Download presentation
1
문자코드 변환 콘코던서 형태소분석기 한국어 정보의 전산처리

2
문서의 포맷 변환: 글 파일 대부분의 텍스트 처리 소프트웨어는 텍스트 파일을 입출력 포 맷으로 함.
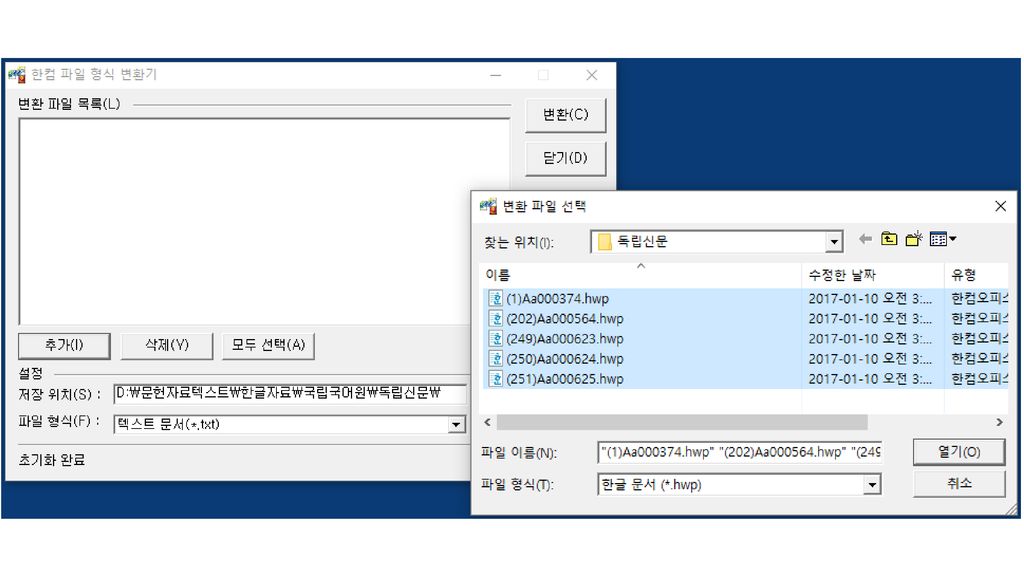
인문학 분야의 전산화된 자료 중에는 한글과 컴퓨터社의 워드 프로세서인 “글” 포맷으로 된 경우가 종종 있음. “글” 파일은 한컴社 나름대로 만드 한컴 문자코드를 바탕으로 하고 있으므로, 다른 소프트웨어에서는 사용할 수 없음. 글(hwp) 파일을 텍스트(txt) 파일로 변환해야만 함. 하나하나의 문서에 대해 글 워드프로세서에서 일일이 “다른 이름으로 저장하기” 메뉴로 변환하는 것은, 수많은 파일을 다루 는 경우에는 비효율적임. 이럴 때는 “한컴 파일형식 변환기“(HwpConv)가 편리함.
 파일을 텍스트(txt) 파일로 변환해야만 함. 하나하나의 문서에 대해 글 워드프로세서에서 일일이 다른 이름으로 저장하기 메뉴로 변환하는 것은, 수많은 파일을 다루 는 경우에는 비효율적임. 이럴 때는 한컴 파일형식 변환기 (HwpConv)가 편리함.")
4
한컴 파일형식 변환기 사용시 유의점 출력 파일 형식은 대개 “텍스트 문서”를 선택해야 함.
텍스트 문서에도 여러 가지 문자 인코딩 방식이 있을 수 있는데 글에서 개별 문서에 대해 “다른 이름으로 저장” 메뉴를 사용할 때는 이런 여러 인코딩을 선택할 수 있는 반면에 한컴 파일형식 변환기에서는 자동으로 시스템 기본 인코딩(한 글 윈도즈 운영체제의 경우 cp949=완성형)으로 변환해 버림. 한글 완성형에서 지원하지 않는 문자는 $#코드번호; 형식으로 출력함. (이 코드번호는 유니코드의 코드값) 한글 완성형에서 지원하지 않는 문자를 포함하고 있지 않다면, 이 방법은 문제가 없음.
으로 변환해 버림. 한글 완성형에서 지원하지 않는 문자는 $#코드번호; 형식으로 출력함. (이 코드번호는 유니코드의 코드값) 한글 완성형에서 지원하지 않는 문자를 포함하고 있지 않다면, 이 방법은 문제가 없음.")
