거리) 등이 있다.")
19
계층적 군집분석의 예제 우리나라 제조업의 가동률에 관한 자료를 이용하여 업체들을 군집으로 분류하시오
분석 – 분류분석 – 계층적 군집분석

20
계층적 군집분석 예제 통계량

21
계층적 군집분석 예제 도표 방법 방법 : 집단간연결(평균연결법 그룹간평균), 집단내연결, 가장 가까운 항목(최단연결법), 가장먼항목, 중심적 군집화(중심연결법), 중위수군집화(중앙값연결법), Ward군집화
, 집단내연결, 가장 가까운 항목(최단연결법), 가장먼항목, 중심적 군집화(중심연결법), 중위수군집화(중앙값연결법), Ward군집화.")
22
계층적 군집분석 예제 결과분석 단일업종들 사이의 거리에서 낙동제조업과 화학제조업 간의 거리가 0.011로 가장 짧고, 신발제조업과 전지제조업간의 거리가 로 가장 멀다. 즉 가까우면 같은 군집일 가능성이 크고, 멀면 다른 군집에 속할 가능성이 크다.

23
계층적 군집분석 예제 군집화 일정표 단계를 보면 나누어진 군집이 하나로 모이는데 14단계를 거친다.
어느 단계에서 끊어서 몇 개의 군집으로 만드느냐가 관건(계수값이 갑자기 큰폭으로 상승하는 곳에서 군집의 수를 정하면 된다)
")
24
계층적 군집분석 예제 소속 군집 및 케이스 소속군집은 3군집, 4군집, 5군집으로 결정할 경우 각 케이스가 소속된 군집을 표시한다. 케이스의 경우 군집의 수가 14이면 모든 케이스가 각각 다른 군집으로, 군집의 수가 1이면 전지제조업과 나머지 모두, 즉 어느 선을 중심으로 선을 긋는가를 결정 3군집으로 할경우 (2,7,3,15,4,6,9,12,5,11,14) (8,10) (13)
 (8,10) (13)")
25
계층적 군집분석 예제 소속 군집 및 케이스 3군집으로 할경우 (2,7,3,15,4,6,9,12,5,11,14) (8,10) (13)
 (8,10) (13)")
26
계층적 군집분석 예제 군집간 차이검증(저장 : 각 케이스가 어느 군집에 속하는지에 대한 정보를 변수를 활용해 저장)
CLU3_1 변수를 이용해 분산분석을 실시

27
분석-평균비교-집단별 평균분석

28
결과해석 에타는 명목척도와 등간,비율척도의 상관성 에타제곱은 설명력을 나타냄

29
K-평균 군집분석 (K-MEANS CLUSTER ANALYSIS)
- 군집의 수를 미리 정함(초기에 군집수를 결정하는것은 매우 어려우므로 군집수를 변화시켜가면서 결과값을 비교 분석하는 것이 필요) - 대용량 데이터 군집분석에 유용하게 이용됨 기본 절차 1. 개체를 초기의 K군집으로 분류(지정가능, 프로그램 제공 가능) 2. 각 군집내 각각의 변수에 대해 중심점 계산 3. 각 케이스에 대해 중심점과 거리를 계산(계산 결과가 현재 속하고 있는 군집의 중심점과 근접하면 그냥 놔두고, 그렇지 않으면 다른 군집으로 분류) 4. 모든 케이스가 서로 다른 군집으로 분류될 때 까지 2,3,4과정 반복
 - 대용량 데이터 군집분석에 유용하게 이용됨. 기본 절차. 1. 개체를 초기의 K군집으로 분류(지정가능, 프로그램 제공 가능) 2. 각 군집내 각각의 변수에 대해 중심점 계산. 3. 각 케이스에 대해 중심점과 거리를 계산(계산 결과가 현재 속하고 있는 군집의 중심점과 근접하면 그냥 놔두고, 그렇지 않으면 다른 군집으로 분류) 4. 모든 케이스가 서로 다른 군집으로 분류될 때 까지 2,3,4과정 반복.")
30
K-평균 군집분석의 예제 12개의 시리얼 제품의 함유 성분 (100g기준)자료를 이용하여 시리얼 제품을 군집으로 분류
분석 – 기술통계 – 기술통계

