오라클 데이터베이스 성능 튜닝
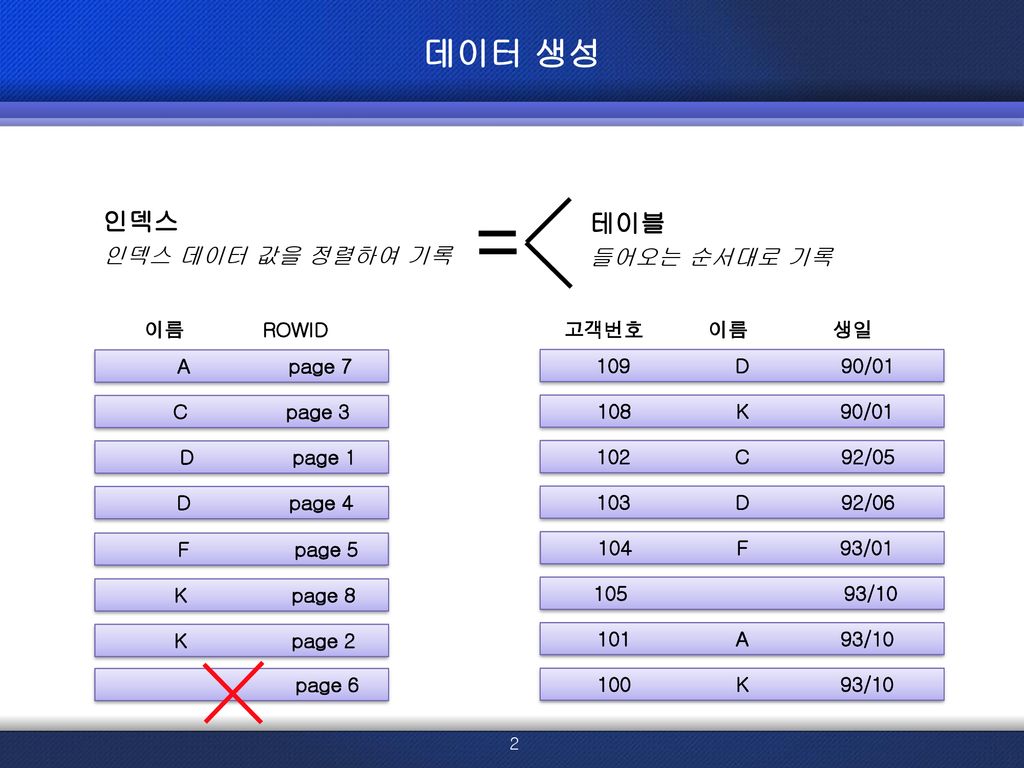
데이터 생성 인덱스 테이블 인덱스 데이터 값을 정렬하여 기록 들어오는 순서대로 기록 고객번호 이름 생일 이름 ROWID 고객번호 이름 생일 이름 ROWID A page 7 109 D 90/01 C page 3 108 K 90/01 D page 1 102 C 92/05 D page 4 103 D 92/06 F page 5 104 F 93/01 K page 8 105 93/10 K page 2 101 A 93/10 page 6 100 K 93/10
테이블 액세스(인덱스 없는 경우) ① Filter WHERE 이름 = ‘K’ 고객번호 이름 생일 X O 고객번호 이름 생일 100 D 90/01 X 101 K 90/01 O FULL TABLE SCAN 102 C 92/05 X 103 D 92/06 X 104 F 93/01 X 105 X 93/10 X 106 A 93/10 X 107 K 93/10 O
테이블 액세스(인덱스 있는 경우) Access WHERE 이름 = ‘K’ INDEX SCAN TABLE ACCESS BY ROWID 이름 ROWID 고객번호 이름 생일 A page 7 100 D 90/01 C page 3 101 K 90/01 D page 1 102 C 92/05 D page 4 103 D 92/06 F page 5 104 F 93/01 K page 8 105 X 93/10 K page 2 106 A 93/10 X X page 6 107 K 93/10
인덱스 사용 기준 인덱스 대상 컬럼 인덱스 사용시 손해보는 경우 조건문에 자주 등장하는 컬럼 같은 값이 적은 컬럼(분포도가 좁은 컬럼) 조인에 참여하는 컬럼 인덱스 사용시 손해보는 경우 데이터가 적은 테이블 같은 값이 많은 컬럼(분포도가 넓은 컬럼) 조회보다 DML의 부담이 큰 경우
결합 인덱스의 사용 결합 인덱스 2개이상의 컬럼이 조건문에 자주 등장시 WHERE 이름 = ‘C’ 2개이상의 컬럼이 조건문에 자주 등장시 WHERE 이름 = ‘C’ AND 생일 > ‘92/12’ 이름 생일 ROWID 고객번호 이름 생일 A 93/10 page 7 109 C 94/01 C 92/05 page 3 108 K 90/01 C 93/01 page 5 102 C 92/05 C 93/10 page 6 103 D 92/06 C 94/01 page 1 104 C 93/01 X D 92/06 page 4 105 C 93/10 K 90/01 page 2 101 A 93/10 K 93/10 page 8 100 K 93/10
결합 인덱스의 사용 결합 인덱스 인덱스만으로도 결과를 얻을 수 있을때 ... SELECT 이름, 생일 FROM 고객테이블 WHERE 이름 = ‘C’ AND 생일 > ‘92/12’ 결합 인덱스 인덱스만으로도 결과를 얻을 수 있을때 ... 이름 생일 ROWID 고객번호 이름 생일 A 93/10 page 7 109 C 94/01 C 92/05 page 3 108 K 90/01 C 93/01 page 5 O 102 C 92/05 C 93/10 page 6 O 103 D 92/06 C 94/01 page 1 O 104 C 93/01 X D 92/06 page 4 105 C 93/10 K 90/01 page 2 101 A 93/10 K 93/10 page 8 100 K 93/10
결합인덱스 사용 기준 결합인덱스를 사용하는 경우 결합인덱스의 컬럼 순서 자주 조건에 같이 등장하는 경우 인덱스만 읽고도 결과를 얻을 수 있을 때 결합인덱스의 컬럼 순서 사용빈도가 높은 컬럼부터 SCAN 범위를 줄여주는 컬럼부터 자주 사용되는 컬럼부터
