Download presentation
1
Introduction of Deep Learning
Dong-Hyun Kwak

2
Table of Contents Artificial Neural Networks Perceptron
Rate coding / Spiking Perceptron XOR Non linear Problem Multi-layer Perceptron Universal Function Approximator Non Linear Activation Function Logistic Regression Gradient Descent Momentum: Per-dimension Learning Rate Error Back-propagation Chain Rule Why Deep? Gradient Vanishing Problem RBM layer-wise pretraining ReLU Regression / Binary Classification / Multi Classification Linear Regression + Least Mean Square / Softmax + Cross Entropy

3
Artificial Neural Networks – Spiking Neuron
포아송 프로세스가 아웃풋임. Computational Neuro-Science에서 주로 연구하는 모델. 여기는 사람의 뉴런을 분석하기 위해 모델링을 함

4
Artificial Neural Networks – Rate Coding Neuron
근데 frequency 도메인으로 보면 처리할 수 있는 정보량이 같음

5
https://blog.dbrgn.ch/2013/3/26/perceptrons-in-python/
Perceptron

6
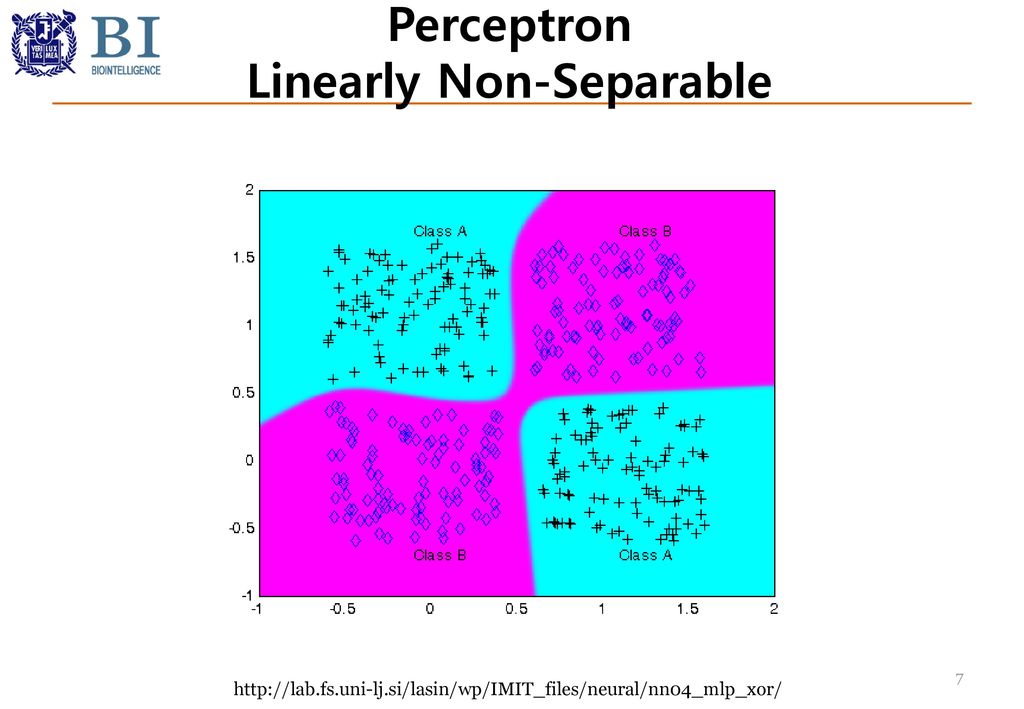
Perceptron - XOR

7
Perceptron Linearly Non-Separable
8
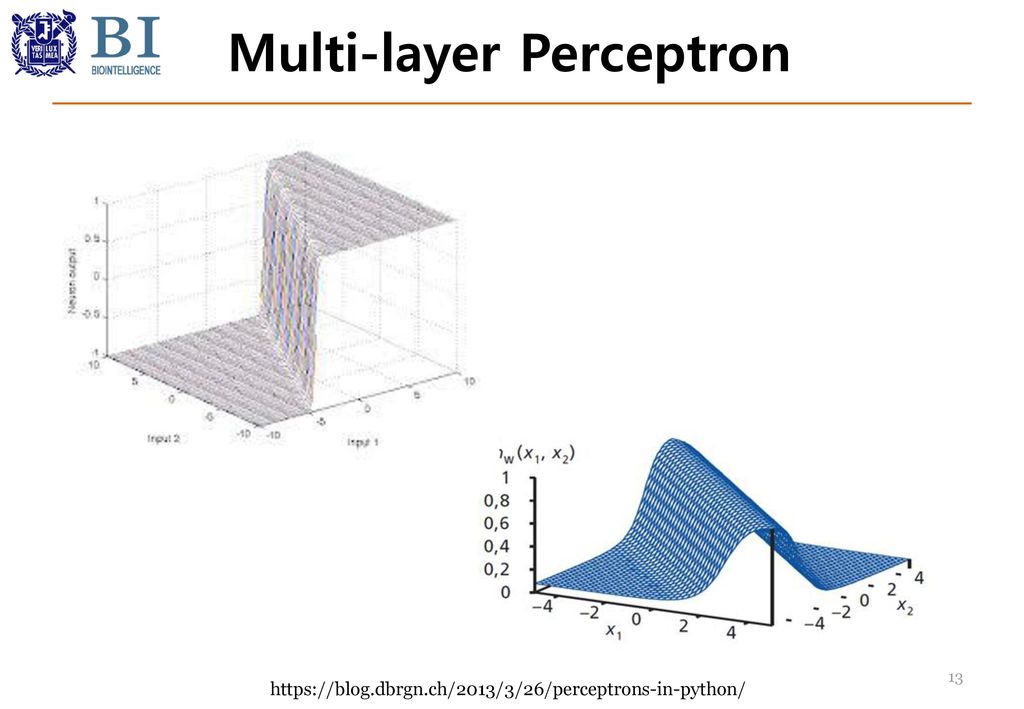
Multi-layer Perceptron

9
Multi-layer Perceptron Universal Function Approximation
In the mathematical theory of artificial neural networks, the universal approximation theorem states[1] that a feed-forward network with a single hidden layer containing a finite number of neurons (i.e., a multilayer perceptron), can approximate continuous functions