31
K-평균 군집분석의 예제 분석 – 분류분석 – K-평균 군집분석

32
K-평균 군집분석의 예제 반복계산 저장 옵션

33
K-평균 군집분석의 예제 출력결과 표준화 단백질, 탄수화물, 칼로리는 각 군집에 따라 변수들의 평균에 차이가 있다

34
이단계 군집분석 (two-step CLUSTER ANALYSIS)
개요(분석-분류분석- 이단계 군집분석) - 군집분석에서 전통적으로 널리 이용되고 있는 것은 계층적 군집분석과 K-평균 군집분석이다. 그러나 계층적 군집분석은 대량의 데이터를 처리할 경우 계산시간이 아주 많이 소요되고, K-평균 군집분석은 속도는 빠르나 군집수를 미리 정해야하고 특이점(outlier)에 영향을 많이 받는 단점이 있다. - 이단계 군집분석은 범주형이나 연속형이 혼재된 경우에도 이용가능하며 데이터의 처리를 한번만 요구하므로 대량의 데이터 처리에 매우 유용하다(속도면에서 매우 빠름) 기본 절차 ( 1단계 ) . 각 개체를 읽어 다수의 사전군집(pre cluster)를 만든다. 즉 각 케이스를 하나씩 읽어가며 거리 크기에 따라 기존에 형성된 사전군집에 포함시키거나, 또는 새로운 사전군집을 형성한다. ( 2단계) . 이 단계가 끝나면 계층적 군집분석으로 넘어간다.(사전군집이 많을 수록 더 좋은 군집결과가 나올 가능성은 높지만 속도가 느려지는 단점이 있다)
 - 군집분석에서 전통적으로 널리 이용되고 있는 것은 계층적 군집분석과 K-평균 군집분석이다. 그러나 계층적 군집분석은 대량의 데이터를 처리할 경우 계산시간이 아주 많이 소요되고, K-평균 군집분석은 속도는 빠르나 군집수를 미리 정해야하고 특이점(outlier)에 영향을 많이 받는 단점이 있다. - 이단계 군집분석은 범주형이나 연속형이 혼재된 경우에도 이용가능하며 데이터의 처리를 한번만 요구하므로 대량의 데이터 처리에 매우 유용하다(속도면에서 매우 빠름) 기본 절차. ( 1단계 ) . 각 개체를 읽어 다수의 사전군집(pre cluster)를 만든다. 즉 각 케이스를 하나씩 읽어가며 거리 크기에 따라 기존에 형성된 사전군집에 포함시키거나, 또는 새로운 사전군집을 형성한다. ( 2단계) . 이 단계가 끝나면 계층적 군집분석으로 넘어간다.(사전군집이 많을 수록 더 좋은 군집결과가 나올 가능성은 높지만 속도가 느려지는 단점이 있다)")
35
이단계 군집분석 예제 서베이 자료 이용(변수 46개, 케이스수 2832건)하여 군집으로 분류(연속변수 : 연령 , 범주형 변수 : 성별, 신문(얼마나 자주), 최종학력 분석 – 분류분석 – 이단계 군집분석

36
이단계 군집분석 예제 옵션 출력결과

37
이단계 군집분석 예제 출력결과 표(아래 결과를 더블 클릭하여 각종 정보를 얻는다)
")
38
이단계 군집분석 예제 출력결과 표 군집결과는 TSC_7084변수에 나타나 있다.
여기서 -1은 특이점, .은 결측치를 나타낸다.