스캔범위결정 조건과 검증조건 WHERE 이름 = ‘C’ AND 생일 > ‘92/12’ AND 고객번호 = 105 인덱스 범위결정 Filter 이름 생일 ROWID 고객번호 이름 생일 A 93/10 page 7 109 D 90/01 C 92/05 page 3 108 K 90/01 C 93/01 page 5 102 C 92/05 C 93/10 page 6 103 D 92/06 X D 90/01 page 1 104 C 93/01 O X D 92/06 page 4 105 C 93/10 K 90/01 page 2 101 A 93/10 K 93/10 page 8 100 K 93/10
스캔범위결정 조건과 검증조건 Filter Filter Access 범위결정 WHERE 이름 = ‘C’ AND 생일 like ‘%10’ AND 고객번호 = 105 Access 범위결정 Filter Filter 이름 생일 ROWID 고객번호 이름 생일 A 93/10 page 7 109 D 90/01 C 92/05 page 3 X 108 K 90/01 C 93/10 page 5 102 C 92/05 C 93/10 page 6 103 D 92/06 X D 90/01 page 1 104 C 93/01 X D 92/06 page 4 105 C 93/10 O K 90/01 page 2 101 A 93/10 K 93/10 page 8 100 K 93/10
인덱스를 사용하지 못하는 경우 인덱스 컬럼에 변형이 일어난 경우 부정형으로 조건을 기술한 경우 NULL을 비교하였을 경우 내부적인 변형이 일어난 경우 옵티마이져의 판단에 따라 (cost-based optimizer)
인덱스 컬럼의 변형 Select … from department where max_salary * 12 > 2500; max_salary ROWID 부서번호 부서명 max_salary 100 xxxx.xxxx.xxxxxxxx 109 D 150 X 100 xxxx.xxxx.xxxxxxxx 108 K 180 X 150 xxxx.xxxx.xxxxxxxx 102 C 100 X 180 xxxx.xxxx.xxxxxxxx 103 D 200 X 200 xxxx.xxxx.xxxxxxxx 104 C 100 X 200 xxxx.xxxx.xxxxxxxx 105 C 350 O 300 xxxx.xxxx.xxxxxxxx 101 A 200 X 350 xxxx.xxxx.xxxxxxxx 100 K 300 O
인덱스 컬럼의 변형 Select … from department where max_salary > 2500/12 ; 부서번호 ROWID 부서번호 부서명 max_salary 100 xxxx.xxxx.xxxxxxxx 109 D 150 100 xxxx.xxxx.xxxxxxxx 108 K 180 150 xxxx.xxxx.xxxxxxxx 102 C 100 180 xxxx.xxxx.xxxxxxxx 103 D 200 200 xxxx.xxxx.xxxxxxxx 104 C 100 200 xxxx.xxxx.xxxxxxxx 105 C 350 O 300 xxxx.xxxx.xxxxxxxx 101 A 200 350 xxxx.xxxx.xxxxxxxx 100 K 300 O
부정형 조건 Select … from Employee_TEMP where 부서번호 <> ’100’ ; 부서번호 ROWID 부서번호 부서명 max_salary 99 xxxx.xxxx.xxxxxxxx 99 D 150 O 100 xxxx.xxxx.xxxxxxxx 100 K 180 X 100 xxxx.xxxx.xxxxxxxx 100 C 100 X 100 xxxx.xxxx.xxxxxxxx 100 D 200 X 100 xxxx.xxxx.xxxxxxxx 100 C 100 X 100 xxxx.xxxx.xxxxxxxx 100 C 350 X 100 xxxx.xxxx.xxxxxxxx 100 A 200 X 101 xxxx.xxxx.xxxxxxxx 101 K 300 O
