Download presentation
1
32비트 캐리 예측 덧셈기(CLA) RCA(Ripple Carry Adder)
Simple but slow due to the long carry propagation path

2
CLA(Carry Look ahead Adder)의 원리
Carry generate function Gi = Ai • Bi : Ci-1 에 관계없이 Ci=1 이 됨. Carry propagation function Pi = Ai Bi : Ci-1 에 따라 Ci 가 생성됨. Pi, Gi 는 동시에 생성가능. Si = (Ai Bi) Ci-1 = Pi Ci-1 로 쓸수 있음. Ci = Ai • Bi + (Ai Bi) • Ci-1 = Gi + Pi • Ci-1 로 쓸 수 있음. 따라서 C0 = G0 + P0 • C-1 C1 = G1 + P1 • C0 = G1 + G0 • P1 + P0 • P1 • C-1 C2 = G2 + P2 • C1 = G2 + G1 • P2 + G0 • P1 • P2 + P0 • P1 • P2 • C-1 …. Pi 와 Gi 동시 발생되므로, C0 만을 이용하여 Ci(i>0) 를 모두 동시에 구할 수 있다
 Ci-1 = Pi Ci-1 로 쓸수 있음. Ci = Ai • Bi + (Ai Bi) • Ci-1 = Gi + Pi • Ci-1 로 쓸 수 있음. 따라서. C0 = G0 + P0 • C-1. C1 = G1 + P1 • C0 = G1 + G0 • P1 + P0 • P1 • C-1. C2 = G2 + P2 • C1 = G2 + G1 • P2 + G0 • P1 • P2 + P0 • P1 • P2 • C-1. …. Pi 와 Gi 동시 발생되므로, C0 만을 이용하여 Ci(i>0) 를 모두 동시에 구할 수 있다.")
3
CLA 의 블록 다이어그램 PGU : Propagate / Generic unit
CLU : Carry Look ahead Unit : C(nio)생성, SU : Summation Unit
생성, SU : Summation Unit.")
4
하위레벨 component의 VHDL 모델링
32 비트 CLA 를 4비트 BCLU (Block CLU)와 8비트 CLU를 이용하여 2-level 로 모델링 함.
와 8비트 CLU를 이용하여 2-level 로 모델링 함.")
5
PGU

6
Cont’d

7
BCLU 32 비트 CLU는 fanin이 너무 크기 때문에, 8개의 4비트 BCLU 와 1개의 8비트 CLU 를 이용하여 그림과 같이 구성한다.

8
Cont’d 임의의 k 번째(0 =< k =< 7) BCLU 는 각 비트의 Pi, Gi와 1-비트의 Cin을 입력으로 C4k, C4k+1, C4k+2와 블록 전달함수 Pk*, 블록 발생함수 Gk*를 출력으로 생성한다. C4k+3 = Gk* + Pk* • Cin으로 표시됨. Gk*, Pk*는 상위레벨 CLU에 입력되어, C4k+3(k=0….7)을 동시에 생성하는데 사용됨. Gk* = G4k+3 + G4k+2 • P4k+3 + G4k+1 • P4k+3 • P4k+2 + G4k • P4k+3 • P4k+2 • P4k+1 Pk* = P4k • P4k+1 • P4k+2 • P4k+3
을 동시에 생성하는데 사용됨. Gk* = G4k+3 + G4k+2 • P4k+3 + G4k+1 • P4k+3 • P4k+2 + G4k • P4k+3 • P4k+2 • P4k+1. Pk* = P4k • P4k+1 • P4k+2 • P4k+3.")
9
BCLU 의 VHDL 모델

10
Cont’d

11
8-bit CLU(Carry Look ahead Unit)
C-1 과 8개의 BCLU에서 온 Pk*, Gk* 를 입력으로, (C4k+3, 0=<k=<7) 생성. C4k+3 = Gk* + Gk-1 • Pk* + …+ G0* • Pk* • Pk-1* •… + C-1 • Pk* • Pk-1* •… P0* (0=<k=<7)
 생성. C4k+3 = Gk* + Gk-1 • Pk* + …+ G0* • Pk* • Pk-1* •… + C-1 • Pk* • Pk-1* •… P0* (0=<k=<7)")
12
CLU의 VHDL 모델

13
Cont’d

14
SU(Summation Unit) 32-비트 Pi, 32-비트 Ci를 입력으로, 32-비트의 합 Si(0=<i=<31) 생성 블록다이아그램
 32-비트 Pi, 32-비트 Ci를 입력으로, 32-비트의 합 Si(0=<i=<31) 생성 블록다이아그램")
15
Cont’d(VHDL 모델)
")
16
전체 CLA의 모델링 Block Diagram

17
VHDL 모델

18
Cont’d

19
Cont’d

20
Cont’d

21
Cont’d

22
Cont’d

23
논리합성결과

24
CLA 설계에 대한 검증 TB-CLA : 두개의 입력파일 “in_file1”과 “in_file2”를 읽어 들여 덧셈을 수행함. 연산결과 Carry와 Sum을 “out_file1”, “out_file2”에 기록함. => 테스트 입력파일 수정만으로 새로운 테스트 가능(source 수정 없이) Library std.textio.all; 추가 필요 VHDL 모델
 Library std.textio.all; 추가 필요. VHDL 모델.")
25
Cont’d

26
Cont’d

27
Cont’d

28
Cont’d

29
UIM(Universal Indirect Multiplier)
32-비트 CLA 이용 US(Unsigned), SM(Signed Magnitude), OC(One’s Complement), TC(Two’s Complement) 의 4 가지 Fixed-point number system 으로 표현되는 수의 곱셈을 add-shift 방식의 간접 곱셈을 통해 수행하는 32-비트 곱셈기
, SM(Signed Magnitude), OC(One’s Complement), TC(Two’s Complement) 의 4 가지 Fixed-point number system 으로 표현되는 수의 곱셈을 add-shift 방식의 간접 곱셈을 통해 수행하는 32-비트 곱셈기.")
30
UIM(Universal Indirect Multiplier)
add-shift 방식 곱셈 (3) X (5) (15) (피승수) (승수) <- 승수가 1 이면 피승수를 더함. <- 승수가 0 이면 0 을 더함. (곱셈 결과)
 X (5) (15) (피승수) (승수) <- 승수가 1 이면 피승수를 더함. <- 승수가 0 이면 0 을 더함. (곱셈 결과)")
31
UIM – Data Path 구조

