Download presentation
Presentation is loading. Please wait.

1
문자코드, 문자 입출력 한국어 정보의 전산 처리

2
컴퓨터의 기본 속성 컴퓨터에서 모든 데이터와 명령은 2진수로 표상됨.
컴퓨터의 핵심 구성요소인 저장장치와 연산장치는 모두 반도체임. 반도체는 기억소자를 매우 작게 하여 좁은 공간 안에 수많은 기억소자 들을 집적해 놓은 것. 하나의 기억소자는 on(켜져 있는 상태)과 off(꺼져 있는 상태)의 두 가 지 상태에만 있을 수 있음. 하나의 기억소자가 3가지 상태를 가질 수 있는 반도체에 대한 연구가 진행되 고 있음. (상용화되려면 시간이 꽤 걸릴 듯) 편의상 on 상태를 1로, off 상태를 0으로 간주함. 컴퓨터에서 행해지는 연산은 궁극적으로 ‘어떤 위치의 기억소자의 상 태를 0에서 1로, 또는 1에서 0으로 바꿔라’라는 가장 기초적인 연산으 로 구성되어 있음.
과 off(꺼져 있는 상태)의 두 가 지 상태에만 있을 수 있음. 하나의 기억소자가 3가지 상태를 가질 수 있는 반도체에 대한 연구가 진행되 고 있음. (상용화되려면 시간이 꽤 걸릴 듯) 편의상 on 상태를 1로, off 상태를 0으로 간주함. 컴퓨터에서 행해지는 연산은 궁극적으로 ‘어떤 위치의 기억소자의 상 태를 0에서 1로, 또는 1에서 0으로 바꿔라’라는 가장 기초적인 연산으 로 구성되어 있음.")
3
X 정보 처리란? X를 컴퓨터에서 구현/표현할 수 있는 방안을 모색
내부 처리, 입력, 출력의 순서로 살펴봄.

4
X가 음악인 경우 입력 공기 중에서 음파의 형태로 구현되는 소리 정보(아날로그 사운드) 를 마이크 등의 입력 장치를 통해 흡수 내부 처리 아날로그 사운드에 포함된 여러 정보(파형, 주파수, 세기 등)를 일정 한 규약에 따라 디지털화(2진수로 표현). 디지털 파일의 형태(wave, mp3 등)로 저장하고 유통. 출력 디지털 음악 파일을 스피커, 이어폰 등의 출력 장치를 통해 아날로 그 사운드(음파)로 재현
로 저장하고 유통. 출력. 디지털 음악 파일을 스피커, 이어폰 등의 출력 장치를 통해 아날로 그 사운드(음파)로 재현.")
5
X가 이미지/사진인 경우 입력 이미지가 갖고 있는 시각 정보(아날로그 이미지)를 스캐너, 카메라 등 의 입력 장치를 통해 흡수 내부 처리 아날로그 이미지에 포함된 여러 정보를 일정한 규약에 따라 디지털화. 예컨대 아날로그 이미지가 펼쳐져 있는 공간을 일정한 수의 격자(화 소)로 분해하고 각 격자의 색채를 디지털 형태로 표현. 예컨대 R·G·B의 세 차원 각각을 0~255 사이의 정수로 표현. 이들 정수 도 궁극적으로는 2진수로 표현. bmp, jpg, gif 등의 파일 포맷으로 저장하고 유통. 출력 디지털 이미지 파일을 모니터, 프린터 등의 출력 장치를 통해 아날로 그 이미지로 재현
로 분해하고 각 격자의 색채를 디지털 형태로 표현. 예컨대 R·G·B의 세 차원 각각을 0~255 사이의 정수로 표현. 이들 정수 도 궁극적으로는 2진수로 표현. bmp, jpg, gif 등의 파일 포맷으로 저장하고 유통. 출력. 디지털 이미지 파일을 모니터, 프린터 등의 출력 장치를 통해 아날로 그 이미지로 재현.")
6
X가 한국어인 경우 한국어 정보 처리란, 한국어라는 언어 및 이를 사용하여 생산되는 수많 은 발화, 문장, 담화, 텍스트들을 컴퓨터로 적절히 처리하여, 이로부터 사용자가 원하는 정보를 추출하는 것. 언어 행위, 언어 생활은 음성언어를 사용하여 이루어지기도 하고 문자 를 사용하여 이루어지기도 함. 음성언어보다는 문자가, 컴퓨터가 처리하기에 적합하므로, 음성언어를 사용하여 이루어진 언어 행위의 산물도 문자로 변환하여 컴퓨터로 처 리하는 것이 일반적임. 음성언어→문자 변환을 흔히 음성인식(speech recognition)이라 함. 따라서 한국어 정보 처리는, 음성언어로서의 한국어를 한글, 로마자 등 의 문자로 변환하여 처리하는 것이 보통임.
이라 함. 따라서 한국어 정보 처리는, 음성언어로서의 한국어를 한글, 로마자 등 의 문자로 변환하여 처리하는 것이 보통임.")
7
X가 문자인 경우 입력 키보드나 터치패드상의 가상 키보드 등의 입력 장치를 통해, (일정한 규약에 따라 정해진) 키 스트로크 연쇄와 문자 간의 매핑 관계에 따라 문자 정보를 입력함. 내부 처리 미리 정해진 규약에 따라 문자를 2진수 형태로 변환하여 기억장치 (CPU 캐시, RAM, 하드디스크)에 저장. 텍스트(txt) 파일 포맷으로 저장하고 유통. 출력 2진수 형태로 저장된 정보를 정해진 규약에 따라 문자로 매핑하여, 각 문자를 모니터, 프린터 등의 출력 장치에 시각적 형태의 문자로 재현. 하나의 문자가 폰트에 따라 다양한 시각적 형태로 드러날 수 있음.
에 저장. 텍스트(txt) 파일 포맷으로 저장하고 유통. 출력. 2진수 형태로 저장된 정보를 정해진 규약에 따라 문자로 매핑하여, 각 문자를 모니터, 프린터 등의 출력 장치에 시각적 형태의 문자로 재현. 하나의 문자가 폰트에 따라 다양한 시각적 형태로 드러날 수 있음.")
8
문자코드(character code)의 기본 개념
문자코드: 문자의 내부 처리에서, 각 문자와 2진수 사이의 매핑 관계를 정해 놓은 것 0 또는 1(즉 on or off)의 1자리 2진수에 해당하는 정보를 저장할 수 있 는 단위를 비트(bit, binary digit)라고 한다. 하드웨어적으로 말하면, 최소의 기억소자. 즉 1 비트의 저장 공간에는 2가지 기호밖에 저장할 수 없다. 8 비트의 묶음을 1 바이트(byte)라고 한다. 1 바이트에 저장될 수 있는 기호의 수 = 28 = 256 연산장치가 한번에 읽을 수 있는 단위를 워드(word)라고 한다. 워드의 크기는 하드웨어에 따라 다르다. 8비트 컴퓨터: 1워드=8비트=1바이트 64비트 컴퓨터: 1워드=64비트=8바이트
의 1자리 2진수에 해당하는 정보를 저장할 수 있 는 단위를 비트(bit, binary digit)라고 한다. 하드웨어적으로 말하면, 최소의 기억소자. 즉 1 비트의 저장 공간에는 2가지 기호밖에 저장할 수 없다. 8 비트의 묶음을 1 바이트(byte)라고 한다. 1 바이트에 저장될 수 있는 기호의 수 = 28 = 256. 연산장치가 한번에 읽을 수 있는 단위를 워드(word)라고 한다. 워드의 크기는 하드웨어에 따라 다르다. 8비트 컴퓨터: 1워드=8비트=1바이트. 64비트 컴퓨터: 1워드=64비트=8바이트.")
