Download presentation
1
비모수 분석 및 복습

2
생명표(life table), Kaplan-Meier
자료에 따른 통계분석 방법 알고 싶은 내용 모수적 방법 (정규성) 비모수적 방법 (정규성아님) 독립된 두 집단의 평균 비교 t-test Wilcoxon test 짝지은 두 집단의 평균 비교 Paired t-test Paired-samples Wilcoxon test 세 집단 이상 평균 비교 ANOVA (Analysis of Variance) Kruskal-Wallis test 반복 측정된 세 집단 이상의 평균 비교 Repeated measured ANOVA Friedman rank-sum test 두 변수간의 상관관계 Pearson’s correlation Spearman’s correlation Kendall’s tau 독립(설명)변수와 연속형 종속(반응)변수와의 관계 회귀분석 (Linear regression analysis) 독립(설명)변수와 이분형 종속(반응)변수와의 관계 로지스틱 회귀분석 (Logistic regression analysis) 두 집단 이상의 frequency 비교 Chi-square test (χ2 test) Fisher’s exact test 시간에 따른 event 발생 위험도 산출 생명표(life table), Kaplan-Meier Weibull model, exponential model, Gaussian model, logistic model, lognormal model, log-logistic model Cox proportional hazard model
 비모수적 방법 (정규성아님) 독립된 두 집단의 평균 비교. t-test. Wilcoxon test. 짝지은 두 집단의 평균 비교. Paired t-test. Paired-samples Wilcoxon test. 세 집단 이상 평균 비교. ANOVA (Analysis of Variance) Kruskal-Wallis test. 반복 측정된 세 집단 이상의 평균 비교. Repeated measured ANOVA. Friedman rank-sum test. 두 변수간의 상관관계. Pearson’s correlation. Spearman’s correlation. Kendall’s tau. 독립(설명)변수와 연속형 종속(반응)변수와의 관계. 회귀분석 (Linear regression analysis) 독립(설명)변수와 이분형 종속(반응)변수와의 관계. 로지스틱 회귀분석 (Logistic regression analysis) 두 집단 이상의 frequency 비교. Chi-square test (χ2 test) Fisher’s exact test. 시간에 따른 event 발생 위험도 산출. 생명표(life table), Kaplan-Meier. Weibull model, exponential model, Gaussian model, logistic model, lognormal model, log-logistic model. Cox proportional hazard model.")
3
두 집단 평균치 분석

4
성별 강박 표준화 점수(t_obs)의 평균이 같을까?
대립가설: 성별 강박 표준화 점수(T_OBS)의 평균이 다르다. 먼저 독립된 두 집단의 분산이 같은지 다른지를 판단 =>분산동질성 검정을 실시
의 평균이 다르다. 먼저 독립된 두 집단의 분산이 같은지 다른지를 판단. =>분산동질성 검정을 실시.")
5
obsessive compulsive symptom
표 틀 만들고 채우기 Table 1. Distribution of standardized score of obsessive compulsive symptom according to gender Standardized score of obsessive compulsive symptom N % Mean SD All Gender Male Female p-value p-value calculated using t-test 수치적 요약 빈도 분포 반드시 먼저 성별변수(sex)를 요인으로 만든 후
를 요인으로 만든 후.")
6
성별변수(sex)를 요인으로 바꾸기
를 요인으로 바꾸기")
7
성별 빈도분포

8
분산 동질성 검정: 분산이 같은지 먼저 확인

9
p-value가 유의수준 0.05보다 크므로 귀무가설을 기각할 수 없다. (p=0.21)
따라서, 성별 강박표준화 점수의 분산에는 차이가 있다고 할 수 없다. 즉, 동등한 분산을 가졌다고 할 수 있다.