32
UIM(Universal Indirect Multiplier)
Data Path 구조 MR: 승수, AX: 피승수 저장, 최종결과: AC-MR에 저장 MR 은 한 바이트씩 오른쪽으로 shift 입력 X, Y: Mode(US, SM, OC, TC) 결정 수의 모드에 따른 UIM의 동작(Slide 5) Data load, cycle, n-비트 add-shift에 n-cycle 소요 SM 의 경우 음수인 피 연산자의 부호 비트를 보수 취하는 동작 필요 OC 의 경우 음수인 피 연산자와, 연산 결과 값을 1의 보수를 취하기 위해 두 사이클 더 필요 TC: 1의 보수에 1을 더하기 위해 OC 보다 두 사이클 더 필요 n=32 인 경우 US(=33), SM(=35), OS(=35), TC(=37) 사이클씩 필요함
 결정. 수의 모드에 따른 UIM의 동작(Slide 5) Data load, cycle, n-비트 add-shift에 n-cycle 소요. SM 의 경우 음수인 피 연산자의 부호 비트를 보수 취하는 동작 필요. OC 의 경우 음수인 피 연산자와, 연산 결과 값을 1의 보수를 취하기 위해 두 사이클 더 필요. TC: 1의 보수에 1을 더하기 위해 OC 보다 두 사이클 더 필요. n=32 인 경우. US(=33), SM(=35), OS(=35), TC(=37) 사이클씩 필요함.")