9
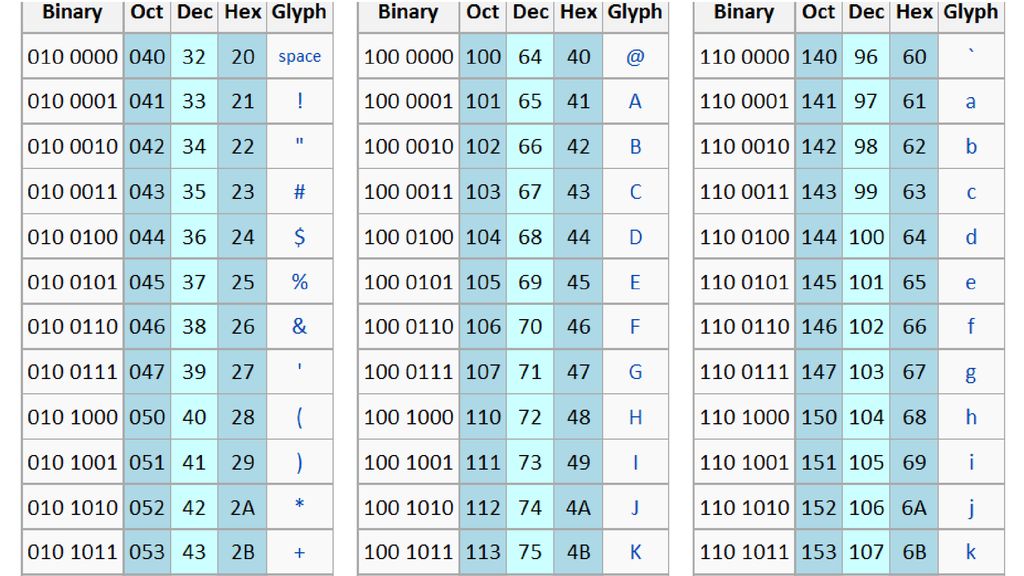
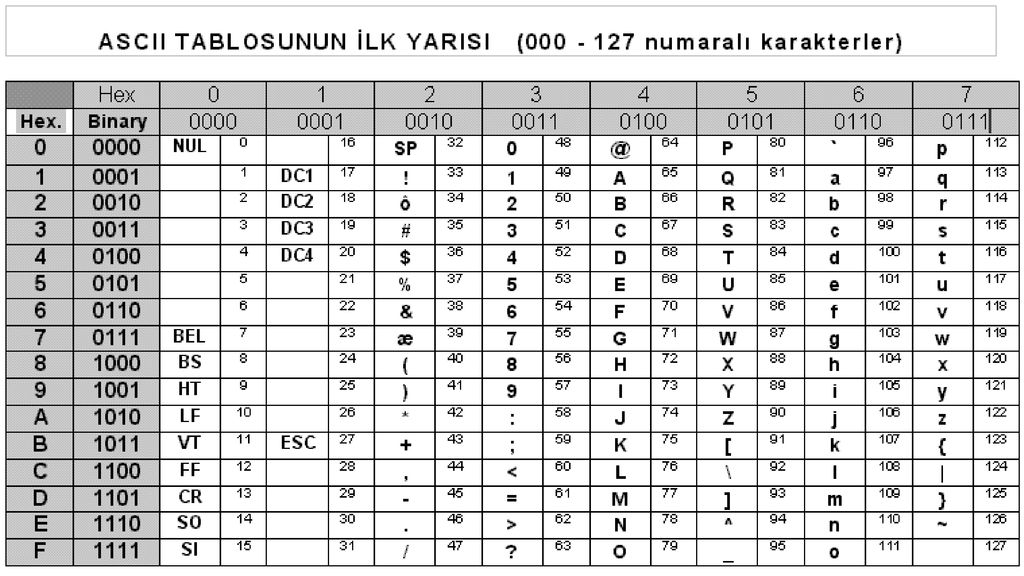
아스키 코드 컴퓨터 기술은 미국에서 가장 먼저 발달했음. 미국에서 사용되는 문자는 로마자(속칭 영문자).
영문자 대문자 26개, 소문자 26개, 아라비아숫자, 기타 기호 등을 모두 합쳐도 100개 남짓. 따라서 하나의 문자를 1바이트로 표현할 수 있음. 달리 말하면 1바이트의 저장공간만 있으면 100여개의 문자를 구분할 수 있음. 미국 국가 표준 기구(ANSI, American National Standard Institute)에서 는 이 문자들과 2진수 사이의 매핑 관계를 정해 놓았음. 이것을 아스키(ASCII, American Standard Code for Information Interchange)라고 함.
에서 는 이 문자들과 2진수 사이의 매핑 관계를 정해 놓았음. 이것을 아스키(ASCII, American Standard Code for Information Interchange)라고 함.")
12
아스키 코드 아스키 코드에서 영문자 대문자는 65~90번, 소문자는 97~122번에 배 정되어 있고, 숫자는 48번(0)~57번(9)에 배당되어 있음. 여기서 A가 65번이라는 말의 의미는? A라는 문자가 컴퓨터에서 처리될 때에는 1 바이트의 저장 공간 안에 다음과 같이 2진수로 기록된다는 뜻. 이 2진수는 10진수로 표현하면 65가 되고 16진수로 표현하면 41이 된다. 16진수를 표기할 때에는 10진수와 구분하기 위해 앞에 ‘0x’를 붙여 준다. 2진수 16진수 10진수 A 0x41 65 B 0x42 66 C 0x43 67

13
텍스트(txt) 파일 컴퓨터에서 메모장 같은 텍스트 에디터를 열고 키보드에 Hello! 이라고 입력하면
메모리에는 이라고 기록됨. 이 2진수들의 연쇄를 16진수들의 연쇄로 고쳐 적으면 0x48 0x65 0x6c 0x6c 0x6f 0x21 이 됨. 이것을 텍스트 파일로 저장하면 하드디스크의 일정한 주소 영역에 위 의 2진수들이 차례로 기록되어 저장되는 것임.

14
1바이트 문자와 2바이트 문자 한글은 현재 통용되고 있는 것만 따져도 수천 개나 되기 때문에
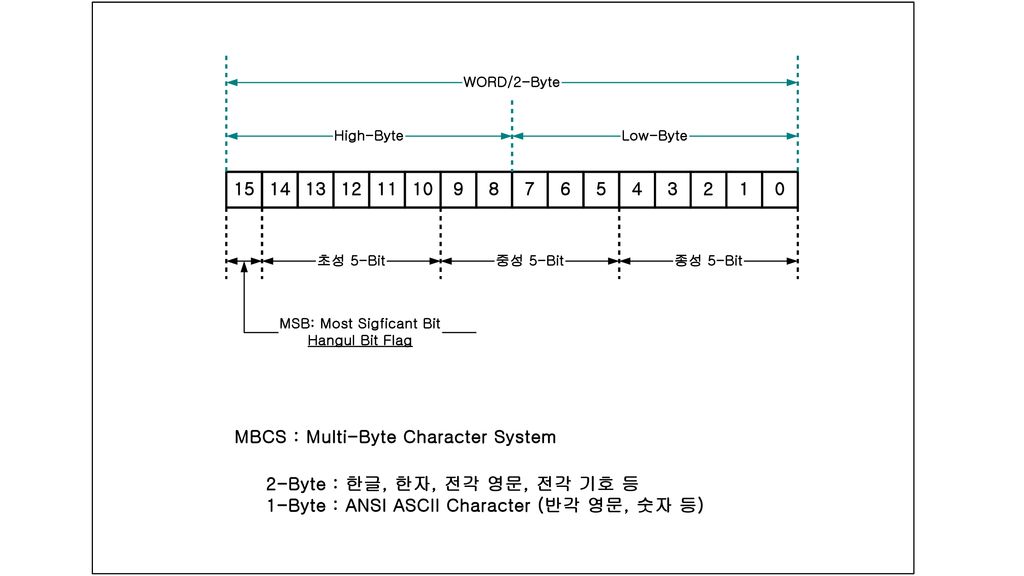
1바이트 가지고는 모든 한글을 구별하여 나타낼 수 없음. 2바이트=16비트. 216 = 개의 기호를 구분할 수 있음. 따라서 2바이트로 모든 한글 문자들을 나타낼 수 있음. 예컨대 한글 문자 ‘가‘는 (16진수로는 0xb0a1)으 로 나타낼 수 있음. 컴퓨터가 연산을 수행할 때, 저장공간에 기록되어 있는 문자가 1바이 트짜리인지 2바이트짜리인지 어떻게 알까? 1바이트 문자는 바이트의 첫 비트(MSB, most significant bit)가 0이고 2바이트 문자는 MSB가 1이라고 규약을 정해 놓으면 됨.
으 로 나타낼 수 있음. 컴퓨터가 연산을 수행할 때, 저장공간에 기록되어 있는 문자가 1바이 트짜리인지 2바이트짜리인지 어떻게 알까 1바이트 문자는 바이트의 첫 비트(MSB, most significant bit)가 0이고. 2바이트 문자는 MSB가 1이라고 규약을 정해 놓으면 됨.")
15
문자코드의 국가 표준 문자코드의 표준이 없고, 회사마다 기계마다 다르다면, A 회사에서 만 든 컴퓨터/소프트웨어로 작성한 텍스트 문서를 B 회사에서 만든 컴퓨 터/소프트웨어로 열어 보면 완전히 다른 문자로 보일 수 있음. 정보의 원활한 유통과 처리를 위해서는 문자코드의 표준이 필요함. 미국에서 아스키 코드를 문자코드의 국가 표준으로 정해 놓았음. 그 후 전세계에서 아스키 코드가 국제 표준처럼 자리잡았음. 아스키 코드에 포함된 문자들 이외의 문자를 사용하는 국가에서는, 그 국가 나름의 문자코드 표준을 제정해야 할 필요성이 대두됨. 1바이트 문자뿐 아니라 2바이트 문자까지 사용해야 하는 나라에서는 문자코드의 표준을 정하는 일이 그리 단순치 않을 수 있음. 경제성(저장공간을 적게 차지할수록 좋음)과 효율성(연산을 빨리 수행 할 수 있을수록 좋음)을 고려하여 문자코드 표준을 정해야 함.
과 효율성(연산을 빨리 수행 할 수 있을수록 좋음)을 고려하여 문자코드 표준을 정해야 함.")
16
한글 코드의 초기 역사 초기에는 한글 한 글자를 3바이트로 표현하는 방안이 제안됨. 가변 바이트 방안
초성 1바이트, 중성 1바이트, 종성 1바이트 한글 한 글자가 초성, 중성, 종성의 세 부분으로 이루어져 있다는 사실을 반영한, 나름대로 합리적인 방안이기는 하나 초창기에는 저장공간이 비쌌기 때문에, 저장공간을 가능한 한 적게 차지하는 방 안이 선호되었고 2바이트로도 표현할 수 있는 것을 3바이트로 표현하는 방안은 환영받지 못했음. 가변 바이트 방안 한글 한 글자를 구성하는 자소의 개수만큼 바이트를 배당. ‘가’는 2바이트, ‘강‘은 3바이트, ‘읽’은 4바이트 나름대로 합리적인 방안이나, 경제성의 측면에서 환영받지 못함. 한글의 구성 원리를 반영하면서도 보다 경제적인 방안이 모색되게 됨.

17
조합형 한글 코드 (KSSM) 한글 한 글자를 2바이트=16비트로 표현 첫 비트(MSB)는 1로 고정.