10
성별 강박 표준화 점수(T_OBS)의 평균이 같을까?
분산 동질성 검정을 하였으므로 독립된 두 집단의 평균에 차이가 있는지를 검정하기 위해 t-test 실시

11
분산동질성검정결과 분산이 다르다고 할 수 없으므로

12
결과 해석: p-value가 유의수준 0.05보다 작으므로 귀무가설을 기각할 수 있다. (p<0.0001) 따라서, 성별 강박표준화 점수의 평균에는 차이가 있다고 할 수 있다.
 따라서, 성별 강박표준화 점수의 평균에는 차이가 있다고 할 수 있다.")
13
Table 2. Distribution of standardized score of obsessive compulsive
symptom according to gender Standardized score of obsessive compulsive symptom N % Mean SD All 1197 100.0 50.0 10.0 Gender Male 554 46.3 48.3 9.6 Female 643 53.7 51.4 10.1 p-value <0.0001 p-value calculated using t-test

14
생명표(life table), Kaplan-Meier
자료에 따른 통계분석 방법 알고 싶은 내용 모수적 방법 (정규성) 비모수적 방법 (정규성아님) 독립된 두 집단의 평균 비교 t-test Wilcoxon test 짝지은 두 집단의 평균 비교 Paired t-test Paired-samples Wilcoxon test 세 집단 이상 평균 비교 ANOVA (Analysis of Variance) Kruskal-Wallis test 반복 측정된 세 집단 이상의 평균 비교 Repeated measured ANOVA Friedman rank-sum test 두 변수간의 상관관계 Pearson’s correlation Spearman’s correlation Kendall’s tau 독립(설명)변수와 연속형 종속(반응)변수와의 관계 회귀분석 (Linear regression analysis) 독립(설명)변수와 이분형 종속(반응)변수와의 관계 로지스틱 회귀분석 (Logistic regression analysis) 두 집단 이상의 frequency 비교 Chi-square test (χ2 test) Fisher’s exact test 시간에 따른 event 발생 위험도 산출 생명표(life table), Kaplan-Meier Weibull model, exponential model, Gaussian model, logistic model, lognormal model, log-logistic model Cox proportional hazard model
 비모수적 방법 (정규성아님) 독립된 두 집단의 평균 비교. t-test. Wilcoxon test. 짝지은 두 집단의 평균 비교. Paired t-test. Paired-samples Wilcoxon test. 세 집단 이상 평균 비교. ANOVA (Analysis of Variance) Kruskal-Wallis test. 반복 측정된 세 집단 이상의 평균 비교. Repeated measured ANOVA. Friedman rank-sum test. 두 변수간의 상관관계. Pearson’s correlation. Spearman’s correlation. Kendall’s tau. 독립(설명)변수와 연속형 종속(반응)변수와의 관계. 회귀분석 (Linear regression analysis) 독립(설명)변수와 이분형 종속(반응)변수와의 관계. 로지스틱 회귀분석 (Logistic regression analysis) 두 집단 이상의 frequency 비교. Chi-square test (χ2 test) Fisher’s exact test. 시간에 따른 event 발생 위험도 산출. 생명표(life table), Kaplan-Meier. Weibull model, exponential model, Gaussian model, logistic model, lognormal model, log-logistic model. Cox proportional hazard model.")
15
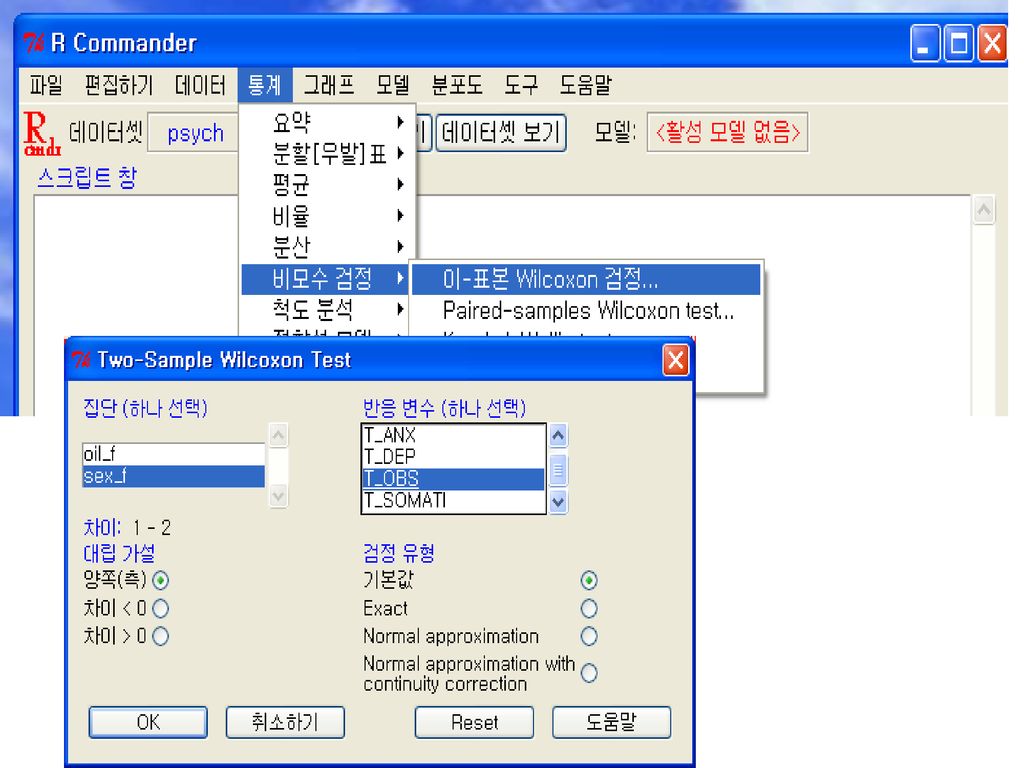
Wilcoxon rank sum test 비모수적 방법을 사용할 때! –표본수가 적어 모집단의 분포를 가정할 수 없는 경우
–순위 척도인 경우