부정형 조건 Select … from Employee_TEMP where 부서번호 < ‘100’ OR 부서번호 > ‘100’ ; max_salary ROWID 부서번호 부서명 max_salary 99 xxxx.xxxx.xxxxxxxx 99 D 150 O 100 xxxx.xxxx.xxxxxxxx 100 K 180 100 xxxx.xxxx.xxxxxxxx 100 C 100 100 xxxx.xxxx.xxxxxxxx 100 D 200 100 xxxx.xxxx.xxxxxxxx 100 C 100 100 xxxx.xxxx.xxxxxxxx 100 C 350 100 xxxx.xxxx.xxxxxxxx 100 A 200 101 xxxx.xxxx.xxxxxxxx 101 K 300 O
NULL 비교 Select … from Employee where 생일 is not null; Select …
내부변형 Select … from Employee where 부서번호 = :A (상수) Select … where 부서번호 = to_char( :A) Select … from Employee where 생일 = to_char( :B, ‘yyyymmdd’) Select … from Employee where 생일 = :B (일자)
SQL의 활용 1. EXISTS 대신 JOIN 의 사용 SELECT … FROM EMP E WHERE EXISTS (SELECT 'X' FROM DEPT D WHERE D.DEPT_NO = E.DEPT_NO AND D.DEPT_CAT = 'A'); JOIN 사용문장 SELECT ENAME .. FROM DEPT D, EMP E WHERE E.DEPT_NO = D.DEPT_NO AND D.DEPT_CAT = 'A';
SQL의 활용 2. IN 대신 EXISTS 의 활용 ERD 상에서 base가 되는 테이블에 대한 query는 select할 때 여러 테이블과 join을 하는 경우가 많다. 이러한 경우 IN과 Sub-query를 사용하는 것 보다 EXISTS나 NOT EXISTS를 사용하는 것이 더 나은 성능을 보여주는 경우 IN 사용문장 SELECT * FROM EMP WHERE EMPNO > 7777 AND DEPTNO IN (SELECT DEPTNO FROM DEPT WHERE LOC = 'MELB'); EXISTS 사용문장 SELECT * FROM EMP E WHERE EMPNO > 7777 AND EXISTS (SELECT 'x' FROM DEPT D WHERE D.DEPTNO = E.DEPTNO AND D.LOC = 'MELB');
SQL의 활용 3. NOT IN 대신 NOT EXISTS 의 활용 아래와 같이 Sub-query문에서 NOT IN은 내부적으로 sort와 merge를 수반한다. NOT IN을 사용하면 대체적으로 가장 효율이 나쁜데, 이는 sub-query select에 대상이 되는 테이블을 강제로 full table scan 하도록 하기 때문이다 NOT EXISTS 나 OUT JOIN 문장으로 변경 NOT IN 사용문장 SELECT … FROM EMP WHERE DEPT_NO NOT IN (SELECT DEPT_NO FROM DEPT WHERE DEPT_CAT = 'A'); NOT EXISTS 사용문장 OUTER JOIN 사용문장 SELECT … FROM EMP E WHERE NOT EXISTS (SELECT 'X' FROM DEPT D WHERE D.DEPT_NO = E.DEPT_NO AND D.DEPT_CAT = 'A'); SELECT … FROM EMP A, DEPT B WHERE A.DEPT_NO = B.DEPT_NO (+) AND B.DEPT_NO IS NULL AND B.DEPT_CAT(+) = 'A';