나머지 15비트 중, 앞 5비트는 초성, 그 다음 5비트는 중성, 마지막 5비 트는 종성을 나타냄. 5비트로 나타낼 수 있는 기호의 개수 = 25 =32 가지 한글의 초성은 19개, 중성은 21개, 종성은 28개이므로 모두 5비트로 표현 가능. 2바이트라는 적은 저장공간을 차지하면서도 초성, 중성, 종성으로 이루어져 있다는 한글의 구성적 특성을 잘 반영. 글자의 코드값을 보고 (약간의 연산을 수행하면) 초성, 중성, 종성이 무 엇인지 알 수 있음. 초성, 중성, 종성이 무엇인지 알면, 보다 사용자 친화적인 인터페이스를 만들 수 있음.
 초성, 중성, 종성이 무 엇인지 알 수 있음. 초성, 중성, 종성이 무엇인지 알면, 보다 사용자 친화적인 인터페이스를 만들 수 있음.")
19
강 초성 ㄱ 중성 ㅏ 종성 ㅇ ‘강’의 코드값 00010 0x02 00011 0x03 01100 0x0c
0x886c

20
조합형 한글 코드에서 초성, 중성, 종성에 배당된 값
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 초성 채움 ㄱ ㄲ ㄴ ㄷ ㄸ ㄹ ㅁ ㅂ ㅃ ㅅ ㅆ ㅇ ㅈ ㅉ ㅊ ㅋ ㅌ ㅍ ㅎ 중성 ㅏ ㅐ ㅑ ㅒ ㅓ ㅔ ㅕ ㅖ ㅗ ㅘ ㅙ ㅚ ㅛ ㅜ ㅝ ㅞ ㅟ ㅠ ㅡ ㅢ ㅣ 종성 ㄳ ㄵ ㄶ ㄺ ㄻ ㄼ ㄽ ㄾ ㄿ ㅀ ㅄ

21
완성형 한글 코드 정부에서 표준으로 채택한 것은 완성형: KS C 5601, KS X 1001
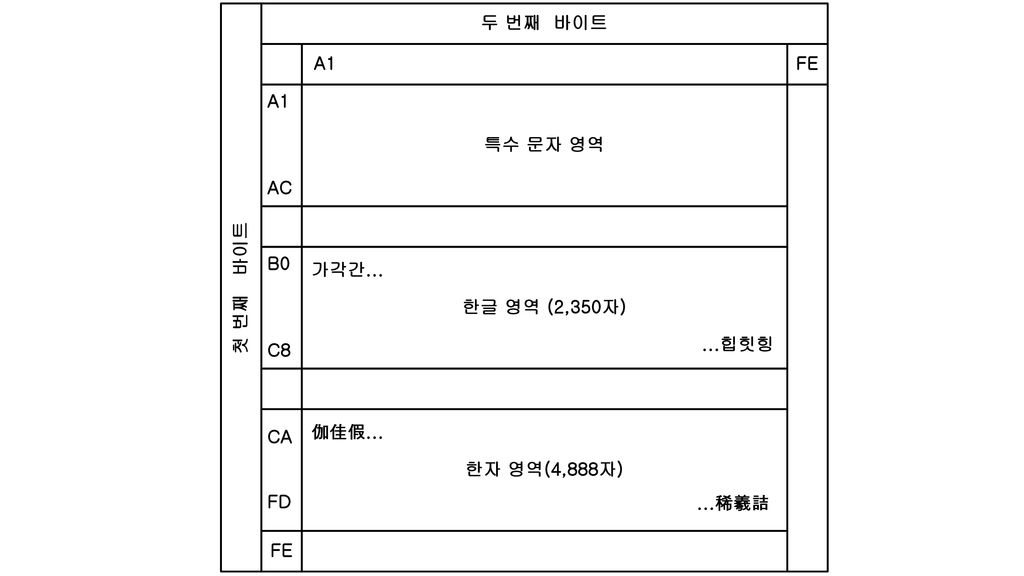
조합형이 초성, 중성, 종성 코드를 조합/결합하는 방식인 데 비해 완성형은 그렇지 않음. (그래서 ‘완성형‘이라는 명칭이 붙었음.) 한글 한 글자를 역시 2바이트로 표현 현대 일상생활에서 사용하는 글자 2350자만을 추림. 이론상 가능한 현대 한글은 초성 19 × 중성 21 × 종성 28 = 11172자 앞 바이트는 0xb0~0xc8(25개), 뒤 바이트는 0xa1~0xfe(94개)를 한글 영 역으로 사용. 25×94=2350자 앞 바이트는 0xca~0xfd(52개), 뒤 바이트는 0xa1~0xfe(94개)를 한자 영 역으로 사용. 52×94=4888자
 한글 한 글자를 역시 2바이트로 표현. 현대 일상생활에서 사용하는 글자 2350자만을 추림. 이론상 가능한 현대 한글은 초성 19 × 중성 21 × 종성 28 = 11172자. 앞 바이트는 0xb0~0xc8(25개), 뒤 바이트는 0xa1~0xfe(94개)를 한글 영 역으로 사용. 25×94=2350자. 앞 바이트는 0xca~0xfd(52개), 뒤 바이트는 0xa1~0xfe(94개)를 한자 영 역으로 사용. 52×94=4888자.")
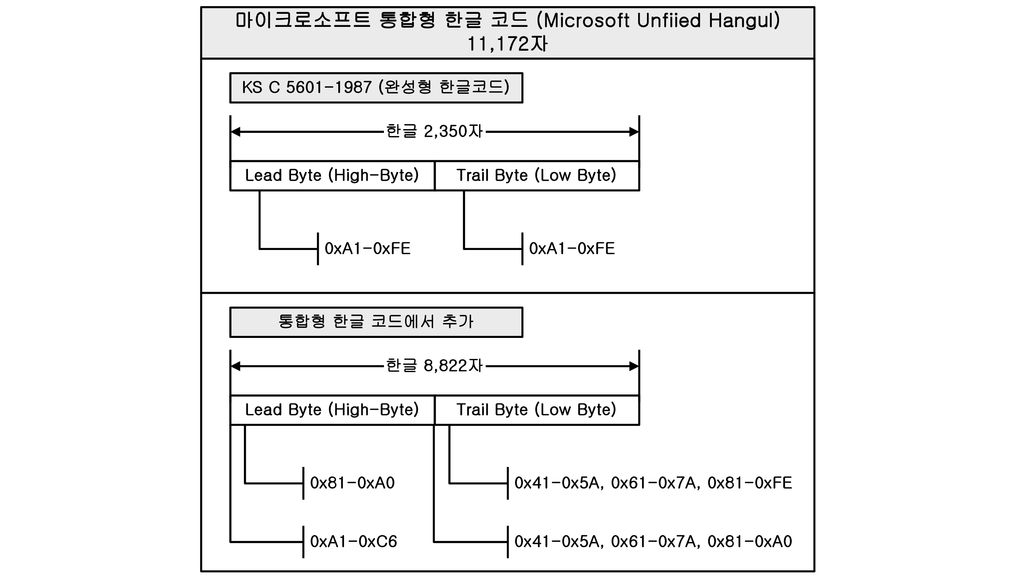
23
완성형의 문제점 애초에 사용할 일이 없을 것으로 생각되어 2350자에서 배제되었던 글자 중 일부를 사용할 필요가 생김: 똠, 펲 마이크로소프트에서 윈도98을 출시하면서 이 문제를 보완하여 마이크로 소프트 통합형 한글(Microsoft Unified Hangul)을 내놓음. 한글 8822자(= )에 새로 코드 배당 새로 배당하는 글자의 코드 영역이 기존 글자의 코드 영역과 겹치면 안 됨. backward compatibility: 컴퓨터 관련 규약을 업데이트할 때, 이미 정해져 있던 것을 고치지는 말고 새로운 것을 추가하기만 해야, 과거의 규약에 입각해서 만들어진 데 이터, 소프트웨어, 하드웨어 등이 새 버전에서도 유효함. 만약, 2350자의 코드 값을 새로 배정하면, 예전의 문자코드에 입각하여 작성한 텍 스트 문서를 새 문자코드에 입각하여 만들어진 텍스트 에디터에서 열면 엉뚱한 문 자로 인식되게 됨. 그러다 보니, =11172자의 코드 값 배열 순서가 한글 자모순 배 열 순서와 불일치하게 됨.
을 내놓음. 한글 8822자(= )에 새로 코드 배당. 새로 배당하는 글자의 코드 영역이 기존 글자의 코드 영역과 겹치면 안 됨. backward compatibility: 컴퓨터 관련 규약을 업데이트할 때, 이미 정해져 있던 것을 고치지는 말고 새로운 것을 추가하기만 해야, 과거의 규약에 입각해서 만들어진 데 이터, 소프트웨어, 하드웨어 등이 새 버전에서도 유효함. 만약, 2350자의 코드 값을 새로 배정하면, 예전의 문자코드에 입각하여 작성한 텍 스트 문서를 새 문자코드에 입각하여 만들어진 텍스트 에디터에서 열면 엉뚱한 문 자로 인식되게 됨. 그러다 보니, =11172자의 코드 값 배열 순서가 한글 자모순 배 열 순서와 불일치하게 됨.")
25
자모순-코드순 불일치 이로 인해, 단순히 코드값에 따 라 소팅을 하면, 자모순과 어긋 나는 결과가 발생함.