16
비모수적 방법 (Wilcoxon test)
성별 강박 표준화 점수(T_OBS)의 평균이 같을까? 비모수적 방법에서는 평균비교가 아니라 실제로 중앙값을 비교하게 된다. 따라서 분산동질성 검정이 필요없다. 귀무가설: 성별 강박 표준화 점수(T_OBS)의 평균이 같다. 대립가설: 성별 강박 표준화 점수(T_OBS)의 평균이 다르다. 독립된 두 집단의 평균비교를 하는데 비모수적 방법을 사용하므로 Wilcoxon test를 사용한다.
의 평균이 같을까 비모수적 방법에서는 평균비교가 아니라 실제로 중앙값을 비교하게 된다. 따라서 분산동질성 검정이 필요없다. 귀무가설: 성별 강박 표준화 점수(T_OBS)의 평균이 같다. 대립가설: 성별 강박 표준화 점수(T_OBS)의 평균이 다르다. 독립된 두 집단의 평균비교를 하는데 비모수적 방법을 사용하므로 Wilcoxon test를 사용한다.")
18
p-value가 유의수준 0.05보다 작으므로 귀무가설을 기각할 수 있다. (p<0.0001)
따라서, 성별 강박표준화 점수의 평균에는 차이가 있다고 할 수 있다.