33
수의 모드에 따른 UIM의 동작

34
UIM 제어기 UIM 제어기 표 4.1 에 따른 동작 제어 위해 C0 ~ Cn+4 사이클 제어 신호 발생
각 Register 에 대한 제어신호(2비트씩) 할당
 할당.")
35
UIM 제어기-UIM의 micro-operation table

36
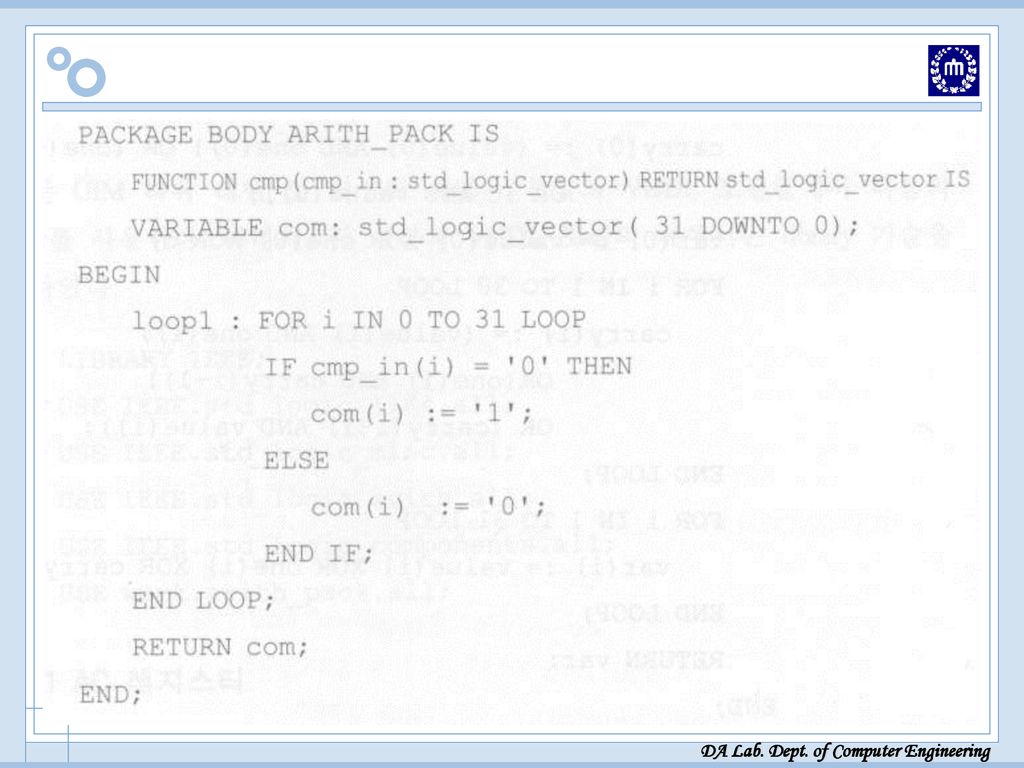
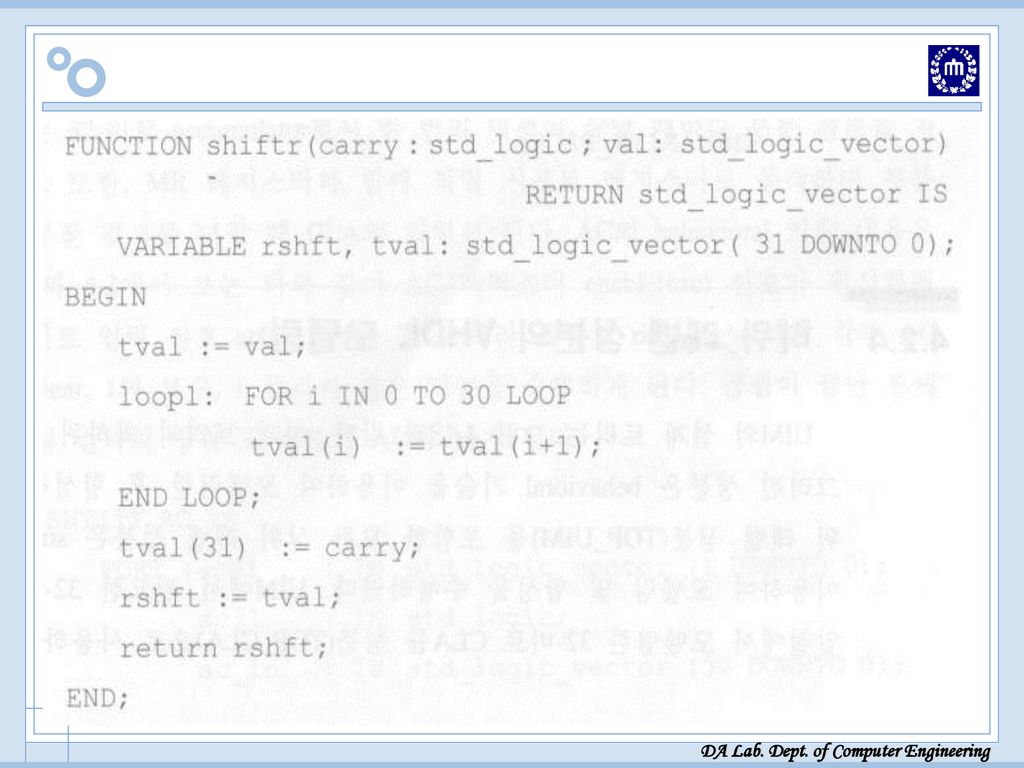
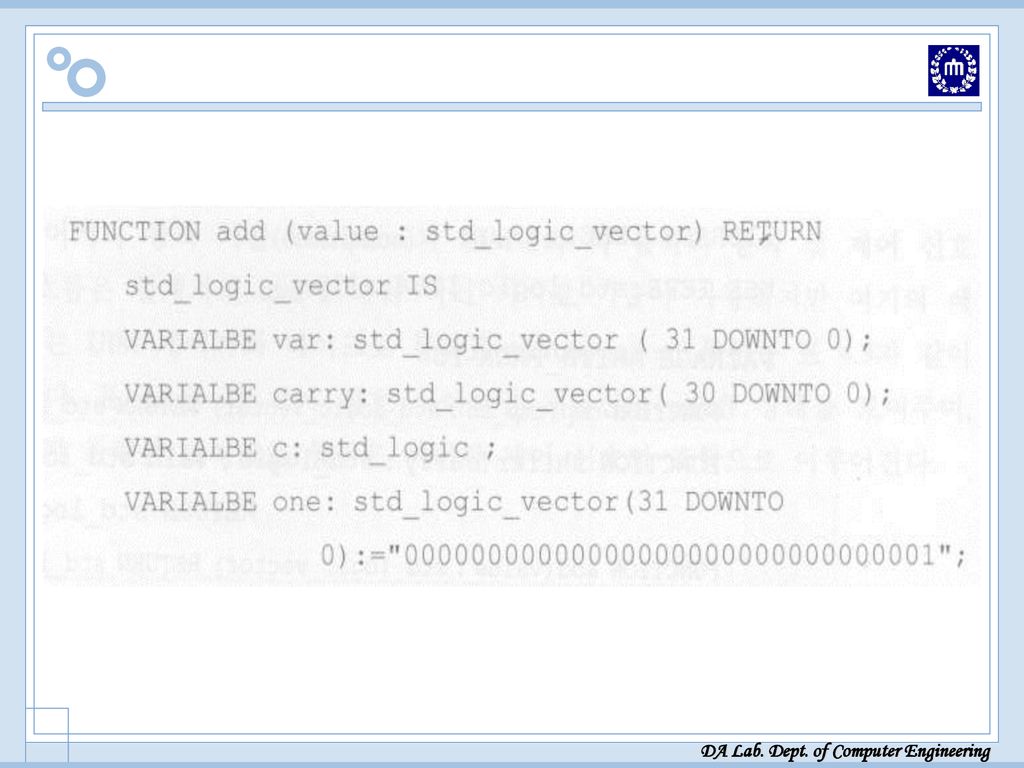
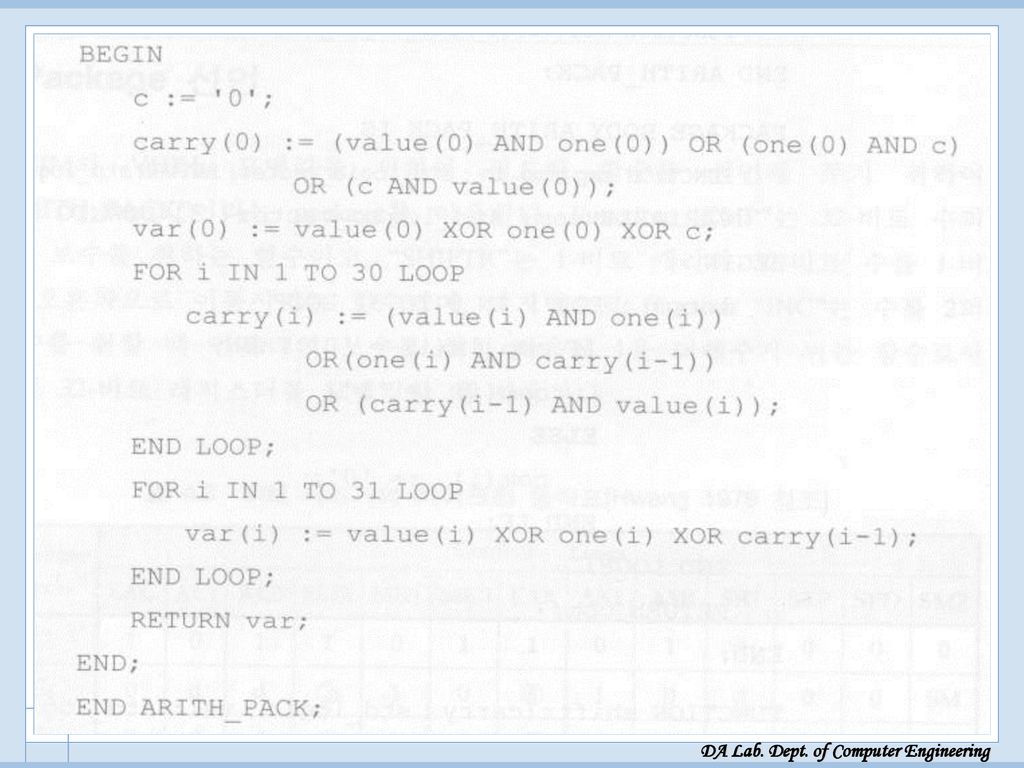
Package 선언 Package 선언 필요한 함수 선언 위해 “Arith-Pack” Package
Function cmp: 1의 보수 취하기 Function shiftr: 1-비트 carry와 32-비트 수를 1-비트 오른쪽으로 이동시키는 함수 Function INC: 2의 보수 구하기 위해 1의 보수 후에 1 증가시키는 함수