SQL의 활용 4. DISTINCT 대신 EXISTS 의 활용 EMP 테이블 FULL SCAN 1:M 관계에서의 select에서는 EXISTS를 사용해야 한다 DISTINCT 사용문장 SELECT DISTINCT DEPT_NO, DEPT_NAME FROM DEPT D, EMP E WHERE D.DEPT_NO = E.DEPT_NO; EMP 테이블 FULL SCAN EXISTS 사용문장 SELECT DEPT_NO, DEPT_NAME FROM DEPT D WHERE EXISTS (SELECT 'X' FROM EMP E WHERE E.DEPT_NO = D.DEPT_NO); EMP 테이블 INDEX SCAN
SQL의 활용 5. Row수 count 하기 6. Table Alias의 사용 일반적인 믿음과 달리 COUNT(*)가 COUNT(1)보다 빠르다. 만약 인덱스를 통해 COUNT 한 값을 추출하고자 할 때에는 인덱스로 잡혀있는 컬럼을 COUNT(EMPNO)와 같이 추출하는 것이 가장 빠르게 결과값을 얻을 수 있다. 6. Table Alias의 사용 여러 개의 테이블에 대한 Query시 항상 테이블에 대한 alias를 사용하고, 각각의 컬럼에 alias를 붙여 사용하는 것이 좋다. ORACLE이 dictionary에서 해당 컬럼이 어느 테이블에 있는지를 찾지 않아도 되므로 parsing 시간을 줄일 수 있고, 컬럼에 대한 혼동을 미연에 방지 할 수 있다.
SQL의 활용 7. WHERE절과 HAVING절의 차이 자주 사용하지는 않지만 간혹 HAVING을 WHERE 대신 사용하는 경우가 있다. 그러나 SELECT문에서 HAVING을 WHERE 대신 사용하는 것은 피하는 것이 좋다. HAVING은 fetch된 row들에 대한 filter 역할을 한다. 여기에는 sort나 sum 등의 작업이 수반된다. 만약 select 하고자 하는 데이터를 일정 조건에 따라 추출하고자 할 경우에는 where절을 사용하여 HAVING을 사용함으로써 발생할 수 있는 overhead를 줄여주는 것이 좋다. HAVING절 사용문장 SELECT JOB, AVG(SAL) FROM EMP GROUP BY JOB HAVING JOB = ‘PRESIDENT’ OR JOB = ‘MANAGER’; GROUP BY 이후 결과를 FILTER 함 WHERE절 사용문장 SELECT JOB, AVG(SAL) FROM EMP WHERE JOB = ‘PRESIDENT’ OR JOB = ‘MANAGER’ GROUP BY JOB; GROUP BY 전 데이터 ACCESS 단계에서 조건에서 FILER 함
SQL의 활용 8. SELECT절에서 Asterisk('*') 사용 9. UNION-ALL의 사용 Dynamic SQL 컬럼 '*'는 테이블의 모든 컬럼을 참조할 수 있게 해 준다. 그러나 이러한 '*'는 값을 되돌려 줄 때 테이블의 모든 컬럼을 변환하여 반환하므로 매우 비효율적이다. SQL Parser는 Data Dictionary에서 해당 테이블에 대한 모든 컬럼의 이름을 읽어서 SQL 명령문 내의 '*'을 대체하는 작업을 한다.비록 0.01초 밖에 더 걸리지 않는 작업일 지라도 여러 번 반복하면 많은 시간이 걸릴 수도 있으므로 되도록 Asterisk(*)를 사용하지 않는 것이 좋다. 9. UNION-ALL의 사용 두개의 query에 대해서 UNION을 사용할 때, 각각의 query에 의한 결과값이 UNION-ALL에 의해 합쳐지고 다시 내부 작업인 SORT UNIQUE 작업에 의해 최종 결과값을 사용자에게 되돌려 준다. 이 때 UNION 대신 UNION-ALL을 사용하게 되면 SORT UNIQUE 작업은 불필요하게 되며, 그만큼의 시간을 줄일 수 있고 수행 성능을 향상시킬 수 있다. 이는 SORT가 필요하지 않은 경우에만 가능하므로 정확히 확인하고 사용하여야 한다.
