Download presentation
1
(Statistical Modeling)
통계 모델링 (Statistical Modeling) 한국어 정보의 전산 처리
 한국어 정보의 전산 처리")
2
문제의 성격에 따른 통계 기법 회귀 문제(regression problem)
독립변수(예측변수), 종속변수(반응변수) 둘 다 연속형(수치형) 선형회귀분석(linear regression analysis): 단순회귀, 다항회귀; 비선형회귀 판별/분류 문제(discrimination/classification problem) 종속변수가 범주형. 어떤 범주들이 있는지 미리 알고 있음. 독립변수가 모두 수치형인 경우: 로지스트 회귀분석(logistic regession), 판별분석(discriminant analysis), Bayes classifier, K-Nearest Neighbor 독립변수에 범주형이 포함된 경우: 로그선형분석(log-linear analysis) 군집 문제(clustering problem) 독립변수만 있고 종속변수는 없음. 어떤/몇 개의 군집이 있는지 모름. 군집분석(cluster analysis), 다차원척도법, 인자분석(factor analysis)
, 종속변수(반응변수) 둘 다 연속형(수치형) 선형회귀분석(linear regression analysis): 단순회귀, 다항회귀; 비선형회귀. 판별/분류 문제(discrimination/classification problem) 종속변수가 범주형. 어떤 범주들이 있는지 미리 알고 있음. 독립변수가 모두 수치형인 경우: 로지스트 회귀분석(logistic regession), 판별분석(discriminant analysis), Bayes classifier, K-Nearest Neighbor. 독립변수에 범주형이 포함된 경우: 로그선형분석(log-linear analysis) 군집 문제(clustering problem) 독립변수만 있고 종속변수는 없음. 어떤/몇 개의 군집이 있는지 모름. 군집분석(cluster analysis), 다차원척도법, 인자분석(factor analysis)")
3
회귀 문제의 예 TV, 라디오, 신문 광고 투입액과 판매량의 관계
광고 투입액을 X(x1, x2, x3)로 하면 판매량(Y)은 얼마가 되는가? 순이익을 최대화하기 위해서는(또는 광고 투입액 총액이 정해져 있을 때) 3가지 광고 투입액을 각각 얼마로 해야 하는가?
로 하면 판매량(Y)은 얼마가 되는가 순이익을 최대화하기 위해서는(또는 광고 투입액 총액이 정해져 있을 때) 3가지 광고 투입액을 각각 얼마로 해야 하는가")
4
판별/분류 문제의 예 수신 메일 중 스팸메일과 햄메일 판별 메일 제목, 본문에 포함된 단어/형태소의 빈도 통계 추출.
각 단어/형태소의 빈도를 하나의 차원/변수로 간주하여 차원을 적절히 축소한 뒤(예: 2차원) 2차원 공간에서 두 범주를 가르는 경계선에 해당하는 방정식을 구함.
 2차원 공간에서 두 범주를 가르는. 경계선에 해당하는 방정식을 구함.")
5
군집 문제의 예 데이터가 몇 개의 군집으로 나뉘는지 모르는 상태에서 n개의 변수에 대한 관측값을 얻음.
차원을 적절히 축소한 뒤(예: 2차원) 군집내 거리는 최소화하고 군집간 거리는 최대화할 수 있도록 군집의 수와 경계를 정함. 좌: 군집간 거리가 커서 군집화가 용이. 우: 관측치들이 몰려 있어 군집화가 비교적 어려움.
 군집내 거리는 최소화하고 군집간 거리는 최대화할 수 있도록. 군집의 수와 경계를 정함. 좌: 군집간 거리가 커서. 군집화가 용이. 우: 관측치들이 몰려 있어. 군집화가 비교적 어려움.")
6
군집 문제의 예 NCI60 dataset: 6830명의 환자에 대해 64개 cancer cell line 측정.
주성분분석(principal component analysis)으로 2개의 주성분(Z1, Z2) 추출하여 2차원 평면에 배열. 좌: 4개의 군집으로 뚜렷이 나뉨. 우: 환자의 실제 14개 암 유형을 색, 모양으로 구별하여 표시. 동일 암 유형의 환자들은 가까이에 놓여 있음.