19
세 집단이상의 평균치 분석

20
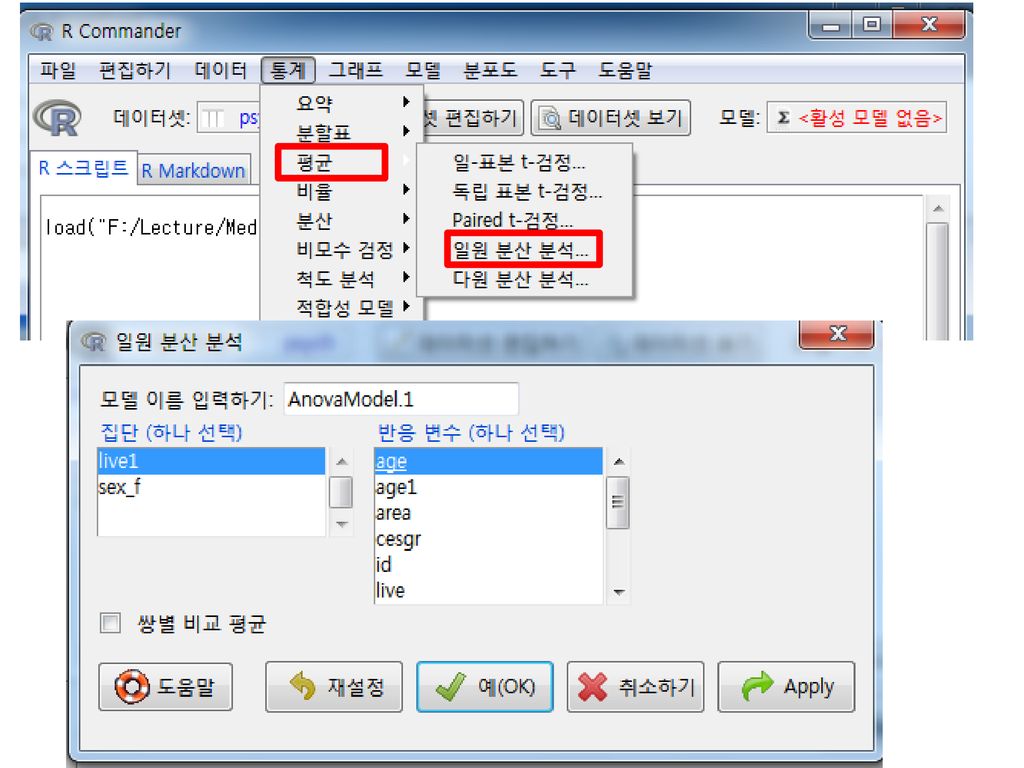
세 집단 이상에서의 그룹간 평균비교 : ANOVA
그룹에 따른 어떤 변수의 평균을 비교하고 싶다면 그룹에 해당되는 변수는 범주형(요인)이어야 하고, 평균을 비교하고 싶은 변수는 연속형이며 정규분포를 따라야 한다.
이어야 하고, 평균을 비교하고 싶은 변수는 연속형이며 정규분포를 따라야 한다.")
21
지역별로 주민들의 연령의 평균에 차이가 있는가?
귀무가설: 모든 지역에서 주민들의 연령의 평균은 같다. 대립가설: 모든 지역에서 주민들의 연령의 평균이 같은 것은 아니다.

22
지역별(live1) : factor(범주형) 변수
연령(age) : 연속형 변수
 : 연속형 변수.")
24
p-value가 유의수준 0.05보다 작으므로 귀무가설을 기각할 수 있다. (p<0.0001)
그룹별 평균과 표준편차를 구해줌 p-value가 유의수준 0.05보다 작으므로 귀무가설을 기각할 수 있다. (p<0.0001) 즉, 유의수준 0.05하에서 각 지역별 주민들의 연령의 평균이 모두 같다고 할 수 없다.
 즉, 유의수준 0.05하에서 각 지역별 주민들의 연령의 평균이 모두 같다고 할 수 없다.")
25
다중비교(multiple comparison), 사후검정
P-value : 4개 지역 중 어느 하나라도 다른 지역과 연령에 차이가 있으면 차이가 있는 것으로 판정 구체적으로 어느 지역과 어느 지역의 연령에 차이가 있는지를 알려면??

26
다중비교(multiple comparison), 사후검정
, 사후검정")
27
귀무가설: 지역1과 지역2의 주민들의 연령 평균에는 차이가 없다.
각각의 신뢰구간이 0을 포함하는지 여부 확인 0을 포함: 귀무가설 기각할 수 없음 0을 포함하지 않음: 귀무가설 기각할 수 있음

28
유의수준 0.05하에서 지역1과 지역2의 주민 연령평균에는 차이가 없다고 할 수 있다.
유의수준 0.05하에서 지역1과 지역3, 지역1과 지역4, 지역2와 지역3, 지역2와 지역4, 지역3과 지역4 주민의 연령 평균에는 유의한 차이가 있다고 할 수 있다.