SQL의 활용 10. ORDER BY를 사용하지 않고 정렬하기 ORDER BY을 사용할 때 인덱스를 사용하여 sort를 하지 않고 정렬된 결과값을 얻고자 할 때에는 다음의 두 조건을 만족하여야 한다. ▶ ORDER BY에 사용된 모든 컬럼이 동일한 순서로 하나의 인덱스로 만들어져 있어야 한다. ▶ ORDER BY에 사용된 모든 컬럼은 테이블 정의에 반드시 NOT NULL이어야 한다. (Null값은 인덱스에 저장되지 않으므로) Case 2에서처럼 의미 없는 Where에 의해 ORDER BY와 같이 sort 과정을 거치지 않고도 동일한 결과를 얻을 수 있다.
SQL의 활용 11. WHERE절에서 인덱스 사용을 위한 주의할 사항
SQL의 활용 12. DECODE 함수를 통한 내부처리 단축 ( DB CALL 줄이기 ) DECODE 함수를 활용하여 동일한 row에 대해 다시 읽는 것을 방지하거나 동일한 테이블에 대한 join을 피할 수 있다. 비슷한 문장을 두번 나누어 처리 SELECT COUNT(*), SUM(SAL) FROM EMP WHERE DEPT_NO = 0020 AND ENAME LIKE 'SMITH%'; WHERE DEPT_NO = 0030 SELECT COUNT(DECODE(DEPT_NO, 0020, 1, NULL)) D20_CNT, SUM (DECODE(DEPT_NO, 0020, SAL, NULL)) D20_SAL, COUNT(DECODE(DEPT_NO, 0030, 1, NULL)) D30_CNT, SUM (DECODE(DEPT_NO, 0030, SAL, NULL)) D30_SAL FROM EMP WHERE ENAME LIKE 'SMITH%'; DECODE 문으로 문장 통합
SQL의 활용 13. 1 QUERY 시 테이블에 대한 참조를 최소화 ( WHERE 조건 ) Query시 테이블에 대한 access 회수를 최소화 함으로써 성능을 향상 시킬 수 있다. 특히 Sub-query를 포함하거나 여러 컬럼에 대한 update를 수행할 때 작업 시간을 단축할 수 있다. 동일 테이블 두번참조 ( 비효율 ) SELECT TAB_NAME FROM TABLES WHERE TAB_NAME = (SELECT TAB_NAME FROM TAB_COLUMNS WHERE VERSION = 604) AND DB_VER = (SELECT DB_VER WHERE VERSION = 604); SELECT TAB_NAME FROM TABLES WHERE (TAB_NAME, DB_VER) = (SELECT TAB_NAME, DB_VER FROM TAB_COLUMNS WHERE VERSION = 604); 테이블을 한번만 참조하도록 ( 효율적 )
SQL의 활용 13.2 QUERY 시 테이블에 대한 참조를 최소화 (MULTI COLUMN UPDATE ) 동일 테이블 두번참조 ( 비효율 ) UPDATE EMP SET EMP_CAT = (SELECT MAX(CATEGORY) FROM EMP_CATEGORIES), SAL_RANGE = (SELECT MAX(SAL_RANGE) FROM EMP_CATEGORIES ) WHERE EMP_DEPT = 0020; UPDATE EMP SET (EMP_CAT, SAL_RANGE) = (SELECT MAX(CATEGORY), MAX(SAL_RANGE) FROM EMP_CATEGORIES) WHERE EMP_DEPT = 0020; 테이블을 한번만 참조하도록 ( 효율적 )
SQL의 활용 14. Stored Function을 활용한 SQL의 부하 감소 JOIN 수행후 GROUP BY 시 부하가 클 경우 부하를 감소 시킨 사례 JOIN 후 GROUP BY 수행한 경우 SELECT H.EMPNO, E.ENAME, T.TYPE_DESC, COUNT(*) FROM HISTORY_TYPE T, EMP E WHERE H.EMPNO = E.EMPNO GROUP BY H.EMPNO, E.ENAME, T.TYPE_DESC; CREATE OR REPLACE FUNCTION Lookup_Emp (emp IN NUMBER) RETURN VARCHAR2 AS ename VARCHAR2(30); CURSOR C1 IS SELECT ENAME FROM EMP WHERE EMPNO = emp; BEGIN OPEN C1; FETCH C1 INTO ename; CLOSE C1; RETURN (NVL(ename, '?'); END; JOIN 후 GROUP BY 수행시 JOIN ,GROUP BY 수행에 부하 유발 GROUP BY 수행후 STORED FUNCTION 호출 SELECT H.EMPNO, Lookup_Emp(H.EMPNO), H.HIST_TYPE, COUNT(*) FROM EMP_HISTORY H GROUP BY H.EMPNO, H.HIST_TYPE; GROUP BY 만 수행후 최종 SELECT 절에서 FUNCTION 호출