5
텍스트 파일의 코드변환 하나의 파일을 대상으로 할 때는, 텍스트 에디터에서 “다른 이름으로 저장하기 “ 메뉴를 이용하면 됨.
수백, 수천 개의 파일을 대상으로 할 때는, 그 방법이 비효율적임. 이럴 때는 command line tool이 적절함. uniconv [input-encoding] [input-file] [output-encoding] [output-file] uniconv.exe와 BTUC220.DLL을 C:/Cygwin64/bin 폴더에 복사할 것. (모든 폴더에서 이용 할 수 있도록 하기 위해) 윈도즈 운영체제에서는 그런 경우 batch 파일을 만들어서 처리하면 효율적임. 리눅스나 cygwin에서는 bash shell script를 만들어서 처리하는 것이 더 효율적 임. #!/usr/bin/env bash for fn in `ls *.txt`; do uniconv ucs2 $fn utf-8 u8/$fn done
 윈도즈 운영체제에서는 그런 경우 batch 파일을 만들어서 처리하면 효율적임. 리눅스나 cygwin에서는 bash shell script를 만들어서 처리하는 것이 더 효율적 임. #!/usr/bin/env bash. for fn in `ls *.txt`; do. uniconv ucs2 $fn utf-8 u8/$fn. done.")
6
유니코드 서명(signature) 유니코드 문서에서, “이 문서는 ~~ 인코딩으로 되어 있습니다” 하는 정보를 알려주는 특수 문자 BOM(byte order mark)라고도 함. UTF-16LE(little-endian) : 0xff 0xfe UTF-16BE(big-endian) : 0xfe 0xff UTF-8 : 0xff 0xff 0xfe “BOM은 만악의 근원이다”라는 인식이 프로그래머들 사이에 확 산되고 있어, BOM을 붙이지 않는 것이 최근 추세.
 : 0xff 0xfe. UTF-16BE(big-endian) : 0xfe 0xff. UTF-8 : 0xff 0xff 0xfe. BOM은 만악의 근원이다 라는 인식이 프로그래머들 사이에 확 산되고 있어, BOM을 붙이지 않는 것이 최근 추세.")
7
운영체제에 따른 줄바꿈 문자의 차이 기계식 타자기에서 줄을 바꿀 때에는
CR(carriage return, 헤드를 맨 왼쪽으로 보냄)과 LF(line feed, 헤드를 한 줄 아래로 내림) 둘 다 수행해야 했음. 아스키 코드에서 CR은 0x0d, LF는 0x0a를 할당받음. Unix 및 그 뒤를 이은 Linux에서는 LF만으로 줄바꿈을 나타냄. Macintosh에서는 CR만으로 줄바꿈을 나타냄. Microsoft의 MS-DOS 및 윈도즈 운영체제에서는 CR-LF 2개의 문자로 줄바꿈을 나타냄. 지능적인 소프트웨어는 줄바꿈 문자가 이 세 가지 중 어느 것으로 되어 있는지 판단해서 적절히 대응함. EmEdior 등에서는 파일 저장시 줄바꿈 문자 지정 가능. CR-LF를 LF로 바꾸는 command: <input sed -e 's/\r//' >output
과 LF(line feed, 헤드를 한 줄 아래로 내림) 둘 다 수행해야 했음. 아스키 코드에서 CR은 0x0d, LF는 0x0a를 할당받음. Unix 및 그 뒤를 이은 Linux에서는 LF만으로 줄바꿈을 나타냄. Macintosh에서는 CR만으로 줄바꿈을 나타냄. Microsoft의 MS-DOS 및 윈도즈 운영체제에서는 CR-LF 2개의 문자로 줄바꿈을 나타냄. 지능적인 소프트웨어는 줄바꿈 문자가 이 세 가지 중 어느 것으로 되어 있는지 판단해서 적절히 대응함. EmEdior 등에서는 파일 저장시 줄바꿈 문자 지정 가능. CR-LF를 LF로 바꾸는 command: <input sed -e s/\r// >output.")