29
Excel에서 Table 만들기 기존 변수 새로 만든 변수 live live1 1과 2 1 3과 4 2 5, 6, 7 3 8 4 Table 1. Distribution of age according to living area N % Mean SD All 1197 100.0 44.9 20.7 Living area 1 and 2 411 34.3 49.0 19.4 3 and 4 203 17.0 49.9 20.0 5, 6, and 7 283 23.6 44.8 21.6 8 300 25.1 36.4 19.5 p-value <0.0001 SD: 기본이 되는 평균값에 최저, 최고값의 폭 지역별 연령 평균의 차이를 알아보기 위해 ANOVA 실시하고 Turky의 사후검정을 실시하였다. 그 결과 1과 2지역을 제외한 모든 지역에서 연령의 차이는 유의한 차이를 보였다(P<0.0001).
.")
30
비모수분석: Kruskal-Wallis test

31
Kruskal-Wallis test 비모수적 방법을 사용할 때! –표본수가 적어 모집단의 분포를 가정할 수 없는 경우
–순위 척도인 경우

32
지역별로 주민들의 연령의 평균에 차이가 있는가?
귀무가설: 모든 지역에서 주민들의 연령의 평균은 같다. 대립가설: 모든 지역에서 주민들의 연령의 평균이 같은 것은 아니다.

33
앞의 모수적 방법(ANOVA)과 같은 변수 선택
과 같은 변수 선택")
34
p-value가 유의수준 0.05보다 작으므로 귀무가설을 기각할 수 있다. (p<0.0001)
따라서, 유의수준 0.05하에서 지역별 주민들의 연령의 평균은 다르다고 할 수 있다.