37
Package 선언[VHDL 소스]
![Package 선언[VHDL 소스]](http://slidesplayer.org/slide/14456355/90/images/37/Package+%EC%84%A0%EC%96%B8%5BVHDL+%EC%86%8C%EC%8A%A4%5D.jpg "Package 선언[VHDL 소스]")
42
UIM 설계 트리

43
AC 레지스터 AC 레지스터 MR과 함께 shift 됨
EAC(enable 신호)가 활성화된 상태에서 ac0와 ac1의 값에 따라 rising edge 에서 AC load, clear, 1의 보수, 1의 증가 기능 수행함
가 활성화된 상태에서 ac0와 ac1의 값에 따라 rising edge 에서 AC load, clear, 1의 보수, 1의 증가 기능 수행함.")
44
AC 모델링[VHDL 소스]
![AC 모델링[VHDL 소스]](http://slidesplayer.org/slide/14456355/90/images/44/AC+%EB%AA%A8%EB%8D%B8%EB%A7%81%5BVHDL+%EC%86%8C%EC%8A%A4%5D.jpg "AC 모델링[VHDL 소스]")
47
MR 레지스터: 승수저장, 부분 곱 하위 부분 저장[VHDL 소스]
![MR 레지스터: 승수저장, 부분 곱 하위 부분 저장[VHDL 소스]](http://slidesplayer.org/slide/14456355/90/images/47/MR+%EB%A0%88%EC%A7%80%EC%8A%A4%ED%84%B0%3A+%EC%8A%B9%EC%88%98%EC%A0%80%EC%9E%A5%2C+%EB%B6%80%EB%B6%84+%EA%B3%B1+%ED%95%98%EC%9C%84+%EB%B6%80%EB%B6%84+%EC%A0%80%EC%9E%A5%5BVHDL+%EC%86%8C%EC%8A%A4%5D.jpg "MR 레지스터: 승수저장, 부분 곱 하위 부분 저장[VHDL 소스]")
50
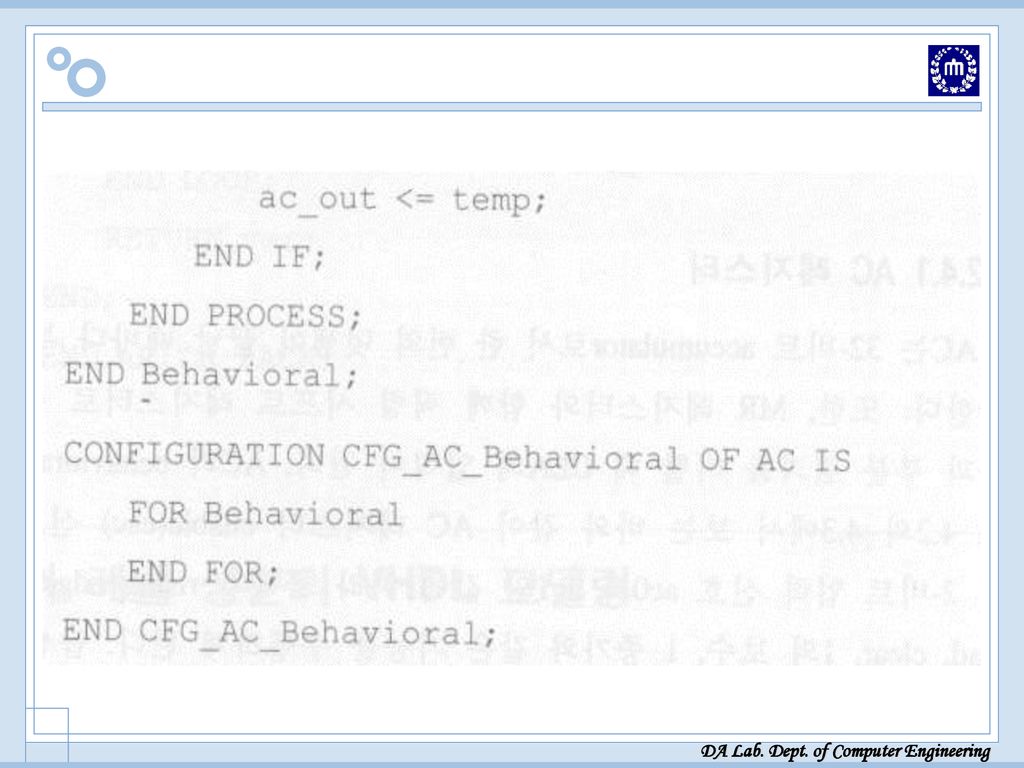
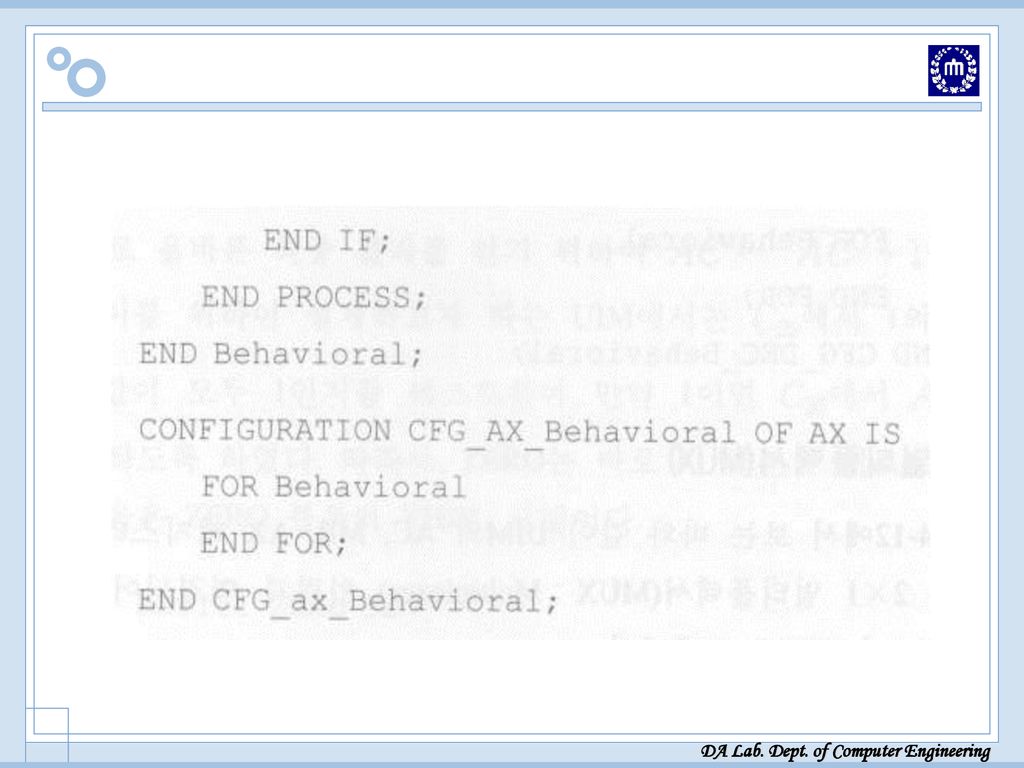
AX 레지스터: 피 승수 저장[VHDL 소스]
![AX 레지스터: 피 승수 저장[VHDL 소스]](http://slidesplayer.org/slide/14456355/90/images/50/AX+%EB%A0%88%EC%A7%80%EC%8A%A4%ED%84%B0%3A+%ED%94%BC+%EC%8A%B9%EC%88%98+%EC%A0%80%EC%9E%A5%5BVHDL+%EC%86%8C%EC%8A%A4%5D.jpg "AX 레지스터: 피 승수 저장[VHDL 소스]")
53
DEC(디코더): mode(X, Y) -> US, SM, TC, OC 생성[VHDL 소스]
![DEC(디코더): mode(X, Y) -> US, SM, TC, OC 생성[VHDL 소스]](http://slidesplayer.org/slide/14456355/90/images/53/DEC%28%EB%94%94%EC%BD%94%EB%8D%94%29%3A+mode%28X%2C+Y%29+-%3E+US%2C+SM%2C+TC%2C+OC+%EC%83%9D%EC%84%B1%5BVHDL+%EC%86%8C%EC%8A%A4%5D.jpg "DEC(디코더): mode(X, Y) -> US, SM, TC, OC 생성[VHDL 소스]")
56
MUX(멀티 플렉서): 2-to-1[VHDL 소스]
![MUX(멀티 플렉서): 2-to-1[VHDL 소스]](http://slidesplayer.org/slide/14456355/90/images/56/MUX%28%EB%A9%80%ED%8B%B0+%ED%94%8C%EB%A0%89%EC%84%9C%29%3A+2-to-1%5BVHDL+%EC%86%8C%EC%8A%A4%5D.jpg "MUX(멀티 플렉서): 2-to-1[VHDL 소스]")
58
ZERO 블록 ZERO 블록 2’s complement(TC=1)연산 때, C36 에서 MR <- MR + 1 을 수행함. 이 때 MR=0이 되면, Carry Out이 생겨, AC = AC + 1을 수행해야 함 C35 에서 1의 보수를 취한 후에 MR 값이 모두 1이면, C36 에서 AC <- AC + 1 을 수행하도록 함 ZERO 는 이 조건을 검사하는 블록임