으로 2개의 주성분(Z1, Z2) 추출하여 2차원 평면에 배열. 좌: 4개의 군집으로 뚜렷이 나뉨. 우: 환자의 실제 14개 암 유형을 색, 모양으로 구별하여 표시. 동일 암 유형의. 환자들은. 가까이에. 놓여 있음.")
8
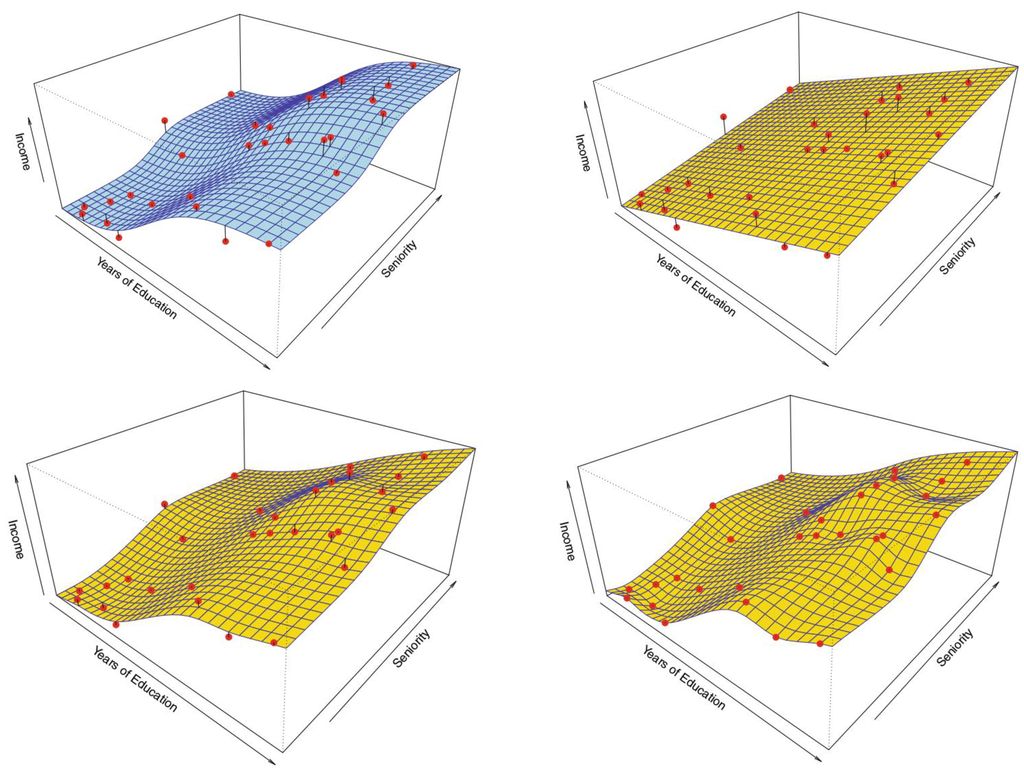
모델의 복잡도 좌상: Income dataset. simulation에 의해 생성되었음.
독립변수: 교육기간, 근무연한; 종속변수: 수입 우상: 독립변수와 종속변수 사이의 관계가 선형적(linear) 관계라는 가정하에 선형회귀 기법으로 얻은 모델. 수입 ≈ β0 + β1 × 교육기간 + β2 × 근무연한 좌하: 선형적 관계라는 가정을 하지 않고 thin-plate spline 기법으로 얻은 모델. 매끈함(smoothness) 수준을 높게 설정한 것. 우하: thin-plate spline 기법으로 얻은 모델. 매끈함 수준을 낮게 설정한 것. 매우 울퉁불퉁함. 관측치를 매우 잘 설명하나, pattern뿐 아니라 noise까지 반영한 것(overfitting).
 관계라는 가정하에 선형회귀 기법으로 얻은 모델. 수입 ≈ β0 + β1 × 교육기간 + β2 × 근무연한. 좌하: 선형적 관계라는 가정을 하지 않고 thin-plate spline 기법으로 얻은 모델. 매끈함(smoothness) 수준을 높게 설정한 것. 우하: thin-plate spline 기법으로 얻은 모델. 매끈함 수준을 낮게 설정한 것. 매우 울퉁불퉁함. 관측치를 매우 잘 설명하나, pattern뿐 아니라 noise까지 반영한 것(overfitting).")