, can approximate continuous functions")
10
Multi-layer Perceptron Universal Function Approximation
[여창준a] [오후 1:54] measurable function [여창준a] [오후 1:54] lebesgue integral 같은거 할줄알아야 [여창준a] [오후 1:54] 아 그리고 borel set이 뭔지도 알아야되고 [여창준a] [오후 1:54] Lp space가 뭐고 [여창준a] [오후 1:54] 그 위에서 적분은 또 어떻게 하고 [여창준a] [오후 1:54] 이런거 다 알아야 저 논문 보는데

11
Activation Function

12
Sigmoid Function 확률적 해석이 가능함

13
Multi-layer Perceptron
14
Multi-layer Perceptron
Hidden Layer에 Activation Function이 없으면? 2층 네트워크 == Logistic Regression과 같음

15
Gradient Descent Loss Function 을 W(parameter)로 편미분해서 W에 대한 Gradient를 구한다. Gradient를 이용해서 W를 업데이트 한다. W* = W − λ Loss'(W)
")
16
Gradient Descent

17
Gradient Descent의 문제점 1) Local Optima Momentum
(사실은 per-dimension learning rate) Divergence Gradient Decaying V = µV' + λ Loss'(W) W* = W - V - 모멘텀은, 원래 가던 방향을 남겨놓기 때문에, 발산하는걸 상쇄시켜줌 adagrad는 글로벌하게 디맨전마다 러닝레이트를 다르게 주는 것임. 그래서 Gradient decaying은 어떤 optimizer와도 같이 사용이 가능함.
 Divergence. Gradient Decaying. V = µV + λ Loss (W) W* = W - V. - 모멘텀은, 원래 가던 방향을 남겨놓기 때문에, 발산하는걸 상쇄시켜줌. adagrad는 글로벌하게 디맨전마다 러닝레이트를 다르게 주는 것임. 그래서 Gradient decaying은 어떤 optimizer와도 같이 사용이 가능함.")
18
Gradient Descent의 문제점 느림 Stochastic Gradient Descent
(또한 랜덤한 요소의 작용으로 더 수렴이 좋음. 그러나 subset이 전체의 분포를 충분히 반영해야함)
")
19
Error Back-propagation
Chain Rule Delta = node’s error