59
ZERO 블록[VHDL 소스]
![ZERO 블록[VHDL 소스]](http://slidesplayer.org/slide/14456355/90/images/59/ZERO+%EB%B8%94%EB%A1%9D%5BVHDL+%EC%86%8C%EC%8A%A4%5D.jpg "ZERO 블록[VHDL 소스]")
61
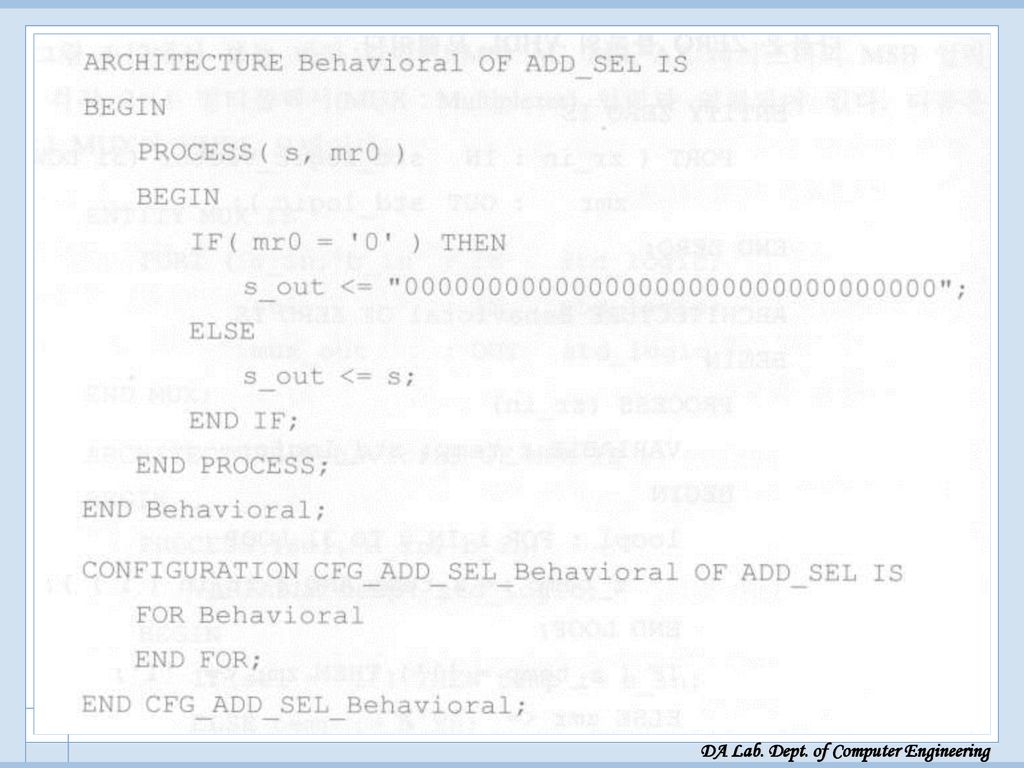
ADD-SEL 블록 ADD-SEL 블록 n-비트 덧셈기의 오른쪽 입력은 MR의 LSB 값(MR(0))에 따라 ‘1’ 이면 AX 가, ‘0’ 이면 zero 가 된다.
)에 따라 ‘1’ 이면 AX 가, ‘0’ 이면 zero 가 된다.")
62
ADD-SEL 블록[VHDL 소스]
![ADD-SEL 블록[VHDL 