9
모델의 정확도와 해석가능성의 trade-off
모델이 inflexible할수록 정확도는 떨어지나, 해석가능성이 높음(각 독립변수와 종속변수 사이의 관계를 쉽게 이해할 수 있음). 모델이 flexible할수록 정확도는 높아지나, 해석가능성이 낮음. 종속변수를 정확하게 예측하는 것만이 목표라면 flexible한 모형이 적절하나 모델을 해석해서 변수들 사이의 관계를 이해할 필요가 있다면 정확도를 약간 희생하더라도 해석가능성이 높은 모델을 선택하는 것이 적절함.
. 모델이 flexible할수록 정확도는 높아지나, 해석가능성이 낮음. 종속변수를 정확하게 예측하는 것만이 목표라면 flexible한 모형이 적절하나. 모델을 해석해서 변수들 사이의 관계를 이해할 필요가 있다면. 정확도를 약간 희생하더라도. 해석가능성이 높은 모델을. 선택하는 것이 적절함.")
10
모델의 정확도 모델이 종속변수에 대해 예측하는 수치와 실제 수치를 비교하여 정확도 측정.
평균제곱오차(mean squared error, MSE) training data에 대한 MSE는 당연히 작을 것이고 test data에 대한 MSE가 작아야 좋은 모델임.
 training data에 대한 MSE는 당연히 작을 것이고. test data에 대한 MSE가 작아야 좋은 모델임.")
12
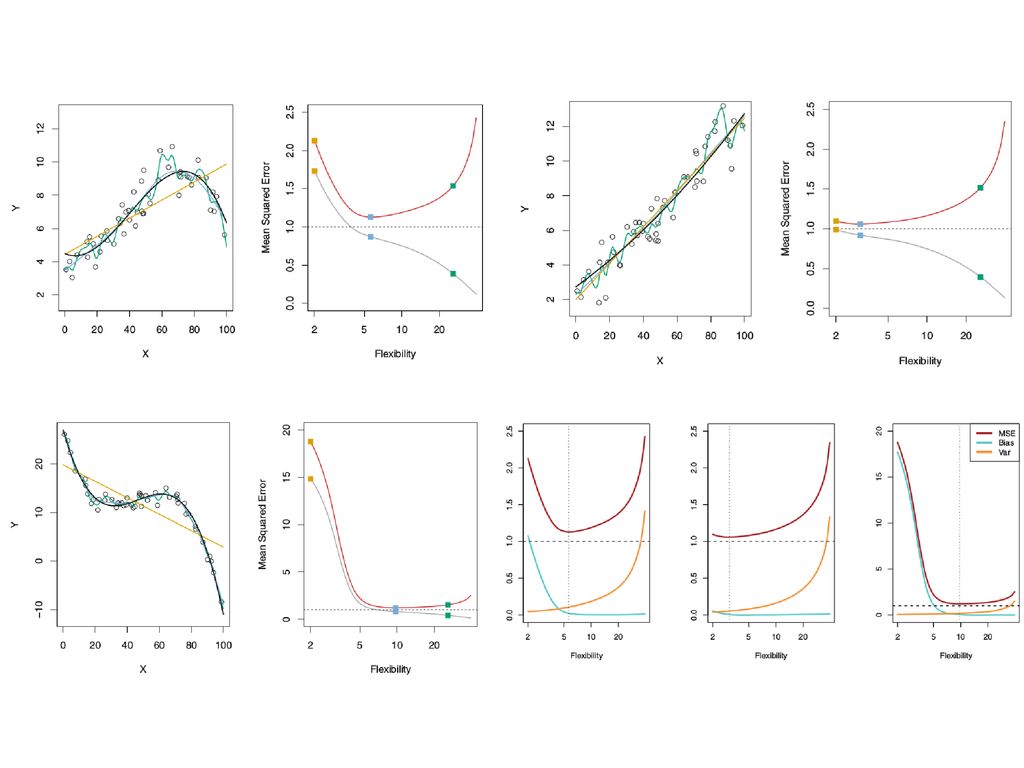
분산과 편향도의 trade-off 검정: 실제 데이터 오렌지: 선형회귀 모델
청색: smooth thin-plate spline 모델 녹색: rough(less smooth) thin-plate spline 모델 좌상: 실제 데이터가 moderately non-linear 우상: 실제 데이터가 거의 linear 좌하: 실제 데이터가 심하게 non-linear flexibility의 증가에 따른 test MSE의 변화를 그래프화하면 거의 항상 U자형이 됨. MSE=오차+분산+편향도 flexibility가 증가하면 분산은 증가하고 편향도는 낮아짐. 좌상, 우상 그림에서 녹색 모형이 지나치게 flexible해서 overfitting되어 있음.