연번 KS C 5601 코드 통합형 코드 한글 1 0xB0A1 가 2 0xB0A2 각 3 - 0x8141 갂 4 0x8142 갃 5 0xB0A3 간 6 0x8143 갅 7 0x8144 갆 8 0xB0A4 갇 9 0xB0A5 갈 10 0xB0A6 갉 11 0xB0A7 갊 12 0x8145 갋 13 0x8146 갌 14 0x8147 갍 15 0x8148 갎 16 0x8149 갏 자모순-코드순 불일치 이로 인해, 단순히 코드값에 따 라 소팅을 하면, 자모순과 어긋 나는 결과가 발생함. 자모순과 일치하는 소팅 결과 를 얻기 위해서는, 단순히 코드 값에 따라 정렬하는 것이 아니 라, 좀 더 특별한 배려가 필요 하게 됨. 근시안적인 문자코드 정책으 로 인해, IT 자원을 불필요한 데 낭비하게 된 사례.

26
완성형의 문제 2: 자소 분해 완성형 코드 자체만 가지고는 초성, 중성, 종성을 알 수 없기 때문에 (자소 분해)
완성형 코드 자체만 가지고는 초성, 중성, 종성을 알 수 없기 때문에 (자소 분해) 완성형 코드로 된 텍스트에서 자소 분해를 하려면 일단 완성형-조합형 매핑 테이블을 만들고 각 한글 글자를 조합형 코드로 변환한 뒤 조합형에서 한글 한 글자를 표현하는 16비 트 중 MSB를 제외한 15비트를 5비트씩 나누어 초성, 중성, 종성 값을 알아냄. 이 역시, 잘못된 문자코드 정책으로 인해, IT 자원을 불필요한 데 낭비하게 된 사례임.
 완성형 코드로 된 텍스트에서 자소 분해를 하려면. 일단 완성형-조합형 매핑 테이블을 만들고. 각 한글 글자를 조합형 코드로 변환한 뒤. 조합형에서 한글 한 글자를 표현하는 16비 트 중. MSB를 제외한 15비트를 5비트씩 나누어 초성, 중성, 종성 값을 알아냄. 이 역시, 잘못된 문자코드 정책으로 인해, IT 자원을 불필요한 데 낭비하게 된 사례임.")
27
일본, 중국, 대만의 문자코드 한자를 많이 쓰는 일본과 중국에서도 한국과 비슷하게 1 byte 문자만으로 부족하여
나름의 2 byte 문자 code 체계를 고안하여 사용하고 있다. 일본에서는 JIS(Japan Industrial Standard)라는 code 체계 및 이 를 간소화한 Shift-JIS를 많이 사용하고 있다. 이 밖에 EUC(extended unix characterset)-JP도 많이 사용된다. 簡體를 주로 사용하는 중국(대륙)에서 채택된 표준은 GB, 繁體를 주로 사용하는 대만에서 채택된 표준은 Big5라고 한다.
라는 code 체계 및 이 를 간소화한 Shift-JIS를 많이 사용하고 있다. 이 밖에 EUC(extended unix characterset)-JP도 많이 사용된다. 簡體를 주로 사용하는 중국(대륙)에서 채택된 표준은 GB, 繁體를 주로 사용하는 대만에서 채택된 표준은 Big5라고 한다.")
28
왼쪽부터 S-JIS, EUC-JP, GB, Big-5

29
문자코드의 국가간 충돌 각 나라는 다른 나라에서 어떤 글자에 어떤 코드값을 배정했는지를 신 경 쓰지 않고 (또는 신경을 썼더라도 어쩔 수 없이) 자기 나름대로 코드값을 배정했기 때문에 같은 글자가 각 문자코드 체계에서 서로 다른 코드값을 배정받게 되었 음. 거꾸로 말하면, 하나의 코드값(code point)이 각 코드 체계에서 서로 다 른 글자를 나타내게 되었음. 이에 따라 하나의 문서 내에서 한글, 한자(번체자, 간체자), 가나 등을 섞 어서 쓰기가 어렵게 됨. 모든 텍스트 문서는 “이 문서는 ~~ 코드 체계에 따라 작성되었음”이라 는 정보를 포함해야 국제적으로 유통될 수 있게 되었음. 이 정보가 누락되어 있거나, 소프트웨어가 오인하면, 문자 깨짐 현상이 발생.
이 각 코드 체계에서 서로 다 른 글자를 나타내게 되었음. 이에 따라 하나의 문서 내에서 한글, 한자(번체자, 간체자), 가나 등을 섞 어서 쓰기가 어렵게 됨. 모든 텍스트 문서는 이 문서는 ~~ 코드 체계에 따라 작성되었음 이라 는 정보를 포함해야 국제적으로 유통될 수 있게 되었음. 이 정보가 누락되어 있거나, 소프트웨어가 오인하면, 문자 깨짐 현상이 발생.")
30
유니코드(Unicode)의 대두 이러한 국가간 코드 영역의 중복 문제를 해소하기 위해
사실은 MS사에서 자사 제품의 지역화(localization) 비용을 줄이기 위해서 유니코 드 체제를 강력히 후원해 오고 있음 각국 대표들이 모여 세계의 모든 문자들을 동시에 표현할 수 있으면서 각 문자가 서로 겹치지 않는 통일된 문자 code 체계를 만드는 방안을 논 의하게 됨. 이 회의는 유니코드 컨소시엄에서 주관하고 있으며 유니코드 version ( )까지 나와 있음. ( 참조) ISO(국제 표준 기구)에서도 유니코드를 표준으로 채택: ISO/IEC 10646
 비용을 줄이기 위해서 유니코 드 체제를 강력히 후원해 오고 있음. 각국 대표들이 모여 세계의 모든 문자들을 동시에 표현할 수 있으면서 각 문자가 서로 겹치지 않는 통일된 문자 code 체계를 만드는 방안을 논 의하게 됨. 이 회의는 유니코드 컨소시엄에서 주관하고 있으며 유니코드 version 12.0 ( )까지 나와 있음. ( 참조) ISO(국제 표준 기구)에서도 유니코드를 표준으로 채택: ISO/IEC")
31
유니코드의 문자 인코딩 방식 1: UTF-32 ≒ UCS-4
모든 문자를 4바이트=32비트로 표현한다. 따라서 232 = 4,294,967,296개(약 43억개)의 문자들을 구별하여 표상할 수 있음. 장점 표상 방식이 가장 깔끔함. 모든 문자를 일관되게 4바이트로 표현하므로, 소프트웨어가 특별한 고려를 할 필요 없이, 일관성 있게 문자를 처리할 수 있음. 단점 하나의 문자를 저장하는 데 너무 많은 저장 공간이 소요됨. 반도체 가격이 빠른 속도로 싸지고 있으므로, 저장 공간을 많이 차지하는 게 큰 문제가 아닌 듯이 생각할지도 모르지만 구글이나 포털업체처럼 대용량 서버를 운용해야 하는 회사 입장에서는 저장 공 간은 곧 돈과 직결됨.
의 문자들을 구별하여 표상할 수 있음. 장점. 표상 방식이 가장 깔끔함. 모든 문자를 일관되게 4바이트로 표현하므로, 소프트웨어가 특별한 고려를 할 필요 없이, 일관성 있게 문자를 처리할 수 있음. 단점. 하나의 문자를 저장하는 데 너무 많은 저장 공간이 소요됨. 반도체 가격이 빠른 속도로 싸지고 있으므로, 저장 공간을 많이 차지하는 게 큰 문제가 아닌 듯이 생각할지도 모르지만. 구글이나 포털업체처럼 대용량 서버를 운용해야 하는 회사 입장에서는 저장 공 간은 곧 돈과 직결됨.")
32
유니코드의 문자 인코딩 방식 2: UTF-16 ≒ UCS-2
사용 빈도가 높은 글자는 BMP(basic multilingual plane)에 배당하고 사용 빈도가 낮은 글자는 SP(supplementary plane)에 배당. BMP에 속하는 글자는 2바이트로 표현. 216=65,536개의 기호가 구분될 수 있음: U+0000~U+FFFF 영문자, 한글, 한자의 상당 부분(한중일 통합 한자, Extension-A), 일본 가나 등 SP에 속하는 글자는 4바이트로 표현. 한자 중 Extension-B, Extension-C 등 4바이트 문자의 경우, “저는 4바이트 짜리입니다.” 하는 정보를 알려주어야 하기 때문에, 앞의 2바이트(High-Surrogate)와 뒤의 2바이트(Low- Surrogate)가 각각 일정한 범위 안에 있어야 함. High-Surrogate: U+D800~U+DBFF. 상위 6비트가 나머지 10비트 사용. Low-Surrogate: U+DC00~U+DFFF. 상위 6비트가 나머지 10비트 사용. BMP에 속하는 문자들은 이 범위를 차지할 수 없고 비워 두어야 함. 따라서 BMP에 속하는 문자의 수는 65536개보다 적음. SP에 속하는 문자의 코드값 범위: U+10000~U+10FFFF
에 배당하고. 사용 빈도가 낮은 글자는 SP(supplementary plane)에 배당. BMP에 속하는 글자는 2바이트로 표현. 216=65,536개의 기호가 구분될 수 있음: U+0000~U+FFFF. 영문자, 한글, 한자의 상당 부분(한중일 통합 한자, Extension-A), 일본 가나 등. SP에 속하는 글자는 4바이트로 표현. 한자 중 Extension-B, Extension-C 등. 4바이트 문자의 경우, 저는 4바이트 짜리입니다. 하는 정보를 알려주어야 하기 때문에, 앞의 2바이트(High-Surrogate)와 뒤의 2바이트(Low- Surrogate)가 각각 일정한 범위 안에 있어야 함. High-Surrogate: U+D800~U+DBFF. 상위 6비트가 나머지 10비트 사용. Low-Surrogate: U+DC00~U+DFFF. 상위 6비트가 나머지 10비트 사용. BMP에 속하는 문자들은 이 범위를 차지할 수 없고 비워 두어야 함. 따라서 BMP에 속하는 문자의 수는 65536개보다 적음. SP에 속하는 문자의 코드값 범위: U+10000~U+10FFFF.")