20
Deep Layer

21
Deep Layer

22
Gradient Vanshing

23
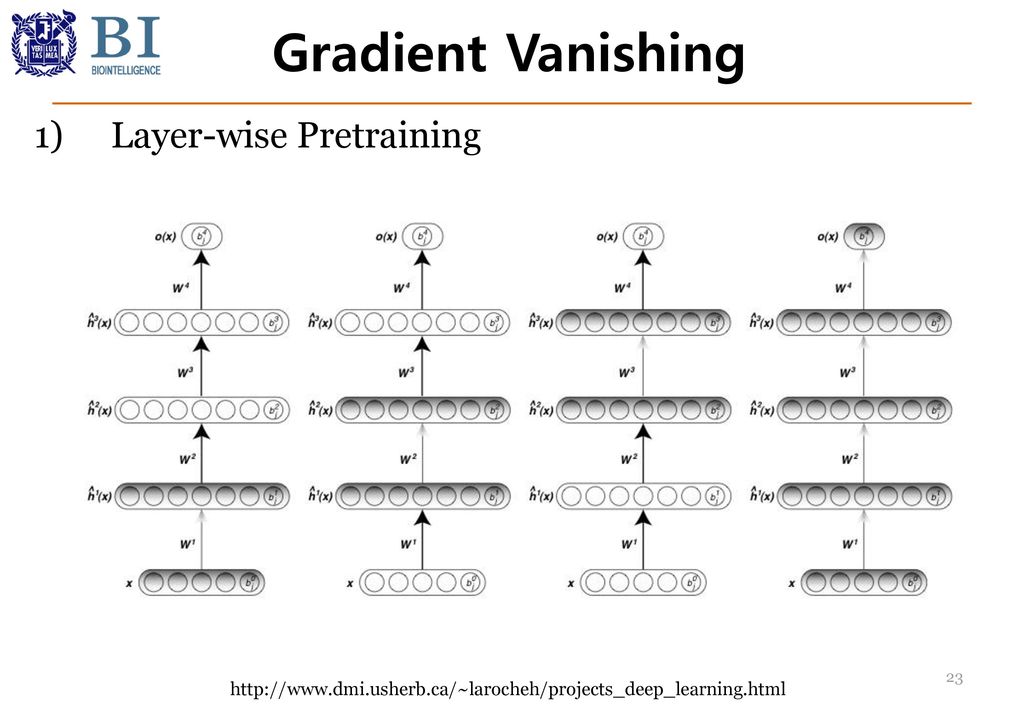
Gradient Vanishing Layer-wise Pretraining
24
Gradient Vanishing 의미 1) Global optima와 더 가까운 Initial Weight 제공
의미 2) Layer간의 긴밀함이 증가해서 gradient가 더 잘 전파됨
 Layer간의 긴밀함이 증가해서 gradient가 더 잘 전파됨.")
25
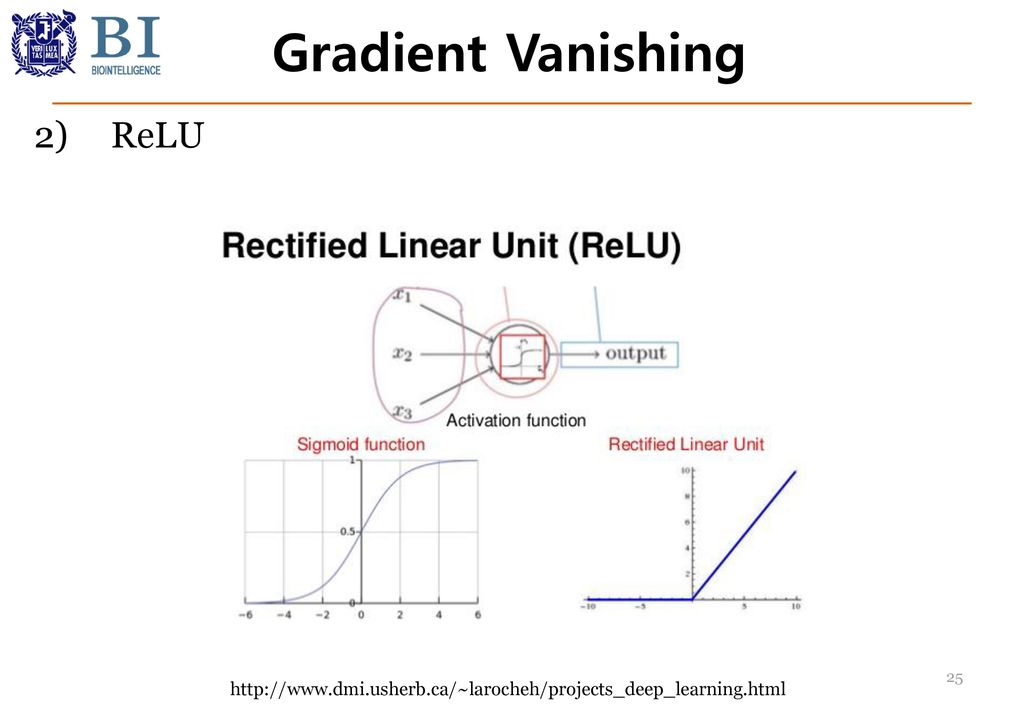
Gradient Vanishing 2) ReLU
26
Output Node 1) Regression Weighted Sum + Least Mean Square
2) Classification Softmax + Cross-Entropy
 Classification Softmax + Cross-Entropy.")
27
THANK YOU



, 이주연 (13), 박혜원 (14), 안혜경 (15) 허니버터칩으로 알아본 SNS 의 영향 력.>")


 장 소 : 문산종합사회복지관장) 파주시문산종합사회복지관 기관안내.>")


 문제 Machine Learning.>")


>")




>")



 안녕하십니까 자유전공학부 행정실 입니다.>")