8
배치(batch) 처리 명령 프롬프트에서 내릴 일련의 명령들을 (한 줄에 하나의 명령 씩) 하나의 파일(배치 파일)에 모아 놓아서 이 파일을 ~~.bat라고 이름붙여 놓고 명령 프롬프트에서 ~~(.bat)라고 하면 이 파일 안의 명령들이 순차적으로 실행됨. 배치 파일의 줄바꿈 문자는 CR-LF로 되어 있어야 함. 배치 파일의 인코딩은 시스템 default(한글 윈도즈의 경우 cp949)이어야 함. 배치 파일로 처리할 수 있는 일의 거의 대부분은 bash shell로 처리할 수 있고, 그것이 더 elegant한 방법임.
이어야 함. 배치 파일로 처리할 수 있는 일의 거의 대부분은 bash shell로 처리할 수 있고, 그것이 더 elegant한 방법임.")
9
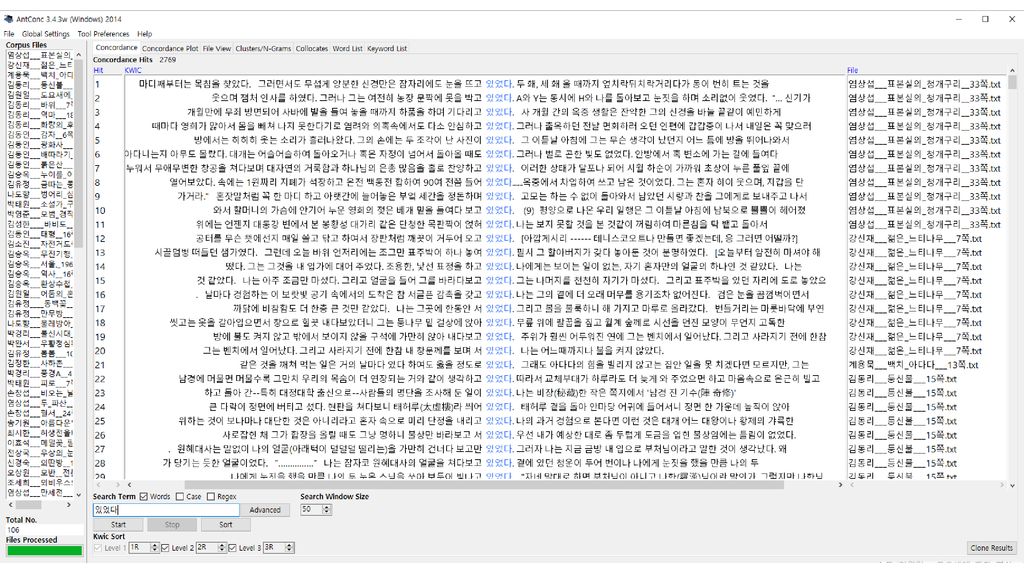
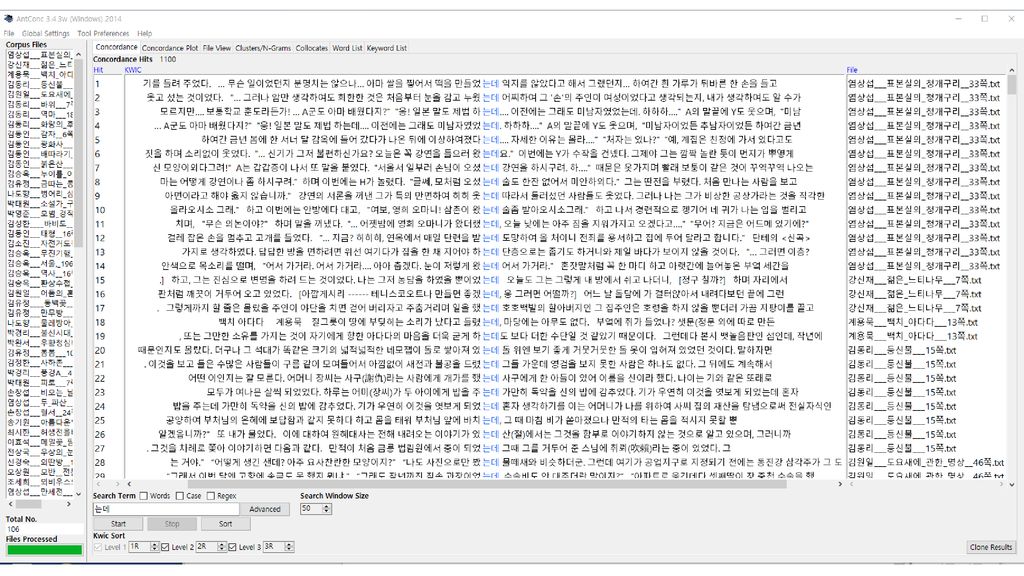
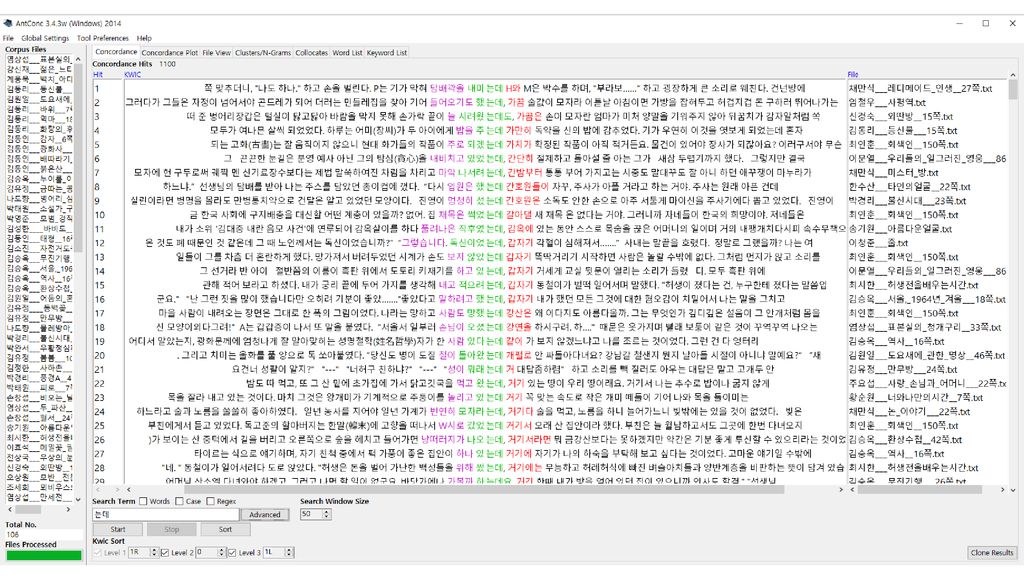
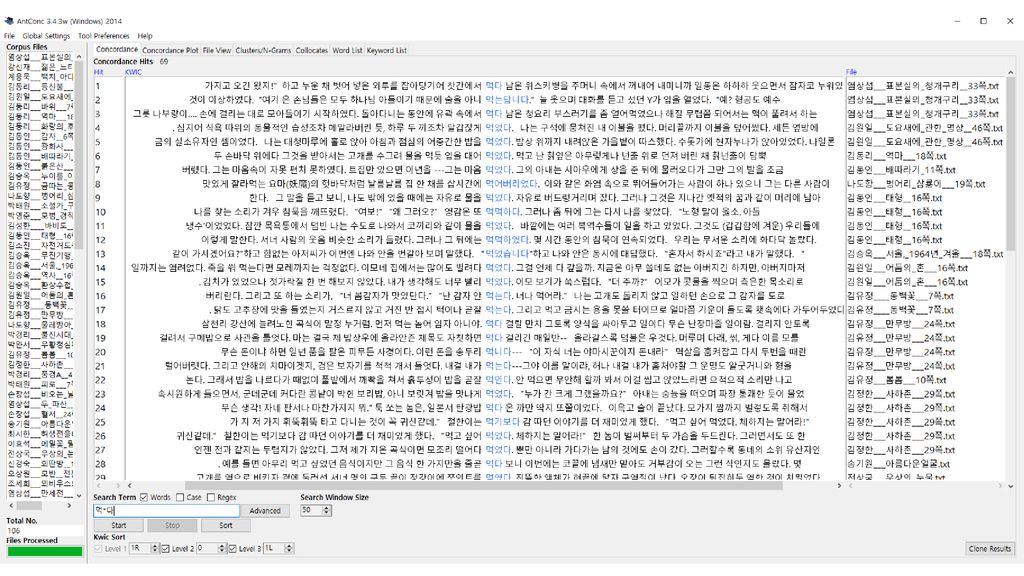
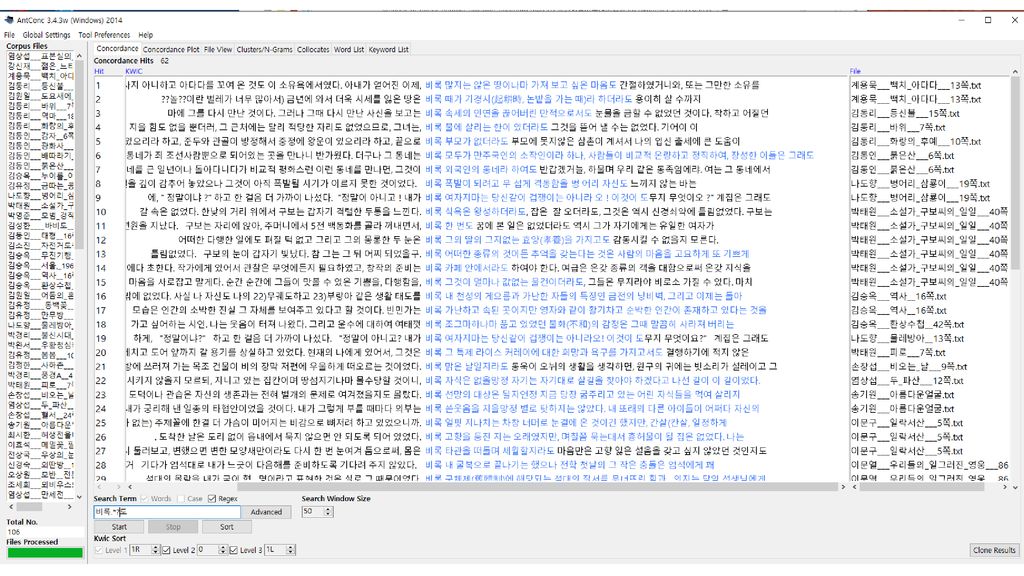
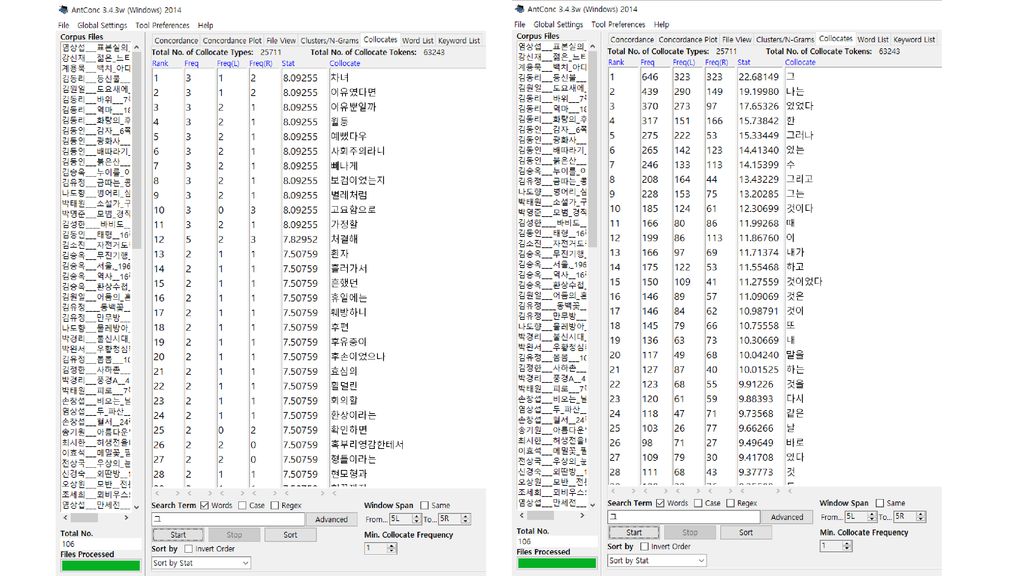
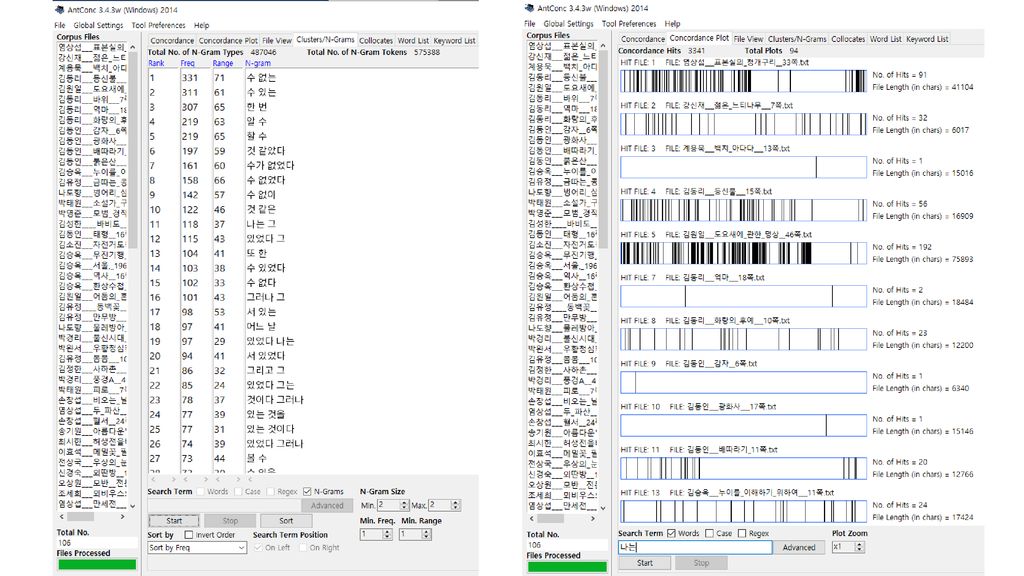