33
유니코드의 문자 인코딩 방식 3: UTF-8 사용 빈도에 따라 하나의 글자를 1바이트~4바이트로 표현.
하나의 글자가 몇 바이트로 표현되는가는, 첫 바이트의 상위 비트(들)로 표현. 1바이트 문자의 MSB는 0 2바이트 문자는 첫 바이트의 상위 비트가 110 3바이트 문자는 첫 바이트의 상위 비트가 1110 4바이트 문자는 첫 바이트의 상위 비트가 11110 첫 바이트가 아닌 나머지 바이트들은 상위 비트가 10 한 문자에 대한 바이트 표현이 다른 문자에 대한 바이트 표현의 일부가 되는 경우가 없도록 함. 문자열(string) 내에서 substring을 찾는 알고리즘이 적용될 수 있음. 장점: ASCII-compatible (아스키 코드에 입각한 소프트웨어 사용 가능) 단점: 하나의 글자를 표현하는 데 소요되는 바이트 수가 들쭉날쭉
로 표현. 1바이트 문자의 MSB는 0. 2바이트 문자는 첫 바이트의 상위 비트가 바이트 문자는 첫 바이트의 상위 비트가 바이트 문자는 첫 바이트의 상위 비트가 첫 바이트가 아닌 나머지 바이트들은 상위 비트가 10. 한 문자에 대한 바이트 표현이 다른 문자에 대한 바이트 표현의 일부가 되는 경우가 없도록 함. 문자열(string) 내에서 substring을 찾는 알고리즘이 적용될 수 있음. 장점: ASCII-compatible (아스키 코드에 입각한 소프트웨어 사용 가능) 단점: 하나의 글자를 표현하는 데 소요되는 바이트 수가 들쭉날쭉.")
34
UTF-16과 UTF-8의 대응 관계 코드 범위(십육진법) UTF-16BE 표현(이진법) UTF-8 표현(이진법) 설명
xxxxxxx 0xxxxxxx ASCII와 동일한 범위 FF 00000xxx xxxxxxxx 110xxxxx 10xxxxxx 첫 바이트는 110 또는 1110으로 시작하고, 나머지 바이트들은 10으로 시작함 FFFF xxxxxxxx xxxxxxxx 1110xxxx 10xxxxxx 10xxxxxx FFFF 110110yy yyxxxxxx xx xxxxxxxx 11110zzz 10zzxxxx 10xxxxxx 10xxxxxx UTF-16 Surrogate 쌍 영역 (yyyy = zzzzz - 1). UTF-8로 표시된 비트 패턴은 실제 코드 포인트와 동일하다.
. UTF-8로 표시된 비트 패턴은 실제 코드 포인트와 동일하다.")
35
유니코드와 한글 한글 11,172자가 BMP에 배당됨: 0xAC00~ 0xD7A3 한자 다음으로 넓은 영역을 차지함.
초성, 중성, 종성 조합식은 아니나 자모순대로 배열되어 있어, 계산에 의한 자모 분해가 가능. 한글 글자의 코드값을 X라 하면 초성 값 = ( X - 0xac00 ) / 588 Y = ( X - 0xac00 ) % 588 중성 값 = Y / 28 종성 값 = Y % 28 = ( X - 0xac00 ) % 28 완성형의 전철을 밟지 않고 11,172자 모두 코드값을 배당받아, 한글의 컴퓨터 처리가 원활히 이루어지게 되었음. 자음과 모음 각 자소(옛한글 포함)도 따로 코드 배정
 / 588. Y = ( X - 0xac00 ) % 588. 중성 값 = Y / 28. 종성 값 = Y % 28 = ( X - 0xac00 ) % 28. 완성형의 전철을 밟지 않고 11,172자 모두 코드값을 배당받아, 한글의 컴퓨터 처리가 원활히 이루어지게 되었음. 자음과 모음 각 자소(옛한글 포함)도 따로 코드 배정.")
36
옛한글의 정보화 국어사 자료에는 옛한글, 구결자 등 특수한 문자가 많이 사용됨.
ASCII, 완성형, 조합형 등의 코드 체계에서는 옛한글, 구결자를 표상할 수 없음. ‘보석글’이라는 워드프로세서에서 처음으로 옛한글에 코드를 배당하여 표상. ‘한글과컴퓨터사’의 ‘글’ 워드프로세서의 HNC 코드에서도 옛한글에 코드를 배당. 구결자도 코드값을 배정받음: 총 269자 1992년 ‘글 2.0 전문가용’에서: HNC 코드번호 1D00~ 1DF3 (244자) ‘글 3.01’에서 구결자 16자 추가: HNC 코드번호 1DF4~1E03 ‘글 97’에서 구결자 9자 추가: HNC 코드번호 1E04~1E0C
 ‘글 3.01’에서 구결자 16자 추가: HNC 코드번호 1DF4~1E03. ‘글 97’에서 구결자 9자 추가: HNC 코드번호 1E04~1E0C.")
37
유니코드와 옛한글 2000년 무렵 한글과컴퓨터사(글), 한국 MS(MS Word), 삼성전자(훈민 워드)는 각각 자사 제품을 유니코드 기반으로 뜯어고치는 과정에서 유니코드에서 코드를 배정받지 못한 옛한글, 구결자 등을 처리하는 방식 을 3사가 통일하기로 합의. 문자코드가 통일되어 있어야, 타사 제품으로 작성한 문서를 자사 제품에서 읽을 수 있음. 사용자 정의 영역(private use area)에 옛한글과 구결자를 배당. 옛한글: U+E0BC ~ U+F66E (5299자) (그 외는 옛한글 자소 조합식. 6바이트) 구결자: U+F67E ~ U+F77c (255자. HNC의 269자 중 자형이 동일한 것은 통합) 옛한글 자소: U+F785 ~ U+F8F7 이를 화면상에 표현할 수 있도록 글꼴도 제작. 글: 한컴돋움, 한컴바탕 등; MS: 새굴림, 새돋움, 새바탕, 새궁서 등 사용자 정의 영역을 이용한 것은 당시로서 어쩔 수 없는 선택이기는 했 으나, 이는 어디까지나 임시방편. 국제적 통용성이 없음.
에 옛한글과 구결자를 배당. 옛한글: U+E0BC ~ U+F66E (5299자) (그 외는 옛한글 자소 조합식. 6바이트) 구결자: U+F67E ~ U+F77c (255자. HNC의 269자 중 자형이 동일한 것은 통합) 옛한글 자소: U+F785 ~ U+F8F7. 이를 화면상에 표현할 수 있도록 글꼴도 제작. 글: 한컴돋움, 한컴바탕 등; MS: 새굴림, 새돋움, 새바탕, 새궁서 등. 사용자 정의 영역을 이용한 것은 당시로서 어쩔 수 없는 선택이기는 했 으나, 이는 어디까지나 임시방편. 국제적 통용성이 없음.")
38
옛한글 표현 방식의 변화 MS-Word 2007, 글 2010부터는 옛한글 표현 방식이 조합식으로 바뀜.
유니코드의 BMP에 코드값을 배정받은 초성, 중성, 종성을 조합하여 하 나의 한글 글자(음절)를 표현함. 하나의 글자를 표현하는 데 소요되는 바이트 수가 일정하지 않음. 종성이 없는 옛한글 글자: 초성 2바이트 + 중성 2바이트 = 4바이트 종성이 있는 옛한글 글자: 초성 2 + 중성 2 + 종성 2 = 6바이트 현대 한글은 모두 2바이트 옛한글 한 글자를 표현하는 데 소요되는 바이트 수가 현대 한글보다 많 아 저장 공간을 많이 차지함. 구버전(MS-Word 2003 이하, 글 2007 이하)에서 작성한 옛한글 문서 와 신버전에서 작성한 옛한글 문서의 문자코드가 달라 호환성에 문제 발생. 글 2010에서 입력한 옛한글은 조합식이므로, 글 2007 이하 버전에서 열면 초 성, 중성, 종성이 조합되지 않고 따로따로 나옴.
를 표현함. 하나의 글자를 표현하는 데 소요되는 바이트 수가 일정하지 않음. 종성이 없는 옛한글 글자: 초성 2바이트 + 중성 2바이트 = 4바이트. 종성이 있는 옛한글 글자: 초성 2 + 중성 2 + 종성 2 = 6바이트. 현대 한글은 모두 2바이트. 옛한글 한 글자를 표현하는 데 소요되는 바이트 수가 현대 한글보다 많 아 저장 공간을 많이 차지함. 구버전(MS-Word 2003 이하, 글 2007 이하)에서 작성한 옛한글 문서 와 신버전에서 작성한 옛한글 문서의 문자코드가 달라 호환성에 문제 발생. 글 2010에서 입력한 옛한글은 조합식이므로, 글 2007 이하 버전에서 열면 초 성, 중성, 종성이 조합되지 않고 따로따로 나옴.")
39
한글 문자코드의 역사에서 얻을 수 있는 교훈 정보화에 있어, 한글의 특성을 컴퓨터상에서도 잘 반영할 수 있도록 할 필 요가 있음. 완성형보다는 조합형이 한글의 구조적 특성을 잘 반영. 정보화 정책은 근시안적이기보다는 먼 미래를 내다볼 수 있어야 함. KS C 5601에서 한글 2350자만 코드값을 배당한 것은 근시안적 결정. backward compatibility를 깨지 않는 것이 좋음. 깰 경우 구버전에 입각한 데이터와 신버전에 입각한 데이터가 양립 불가능하게 됨. (옛한글 처리 방식의 변화로 호환성 깨짐.) 국제 표준(예: 유니코드), 국제 동향에 민감/신속/적절히 대응해야 함. 가능한 한 국제 표준을 따르는 것이 좋음. 사용자 정의 영역에 배당된 글자(예: 옛한글, 구결자)는 이들 글자를 지원하는 폰트 가 설치되어 있어야만 제대로 출력됨. 해당 폰트가 설치되어 있지 않은 컴퓨터(예컨대 외국)에서는 옛한글이 제대로 보이 지 않음. 외국인 한류 팬이 한국 전통 문화를 배우려 해도 지장이 많음.