39
다차원척도법(Multidimensional Scaling)
")
40
다차원척도법 (Multidimentional Scaling:MDS)
사용목적(분석-척도-다차원척도법(ALSCAL)(M) - 우리는 사회내의 다양한 대상들과 밀접한 관계를 유지하면서 대상물을 좋은것/싫은것, 서로 비슷한것/다른것을 분류 - 그러나 인간의 인지능력의 한계 때문에 대상물이 가지고 있는 모든 속성을 평가 기준으로 삼기보다는 몇가지 속성만을 사용한다. 즉, 배우자 선택에서 외모, 건강, 학력, 재력, 성격, 장래성 등으로 평가할 때 기중에 대한 가중치가 다르기 때문에 각기 다른 배우자를 선택 - 다차원척도법은 응답자가 느끼고 있는 다양한 측면의 지각도나 선호도를 (다변량자료) 좌표상에 기하학적인 공간으로 표현. 즉, 인지하고 있거나 심리적 또는 추상적인 개념들을 2차원 공간의 그래프로 표현하여 느낌에 대한 관계를 쉽게 파악하도록 하는 것이 목적 - 예 : 정치에서 어떤 후보자들이 비슷한/다른 그룹으로 평가되는지 / 인류학에서 신념, 언어등의 데이터를 근거로 다양한 집단간 연구 / 다양한 도시, 군 지역들의 인구학적, 경제학적 요인들을 분석하여 각 지역의 상이/유사성 연구
(M) - 우리는 사회내의 다양한 대상들과 밀접한 관계를 유지하면서 대상물을 좋은것/싫은것, 서로 비슷한것/다른것을 분류. - 그러나 인간의 인지능력의 한계 때문에 대상물이 가지고 있는 모든 속성을 평가 기준으로 삼기보다는 몇가지 속성만을 사용한다. 즉, 배우자 선택에서 외모, 건강, 학력, 재력, 성격, 장래성 등으로 평가할 때 기중에 대한 가중치가 다르기 때문에 각기 다른 배우자를 선택. - 다차원척도법은 응답자가 느끼고 있는 다양한 측면의 지각도나 선호도를 (다변량자료) 좌표상에 기하학적인 공간으로 표현. 즉, 인지하고 있거나 심리적 또는 추상적인 개념들을 2차원 공간의 그래프로 표현하여 느낌에 대한 관계를 쉽게 파악하도록 하는 것이 목적. - 예 : 정치에서 어떤 후보자들이 비슷한/다른 그룹으로 평가되는지 / 인류학에서 신념, 언어등의 데이터를 근거로 다양한 집단간 연구 / 다양한 도시, 군 지역들의 인구학적, 경제학적 요인들을 분석하여 각 지역의 상이/유사성 연구.")
41
다차원척도의 목적(분석-척도-다차원척도법(ALSCAL)(M)
- 사람이 대상을 인지하거나 평가할때 어떠한 기준에 의해서 하게 되는지에 관한 문제(대학을 평가할때 사용되는 요인은? 교수진수준, 통학거리, 동문관계, 취업 등이 기준이 된다면…이 기준을 어떻게 밝혀낼 것인가의 문제) - 규명된 각 차원에 평가대상이 어떠한 위치에 포지션닝 되는가의 문제(포지셔닝맵을 만든다. 시각적으로 2차원 공간에 나타내고, 이상의 차원에 대해서는 여러 개의 2차원 포지셔닝맵이 산출된다) - 특히 기업에서는 여러 개의 상품들을 동일 공간에 위치시켜봄으로써 상품이 갖고 있는 여러가지 속성 차원에서의 강점과 약점을 차악하는데 매우 유용한 정보 산출
 - 규명된 각 차원에 평가대상이 어떠한 위치에 포지션닝 되는가의 문제(포지셔닝맵을 만든다. 시각적으로 2차원 공간에 나타내고, 이상의 차원에 대해서는 여러 개의 2차원 포지셔닝맵이 산출된다) - 특히 기업에서는 여러 개의 상품들을 동일 공간에 위치시켜봄으로써 상품이 갖고 있는 여러가지 속성 차원에서의 강점과 약점을 차악하는데 매우 유용한 정보 산출.")