소스]](http://slidesplayer.org/slide/14456355/90/images/62/ADD-SEL+%EB%B8%94%EB%A1%9D%5BVHDL+%EC%86%8C%EC%8A%A4%5D.jpg "ADD-SEL 블록[VHDL 소스]")
64
CTR_BLK(제어 블록) 블록 다이아 그램
 블록 다이아 그램")
65
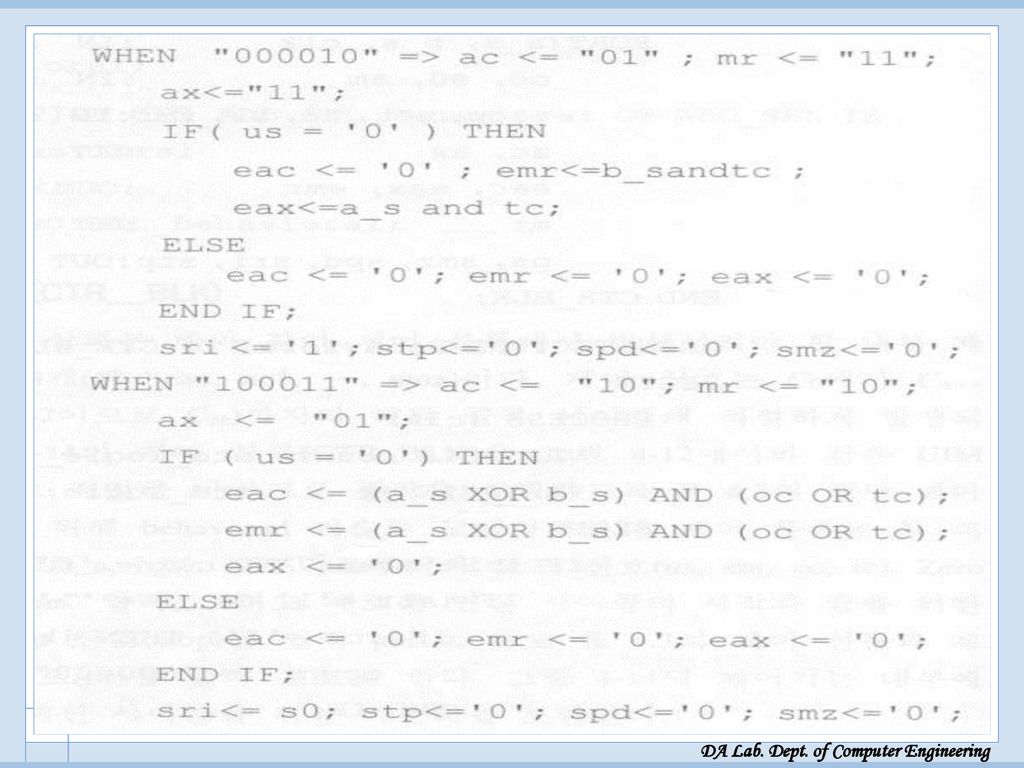
CTR_BLK(제어 블록)[VHDL 모델]
![CTR_BLK(제어 블록)[VHDL 모델]](http://slidesplayer.org/slide/14456355/90/images/65/CTR_BLK%28%EC%A0%9C%EC%96%B4+%EB%B8%94%EB%A1%9D%29%5BVHDL+%EB%AA%A8%EB%8D%B8%5D.jpg "CTR_BLK(제어 블록)[VHDL 모델]")
71
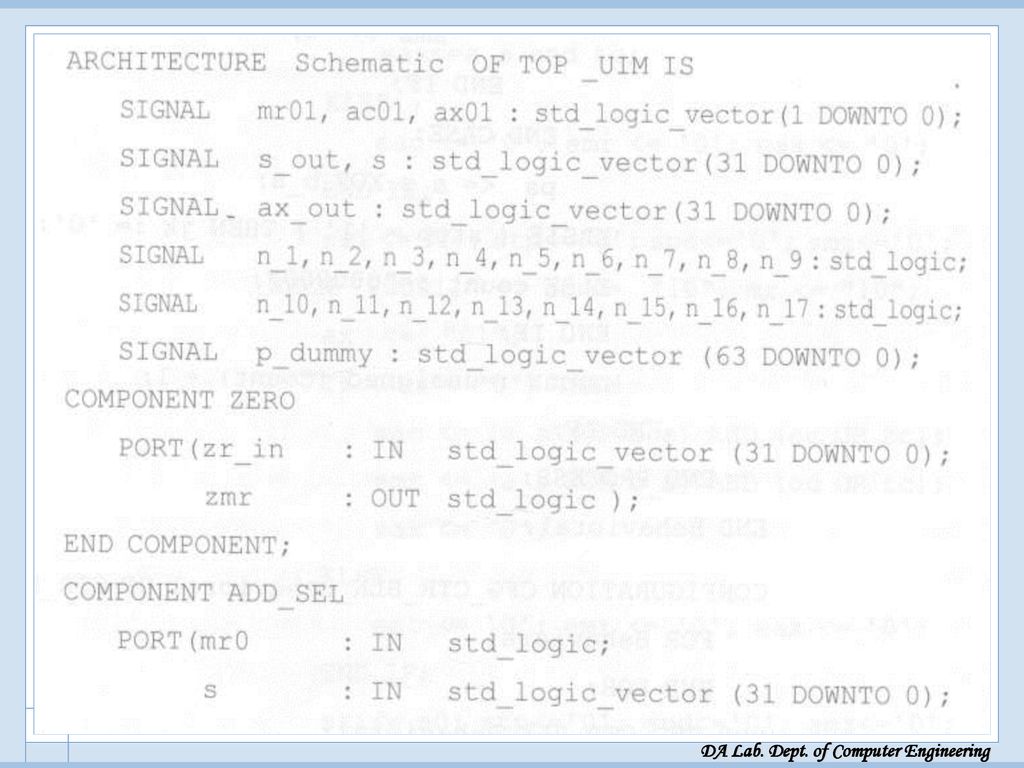