MAX, MIN 사용 시 인덱스와 ROWNUM을 최대한 활용하라. Case 별 사례 MAX, MIN 사용 시 인덱스와 ROWNUM을 최대한 활용하라. Select max(sal) from employee ● S O R T TABLE Select /*+index_desc(e I_sal ) */ sal from employee e where sal > 0 and ROWNUM =1; INDEX(SAL)
Case 별 사례 1:M select a.rmp into :b0 from mrdrm a where a.c_cd='003' and a.cno=:b1 and a.shcd=:b2 and a.dt= ( select max(b.dt) from mrdrm b where b.c_cd=a.c_cd and b.cno= a.cno and b.shcd=a.shcd and b.dt<=:b3) EXECUTION PLAN -------------------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'MRDRM' 2 1 INDEX (RANGE SCAN) OF 'MRDRM_IDX02' (UNIQUE) 3 2 SORT (AGGREGATE) 4 3 INDEX (RANGE SCAN) OF 'MRDRM_IDX02' (UNIQUE) 인덱스 정보 ---------------------------------------------------- MRDRM_IDX02 : C_CD+CNO+SHCD+DT MRDRM_IDX02 'MRDRM_IDX02' MRDRM SORT후 MAX(DT)와 비교 1:M
Case 별 사례 1:1 select a.rmp into :b0 from mrdrm a where a.c_cd='003' EXECUTION PLAN ------------------------------------------------------------------------ 0 SELECT STATEMENT Optimizer=CHOOSE 1 0 TABLE ACCESS (BY INDEX ROWID) OF 'MRDRM' 2 1 INDEX (RANGE SCAN) OF 'MRDRM_IDX02' (UNIQUE) 3 2 COUNT (STOPKEY) 4 3 INDEX (RANGE SCAN DESCENDING) OF 'MRDRM_IDX02' 인덱스 정보 ---------------------------------------------------- MRDRM_IDX02 : C_CD+CNO+SHCD+DT select a.rmp into :b0 from mrdrm a where a.c_cd='003' and a.cno=:b1 and a.shcd=:b2 and a.dt= ( select /*+index_desc (b mrdrm_idx02)*/ b.dt from mrdrm b where b.c_cd=a.c_cd and b.cno= a.cno and b.shcd=a.shcd and b.dt<=:b3 and ROWNUM=1) 역순으로 첫번째 DT와 비교 1:1 'MRDRM_IDX02' MRDRM
Case 별 사례 SELECT 'OUT' IN_OUT, 'OWP' CLSS, nvl(B.ITM_TYP_CD,' ') ITM_TYP_CD, nvl(B.TRD_TR_DVCD,' ') TRD_TR_DVCD FROM ITEM B WHERE B.C_CD = :C_Cd AND B.ORDDAY = DECODE(B.ORD_SVCD,'02',:svcDay,:WorkDay) AND B.ITM_TYP_CD = '01’ AND B.ORD_SVCD IN ('01','02','04') EXECUTION PLAN --------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE 1 0 PARTITION (CONCATENATED) 2 1 TABLE ACCESS (FULL) OF ‘ITEM'