42
다차원척도의 절차 (1) 문제의 정의 다차원척도의 결과가 어디에 사용될 것인지에 대하여 정확히 파악(예를들어 자동차에 대한 소비자의 지각 정도를 측정하는 경우에 고급자동차를 MDS에서 제외시키면 고급자동차의 차원은 공간상에 표시되지 않아 속성을 확인 할 수 없다) (2) 측정자료의 수집 MDS에서 입력데이터는 유사성 또는 선호도의 데이터가 사용된다.(등간/비율 척도 및 서열척도)( 단 서열척도는 등간척도로 변환후 사용)
 측정자료의 수집 MDS에서 입력데이터는 유사성 또는 선호도의 데이터가 사용된다.(등간/비율 척도 및 서열척도)( 단 서열척도는 등간척도로 변환후 사용)")
43
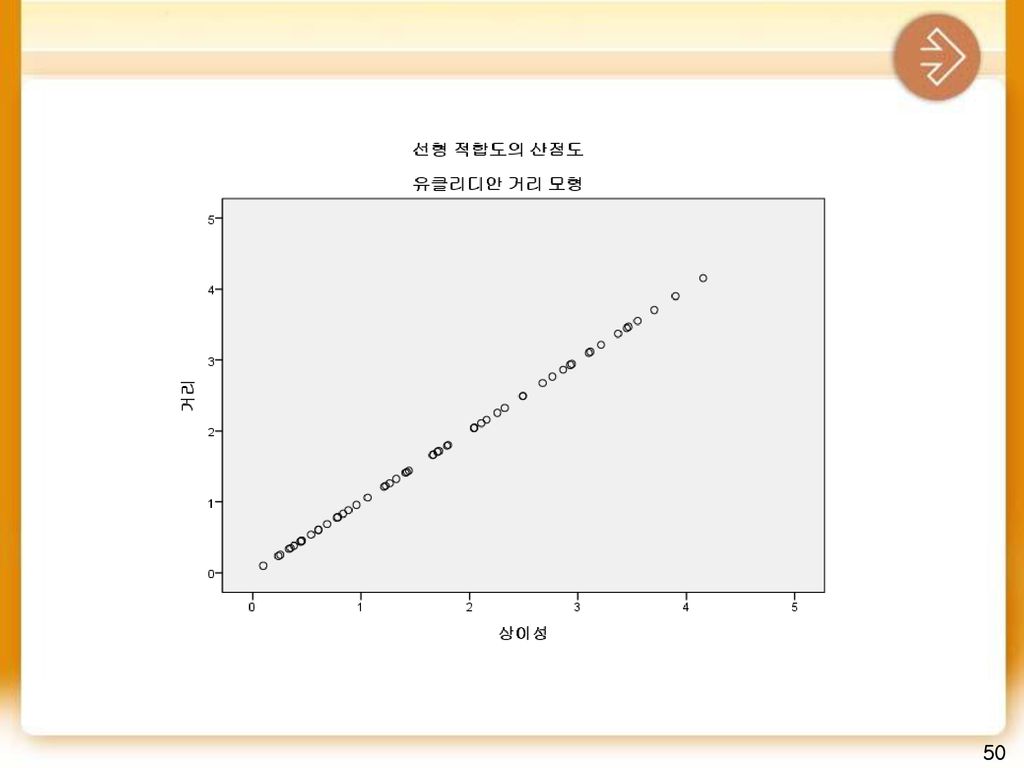
다차원척도의 절차 (3) 차원수 결정 .MDS는 입력데이터를 이용하여 공간상의 관측 대상들 간의 상대적인 거리를 가능한 한 정확히 측정하여 다차원 평가공간을 형성 .다차원 공간에서 적합은 더 이상 개선되지 않을 때까지 반복해서 계속됨. . 이 적합의 정도를 스트레스 값(stress value)으로 나타낸다. 이 스트레스 값은 불일치의 정도(badness of fits)로 볼 수 있음. – 스트레스 값의 크기에 따라 차원수 결정의 적절성이 확인 . 스트레스 값은 실제거리와 추정된 거리와의 오차(스트레스값이 0이면 완벽함을 의미) = 관측대상 i부터 j까지의 실제 거리 = 프로그램에 의해서 추정된 거리
으로 나타낸다. 이 스트레스 값은 불일치의 정도(badness of fits)로 볼 수 있음. – 스트레스 값의 크기에 따라 차원수 결정의 적절성이 확인. . 스트레스 값은 실제거리와 추정된 거리와의 오차(스트레스값이 0이면 완벽함을 의미) = 관측대상 i부터 j까지의 실제 거리. = 프로그램에 의해서 추정된 거리.")
44
스트레스 값 적합 정도 > 0.2 아주 나쁨 0.2 나 쁨 0.1 보 통 0.05 좋 음 0.025 아주 좋음 완벽함
완벽함 (5) 차원의 이름과 포지셔닝 맵 . 차원의 수가 결정되면 이름을 결정해야 함(요인분석에서 요인의 이름을 명명하는 경우과 같음) . 명명된 포지셔닝 맵은 신제품 개발, 시장세분화, 마케팅 믹스 전략 등에 활용 (6) 신뢰성과 타당성 검토 상관계수의 제곱값인 결정계수를 이용(R2) 대략 60% 이상이면 받아들일 만한 수치
 차원의 이름과 포지셔닝 맵 . 차원의 수가 결정되면 이름을 결정해야 함(요인분석에서 요인의 이름을 명명하는 경우과 같음) . 명명된 포지셔닝 맵은 신제품 개발, 시장세분화, 마케팅 믹스 전략 등에 활용. (6) 신뢰성과 타당성 검토 상관계수의 제곱값인 결정계수를 이용(R2) 대략 60% 이상이면 받아들일 만한 수치.")
45
다차원척도의 예제(분석-척도-다차원척도법(ALSCAL)(M)
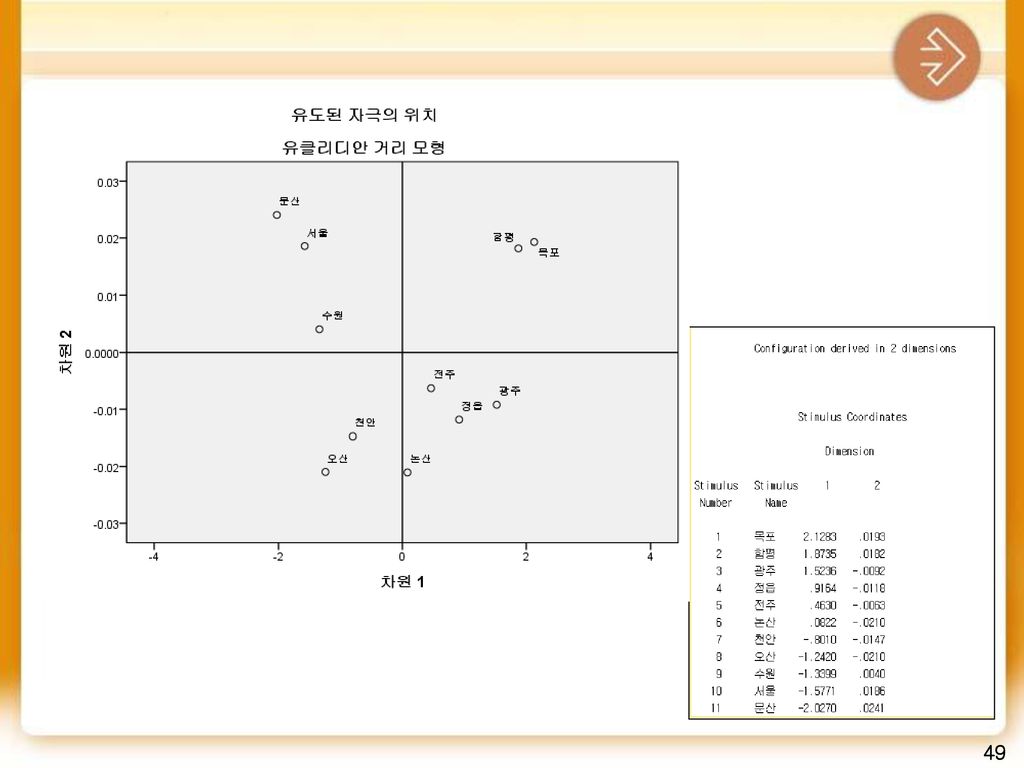
- 우리나라 국도 1호선(목포~신의주)중 목포에서 문산까지의 거리(Km)를 이용하여 지도를 재현하는 문제 - 엑셀 자료
중 목포에서 문산까지의 거리(Km)를 이용하여 지도를 재현하는 문제. - 엑셀 자료.")
46
spss 데이터