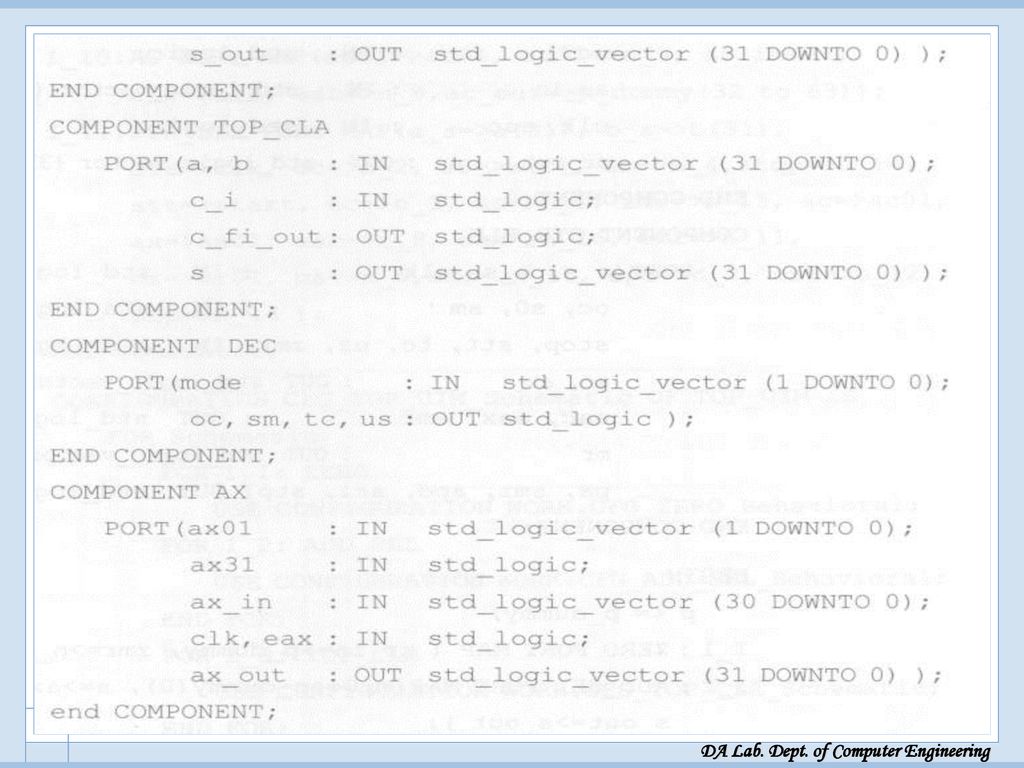
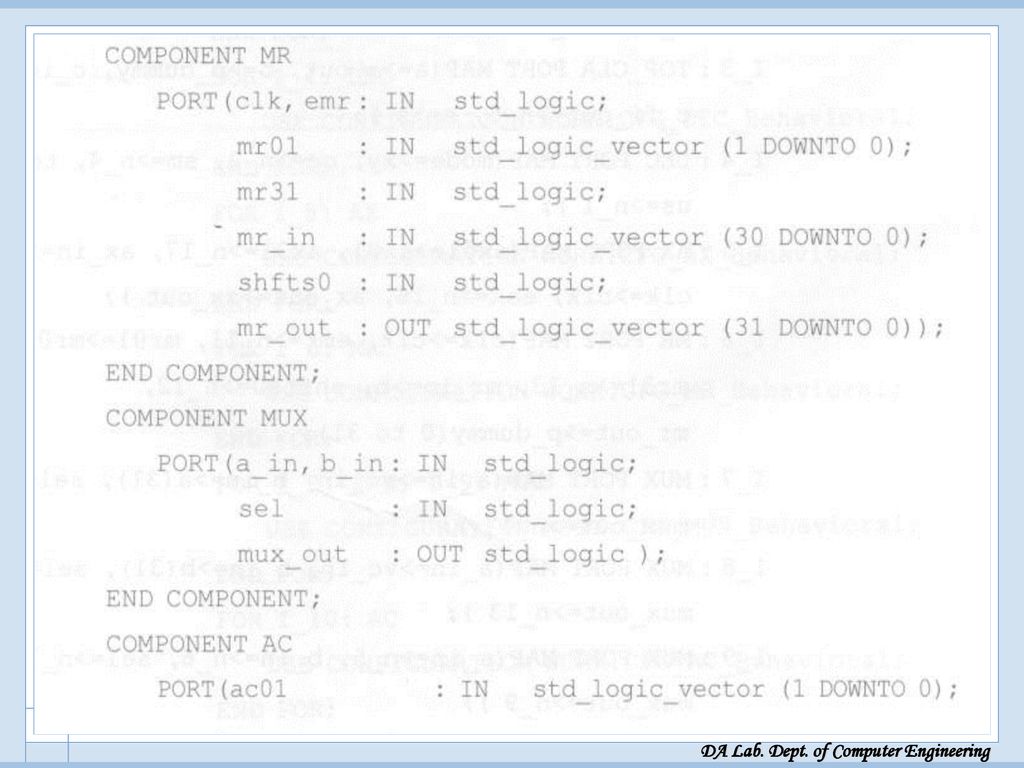
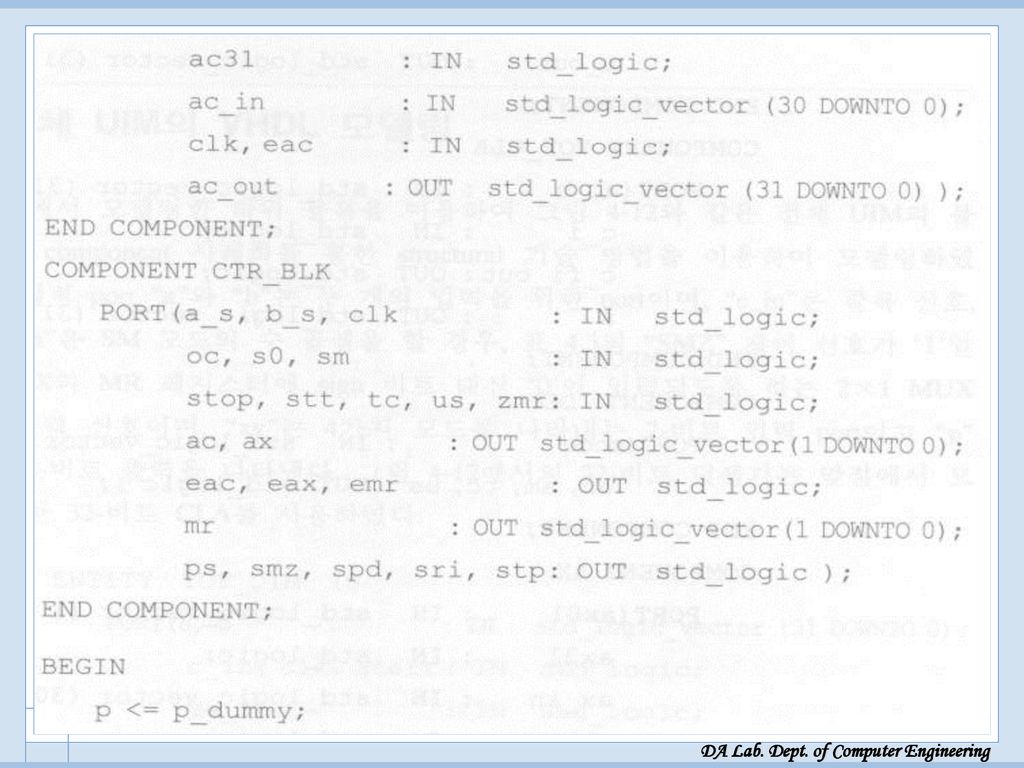
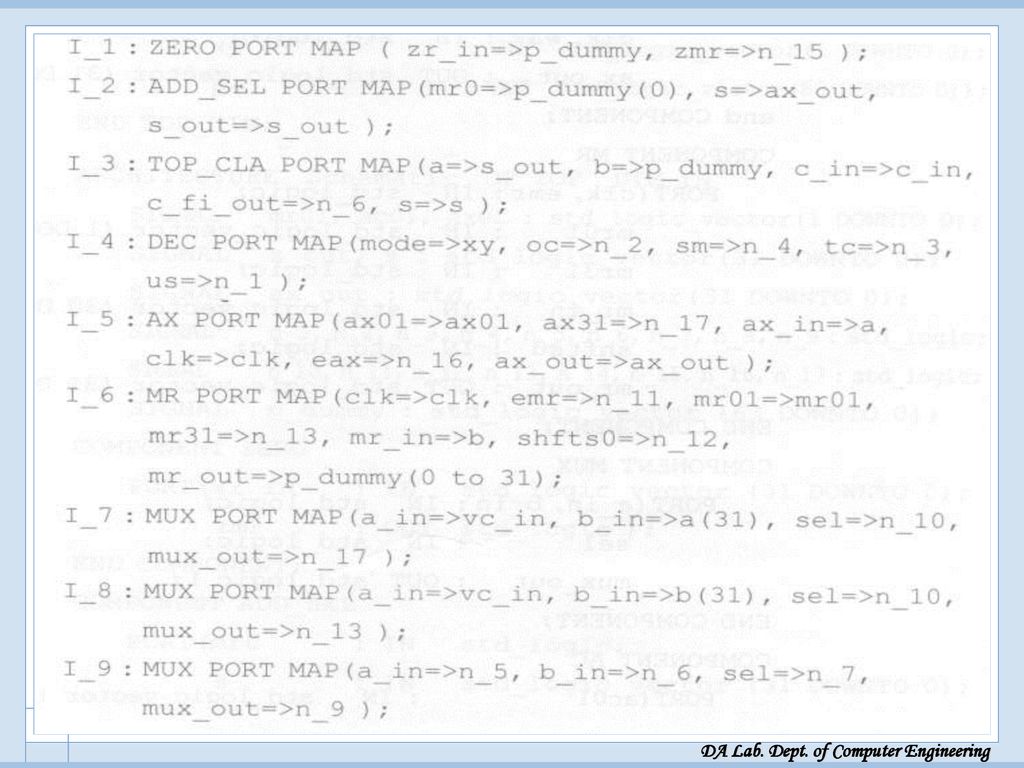
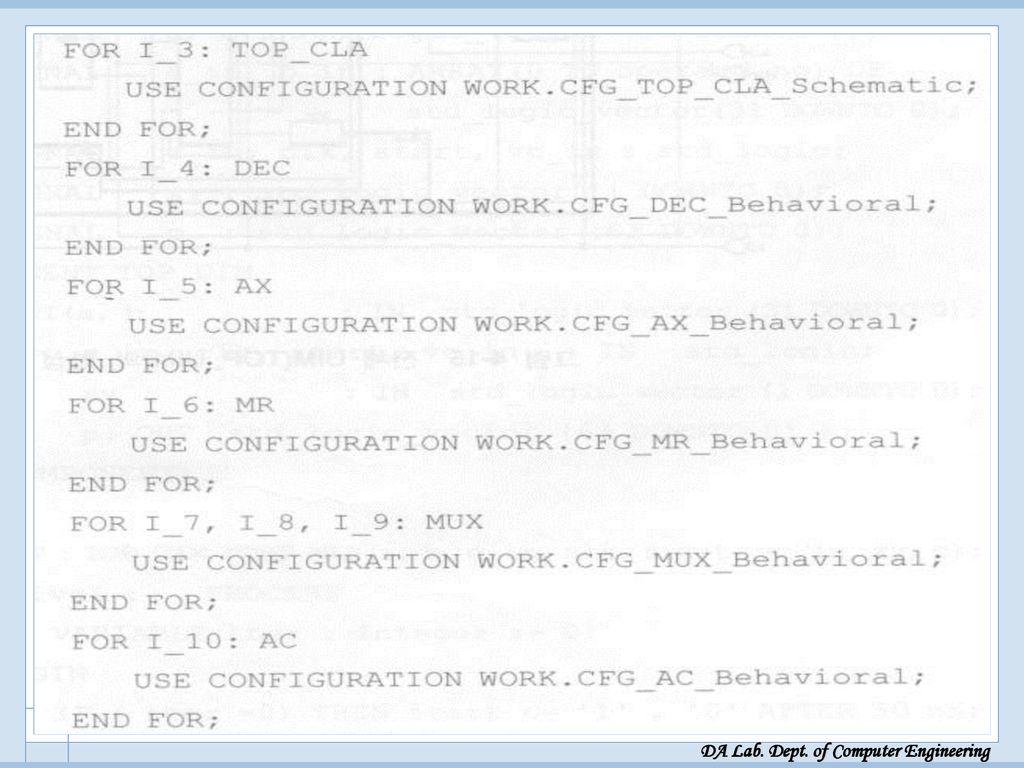
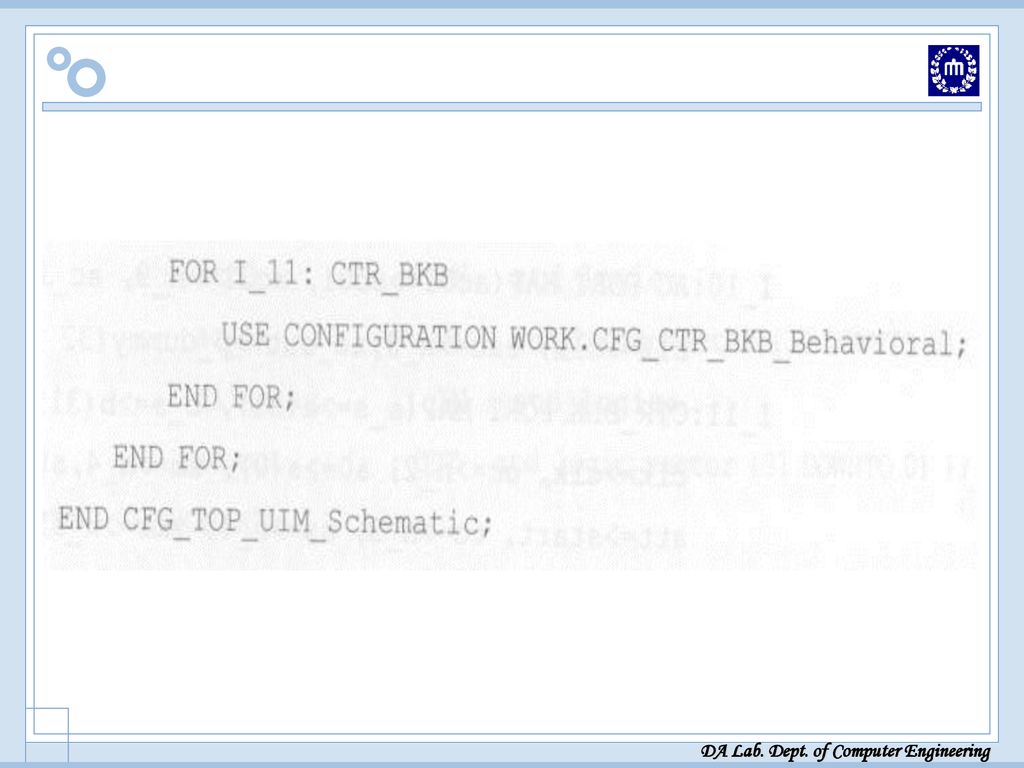
UIM 전체 VHDL 모델링 UIM 전체 VHDL 모델링
Start: 시작 신호, c_in: carry in, clk: clock vc_in 은 SM 모드수 곱셈시에, SMZ 제어 신호가 1일때, AX와 MR 레지스터에 sign bit 대신 ‘0’이 입력되도록 하는 2x1 MUX의 입력신호(‘0’ 부분)로 쓰임 xy: 모드 p: 64 비트 출력
로 쓰임. xy: 모드. p: 64 비트 출력.")
72
UIM 전체 VHDL 모델링[VHDL 소스]
![UIM 전체 VHDL 모델링[VHDL 소스]](http://slidesplayer.org/slide/14456355/90/images/72/UIM+%EC%A0%84%EC%B2%B4+VHDL+%EB%AA%A8%EB%8D%B8%EB%A7%81%5BVHDL+%EC%86%8C%EC%8A%A4%5D.jpg "UIM 전체 VHDL 모델링[VHDL 소스]")















>")

![암 보다 더 무서운 당뇨 2010년 [아시아경제 강경훈 기자 2010.11.02].](/86/14054160/big_thumb.jpg "암 보다 더 무서운 당뇨 2010년 [아시아경제 강경훈 기자 2010.11.02].>")









>")




 - 8086 매크로 어셈블리어 시스템프로그래밍.>")
.>")