 thin-plate spline 모델. 좌상: 실제 데이터가 moderately non-linear. 우상: 실제 데이터가 거의 linear. 좌하: 실제 데이터가 심하게 non-linear. flexibility의 증가에 따른 test MSE의 변화를 그래프화하면 거의 항상 U자형이 됨. MSE=오차+분산+편향도. flexibility가 증가하면 분산은 증가하고 편향도는 낮아짐. 좌상, 우상 그림에서 녹색 모형이 지나치게 flexible해서 overfitting되어 있음.")
13
R의 modelr 패키지를 이용한 통계 모델링
modelr의 sim1 dataset을 재료로 하여 통계 모델링 과정을 예시. X와 Y의 관계가 대체로 선형적임을 알 수 있음. sim1 %>% ggplot(aes(x,y))+geom_point()+geom_smooth(method=lm)에 의해 선형회귀곡선을 구할 수 있으나 (lm: linear model) 회귀곡선의 기울기(slope)와 절편(intercept)을 알아야 예측이 가능함. sim1_mod <- lm(y ~ x, data = sim1); coef(sim1_mod) # y = * x
)+geom_point()+geom_smooth(method=lm)에 의해 선형회귀곡선을 구할 수 있으나 (lm: linear model) 회귀곡선의 기울기(slope)와 절편(intercept)을 알아야 예측이 가능함. sim1_mod <- lm(y ~ x, data = sim1); coef(sim1_mod) # y = * x.")
14
독립변수들 사이의 상호작용 독립변수들 사이의 상호작용이 없는 모형이 있는 모형보다 단순하고 편리하나
상호작용이 있는지 없는지를 조사한 뒤 실제 데이터에 더 적합한 모델을 선택해야 함. modelr의 sim3 dataset으로 이 과정을 예시함. x1: 수치형(정수) x2: 범주형(a, b, c, d) y: 수치형(실수)
 x2: 범주형(a, b, c, d) y: 수치형(실수)")
15
2가지 선형회귀 모델 mod1 <- lm(y ~ x1 + x2, data = sim3)
y = a0 + a1*x1 + a2*x2 mod2 <- lm(y ~ x1 * x2, data = sim3) x1과 x2 사이에 상호작용이 있다고 가정하는 모델 y = a0 + a1*x1 + a2*x2 + a12*x1*x2 grid <- sim3 %>% data_grid(x1, x2) %>% gather_predictions(mod1, mod2) mod1, mod2에 따른 예측값을 얻음. ggplot(sim3, aes(x1, y, color = x2)) + geom_point() + geom_line(data = grid, aes(y = pred)) + facet_wrap(~ model) 두 모델의 예측값을 실제 관측값과 비교해 봄.
 x1과 x2 사이에 상호작용이 있다고 가정하는 모델. y = a0 + a1*x1 + a2*x2 + a12*x1*x2. grid <- sim3 %>% data_grid(x1, x2) %>% gather_predictions(mod1, mod2) mod1, mod2에 따른 예측값을 얻음. ggplot(sim3, aes(x1, y, color = x2)) + geom_point() + geom_line(data = grid, aes(y = pred)) + facet_wrap(~ model) 두 모델의 예측값을 실제 관측값과 비교해 봄.")
16
모델1은 상호작용이 없다고 가정하므로, 네 범주에 대한 회귀선의 기울기가 같음.
모델2는 상호작용을 가정하므로, 네 범주에 대한 회귀선의 기울기가 다름.

17
잔차(residual) 잔차: 예측값과 관측값의 차이 y축을 잔차로 하여 그래프를 그려 보는 것이 유용함.