 ~ 5 일 ( 금 ) (1 박 2 일 ) ✽장소 강원도 정동진 ( 레일바이크 ), 경포대 ( 모터보트 ), 오죽헌, 용평리조트 일대 ✽참가인원 중학교 1 학년 ~ 고등학교 3 학년.>")
 2. 시장세분화 전략 3. 타겟팅 (Targeting) 선정 4. 포지셔닝 (Positioning) 전략.>")

 아씨의 방에는 바느질을 위한 친구가 몇 명이 있었나요 ? 정답은 ? 일곱.>")


 - 시행초기에 투자 분양가 5,400 만원 실투자금 2,500 만원으로.>")

 11:00 상망동주민센터 2 층 회의실. 1. 아이의 웃음소리가 커지는 상망동 만들기 (2012 년도 인구증가 대책 ) 2. 제 18 대 대선 선거 중립 유지 및 개입 금지 3. 여성친화도시 조성 시민참여단 모집 4. 2012 영주 풍기인삼축제.>")
 창원 불모산 – 진해 안민고개 산행.>")
 : 다수의 대상들 ( 소비자, 제품, 기타 ) 을 그들이 소유하는 특 성을 토대로 유사한 대상들끼리 그룹핑하는 다변량 통계기법 → 군집내의 구성원들은 가급 적.>")

 마저 외면 할 수 없는 인간들이 만든 감동의 순간 우리는 무엇을 해야 할 것인가 ?>")


>")



, R은 인장시편의 폭방향 진변형률과 두께방향 변형률의 비로 표시한다. 압연방향과 0˚방향의 시편으로부터 측정한 소성변형률비(R0)는 이고, 압연방향과 90˚방향의 시편에서 측정한 소성변형률비(R90)는.>")