35
반복측정된 세 집단이상의 평균치 분석

36
생명표(life table), Kaplan-Meier
자료에 따른 통계분석 방법 알고 싶은 내용 모수적 방법 (정규성) 비모수적 방법 (정규성아님) 독립된 두 집단의 평균 비교 t-test Wilcoxon test 짝지은 두 집단의 평균 비교 Paired t-test Paired-samples Wilcoxon test 세 집단 이상 평균 비교 ANOVA (Analysis of Variance) Kruskal-Wallis test 반복 측정된 세 집단 이상의 평균 비교 Repeated measured ANOVA Friedman rank-sum test 두 변수간의 상관관계 Pearson’s correlation Spearman’s correlation Kendall’s tau 독립(설명)변수와 연속형 종속(반응)변수와의 관계 회귀분석 (Linear regression analysis) 독립(설명)변수와 이분형 종속(반응)변수와의 관계 로지스틱 회귀분석 (Logistic regression analysis) 두 집단 이상의 frequency 비교 Chi-square test (χ2 test) Fisher’s exact test 시간에 따른 event 발생 위험도 산출 생명표(life table), Kaplan-Meier Weibull model, exponential model, Gaussian model, logistic model, lognormal model, log-logistic model Cox proportional hazard model
 비모수적 방법 (정규성아님) 독립된 두 집단의 평균 비교. t-test. Wilcoxon test. 짝지은 두 집단의 평균 비교. Paired t-test. Paired-samples Wilcoxon test. 세 집단 이상 평균 비교. ANOVA (Analysis of Variance) Kruskal-Wallis test. 반복 측정된 세 집단 이상의 평균 비교. Repeated measured ANOVA. Friedman rank-sum test. 두 변수간의 상관관계. Pearson’s correlation. Spearman’s correlation. Kendall’s tau. 독립(설명)변수와 연속형 종속(반응)변수와의 관계. 회귀분석 (Linear regression analysis) 독립(설명)변수와 이분형 종속(반응)변수와의 관계. 로지스틱 회귀분석 (Logistic regression analysis) 두 집단 이상의 frequency 비교. Chi-square test (χ2 test) Fisher’s exact test. 시간에 따른 event 발생 위험도 산출. 생명표(life table), Kaplan-Meier. Weibull model, exponential model, Gaussian model, logistic model, lognormal model, log-logistic model. Cox proportional hazard model.")
37