 국제 표준(예: 유니코드), 국제 동향에 민감/신속/적절히 대응해야 함. 가능한 한 국제 표준을 따르는 것이 좋음. 사용자 정의 영역에 배당된 글자(예: 옛한글, 구결자)는 이들 글자를 지원하는 폰트 가 설치되어 있어야만 제대로 출력됨. 해당 폰트가 설치되어 있지 않은 컴퓨터(예컨대 외국)에서는 옛한글이 제대로 보이 지 않음. 외국인 한류 팬이 한국 전통 문화를 배우려 해도 지장이 많음.")
40
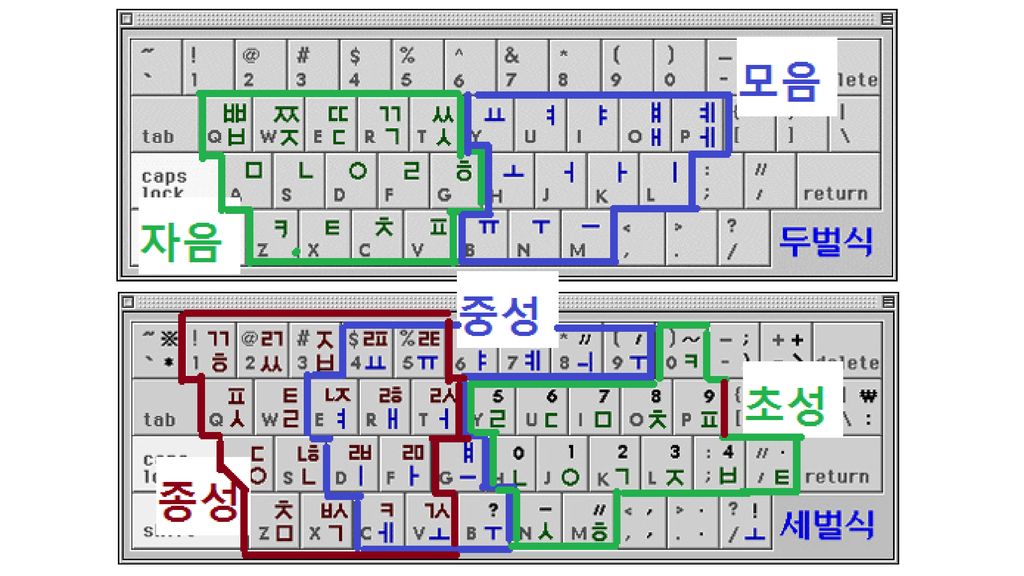
문자 입력: 키보드 대형 컴퓨터나 개인용 컴퓨터(PC)가 주종을 이루는 시대의 가장 일반적 인 입력 장치는 키보드.
키보드에서 각 문자(또는 문자 구성요소. 예컨대 자소)와 키의 매핑을 어 떻게 할 것인가? 키 배열을 어떻게 할 것인가? 한글: 2벌식, 3벌식 등 영문자: QWERTY 자판 등 입력을 효율화할 수 있는 키 배열을 고안하는 게 중요. 그러나 더 효율적인 키 배열을 고안해도, 이미 자리잡은 키 배열을 대치하기가 매 우 어려움. 2벌식, QWERTY가 효율성이 상대적으로 떨어지는데도 표준으로 자리잡음. 기호(문장부호)도 일상생활에서 자주 쓰는 것을 자판에서 쉽게 입력할 수 있도록 배열할 필요가 있음. (예: 가운뎃점) 거꾸로 현재 통용되는 자판에서 쉽게 입력할 수 있도록 문장부호에 관한 어문규 범에서 배려할 수도 있음. (최근의 문장부호 규정 개정)
와 키의 매핑을 어 떻게 할 것인가 키 배열을 어떻게 할 것인가 한글: 2벌식, 3벌식 등. 영문자: QWERTY 자판 등. 입력을 효율화할 수 있는 키 배열을 고안하는 게 중요. 그러나 더 효율적인 키 배열을 고안해도, 이미 자리잡은 키 배열을 대치하기가 매 우 어려움. 2벌식, QWERTY가 효율성이 상대적으로 떨어지는데도 표준으로 자리잡음. 기호(문장부호)도 일상생활에서 자주 쓰는 것을 자판에서 쉽게 입력할 수 있도록 배열할 필요가 있음. (예: 가운뎃점) 거꾸로 현재 통용되는 자판에서 쉽게 입력할 수 있도록 문장부호에 관한 어문규 범에서 배려할 수도 있음. (최근의 문장부호 규정 개정)")
42
키보드 문자 입력 방식의 국가간 비교 중국은 영문 자판에서 한어병음을 이용하여 입력.
로마자(영문자)로 입력한 뒤 한자로 변환 일본도 영문자로 입력하여 가나나 한자로 변환. 한글, 영문자는 중국, 일본의 한자와 비교하면 훨씬 간단. 변환이라는 추가 단계를 거칠 필요가 없음. 그러나 이러한 편리함이 안이한 태도를 낳은 측면도 있음. 중국, 일본에서는 예측 입력 시스템(자동 완성 기능)이 발달하였음. 긴 표현의 앞 부분만 입력하면, 사용자가 입력하고자 하는 표현을 컴퓨터가 예측하여 팝업 으로 제시해 줌. 사용자는 앞 부분 조금만 입력한 뒤 팝업으로 뜬 표현을 클릭하면 됨. 사용자가 입력한 앞 부분으로부터 예측되는 표현이 복수 있을 때 사용자의 과거의 입력 이력, 일반적인 사용 빈도 등을 참조하여 고빈도 표현을 위에 제시. 한글 입력에서는 이러한 예측 시스템이 별로 발달하지 않았음. 몇몇 인터넷 사이트, 사전, 네비게이션 등에서 부분적으로 사용될 뿐. (예외: 초성 입력) 예측 시스템을 구현하기 위해서는 방대한 사전을 구축하고 각 표현의 사용 빈도 를 조사하는 등의 작업이 필요함. 모바일 시대에는 필요성이 증대됨.
로 입력한 뒤 한자로 변환. 일본도 영문자로 입력하여 가나나 한자로 변환. 한글, 영문자는 중국, 일본의 한자와 비교하면 훨씬 간단. 변환이라는 추가 단계를 거칠 필요가 없음. 그러나 이러한 편리함이 안이한 태도를 낳은 측면도 있음. 중국, 일본에서는 예측 입력 시스템(자동 완성 기능)이 발달하였음. 긴 표현의 앞 부분만 입력하면, 사용자가 입력하고자 하는 표현을 컴퓨터가 예측하여 팝업 으로 제시해 줌. 사용자는 앞 부분 조금만 입력한 뒤 팝업으로 뜬 표현을 클릭하면 됨. 사용자가 입력한 앞 부분으로부터 예측되는 표현이 복수 있을 때. 사용자의 과거의 입력 이력, 일반적인 사용 빈도 등을 참조하여 고빈도 표현을 위에 제시. 한글 입력에서는 이러한 예측 시스템이 별로 발달하지 않았음. 몇몇 인터넷 사이트, 사전, 네비게이션 등에서 부분적으로 사용될 뿐. (예외: 초성 입력) 예측 시스템을 구현하기 위해서는 방대한 사전을 구축하고 각 표현의 사용 빈도 를 조사하는 등의 작업이 필요함. 모바일 시대에는 필요성이 증대됨.")
44
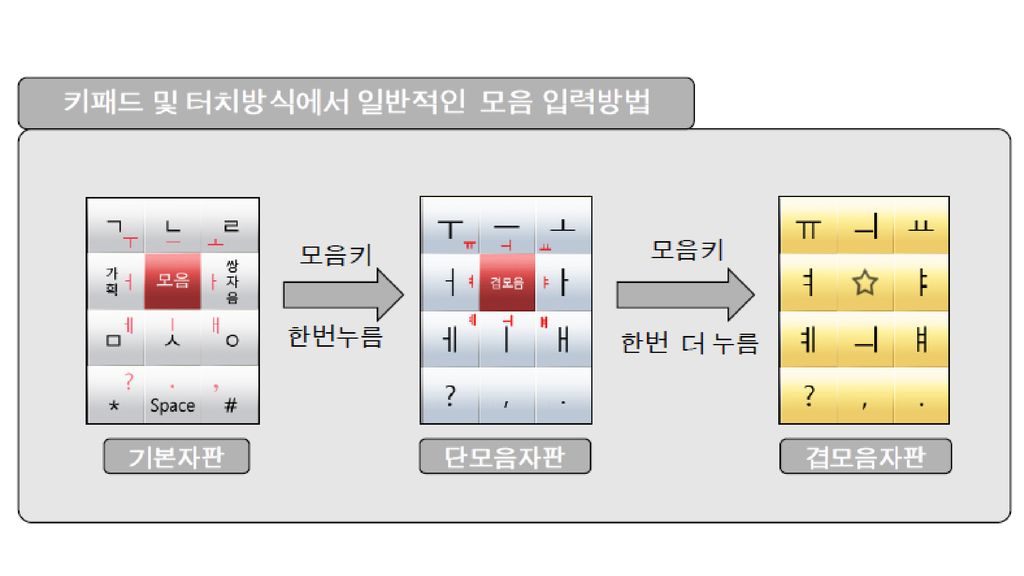
문자 입력: 모바일 기기 모바일 기기의 대두로 입력 장치가 다시 관심의 초점이 됨.