콘코던서(Concordancer) 입력 텍스트 파일에서 사용자가 찾고자 하는 문자열을 찾아서 보여주는 소프트웨어
입력 텍스트 파일에서 사용자가 찾고자 하는 문자열을 찾아서 보여주는 소프트웨어 과거에는 kwoc(key word out of context) 방식도 쓰였으나 요즘은 대개 kwic(key word in context) 방식으로 보여줌. 문자열 검색 기능이 기본이나, 여기에 몇몇 기능이 추가되기도 함. 고급 검색: 아무개문자(wild card) 검색, 정규표현 검색, 자소 검색 검색 결과의 소팅: 앞뒤 문맥 기준, 제2, 제3의 소팅 기준 사용 통계: 어절/단어 통계, 음절 통계, 자소 통계 연어 정보: 두 요소가 일정한 범위 내에서 공기하는 빈도
 방식도 쓰였으나. 요즘은 대개 kwic(key word in context) 방식으로 보여줌. 문자열 검색 기능이 기본이나, 여기에 몇몇 기능이 추가되기도 함. 고급 검색: 아무개문자(wild card) 검색, 정규표현 검색, 자소 검색. 검색 결과의 소팅: 앞뒤 문맥 기준, 제2, 제3의 소팅 기준 사용. 통계: 어절/단어 통계, 음절 통계, 자소 통계. 연어 정보: 두 요소가 일정한 범위 내에서 공기하는 빈도.")
10
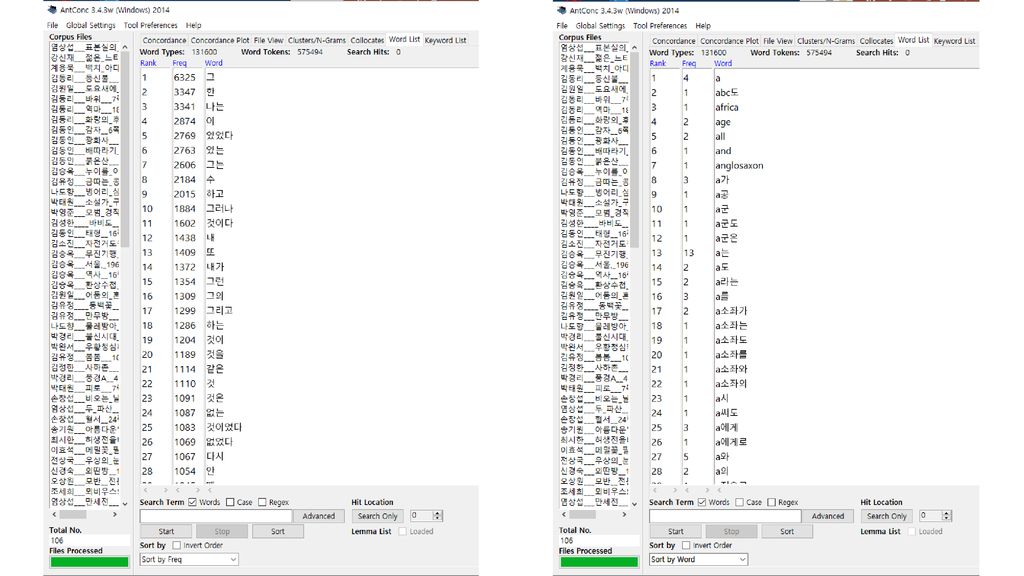
AntConc 일본 와세다 대학의 Laurence Anthony가 개발.