모델에 의해 예측된 패턴을 제거한 후에 남은 데이터에 여전히 어떤 패턴이 있는지를 알아볼 수 있음. 잔차 그래프에 일정한 패턴이 없으면 그것은 random error에 의해 발생한 것으로 간주. 기존 모델이 데이터 내의 패턴을 매우 잘 포착했음을 의미. 잔차 그래프에 일정한 패턴이 있으면, 그것은 모델에 의해 예측된 패턴 외에 추가적인 패턴이 있음을 의미. 기존 모델이 미흡하므로 모델을 보강해야 함을 의미.

18
잔차 그래프 작성 sim3 <- sim3 %>% gather_residuals(mod1, mod2)
sim3resid %>% ggplot(aes(x1, resid, color = x2)) + geom_point() + facet_grid(model ~ x2) 잔차를 y축에 표시하되 모델과 x2에 따라 그래프를 분리하여 제시.
) + geom_point() + facet_grid(model ~ x2) 잔차를 y축에 표시하되. 모델과 x2에 따라 그래프를 분리하여 제시.")
19
모델2는 모델에 의해 예측된 값을 제외하고 나니, 잔차에 일정한 패턴이 없음. 모델이 데이터를 이미 잘 설명하고 있음.
모델1은 (특히 b, d, c의 경우) 모델에 의해 예측된 값을 제외하고 나도, 잔차에 일정한 패턴이 보임. 모델이 데이터의 패턴을 충분히 설명하지 못하고 있음.
 모델에 의해 예측된 값을 제외하고 나도, 잔차에 일정한 패턴이 보임. 모델이 데이터의 패턴을 충분히 설명하지 못하고 있음.")
20
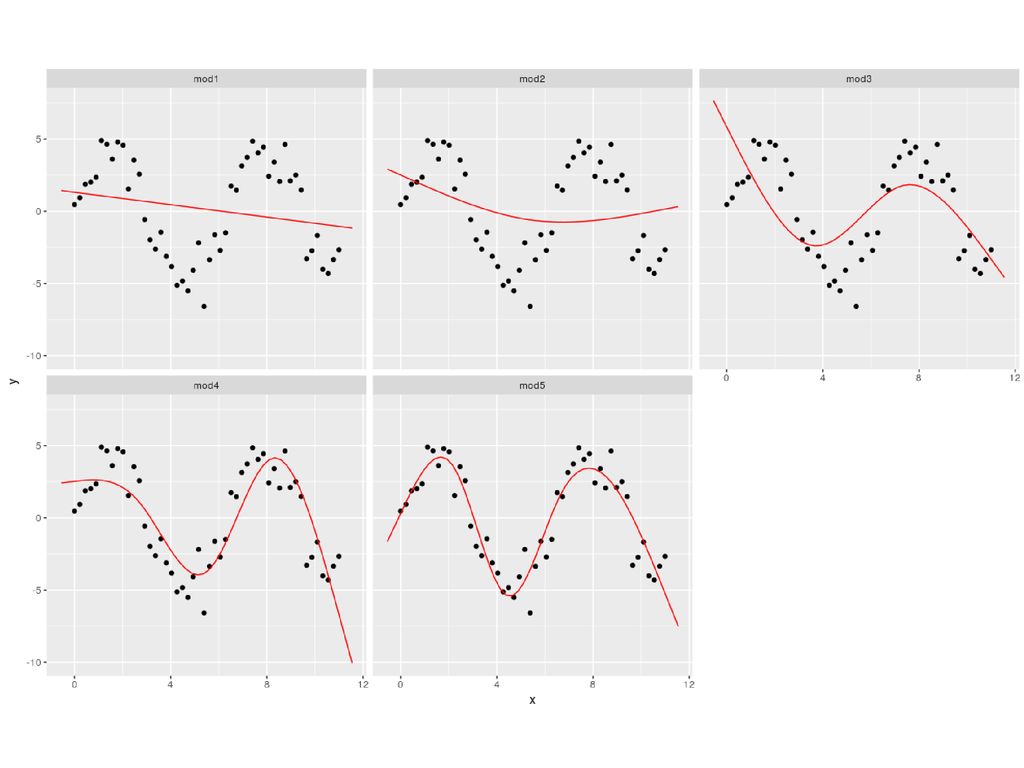
비선형 데이터의 모델링 비선형 데이터를 만들어서 여러 모델이 데이터를 얼마나 잘 설명하는지 알아봄.