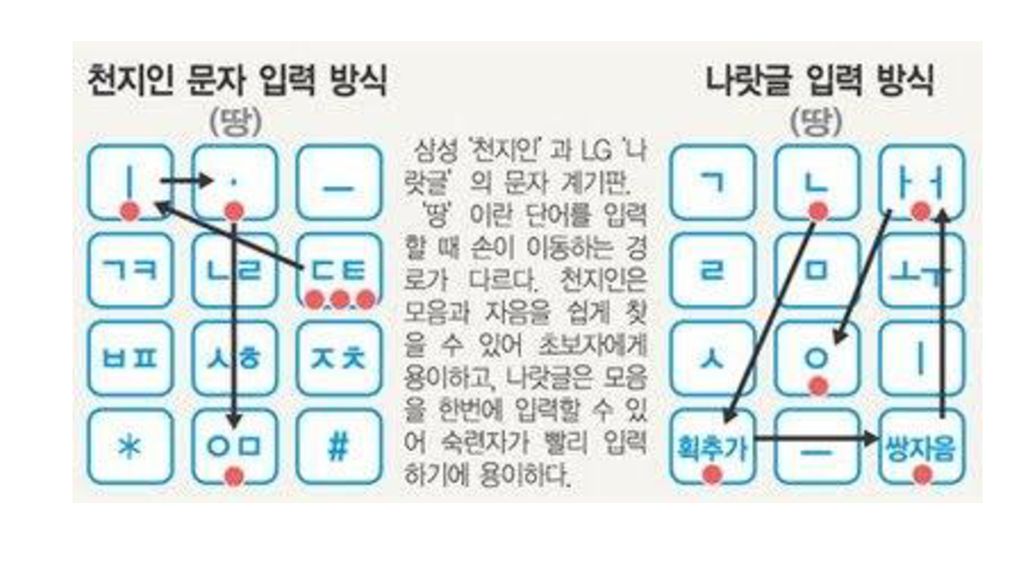
모바일 기기가 소형이기 때문에 키의 수에 제한이 많음. (대개 12개) 영문자의 경우 알파벳 순서대로 하나의 키에 문자 3개씩 배당. 1번 키를 한 번 누르면 a, 두 번 누르면 b, 세 번 누르면 c가 되는 식. toggle 방식: c 상태에서 한 번 더 누르면 다시 a가 됨. 하나의 키에 함께 배당된 문자들 사이에 별다른 연관성이 없고, toggle 방식으로 인해 입력 효율성이 떨어짐. 한글의 과학성/체계성이 모바일 기기에서 특히 빛을 발하여, 모바일 기기에서의 입력 효율이 세계 최고 수준임. 천지인 방식 모음 입력에서 훈민정음 모음자의 구성원리를 잘 반영하였으나 모음 입력을 위해 키를 여러 번 눌러야 하는 단점이 있음. 자음 입력은 기본적으로 toggle 방식 나랏글 방식 자음 입력에서 훈민정음의 가획/병서의 원리를 잘 반영하였으나 (격음: 가획, 경음: 병서) 모음 입력은 기본적으로 toggle 방식
 영문자의 경우 알파벳 순서대로 하나의 키에 문자 3개씩 배당. 1번 키를 한 번 누르면 a, 두 번 누르면 b, 세 번 누르면 c가 되는 식. toggle 방식: c 상태에서 한 번 더 누르면 다시 a가 됨. 하나의 키에 함께 배당된 문자들 사이에 별다른 연관성이 없고, toggle 방식으로 인해 입력 효율성이 떨어짐. 한글의 과학성/체계성이 모바일 기기에서 특히 빛을 발하여, 모바일 기기에서의 입력 효율이 세계 최고 수준임. 천지인 방식. 모음 입력에서 훈민정음 모음자의 구성원리를 잘 반영하였으나. 모음 입력을 위해 키를 여러 번 눌러야 하는 단점이 있음. 자음 입력은 기본적으로 toggle 방식. 나랏글 방식. 자음 입력에서 훈민정음의 가획/병서의 원리를 잘 반영하였으나 (격음: 가획, 경음: 병서) 모음 입력은 기본적으로 toggle 방식.")
48
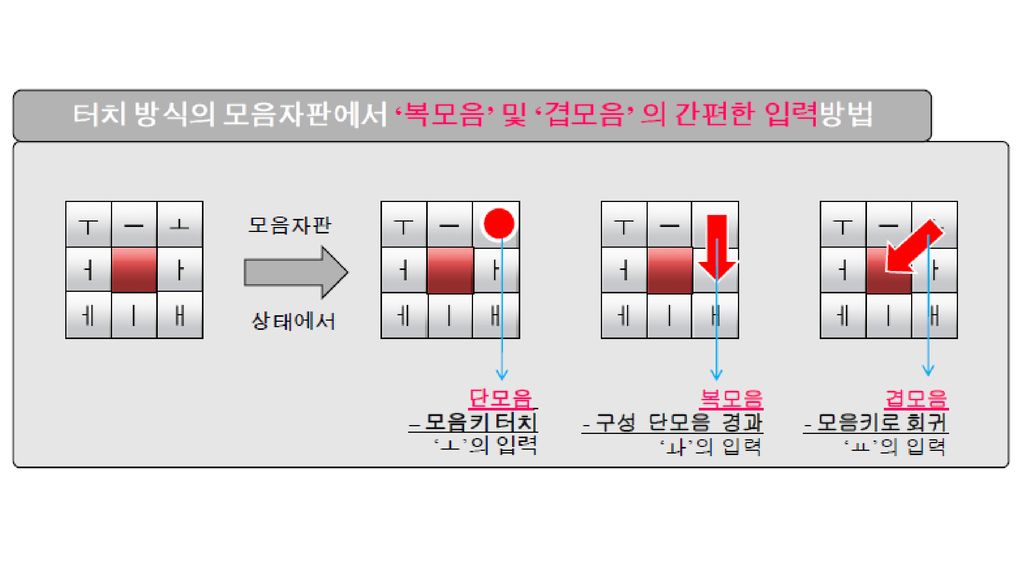
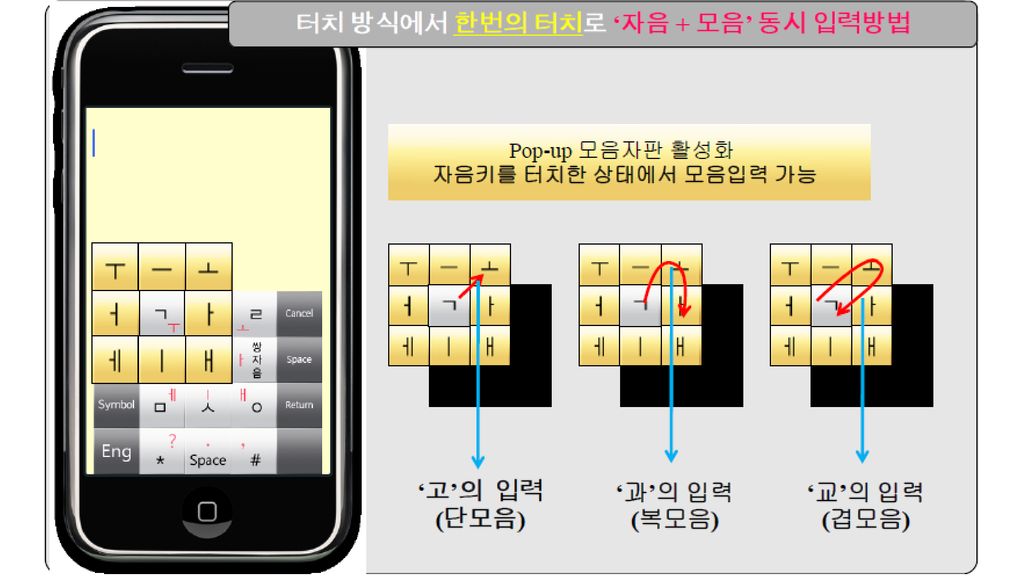
모바일 기기에서 한글 입력의 발전 방향 스마트폰, 터치 인터페이스의 발달은 문자 입력 시스템에도 엄청나게 다양한 발 전 가능성을 가져다주게 되었음. 버튼을 누르는 식의 입력뿐 아니라 drag 등의 입력 방식도 가능함. ㄱ 키를 누르고 [가획] 키를 눌러서 ㅋ을 입력할 수도 있겠으나 ㄱ 키를 터치한 상태에서 drag하여 [가획] 키로 이동하여 손을 뗌으로써 ㅋ을 입력할 수도 있음. (흘려쓴 글씨에서 획들이 연결되는 것과 비슷한 현상) contextual menu, contextual key array [병서] 키는 ㄱ, ㄷ, ㅂ, ㅅ, ㅈ 키를 눌렀다는 context에서만 의미가 있음. [가획] 키는 자음(ㄱ, ㄴ, ㄷ, ㅂ, ㅅ, ㅈ) 키 context에서의 의미와 모음(ㅏ, ㅓ, ㅗ, ㅜ) 키 context에서의 의미가 다름. 양성모음과 음성모음을 별도의 키에 배당하지 않고, 양성모음만 배당한 뒤, [음성] 키를 누 르면 양성모음이 짝이 되는 음성모음으로 바뀌게 할 수도 있음. 키 배열을 고정시키지 않고, 사용자가 무슨 키를 눌렀는지에 따라 그 context에서 적절한 키 배열이 나타나게 할 수도 있음. 모음 키는 수직 획, 수평 획만 배당하고 수직 획을 누르면 그 좌우에 점이 나타나, 좌로 drag하면 ㅓ, 우로 drag하면 ㅏ가 되고 수평 획을 누르면 그 상하에 점이 나타나, 위로 drag하면 ㅗ, 아래로 drag하면 ㅜ가 되고 상하좌우로 좀 길게 drag하면 ㅛ, ㅠ, ㅕ, ㅑ가 되는 식의 방안도 생각해 볼 수 있음. 초성 입력 등, 한글의 특성을 적절히 활용하는 방안에 대한 모색도 필요.