Perl로 제작하여, 여러 운영체제용의 실행 파일로 컴파일. 무료, 다양한 기능 제공, 실행 속도가 비교적 빠름. 사용자 피드백을 수용하여, 비교적 자주 업데이트됨. 다양한 인코딩 지원. 기본 검색은 어절을 단위로 함: 입력한 검색어가 온전한 어절을 이루는 경우만 찾아 줌. 어절의 일부를 검색하려면 Words 선택을 해제해야 함.

19
콘코던서들의 비교 EmEditor 글잡이 한마루 깜짝새 UniConc MonoConc AntConc 복수 파일 처리 ○ ×
유니코드 처리 △ 통계 정규표현 자소 검색 연어 N-gram

20
형태소분석기 언어학적 분석이 전혀 되어 있지 않은 말뭉치(corpus)를 원시 말뭉치 (raw corpus)라고 함.
원시 말뭉치로부터도 유용한 정보를 많이 얻을 수 있기는 하나 한국어에는 조사와 어미가 매우 다양해서 [체언+조사], [용언+어미]의 다양한 형태를 그대로 놔둔 상태에서 여 러 정보/통계를 뽑는다면 많은 문제가 발생. ‘사람이’가 몇 번, ‘사람을‘이 몇 번 나온다는 정보보다는 ‘사람‘이 몇 번, 조사 ‘-이’가 몇 번, 조사 ‘-을‘이 몇 번 나온다는 정보가 유용함. 이를 위해 형태소분석기가 유용함. 정확도가 100%는 아니지만 95% 이상은 되므로, 대체적인 경향성을 파악하는 데는 큰 문제가 없음.

21
형태소분석기들의 비교 공개된 것들을 중심으로 비교함. 강승식 교수(국민대)의 HAM: 태그셋이 매우 단순함.
지능형 형태소 분석기 21세기 세종계획의 일환으로, 고려대 컴공과 임해창 교수 연구실에서 만듦. 완성형만 지원. (유니코드 지원 안 함) 최신 운영체제에서 잘 작동하지 않음. (유지 보수가 잘 안 되고 있음) Utagger 울산대 한국어 처리 연구실(옥철영 교수)에서 만듦. 유니코드 지원. 성능이 상당히 우수한 편. 특징: 공부하/VV (cf. 공부/NNG+하/XSV) 꼬꼬마 서울대 컴퓨터공학과 이상구 교수 연구실에서 만듦. Java 기반.
 최신 운영체제에서 잘 작동하지 않음. (유지 보수가 잘 안 되고 있음) Utagger. 울산대 한국어 처리 연구실(옥철영 교수)에서 만듦. 유니코드 지원. 성능이 상당히 우수한 편. 특징: 공부하/VV (cf. 공부/NNG+하/XSV) 꼬꼬마. 서울대 컴퓨터공학과 이상구 교수 연구실에서 만듦. Java 기반.")

![- C-style formatting - format() method. file = open(‘file.txt’, [mode]) ◦ Mode ‘r’: for reading (default) ‘w’: for writing (truncate if already.](/40/11033319/big_thumb.jpg "- C-style formatting - format() method. file = open(‘file.txt’, [mode]) ◦ Mode ‘r’: for reading (default) ‘w’: for writing (truncate if already.>")











.>")



![[Homework #3] [복습문제, p444~446]에서 다음 문제의 해답제시](/90/14589151/big_thumb.jpg "[Homework #3] [복습문제, p444~446]에서 다음 문제의 해답제시>")


![[beginning] Linux & vi editor](/90/14725631/big_thumb.jpg "[beginning] Linux & vi editor>")