sim5 <- tibble( x = seq(0, 3.5 * pi, length = 50), y = 4 * sin(x) + rnorm(length(x)) ) sin 함수로 관측값을 만들되, rnorm 함수로 정규분포를 따르는 오차를 추가함. sim5 %>% ggplot(aes(x, y)) + geom_point() 5개의 모형을 만듦. library(splines) mod1 <- lm(y~ns(x,1), data=sim5) mod2 <- lm(y~ns(x,2), data=sim5) mod3 <- lm(y~ns(x,3), data=sim5) mod4 <- lm(y~ns(x,4), data=sim5) mod5 <- lm(y~ns(x,5), data=sim5)
, y = 4 * sin(x) + rnorm(length(x)) ) sin 함수로 관측값을 만들되, rnorm 함수로 정규분포를 따르는 오차를 추가함. sim5 %>% ggplot(aes(x, y)) + geom_point() 5개의 모형을 만듦. library(splines) mod1 <- lm(y~ns(x,1), data=sim5) mod2 <- lm(y~ns(x,2), data=sim5) mod3 <- lm(y~ns(x,3), data=sim5) mod4 <- lm(y~ns(x,4), data=sim5) mod5 <- lm(y~ns(x,5), data=sim5)")
21
모델의 비교 grid <- sim5 %>%
data_grid(x = seq_range(x, n = 50, expand = 0.1)) %>% gather_predictions(mod1,mod2, mod3, mod4, mod5, .pred = "y") 5개 모델에 따른 예측값을 얻어 grid 변수에 저장. ggplot(sim5, aes(x, y)) + geom_point() + geom_line(data = grid, color = "red") + facet_wrap(~ model) sim5 data의 관측값을 scatterplot으로 그리고 예측값(grid)을 붉은 선 그래프로 그리되 모델에 따라 그래프를 따로 그려 비교함. 모델의 복잡도가 증가할수록 데이터를 잘 설명함을 볼 수 있음.
) %>% gather_predictions(mod1,mod2, mod3, mod4, mod5, .pred = y ) 5개 모델에 따른 예측값을 얻어 grid 변수에 저장. ggplot(sim5, aes(x, y)) + geom_point() + geom_line(data = grid, color = red ) + facet_wrap(~ model) sim5 data의 관측값을 scatterplot으로 그리고. 예측값(grid)을 붉은 선 그래프로 그리되. 모델에 따라 그래프를 따로 그려 비교함. 모델의 복잡도가 증가할수록 데이터를 잘 설명함을 볼 수 있음.")
23
대안적 모델들 linear model, 예: lm()
가장 단순하고 해석하기 쉽고 널리 사용됨. 종속변수가 연속형(수치형)이고 오차가 정규분포를 따른다고 가정. Generalized linear model, 예: stats::glm() 종속변수가 연속형이 아닌 경우도 처리 가능. Generalized additive model, 예: mgcv::gam() 임의의 smooth 함수를 사용할 수 있음. Penalized linear model, 예: glmnet::glmnet(): 복잡한 모델에 벌점을 줌. Robust linear model, 예: MASS:rlm(): outlier에 벌점을 줌. Tree, 예: rpart::rpart() 데이터를 점점 더 작은 부분으로 쪼개어 모델을 만듦.
이고 오차가 정규분포를 따른다고 가정. Generalized linear model, 예: stats::glm() 종속변수가 연속형이 아닌 경우도 처리 가능. Generalized additive model, 예: mgcv::gam() 임의의 smooth 함수를 사용할 수 있음. Penalized linear model, 예: glmnet::glmnet(): 복잡한 모델에 벌점을 줌. Robust linear model, 예: MASS:rlm(): outlier에 벌점을 줌. Tree, 예: rpart::rpart() 데이터를 점점 더 작은 부분으로 쪼개어 모델을 만듦.")


 윷놀이와 컴퓨터 게임.>")
 아씨의 방에는 바느질을 위한 친구가 몇 명이 있었나요 ? 정답은 ? 일곱.>")


 3-1 3 단원. 언어의 특성 기호성 자의성 사회성 규칙성 창조성 역사성.>")


>")




 문제 Machine Learning.>")

.>")
공영홈쇼핑.>")

 2014년 가을학기 강원대학교 컴퓨터과학전공 문양세.>")