 contextual menu, contextual key array. [병서] 키는 ㄱ, ㄷ, ㅂ, ㅅ, ㅈ 키를 눌렀다는 context에서만 의미가 있음. [가획] 키는 자음(ㄱ, ㄴ, ㄷ, ㅂ, ㅅ, ㅈ) 키 context에서의 의미와 모음(ㅏ, ㅓ, ㅗ, ㅜ) 키 context에서의 의미가 다름. 양성모음과 음성모음을 별도의 키에 배당하지 않고, 양성모음만 배당한 뒤, [음성] 키를 누 르면 양성모음이 짝이 되는 음성모음으로 바뀌게 할 수도 있음. 키 배열을 고정시키지 않고, 사용자가 무슨 키를 눌렀는지에 따라 그 context에서 적절한 키 배열이 나타나게 할 수도 있음. 모음 키는 수직 획, 수평 획만 배당하고. 수직 획을 누르면 그 좌우에 점이 나타나, 좌로 drag하면 ㅓ, 우로 drag하면 ㅏ가 되고. 수평 획을 누르면 그 상하에 점이 나타나, 위로 drag하면 ㅗ, 아래로 drag하면 ㅜ가 되고. 상하좌우로 좀 길게 drag하면 ㅛ, ㅠ, ㅕ, ㅑ가 되는 식의 방안도 생각해 볼 수 있음. 초성 입력 등, 한글의 특성을 적절히 활용하는 방안에 대한 모색도 필요.")
54
문자 출력: 폰트(font) 컴퓨터 운영체제의 system 폴더의 font 폴더 안에 폰트 파일들이 들어 있음.
폰트 파일의 기능은, 특정 코드값으로 저장되어 있는 정보를 화면에 일정한 이 미지(문자의 경우 glyph라 부름)로 변환하여 보여줌. 폰트 파일에서 문자코드와 glyph 이미지 사이의 매핑 관계를 정의해 놓았음. 로마자의 경우, 컴퓨터의 대두 이전부터 출판/언론계에서 매우 다양한 폰트가 개발되었고 이들 폰트가 컴퓨터로 옮겨짐은 물론, 컴퓨터상에서 더욱 다양한 폰트가 개발됨. 스티브 잡스의 특별한 관심 덕분에 애플사의 제품들은 특별히 아름다운 폰트들 을 다양하게 제공. 한글 폰트는 그에 비하면 훨씬 부족한 편. 옛한글을 지원하는 폰트는 더 부족. 주요 운영체제에서 default로 제공하는 폰트가 대부분의 텍스트를 온통 뒤덮는 현상 예: 굴림(윈도 구버전), 돋움(웹디자이너들이 선호), 맑은고딕(윈도비스타 이후), 나눔고딕(네 이버), 산돌고딕(iOS 5.1) 사각형의 틀에 얽매여 있는 편.
로 변환하여 보여줌. 폰트 파일에서 문자코드와 glyph 이미지 사이의 매핑 관계를 정의해 놓았음. 로마자의 경우, 컴퓨터의 대두 이전부터 출판/언론계에서 매우 다양한 폰트가 개발되었고. 이들 폰트가 컴퓨터로 옮겨짐은 물론, 컴퓨터상에서 더욱 다양한 폰트가 개발됨. 스티브 잡스의 특별한 관심 덕분에 애플사의 제품들은 특별히 아름다운 폰트들 을 다양하게 제공. 한글 폰트는 그에 비하면 훨씬 부족한 편. 옛한글을 지원하는 폰트는 더 부족. 주요 운영체제에서 default로 제공하는 폰트가 대부분의 텍스트를 온통 뒤덮는 현상. 예: 굴림(윈도 구버전), 돋움(웹디자이너들이 선호), 맑은고딕(윈도비스타 이후), 나눔고딕(네 이버), 산돌고딕(iOS 5.1) 사각형의 틀에 얽매여 있는 편.")
57
한글 폰트 개발의 방향성 스마트폰, 태블릿, 킨들, 전자책 등의 대두로 폰트의 중요성이 더 커짐.
STDU Viewer, 아이패드의 ibook에서는 이미지 기반 PDF 파일의 페이지를 화면에 띄울 때 OCR을 통해 문자를 인식한 뒤, 각 문자를 매끈한 폰트로 바꾸어 보여줌. (읽을 맛이 남) 안드로이드나 윈도 운영체제에서 거친 문자를 그대로 보여주는 것과는 대조적. 폰트 개발에서, 가독성과 아름다움을 동시에 추구해야 함. 목적에 따라 주안점이 다름. 정보 전달이 주목적일 때는 가독성 중시, 시각예술의 성격을 띠면 아름다움 중시. 한 가지 폰트를 장기간 사용하면 질리게 되므로, 다양한 폰트 개발이 필요. 한글의 조형미를 살릴 수 있는 폰트 개발이 필요. 과거 문헌 자료의 다양한 활자, 서체 등을 바탕으로 하는 것도 하나의 방법. 예: 석보상절체 무료로 자유롭게 쓸 수 있는 폰트가 더 많아져야 함. (cf. free software)
 안드로이드나 윈도 운영체제에서 거친 문자를 그대로 보여주는 것과는 대조적. 폰트 개발에서, 가독성과 아름다움을 동시에 추구해야 함. 목적에 따라 주안점이 다름. 정보 전달이 주목적일 때는 가독성 중시, 시각예술의 성격을 띠면 아름다움 중시. 한 가지 폰트를 장기간 사용하면 질리게 되므로, 다양한 폰트 개발이 필요. 한글의 조형미를 살릴 수 있는 폰트 개발이 필요. 과거 문헌 자료의 다양한 활자, 서체 등을 바탕으로 하는 것도 하나의 방법. 예: 석보상절체. 무료로 자유롭게 쓸 수 있는 폰트가 더 많아져야 함. (cf. free software)")
58
한글은 정보화 측면에서도 매우 우수한 문자 한글의 우수성/과학성/체계성은 정보화와 관련하여 특별히 두드러지게 드러나는 측면이 있음. 모바일 기기의 압축된 키 배열, 초성 입력 방식 등 한글 정보화의 입력, 내부 처리, 출력 단계 모두 나름의 흥미로운 역사를 가지고 있음. 입력: 키보드, 모바일 등에서의 다양한 입력 방식 내부 처리: 조합형, 완성형, 유니코드 등의 다앙햔 한글 코드 출력: 다양한 폰트 한국어/한글 정보화와 관련하여 창의적이고 미래지향적인 혁신이 앞으 로 많이 나올 필요가 있음. 15세기에 세종이 한글을 만든 것은 매우 모험적인 실험이었지만 그것이 지닌 과 학성, 체계성 덕분에 먼 미래에 우리가 큰 혜택을 보고 있음. 한국어/한글을 정보화하는 방안에 대해 창의적이고 효율적인 새로운 방식이 얼마 든지 있을 수 있음. (그러나 기존 방식에 대한 이해를 바탕으로 해야 함.)
")
Similar presentations







![- C-style formatting - format() method. file = open(‘file.txt’, [mode]) ◦ Mode ‘r’: for reading (default) ‘w’: for writing (truncate if already.](/40/11033319/big_thumb.jpg "- C-style formatting - format() method. file = open(‘file.txt’, [mode]) ◦ Mode ‘r’: for reading (default) ‘w’: for writing (truncate if already.>")
 Lecture #2. 2 멀티미디어 구성 요소 멀티미디어 구성 요소 : 1) 텍스트 2) 그래픽 & 이미지 3) 사운드 4) 비디오 & 애니메이션 미디어 접근법 : 1) 특징 : 정보표현 능력 vs 비용 등 2) 컴퓨터.>")
![- 1 - 사용설명서 – 전자세금계산서 (EBANK36524) [ 회계 ]. - 2 - 1. ERPM3 에서 입력한 매출세금계산서 ( 계산서 포함 ) 를 전자적으로 발행합니다. ( 전자세금계산서발행 메뉴 ) ** 국세청전송 - 2009 년 11 월 1 일부터 시범운영.](/40/11034502/big_thumb.jpg "- 1 - 사용설명서 – 전자세금계산서 (EBANK36524) [ 회계 ]. - 2 - 1. ERPM3 에서 입력한 매출세금계산서 ( 계산서 포함 ) 를 전자적으로 발행합니다. ( 전자세금계산서발행 메뉴 ) ** 국세청전송 - 2009 년 11 월 1 일부터 시범운영.>")




![사회문화탐구반 [1 조 ] 주제 : 10 대 ~ 30 대가 선호하는 스포츠 스타 조원 : 박희정, 손유진, 최혜영, 추효은.](/40/11085498/big_thumb.jpg "사회문화탐구반 [1 조 ] 주제 : 10 대 ~ 30 대가 선호하는 스포츠 스타 조원 : 박희정, 손유진, 최혜영, 추효은.>")

 설립년도 ( 사업장 )YYYY.MM( 서울 ) 특화분야기업형태 인력현황상시고용인력 : xx 명 ( 특급 :xx 고급 :xx, 중급 :xx, 초급.>")