Case 별 사례 SELECT 'OUT' IN_OUT, 'OWP' CLSS, nvl(B.ITM_TYP_CD,' ') ITM_TYP_CD, nvl(B.TRD_TR_DVCD,' ') TRD_TR_DVCD FROM ITEM B WHERE B.C_CD = :C_Cd ((B.ORDDAY = :TrDay AND B.ORD_DVCD='02’) OR (B.ORDDAY = :WorkDay AND B.ORD_DVCD<>'02’)) AND B.ITM_TYP_CD = '01’ AND B.ORD_SVCD IN ('01','02','04') EXECUTION PLAN ------------------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE 1 0 CONCATENATION 2 1 TABLE ACCESS (BY GLOBAL INDEX ROWID) OF ‘ITEM' 3 2 INDEX (RANGE SCAN) OF 'PK_ITEM_IND01' (UNIQUE) 4 1 TABLE ACCESS (BY GLOBAL INDEX ROWID) OF ‘ITEM' 5 4 INDEX (RANGE SCAN) OF 'PK_ITEM_IND01' (UNIQUE)
Case 별 사례 SELECT A.C_CD,SUBSTR(A.AC_NO,10,2), sum(decode(B.AC_STUS_CD,'04',A.gen_de,0)) FROM ACCOUNT B, CUSTOMER A WHERE A.c_cd = :c_cd AND A.PD_CD LIKE :IN_pd_cd AND A.PD_CD <> '03' AND A.GEN > 0 AND A.C_CD = B.C_CD AND A.AC_NO = B.AC_NO AND B.AC_TYP_CD <> '06’ AND SUBSTR(A.AC_NO,1,3) = :IN_org_cd AND SUBSTR(A.AC_NO,4,6) < '600000’ GROUP BY A.C_CD,SUBSTR(A.AC_NO,10,2),SUBSTR(A.AC_NO,1,3) EXECUTION PLAN ---------------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE 1 0 SORT (GROUP BY) 2 1 PARTITION (CONCATENATED) 3 2 NESTED LOOPS 4 3 TABLE ACCESS (FULL) OF ‘CUSTOMER' 5 3 TABLE ACCESS (BY LOCAL INDEX ROWID) OF 'ACCOUNT' 6 5 INDEX (UNIQUE SCAN) OF 'PK_ACCCOUNT_01' (UNIQUE)
Case 별 사례 SELECT A.C_CD, …… FROM ACCOUNT B,CUSTOMER A WHERE A.c_cd = :c_cd AND A.PD_CD LIKE :IN_pd_cd AND A.PD_CD <> '03' AND A.GEN > 0 AND A.C_CD = B.C_CD AND A.AC_NO = B.AC_NO AND B.AC_TYP_CD <> '06' AND A.AC_NO between :IN_org_cd||'00000000’ and :IN_org_cd||'59999999' GROUP BY A.C_CD,SUBSTR(A.AC_NO,10,2), SUBSTR(A.AC_NO,1,3) EXECUTION PLAN ---------------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE 1 0 SORT (GROUP BY) 2 1 NESTED LOOPS 3 2 TABLE ACCESS (BY GLOBAL INDEX ROWID) OF ‘CUSTOMER' 4 3 INDEX (RANGE SCAN) OF 'PK_CUSTOMER' (UNIQUE) 5 2 PARTITION (SINGLE) 6 5 TABLE ACCESS (BY LOCAL INDEX ROWID) OF 'ACCOUNT' 7 6 INDEX (UNIQUE SCAN) OF 'PK_ACCCOUNT_01' (UNIQUE)