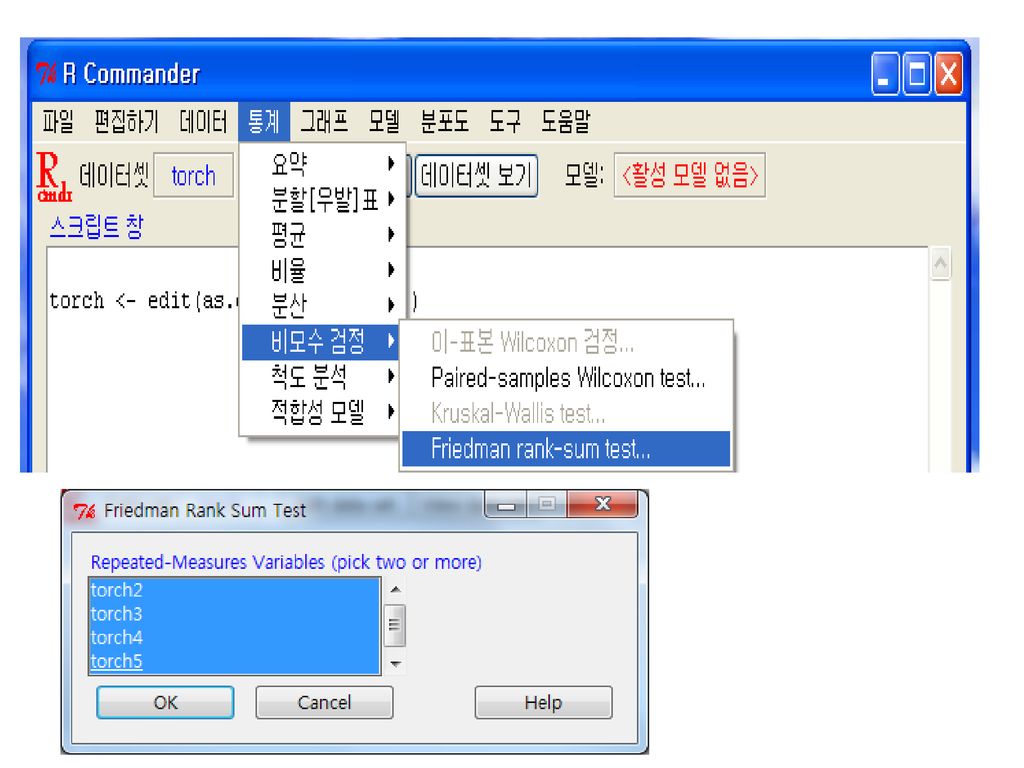
비모수의 반복 측정치 (여러 집단 또는 여러 번) 평균 비교: Friedman rank-sum test (p. 192)
 평균 비교: Friedman rank-sum test (p. 192)")
38
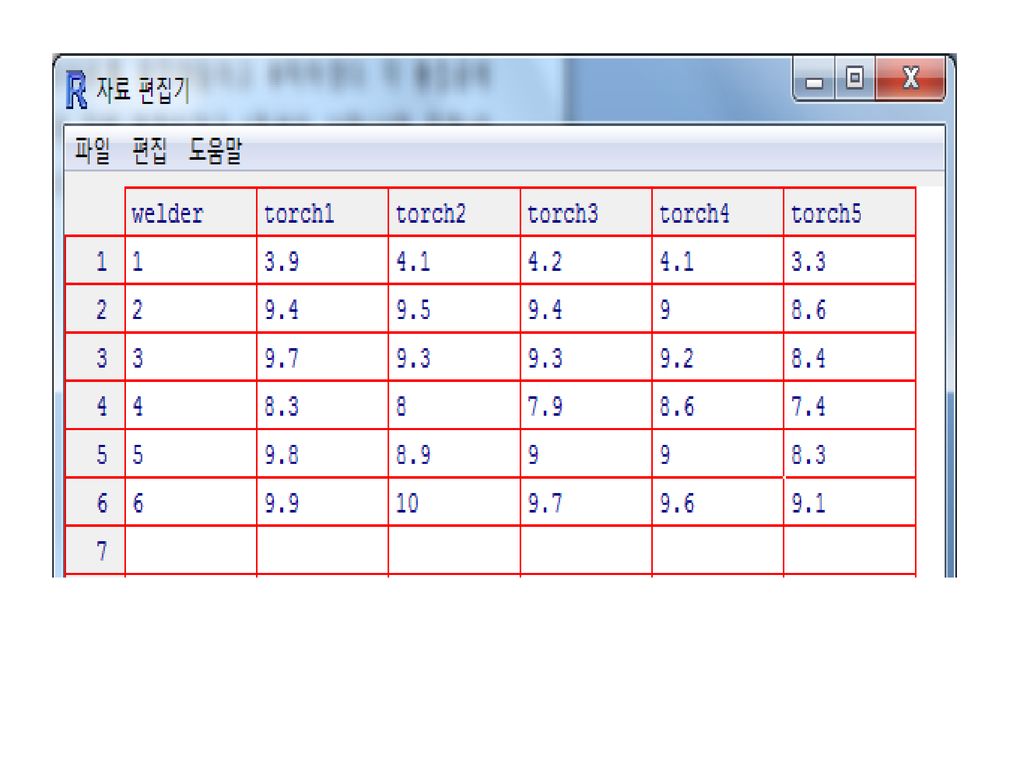
여섯 명의 용접공이 다섯 종류의 용접기를 번갈아 사용하여 그 성능 (10점 만점, 연속형점수)을 비교하였다
여섯 명의 용접공이 다섯 종류의 용접기를 번갈아 사용하여 그 성능 (10점 만점, 연속형점수)을 비교하였다. 이 용접기들의 성능이 같다고 할 수 있는가? (p.193 표 5-1) 용접공 용접기1 용접기2 용접기3 용접기4 용접기5 1 3.9 4.1 4.2 3.3 2 9.4 9.5 9.0 8.6 3 9.7 9.3 9.2 8.4 4 8.3 8.0 7.9 7.4 5 9.8 8.9 9.0 8.3 6 9.9 10.0 9.7 9.6 9.1 다른 예: 여섯 개의 항생제를 다섯 종류의 박테리아 배지에 떨어뜨렸을 때 살균력을 반지름으로 측정하였다. 항생제의 살균력이 같다고 할 수 있는가?
을 비교하였다. 이 용접기들의 성능이 같다고 할 수 있는가 (p.193 표 5-1) 용접공. 용접기1. 용접기2. 용접기3. 용접기4. 용접기 다른 예: 여섯 개의 항생제를 다섯 종류의 박테리아 배지에 떨어뜨렸을 때 살균력을 반지름으로 측정하였다. 항생제의 살균력이 같다고 할 수 있는가")
42
용접기1의 점수 중앙값이 가장 높다.->용접기 1의 성능이 가장 높다.
평균대신 중앙값 비교 (비모수) 용접기1의 점수 중앙값이 가장 높다.->용접기 1의 성능이 가장 높다. p-value가 유의수준 0.05보다 작으므로 귀무가설을 기각할 수 있다. (p=0.009) 즉, 유의수준 0.05하에서 용접기의 성능에는 차이가 있다고 할 수 있다.
 용접기1의 점수 중앙값이 가장 높다.->용접기 1의 성능이 가장 높다. p-value가 유의수준 0.05보다 작으므로 귀무가설을 기각할 수 있다. (p=0.009) 즉, 유의수준 0.05하에서 용접기의 성능에는 차이가 있다고 할 수 있다.")
43
다음주 시험 OPEN BOOK 표에서 평균, 표준편차 채우기 가설 세우기 (귀무, 대립 모두 써야 함) 분석방법 쓰기
상관계수와 p-value 구하기 분석결과 쓰기 유의한지 아닌지, 유의하지 않다면 왜 그러한지 이유를 써야 하는 부분


 통계량 (statistic) 표본자료의 함수 즉 모집단 … … 표본 표본추출 … … 통계량 계산.>")





>")
>")
 6:30-10:30 장소 : 삼성암센터 (지하1층 세미나실2)>")

를 통하여 변수간의 차이를 비교할 때.>")





 6:30-10:30 장소 : 삼성암센터 (지하1층 세미나실2)>")
 Department of Biostatistics, Samsung Biomedical Research Institute Samsung Medical Center.>")
 2016. 5. 20 서구원 한양사이버대학교 미디어MBA.>")
